
Relevant experience learning:A deep reinforcement learning method for UAV autonomous motion planning in complex unknown environments
2021-12-24 02:49ZijianHUXiaoguangGAOKaifangWANYiweiZHAIQianglongWANG
CHINESE JOURNAL OF AERONAUTICS 2021年12期
Zijian HU, Xiaoguang GAO, Kaifang WAN, Yiwei ZHAI, Qianglong WANG
School of Electronic and Information, Northwestern Polytechnical University, Xi’an 710129, China
KEYWORDS Autonomous Motion Planning (AMP);Deep Deterministic Policy Gradient (DDPG);Deep Reinforcement Learning (DRL);Sampling method;UAV
Abstract Unmanned Aerial Vehicles (UAVs) play a vital role in military warfare. In a variety of battlefield mission scenarios,UAVs are required to safely fly to designated locations without human intervention.Therefore,finding a suitable method to solve the UAV Autonomous Motion Planning(AMP)problem can improve the success rate of UAV missions to a certain extent.In recent years,many studies have used Deep Reinforcement Learning (DRL) methods to address the AMP problem and have achieved good results. From the perspective of sampling, this paper designs a sampling method with double-screening, combines it with the Deep Deterministic Policy Gradient(DDPG) algorithm, and proposes the Relevant Experience Learning-DDPG (REL-DDPG) algorithm.The REL-DDPG algorithm uses a Prioritized Experience Replay(PER)mechanism to break the correlation of continuous experiences in the experience pool, finds the experiences most similar to the current state to learn according to the theory in human education,and expands the influence of the learning process on action selection at the current state.All experiments are applied in a complex unknown simulation environment constructed based on the parameters of a real UAV. The training experiments show that REL-DDPG improves the convergence speed and the convergence result compared to the state-of-the-art DDPG algorithm, while the testing experiments show the applicability of the algorithm and investigate the performance under different parameter conditions.
1. Introduction
In recent years, Unmanned Aerial Vehicle (UAV) technology has developed rapidly and been widely used in military warfare. Because military UAVs have the characteristics of fewer use restrictions, no casualties, good concealment, and high cost-effectiveness, they are mainly used in intelligence, surveillance, and reconnaissance1-3; ground attacks4,5; electronic countermeasures6,7; destruction or suppression of enemy air defences8,9; etc. When performing these missions, UAVs are often required to adopt a safe flight policy from the starting point to accurately fly to the destination in a complex unknown environment.
Many studies use traditional methods to solve the UAV Autonomous Motion Planning (AMP) problem. Yang et al.10introduced an improved sparse A*search algorithm which can enhance the planning efficiency and reduce the planning time.Khuswendi et al.11designed a path-planning algorithm based on the potential field method and the A* algorithm and compared it with other algorithms in terms of time and distance.Ren et al.12proposed a three-dimensional (3D) pathplanning algorithm for UAVs and verified the safety and adaptability of the algorithm.These non-learning-based methods have achieved good results when all the information of the environment is known, but they cannot perform well in unknown environments. To solve this problem, some modelbased algorithms have been proposed, such as Simultaneous Localization and Mapping (SLAM). This type of method solves the UAV AMP in two steps:(A) perceive and estimate the environment state and(B) model and optimize the control command.13Bryson and Sukkarieh14introduced a robust inertial sensor-based SLAM algorithm for a UAV using bearingonly observations and tested it in a 2×2 km2real farmland environment. Cui et al.15presented a navigation system based on SLAM and realized the autonomous navigation of a UAV in a foliage environment. Azizi et al.16proposed an efficient inertia SLAM algorithm independent of any external positioning information for UAVs. Because this type of model-based algorithm needs to model the environment, once the environment changes, modelling will lead to unaffordable computation costs.
To overcome the limitations mentioned above, researchers have resorted to using Reinforcement Learning (RL), an online learning-based method to address UAV AMP problems. Sharma17designed an autopilot based on fuzzy Qlearning18to control UAVs. Zhao et al.19introduced a UAV path learning and obstacle avoidance method based on Qleaning. RL can indeed solve the problem of UAV motion planning in unknown dynamic environments, but as the complexity of the environment increases, the commonly known‘‘dimension curse” problem limits its further development.To maintain a better representation of the high-dimensional continuous state space, Deep Mind innovatively combined Deep Learning (DL) with RL to form a new hotspot known as Deep Reinforcement Learning (DRL).20By leveraging the perceived capabilities of DL and the decision-making capabilities of RL, many studies21-29have proven that DRL is an effective approach for controlling UAVs. Liu et al.21solved the target-tracking problems for UAVs in a simulation environment through a DQN20approach. Kersandt22used DQN, double DQN,23and dueling DQN24in the same UAV control mission and compared each of these methods.Polvara et al.25introduced a sequential DQN algorithm for the autonomous landing task of UAVs in noisy conditions. Yan et al.26proposed an improved dueling double DQN algorithm for UAV path planning in dynamic environments with potential enemy threats.However,these value-based DRL methods cannot solve the problem with continuous action space. In the actual battlefield environment, the UAV’s action space is continuous, which requires some policy-based DRL methods to complete the control of the UAV. Rodriguez-Ramos et al.30used the Deep Deterministic Policy Gradient (DDPG)31to address the continuous UAV landing maneuver on a moving platform and tests in real flights. Based on the DDPG algorithm, Yang et al.32designed a training method of UAV air combat maneuver model combined with an optimization algorithm, which can explore better solutions. Li and Wu33proposed an improved DDPG algorithm for UAV ground target-tracking tasks in obstacle environments.
