
基于自适应模板更新与多特征融合的视频目标分割算法
2021-12-07 07:10:46汪水源侯志强李富成马素刚
光电工程 2021年10期
汪水源,侯志强*,王 囡,李富成,蒲 磊,马素刚
基于自适应模板更新与多特征融合的视频目标分割算法
汪水源1,2,侯志强1,2*,王 囡1,2,李富成1,2,蒲 磊3,马素刚1,2
1西安邮电大学计算机学院,陕西 西安 710121;2西安邮电大学陕西省网络数据分析与智能处理重点实验室,陕西 西安 710121;3火箭军工程大学作战保障学院,陕西 西安 710025
针对SiamMask不能很好地适应目标外观变化,特征信息利用不足导致生成掩码较为粗糙等问题,本文提出一种基于自适应模板更新与多特征融合的视频目标分割算法。首先,算法利用每一帧的分割结果对模板进行自适应更新;其次,使用混合池化模块对主干网络第四阶段提取的特征进行增强,将增强后的特征与粗略掩码进行融合;最后,使用特征融合模块对粗略掩码进行逐阶段细化,该模块能够对拼接后的特征进行有效的加权组合。实验结果表明,与SiamMask相比,本文算法性能有明显提升。在DAVIS2016数据集上,本文算法的区域相似度和轮廓相似度分别为0.727和0.696,比基准算法提升了1.0%和1.8%,速度达到40.2 f/s;在DAVIS2017数据集上,本文算法的区域相似度和轮廓相似度分别为0.567和0.615,比基准算法提升了2.4%和3.0%,速度达到42.6 f/s。
视频目标分割;模板更新;特征融合;掩码细化

1 引 言
近年来,视频目标分割(video object segmentation,VOS)在视频监控、自动驾驶和智能机器人等领域具有广泛的应用,受到了越来越多研究人员的关注。
按照人工参与程度的不同,可以将视频目标分割分为交互式视频目标分割、无监督视频目标分割和半监督视频目标分割。交互式VOS根据用户的迭代输入来分割感兴趣目标,它主要用于获取高精度的分割结果[1]。无监督VOS旨在使用显著特征、独立运动或已知类别标签自动估计目标掩码[2],它不需要用户给出任何输入,通常用来自动分割视频中最关键、最显著的目标。半监督VOS是视频目标分割领域中最受关注的任务,也是本文的研究方向。半监督VOS给出了视频第一帧中目标的真实掩码,它的目的是在剩余帧中自动分割出目标掩码,然而,在整个视频序列中,待分割目标可能会经历较大的外观变化、遮挡和快速运动等情况,因此,想要在视频序列中鲁棒地分割出目标是一项极具挑战性的任务。
早期的半监督视频目标分割相关工作以OSVOS[3],MaskTrack[4]等算法为代表。OSVOS利用视频首帧掩码独立地处理视频的每一帧,虽然有效地解决了遮挡问题,但它忽略了视频中隐含的时序信息。MaskTrack使用光流将分割掩码从当前帧传播到下一帧。OnAVOS[5]通过在线自适应机制扩展了第一帧微调。PReMVOS[6]通过使用广泛的微调和合并算法组合了包括光流网络在内的四个不同的神经网络。