
基于深度学习的语义栅格地图构建方法
2021-10-12 00:42:58聂文康
武汉科技大学学报 2021年6期
聂文康,蒋 林,2,雷 斌,2,汤 勃
(1.武汉科技大学冶金装备及其控制教育部重点实验室,湖北 武汉,430081;2.武汉科技大学机器人与智能系统研究院,湖北 武汉,430081)
地图构建是智能机器人完成定位导航任务的第一步也是关键一步。目前,对机器人智能化和自动化程度的要求越来越高,人们希望机器人能理解周围环境所包含的几何和语义信息,但利用传统的即时定位与地图构建(simultaneous loca-lization and mapping, SLAM)方法获得的拓扑地图或栅格地图只能表达环境中的拓扑信息与几何信息[1],缺少对环境语义信息的提取与描述,导致机器人无法真正理解环境。因此,语义SLAM应运而生,其关键在于对环境中目标物体进行语义的精确标注[2]。
近些年来业内人员对语义SLAM进行了较多研究,大部分是利用SLAM方法构建环境地图,再通过传统视觉方法或者深度学习方法进行视觉特征提取从而获得环境语义信息。Tateno等[3]利用深度学习方法预测出深度信息,用以替代视觉SLAM算法中对深度的假设和估计。McCormac等[4]将SLAM与CNN网络架构相融合以获得语义地图。白云汉[5]基于视觉 SLAM 和深度神经网络,利用深度学习进行特征检测,针对机器人所处的空间构建语义地图。屈文彬[6]提出了多特征融合的智能机器人语义地图构建技术。王锋[7]借助RGB-D摄像头对室内环境进行三维重建,然后进行场景分割,建立了一种包含语义信息和抽象拓扑关系的语义地图。胡美玉等[8]提出一种基于改进DeepLab算法的图像分割方法,并利用相邻关键帧之间的空间对应关系构建三维稠密语义地图。赵洋[9]在Mask-RCNN算法结果上通过GrabCut方法优化分割效果,在此基础上构建了三维语义标注地图。常思雨[10]设计了一种基于改进GrabCut方法的目标RGB-D分割算法,该算法结合通过CPF算法分割的几何平面信息以提升GrabCut的分割效果,建立了语义八叉树地图。Kundu等[11]通过语义分割融合视觉SLAM方法建立了三维语义地图。
按传感器来分,SLAM主要包括激光SLAM和视觉SLAM两大类,上述研究多采用视觉SLAM方法实现三维语义地图的构建。视觉 SLAM 可以获取丰富的纹理信息,但其受光线影响较大,边界不够清晰,暗处纹理少,且运算负荷大[12],地图构建存在累计误差,不利于构建二维语义地图,构建二维地图选用激光SLAM更佳。激光传感器具有测量精度高、方向准、处理速度快等优点,蒋林等[13]就提出了一种利用激光实现机器人自主沿墙运动的路径规划和避障算法。
但是,利用激光SLAM构建的地图缺乏语义信息,而基于深度学习方法并结合视觉传感器感知周围环境语义信息,再利用激光SLAM技术获得包含空间尺度信息的地图,就可以得到含有几何和语义双重信息的语义地图。为此,本文提出一种包含墙角信息的语义地图构建方法,利用激光SLAM算法进行栅格地图创建,同时结合视觉传感器和深度学习模型进行目标检测识别,对环境中物体的语义信息进行提取并进行点云滤波处理,去除假语义信息,然后结合贝叶斯估计方法[14],对栅格中是否含有物体进行增量式估计,将得到的激光地图和物体语义地图进行信息融合,并将得到的语义地图进行表示。本文借助搭载有激光传感器和视觉传感器的机器人实验平台进行相关方法阐述及验证。
1 基于深度学习的物体检测识别
1.1 图像语义分割
图像语义分割是对图像中每一个像素点进行分类,从而进行区域划分。本文采用DeepLab v2语义分割算法[15]进行语义提取。DeepLab v2是一个相对成熟的结构,其基于一个深度卷积神经网络,如 VGG-16 或ResNet-101,使用双线性插值方法将特征图放大到原始图像分辨率,即上采样,然后应用全连接的CRF优化分割结果以得到更好的边缘。它在卷积过程中使用了空洞卷积,可以控制特征图的分辨率,还可以有效扩大滤波器的视野,从而在不增加参数量和计算量的情况下整合更多的图像上下文信息。
本文根据数据所处场景适中且广泛存在、数据类别和数量较为均衡的原则进行室内语义分割数据集的制作。收集了多视角、多距离、多亮度下的室内场景图片,并添加机器人实际使用场景图片,组成本文室内语义分割任务的INDOOR1数据集。考虑到语义分割数据集制作的复杂性,INDOOR1数据集的图片数量比较适当,包含门、柜子、垃圾桶、椅子、床、背景6个类别,共330张图片,其中290张用于训练,40张用于检验。
采用ImageNet数据集上预训练的VGG-16网络权重来初始化DeepLab v2网络模型的权重,在GPU模式下对INDOOR1数据集进行训练,训练过程中主要的相关配置参数为:每次批量处理的图片数量为4张;优化算法采用随机梯度下降法(SGD);基础学习率设为0.001,训练过程中动态调整学习率;学习动量设为0.9;权重衰减值设为0.0005;最大迭代次数设为50 000。训练完成后进行模型测试,结果如图1所示,可以看到DeepLab v2网络对于室内物体有良好的分割效果。

