
鬼影卷积自适应视网膜血管分割算法
2021-12-07 07:14梁礼明周珑颂冯新刚
光电工程 2021年10期
梁礼明,周珑颂,陈 鑫,余 洁,冯新刚
鬼影卷积自适应视网膜血管分割算法
梁礼明1,周珑颂1,陈 鑫1,余 洁1,冯新刚2*
1江西理工大学电气工程与自动化学院,江西 赣州 341000;2江西理工大学应用科学学院,江西 赣州 341000
针对视网膜血管分割存在主血管轮廓模糊、微细血管断裂和视盘边界误分割等问题,提出一种鬼影卷积自适应视网膜血管分割算法。算法一是用鬼影卷积替代神经网络中普通卷积,鬼影卷积生成丰富的血管特征图,使目标特征提取充分进行。二是将生成的特征图进行自适应融合并输入至解码层分类,自适应融合能够多尺度捕获图像信息和高质量保存细节。三是在精确定位血管像素与解决图像纹理损失过程中,构建双路径注意力引导结构将网络底层特征图与高层特征图有效结合,提高血管分割准确率。同时引入Cross-Dice Loss函数来抑制正负样本不均问题,减少因血管像素占比少而引起的分割误差,在DRIVE与STARE数据集上进行实验,其准确率分别为96.56%和97.32%,敏感度分别为84.52%和83.12%,特异性分别为98.25%和98.96%,具有较好的分割效果。
视网膜血管;鬼影卷积;自适应融合模块;双路径注意力引导结构

1 引 言
视网膜血管形态结构是反映人体健康的重要指标,其图像的处理与分割对青光眼、心血管疾病和静脉阻塞等多种疾病的早期发现和治疗具有非常重要的意义[1]。然而,现实中视网膜血管分割面临着眼球末端血管呈交织状分布且轮廓模糊等难题。因此,迫切需要能够自动识别和自动分割血管结构的算法,去帮助医疗人员诊断眼底疾病。
目前,视网膜血管分割算法主要分为无监督和有监督学习方法[2],其中无监督学习方法主要关注眼底血管原始信息。She等[3]将Franqi滤波器和方向分数相结合来提取视网膜血管,Hessian矩阵组成的Franqi滤波器可以提高线状物体的平滑性,增强眼底血管与背景对比度。同时引入方向分数去扩展平面维度,使二维血管图像映射到多维平面中以捕获多尺度特征信息,改善微细血管末端交叉相连问题,但该算法并没有很好解决视盘对于血管分割的影响。有监督学习需要先验标记信息,利用人工Label图像对分类器进行特征训练。Liang等[4]集成可变形卷积到传统U型网络中构成ASU-Net,该算法根据血管形状和尺度自适应地调整感受野,以捕捉结构复杂的视网膜血管,并通过低级特征图与高级特征图相聚合的方式,来实现微血管精确定位,但是需要引入大量卷积算子去学习可变形偏移量,使得训练和测试时间大幅度增加;Wang等[5]提出HA-Net视网膜血管分割网络,该网络包含一层编码器和三层解码器,首先利用主解码器生成粗略血管分割图并自动确定图像中硬区域和软区域,然后将软硬区域分别输进对应的辅助解码器中进行重新分割,算法存在过度分割现象,致使血管轮廓整体过粗和错误生成假血管分支。
虽然上述算法在分割领域有较好研究成果,但分割视网膜血管时仍存在缺陷,文献[3]利用方向分数扩展维度,将二维图像结构映射到不同平面,会使眼底视盘区域、硬性渗出物和正常血管融合,进而影响微细血管分割。文献[4]引入可变形卷积复杂化网络结构,带来大量参数和提高训练时长,不利于算法实际应用。文献[5]多层解码器并联会使网络出现过拟合情况,生成假血管分支。针对上述存在问题,本文提出一种鬼影卷积自适应视网膜分割算法,先对彩色眼底图片进行RGB(Red、Green、Blue)三通道分离和限制对比度直方图均衡化(CLAHE)处理,增强视网膜微细血管与视盘区域对比度,降低光照强度和颜色通道对分割效果的影响。然后将眼底图片输入鬼影卷积自适应网络中进行训练以提取血管特征,U型网络编码器和解码器中普通卷积替换成鬼影卷积,鬼影卷积利用较小计算量生成丰富甚至冗余的特征图,可以有效减少网络参数和训练时长,快速提取出视网膜血管信息。为增加卷积层感受野,多尺度提取目标特征,将自适应融合模块置于神经网络底端。同时利用双路径注意力引导结构级联编码部分和解码部分,解决池化层信息损失和实现语义全局传递,能够更好地保留血管像素,分割出边缘细节更加完整的图片。
