
中文水印字库的自动生成方法
2022-01-27 04:27孙杉张卫明方涵俞能海
中国图象图形学报 2022年1期
孙杉,张卫明,方涵,俞能海
1.中国科学技术大学网络空间安全学院, 合肥 230027; 2.中国科学院电磁空间信息重点实验室, 合肥 230027
0 引 言
数字水印是信息隐藏技术的重要分支,可以用于数字产品版权保护、原始数据的真伪鉴别、数据侦测与跟踪等。数字水印技术是利用多媒体文件的冗余性以及人类感知系统的不敏感性,对多媒体文件进行一些修改使得水印成为载体不可分割的一部分,使人们很难分辨出原始和嵌入水印后的多媒体文件之间的区别。同时,在嵌入水印后的多媒体文件遭受一些故意或非故意的攻击后,仍能从失真文件中提取出水印信息或是证明水印信息的存在。根据水印嵌入的载体形式,可以将数字水印技术分为图像水印(Fang 等,2019;Su和Chen,2018;陈怡 等,2019;邓小鸿 等,2014)、视频水印(Kelkoul等,2018;李淑芝 等,2015)和文本水印(Brassil等,1995)等。本文主要研究文本水印技术,旨在解决文本的泄密溯源问题。
目前,很多重要信息,如各类公文、方案和报告等都是通过文本形式传播。随着无纸化办公的广泛应用,如何保护这些文档不被泄露成为一个重要的安全问题。现存的通过加密、权限控管和身份认证等手段对文件进行安全管理的方法已经比较完善。但是一旦文档被截屏或打印到纸质介质上时,就很难对泄密行为进行监管,当文档遭到泄露后,相关负责人员很难找到泄露源头。为了解决泄密溯源的问题,本文使用文档水印方案,通过向文本中添加不可见的数字水印(如设备号、日期等),一旦含水印文本被泄密,即可从泄密文件中提取出水印信息,从而实现文档信息的溯源。这种溯源能力还可以起到震慑作用,从而减少泄密事件的发生。
由于文档载体相对于其他载体冗余信息要小得多,在文档中嵌入不可见水印比较困难。目前的文档水印方法主要可以分为以下几类:
1)基于文档结构的文档水印算法(Brassil等,1995,1999;Huang和Yan,2001)。这类方法是最早的一类文档水印方法,通过轻微地调整文档结构(如字间距、行间距等)来实现水印数据的嵌入。但这类方法无法抵抗简单的几何变化攻击,而且嵌入的信息量少。
2) 基于自然语言处理的文档水印算法(Atallah等,2001;张宇 等,2005)。这类方法通过调整句子的语法结构,或者通过等价信息替换而不改变句子的意义完成水印嵌入。Atallah等人(2001)根据具体的水印信号对语句结构的顺序进行调整来插入水印。张宇等人(2005)通过修改语义和句法结构(如同义词替换、主动式变被动式等)嵌入水印。这类方法的鲁棒性非常强,但水印的嵌入过程改变了文档的内容,破坏了文档的完整性,对于政府机构文件、法律文件等使用场景来说是不可接受的。
3)基于网格图案的文档水印算法(Suzaki和Suto,2005;Takahashi等,2008;Briffa等,2010)。这类方法在文档上叠加一层底纹代表水印信息,可以用于任何种类的文本文档,嵌入容量很大,也可抵抗多次复印攻击。但是这类方法大多属于可见水印(Suzaki和Suto,2005;Takahashi等,2008),视觉效果较差;而少数的属于不可见水印(Briffa等,2010),鲁棒性较差。
4)基于图像的文档水印算法(Wu和Liu,2004;亓文法 等,2008;艾平,2014)。该类方法首先将文档转化成文本二值图像,以像素翻转的方式嵌入水印,主要应用于抗打印扫描场景。但这类方法只能针对二值文档图像,而且很容易导致笔画边界不平整,降低了文档的视觉质量。此外,该类方法无法实现文档水印的实时嵌入。
5)基于字符几何特征的方法(刘东 等,2007;Xiao等,2018;Qi等,2019)。这是一类更为直观的方案,通过修改字符的大小、形状和亮度等特征表达水印信息。随着深度学习的飞速发展,出现了一些基于深度学习方法的水印方案。FontCode(Xiao等,2018)利用字形流形学习生成新的字体代表水印编码,再使用卷积神经网络(convolutional neural networks,CNN)对水印模式进行识别。但是该方法只适用于字母和数字,无法生成具有复杂字形的字体。Qi等人(2019)针对中文字符特征手工建立特殊的字体库,利用模板匹配实现对水印模式的提取。该方法有很好的视觉质量和很高的鲁棒性,但是需要手动设计字库的修改模式,对于使用中文这种具有庞大数量字符的文字系统来说工作量是巨大的,给实际使用带来了很大的不便。