Although DRL has achieved good results in the control of UAVs, as the environment becomes increasingly complex,the convergence result and convergence speed of the algorithm will be greatly affected. For such large equipment as UAVs, each episode of experimentation will require considerable manpower and material resources. It is of great research significance to choose a suitable sampling method and use limited experiences to train the best UAV in as few episodes as possible. Schaul et al.34proposes a Prioritized Experience Replay (PER) sampling method. PER sorts the Temporal Difference error (TD-error) of each experience in the experience pool, and preferentially selects the experiences with the largest TD-error for learning, which greatly improves the convergence speed of DQN. Han et al.35introduced the idea of PER to the decision-making problem of UAVs and conducted experiments in a 3D simulation environment. Shi and Liu36designed a Reward Classification-DDPG (RC-DDPG) algorithm to increase the convergence efficiency of the DDPG algorithm by storing the experiences in two different experience pools according to the reward.Experiments show that the use of these sampling methods can improve the convergence speed of the DRL algorithm to some extent. However, these methods only determine the importance of each experience based on some indicators,and do not consider the relevance to the current state, especially when dealing with practically complex issues such as UAV AMP. In addition, the simulation environment of some of the above studies is too simple and lacks practical reference value. For example, references21,22,25-27,29,35use discrete action spaces, references26,27,33use two-dimensional environments, Ref.28fixes the velocity and altitude of the UAV, and the simulation environment size of most references is not large enough.
To address these problems, explorations and experiments are conducted in this study. The main contributions of this paper are as follows:
(1) A complex 3D simulation environment for AMP is established based on actual UAV parameters.
We build a universal environment based on the parameters of the Chinese‘Wing Loong Ⅱ’UAV,and we adjust the parameters through a large number of experiments so that the DDPG algorithm can achieve a mission success rate close to 80% in this complex environment. The UAV, obstacles, etc.in this environment are decided in equal proportion according to the actual situation. The various parameters of the UAV,obstacles, and targets can be adjusted to simulate different mission scenarios. In addition, the complete UAV kinematics model enables the environment to better simulate real situations.
(2) A Relevant Experience Learning (REL) sampling method is designed and a REL-DDPG algorithm is proposed.
When humans learn new things, they often associate new things with similar old experiences and achieve higher learning efficiency. In order to simulate this phenomenon, this paper introduces a double-screening sampling method REL to select the more conducive experiences for learning. DDPG, one of the state-of-the-art DRL algorithms for solving the problem of continuous action space like UAV AMP,is used as a benchmark method.After adjusting the order of learning and action selection in DDPG to increase the impact of learning on action selection at the current state, the REL-DDPG is proposed.Experimental results show that the UAV trained by the REL-DDPG is better than the UAVs trained by the DDPG combined with the current optimal sampling methods.In addition,REL-DDPG improved the convergence speed by 36.51%and the convergence result by 15.06% compared with the traditional DDPG algorithm.
The remainder of this paper is organized as follows. Section 2 introduces the UAV AMP problem and formulates it as an RL problem. Section 3 proposes the two algorithms EPS-DDPG and REL-DDPG. The simulation environment is described in Section 4. Section 5 presents and discusses the training and testing experiment results. Section 6 concludes this paper and envisages some future work.
2. Problem formulation
2.1. UAV AMP
As mentioned before, in actual military applications, UAV AMP is a key technology. Whether the UAV can safely and accurately fly to the target point will directly affect the success of the combat mission.Here,we take a more common ground attack mission as an example.
Fig.1 shows the combat scenario,where the blue mission is to destroy the target building behind the red without being discovered by the red.Whether the UAV chooses to drop a bomb or perform a suicide attack,it must be as close to the target as possible. In this mission, the possible hazards encountered by the UAV include terrain factors, red air defense weapons,red radars, and red UAVs. Before performing the mission,the blue uses satellites to determine the approximate location of the target in advance, and transmits the target information to the UAV through the Airborne Warning and Control System (AWACS). A blue UAV needs to constantly perceive the external environment through its own sensors during the flight, adjust its posture to keep away from dangerous areas,and complete the mission while ensuring its own safety.
In addition to the abovementioned mission, UAVs are required to complete AMP in most military missions in which UAVs participate.We can understand the UAV AMP as using known information to adjust the posture in real-time and reach the designated location while avoiding collision with obstacles or entering dangerous areas.
2.2. UAV model
To be closer to reality,this paper controls the UAV movement by controlling the load factor. According to Ref.37, the acceleration auof the UAV can be calculated from the required load factor nu:
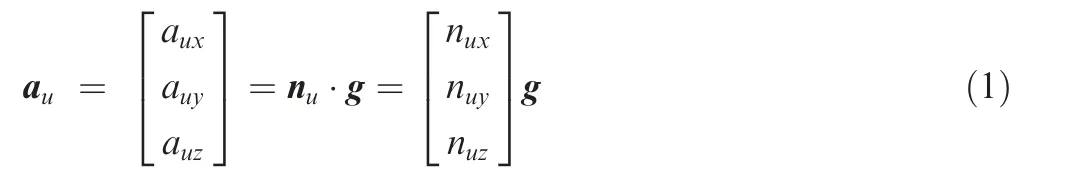
where g is acceleration due to gravity. Through the acceleration au, we can calculate the velocity vuand position puof the UAV at the current moment by integrating the acceleration auand velocity vurespectively according to the velocity v0and position p0at the previous moment:
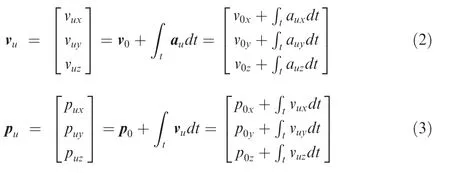
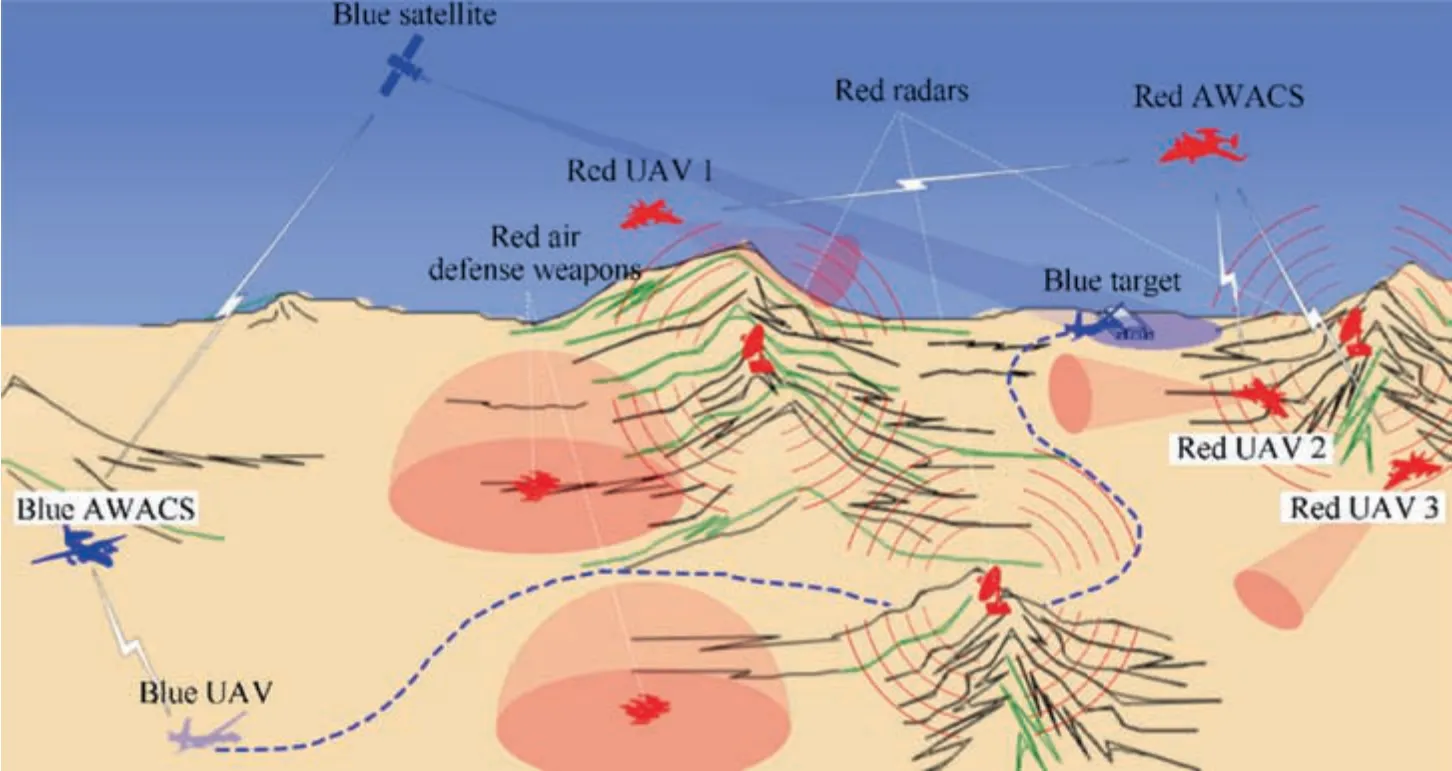
Fig. 1 Combat scenario for the ground attack mission.

