
抽取式文本摘要新闻文本分类
2022-01-07 02:06:02张丽杰张甜甜周威威
长春工业大学学报 2021年6期
张丽杰, 张甜甜, 周威威
(长春工业大学 计算机科学与工程学院, 吉林 长春 130012)
0 引 言
大数据、云计算等现代信息技术的发展,极大地推动了传统纸质文档快速向电子化、数字化文档进行转变的进程。其中表现最为明显的便是新闻行业。网络新闻发展迅速,每天不断地产生数以万计的新闻文本,令人目不暇接。对新闻文本进行科学分类,既能方便不同的阅读群体根据需求快速选取自身感兴趣的新闻,也能有效地满足不同阅读群体对海量新闻素材进行检索的需求[1]。
新闻文本分类是当前信息爆炸时代的热点问题之一,也是自然语言处理的经典任务场景之一。新闻文本分类的核心思想是对训练数据进行特征提取,对测试数据进行最优特征提取,而后对两者特征进行匹配得到最终结果。一般包括5个步骤:数据预处理、文本表示、特征选择、训练分类器、类别预测[2-3]。
文中结合Word Embedding模型[4]提出一种基于抽取式文本摘要的新闻文本分类方法。其中,文本通过空间向量模型的表示方法,即将每一个权重影响因素都当作一个表示维度。每个维度的权值分别通过TFIDF[5]、LDA[6]、位置权重指派[7]和MMR[8]获取。特征选择、训练分类器和类别预测阶段通过词嵌入模型构建成包含整个新闻文本信息特征的矩阵,通过pytorch框架搭建神经网络,提取特征矩阵中有效信息对新闻文本进行主题分类[9-10]。
1 一种基于抽取式文本摘要的新闻文本分类方法
文中提出一种用于新闻文本分类的方法。首先训练数据采用抽取式文本摘要处理后的新闻内容,按特定格式组成训练集和测试集;然后基于Word Embedding模型将训练数据编码成向量形式,对模型进行训练;最后使用训练好的网络模型将测试数据编码成向量形式,进行新闻的类别预测。
基于抽取式文本摘要新闻文本分类方法流程如图 1 所示。
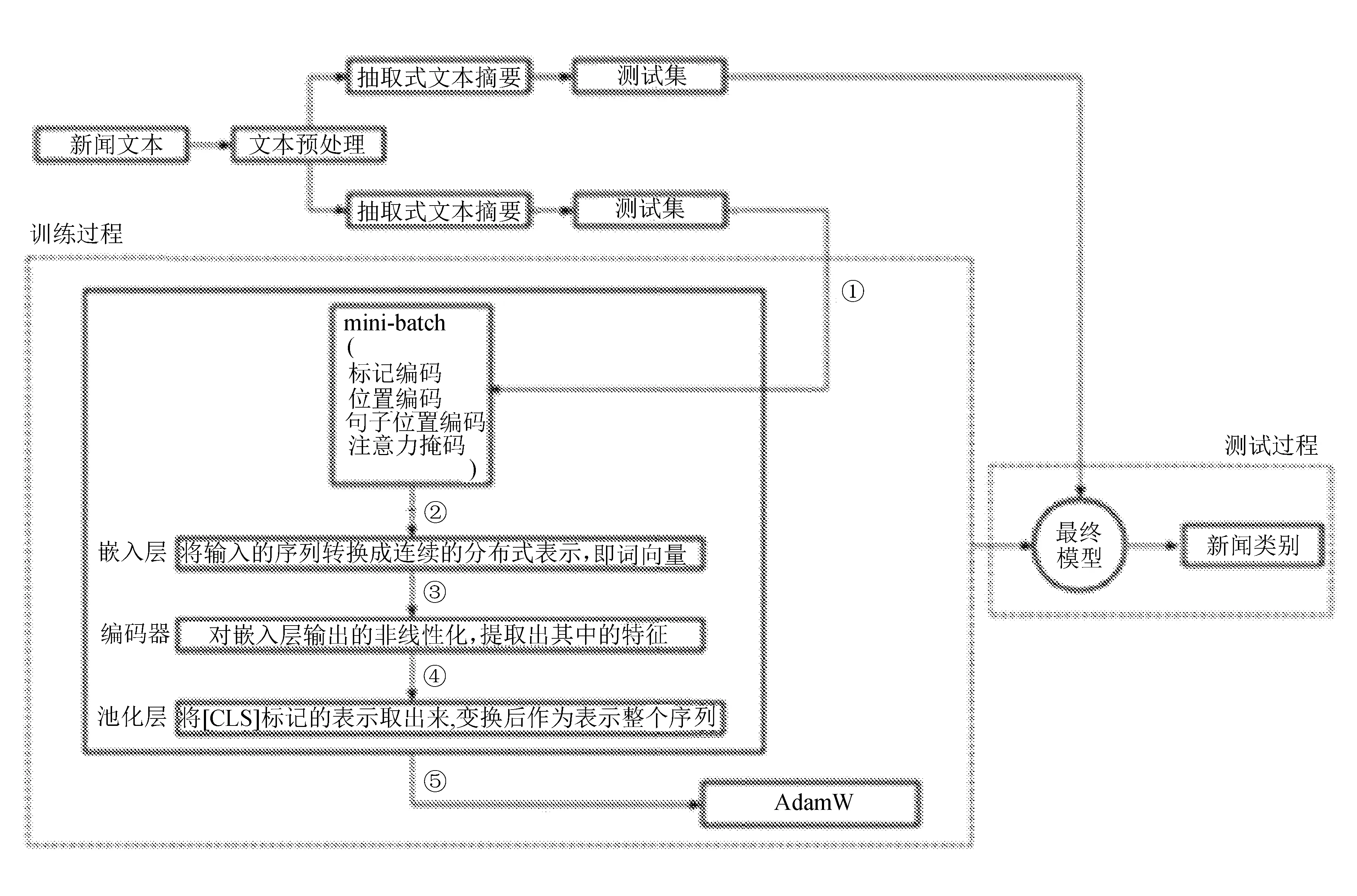
图1 基于抽取式文本摘要新闻文本分类方法流程
通过抽取式文本摘要对预处理后的文本做进一步处理,得到数据集和训练集。利用训练集借助BERT的参数做前向运算,前向结果与损失函数的运算结果进行反向传递,从而实现对BERT的参数做出修改的效果。最终训练结束,得到适合该任务的BERT。紧接着,利用测试集做前向运算,得到分类结果,以此来测试修改后BERT的准确性,若效果较好,该模型可投入使用。
1.1 抽取式文本摘要
对于新闻文本,从中抽取关键句子作为文本摘要,效果较好。文中使用抽取式文本摘要实现方式及选择理由。