2 网络结构
2.1 鬼影模块
神经网络通过卷积层扩展输入特征图数量,产生丰富甚至冗余的信息以保证视网膜血管特征充分提取,但冗余特征也带来大量浮点运算(floating point operations,FLOP)和参数(parameters),导致网络训练时间过长和占用内存过大。眼底图像经过普通卷积输出结果如图1所示,图中存在大量类似结构像彼此幽灵一样,利用这种相似特性本文采用鬼影卷积(ghost convolution)[6]生成冗余特征图,该卷积利用廉价线性运算替代部分卷积操作,可以有效地减少网络参数和优化网络结构。
鬼影卷积层输出个特征图,步骤如下:




鬼影卷积层能够与普通卷积层一样生成视网膜特征图,因此可以轻松地替换普通卷积层嵌入神经网络架构中降低计算成本。普通卷积核大小为,鬼影卷
积核大小为,输出个视网膜特征图浮点运算量之比为


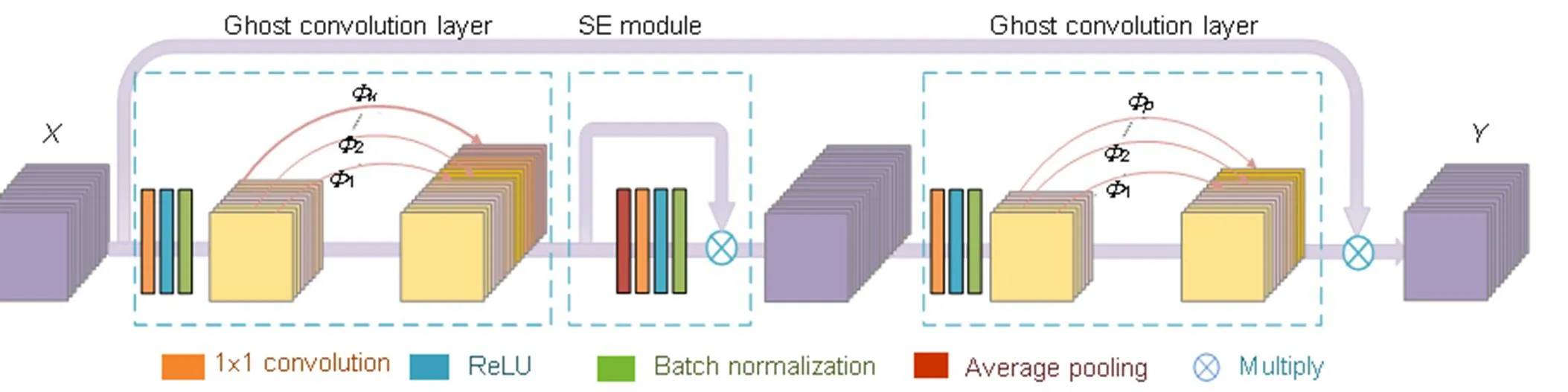
本文利用鬼影卷积层(ghost convolution layer)设计出鬼影模块(ghost module)优化网络结构,模块结构见图3。Ghost module主要由三部分组成:第一部分扩展鬼影卷积层,利用鬼影卷积层增加视网膜特征图数量;第二部分SE注意力模块[7],SE模块可以动态地抑制与血管任务不相关区域特征,提高网络分割精度;第三部分压缩鬼影卷积层,利用鬼影卷积层减少特征图数量以匹配输出所需。

图1 普通卷积层输出结果
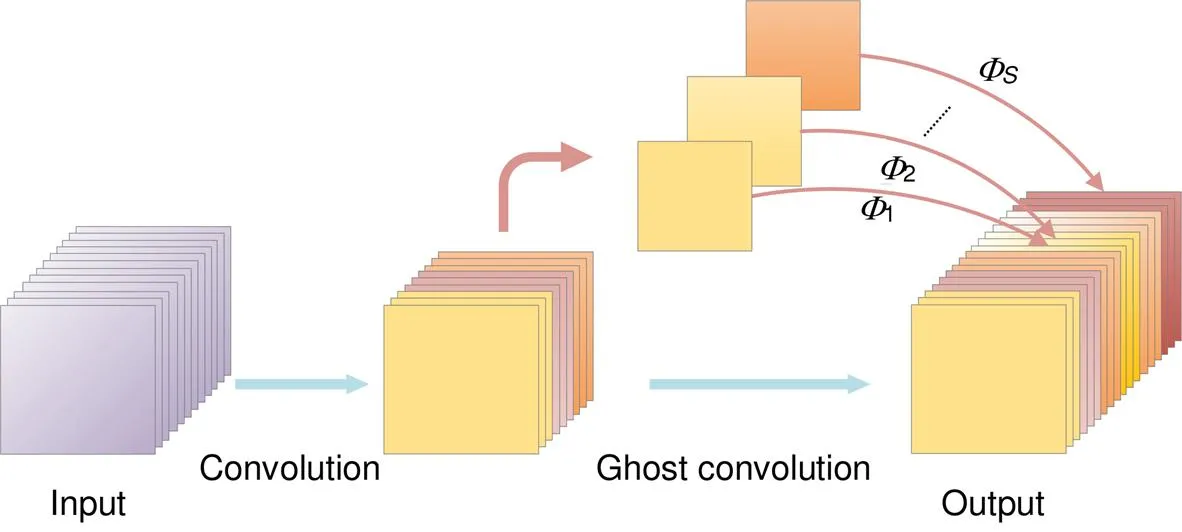
图 2 鬼影卷积层
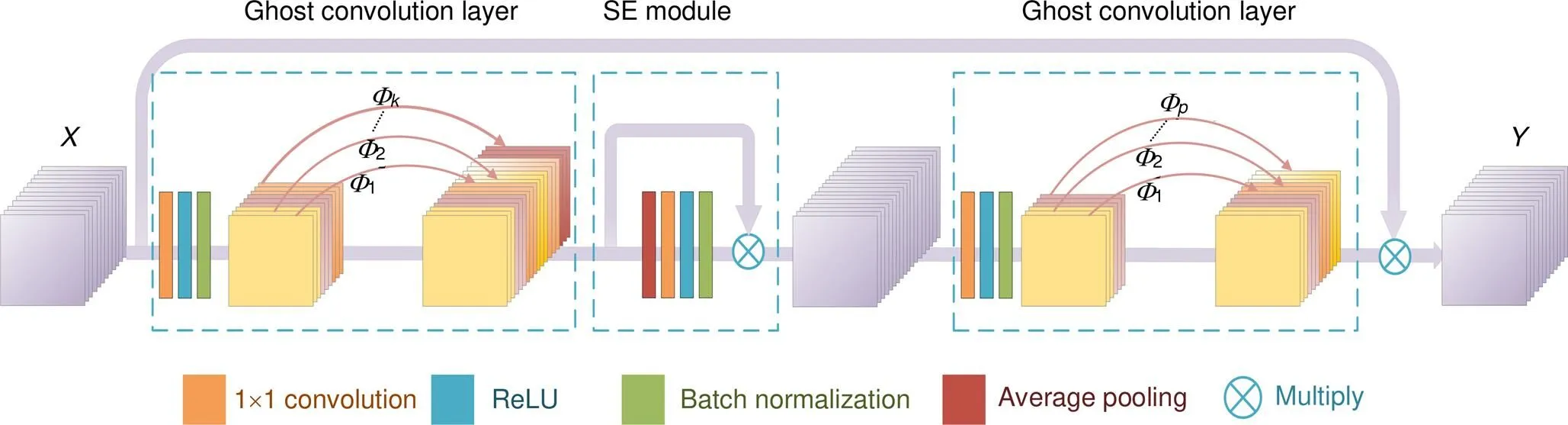
图3 鬼影模块
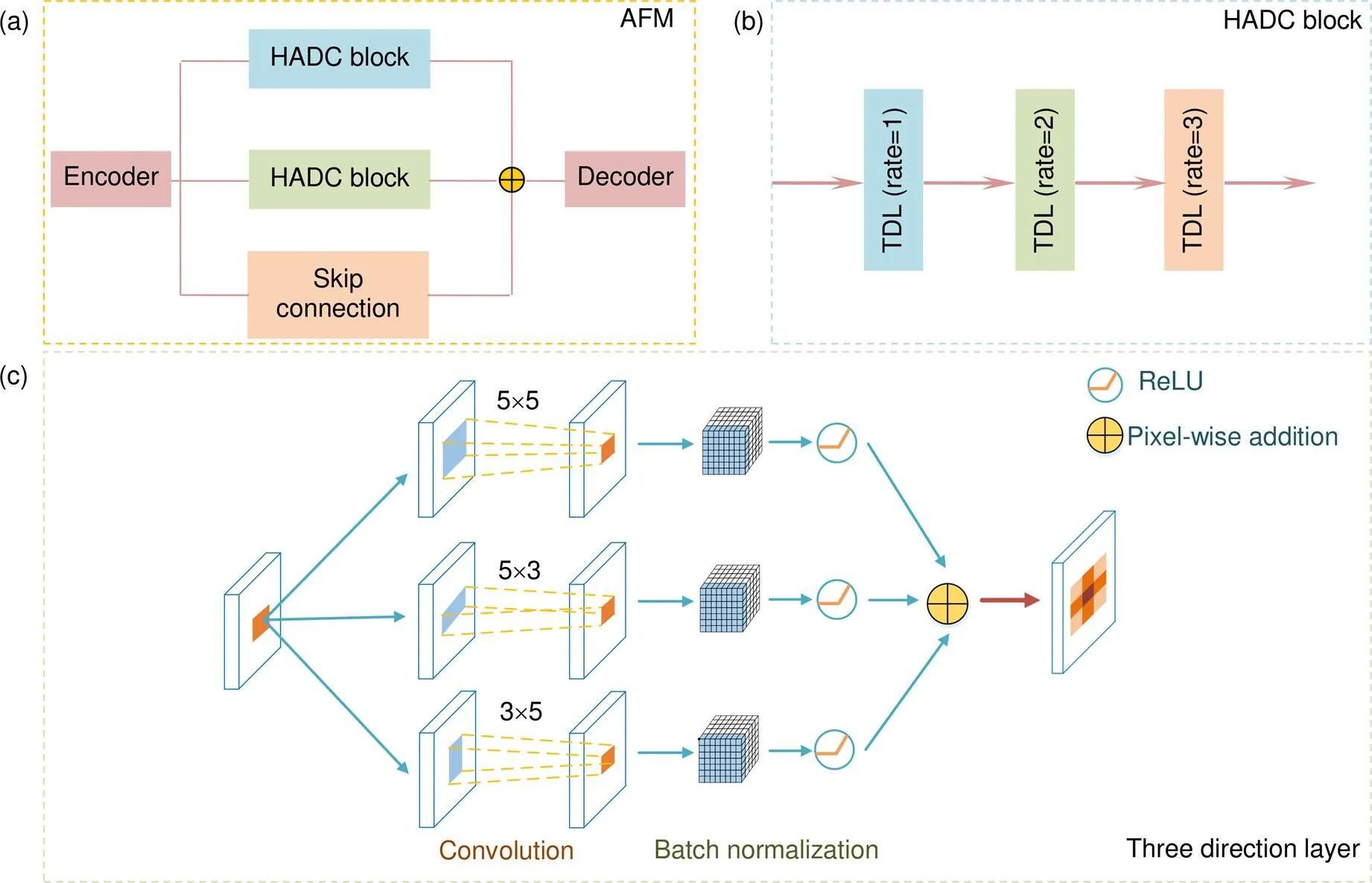
图4 自适应融合模块
2.2 自适应特征融合
融合多尺度特征可以增强模型分割性能,在网络底端引入空洞卷积可以使输入特征图在不连接池化层的情况下扩大感受野,让卷积后输出拥有更多细节信息。本文基于非对称扩张卷积提出自适应融合模块(adaptive fusion module,AFM),该模块由一对混合非对称扩张卷积(HADC)[8]和一个跳跃路径(skip connection)[9]组成。自适应融合主要思想是通过不同感受野分支捕获不同尺度信息,从而达到多维特征提取,整体结构如图4(a)所示。
混合非对称扩张卷积包含三个三向层(three direction layer,TDL),各层空洞卷积率(rate)[10]依次扩大,分别为1、2和3,变化的空洞卷积率组合可以保证在扩大感受野同时减少区域像素丢失,如图4(b)所示。其中三向层中卷积以并行方式工作,在和轴上互补融合血管像素,如图4(c)所示。TDL利用5×5空洞卷积探索全局信息,3×5空洞卷积补充横向层信息,5×3空洞卷积补充纵向层信息,多方向元素交叉融合可以保存高质量细节。支路的跳跃连接由1×1卷积构成,用于防止梯度爆炸和梯度消失(导数出现指数上升和下降)。独特的分支结构使得自适应融合模块能够增加卷积层感受野,从而探索多维区域尺度特征和提取全局语义信息。该模块将编码部分信息进行自适应融合后输入解码部分预测分类,可以保留视网膜血管深层像素。
2.3 注意力机制
U-Net[11]原始上下采样方式容易丢失底层特征,难以高精度预测出视网膜血管轮廓。因此增强眼底血管像素对于提高分割精度十分重要,注意力引导(AG)结构通过跳跃式连接将低级特征图(编码层特征图)与高级特征图(解码层特征图)级联,增强眼底像素传递,改善血管细节模糊现象,结构如图5所示。h是高级特征图,l是低级特征图,低级和高级特征图先用1×1卷积处理并相加,在用1×1卷积提取血管特征,ReLU激活函数防止梯度消失,Sigmoid函数获取注意力系数Î[0,1],注意力系数与高级特征图h相乘确定其权重,与目标任务关系越紧密的图像被保留的特征越多。
