
基于SMOTE-XGBoost的变压器缺陷预测
2021-10-16 06:14王文博曾小梅赵引川张云云
华北电力大学学报(自然科学版) 2021年5期
王文博,曾小梅,赵引川,张云云,刘 达
(1.华北电力大学 数理学院,北京 102206;2.华北电力大学 智慧能源研究所,北京 102206;3.中国能源建设集团安徽省电力设计院有限公司,安徽 合肥 230602)
0 引 言
变压器作为电力系统中的重要设备,在电力传输过程中至关重要[1,2]。变压器缺陷可能会造成极大的经济损失和不利的社会影响。准确预测变压器缺陷可以有效避免灾难性损失的发生[3]。因此,准确诊断变压器缺陷情况尤为重要。
在大数据背景下,电网企业不断更新在线监测设备和计算机数据存储系统,这有助于实现电力设备的缺陷与故障诊断[4]。目前关于变压器缺陷预测的方法颇多,主要包括基于统计学的方法与机器学习方法。基于统计学的方法有多元线性回归[5]和时间序列[3,6]。但这两种方法都存在一定的局限性。多元线性回归方法仅适用于线性可分的情况,对缺陷发生与否的二分类预测问题有很大的偏差。时间序列的方法虽然降低了模型的建模难度,但缺陷影响因素多,导致预测精度较低。目前适用于数据集大且预测精度要求较高的变压器缺陷诊断模型是机器学习模型,如支持向量机[7,8]、逻辑回归[9]等。
在实际生产中发生故障的变压器数量往往小于正常的数量。即无缺陷的样本数量远大于有缺陷的样本数量。因此,变压器状态数据集是不平衡数据集。这种类别不平衡的分布很大程度上影响了监督分类方法的准确性[10,11],导致模型无法准确地预测变压器的健康状态。普通分类器通常以最小化总体训练误差为目标,这使得模型在训练过程中对多数样本的类别会重点考虑而产生过拟合;而对于占比较少的样本,由于没有特殊考虑而产生欠拟合[12,13]。这导致分类结果对无缺陷的变压器数据集更有利,分类器的泛化能力较差。因此,有效解决在类别不平衡的情况下的缺陷预测问题尤为重要。
然而,现有考虑变压器缺陷数据的类别不平衡问题的研究很有限[14,15]。文献[14]利用SMOTE和决策树模型对变压器状态进行评估,取得较好的效果。文献[15]利用SMOTE和SVM模型对变压器故障进行预测,结果表明该模型可以有效提升缺陷预测精度。这些结合SMOTE采样和机器学习算法的研究都取得了不错的预测效果。因此,本文在此研究基础上提出一种基于SMOTE-XGBoost(Extreme Gradient Boosting)的变压器缺陷预测模型,以期进一步提高变压器缺陷预测精度。XGBoost模型是一种集成算法,是经过优化的分布式梯度提升库,可进行大规模并行运算,具有高效、灵活且可移植等优点,对于设备的实时诊断很有意义。