1.1.1 实现方式
抽取式文本摘要找出那些包含信息最多的句子,将其作为整篇文章含义的体现。信息量从两个方面来衡量,一是“关键词”,二是“位置关系”。一个句子中包含的关键词越多,说明这个句子越重要;一个句子是首句或结尾句或破折句,就说明这个句子越重要。
实现步骤如下:
Step1:清洗文本;
Step2:分词以及词性标注并计算词频;
Step3:计算每个词的权重;
Step4:按照MMR算法重新计算权重,计算句子相似度,去除相似句子;
Step5:排序最终权重,取前若干句作为最终的文本摘要。
1) 利用TFIDF算法计算句子权重。
对TFIDF进行归一化处理,计算公式为
式中:TF(ti)----特征项ti在文档d中出现的次数;
N----总文档数;
ni----出现特征项ti的文档数。
2)利用LDA主题模型计算句子权重。
i)在LDA模型中,具体定义如下:文档集D={d1,d2,…,dm}中,m代表文档集的文档数目,单一文档为d={w1,w2,…,wn},n代表特征词个数,则文档dm中的第n个特征词为wm,n,潜在主题集合z={z1,z2,…,zK}。则LDA模型生成文档时首先计算主题中的特征词分布概率向量φk~Dir(β)和主题分布概率向量θm~Dir(α),接着求解每个特征词wm,n,生成的概率为
P(zm,n=k|θm),
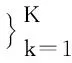
ii)计算出每个词的概率后,求sen_weight,公式为
sen_weight=topic_weight×topic_theta+
tfidf_weight,
其中,topictheta设置为0.2,tfidf_weight为1)中所得句子权重。
3)位置权重指派。
位置权重指派表见表1。

表1 位置权重指派表
4)利用MMR算法重新计算权重。
对MMR原始公式简化,将其应用于文本摘要中,
max[λ×weight(i)-(1-λ)×
max[similarity(i,j)]],
式中:weight(i)----文章第i句的权重,即D(Sj);
similarity(i,j)----当前句子i与已经成为候选摘要的句子j的余弦相似度;
λ----需要调节的参数,用来控制文章摘要的多样性。
1.1.2 选取理由
选取理由主要有两个方面:一是如何衡量好“关键词”的权重;二是如何衡量好“位置关系”的权重。