各类文档水印方法的优缺点如表1所示,从表中可以看出,基于字符几何特征的文档水印方法在视觉效果、鲁棒性和容量这3个方面达到了较好的折中,而且不会改变文档的内容,适合用于文档溯源场景。但是目前现存的基于字符几何特征的中文文档水印还需要人工设计修改特征,不能自动生成字符。为了充分利用字符的几何特征并且能够自动生成字库,本文提出了一种基于自动生成字库的中文文档水印方案。该方案的自动生成字库模块主要由一个端到端的编码—解码器结构的神经网络组成。首先编码器利用字符图片生成变形字体图像,期间利用掩码指导生成函数使得生成的字符扰动集中到字符轮廓上。而后根据生成的字体图像转化为字库,并通过水印中不同的比特信息进行字符的选择完成水印的嵌入,同时利用在形变字体生成时训练好的解码端提取水印信息。与现有的方法相比,本方案最终生成的含水印文档具有较好的视觉质量,其水印提取率在各种数字信道失真场景和打印扫描场景下均保持很高的鲁棒性和稳定性。综上所述,本文主要有以下3点贡献:
1)提出了一种端到端网络框架,由一个编码—解码器联合网络组成,能自动地生成与目标字体相近的中文变形字体图像,以便后续转化成字库,同时能够实现水印的嵌入和消息的提取。
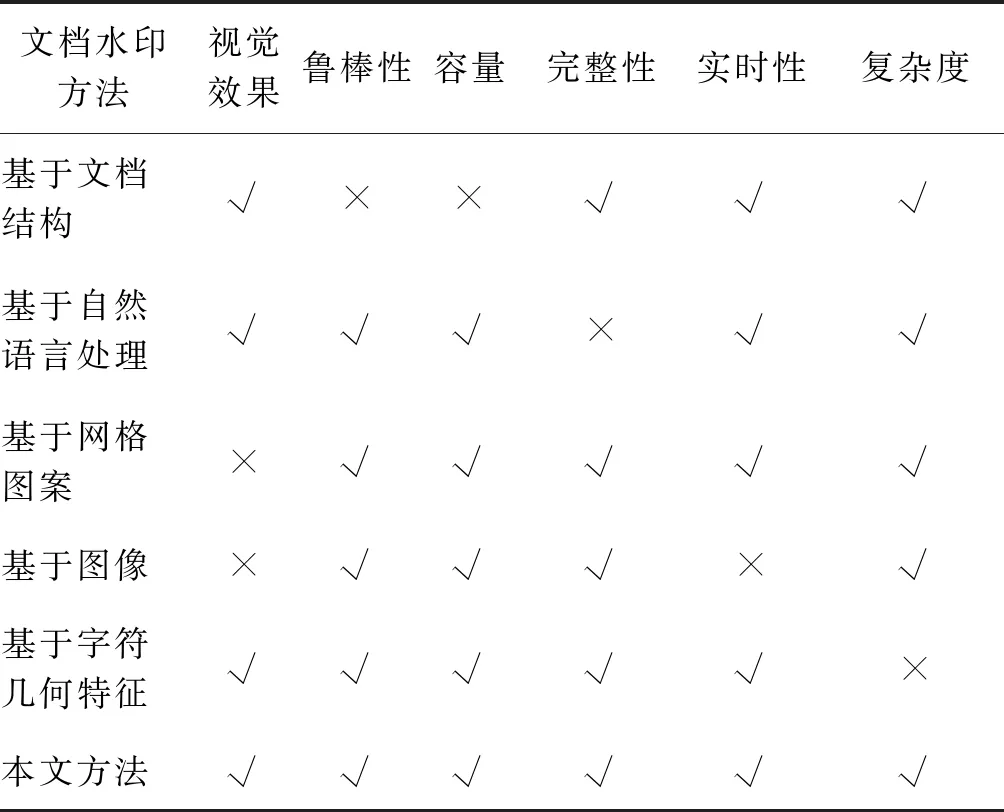
表1 各类文档水印方法比较Table 1 Comparisons of various document watermarking methods
2)提出了一种掩码指导失真函数的方案,有效提升了生成变形字体字库的视觉质量。
3)实验证明了本水印方案在数字噪声信道和打印扫描场景下的溯源有效性。
1 相关工作
1.1 传统的抗打印扫描文档水印方法
传统的抗打印扫描文档水印方法大多是将文档转化为二值图像再进行水印的嵌入。由于打印扫描设备型号、老化程度和人工操作的不同,文档图像将会产生不同程度的失真。为了实现抗打印扫描水印算法,需要找到一种打印扫描前后都不受影响的特征值,即利用打印扫描前后的不变量来指导抗打印扫描水印算法的设计与实现。亓文法等人(2008)通过大量实验找到了打印扫描过程的不变量,即当前字符黑色像素点数量与平均字符黑色像素点数量之间的比值μ,并以这个特征量作为抗打印扫描文档水印算法中嵌入水印的依据。
艾平(2014)在MinWu(Wu和Liu,2004)像素翻转模型的基础上,提出了一种考虑像素块3种度量因素(平滑度、连通性和距离度量)的加权像素反转模型。根据3种度量因素来确定像素翻转策略,并制定像素翻转性分数的打分策略。通过翻转分数比较高的像素点,使得打印扫描不变量μ满足某种约束关系,这里使用奇偶量化将μ修改为量化步长K的奇数倍或偶数倍来代表水印编码。在水印提取过程中,将含水印的文本图像打印到纸质介质上后,再对其进行扫描,得到灰度文档图像。经过字符切分后计算出打印扫描不变量μ′,最后通过奇偶量化对嵌入区域中的字符进行水印提取。
这类方法是通过像素翻转实现文档特征值的修改,因此在水印嵌入前需要将文档转化为二值图像,这直接降低了文档的图像质量。在可翻转像素点不足的情况下,文档嵌入水印后也会产生明显的笔画断连和不平整。
1.2 基于字符几何特征的英文文档水印方法
在FontCode(Xiao等,2018)中,作者根据水印信息对英文字符的几何特征进行一些微小的扰动生成水印文档。嵌入端字符扰动的方法是基于字符结构实现的(Campbell和Kautz,2014),而提取端是通过对扰动模式的识别进行水印信息恢复。字符扰动模型包括字符匹配、流形生成和字体生成3个部分。利用现有字体的多样性,该模型将所有不同的字体中的每个字符单独进行轮廓匹配,而后根据这些高维轮廓特征生成低维流形。字型流形是一种利用高斯过程潜在变量生成模型构成低维空间的映射,同时也能通过对低维空间的修改映射回高维特征,进而推断和获得新的字体。
在FontCode水印嵌入的预处理阶段,首先利用多种字体库生成字体生成模型中的低维流形,并且为常用字体构造一个扰动符号的水印码表。然后根据水印信息选择水印码表中的扰动类型,对原始的文本文档进行字符替换从而完成水印的嵌入。在含水印文档图像经过跨媒介传输后,通过光学字符识别(optical character recognition,OCR)检测得到每个字符的边界框,完成字符分割。而后将单个字符图像送入一个简单的卷积神经网络得到当前水印标签,组合所有的水印标签即可提取出完整的水印信息。