本研究分别对不平衡数据集的处理方法和预测模型进行了对比分析,即分别采用随机上采样(Up_sample)、随机下采样(Down_sample)、SMOTE和代价敏感学习(Cost Sensitive Learning,CSL)算法对不平衡数据集进行处理,然后分别采用Logistic、CART、SVM和XGBoost四种预测模型进行预测。实证结果表明,SMOTE-XGBoost模型的预测效果最佳。
1 数据获取与模型介绍
1.1 数据获取
在大数据背景下,可基于用电信息采集系统和营配数据共享渠道获取电网大数据。就变压器设备而言,设备的属性、所处环境、负荷等数据可实时存储,可采集终端数据获取变压器特征信息。根据数据集的特点进行智能化处理,实现变压器设备的缺陷预测。
1.2 不平衡数据集算法
数据的类别不平衡问题是指数据的某一类别数量要远多于其他类。特别是对于二分类问题,一类数据是大样本数据,而另一类数据仅有少数样本。类别不平衡问题在生产和生活场景中很普遍。例如,故障诊断[16,17]、异常检测[18,19]、电子邮件归档[20]等。在模型训练过程中如果直接使用不平衡数据集进行训练,很容易导致分类失效。因为模型在分类时会受样本量多的类别的影响,容易产生“少数服从多数”的分类结果[21]。而很多时候,样本少的类别更具有研究价值[22]。所以对于不平衡数据集而言,一个优秀的分类模型应该是在少数类别中有更高的识别率,同时,不会严重影响多数类的预测准确性。
目前,不平衡数据的处理方法主要分四类,分别是数据采样、算法改进、代价敏感学习和集成学习。数据采样是对数据进行预处理来解决数据不平衡问题,这种方法的主要优点是独立于底层分类器,可以很容易地嵌入到集成学习中,是处理不平衡数据集的积极可行的解决方案[23,24];算法改进和代价敏感方法更依赖于问题;集成学习方法与数据采样方法一样都可以独立于基本分类器使用[12];因此,数据采样和集成方法在处理不平衡数据时更为通用。