单路径注意力引导结构可能会导致空间图像产生噪声,影响模型分割的鲁棒性,因此本文将单路径引导结构改进成双路径引导(dual-pathway attention guided,DAG)结构,结构如图6所示。双路径引导能够产生二个注意力系数,输出1是确定权重的高级特征图h,输出2是确定权重的低级特征图l,二者相加并用1×1卷积、批量归一化(BN)和ReLU激活函数处理得到最终输出,添加双路径引导结构使得图像边缘更加清晰。
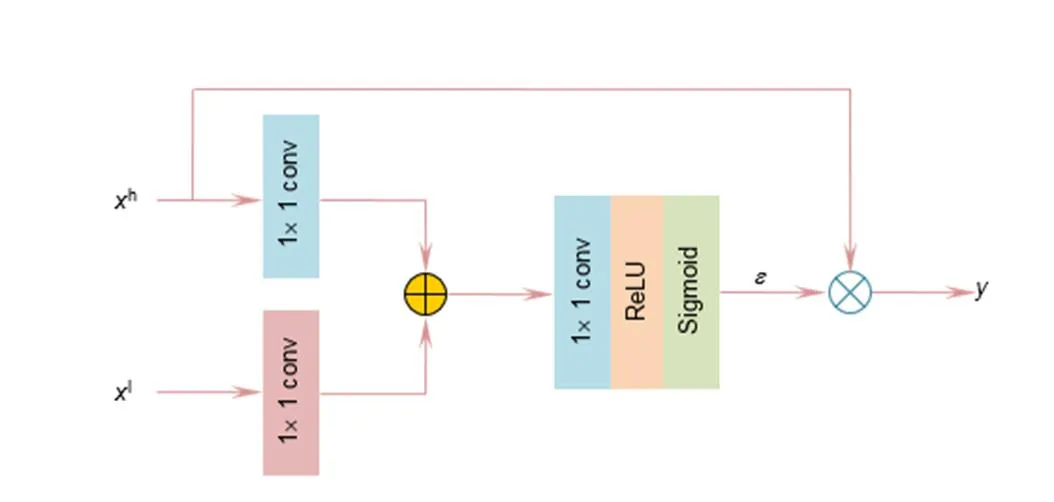
图5 注意力引导结构
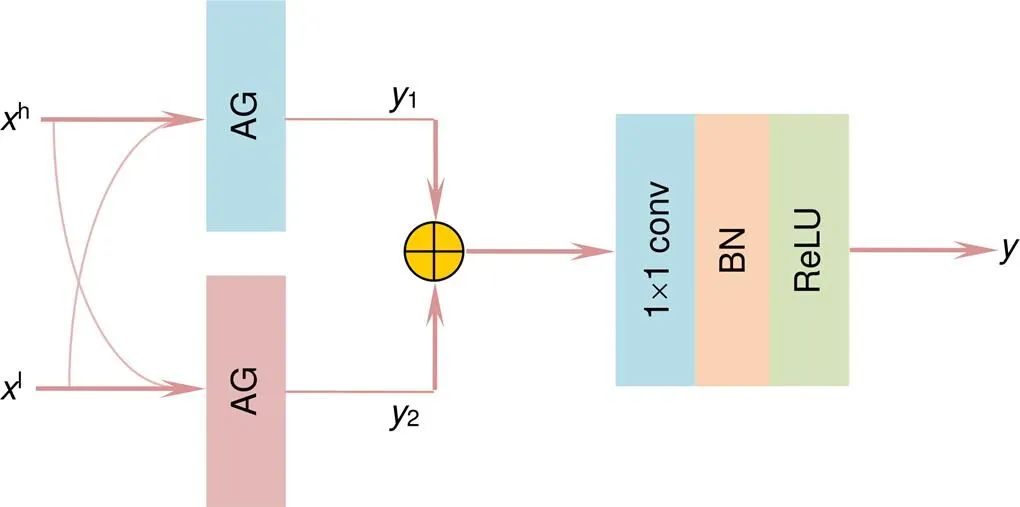
图6 双路径注意力引导结构

图7 鬼影卷积自适应网络
2.4 网络结构
视网膜血管拥有复杂的形态结构和多变的尺度信息,为确保算法可以融合全局信息,分割出更多微细血管数目,本文提出鬼影卷积自适应视网膜血管分割算法,网络整体结构如图7所示。鬼影卷积自适应网络(GANet)主体由图像预处理(image preprocessing)、编码器、解码器和连接部分共同组成。原始眼底图像尺度为565×584×3,预处理先将眼底图片裁剪成64×64×1,再输入到神经网络中进行训练。网络左半部为编码器用于视网膜血管特征提取,由鬼影模块(ghost module)和最大池化层(maxpooling)组成,对眼底图像进行空间维度收缩和通道扩张,将尺度为64×64×1的眼底图像变成4×4×512。网络右半部为解码器用于类别预测,由上采样(upsampling)和鬼影模块组成,将4×4×512尺度图像恢复为64×64×1。连接部分分为自适应融合模块(AFM)和双路径注意力引导结构(DAG),其中自适应融合模块置于网络下层,连接神经网络底端编码器和解码器,交叉融合血管像素,减少特征丢失和保存高质量细节。双路径注意力引导结构置于网络上中层,级联相应解码层和编码层,结合低级特征图和高级特征图,降低池化层对信息的损害,提高血管像素定位精度。网络末端是Sigmoid激活函数,对血管和背景进行分类得到64×64×1的分割结果图,最后拼接(splicing)裁剪结果图得到最终血管分割结果。此外,本文引入新型混合损失(Cross-Dice Loss)函数来抑制正负样本不均问题,减少因血管像素占图片整体像素比例较小而引起的分割误差,从而得到更为优异地分割结果。
2.5 损失函数
视网膜血管分割任务中常用交叉熵损失(Cross -entropy Loss)函数衡量模型预测的好坏,Cross-entropy Loss基于像素平均值预测,面对血管像素占眼底图像整体像素比例较小时,会使预测偏向背景目标。Dice-coefficient Loss可以引入权重来缓解类别间不平衡的影响,关注预测与事实之间重叠,但分割眼底图像边界时效果较差。将Dice-coefficient Loss和Cross-entropy Loss混合成一种新型损失(Cross-Dice Loss)函数用于本文算法评估,可以很好地适应前景与背景像素比例不平衡的分割任务,表现出预测结果与实际结果的区别,新损失函数定义为

3 实验结果与分析
3.1 数据集与图像预处理
本文采用公开数据库中的DRIVE和STARE数据集作为实验数据集,DRIVE数据库中包含40张彩色眼底图片,官方已经将数据集进行手工分割且分为训练集和测试集。STARE数据库中包含20张彩色眼底图片,将数据集平均分成五份,采用五折交叉验证方式进行实验。为获取更好实验结果,需要对原始眼底图像进行预处理再输入到模型中训练,预处理的步骤如下。

图8 预处理图像。(a) 原图;(b) 绿色通道图;(c) CLAHE图;(d) 伽马变换图
1) 图像扩充:DRIVE和STARE数据集中包含图片数量较少,采用沿轴18°旋转采样,将数据集扩充20倍,以增加网络训练样本量。
2) RGB(Red、Green、Blue)三通道处理:将眼底图像分离成RGB三通道特征图,发现绿色通道对比其他通道亮度适中、血管与背景对比度好,故选用绿色通道图片作为预处理后续图片。
3) 限制对比度直方图均衡化(CLAHE)处理:CLAHE处理在增强血管与背景对比度的同时不放大噪声,使处理后的眼底图片更加平滑。均衡化后采用伽马变换对图片较暗部分进行亮度提升,增强图片可视度,预处理如图8所示。