图1 DeepLab v2网络测试结果
1.2 目标检测
目前基于深度学习的物体检测识别方法主要分为两大类:一类是基于区域建议,另一类是基于回归算法。SSD网络[16]是后者的典型代表,它结合了YOLO[17]的网格化回归思想和Faster R-CNN的RPN网络中的Anchor机制[18],并加入了多尺度特征图检测,兼有检测识别准确率高和速率快的优点,因此本文选用SSD网络实现目标检测。
SSD网络模型结构如图2所示,主要分为两部分,第一部分使用去除最后一层全连接层FC8并将FC6和FC7全连接层转化为卷积层的VGG-16网络作为前端的基础特征提取网络,第二部分为后端额外新增的特征提取层,主要用于实现多尺度特征图检测。
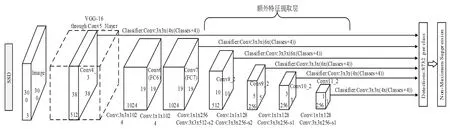
图2 SSD网络模型结构图
数据集的优劣直接决定了最终训练生成的网络模型的检测识别效果。与室内语义分割数据集的制作类似,收集了多视角、多距离、多亮度下的室内场景图片,并添加机器人实际使用场景的图片,组成了本文室内物体检测识别任务的数据集INDOOR2,一共有8840张RGB格式的室内场景图片,包含11类室内常见物体。为了进一步丰富数据集,提高模型的泛化能力,网络训练前对数据集进行颜色改变、尺度变换、随机裁剪等数据增强操作。
本文采用ImageNet数据集上预训练的网络权重初始化SSD网络模型的权重,在GPU模式下对室内物体检测数据集进行训练,测试结果如图3所示,可以看出,SSD网络模型对于室内大部分没被过分遮挡的物体都有较好的识别效果,能满足后续进行初步语义提取的要求。

图3 SSD网络测试结果
2 语义地图构建方法
研究所采用的移动机器人实验平台由本实验室自主开发和搭建。主控系统为酷睿M4I7-D迷你主机,配有ROS机器人系统,同时安装了Caffe深度学习框架用于深度学习网络模型的训练测试;激光雷达传感器选用性能稳定的SICK LMS111单线激光雷达,最大测量距离为20 m,最大扫描范围为0°~270°,最高分辨率达到0.25°,最高扫描频率可至50 Hz,根据实际要求对其性能参数进行了调整,如表1所示;深度相机选用型号为Kinect v2,结合获取的视觉信息和目标检测模型实现对室内物体的检测识别,具体参数如表2所示。