尽管这些方法取得了不错的分割效果,但它们所采用的在线微调技术严重影响了分割速度。DyeNet[7]将模板匹配引入到重识别网络中,并抛弃了在线微调,但利用光流和循环神经网络使其训练复杂且计算量大。之后的一些工作旨在避免微调和使用光流,从而实现更快的分割速度。FAVOS[8]提出了一种基于部分区域的跟踪方法来跟踪目标对象的局部区域。PML[9]使用最近邻分类器学习像素方式的嵌入。VideoMatch[10]使用软匹配层,将当前帧的像素映射到学习嵌入空间中的第一帧。以上方法仅使用视频的前一帧或第一帧掩码作为当前帧的参考,利用前一帧掩码可以更好地处理外观的变化,但同时会牺牲对遮挡和误差漂移的鲁棒性,而利用第一帧掩码与此相反。
后续工作更注重前一帧和第一帧相结合。FEELVOS[11]扩展了MaskTrack,它采用语义像素级嵌入以及全局和局部匹配机制将目标信息从视频的第一帧和前一帧传输到当前帧。与微调方法相比,FEELVOS实现了更快的运行速度,但容易产生累积误差。AGAME[12]提出了一种概率生成模型来预测目标和背景的特征分布。OSMN[13]使用两个网络分别提取第一帧和前一帧的实例级信息,从而对当前帧进行分割预测。RGMP[14]采用在多个阶段中训练的编码器-解码器孪生网络架构来捕捉搜索图像和模板图像之间的局部相似性。STMVOS[15]利用存储网络从当前帧之前的包括第一帧和上一帧在内的更多帧中存储和读取信息,其性能优于之前所有的方法,但是,STMVOS的训练过程较为繁琐,对硬件需求较高。
SiamMask[16]通过在SiamRPN[17]的基础上增加Mask分支,形成了一种多分支的孪生网络框架。在视频目标分割领域,SiamMask在DAVIS2016[18]和DAVIS2017[19]数据集上取得具有竞争性分割精度的同时,速度比同时期的方法快了近一个数量级。对比经典的OSVOS,SiamMask快了两个数量级,使得视频目标分割可以得到实际应用。但是,由于缺少模板更新,在复杂视频中,SiamMask容易出现跟踪漂移现象;此外,在掩码生成过程中,SiamMask所使用的特征信
息损失较多,融合过程较为粗糙,没有采用主干网络全阶段的特征图对掩码进行细化。为了解决以上问题,本文提出一种基于自适应模板更新与多特征融合的视频目标分割算法。首先,所提算法使用自适应更新策略对模板进行处理,该策略可以利用每一帧的分割结果对模板进行更新;其次,为了使用更多的特征信息对掩码进行细化,本文算法使用混合池化模块对主干网络第四阶段提取的特征进行增强,将增强后的特征与粗略掩码进行融合;最后,为了生成更为精细的掩码,本文算法使用特征融合模块将主干网络各个阶段具有更丰富空间信息的中间特征参与到掩码细化过程中。实验结果表明,本文算法显著改善了基准算法因遮挡、相似背景干扰等原因导致的跟踪漂移现象,在DAVIS2016和DAVIS2017数据集上的性能得到明显提升,运行速度满足实时性要求。
2 本文算法