本文选择了较有代表性的4种数据平衡算法,随机上采样(Up_sample)、随机下采样(Down_sample)、SMOTE和代价敏感学习(Cost Sensitive Learning,CSL)算法来解决变压器数据集的不平衡问题。
1.2.1 随机上采样与随机下采样
随机上采样是上采样的一种最常见的方法,是从变压器缺陷样本中随机地抽取样本添加到样本空间中,以达到缺陷样本与无缺陷样本的数据平衡。随机下采样是下采样方法的一种,其思想是通过减少无缺陷样本数以达到数据类别平衡。
1.2.2 代价敏感学习
代价敏感学习解决类别不平衡问题是通过定义错误分类的正样本和负样本的不同成本来防止过度拟合。对于变压器缺陷预测来说,要尽量避免将缺陷样本误分为无缺陷样本,为缺陷样本赋予更高的学习权重,从而让算法更加专注于缺陷样本的分类情况。
1.2.3 SMOTE算法
SMOTE算法是一种通过创造少数类样本来解决数据集不平衡问题的算法[25]。SMOTE算法是计算距离最近K个样本,然后随机地从中选择数据从而生成新样本,是一种基于“插值”来合成新样本的方法。
(1)

1.3 XGBoost算法原理
对于变压器的预测问题,一个有n个样本m个特征的数据集D={(xi,yi)}(|D|=n,xi∈Rm),需要预测主变压器是否会发生缺陷,发生缺陷为1,不发生缺陷为0。也就是说任务是一个二分类问题,使用XGBoost算法来实现梯度提升决策树(Gradient Boosting Decision Tree,GBDT),XGBoost是一种基于梯度增强决策树的改进算法,集合了大量弱而互补的分类器,可以有效地构造提升树并实现并行运行。该模型引进直方图算法生成分割点,被广泛应用在二分类问题上且达到较高的精度。其核心思想是优化目标函数的值[26]。
2 建模流程和评价指标
2.1 建模流程
本文基于此背景构建了变压器缺陷预测模型。图1展示了建模流程。
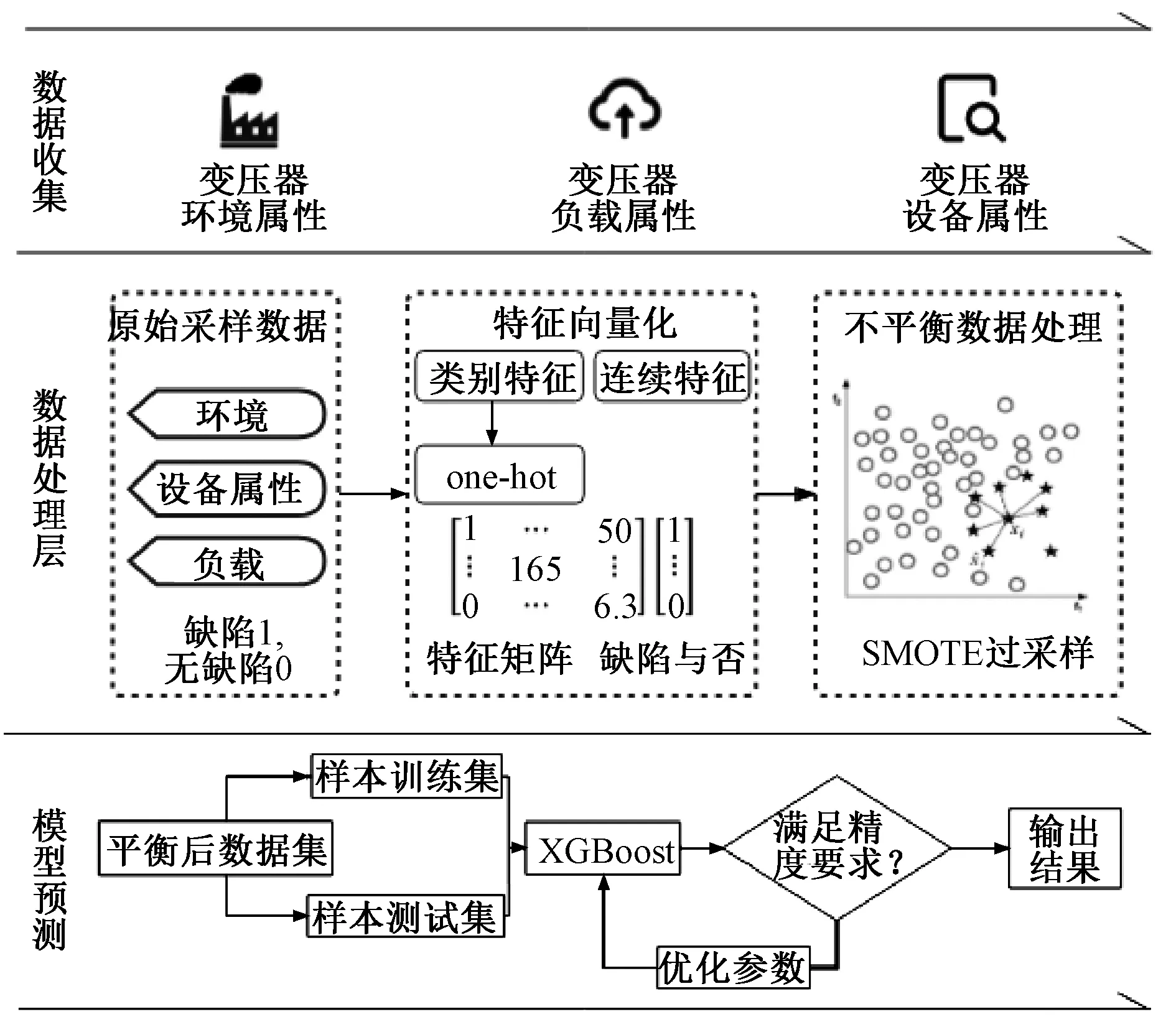
图1 建模流程图
(1)数据收集:通过物联网技术来采集变压器的环境、运行状况与设备信息等相关数据。
(2)数据清洗与整理:将收集的原始数据进行数据的清洗整理,然后进行特征的向量化,最后使用SMOTE 算法平衡数据集。
(3)模型构建:将平衡后的数据集作为XGBoost模型的输入来进行模型训练,最后预测变压器缺陷。
2.2 评价指标