这个方法适用于大多数文档类型,而且人眼几乎分辨不出字符修改的扰动,对各种跨媒介传输都有很好的鲁棒性。但是此方法只能适用于具有简单轮廓的字符集合,比如字母或数字。对于类似中文这种具有复杂形状的字符,此方法无法生成高质量的字体流形进而嵌入水印信息。
1.3 基于字符几何特征的中文文档水印方法
由于字体流形生成矢量字库方法的局限性,上述基于英文字符几何特征的文档水印方法难以应用于中文字符。Qi等人(2019)提出了一种抗打印扫描的中文文档水印方法。在水印嵌入的预处理阶段,该方法通过适当改变字符的拓扑结构,设计字符生成特殊矢量字体库,并根据每个不同的字形代表不同的水印信息位建立了水印码表,生成对应的字符模板。在打印文本文档时,该方法通过终端监控服务程序拦截文本文档内容,而后根据要嵌入的水印信息序列,动态替换含编码的字符嵌入水印信息。在经过跨媒介传输后,对文档进行字符切割,而后利用快速归一化互相关方法(Hii等,2006)对当前字符和模板字符进行模板匹配得到水印信息。
这类方法的性能依赖于变形字库的生成过程,既要保证人眼对字符的几何改变不敏感,又要保证文档在跨媒介传输后仍具有鲁棒性,所以生成高质量的中文字库至关重要。而设计一款中文字体,至少需要六千多个字,甚至能达到一万多字。若仅对常用字生成含水印字符,会限制该类方法的水印容量和适用范围。数量庞大的汉字给中文字库的制作带来了巨大挑战,同时字体的设计和操作需要大量的专业知识,这将耗费大量的人力物力。为了解决这一问题,本文提出了一种可以自动生成变形字库的中文文档水印方法,利用神经网络强大的学习能力自动指导字符扰动的方向,从而实现端到端的水印嵌入和提取。
2 基于自动生成字库的中文文档水印方法
本文提出一种基于变形字库的中文文档水印方案,包括3个阶段。第1阶段是水印字库生成与解码器训练阶段,第2阶段是水印嵌入阶段,第3阶段是水印提取阶段,具体流程如图1所示。在第1阶段中,本文提出了一种基于深度神经网络的变形字体生成网络,能自动生成中文变形字体并保证文字特征在数字和打印扫描信道下的鲁棒性。利用编码—解码器网络生成字符图像,而后通过一些专业的转换工具将字符图像转为字库格式的文件类型(如ttf、ttc文件等),从而实现字库的生成过程。生成字库的同时训练解码器作为水印提取端。在此过程中,本文在编码—解码器联合网络之间加入噪声层以保证文档水印方法的鲁棒性。在第2阶段水印嵌入时,将原始文档分割为单字符,依据水印的信息实现字库中文字的选择,生成含水印的文档。在第3阶段中,含水印的文档经过截屏或打印扫描后,通过文档校正和字符分割,将字符图像送入阶段1中训练好的解码器进行水印信息的提取。文档在泄露后,一旦被捕获,就能提取出水印从而实现信息来源的追踪。
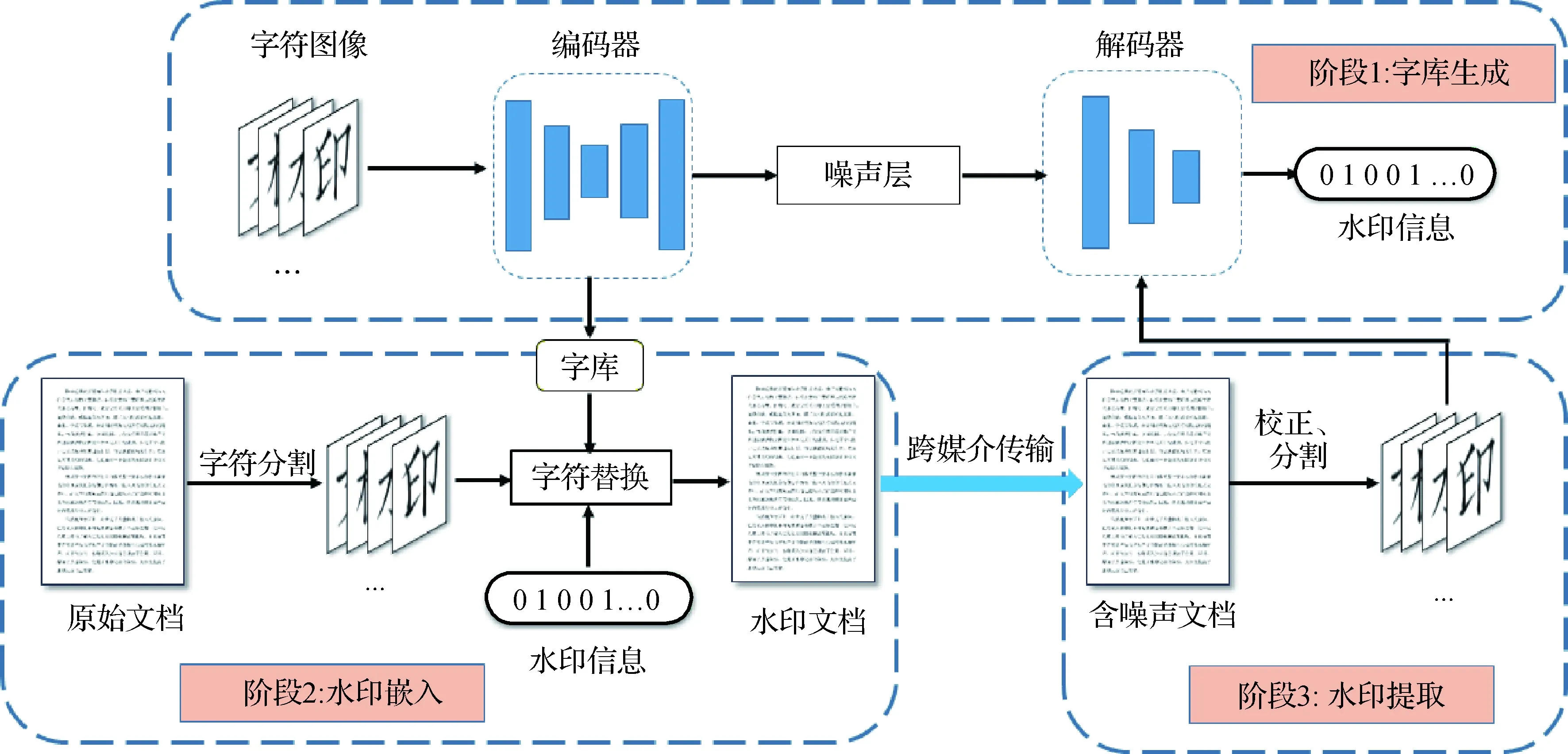
图1 跨媒介传输的文档水印溯源流程Fig.1 Tracing process of document watermarking in cross media transmission
2.1 数字传输信道下的文档水印方法
针对常见的数字传输信道下的失真(如截屏、放缩、高斯噪声和JPEG压缩),本文设计了一个基于可导噪声层的变形字体生成网络结构来自动生成字库,同时结合嵌入算法与提取算法,提出一种能抵抗数字传输信道的文档水印方案。本文方法的整体框架可以分为水印字库生成与解码器训练、水印嵌入和水印提取3个阶段。
2.1.1 水印字库生成与解码器训练
在水印字库生成与解码器训练阶段,通过一个编码—解码器网络自动生成含水印的字符图像并完成水印提取器的训练过程,这是本文水印方案的核心部分。
1)网络架构。本网络模型包括4个部分,分别是:编码器E、噪声层N、解码器D和对抗识别器A,网络架构如图2所示。该网络生成新字库的同时进行水印提取端的训练。字库生成过程为提取端提供训练样本,提取端用于指导字符图像的生成方向,两个模块相互协同,使网络生成视觉质量更高且鲁棒性更强的变形字体。编码器E接收水印信息W和载体字符图像IC后生成编码字符图像IE;噪声层N对编码字符图像IE进行加噪生成含噪字符图像IN;解码器D对加噪字符图像IN解码,提取水印标签W′;对抗识别器A检测当前图像I′∈{IC,