2.3. RL for UAV AMP

At each discrete time step t,the state of the UAV is st,and atis the action performed by the UAV at this state. Subsequently,the UAV obtains the reward rtfrom the environment and reaches the next state st+1at the next time step.The action chosen by the UAV at each time step is determined by the collection of policies π. For example, an element π (a|s ) from π represents the probability that the UAV takes an action a at a certain state s. Among all the policies, there is an optimal policy π*.When the UAV follows this policy to choose actions,it can obtain the largest cumulative reward Rt. From the beginning of time step t to the end of the episode at time T,the accumulating reward Rtis defined as follows:

2.3.1. State and action specification

2.3.2. Reward shaping
In the RL process, the design of the reward function is very important. This is because the reward r(s,a ) is the only criterion for evaluating the quality of the selected action a at the current state s. If the reward function is not well designed, it may lead to nonconvergence of the entire algorithm. A wellshaped reward function should contain as many useful human experiences as possible.13When dealing with the UAV AMP problem, due to the huge state space and action space, the use of sparse rewards will cause most of the experiences learned by the UAV to be meaningless, which will seriously affect the efficiency of the algorithm and even lead to nonconvergence.Therefore,we abandon the use of sparse rewards and design a non-sparse reward function that incorporates part of the human experience. The design of the reward function mainly considers the following aspects:
(1) rp: the effect of position on the reward function. The mission of UAVs is to approach the target while avoiding threats. This requires an indicator to evaluate whether the actions taken by the UAV make its position closer to the target position:
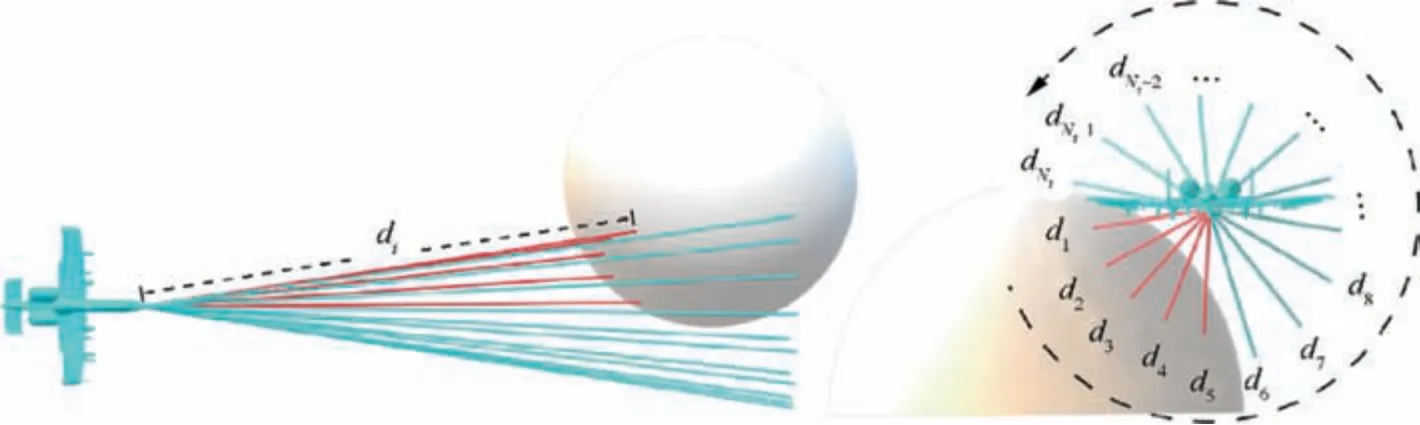
Fig. 2 UAV sensed data from the environment.

where Dpreand Dcurare the distances between the UAV and the target at the previous time step and the current time step,respectively.
(2) ra:the effect of the angles between the UAV and the target on the reward function.To make the UAV approach the target as soon as possible, the yaw and pitch angles between the UAV and the target should be as small as possible.In other words,we hope that at each time step,the UAV’s velocity direction is as close to the direction of the target as possible.

As shown in Fig. 3, φuTand αuTare the yaw and pitch angles between the UAV and the target, respectively.
(3) rh: the effect of flying height on the reward function. In the battlefield environment, the existence of a multipath effect makes the probability of radar finding lowaltitude targets low or even non-existent. Therefore,many countries use low-altitude penetration to complete combat missions in wars.In this paper,we hope that the lower the flying altitude of the UAV is, the greater the reward it can obtain:

where Henvis the maximum height of the environment.
(4) rd:the effect of the degree of danger on the reward function. The UAV perceives the unknown environment through its own TAR,and the return value of the detector determines the degree of danger of the current state.The UAV should complete combat missions while ensuring its own safety. Therefore, the closer the detected obstacle is to the UAV itself, the lower the reward value will be, and the highest reward will be obtained if obstacles are not detected.

where ddis the detection distance of the TAR on the UAV.
(5) rv:the effect of velocity on the reward function.The battlefield environment is changing rapidly, and once an attack opportunity is missed, the difficulty of the mission may be greatly increased. The UAV needs to complete the task as quickly as possible, that is, the higher the velocity,the greater the reward the UAV will receive.

In addition to the abovementioned influencing factors, the UAV will also obtain the corresponding rsand rfwhen the mission succeeds or fails, respectively. In summary, the setting of the reward function in this paper is as follows:
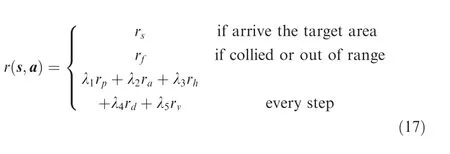
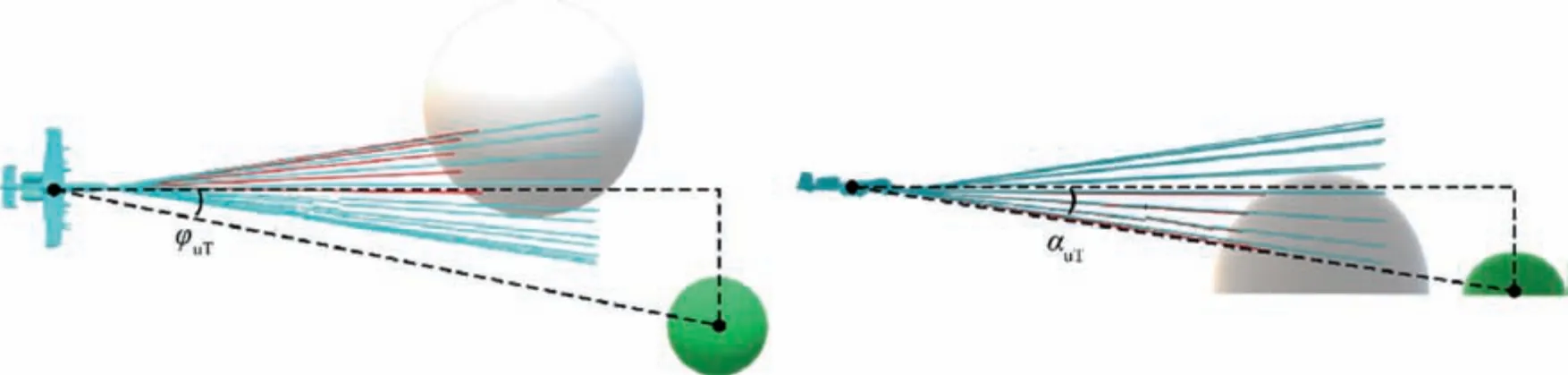
Fig. 3 The yaw and pitch angles between the UAV and the target.
where λ1,λ2,•••,λ5are used to tune the contribution rates of different influencing factors.
3. REL-DDPG for motion control
3.1. DDPG
As introduced in Section 2, the AMP problem of UAVs is a problem of continuous action space. In continuous spaces,finding a greedy policy requires optimization at every time step, but this optimization is too slow to be practical with large, unconstrained function approximators and is nontrivial.31Therefore, the value-based methods of solving the state-action value function are no longer applicable. Policybased methods, a type of method that chooses the next action based on the probability,are suitable to control the motion of UAVs.
Lillicrap31applied the idea of DQN to the continuous action space and proposes the DDPG algorithm based on the deterministic policy gradient42and the actor-critic framework.43,44
As shown in Fig. 4, the main modules in the framework of DDPG are the environment, experience pool, actor network and critic network. The functions of the environment and experience pool are used to generate and store experience,respectively. In the process of continuously interacting with the environment, the agent obtains experiences and stores them in the experience pool for future learning.The actor network is used to determine the probability of the agent choosing an action. When the agent interacts with the environment, it will select actions according to the action selection probability provided by the actor network. The critic network evaluates this action selected by the agent based on the state of the environment. The actor network then modifies the probability of choosing the action based on the evaluation.
To optimize the training process, the DDPG algorithm adopts the idea of the DQN algorithm, and constructs two artificial neural networks with the same structure for the actor and the critic network, called eval-net and target-net, respectively.In the training process,the parameter update frequency of the eval-nets is greater than the parameter update frequency of the target-nets, which can improve the stability of the algorithm.20In addition,to make the actor network more exploratory, DDPG adds independent noise Ntto the output of the actor network:

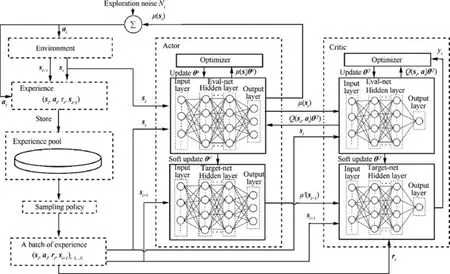
Fig. 4 Framework of DDPG.
where θQ′represents the target-net in the critic network and N is the number of experiences used to learn.
The parameter update method of the target-net adopts a soft-updated method to improve the stability of training:

where τ ∈[0,1 ] is used to determine the update degree. If τ = 1, the update method changes to the hard-updated method used in DQN.
Experiments show that DDPG achieves very good results when dealing with continuous problems. Because the adopted experience playback mechanism20is randomly sampled from the experience database, and a certain policy is not adopted to select better experiences for learning, its efficiency can still be improved.
3.2. EPS-DDPG
3.2.1. Experience pool split
In DRL,the role of the experience pool is to store the interactive information between the agent and the environment for the agent to learn. The agent learns by periodically taking out experiences from the experience pool with moderate probability, thereby continuously improving its policy. Among all of the experiences in the experience pool, different experiences have different effects on network training. This requires the development of a good sampling policy to choose experiences that are more conducive to network convergence to improve the efficiency of training.
When the UAV performs military tasks, the most important thing is to ensure its own safety. Each experience stored in the experience pool corresponds to a different degree of danger for the UAV.This paper proposes an Experience Pool Split(EPS) method that divides the experience pool to store the experiences according to different degrees of danger and associates the sampled experiences with the current state of the UAV to achieve better use of the experiences.
In the UAV AMP problem, the degree of danger of the UAV’s current state can be expressed by the distance between itself and the obstacle directly in front,which can be calculated with the davementioned in Eq. (15). As shown in Fig. 5, the EPS method divides the experience pool into X experience pools and determines the size of each experience pool according to the previous training process. However, this classification cannot exist for a long time. With the training of UAVs,the experience pool is constantly updated,and the policy adopted by UAVs is constantly improving.For example,at the beginning of training, because the UAV knows nothing about the environment, the UAV does not consider too much whether there are obstacles in front of it when performing actions. Therefore, the proportion of dangerous experiences is higher.As the training progresses,the UAV gradually begins to find a good policy to avoid obstacles,and the proportion of dangerous experiences will gradually decrease. At this time, if split experience pools are still used,the neural network will be unstable or even nonconvergent.The corresponding solution is that when a UAV learns a certain obstacle avoidance policy according to this experience pool split method, all of the split experience pools are merged into one, and the order of all experiences in the experience pool is disrupted.
3.2.2. EPS-DDPG algorithm
This paper combines the EPS method with the state-of-the-art DDPG algorithm and finally forms the EPS-DDPG algorithm(Table 1):

Fig. 5 Split and merge the experience pool according to the degree of danger.

Table 1 EPS-DDPG Algorithm.
According to the degree of danger of the UAV, the EPSDDPG algorithm first splits the experience pool and then merges it, which strengthens the connection between experiences and the current state to some extent.However,this algorithm still has some limitations.(A)Past training experience is required. In many cases, past training experience is inconvenient to obtain. Because the EPS-DDPG needs to split the experience pool based on past training experience, this algorithm is not applicable in certain scenarios without training experience. (B) Only an indicator is considered. The EPSDDPG algorithm classifies the experiences in the experience pool according to the degree of danger of the UAV. It may not be able to accurately assess the state based on this indicator alone. Other indicators such as location information and direction information should also be considered. However,once too many indicators are considered, the number of categories of experience pools will also increase sharply,which will bring a certain burden to the split and merger of experience pools. (C) The influence of the merge number Em. Because the capacity of the experience pool is fixed after the split of the experience pool,the value of Emwill greatly affect the convergence result of the algorithm. If Emis too large, the distribution of the experience pool in the later stages of the training will be unreasonable which may affect the convergence results.If Emis too small,a good obstacle avoidance policy will not be learned and the algorithm will become meaningless.To solve these problems,we propose a more reliable algorithm based on the EPS-DDPG algorithm and introduce it in detail in Section 3.3.
3.3. REL-DDPg
3.3.1. Prioritized experience replay
The online storage and use of experiences through the experience pool breaks the correlation between experiences and makes the neural network more stable. At each learning time step,minibatch experiences are taken out with equal probability for learning. However, this equal probability sampling method cannot distinguish the importance of different experiences.Due to the limited capacity of the experience pool,some important experiences are discarded before being fully utilized.To solve this problem and make full use of the experiences,the PER method is proposed.
The PER uses the TD-error of each sampled experience as the criterion for evaluating the priority of the experience, and the calculation method of TD-error is as follows:
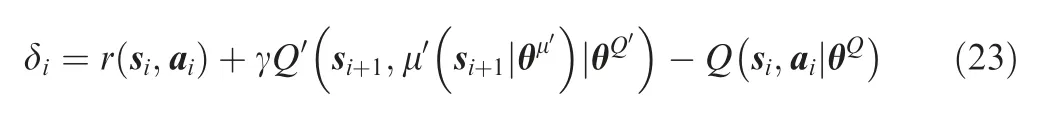
The larger the TD-error is, the greater the influence of this experience is on the update of network parameters, which means that this experience should be learned more. At each learning time step, the TD-error of all sampled experiences is calculated, and the sampling probability of these experiences is updated according to the TD-error.
The sampling probability of each experience is calculated as follows:

where P(i) is the sampling probability of the ith experience in the experience pool and piis the priority of the ith experience.A constant α is used to control the size of pαi, especially when α = 0, P(i) satisfies a uniform distribution.
To improve the efficiency of sampling from the experience pool, the PER algorithm uses a sum-tree structure34to store the experiences. A sum-tree is actually a complete binary tree.The number of leaf nodes is exactly the number of all samples in the experience pool.All leaf nodes are used to store the sampling probabilities of all of the experiences. The value of all remaining nodes is the sum of the values on its child nodes.For example, as shown in Figs. 6, 8 leaf nodes represent 8 experiences. The sampling probability of the experience is the value on the corresponding leaf node. The larger the value is, the higher the sampling probability of the experience is.An input p=24 is randomly given (this input cannot be greater than the sum of the values of all leaf nodes), and the selection is made according to the following steps:
Step 1. Determine whether the current node is a leaf node; if so, the current node is the node that should be sampled.

Fig. 6 Sample process of sum-tree.
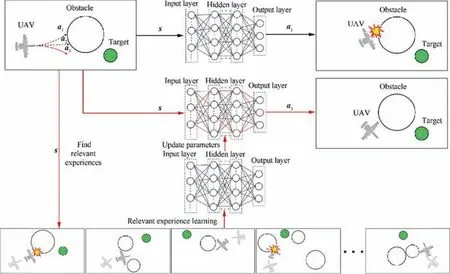
Fig. 7 Effect of learning first and then selecting action.