本文提出一种基于自适应模板更新与多特征融合的视频目标分割算法。算法在SiamMask[6]基础上,利用自适应更新策略对模板进行处理,使用混合池化模块对主干网络第四阶段提取的特征进行增强,并采用特征融合模块对粗略掩码进行逐阶段细化。
2.1 SiamMask算法简介
SiamMask包括提取特征的ResNet-50主干网络、RPN分支和掩码生成模块(mask generation module)三个部分,算法整体框架如图1所示。算法首先需要人工在视频的第一帧(模板帧)中选定待跟踪目标;接着,将选定目标与视频当前帧(搜索帧)同时输入主干网络,分别得到目标模板和提取到的当前帧的特征图,对二者进行互相关得到响应图;随后,根据RPN分支的指导在响应图的对应位置选取部分区域,并上采样得到粗略的初始掩码;最后,利用主干网络所提取的当前帧每阶段的特征图,对粗略掩码进行逐阶段的逐点相加并上采样,得到精细掩码,以此精细掩码作为对应视频每一帧的最终分割结果。
2.2 模板更新模块
基于孪生网络的视频目标分割和视觉目标跟踪算法大多使用视频第一帧中已标记的目标作为模板,在后续帧的搜索区域中与该模板进行匹配,从而得到目标在该帧对应的位置。虽然保持目标模板不变可以提升算法对遮挡和误差漂移的鲁棒性,但在整个视频中,目标的外观和姿态通常改变很大,如不更新模板,跟踪过程会受到目标漂移的影响,进而导致跟踪失败且无法恢复。
受UpdateNet[20]的启发,本文在SiamMask中引入模板更新模块(template update module),该模块采用自适应更新策略对模板进行在线更新,该策略可用以下的表达式表示:


2.3 混合池化模块
由于SiamMask只使用ResNet-50的前四个阶段作为主干网络,且末层提取特征仅下采样到原图尺寸的1/8,这就导致深层特征既没有足够的感受野,又缺少丰富的上下文信息。此外,在掩码生成模块中,SiamMask只使用了主干网络前三个阶段的特征图对掩码进行细化,这使掩码又进一步损失了多尺度的语义信息。为了解决这些问题,综合速度与性能的考虑,本文算法在保持原始算法主干网络结构不变的基础上,继续使用第四阶段的特征对掩码进行细化。前人工作已经证明,金字塔池化模块[21]是增强场景解析网络的有效方法,它可以有效地捕捉长程上下文信息。受SPNet[22]的启发,本文算法引入混合池化模块(mixed pooling module,MPM)对主干网络第四阶段的特征进行增强,该模块可以同时收集特征图的长程和短程依赖关系,增强特征图的感受野。

图1 SiamMask算法整体框架
本文所使用的混合池化模块(MPM)如图3所示。设输入特征图形状为´´,其中,,分别代表特征图的高度,宽度和通道数。为了降低计算复杂度,MPM首先将特征图通道数调整为原来的1/4;随后,将调整后的特征图同时送入上下四个并行分支。其中,Pool_、Pool_分别对特征图的水平和垂直方向进行条状池化,得到´1和1´的特征图;接着,将两个特征图同时扩张至´后进行相加,得到具有充足远程上下文信息的融合特征图。Pool_S5和Pool_S3首先对调整后的特征图进行不同比例的池化,分别得到尺寸为原特征图1/5和1/3的两个特征图;然后,对这两个输出进行上采样并与原始尺寸的特征图相加,得到具备充足短程上下文信息的融合特征图。最后,将两个融合特征图按通道拼接并调整,得到最终融合特征图。