3.2 实验环境和参数设置
实验电脑仿真平台是PyCharm,实验环境是TensorFlow2.0开源框架,电脑配置为Intel©Core™i7-6700H CPU,16 GB内存,Nvidia GeForce GTX 2070 GPU,64位Win10操作系统。
采用Adam算法优化Cross-Dice Loss函数,加快目标函数收敛速度,迭代次数设置为100,网络初始学习率设置为0.0005,训练批量设置为16,训练集中20%样本作为验证集。
3.3 评价指标
本文用准确度(accuracy,简写为Acc,在式中写为cc)、敏感度(sensitivity,简写为Sen,在式中写为en)、特异性(specificity,简写为Spe,在式中写为pe)和受试者工作特征曲线(ROC)下方的面积AUC这四个指标来评估算法性能。其中,敏感度表示检测血管像素数量与真实血管像素数量的比率;特异性表示检测非血管像素的数量与真实非血管像素数量的比率;准确度表示准确分类像素数量与图像中总像素数量的比率。

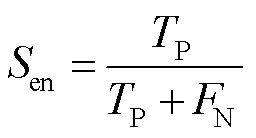

3.4 不同算法主观性对比
为验证鬼影卷积自适应网络(GANet)分割血管的有效性,选取文献[11]中U型网络(U-Net)、文献[12]中密集卷积长短期记忆网络(BCDU-Net)、文献[13]中双层U型网络(DoubleU-Net)和文献[14]中蝶形全卷积神经网络(BFCN)与本文算法(GANet)进行主观性对比。编码器和解码器对称连接,形似英文字母U的网络称为U型网络(U-Net),编码器用于压缩图片进行特征提取,解码器用于恢复图片尺寸进行分类预测。BCDU-Net是在U型网络编码层和解码层中添加密集卷积块,并用记忆神经元级联而成的网络。DoubleU-Net由双层U型网络并联组成,前层采用VGG-19预训练框架,后层类似U-Net结构,并联框架可以多层次提取血管像素。BFCN编码层由多尺度信息提取块构成,同时利用传输层串联网络整体结构,可以多尺度提取血管特征。普通卷积自适应网络(CANet)是将鬼影卷积还原成普通卷积,其余结构与本文算法一致。将上述六种算法置于同一实验环境下进行测试,不同算法对比结果见表1,其中最优指标加粗表示。
表1可以看出,本文网络GANet综合性能比较好,网络参数(parameters)为27400454,低于上述五种算法,仅为CANet的75.62%,证明鬼影卷积具有显著降低网络参数功能。同时单轮训练时长分别为152 s、286 s、294 s、422 s、348 s和244 s。GANet训练时间虽高于U-Net少许,但低于其余四种网络,仅为CANet的70.11%。U-Net未添加任何模块以最简单形式组成,使得训练最短,但本文算法其他指标均高于U-Net,能更好地平衡时间与准确率关系。

表1 不同算法对比结果
在DRIVE数据集上除特异性(Spe)指标外,本文准确度(Acc)、敏感度(Sen)和AUC值均为最高,分别为0.9656、0.8452和0.9869。DoubleU-Net由双层U型网络构成,训练时可能出现过拟合现象,进而生成假血管分支,使特异性值高于本文算法,但本文算法准确度和敏感度更高,血管误分割率更低。在STARE数据集上除AUC值比CANet低0.01%外其余指标均高于上述五种算法,说明本文算法综合性能优于传统算法。图9展示不同算法视网膜血管分割结果,前三幅是DRIVE数据集图片,后三幅是STARE数据集图片,其中9(a)代表数据库中原始彩色图,9(b)代表医学专家手工分割结果称金标准,9(c)~9(h)分别代表U-Net、BCDU-Net、DoubleU-Net、BFCN、CANet和GANet分割结果。在第一幅和第三幅图片中,U-Net、BCDU-Net、DoubleU-Net和BFCN分割眼底视盘区域时不能有效地辨别视盘和血管轮廓,容易将视盘误分割为血管,导致其周围主血管链结,而GANet能够较好地识别视盘与血管,避免假血管生成。第二幅眼底图片左下角存在病变现象,DoubleU-Net、BCDU-Net和CANet抑制病理信息能力较差,病变区域主血管模糊和缺失,而U-Net、BFCN和GANet在分割病变血管时,能够剔除病变斑点,减少血管缺失程度。