在评估不平衡数据的算法时,常使用精确度、召回率和F1值来衡量,精确度是针对预测结果而言,它表示正确预测为正的占全部预测为正的比例;而召回率是针对原样本而言,它表示正确预测为正的占全部实际为正的比例;F1值能够将一个类的精度和召回率结合在同一个指标当中,故最终采用F1值来评估。精确度(Prec)、召回率(Rec)和F1值如式(2)~(4)所示:
(2)
(3)
(4)
式中:TP,FP,TN,FN分别表示真阳性,假阳性,真阴性和假阴性。即TP表示预测为有缺陷,实际也为有缺陷;FP表示预测为有缺陷,实际为无缺陷;TN表示预测为无缺陷,实际为无缺陷;FN表示预测为无缺陷,实际为有缺陷。
3 算法实验及结果分析
3.1 数据描述
本文收集某省电网2000年4月7日到2018年9月29日主变压器缺陷采样数据,有效数据共计31 342条,其中缺陷样本有5 660条,无缺陷样本25 682条。模型输出为1或0,1代表缺陷发生,0代表缺陷不发生。每一条数据包含变压器的24个属性特征,如表1所示。

表1 变压器属性表
3.2 建模过程及参数选择
为了解决变压器缺陷数据集的不平衡问题,本文分别采用Up_sample,CSL,SMOTE和Down_Sample四种不平衡数据集处理方法对原始数据集进行预处理,然后将原始数据集和处理后的数据集分别表示为A_1,A_2,A_3,A_4和A_5,并且进行对比验证。不平衡数据集处理参数及结果见表2,平衡后的样本量见表3。

表2 不平衡数据集处理过程及参数

表3 不平衡数据处理后样本量
对处理后的数据集采用五折交叉验证划分数据集。即第一步将数据集分为五份;第二步,选择其中四份为训练集,一份为验证集;第三步,重复第二步五次,每次选取的训练集不同。
最后,本文采用XGBoost算法预测变压器是否会发生缺陷,同时还采用了三种目前主流的变压器缺陷预测模型:决策树(Classification And Regression Trees,CART)、支持向量机(Support Vector Machine,SVM)和Logistic回归来进行对比验证。本文选取准确率,召回率和F1值三种评价指标评价模型性能。XGBoost算法使用Python的XGBoost包。其中XGBoost的超参数的含义及其设置见表4。图2为使用XGBoost模型预测SMOTE算法平衡后的迭代过程。

表4 XGBoost超参数列表

图2 迭代过程图
3.3 变压器缺陷预测模型解释性验证