图2 模板更新模块与模板更新流程
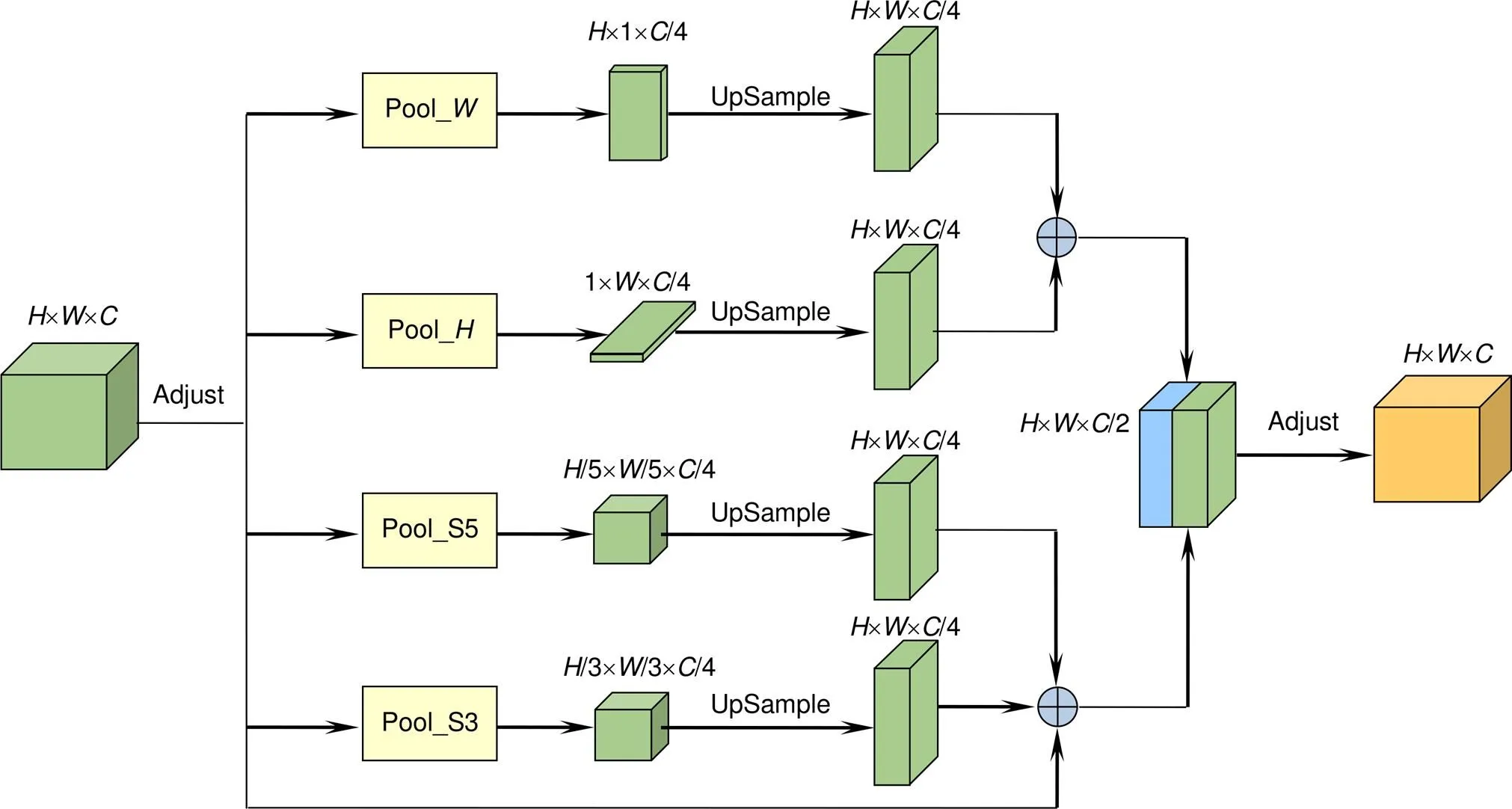
图3 混合池化模块(MPM)
2.4 多尺度掩码细化与特征融合模块
在粗略掩码细化过程中,SiamMask首先将主干网络前三阶段所提取的中间特征通道数调整为原来的1/16,随后再分别与粗略掩码逐点相加并上采样。整个过程没有充分利用浅层网络的特征信息,这会导致掩码丢失更多的空间与语义信息。因此,除继续使用第四阶段的特征外,本文只将浅层网络所提取的特征通道数调整为原来的1/4。受BiseNet[23]的启发,本文算法使用特征融合模块(feature fusion module,FFM)将调整后的每一阶段特征与粗略掩码进行通道拼接。如图4所示,此特征融合模块可以对融合特征重新加权组合,自适应地选择需要关注的通道信息。

图4 特征融合模块(FFM)
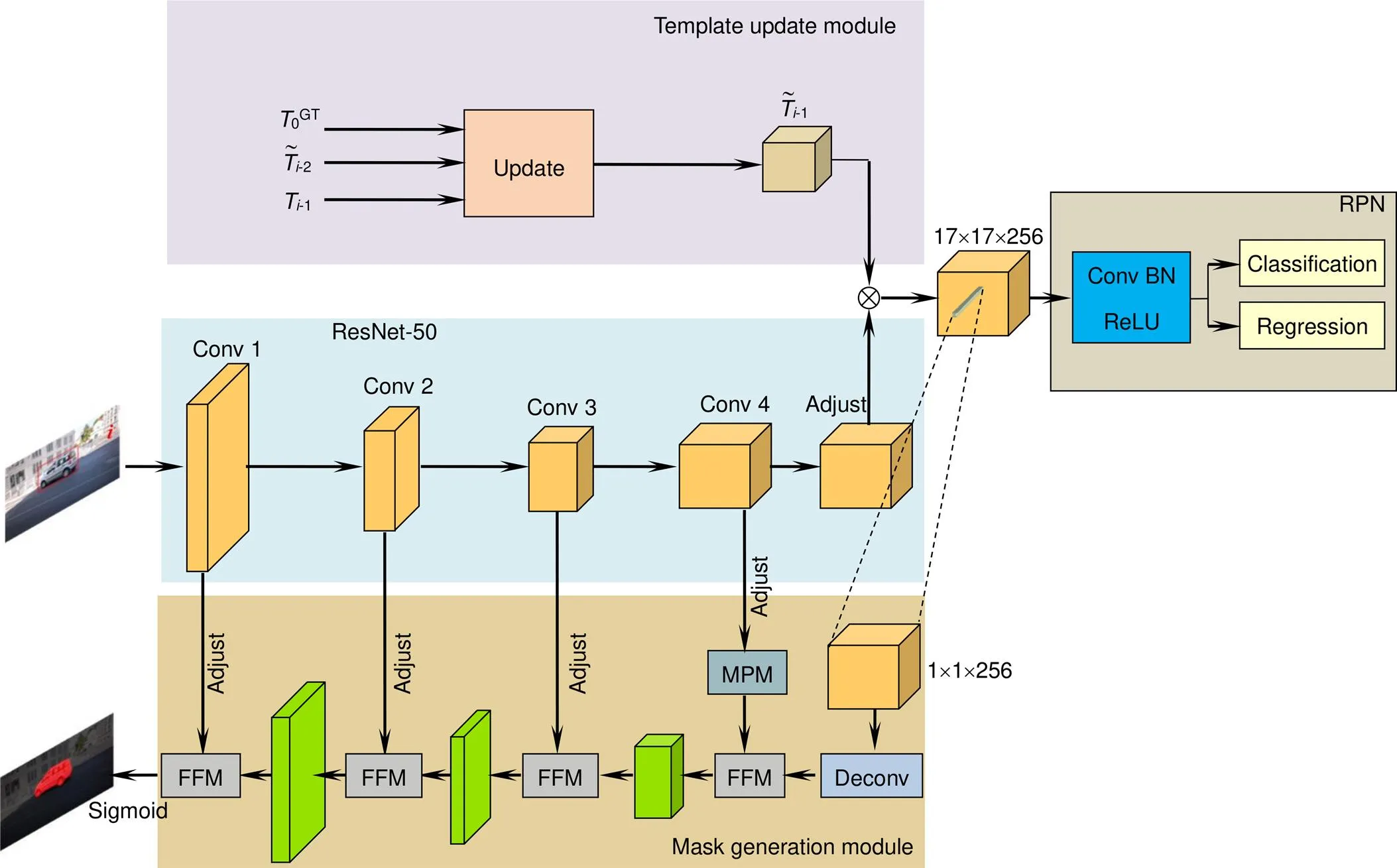
图5 本文算法整体框架
2.5 算法整体框架
如图5所示,本文算法在SiamMask的基础上增加了模板更新模块(template update module),改进了掩码生成模块(mask generation module),主干网络和RPN分支的设置皆与原文保持一致。本文算法依然需要人工在视频的第一帧中选定待跟踪目标,不同于SiamMask,与当前帧特征进行互相关的不再是从第一帧中所提取的目标模板,而是经过模板更新模块逐帧更新的特定模板;采用与SiamMask相同的方式获取粗略掩码后,本文算法使用改进后的掩码生成模块对粗略掩码进行处理,从而得到视频每一帧的精细分割结果。
3 实验结果
为验证所提算法的有效性,本文采用DAVIS2016和DAVIS2017数据集对其进行评估。
DAVIS2016和DAVIS2017是当前视频目标分割界常用的测试数据集,DAVIS2016包含50个高质量视频,其中30个用于训练,20个用于评估,每个视频序列只注释一个目标。DAVIS2017是对DAVIS2016的扩展,包括60个用于训练的视频序列和30个用于评估的视频序列,它涵盖了视频目标分割任务中常见的多种挑战场景,如遮挡、运动模糊和外观变化,每个视频序列平均包含2.03个对象,单个视频序列最多包含5个要跟踪的对象。
本文的实验环境如下:操作系统为64 位的 Ubuntu 16.04,PyTorch版本为0.4.1,16 G内存,GPU为1块NVIDIA 1080Ti。
3.1 网络训练细节