GANet可以捕获更多微细血管数目,使末端细小血管与主干血管平滑连接,第四幅和第五幅图片可以看出其他分割算法微细血管丢失情况严重,造成评价时灵敏度较低。第六幅图片血管附近有明显的硬性渗出物,渗出物容易引起交叉处血管错误连接,同时掩盖细小血管脉络走势,使目标区域产生伪影,GANet和CANet丰富的特征提取使得硬性交叉处血管也能平滑融合,减小无关斑点生成,而其他算法则有不同程度的伪影,其渗出物的识别证明本文算法及其变形算法的鲁棒性更强。
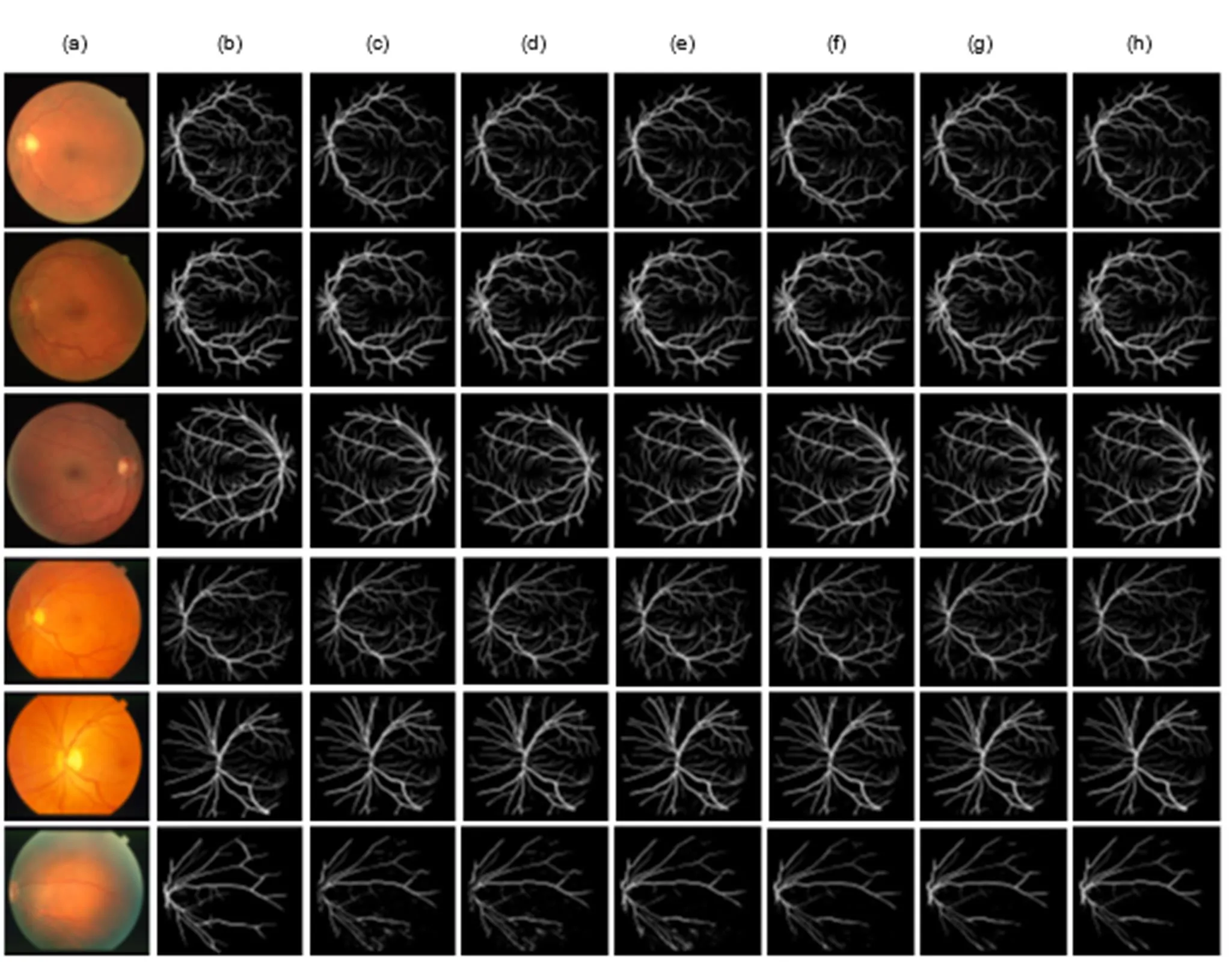
图9 不同算法分割结果。(a) 原图;(b) 金标准;(c) U-Net图;(d) BCDU-Net图;(e) DoubleU-Net图;(f) BFCN图;(g) CANet图;(h) GANet图
进一步清晰展现分割结果,图10和图11给出DRIVE和STARE数据集分割细节,并用颜色强化血管与背景像素,其中10(a)和11(a)代表灰色或彩色原图,10(b)和11(b)代表金标准细节图,10(c)~10(h)和11(c)~11(h)分别代表U-Net、BCDU-Net、DoubleU-Net、BFCN、CANet和GANet分割细节图。图10展示的是图9中第三幅眼底图像,由橙色和红色圆圈可以看出本文算法能够分割出更多微细血管,而其他算法在分割末端血管时效果欠缺。

图10 DRIVE数据集分割细节。(a) 原图;(b) 金标准细节图;(c) U-Net细节图;(d) BCDU-Net细节图;(e) DoubleU-Net细节图;(f) BFCN细节图;(g) CANet细节图;(h) GANet细节图
图11展示的是图9中第六幅眼底图像,由橙色和红色圆圈可以看出本文算法能够识别血管硬性渗出物,避免伪影生成。通过直观细节对比,体现出本文算法能够平滑地拟合主干血管和微细血管,保证视网膜血管分割完整性和准确性,实验对比细节图说明鬼影卷积自适应网络对DRIVE和STARE中的眼底图片具有较好的分割能力。
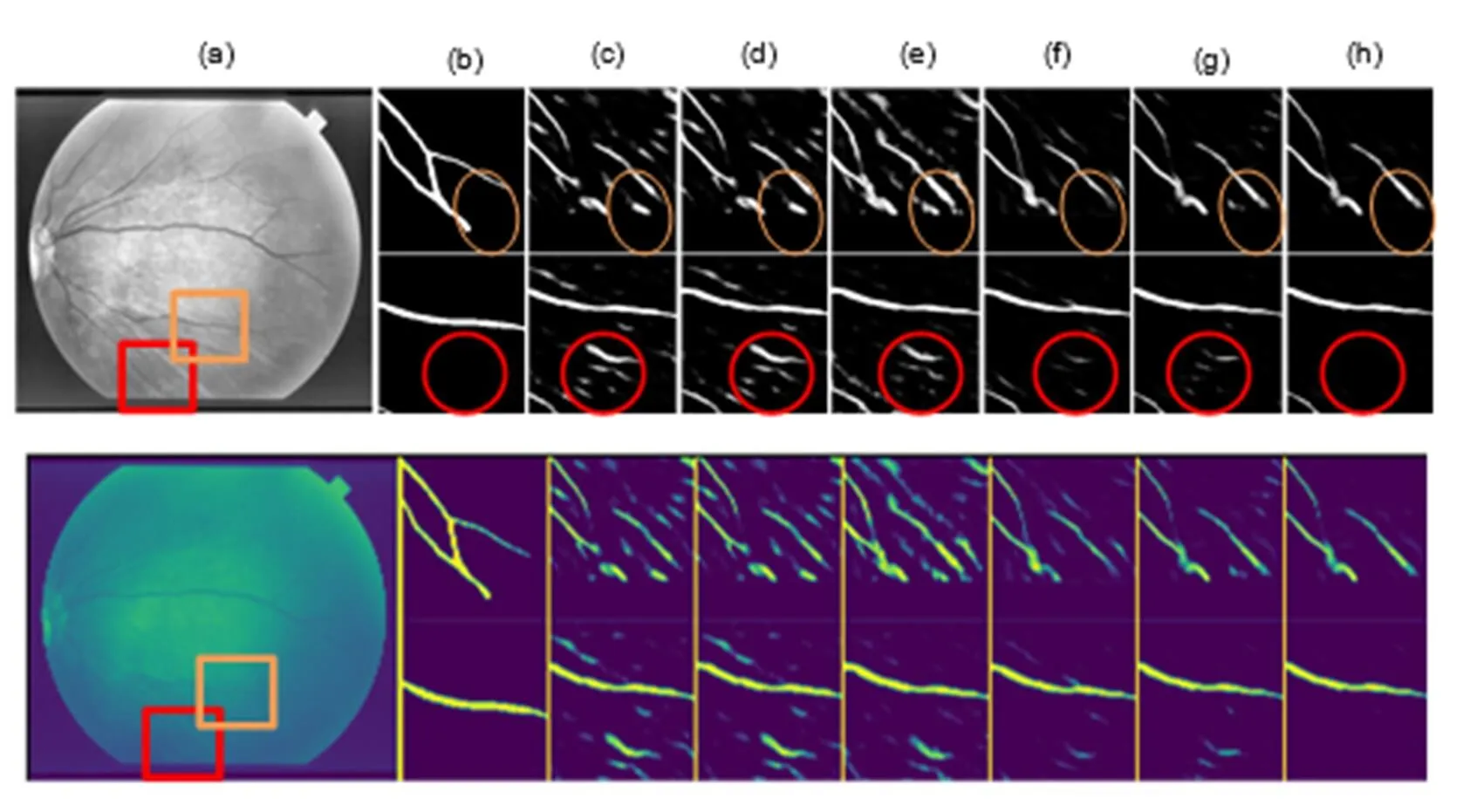
图11 STARE数据集分割细节。(a) 原图;(b) 金标准细节图;(c) U-Net细节图;(d) BCDU-Net细节图;(e) DoubleU-Net细节图;(f) BFCN细节图;(g) CANet细节图;(h) GANet细节图
为更加直观地显现GANet优越性,图12和图13给出DRIVE数据集上的受试者工作特征(ROC)曲线图12(a)和精度召回率(PR)曲线图13(a)走势。ROC曲线以真阳性率(TPR)为纵坐标,假阳性率(FPR)为横坐标,巧妙地以图示方法揭示灵敏度和特异性关系。ROC图中曲线越靠近左上角表明实验准确性越高,假阳性率和假阴性率占比越低,由图12放大图12(b)看出本文算法GANet曲线走势最靠近左上角,分类视网膜图片像素时错误分类为血管像素概率最低。
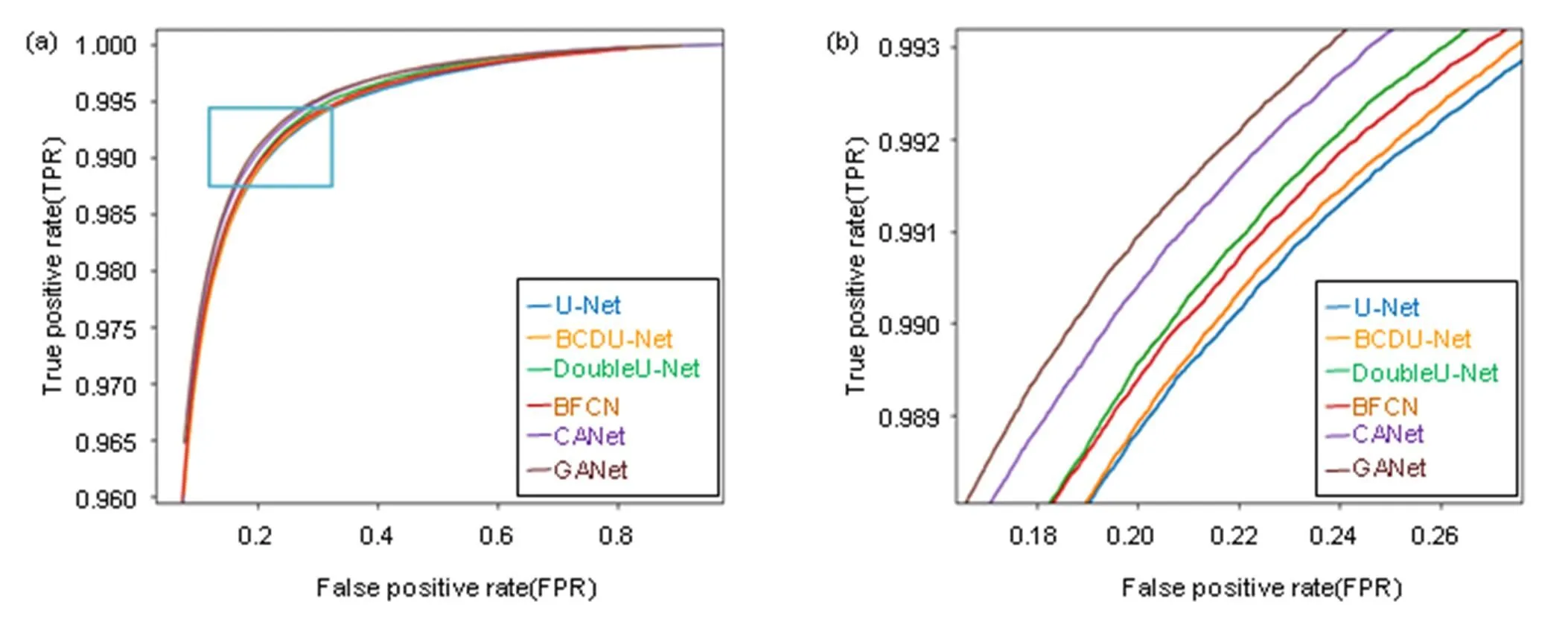
图12 受试者工作特征曲线

图13 精度召回率曲线
PR曲线中P代表精准率(Precision),R代表召回率(Recall),图像蕴含精准率与召回率关系,每条PR曲线对应一个阈值。PR曲线越靠近右上角表明正负样本区分效果越好,由图13放大图13(b)可以看出本文算法GANet曲线走势最靠近右上角,分类视网膜图片像素时错误分类为非血管像素概率最低。
损失函数可以估量模型预测值与真实值不一致程度,图14给出不同算法在STARE数据集上训练损失曲线和测试损失曲线走势图。
3.5 不同算法客观性对比