图2 水印字库生成与解码器网络架构Fig.2 Network architecture of generation of watermarked fonts and decoder
IE}是载体字符图像还是编码字符图像。编码器和解码器通过联合训练,最小化载体字符图像IC和编码字符图像IE之间的图像损失LI、编码水印信息W和预测水印标签W′之间的消息损失LM、对抗识别器能否检测到编码字符图像IE的对抗损失LA。通过该网络架构,编码器E和解码器D的联合训练可用于生成含水印字符图片以自动构造字库,同时提取水印信息;对抗识别器A用于提升字库生成的视觉质量;噪声层N用于提升网络抗攻击鲁棒性。
2)编码器。编码器首先对输入的载体字符图像IC进行卷积,生成隐藏层的高维特征,然后将水印信息复制并拼接在卷积后的高维特征向量上,与此同时,将IC也拼接在高维向量中,之后通过反卷积操作生成编码后的字符图像IE。
编码器的网络结构如图3所示,对于给定尺寸为C×H×W的载体字符图像IC,编码器对输入图像应用带有64个输出滤波器的6个残差块,生成64×H×W的图像中间形式。然后在空间上复制水印信息W以形成一个L×H×W消息量,L是水印长度。把得到的消息量连同原始图像添加到中间形式,连接成一个(64+L+C)×H×W的特征图。然后编码器应用带有64个输出滤波器的6个残差块,输出形状为64×H×W的特征图。最后经过一个卷积核为1×1、步长为1的卷积层,生成形状为C×H×W的编码字符图像IE。
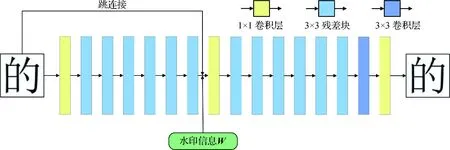
图3 编码器网络结构Fig.3 Network architecture of encoder
为了达到不可见水印的目的,编码字符图像IE在视觉上应该和载体字符图像IC相似。本文方法除了使用像素级别的损失函数衡量IE和IC之间的相似性外,仍需保证图像的修改区域集中在字符笔划的连接处,以保证修改更符合笔顺的连续性。为了实现这样的功能,本文方法在网络中加入掩码指导的失真函数。由此本方法将水印定义为文本边缘区域,通过形态学图像处理中的图像膨胀得到字符图像的修改区域,进而得到掩码图像IM,其中可修改部分置为1,不可修改部分置为100。膨胀操作⊕使用指定的结构元素对IC进行膨胀,该结构元素决定像素邻域的形状,膨胀操作的定义为
IC⊕S={x|(SV)x∩IC≠Φ}
(1)
式中,x表示集合平移的位移量,SV表示对结构元素S做关于其原点的反射得到的集合。(SV)x表示在目标图像IC上将SV平移x,(SV)x与目标图像IC至少有一个非零公共元素相交时,对应的原点位置所组成的集合即为用S膨胀IC的结果。在实验中,本文首先对字符图像IC的黑白像素进行翻转,采用3×3的卷积核作为结构元素进行膨胀。本文将在3.2节通过实验说明加入掩码对字库生成质量的影响。
3)噪声层。为了使本文的模型能够保持对各种图像畸变的鲁棒性,本文考虑了常见的图像失真,并设计了相应的可导噪声层来模拟失真过程,设计的噪声层包括:
(1) 恒等映射层,保持编码字符图像IE不变;
(2) 缩放层,随机缩放编码字符图像IE;
(3) 高斯加噪层,对编码字符图像IE进行高斯加噪;
(4) 平移层,随机平移编码字符图像IE;
(5) 旋转层,随机旋转编码字符图像IE;
(6) 高斯模糊层,对编码字符图像IE进行高斯模糊。
各种噪声层对应的加噪字符图像如图4所示。本文随机选择以上6种噪声层中的一种或几种为一次迭代的总噪声层,噪声层接收编码后的字符图像IE作为输入并输出失真后的字符图像IN。本文将通过实验证明使用噪声层模拟噪声失真,对抗缩放、高斯噪声和JPEG压缩等常见数字失真的有效性。

图4 不同噪声层生成的加噪字符图Fig.4 Noisy character images generated by different noise layers ((a) original character; (b) scaled character; (c) Gaussian noisy character; (d) translated character; (e) rotated character; (f) Gaussian blurred character)
4)解码器。解码器相当于一个字符识别的网络,对编码后加噪的字符图像进行解码,通过网络训练恢复噪声字符图像IN中的水印信息。解码器网络结构如图5所示,该解码器输入含噪字符图像,通过残差块和降采样操作生成具有L维特征通道的中间表示形式,然后使用一个平均池化层和一个全连接层,生成预测的字符标签,用于表达提取的水印消息W′。