LDA主题模型可以找出主题词,从而使得对于关键词的选择更加贴近主题。但是,其过程采用的是词袋模型的方法,未能考虑词与词、词与句子、句子与句子之间的顺序关系。但是文档的结构关系,即文档中每个句子所处的位置是非常重要的。对于TF-IDF算法而言,结合文档的全局信息进行判断和计算节点权重,而不仅仅是依赖其中几个节点有限的信息。但是,IDF 的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权重调整的功能,所以这样获得的关键词不一定能够具有代表性。两者均存在一定的局限性。
将TF-IDF算法和LDA主题模型结合,在计算关键词权重时,可以充分考虑词与词、词与句子、句子与句子之间的全局关系,恰好可以弥补不足,但是还存在位置关系的缺陷。一篇文章中不同句子所处位置不同,往往有不同的重要性,对于首句、结尾句以及破折句,一般来说具有重要作用。所以在TF-IDF算法和LDA主题模型的基础上,使用LEAD3算法对不同位置句子的权重做出定义。
为使抽取式文本摘要内容更加全面,MMR算法同时将相关性和多样性进行衡量,使用MMR算法重新计算权重。排序后取出若干句作为最终的抽取式文本摘要。
1.2 Word Embedding模型
Word Embedding模型所做的就是输入一个句子,基于任务然后返回一个基于训练任务的词向量(Word Embedding)。现在较为常用的Word Embedding模型,如BERT,从结构角度来说,BERT由Transformer的编码器构成。通过强大的编码能力可以将语言映射在一个向量空间中,将字词表示为向量。
以BERT为例,结合Word Embedding模型,基于抽取式文本摘要和关键短语提取的新闻文本分类方法做新闻文本分类任务,任务执行图如图2所示。
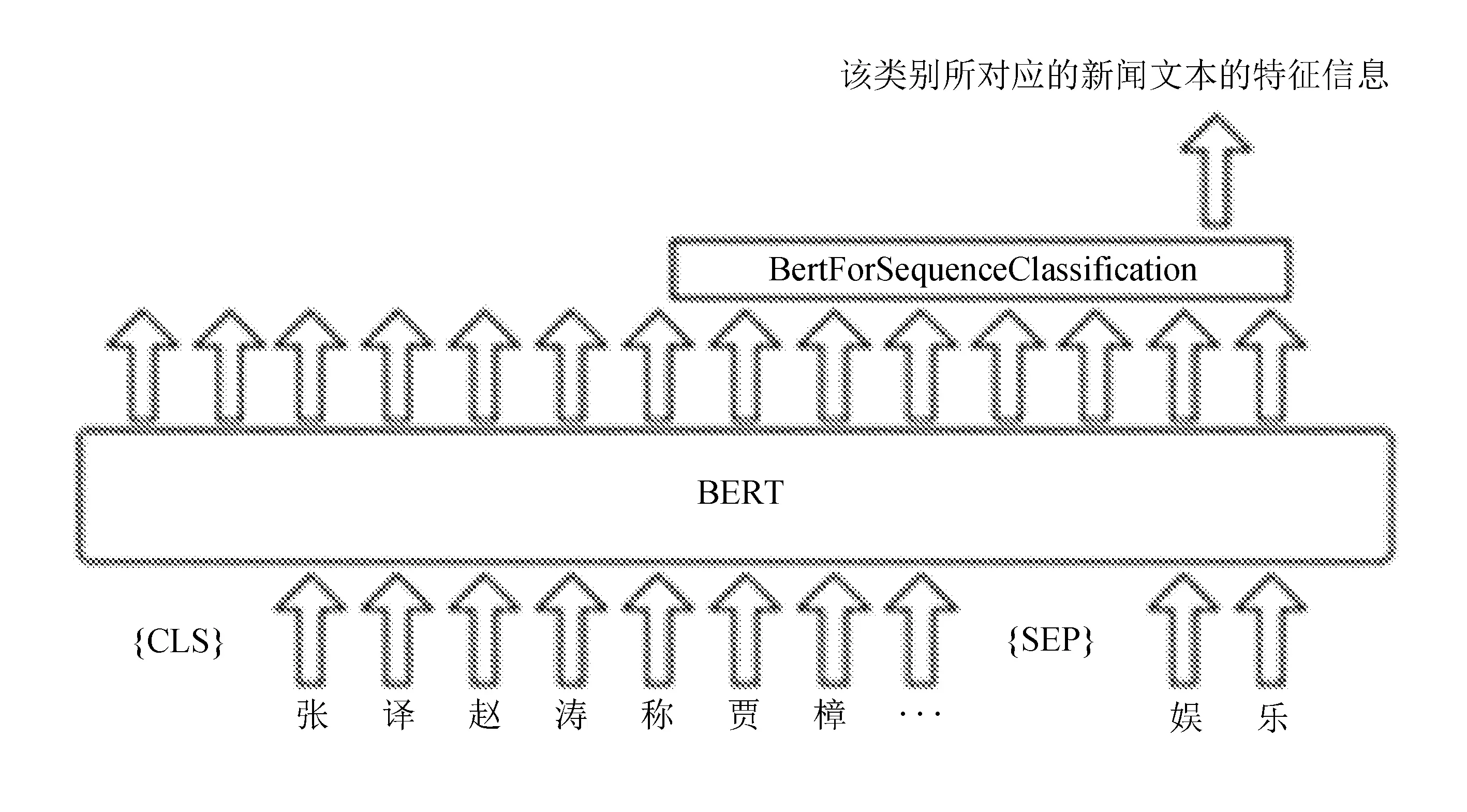
图2 基于抽取式文本摘要和关键短语提取的新闻文本分类方法执行图
图中包含CLS和SEP两个单词,CLS告诉模型所做任务为分类任务,其最后一层的第一个Embedding作为分类任务的展示层。SEP告诉模型左右两边的输入是不一样的。
在输入新闻文本和新闻类别时,使用SEP的特殊单词,将新闻文本和新闻类别一起作为输入。然后在训练好的BERT模型中获取良好的Embedding,将Embedding的结果接入BertForSequenceClassification分类器,最终得到该类别所对应新闻文本的类别特征。
2 实验及结果分析
2.1 实验数据集
使用2个数据集对提出的基于抽取式文本摘要的新闻文本分类方法进行性能测试,包括 THUCNews 数据集、自主构建的数据集。
THUCNews 数据集是由清华大学公开的大规模新闻文本数据集,文中选用其中7个类别的样本,分别为财经、房产、教育、科技、体育、游戏、娱乐。