本文算法与其他文献方法进行客观性对比,不同算法客观性对比结果见表2,其中最优指标加粗表示。本文算法在DRIVE和STARE数据集上评价指标:准确率(Acc)为96.56%和97.32%,敏感度(Sen)为84.52%和83.12%,特异性(Spe)为98.25%和98.96%,AUC值为98.69%和99.00%。通过数据证明本文算法性能对比其他视网膜分割算法具有明显优势,实验对比结果说明鬼影卷积自适应网络(GANet)对DRIVE和STARE库中视网膜图片具有较好地分割能力。文献[16]利用可变形卷积去代替普通卷积,并采用双路径注意力引导结构级联编码器和解码器,可变形卷积包含偏移量学习,可以动态地调整卷积核对目标内容进行自适应采样,但二个数据集四项指标均低于本文算法,其中精度比本文低0.99%和1.12%,敏感度比本文低5.62%和5.14%,特异性比本文低0.26%和0.74%,鬼影卷积提取视网膜血管能力强于可变形卷积。文献[20]基于尺度空间逼近卷积神经网络对视网膜血管进行分割,该网络应用上采样多尺度结构增加交换感受野,提高微薄结构血管分割和边界轮廓定位,同时引入剩余块辅助网络感受野变化,在STARE数据集中其精度和特异性均比本文低0.38%,敏感度和AUC值比本文高0.03%和0.05%,表明自适应融合模块和上采样多尺度结构对血管像素融合各有优劣。文献[22]提出实时模糊形态学视网膜血管分割算法,无监督学习方法利用模糊集理论和模糊逻辑算子去处理不确定和信息缺失的血管,并用黑顶帽操作增强微血管区域像素,提高分割精度,在DRIVE数据集中该算法准确率最高96.67%,比本文高0.11%,但是敏感度、特异性和AUC值均低于本文,敏感度低2.31%,特异性低0.08%,AUC值低0.16%,说明有监督学习方法在分割血管轮廓时效果优于无监督学习方法。文献[23]和文献[24]采用交叉熵损失函数评估算法模型,在面对类别间不平衡时,很难权衡敏感度和特异性。相比DRIVE数据集STARE数据集中眼底图像尺寸更大,血管像素占图片整体像素比例更小。文献[23]利用金字塔思想,将图像放大不同尺度再输入网络中训练,使特异性最高99.03%,但敏感度为75.51%。文献[24]采用迁移学习预训练模型,并将学习的多级别多尺度特征融合以消除错误分割,使敏感度最高89.79%,但特异性为97.01%。本文采用Cross-Dice Loss函数评估算法整体性能,可以很好地适应前景与背景像素比例不平衡的分割任务,权衡敏感度和特异性之间关系,算法敏感度和特异性分别为83.12%和98.96%,综合分析不同算法,得出鬼影卷积自适应网络性能优异。
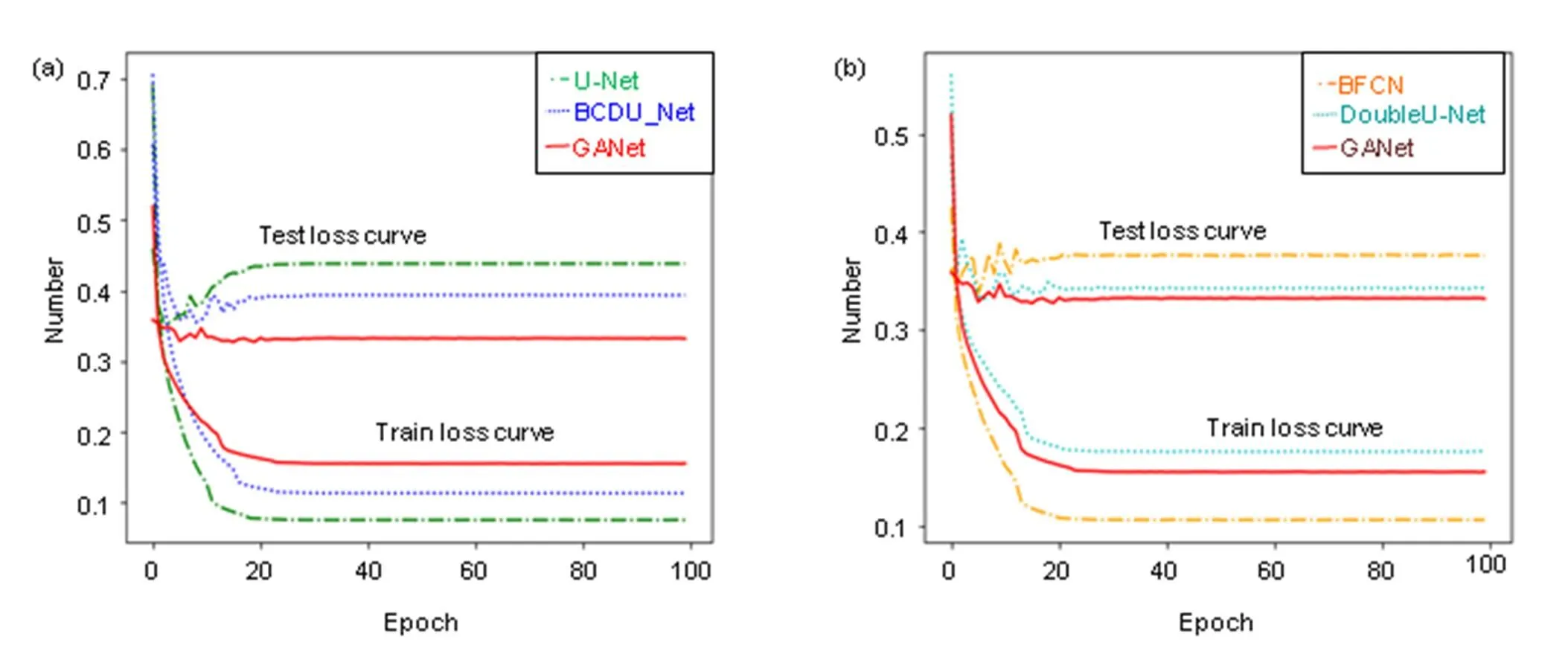
图14 损失曲线
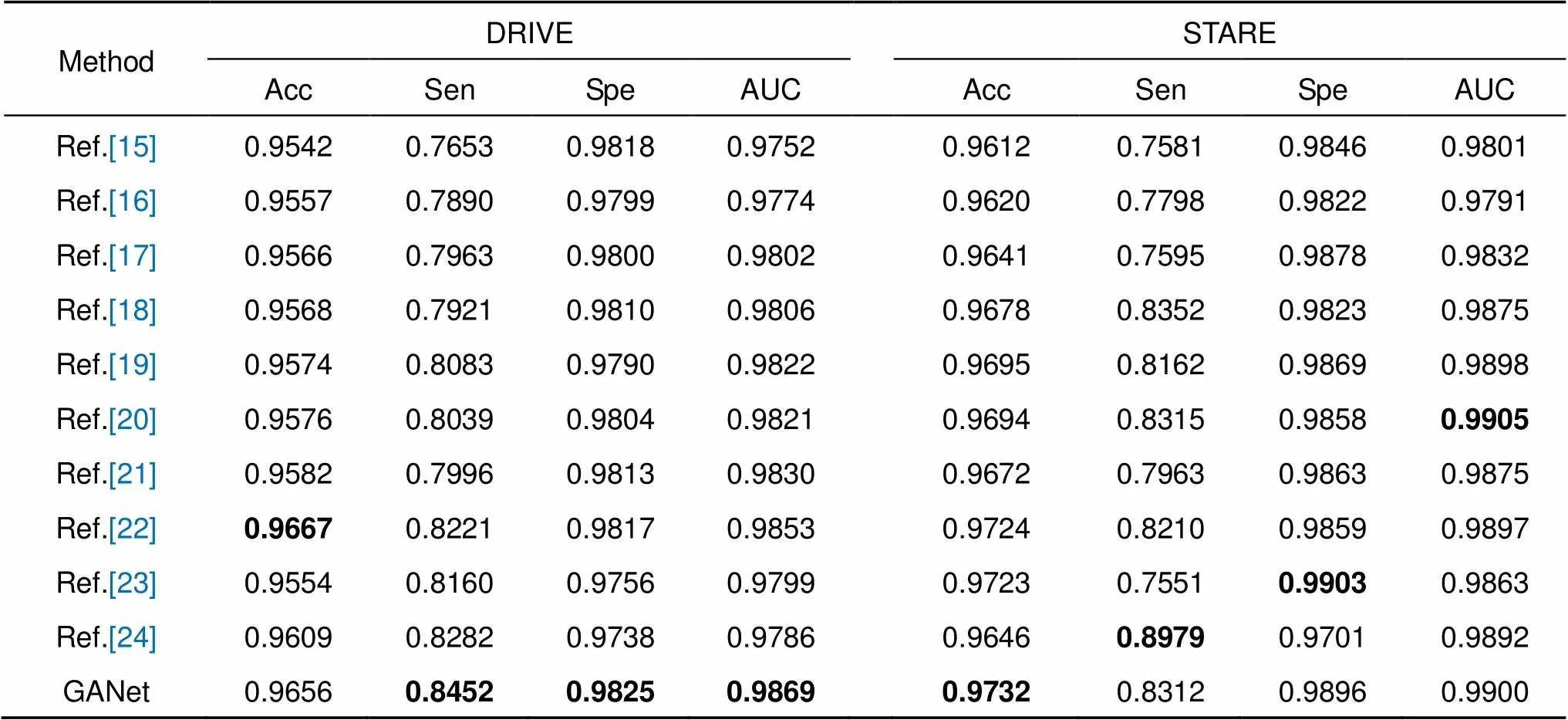
表2 不同算法客观性对比结果
3.6 消融研究
鬼影卷积自适应网络(GANet)生成丰富的视网膜特征图,并自适应融合血管特征,更好地保留血管像素,从而分割出边缘细节更加完整的眼底图片。为验证鬼影卷积自适应网络(GANet)各模块有效性,本文在DRIVE和STARE数据集上进行消融研究。GANet_1以普通卷积层为基础加入自适应融合模块(AFM)和双路径引导结构(DAG),GANet_2将普通卷积层替换成鬼影卷积模块,并加入双路径引导结构(DAG),GANet_3将普通卷积层替换成鬼影卷积模块,并加入自适应融合模块(AFM),表3显示消融实验结果。
消融实验显示本文算法各模块具体作用,其中GANet_1和GANet区别在于是否加入鬼影卷积模块,鬼影卷积模块对比普通卷积层可以产生更丰富的特征图,充分提取眼底信息,分割出更多微细血管,GANet_1和GANet准确度分别为96.45%和96.56%,敏感度分别为83.74%和84.52%,明显提高算法准确度和敏感度。GANet_2在鬼影卷积模块基础上引入双路径引导结构,级联编码器和解码器,解决池化层信息损失和实现语义全局传递,更好地保留血管像素,分割出边缘细节更加完整的图片,使敏感度达到最优85.06%和83.36%。GANet_3在鬼影卷积模块基础上引入自适应融合模块,增加卷积层感受野,多尺度提取目标特征,使特异性达到最优98.51%和99.29%。本文算法在鬼影卷积基础上加入了自适应融合模块和双路径引导结构,在提高算法准确度的同时权衡敏感度和特异性。
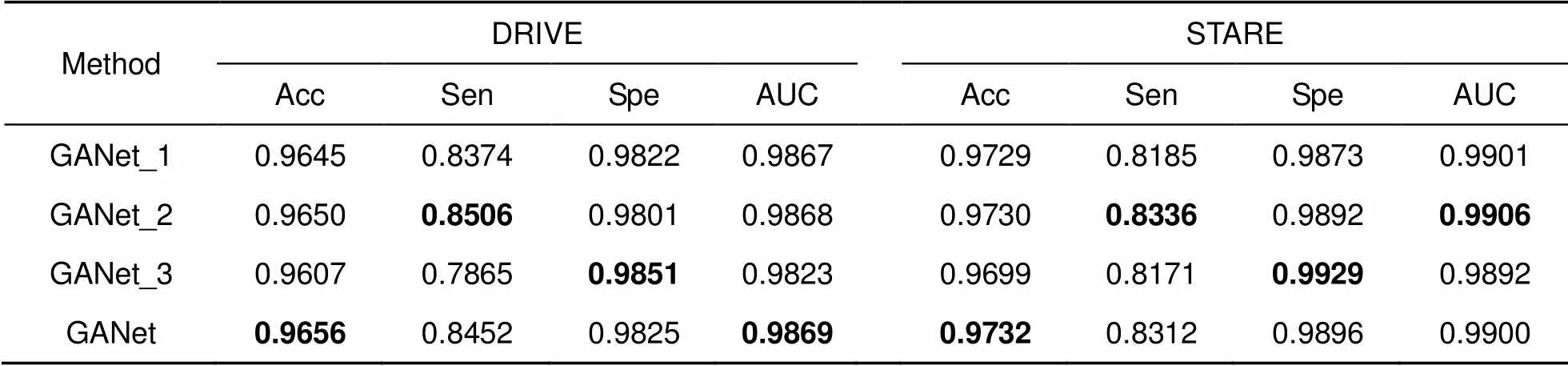
表3 各模块消融研究