本文算法采用两阶段方法完成整个网络的训练,其中,掩码生成模块仅在第二阶段进行训练。在第一阶段,网络首先加载在ImageNet-1k上预训练的ResNet-50权重模型;随后,使用随机梯度下降优化算法,在Youtube-VOS、COCO、ImageNet-DET和 ImageNet-VID数据集上对网络进行训练,epoch设置为50。前五个epoch使用预热策略,学习率从1´10-3逐渐增长到5´10-3,后45个epoch使用对数下降策略,学习率从5´10-3逐渐降低到2.5´10-3。第二阶段仅使用带有掩码标注的Youtube-VOS和COCO数据集进行训练,epoch设置为20,整个第二阶段采用对数下降策略,学习率从1´10-2逐渐下降到2.5´10-3。
3.2 定性分析
图6给出了本文算法与原始算法在DAVIS2016和DAVIS2017上的分割效果图,其中,前两列为DAVIS2016上的定性实验结果,第三和第四列为在多目标的DAVIS2017上的定性实验结果。
在第一列图中,原始算法在目标出现遮挡现象时,跟踪结果发生漂移,而本文算法可以较好地克服此种情景。
在第二列图中,在目标发生较大形变并伴有相似物干扰时,原始算法的分割效果并不理想,而本文算法则实现了对相似干扰背景的剔除,在目标形变的情况下依然可以给出较好的分割掩码。
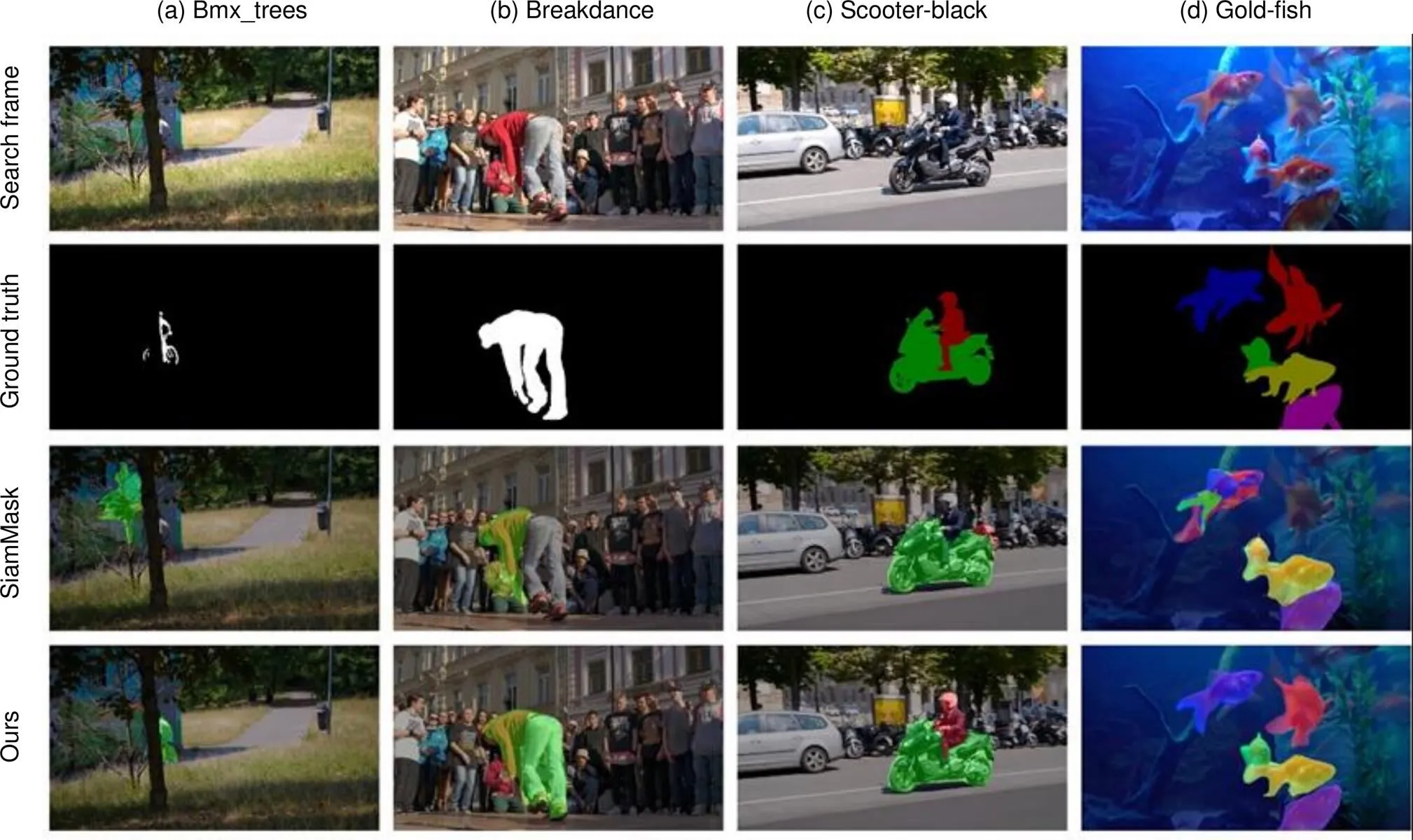
图6 定性实验结果
第三列图中,当两个不同类别的目标同时出现快速运动时,原始算法出现了误判现象(误把摩托车尾部认为是骑摩托的人),而本文算法仍可以分别对两个目标给出较好的分割结果。
第四列图中出现了多个同类别的目标(五条金鱼),它们在图片中分布紧密并伴有目标之间的粘连和遮挡,其中,右上角的金鱼在该帧还出现了较大的形变。在面对此种极具挑战性的场景时,原始算法出现了明显的相似目标误判(左上角金鱼和中间两条粘连的金鱼)和目标的漏检(右上角金鱼),目标的掩码轮廓也比较粗糙。本文算法则精准地分割出全部目标,掩码质量也明显优于原算法。
3.3 定量分析
DAVIS系列数据集的评价指标主要有Jaccard index(J)和F-Measure(F)。Jaccard index是评价分割质量的常用指标,它被计算为预测掩码和掩码真值的交并比(IOU),用来衡量二者之间的区域相似度。F-Measure基于准确率和召回率进行计算,它衡量的是预测掩码与掩码真值之间的轮廓相似度。
表1给出了本文算法和其他五种对比算法(VPN[24]、BVS[25]、PLM[26]、MuG-W[2]、SiamMask[16])在DAVIS2016上的性能指标,从中可以看出,本文算法的区域相似度(J)为0.727,轮廓相似度(F)为0.696,超越了所有的对比算法。相比于SiamMask,J和F分别提升1.0%和1.8%的同时,速度满足实时性要求,达到40.2 f/s。