本文在利用XGBoost对变压器缺陷预测的过程中得到各个属性的重要性得分,可衡量特征在模型中的价值。变压器缺陷预测模型的前十个重要特征得分如图3所示。
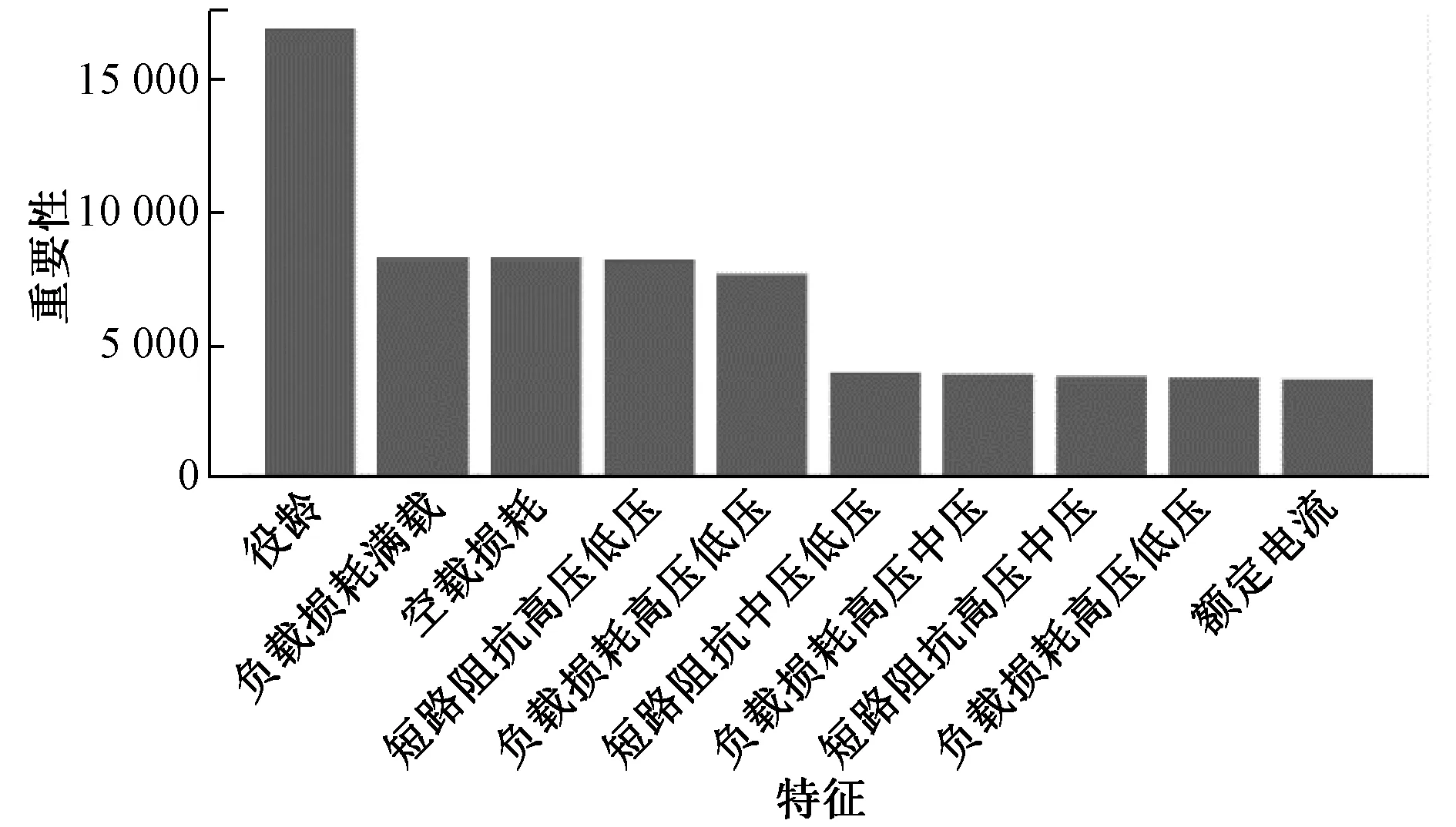
图3 重要特征排序
在所有特征中,役龄是最重要的影响因素,说明变压器的使用时间对变压器缺陷的发生有重要影响。其他的重要特征包括变压器的负载情况和属性特征,反映了变压器的性能对缺陷的影响。
4 结果分析
本文将分类模型Logistic,SVM,CART,XGBoost分别表示为M_1,M_2,M_3和M_4,然后各模型分别结合A_1,A_2,A_3,A_4和A_5数据处理方法进行缺陷预测。最后,分别采用召回率、精确度和F1值对各模型进行评价。实证结果见表5~表7,并利用箱线图对四种不平衡算法的预测效果进行可视化对比,如图4~图7所示。
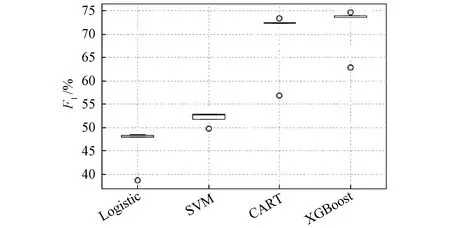
图7 预测算法F1值对比
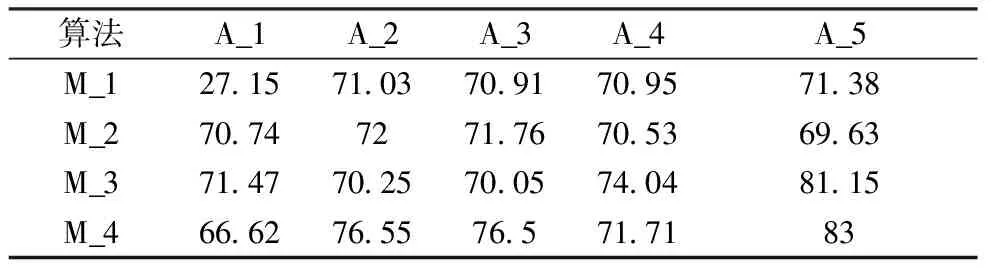
表5 缺陷预测召回率值

表6 缺陷预测精确度值

表7 缺陷预测F1值
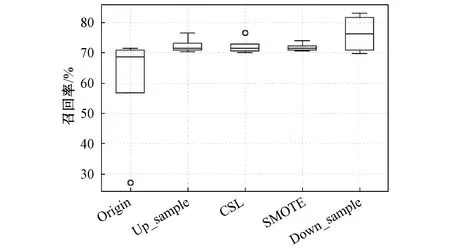
图4 不平衡算法召回率对比
各不平衡算法模型的召回率如表5和图4所示,召回率越高,代表实际缺陷变压器被预测出来的概率越高。结果证实,与未进行不平衡数据处理的模型(origin)相比,不平衡数据算法处理后的模型,召回率显著提高。
各不平衡数据模型的精确度如表6和图5所示,4个不平衡算法中,SMOTE表现最好,即使图4中显示Down_sample的召回率最高,但Down_sample的精确度最差,这可能是由于算法随机地移除无缺陷样本数据造成信息损失而导致预测精度下降。
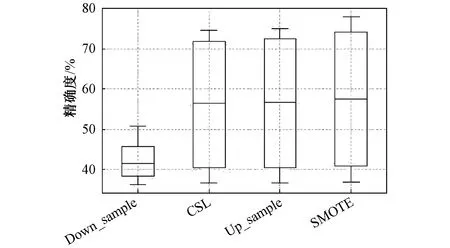
图5 不平衡算法精确度对比
本文采用F1值作为最终的评价指标,如图6所示SMOTE算法在四种算法中效果最优。随机上采样和代价敏感学习的效果稍弱,而随机下采样算法的效果最差。
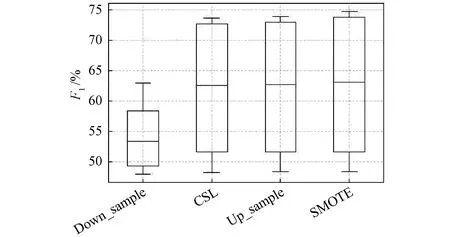
图6 不平衡算法F1值对比