4 结 论
本文针对视网膜血管难以高精度分割,提出鬼影卷积自适应视网膜血管分割算法。算法先对数据库中图片进行预处理,增强眼底图像可识别度。训练网络编码和解码器中普通卷积被替换为鬼影卷积,利用鬼影卷积快速生成丰富特征图的优势,充分提取血管特征。编码层捕获信息经过自适应融合模块后输入解码层中分类,自适应模块利用非对称卷积核交叉融合血管像素,高质量保存视网膜血管细节。为弱化池化层噪声干扰,采用双路径注意力引导结构级联低级特征图与高级特征图,让视网膜特征能够全局传递。此外,本文引入新型混合损失(Cross-Dice Loss)函数来抑制正负样本不均问题,减少因前景占比少而引起的分割误差,得到优异分割结果。实验结果表明,本文算法综合性能优于现有算法,其分割精度数值较高,对于眼科疾病诊断拥有一定应用价值。虽然鬼影卷积能够生成丰富的特征图,但不能很好地确定每张图片信息度,无法辨别出高质量特征图。未来将研究如何巧妙地融合可变形学习量,通过网络学习自动增加高维信息特征图权重,提高视网膜血管分割精度。
[1] Xu G Z, Wang Y W, Hu S,. Retinal vascular segmentation combined with PCNN and morphological matching enhancement[J]., 2019, 46(4): 180466.
徐光柱, 王亚文, 胡松, 等. PCNN与形态匹配增强相结合的视网膜血管分割[J]. 光电工程, 2019, 46(4): 180466.
[2] Liu X M, Cao J, Fu T Y,. Semi-supervised automatic segmentation of layer and fluid region in retinal optical coherence tomography images using adversarial learning[J]., 2018, 7: 3046–3061.
[3] She L H, Guo Y R, Zhang S. Retinal vessel segmentation algorithm based on orientation scores and Frangi filter[J].(), 2020, 41(2): 182–187.
佘黎煌, 郭一蓉, 张石. 基于方向分数和Frangi滤波器的视网膜血管分割算法[J]. 东北大学学报(自然科学版), 2020, 41(2): 182–187.
[4] Liang L M, Sheng X Q, Lan Z M,. U-shaped retinal vessel segmentation algorithm based on adaptive scale information[J]., 2019, 39(08): 126–140. 梁礼明, 盛校棋, 蓝智敏, 等. 自适应尺度信息的U型视网膜血管分割算法[J]. 光学学报, 2019, 39(08): 126–140.
[5] Wang D Y, Haytham A, Pottenburgh J,. Hard attention net for automatic retinal vessel segmentation[J]., 2020, 24(12): 3384–3396.
[6] Han K, Wang Y H, Tian Q,. GhostNet: more features from cheap operations[C]//. 2020: 1577–1586.
[7] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//. 2018: 7132–7141.
[8] Zheng X W, Huan L X, Xia G S,. Parsing very high resolution urban scene images by learning deep ConvNets with edge-aware loss[J]., 2020, 170: 15–28.