Fig. 8 Chinese ‘Wing Loong II’ UAV.
Step 2. Compare the value of the left child node of the current node with p. If the value on the left child node is greater than p, set the left child node as the current node and repeat Step 1, otherwise set the right child node as the current node, use the difference between p and the value on the left child node as input data,and then repeat Step 1.
Following this process,the experience on the grey leaf node with probability 12 is sampled.In the actual sampling process,the PER first divides the sum of the sampling probabilities of all experiences in the experience pool into N segments according to the size of the minibatch and then randomly generates input data in each segment and samples the corresponding experience according to the data. The design of this sampling method reduces the time complexity of the algorithm, while screening out those experiences that are more conducive to the convergence of the neural network, thereby accelerating the convergence of the algorithm.
It is undeniable that the PER can not only accelerate the convergence of the algorithm but also improve the convergence results, but it has an obvious shortcoming: the large TD-error of the sampled experience ei= [si,ai,ri,si+1] can only indicate that eihad a large impact on the neural network when it was stored in the experience pool at that time step,but it does not mean that eistill has a great impact at the current time step. Therefore, this paper attempts to design a sampling method to find the experiences that have a greater impact on the neural network at the current time step on the basis of the PER algorithm, which is described in detail later.
3.3.2. Relevant experience learning
Making machines reach the human level or even surpass the human level is a constant pursuit in the field of artificial intelligence.Similar to humans,machines also need a learning process to master certain abilities. Therefore, we try to introduce some theories or mechanisms that humans use in learning into the training of reinforcement learning agents to improve training efficiency.
Ausubel,45an American cognitive education psychologist,proposed a Meaningful Receptive Learning (MRL) theory and caused a strong response in the education field.Unlike traditional theories,Ausubel believes that learning is a meaningful receiving activity, a process of reconstructing the relationship between the new content to be learned and the inherent knowledge in learners’own minds.If the learner memorizes the knowledge to be learned arbitrarily without understanding its meaning when learning,then the learning process is mechanical learning.When the content to be learned interacts with the existing concepts in the learner’s own cognitive structure,it will lead to the assimilation of the meaning of the new and old knowledge,thereby forming meaningful learning. The more meaningful learning there is, the higher the learning efficiency of learners is. For example, when a student is learning to multiply 3×5,if the teacher can split the multiplication into addition, that is to say, convert 3×5 into 3+3+3+3+3, this will connect the new knowledge of multiplication with the old knowledge of addition mastered by the learner, so that the learner can understand and master multiplication more quickly.
This paper attempts to introduce this MRL theory into the training of DRL agents, and carries out the following explorations:
(1) Relevant experience screening.
Artificially associate the current state of UAV (that is, the new knowledge regarding how to act at this state to be learned)with the old knowledge in the experience pool. The EPSDDPG algorithm that we introduced before classifies and stores experience according to the degree of danger of the UAV, but this classification standard has certain limitations.In a real battlefield environment, in addition to the degree of danger of the UAV’s current state, there are many important indicators such as location and direction to describe the current state. Here we design an experience relevance function fr(s ) to evaluate the relevance between the current state and historical experiences:
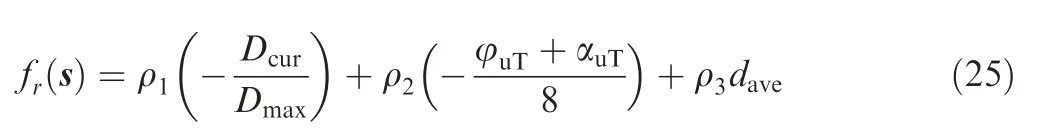
where Dmaxis the theoretical maximum distance between the UAV and the target in the environment and ρ1, ρ2and ρ3are constants. At each time step, calculate the experience relevance of the experience and store it in the experience pool. At each learning time step,filter out the most relevant experiences to the current state for learning.
(2) Break the correlation of experience in the experience pool.
The method of screening experience relevance strengthens the connection between the current state and past experiences,but this will cause the instability of the neural network.Due to the large scale of the environment, the distance that the UAV travels at each time step is very small compared to the scale of the environment. This leads to the fact that the experience stored at time step t is not much different from the experience stored at time step t-1,and even not much different from the experience stored at time step t-2. Therefore, every time we sample from the experience pool, there is a great possibility of sampling some continuous experiences, which will lead to the instability of the neural network.The creation of the experience pool is to break the correlation between experiences.Through random sampling from the experience pool,the probability of continuous experience being learned is reduced,thereby improving the stability of the neural network.20
This paper uses a double-screening mechanism to break the correlation of experience in the experience pool. In the first screening, the PER idea is adopted, and the experience that is most conducive to accelerating network convergence is selected according to TD-error. Then, based on the relevance of these experiences, a second screening is performed, and the experience most similar to the current state will be selected.This method not only breaks the correlation of past experiences in the experience pool but also associates the current state with past experiences and absorbs the advantages of the PER algorithm to a certain extent.
(3) Adjust the order of learning and action selection.
All previous studies on RL or DRL have not given too much consideration to the sequence of learning and action selection at each learning time step, thus ignoring the impact of the sampled experiences on the current state. This paper adjusts the order of learning and action selection, adopting learning first and then selecting the action, so that the experiences selected from the double-screening mechanism can be fully utilized. Take a two-dimensional discrete scenario as an example, which is shown in Fig. 7.
In this scenario, the UAV has three discrete actions (left turn a certain angle a1, forward a2, and right turn a certain angle a3) to choose from at the current time step. Assuming that at the current state s, the neural network will output action a1, which will cause the failure of the mission. At each learning time step, the traditional algorithm (shown as the black arrows in Fig. 7) will first select an action according to the current state and execute the action, so action a1will definitely be selected. After adjusting the order of learning and action selection, our algorithm (shown as the red arrows in Fig.7)will first select the most suitable experiences for learning according to the current state s.After the learning process,the parameters of the neural networks will be changed to a certain extent,and because the learned experiences are the experiences in states similar to s, the neural network with updated parameters will most likely output other actions, or even output a3enables the UAV to safely avoid obstacle ahead.This sequence adjustment can make UAV make better decisions based on past experiences at current state, strengthen the connection between the current state and past experiences, and improve the convergence speed of the algorithm.
3.3.3. REL-DDPG algorithm

The REL-DDPG algorithm uses the tricks of the PER to break the correlation of continuous experiences, and constructs an experience relevance function to select the mostsuitable experiences for learning at different time steps. It also adjusts the order of learning and action selection in the algorithm to enhance the impact of past relevant experience on decision-making at the current state. The use of these mechanisms can improve the convergence speed and convergence results of the algorithm while ensuring stable convergence of the algorithm.

Table 2 REL-DDPG Algorithm.
4. Training and testing environment
To get closer to reality, we design a 3D simulation environment based on the parameters of the Chinese ‘Wing LoongⅡ’UAV.‘Wing Loong Ⅱ’is independently designed and developed by the Chengdu Aircraft Design and Research Institute of the Chinese Aviation Industry (Fig. 8).
The maximum flying height of‘Wing Loong Ⅱ’is 9000 m.It has a maximum flight speed of 370 km/h,a maximum take-off weight of 4.2 t,and an external plug-in capacity of 480 kg,and it can achieve 20 hours of continuous mission life.This type of UAV is equipped with advanced equipment such as synthetic aperture radar, laser-guided missiles, and GPS-guided bombs as standards.All of these ensure that‘Wing Loong Ⅱ’can perform tasks such as intelligence collection, electronic warfare,search, counterterrorism, border patrols and various civilian tasks.
We built a 120×90×10 km3simulation environment in equal proportions based on the parameters of ‘Wing LoongⅡ’ which is shown in Fig. 9.
In the simulation environment, the white hemispheres represent dangerous areas,and their radii range from 5 to 10 km.The green hemisphere represents the target area with a radius of 3 km. The maximum flight speed of the UAV is 103 m/s,and the maximum load factor that the UAV can withstand is 25.For the TAR on the UAV,Nris 32,and the detection distance is 5 km. In addition, the acceleration due to gravity g in the simulation environment is a fixed value of 9.8 m/s2.
For the reward setting, the reward rsfor completing the mission successfully and the reward rffor the failure are 100 and -200, respectively. The contribution rates of different reward influencing factors in Eq. (17) are λ1= 20,λ2= 20, λ3=10, λ4= 40 and λ5= 10.
5. Environmental results and discussion
5.1. Parameter settings
In this section, we conduct experiments and tests on five algorithms, including the traditional DDPG algorithm, the PERDDPG algorithm with PER, the RC-DDPG algorithm based on the classification of the reward,and the two algorithms proposed in this paper. The parameters of each algorithm are set as follows:
(1) The DDPG algorithm.
The input layer of the actor network has 38 nodes and the output layer has 3 nodes,while the input layer of the critic network has 41 nodes and the output layer has 1 node. Both the actor and critic network contain two hidden layers with 100 nodes each. The Adam optimizer is employed to update the network parameters in both the actor network and critic network. The learning rates of the actor network and critic network are 0.0001 and 0.001, respectively. The soft update rates τ of the actor network and critic network are 0.1 and 0.2, respectively. The discount factor γ is 0.9. The capacity of the experience pool is 50000, and the size of the minibatch is 256. During each training session, 200 episodes are first randomly explored to ensure that there are enough experiences in the experience pool for learning. The replay period K is 20, which means that leaning takes place every 20 time steps.
(2) The PER-DDPG algorithm:
The exponents α and β are 0.6 and 0.4, respectively. The rest of the parameters are consistent with the parameter settings in the DDPG algorithm.
(3) The RC-DDPG algorithm:

Fig. 9 Simulation environment.
The reward for experience classification storage is 15. The capacity of the two experience pools storing experiences with different rewards is 25000.R1is used to store experiences with a reward greater than or equal to 15,and R2stores experiences with a reward less than 15.In each sampling,samples are taken from R1and R2at a ratio of 3:1 to form a minibatch.The setting of this ratio refers to Ref.36 The rest of the parameters are consistent with the parameter settings in the DDPG algorithm.
(4) The EPS-DDPG algorithm:
As described in Section 3.2, dave∈[-1,0] can be used to indicate the degree of danger of the current state of the UAV. Therefore, we counted 1,094,199 experiences generated in the first 2000 episodes of the traditional DDPG algorithm training process, and divided these experiences into 3 categories and 5 categories according to the different values of dave. Here we name the algorithms using these two classification methods EPS3-DDPG and EPS5-DDPG, and the experience distributions of these two methods are shown in Fig. 10.
According to the proportion of different daveexperiences in all experiences, the capacity of the split experience pools in EPS3-DDPG and EPS5-DDPG are set to [23995, 20268,5737] and [23995, 14796, 5471, 3400, 2337], respectively. The capacity of the merged experience pool is still 50,000. Emis set to 2000 to merge the experiences after 2000 episodes. The rest of the parameters are consistent with the parameter settings in the DDPG algorithm.
(5) The REL-DDPG algorithm:
The TD-error sample size Ntdis set to 500.The exponents α and β in the first screening are 0.6 and 0.4,which are the same as in the PER-DDPG.The ρ1,ρ2and ρ3in Eq.(25)are 40,40 and 20, respectively. The rest of the parameters are consistent with the parameter settings in the DDPG algorithm.
5.2. Training in a standard environment
The performances of all algorithms above are tested in a static environment. The operating system is Ubuntu 16.04, and the GPU is a GeForce RTX 2070. The number of episodes in a training session is 5000, and the maximum time step for each episode is 3000. Under these conditions, it takes 7-11 hours to perform a training session with 5000 episodes. Each algorithm is trained 10 times under different random seeds to obtain the average value to avoid the influence of random numbers.The average hit rate(the probability of the UAV successfully hitting the target in the last 500 episodes)and episode average reward (the average reward received by the UAV for all time steps in one episode) are used to evaluate the performance of the algorithm, which are shown in Figs. 11 and 12.
To compare the pros and cons of the algorithms in detail,the following indicators are defined:
• Convergence Time (CT):The number of episodes where the hit rate reaches 80%.
• Algorithm Stability (AS): The standard deviation of the hit rate in the last 2000 episodes.
• Algorithm Peak (AP): Highest hit rate in 5000 episodes.
• Qualified Episodes (QE): The number of episodes in which the hit rate is above 80% in 5000 episodes.
• Convergence Result of Average Reward(CRAR):Average of the average reward in the last 2000 episodes.
• Convergence Result of Hit Rate(CRHR):Average hit rate in the last 2000 episodes.
These indicators of all algorithms are calculated and shown in Table 3.
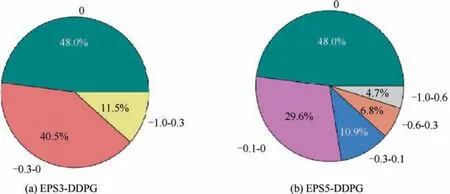
Fig. 10 Experiences distribution of different dave.
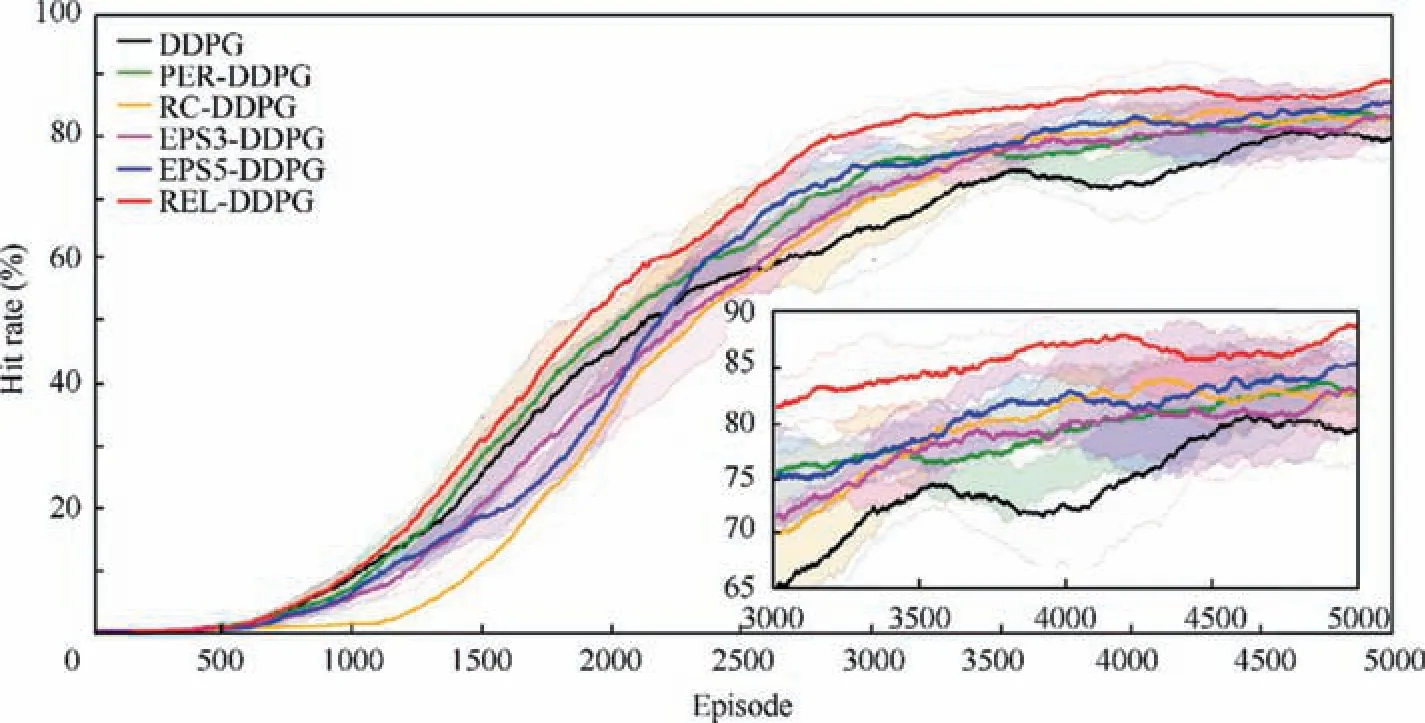
Fig. 11 The hit rates of all algorithms.
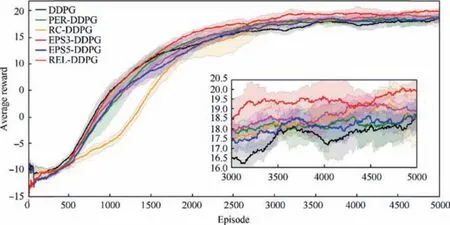
Fig. 12 The episode average rewards of all algorithms.