自主构建的数据集是由个人通过网络爬虫等技术手段,取自人民网、新华网、网易新闻、央视网等新闻网站,并且只作为学习测试使用。新闻种类共计9种,分别为财经、房产、教育、科技、军事、汽车、体育、游戏、娱乐。
数据集的详细情况见表2。
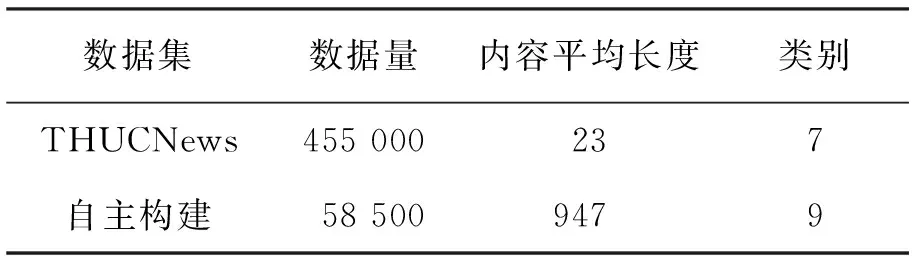
表2 数据集的详细情况
2.2 数据预处理
Step1:对数据集的文本进行清洗,主要包括去除文本中的异常字符、冗余字符、HTML元素、括号信息、URL、Email、电话号码。
Step2:对Step1结果进行处理,分2种情况:
1)字长小于200字,信息量不足,但是特征分布较为集中,不必对其进行抽取式文本摘要操作。
2)字长大于200字,信息量充足,特征分布较分散,做抽取式文本摘要操作,进一步集中特征,将字长降低到200字,并保证信息量充足。
以情况2)为例,处理流程见表3。

表3 文本字长流程表
Step3:将Step2中处理的数据按照“类别,抽取式文本摘要”的格式存储。存储示例见表4。

表4 处理后的数据存储格式表
2.3 实验超参数设置
基于pytorch框架编写神经网络模型,采用AdamW作为模型优化器,使用mini-batch进行批量训练,模型主要超参数见表5。

表5 实验超参数设置
2.4 结果评估与分析
采用准确率(precision)、召回率(recall)、f1分数(f1-score)三个评价指标来衡量分类模型的性能。分别将其应用于FastText模型、BERT模型、RoBERTa-wwm-ext模型[9]。
各模型在THUCNews数据集的指标结果见表6。
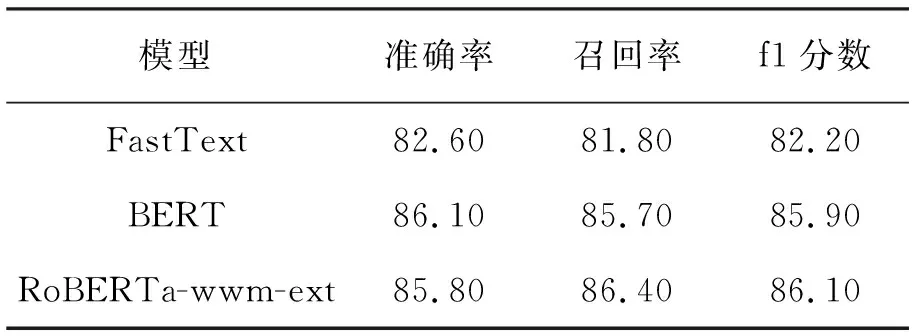
表6 THUCNews数据集的实验结果 %
从表中可以看出,使用文中提出的方法进行分类,模型的三个评价指标都处于较高水平。其中BERT模型的准确率最高为86.10%;RoBERTa-wwm-ext模型的准确率低于BERT模型0.30%,但RoBERTa-wwm-ext模型的召回率和f1分数均为最高,分别为86.40%、86.10%;FastText模型准确率、召回率、f1分数均为最低,但均达到了81.00%以上。可见,文中提出的分类方法对于文本分类问题的效果是相当可观的。
自主构建的数据集上实验的指标结果见表7。
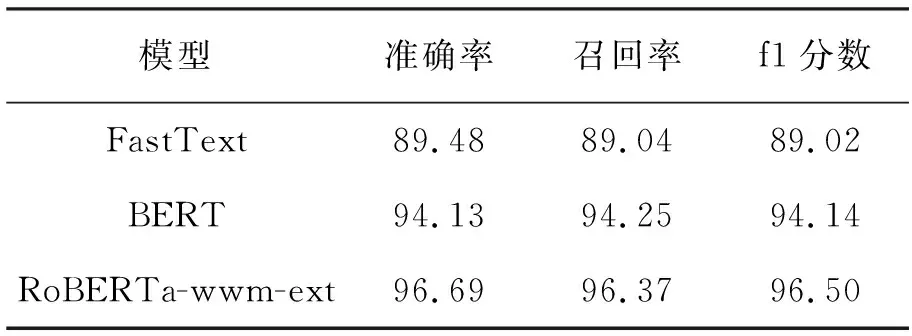
表7 自主构建数据集的实验结果 %