表2给出了本文算法和其他五种对比算法(OSVOS[3]、FAVOS[8]、OSMN[13]、MuG-W[2]、SiamMask[16])在DAVIS2017上的性能指标,从中可以看出,本文算法的区域相似度(J)为0.567,优于其他五种对比算法,比原算法提升了2.4%,轮廓相似度(F)为0.615,比原算法提升了3.0%,虽然略低于OSVOS和FAVOS,但本文算法的速度比它们快了一个甚至是两个数量级,达到42.6 f/s,依然满足实时性要求。SiamMask_R为按SiamMask开源代码进行复现的测试结果,由于硬件设备存在差异及测试参数的影响,本文在DAVIS2016上的复现结果略低于SiamMask,DAVIS2017上的复现结果与SiamMask相同,本文所有工作皆在此复现基础上进行。

表1 DAVIS2016验证集上不同算法之间的性能对比

表2 DAVIS2017验证集上不同算法之间的性能对比
3.4 消融实验
为了验证所提模块的有效性,本文算法采用DAVIS2017数据集进行消融实验。如表3所示,MPM表示是否使用混合池化模块处理过后的主干网络第四阶段特征进行掩码细化;FFM表示在逐阶段掩码细化过程中,是否采用特征融合模块;Update表示是否使用模板更新模块。结果表明,使用多尺度特征可以给粗略掩码提供更多的语义信息,一定程度上提升了分割精度。利用数量更为丰富的通道信息,以通道拼接并自适应选择的特征融合方式代替逐点相加,使得掩码细化过程更为合理,进一步优化了分割效果。Update模块则利用了视频中潜在的时序信息,对每一帧的分割做出更加准确的指导,再次将本文算法的分割精度提升到新的高度。

表3 本文算法在DAVIS2017上的消融实验
4 结 论
本文提出了一种基于自适应模板更新与多特征融合的视频目标分割算法。首先,算法利用每一帧的分割结果对模板进行自适应更新;其次,在掩码生成过程中,使用特征信息更为丰富的中间特征和更为合理的融合过程对掩码进行细化。与SiamMask相比,所提算法性能得到明显提升的同时,速度达到实时。但是,本文算法需要对每一个数据集分别进行参数调试,过程较为繁琐,这也是Siamese系列算法难以复现的原因之一。它们需要使用先验知识和多个后处理来辅助跟踪和分割结果的选择,后处理过程会引入对应的超参数,而Siamese系列算法对超参数的选择非常敏感,如果没有合适的超参数,算法性能会受到比较大的影响。最近的一些工作将Transformer的思想融入到跟踪算法中[27],单个参数即可适用于所有数据集,显著降低了后处理操作对算法性能的影响。因此,本文后续工作将考虑对此进行探索,以进一步优化视频目标分割算法的后处理过程。
[1] Miao J X, Wei Y C, Yang Y. Memory aggregation networks for efficient interactive video object segmentation[C]//, 2020: 10366–10375.
[2] Lu X K, Wang W G, Shen J B,. Learning video object segmentation from unlabeled videos[C]//, 2020: 8957–8967.