Table 3 The overall results of the algorithms.
From the convergence process(Figs.11 and 12),we can see that,in the early stage of training,the speed of convergence of the RC-DDPG is the slowest. This is because the RC-DDPG algorithm classifies experiences according to rewards. In the early stage of training, most of the experiences are generated by the UAV’s random exploration (with lower rewards). This leads to less experiences in R1and more experiences in R2.The RC-DDPG algorithm samples from the two experience pools at a ratio of 3:1 each time it samples,which results in the experiences in R1being reused many times while the experiences in R2are not fully utilized. Similarly, the convergence speed of the EPS-DDPG algorithms is slow at first. This is also caused by the UAV not having a good policy at the beginning of training. At each learning time step, the UAV selects the experiences with a similar degree of danger according to the degree of danger of the current state for learning. Because there is no good policy, the current state is often dangerous. This means that a large number of dangerous experiences are learned. The UAV can only learn how to avoid collision with obstacles but cannot learn how to arrive at the target area.Both of these types of algorithms have a greater convergence speed in the middle of the training, such that the hit rates quickly exceed those of the DDPG and PER-DDPG algorithms. However, the convergence speed of REL-DDPG with the double-screening mechanism is the highest almost from beginning to end. This convergence speed is very meaningful.In the actual UAV training, the loss caused by mission failure causes the UAV to only withstand a certain number of training episodes,it is difficult for a UAV to learn an optimal policy in the physical world.46After the same number of training episodes, the mission success rate of UAVs trained by RELDDPG will always be higher than that of UAVs trained by other algorithms.
The experimental results in Table 3 show the following:
(1) For the speed of convergence, EPS3-DDPG and EPS5-DDPG need 4007 and 3601 episodes, respectively, to achieve an 80% hit rate. Compared with the traditional DDPG algorithm, the convergence speed of EPS3-DDPG and EPS5-DDPG has increased by 12.18%and 21.08%, respectively. However, compared with one of the current optimal algorithms, the RC-DDPG algorithm, the advantage of the EPS-DDPG in convergence speed is minimal. The REL-DDPG algorithm only needs 2897 episodes to converge, which is an increase of 36.51% and 21.58% compared to the DDPG algorithm and the RC-DDPG algorithm,respectively.
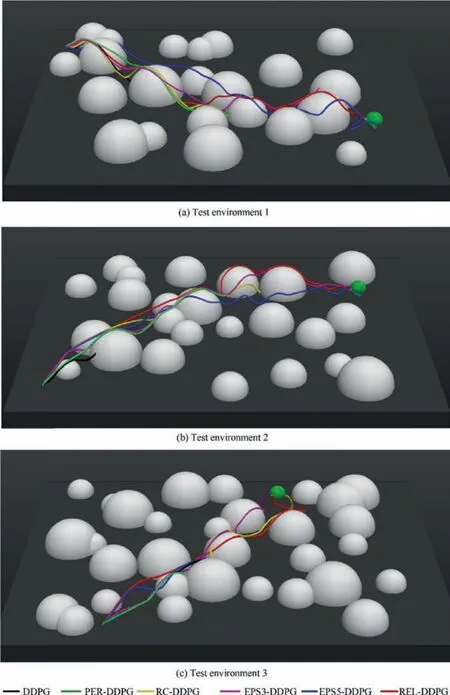
Fig. 13 Flight paths of the UAVs trained by different algorithms in different test environments.
(2) For the convergence results, the hit rates of EPS3-DDPG and EPS5-DDPG are 78.84% and 80.93%,which are improved by 5.91% and 8.72%, respectively,compared with the traditional DDPG algorithm. The convergence result of the REL-DDPG algorithm is the highest (85.65%) among all algorithms. Compared with the DDPG algorithm, the convergence result of RELDDPG is improved by 15.06%. In addition, compared with the two advanced sampling-improved algorithms PER-DDPG and RC-DDPG, the hit rate of the RELDDPG algorithm is improved by 7.91% and 7.22%,respectively.
(3) The indicator AS is used to evaluate the stability of the algorithm after convergence. The smaller AS is,the better the stability of the algorithm is. Table 3 shows that,among the six algorithms, REL-DDPG has the best algorithm stability (1.73), followed by PER-DDPG(2.55). The DDPG algorithm and the RC-DDPG algorithm have the largest AS, reaching 4.21 and 3.91,respectively.

Fig. 14 Flight paths of the UAVs trained by different algorithms in a complex dynamic environment.
5.3. Testing in different situations
5.3.1. Testing in complex static environments
To verify the applicability of the proposed algorithms, this paper tests 6 algorithms in 3 different complex static environments. In these environments, the complexity of the environment is determined by the number of obstacles and the initial positions of the UAV and the target,and the flight paths of the UAVs trained by the six algorithms in these environments are shown in Fig. 13.
In test environment 1(Fig.13(a)),the initial positions of the UAV and target are(-580,340,10)and(470,-150,0)respectively, and the number of obstacles is 22. By observing the flight paths, we can see that only the UAVs trained by the REL-DDPG algorithm and EPS5-DDPG algorithm can successfully avoid obstacles to reach the target position. In test environment 2 with 25 obstacles(Fig.13(b)),the UAVs trainedby EPS3-DDPG,EPS5-DDPG and REL-DDPG can complete the mission flying from(-555,-373,10)to(470,250,0).From Fig. 13(c), the UAVs trained by 3 algorithms (RC-DDPG,EPS3-DDPG and REL-DDPG) can flying from (-355,-413,10)to the target area(170,400,0)while avoiding obstacles in the test environment 3, which has 31 obstacles.