通过上述分析可知SMOTE模型处理数据的最优选择,为了进一步确定最佳预测模型,本研究对各预测模型的F1值进行可视化,如图7所示。从图7可知,决策树和XGBoost在各个方面都优于SVM和logistic回归,这可能是因为实验数据的特征大都没有数值关系,所以树模型更适用于本实验。而XGBoost又优于决策树,因为XGBoost为集成算法,在单模型的基础上可以有效提高预测精度。
综上,四种不平衡处理方法都在一定程度上增加了正例类的召回率。但结合精确度和F1值指标,可以看出四种预测算法中SMOTE表现最优。当使用决策树和XGBoost时,SMOTE均表现最好。其中,SMOTE-XGBoost略胜一筹,因而以SMOTE-XGBoost作为最终预测方案,这一方案优于之前的变压器缺陷预测模型[7,9],可以有效的预测变压器缺陷问题。
5 结 论
变压器是电力设备中的重要组成部分,其健康状态的诊断监测对电网的正常运行至关重要。但变压器状态数据集存在严重的类别不平衡问题,这降低了诊断的正确率。因此,提高变压器不平衡样本的缺陷预测精度非常关键。而现有对变压器缺陷预测的研究很少考虑样本不平衡问题。为了丰富这方面的研究,本文利用SMOTE-XGBoost模型进行预测以提高变压器缺陷诊断的准确率。
本文采用四种不平衡数据集处理方法对变压器缺陷样本进行处理,然后分别采用四种预测模型进行对比分析实验。实证结果表明基于SMOTE-XGBoost模型在变压器缺陷预测中表现最优。该模型不仅解决了变压器的数据集的不平衡问题,且提高了缺陷预测精度。SMOTE方法简单有效地减轻了数据不平衡对预测精度的影响。在预测变压器的缺陷时,XGBoost支持并行处理,可以加快算法的计算速度,该算法比其他算法快十倍以上[26]。参数调整后,SMOTE和XGBoost算法可较为准确快速地预测变压器的缺陷,有效帮助电力企业开展变压器健康状态监测工作,实现电力设备管理维护智能化。
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
智富时代(2018年12期)2018-01-12
智富时代(2018年12期)2018-01-12
新教育时代·教师版(2017年30期)2017-09-12
小学教学研究(2017年1期)2017-01-19
中学生数理化·高二版(2016年5期)2016-05-14
微型计算机(2009年4期)2009-12-23
数理化学习·高三版(2009年6期)2009-07-30