[3] Caelles S, Maninis K K, Pont-Tuset J,. One-shot video object segmentation[C]//, 2017: 5320–5329.
[4] Perazzi F, Khoreva A, Benenson R,. Learning video object segmentation from static images[C]//, 2017: 3491–3500.
[5] Voigtlaender P, Leibe B. Online adaptation of convolutional neural networks for video object segmentation[Z]. arXiv: 1706.09364, 2017.
[6] Luiten J, Voigtlaender P, Leibe B. PReMVOS: proposal-generation, refinement and merging for video object segmentation[C]//, 2018: 565–580.
[7] Li X X, Loy C C. Video object segmentation with joint re-identification and attention-aware mask propagation[C]//, 2018: 93–110.
[8] Cheng J C, Tsai Y H, Hung W C,. Fast and accurate online video object segmentation via tracking parts[C]//, 2018: 7415–7424.
[9] Chen Y H, Pont-Tuset J, Montes A,. Blazingly fast video object segmentation with pixel-wise metric learning[C]//, 2018: 1189–1198.
[10] Hu Y T, Huang J B, Schwing A G. VideoMatch: matching based video object segmentation[C]//, 2018: 56–73.
[11] Voigtlaender P, Chai Y N, Schroff F,. FEELVOS: fast end-to-end embedding learning for video object segmentation[C]//, 2019: 9473–9482.
[12] Johnander J, Danelljan M, Brissman E,. A generative appearance model for end-to-end video object segmentation[C]//, 2019: 8945–8954.
[13] Yang L J, Wang Y R, Xiong X H,. Efficient video object segmentation via network modulation[C]//, 2018: 6499–6507.
[14] Oh S W, Lee J Y, Sunkavalli K,. Fast video object segmentation by reference-guided mask propagation[C]//, 2018: 7376–7385.
[15] Oh S W, Lee J Y, Xu N,. Video object segmentation using space-time memory networks[C]//, 2019: 9225–9234.
[16] Wang Q, Zhang L, Bertinetto L,. Fast online object tracking and segmentation: a unifying approach[C]//, 2019: 1328–1338.
[17] Li B, Yan J J, Wu W,. High performance visual tracking with Siamese region proposal network[C]//, 2018: 8971–8980.
[18] Perazzi F, Pont-Tuset J, McWilliams B,. A benchmark dataset and evaluation methodology for video object segmentation[C]//, 2016: 724–732.
[19] Pont-Tuset J, Perazzi F, Caelles S,. The 2017 DAVIS challenge on video object segmentation[Z]. arXiv: 1704.00675, 2018.
[20] Zhang L C, Gonzalez-Garcia A, Van De Weijer J,. Learning the model update for Siamese trackers[C]//, 2019: 4009–4018.
[21] Zhao H S, Shi J P, Qi X J,. Pyramid scene parsing network[C]//, 2017: 6230–6239.
[22] Hou Q B, Zhang L, Cheng M M,. Strip pooling: rethinking spatial pooling for scene parsing[C]//, 2020: 4002–4011.
[23] Yu C Q, Wang J B, Peng C,. BiSeNet: bilateral segmentation network for real-time semantic segmentation[C]//, 2018: 334–349.
[24] Jampani V, Gadde R, Gehler P V. Video propagation networks[C]//, 2017: 3154–3164.
[25] Märki N, Perazzi F, Wang O,. Bilateral space video segmentation[C]//, 2016: 743–751.
[26] Yoon J S, Rameau F, Kim J,. Pixel-level matching for video object segmentation using convolutional neural networks[C]//, 2017: 2186–2195.
[27] Chen X, Yan B, Zhu J W,. Transformer tracking[Z]. arXiv: 2103.15436, 2021.
Video object segmentation algorithm based on adaptive template updating and multi-feature fusion
Wang Shuiyuan1,2, Hou Zhiqiang1,2*, Wang Nan1,2, Li Fucheng1,2, Pu Lei3, Ma Sugang1,2
1Institute of Computer, Xi’an University of Posts and Telecommunications, Xi’an, Shaanxi 710121, China;2Shaanxi Key Laboratory of Network Data Analysis and Intelligent Processing, Xi’an University of Posts and Telecommunications, Xi’an, Shaanxi 710121, China;3Rocket Force University of Engineering, Operational Support School, Xi’an, Shaanxi 710025, China

Experimental results
Overview:In recent years, video object segmentation (VOS) has been widely used in video surveillance, autopilot, intelligent robot, and other fields, and it has attracted more and more researchers' attention. According to the degree of human participation, video object segmentation can be divided into interactive video object segmentation, unsupervised video object segmentation, and semi-supervised video object segmentation. Semi-supervised VOS is the most concerned task in the field of video object segmentation, and it is also the research direction of this paper. Semi-supervised VOS gives the real mask of the target in the first frame of the video, and its purpose is to segment the target mask automatically in the remaining frames. However, in the whole video sequence, the target to be segmented may experience great appearance changes, occlusion, and fast movement, so it is a very challenging task to segment the target robust in the video sequence.