Table 4 The results of the REL-DDPG algorithm with different Ntd.
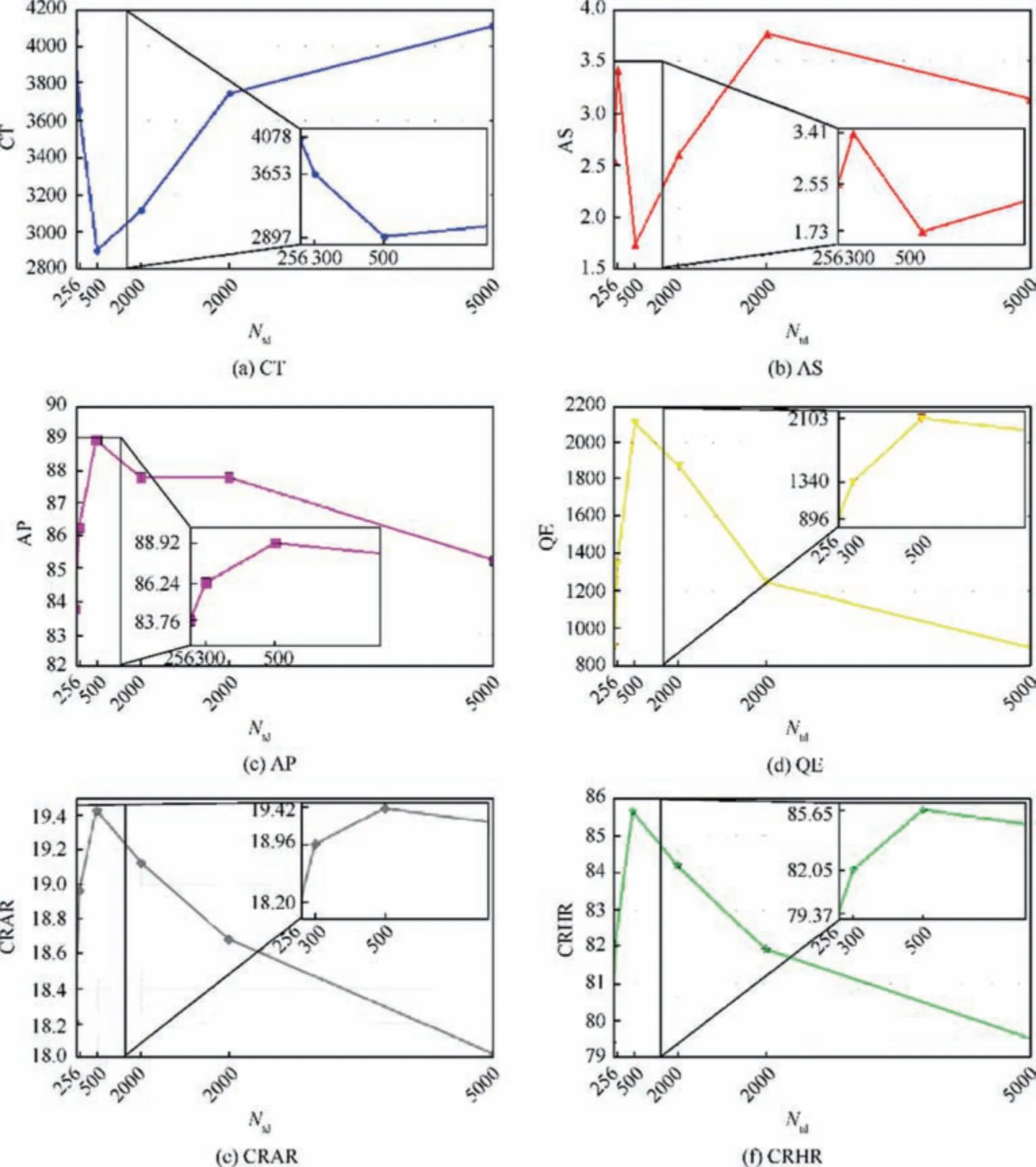
Fig. 15 The indicators of the REL-DDPG algorithm with different Ntd.
In general,the UAV trained by the REL-DDPG algorithm can successfully perform tasks in a variety of complex environments. The UAV trained by EPS-DDPG performed well in some test environments, while UAVs trained by other algorithms performed poorly in complex environments.
5.3.2. Testing in complex dynamic environments
In a real battlefield environment,the enemy radar surveillance area may not be fixed. In addition, the target that the UAV will attack may also be a moving target, such as ground troops. Therefore, this paper designs a dynamic environment closer to the actual situation to test the performance of UAVs trained by various algorithms.
In a test environment with 23 obstacles, obstacles and targets move at a fixed speed. The initial positions of the UAV and the target are (-570, -200, 10) and (420, 300, 0), respectively.The test results of the UAVs trained by 6 algorithms are shown in Fig.14.At time step t=350,the UAV trained by the traditional DDPG algorithm was the first to fail (Fig. 14(a)).Subsequently, at time steps t=679 (Fig. 14(b)) and t=941(Fig. 14(c)), the UAV trained by the PER-DDPG and RCDDPG algorithms contacted the obstacle,causing the mission to fail. However, the UAVs trained by the EPS-DDPG and REL-DDPG algorithms proposed in this paper flew a long distance, but the UAVs trained by the EPS3-DDPG and EPS5-DDPG collided at t=1158 (Fig. 14(d)) and t=1263(Fig. 14(e)), respectively. Among all six algorithms, only the UAV trained by the REL-DDPG algorithm using 1629 time steps successfully completed the AMP in the complex dynamic environment, and the flying path is shown in Fig. 14(f).
5.3.3. Sensitivity of the REL-DDPG
Through the above test experiments, it can be seen that compared to UAVs trained by other algorithms, the UAV trained by the REL-DDPG algorithm proposed in this paper has achieved better performance in a variety of complex environments.Here we explore the influence of the parameter settings in the REL-DDPG algorithm on the performance of the algorithm. As described in Section 3, the REL-DDPG algorithm uses a double-screening mechanism: In the first round, Ntdexperiences are selected based on TD-error, and in the second round, N experiences are selected from the Ntdexperiences based on the relevance of experience to form the minibatch.Therefore,the values of Ntdand N determine the degree of relevance between the experiences in the minibatch used for learning and the current state, that is, the greater Ntd/N is,the greater the degree of relevance is.
In this paper,N is fixed at 256,and experiments are carried out with different Ntdvalues.Each set of experiments was combined 10 times with different random seeds. The experimental results are shown in Table 4 and Fig. 15:
From the experimental results, the relevance between the experiences in the minibatch and the current state has a huge impact on the effect of the algorithm. A relevance that is too low or too high will reduce the effect of the REL-DDPG algorithm. A relevance that is too low will cause the algorithm to not make full use of the experience in the experience pool, and a relevance that is too high will cause continuous experience to be sampled and make the neural network unstable. In the simulation environment of this paper, the REL-DDPG with Ntd=500 has the best effect among all of the experiments, with the fastest convergence rate, the highest convergence result, and the best stability after convergence.
6. Conclusions and future work
Aiming to address the AMP problem of UAVs,this paper classifies experiences according to the current state of UAVs and proposes an EPS-DDPG algorithm that divides and merges the experience pool at different training stages.The experimental results show that the EPS-DDPG algorithm greatly improves the convergence speed and convergence results compared with the traditional DDPG algorithm. Then, on the basis of EPS-DDPG, this paper uses the PER tricks to break the correlation of continuous experiences in the experience pool, finds the old experiences that are most suitable for the current state of learning according to the experience relevance function, adjusts the order of learning and action selection in the RL algorithm, expands the influence of the learning process on action selection at the current state, and proposes the REL-DDPG algorithm. The experimental results prove that compared with the traditional DDPG and the two most advanced sampling methods, the REL-DDPG algorithm with double-screening greatly improves the convergence rate, convergence result, and stability after convergence. Subsequent tests in different complex environments in this paper show the applicability of the algorithm. We also change the parameters of the REL-DDPG algorithm to explore the sensitivity of the algorithm to the parameters and find the most suitable parameters for the current environment. Experimental results show that the two proposed algorithms effectively improve the efficiency and results of UAV motion planning in unknown complex environments, which provides a theoretical basis for future practical applications.
The work we plan to perform in the future mainly includes the following aspects. (A) Mission diversification: In addition to the ground attack mission scenario used in this paper, we will attempt to add more practical mission scenarios to our simulation platform. (B) Cluster control of UAVs: We plan to conduct some research on the cooperative control of multiple UAVs in complex environments.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
This study was co-supported by the National Natural Science Foundation of China (Nos. 62003267, 61573285), the Aeronautical Science Foundation of China (ASFC) (No.20175553027) and Natural Science Basic Research Plan in Shaanxi Province of China (No. 2020JQ-220).
 CHINESE JOURNAL OF AERONAUTICS2021年12期
CHINESE JOURNAL OF AERONAUTICS2021年12期
- CHINESE JOURNAL OF AERONAUTICS的其它文章
- Entropy based inverse design of aircraft mission success space in system-of-systems confrontation
- Nonlinear resonance characteristics of a dual-rotor system with a local defect on the inner ring of the inter-shaft bearing
- Failure mechanisms of bolted flanges in aero-engine casings subjected to impact loading
- Synchronized perturbation elimination and DOA estimation via signal selection mechanism and parallel deep capsule networks in multipath environment
- Improving seeking precision by utilizing ghost imaging in a semi-active quadrant detection seeker
- A high dynamics algorithm based on steepest ascent method for GNSS receiver