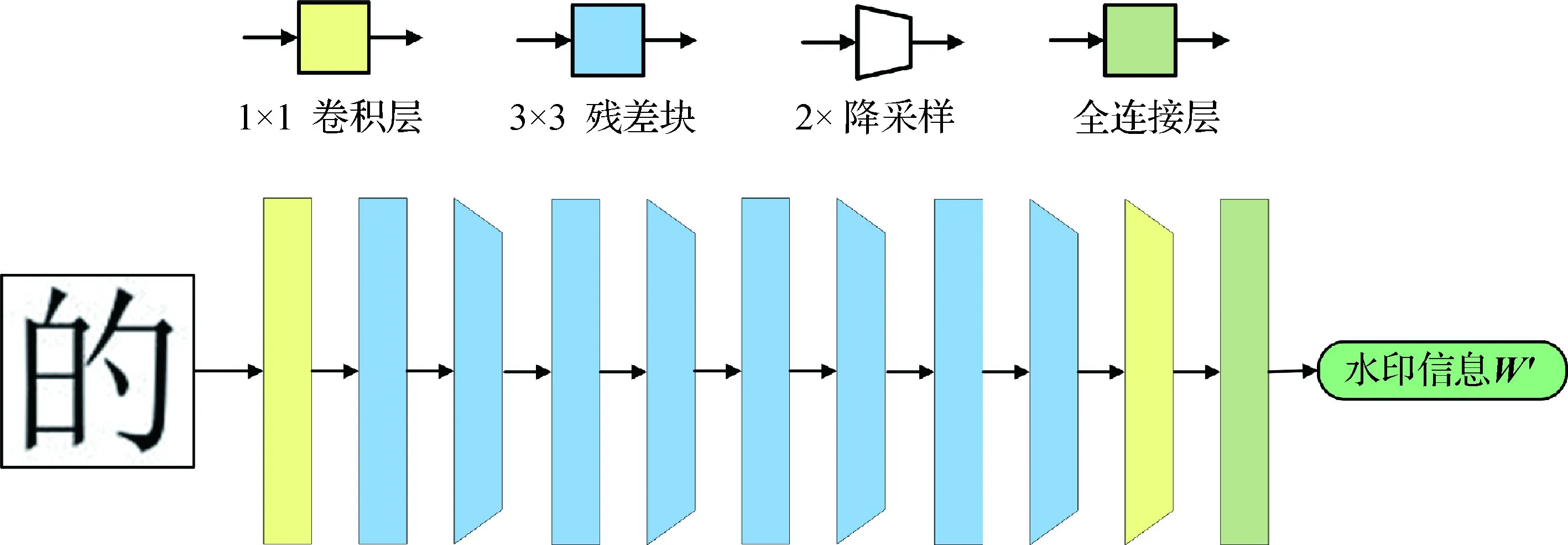
图5 解码器网络结构Fig.5 Network architecture of decoder
5)对抗识别器。对抗识别器用于判断输入图像是编码字符图像IE还是载体字符图像IC。编码—解码器和对抗识别器两个模块作为生成模型和判别模型互相进行对抗训练,使得编码器生成的含水印字符更加真实。本文的对抗识别器使用PatchGAN(Isola等,2017)的结构。
6)损失函数。本文在编码—解码器联合训练网络中定义了6个损失函数。
(1)在编码器E中,最小化载体字符图像IC和编码字符图片IE之间的图像损失LI,即
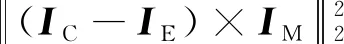
(2)
式中,IM表示掩码图像。
(2)在解码器D中,最小化编码水印信息W和字符解码标签代表的水印信息W′之间的消息损失LM为
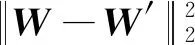
(3)
(3)在对抗网络中,编码器会试图欺骗对抗识别器A,使得对抗识别器无法区分出IC和IE,最终利用生成损失LG提升生成的编码字符图像IE的质量,即
LG(IE)=log(1-A(IE))
(4)
(4)相反,有了IC和IE,对抗识别器A会努力对其进行二分类,通过最小化载体字符图像IC和编码字符图像IE的分类损失LC得以实现,即
LC=log(1-A(IC))+log(A(IE))
(5)
(5)编码—解码器模块总的损失定义为
L2=λ1LI(IC,IE)+λ2LG(IE)+λ3LM(W,W′)
(6)
式中,λ1、λ2和λ3表示控制损失的相对权重,同时对抗识别器也参与其中。
在网络训练阶段,同时训练编码—解码器模块和对抗识别器模块。
2.1.2 水印嵌入
在生成水印字库后,为常用字体构造一个含水印信息的字符码本。该字体中的每个字符对应几种不同的轻微扰动,用这些字的编号代表信息。若生成2个变形字则每个字代表1 bit,若生成4个则每个字可代表2 bit,而原始字符不代表信息。本文在实验中设置生成2种形变字符,构成如图6所示的字符水印码表,字符标签代表水印信息。对于字符形变,人眼几乎不可识别,但是解码器仍然可以识别。所有形变字符根据相应的水印信息生成完整的字符水印码表。在水印嵌入时,根据当前的水印信息,在输入文档中选择水印码表中对应的字符对当前字符进行替换。这样即可把水印信息编码到整个原始文档当中生成含水印文档。

图6 字符水印码表Fig.6 Codebook of watermarked characters
2.1.3 水印提取
在水印提取阶段,需要从当前文档每个字符中恢复字符编码标签以代表水印信息,水印提取过程如图7所示。在收到数字信道传输下失真的文档水印后,首先通过字符分割将整个文档分为单字符图像。而后将当前字符送入水印字库生成阶段训练好的网络中,也就是编码—解码器结构的解码器中。通过解码器识别即可提取出当前字符嵌入的水印消息。
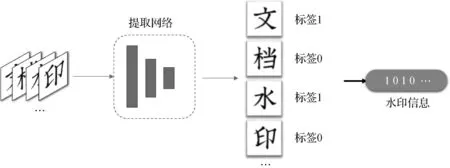
图7 水印提取过程Fig.7 Watermark extraction process
2.2 打印扫描场景下的文档水印方法
对文档进行打印扫描时,文档中的字符经历了数字信号到模拟信号再到数字信号的转化失真。在这个过程中含有大量不均匀的采样和量化操作,会造成原始文件的像素失真和几何失真,导致图像质量大幅下降。而且不同型号的打印扫描设备以及设备的老化程度,都会给文档带来不同程度的失真,导致无法精确地进行失真过程的模拟,这也使得2.1节提到的抵抗数字信道传输的文档水印方案的适应性较差。为此本文提出一种提取端微调方案,在端到端网络的基础上,针对打印扫描场景,仅对字库生成网络进行微调,其他部分均保持不变,使得水印提取的准确率大幅度上升。
打印扫描场景下的文档水印字库生成模型框架如图8所示,本模型将上节中的字库生成模型作为预训练的网络,然后对网络中所提取的新的特征进行训练。这个过程相当于一种迁移学习,也就是微调网络。在微调的过程中,首先通过上述文档水印模型自动生成编码字符图像集,然后将这些字符图片合成完整文档后进行打印扫描。将打印扫描文档进行预处理和字符切割后作为数据集传入解码器,单独调整解码器。本文通过实验证明了使用较小的数据集对网络进行微调即可大幅度提高网络在打印扫描场景下文档水印的提取率。