[9] Zhang S D, He F Z. DRCDN: learning deep residual convolutional dehazing networks[J]., 2020, 36(9): 1797–1808.
[10] Wang Y J, Hu S Y, Wang G D,. Multi-scale dilated convolution of convolutional neural network for crowd counting[J]., 2020, 79(1–2): 1057–1073.
[11] Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]//. 2015: 234–241.
[12] Azad R, Asadi-Aghbolaghi M, Fathy M,. Bi-directional ConvLSTM U-Net with densley connected convolutions[C]//. 2019: 406–415.
[13] Jha D, Riegler M A, Johansen D,. DoubleU-Net: a deep convolutional neural network for medical image segmentation[C]//(). 2020: 558–564.
[14] Jiang Y, Wang F L, Gao J,. Efficient BFCN for automatic retinal vessel segmentation[J]., 2020, 2020: 6439407.
[15] Yan Z Q, Yang X, Cheng K T. Joint segment-level and pixel-wise losses for deep learning based retinal vessel segmentation[J]., 2018, 65(9): 1912–1923.
[16] Li H, Wang Y K, Wan C,. MAU-Net: a retinal vessels segmentation method[C]//(). 2020: 1958–1961.
[17] Jin Q G, Meng Z P, Pham T D,. DUNet: a deformable network for retinal vessel segmentation[J]., 2019, 178: 149–162.
[18] Li X, Jiang Y C, Li M L,. Lightweight attention convolutional neural network for retinal vessel image segmentation[J]., 2021, 17(3): 1958–1967.
[19] Tang P, Liang Q K, Yan X T,. Multi-proportion channel ensemble model for retinal vessel segmentation[J]., 2019, 111: 103352.
[20] Oliveira A, Pereira S, Silva C A. Retinal vessel segmentation based on fully convolutional neural networks[J]., 2018, 112: 229–242.
[21] Wu Y C, Xia Y, Song Y,. NFN+: a novel network followed network for retinal vessel segmentation[J]., 2020, 126: 153–162.
[22] Guo F, Li W Q, Kuang Z H,. MES-Net: a new network for retinal image segmentation[J]., 2021, 80(10): 14767–14788.
[23] Tang Y, Rui Z Y, Yan C F,. ResWnet for retinal small vessel segmentation[J]., 2020, 8: 198265–198274.
[24] Samuel P M, Veeramalai T. Multilevel and multiscale deep neural network for retinal blood vessel segmentation[J]., 2019, 11(7): 946.
Ghost convolution adaptive retinal vessel segmentation algorithm
Liang Liming1, Zhou Longsong1, Chen Xin1, Yu Jie1, Feng Xingang2*
1School of Electrical Engineering and Automation, Jiangxi University of Science and Technology, Ganzhou, Jiangxi 341000, China;2School of Applied Sciences, Jiangxi University of Science and Technology, Ganzhou, Jiangxi 341000, China
Ghost module
Overview:Retinal vascular morphology is an important indicator of human health, and its image processing and segmentation are of great significance for the early detection and treatment of glaucoma, cardiovascular disease, and venous obstruction. At present, retinal vessel segmentation algorithms are mainly divided into unsupervised and supervised learning methods. Unsupervised learning method mainly focuses on the original information of fundus blood vessels and uses matching filtering, mathematical morphology and vascular tracking to segment fundus images. Supervised learning requires prior label information, and the classifier is trained and extracted by manually labeled Label image, and then the retinal vessels are segmented. However, the existing retinal vessel segmentation algorithm has some problems, such as blurred main vessel contour, micro-vessel fracture, and optic disc boundary missegmentation. To solve the above problems, a ghost convolution adaptive retinal vessel segmentation algorithm was proposed. First, color fundus images were separated by RGB (Red, Green, Blue) channels and Contrast Limited Adaptive Histogram Equalization to enhance the contrast between retinal blood vessels and background, and to reduce the influence of light intensity and color channel on the segmentation effect. Then the fundus images were input into the ghoul convolution adaptive network for training to extract the vascular features. The algorithm uses ghoul convolution to replace the common convolution in the neural network, and the ghoul convolution can generate rich vascular feature maps to fully extract the target features. The features are classified and predicted by the adaptive fusion module input into the decoding layer, and the adaptive fusion can capture the image information at multiple scales and preserve the vascular details with high quality. In the process of accurately locating vascular pixels and solving the loss of image texture, a dual-pathway attention guiding structure is constructed to effectively combine the feature maps at the bottom and the high level of the network, which solves the information loss at the pooling layer, achieves global semantic transmission, better retains vascular pixels, and makes the edge details of the segmented image more complete. At the same time, Cross-Dice Loss function is introduced to suppress the problem of uneven positive and negative samples and reduce the segmentation error caused by the small proportion of foreground. The experiment was carried out on DRIVE and STARE datasets. The DRIVE dataset contains 40 color fundus images, which were manually divided into training sets and test sets by the authorities. The STARE database contains 20 color fundus images, which were evenly divided into five parts, and the experiment was carried out in a 50% fold cross validation method. Experimental results: the accuracy rate was 96.56% and 97.32%, sensitivity was 84.52% and 83.12%, specificity was 98.25% and 98.96%, respectively. In the segmentation results, the main vessels were less broken and the microvessels were clear, which has certain medical clinical application value.
Liang L M, Zhou L S, Chen X,Ghost convolution adaptive retinal vessel segmentation algorithm[J]., 2021, 48(10): 210291; DOI:10.12086/oee.2021.210291
Ghost convolution adaptive retinal vessel segmentation algorithm
Liang Liming1, Zhou Longsong1, Chen Xin1, Yu Jie1, Feng Xingang2*
1School of Electrical Engineering and Automation, Jiangxi University of Science and Technology, Ganzhou, Jiangxi 341000, China;2School of Applied Sciences, Jiangxi University of Science and Technology, Ganzhou, Jiangxi 341000, China
In order to solve the problems in retinal vessel segmentation, such as blurred main vessel profile, broken micro-vessels, and missegmented optic disc boundary, a ghost convolution adaptive retinal vessel segmentation algorithm is proposed. The first algorithm uses ghost convolution to replace the common convolution in neural network, and the ghost convolution generates rich vascular feature maps to make the target feature extraction fully carried out. Secondly, the generated feature images are adaptive fusion and input to the decoding layer for classification. Adaptive fusion can capture image information at multiple scales and save details with high quality. Thirdly, in the process of accurately locating vascular pixels and solving image texture loss, a dual-pathway attention guiding structure is constructed to effectively combine the feature map at the bottom and the feature map at the top of the network to improve the accuracy of vascular segmentation. At the same time, Cross-Dice Loss function was introduced to suppress the problem of uneven positive and negative samples and reduce the segmentation error caused by the small proportion of vascular pixels. Experiments were conducted on DRIVE and STARE datasets. The accuracy was 96.56% and 97.32%, the sensitivity was 84.52% and 83.12%, and the specificity was 98.25% and 98.96%, respectively, which proves the good segmentation effect.
retinal vessels; ghost convolution; adaptive fusion module; dual-pathway attention guided structure
National Natural Science Foundation of China (51365017, 61463018), General Project of Jiangxi Natural Science Foundation (20192BAB205084), and Key Project of Science and Technology Research of Jiangxi Provincial Department of Education (GJJ170491)
10.12086/oee.2021.210291
TP391
A
* E-mail: gzfxg1980@163.com
梁礼明,周珑颂,陈鑫,等. 鬼影卷积自适应视网膜血管分割算法[J]. 光电工程,2021,48(10): 210291
Liang L M, Zhou L S, Chen X, et al. Ghost convolution adaptive retinal vessel segmentation algorithm[J]. Opto-Electron Eng, 2021, 48(10): 210291
2021-09-06;
2021-10-02
国家自然科学基金资助项目(51365017,61463018);江西省自然科学基金面上项目(20192BAB205084);江西省教育厅科学技术研究重点项目(GJJ170491)
梁礼明(1967-),男,硕士,教授,主要从事医学影像方面的研究。E-mail:9119890012@jxust.edu.cn
冯新刚(1980-),男,硕士,讲师,主要从事医学影像方面的研究。E-mail:gzfxg1980@163.com
版权所有©2021中国科学院光电技术研究所
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
北京航空航天大学学报(2021年9期)2021-11-02
中医眼耳鼻喉杂志(2021年1期)2021-07-22
中医眼耳鼻喉杂志(2021年2期)2021-07-21
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
印刷技术·数字印艺(2016年11期)2016-12-06
湖南中医药大学学报(2016年1期)2016-12-01
科技视界(2016年6期)2016-07-12
浙江大学学报(工学版)(2015年1期)2015-03-01