从表中可以看出,自主构建的数据集应用文中提出的方法进行分类,模型的三个评价指标达到了更高的水平。其中RoBERTa-wwm-ext模型准确率高达96.69%,召回率高达96.37%,最终f1分数高达96.50%;即便是排名最低的FastText,准确率也为89.48%,召回率89.04%,f1分数89.02%。
由于三个模型在不同数据集上的效果不同,因此,为了验证各模型的适应程度,对其在不同数据集上的准确率进行比较,具体结果见表8。

表8 不同数据集的准确率 %
从表8可以看出,文中提出的方法在自主构建的数据集上表现更优,说明基于抽取式文本摘要的新闻文本分类方法更适合长文本数据集。主要有两个原因:一是短文本含有的类别信息较少;二是短文本含有的类别信息和多个类别都相关。
基于该方法错误分类的文本见表9。

表9 基于该方法错误分类的文本
综上所述,文中基于抽取式文本摘要和关键短语提取的新闻文本分类方法在文本分类任务上可以达到较高的水平,特别是长文本分类任务。
3 结 语
在结合Word Embedding模型的基础上,基于抽取式文本摘要和关键短语提取,实现了一种新闻文本分类方法。通过对TF-IDF、LDA、位置权重指派和MMR计算每个句子的权重,从而对新闻文本进行准确的抽取式文本摘要。实验结果表明,基于抽取式文本摘要的新闻文本分类方法在多个Word Embedding模型上使用,均得到了很好的效果。其中,在长文本数据集上测试时,RoBERTa-wwm-ext模型准确率高达96.69%,召回率高达96.37%,最终f1分数高达96.50%。表明该方法具有较好的新闻文本分类能力。
文中不足之处:
1)文本预处理中使用的是公开停用词表,而没有构建自主的停用词。新闻领域很多的专有名词是不被包含的,因此会不可避免地出现部分特征信息被过滤掉。
2)样本数量较少,且各类新闻数量分布不均匀,导致模型的性能有限。
3)因为短文本的特征信息多变以及不充分的原因,文中在短文本数据集上的效果较差,更加适用于长文本分类。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
当代陕西(2020年17期)2020-10-28 08:18:18
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
信息安全研究(2016年4期)2016-12-01 06:06:54
新校长(2016年8期)2016-01-10 06:43:59
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
河南科技(2014年15期)2014-02-27 14:12:51