图8 打印扫描场景下的文档水印网络架构Fig.8 Document watermarking network architecture in print-scan scene
3 实验结果
3.1 实验设置
针对数字信道传输和打印扫描这两种应用场景,实验对本文中文文档水印模型进行了性能评估。实验过程中采用随机生成的二进制序列作为水印信息,打印扫描设备是HP OfficeJet Pro 8720,分辨率均设置为600 dpi。实验中采用的数据集是中文宋体字符图像,包含常用的3 000个汉字,单幅字符图像大小为64×64像素。测试集是具有252个中文字符的真实文档,在本实验中,每个字符嵌入1 bit水印信息,因此整个文档共嵌入252 bit信息。
本文从以下3个指标来衡量文档水印模型:1) 视觉质量,即生成的水印图像和原始图像的相似度;2) 鲁棒性,即图像遭受截屏失真和打印扫描失真后,水印提取的成功率;3) 容量,即整个文档中嵌入的水印信息比特。
3.2 掩码失真的重要性
本文方法在编码器中分别使用掩码和不使用掩码指导的损失函数生成含水印的编码字符,其他结构均保持不变,效果对比如图9所示,图9(a)表示输入的载体字符图像IC,图9(b)表示使用的掩码图像IM,图9(c)表示使用掩码图像IM生成的编码字符图像IC,图9(d)表示未使用掩码图像生成的编码字符图像IE′。从图中可以看出,未使用掩码图像的编码器生成的字符图像的文字部分出现断连和伪影,这些改变对于人眼来说是非常明显的。而使用掩码图像的生成字符很好地保证了笔划的连续性,表现为仅改变了某些部分的粗细,生成结果和载体字符图像非常相似,有很好的视觉效果,应用到文档中人眼几乎不可区分。所以在接下来的实验中均使用掩码指导的损失函数来生成字库。

图9 使用掩码和未使用掩码生成效果对比Fig.9 Comparison of the effect of using mask and not using mask ((a) original character; (b) mask image; (c) character using mask; (d) character not using mask)
3.3 视觉质量评估
本文对真实的中文文本文档嵌入水印,用以测试本文方法的效果。图10(a)是没有进行水印嵌入的原始图像,共有252个中文字符。在本文方法的字体生成过程中,每个字符嵌入1 bit信息,共嵌入252 bit水印信息。图10(b)显示了使用本文方法嵌入水印后的文档效果。可以看出,文档嵌入水印后的视觉质量非常好,人眼几乎不能分辨出与原始文本图像的差别。
图11展示了本文方法和方法1(亓文法 等,2008)、方法2(Qi等,2019)以及方法3(Fang等,2019)嵌入水印后的局部文档效果比较。方法1中的量化步长K设置为0.15。从图中可以看出,方法1嵌入水印后的字符出现了笔画的残缺、断连和毛刺,这是由于此方法基于文档二值图像,像素点只有翻转和不翻转这两种状态,修改任意像素点对视觉的影响都是巨大的。

图10 嵌入水印前后的文档视觉效果对比Fig.10 Comparison of document visual quality before and after embedding watermark ((a) before; (b) after)

图11 不同方法嵌入水印前后文档局部放大对比Fig.11 Comparison of local enlarged drawings of documents embedded watermark by different methods ((a) original; (b) method #1; (c) method #2; (d) method #3; (e) proposed scheme)
方法2的生成图像的视觉质量相比之下要好很多,这是由于利用了字体设计的专业知识改变字符的拓扑结构,生成人眼不易觉察差别的高质量字库。但是数量庞大的汉字给中文字库的制作带来了巨大挑战。同时在设计字库时,需要考虑怎样修改字符使得文本在失真后仍能识别出这些变化模式,这个设计过程具有较强的主观性和不确定性。