SiamMask forms is a multi-branch twin network framework by adding Mask branches to SiamRPN. In the field of video object segmentation, SiamMask achieves competitive segmentation accuracy on DAVIS2016 and DAVIS2017data-sets. At the same time, the speed is nearly an order of magnitude faster than the method in the same period. Compared with the classical OSVOS, SiamMask is two orders of magnitude faster, so the video object segmentation can be applied in practice. However, due to the lack of template update, SiamMask is prone to tracking drift in complex videos. In addition, in the process of mask generation, SiamMask uses a lot of feature information loss, the fusion process is relatively rough, and does not use the feature map of the whole stage of the backbone network to refine the mask. In order to solve the above problems, this paper proposes a video object segmentation algorithm based on the adaptive template update and the multi-feature fusion. First of all, the proposed algorithm uses an adaptive update strategy to process the template, which can update the template using the segmentation results of each frame. Secondly, in order to use more feature information to refine the mask, this algorithm uses the hybrid pooling module to enhance the features extracted in the fourth stage of the backbone network, and fuses the enhanced features with the rough mask. Finally, in order to generate a more fine mask, this algorithm uses the feature fusion module to participate in the mask thinning process of intermediate features with richer spatial information in each stage of the backbone network. The experimental results show that the proposed algorithm significantly improves the tracking drift caused by occlusion and similar background interference, the performances on DAVIS2016 and DAVIS2017 data-sets are significantly improved, and the running speed meets the real-time requirements.
Wang S Y, Hou Z Q, Wang N,Video object segmentation algorithm based on adaptive template updating and multi-feature fusion[J]., 2021, 48(10): 210193; DOI:10.12086/oee.2021.210193
Video object segmentation algorithm based on adaptive template updating and multi-feature fusion
Wang Shuiyuan1,2, Hou Zhiqiang1,2*, Wang Nan1,2, Li Fucheng1,2, Pu Lei3, Ma Sugang1,2
1Institute of Computer, Xi’an University of Posts and Telecommunications, Xi’an, Shaanxi 710121, China;2Shaanxi Key Laboratory of Network Data Analysis and Intelligent Processing, Xi’an University of Posts and Telecommunications, Xi’an, Shaanxi 710121, China;3Rocket Force University of Engineering, Operational Support School, Xi’an, Shaanxi 710025, China
In order to solve the problem that SiamMask cannot adapt to the change of target appearance and the lack of use of feature information leads to rough mask generation, this paper proposes a video object segmentation algorithm based on the adaptive template update and the multi-feature fusion. First of all, the algorithm adaptively updates the template using the segmentation results of each frame; secondly, the hybrid pooling module is used to enhance the features extracted in the fourth stage of the backbone network, and the enhanced features are fused with the rough mask; finally, the feature fusion module is used to refine the rough mask stage by stage, which can effectively combine the spliced features. Experimental results show that, compared with SiamMask, the performance of the proposed algorithm is significantly improved. On the DAVIS2016 data-set, the region similarity and contour similarity of this algorithm are 0.727 and 0.696, respectively, which is 1.0% and 1.8% higher than that of the benchmark algorithm, and the speed reaches 40.2 f/s. On the DAVIS2017 data-set, the region similarity and contour similarity of this algorithm are 0.567 and 0.615, respectively, which is 2.4% and 3.0% higher than that of the benchmark algorithm, and the speed reaches 42.6 f/s.
video object segmentation; template update; feature fusion; mask thinning
National Natural Science Foundation of China (62072370)
10.12086/oee.2021.210193
TP391
A
2021-06-06;
2021-09-09基金项目:国家自然科学基金资助项目(62072370)
汪水源(1996-),男,硕士研究生,主要从事计算机视觉、视频目标分割的研究。E-mail:wsy_wang1@163.com
侯志强(1973-),男,博士,教授,博士生导师,主要从事图像处理、计算机视觉和信息融合的研究。E-mail:hzq@xupt.edu.cn
* E-mail: hzq@xupt.edu.cn
汪水源,侯志强,王囡,等. 基于自适应模板更新与多特征融合的视频目标分割算法[J]. 光电工程,2021,48(10): 210193
Wang S Y, Hou Z Q, Wang N, et al. Video object segmentation algorithm based on adaptive template updating and multi-feature fusion[J]. Opto-Electron Eng, 2021, 48(10): 210193
版权所有©2021中国科学院光电技术研究所
猜你喜欢
军事文摘(2024年2期)2024-01-10 01:58:34
建材发展导向(2022年23期)2022-12-22 07:30:02
建材发展导向(2022年12期)2022-08-19 02:33:10
广东教育·高中(2022年1期)2022-03-16 23:19:41
心肺血管病杂志(2020年3期)2021-01-14 00:42:12
心肺血管病杂志(2019年6期)2019-07-12 09:04:30
通信学报(2019年5期)2019-06-11 03:05:56
通信技术(2018年3期)2018-03-21 00:56:37
中国房地产业(2016年24期)2016-02-16 06:10:20
中国卫生(2015年9期)2015-11-10 03:11:10