方法3是目前效果较好的图像水印方法,但用于文档水印时生成的字符图像背景出现了大面积的块状浅灰色噪点,这些噪点在文档打印出来后更为明显。这说明了图像水印方法难以直接应用到文档图像,还需要针对文档的特征设计特殊的文档水印方案。此外,这类基于图像的方法需要首先将文档转化为图像,不能进行实时嵌入,而基于字库生成的文档水印方法克服了这一问题。在图11中,本文方法嵌入水印后文档局部放大图和原始文档局部放大图几乎没有差异,在编码—解码器联合训练阶段,字符解码网络向字符生成网络提供了字符生成的修改方向,自动设计出机器更容易识别的水印模式,采用的基于掩码的失真设置也限制了对字符图像的修改均分布在字符轮廓上以生成更高质量的字库。
本文用每个字符承载的平均比特数(bits per character,BPC)来衡量水印嵌入方法的容量,用峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)来衡量水印嵌入后文档图片的视觉质量。本文方法与方法1、方法2以及方法3的容量和视觉质量的定量比较如表2所示。方法1需要把某些字符单独分组出来作为调整字符,导致这些字符无法嵌入水印,所以水印容量比其他方法稍低。方法2对某些结构简单的字符,比如“一”,无法修改其拓扑结构也就无法嵌入水印,这些少量的字符在嵌入水印时称为无效字符。方法3中每个64×64像素块可嵌入1 bit的水印,相当于每字符嵌入1 bit消息。本文的方法对任何结构的字符均可生成水印字符,故每字符均也可嵌入1 bit水印。从表2中可以看出,本文方法的PSNR和SSIM值显著高于其他两种文档水印方法,略高于图像水印方法。虽然由于文档图像的特殊性,PSNR和SSIM不足以完全衡量文档的视觉效果,但也一定程度上说明了本文提出方法的生成水印文档图片与原文档最为相似。
此外,本文还采用了主观质量评价,即问卷调查的方式比较这4种方法的视觉质量。问卷随机选取了20个中文汉字,包含具有复杂字形和简单字形的字符图片,将原始宋体字符图像和文档水印方法生成的含水印字符图像进行对比。对两者的相似性程度进行打分,5为最相似,1为最不相似。本文的调查收回了30份有效问卷,问卷的结果如表3所示。从问卷的结果来看,方法3的视觉质量最差,再次说明了图像水印方法不适合直接用于文档图像。方法1的视觉效果也比较差,本文方法的得分比方法2稍高,具有最好的视觉质量。
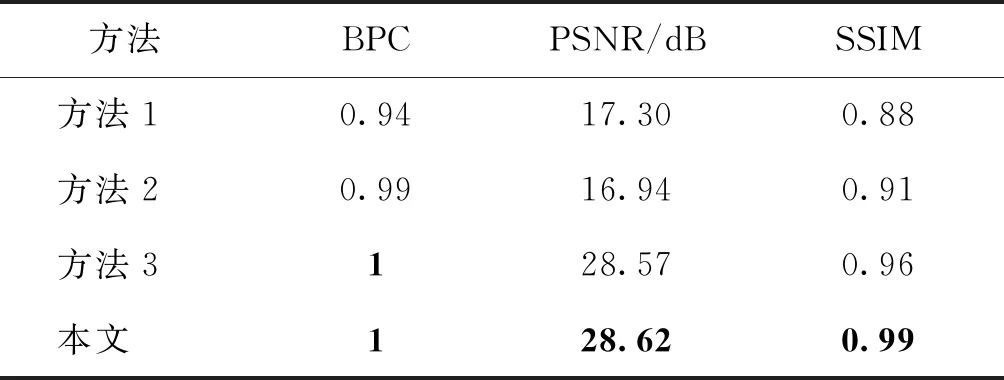
表2 水印容量和视觉质量比较Table 2 Comparisons of embedding capacity and visual quality

表3 文档水印视觉质量问卷结果Table 3 Questionnaire results of visual quality of document watermarking
3.4 针对数字噪声的鲁棒性评估
针对数字噪声的应用场景,这里对本文方法和方法1、方法2、方法3进行了鲁棒性评估比较,水印的提取效果如表4所示。这里的数字噪声包括最常见的截屏、高斯加噪、JPEG压缩和缩放。可以看出,方法3在各种数字噪声中水印提取率均为100%,说明这类图像水印方法对于各类图像处理均有很强的鲁棒性。本文方法在最典型的数字噪声截屏场景下提取率也达到了100%;在高斯噪声和JPEG压缩的失真场景下与其他3种方法取得了几乎相当的效果。本文方法在不同缩放大小的场景下均可正确提取水印。方法1在缩放比例小于1 的失真场景下水印的提取效果较差。该实验验证了本方法在各种数字噪声的场景下水印的提取率都比较稳定。

表4 数字噪声下水印提取效果比较Table 4 Comparison of watermark extraction rate under digital distortion /%
3.5 针对打印扫描场景的鲁棒性评估
针对打印扫描场景对不同字号的文档的水印提取效果进行比较,结果如表5所示。本文方法微调网络的数据集只有500幅字符图像,共训练5轮。为了保证方法1的视觉质量,本文选用的量化步长为0.15,这导致了水印的提取率显著低于其他方法。加大量化步长可以提高抗打印扫描水印提取率,但是会导致文档视觉质量进一步大幅度降低。为了保证鲁棒性和视觉质量的折中,需要谨慎选择量化步长。方法2的水印提取效果在不同字号下均较好。相比于方法2,本文方法在字号增大时,打印扫描下的水印提取率会略微上升。方法3在大字号的打印扫描场景下鲁棒性很高,而在小四号、五号这类小字号场景下无法提取出水印信息。通过比较实验得知,本文的文档水印方法使用几种不同的常用字号在打印扫描场景下的效果均最好。
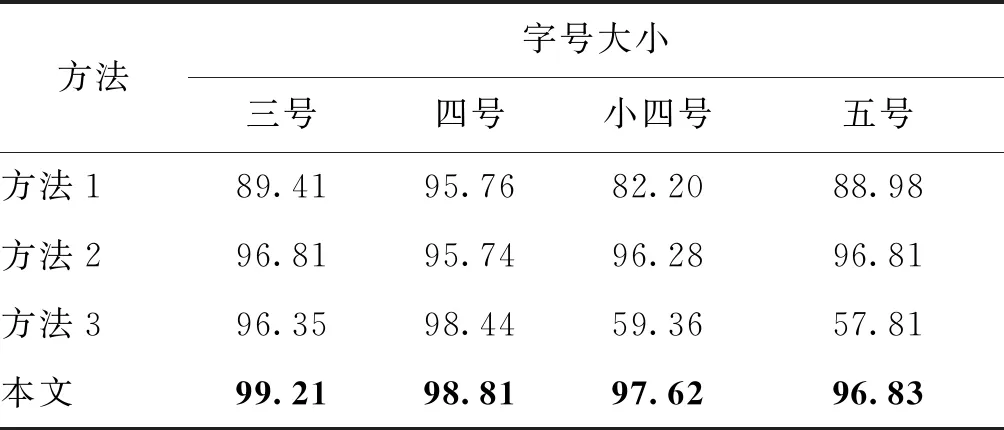
表5 打印扫描场景下不同字号的文档水印提取效果比较Table 5 Comparison of watermark extraction rate of different font sizes in print-scan scene /%
此外,本文针对不同的打印质量和扫描质量进行了交叉提取效果对比。实验选取了最常用的打印分辨率:600 dpi、1 200 dpi和扫描分辨率:400 dpi、600 dpi,文档字号为四号,水印提取效果如表6所示。表中第1行表示打印质量/扫描质量,单位为dpi。从表中可以看出,相比于其他方法,本文方法提取率均为最佳或与最佳结果接近。在打印分辨率为1 200 dpi、扫描分辨率为400 dpi的场景下,由于分辨率相差较大,各方法的水印提取效果均降低。而在其他交叉场景下,本文方法水印提取率均在98%以上。因此,通过比较实验说明,本方法在打印和扫描分辨率不匹配的情况下,也优于其他3种方法。
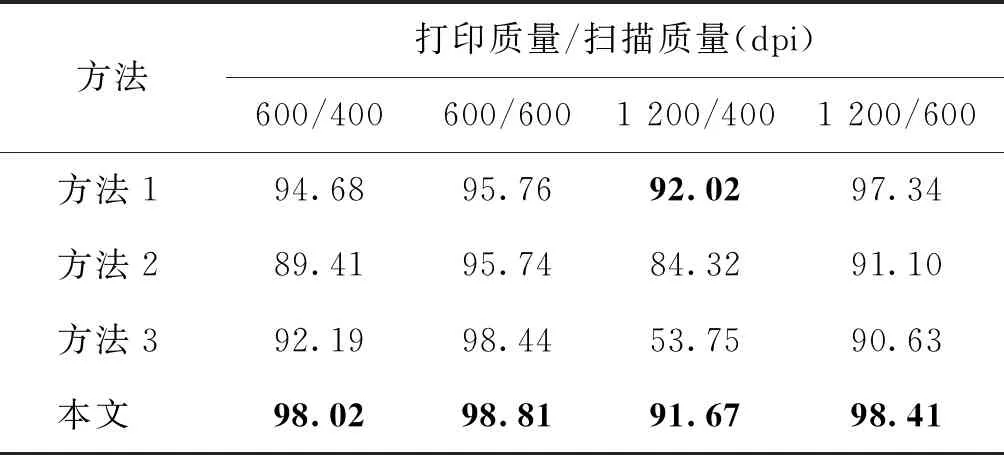
表6 不同打印质量和扫描质量场景下的文档水印提取效果比较Table 6 Comparison of watermark extraction rate of different printing and scanning dpi /%
3.6 针对手写风格字体库的文档水印
为了验证本文文档水印方法的通用性,将本文方法应用于风格化手写字体上。这里使用了3种手写字库,分别是汉仪许嵩体、汉仪赵丽颖体和钟齐山文丰手写体,嵌入水印后的效果如图12所示。图中第1行表示原始手写体字符,第2行表示嵌入水印后的字符。从图中可以看出,尽管手写字体比印刷字体的笔迹更复杂,但本文方法在生成手写字体文档水印方面仍取得了良好的视觉质量。我们也通过水印提取实验验证了该方法同样具有良好的鲁棒性。
4 结 论
利用文档水印技术,可以对文档的泄密源头进行有效追踪,但目前的中文文档水印方法存在复杂度较高、不能自动生成字库的问题。因此,本文提出了一种基于编码—解码器网络的自动生成中文字库的文档水印算法。其中,字库生成网络只需输入目标字体字符图像作为训练样本,即可生成水印编码的字符图像进而生成中文字库,并同步完成水印提取器的训练。而后根据当前水印信息和字库进行字符替换完成水印嵌入,将含噪水印字符送入训练好的提取器即可实现水印的提取。

图12 手写字体原始文档和含水印文档对比Fig.12 Comparison of document visual quality of different handwritten fonts before and after embedding watermark ((a) font HYXuSongJ; (b) font HYZhaoLiYingJ; (c) font HYZhongQiShanJ)
实验表明了本文方法与其他方法相比,无论是主观评价还是定量分析,均具有更好的视觉质量。对于截屏等常见的数字失真场景,本文方法均能保持99%以上的水印提取率。对于打印扫描场景,本文方法在不同字号和多种打印扫描分辨率下,相比于其他方法均具有更好的提取效果。此外,本文还探索了针对手写体风格字库的文档水印效果,表明了本文方法的通用性。
尽管本文方法在数字传输和打印扫描场景下都具有较好的鲁棒性,但目前还不适用于打印拍照和屏幕拍照的场景。这是由于拍照过程对文档的影响更剧烈,难以通过加噪网络对字符失真进行准确模拟。随着智能手机的普及,对文档进行打印拍照和屏幕拍照将愈加普遍,因此针对这两个场景设计鲁棒的文档水印算法是未来可以研究的方向。
猜你喜欢
科技研究·理论版(2021年22期)2021-04-18
现代信息科技(2019年18期)2019-09-10
电脑知识与技术(2017年25期)2017-11-20
科技创新与应用(2017年26期)2017-09-12
电脑知识与技术(2016年28期)2016-12-21
汽车科技(2016年5期)2016-11-14
戏剧之家(2016年18期)2016-10-27
中国知识产权(2016年8期)2016-09-13
中国信息技术教育(2016年13期)2016-09-10
科技视界(2016年16期)2016-06-29