表1 SICK LMS111激光雷达性能参数

表2 Kinect v2性能参数
2.1 基于SLAM算法的栅格地图构建
具体采用Gmapping算法进行地图构建,它是基于粒子滤波算法的一种常用开源SLAM框架,将定位与建图过程分离,即先定位再建图。
构建地图要知道机器人的精确位姿,精确定位又需要构建的地图作为参考。Gmapping算法会构建一个栅格地图,对二维环境进行栅格尺度划分,并假设每一个栅格的状态是独立的。对于环境中的一个点,该点处无障碍物则为空闲状态,若该点存在障碍物则为占据状态。机器人位于建图原点时,其位置已知,根据激光传感器获取的环境特征,由机器人的坐标和朝向计算得到障碍物坐标,障碍物所处的栅格为占据状态,如图4(a)所示。再利用Bresenham直线段扫面算法得到非障碍物格点的集合,以此进行栅格占据状态更新,这样便可以更新二维栅格地图来表征机器人周围的环境,如图4(b)所示,机器人与激光击中点之间为空闲点。
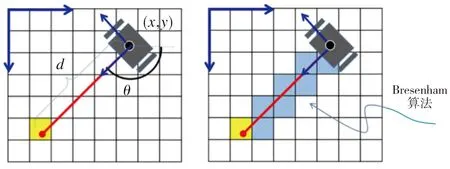
(a)机器人与障碍物 (b)Bresenham算法示意
机器人在环境中移动并不断完善地图,根据机器人获取的里程计数据和里程计运动学模型来估计机器人当前时刻位姿,每个粒子都包含机器人建图开始至当前所有时刻的位姿以及当前环境地图,然后根据激光雷达数据,利用激光雷达似然域模型进行扫描匹配,计算粒子中所包含地图与所构建地图的匹配程度,进行权重更新和重采样,更新粒子地图,得分最高的粒子的位姿即为最优位姿。当机器人移动遍历了整个环境后,类似于图5的二维栅格地图便创建完成。
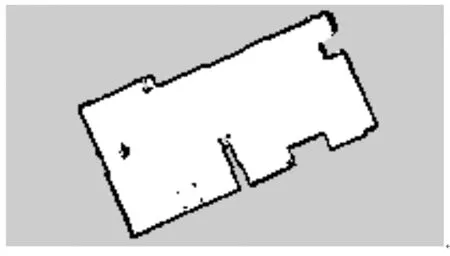
图5 二维栅格地图
2.2 语义点云生成、滤波及其坐标变换
要进行包含墙角信息的语义地图构建,可以利用提前训练好的深度学习模型进行环境物体语义初步提取。由于语义分割算法不能很好地实现类似于墙角这类物体的检测,因此采用目标检测SSD模型识别环境中的墙角,其它类型物体(门、柜子、垃圾桶、椅子等)使用语义分割DeepLab v2模型完成检测分割。
首先,操纵搭载深度相机Kinect v2和激光雷达的机器人平台(见图6)在环境中移动提取环境信息,图6中 Kinect v2深度像机坐标系为OK-XKYKZK,移动机器人坐标系为OR-XRYRZR。另外,真实世界坐标系为OW-XWYWZW,通常以机器人建立环境地图的起点为坐标原点,栅格地图坐标系为OG-XGYGZG。

图6 机器人及传感器坐标系
Kinect v2可以同时获取当前场景的RGB图,利用训练好的深度学习模型对RGB图进行检测分割,如图7所示。图7(a)为当前机器人所处场景图,图7(b)为当前视角下RGB图,图7(c)为物体的语义分割效果图,图中非黑色部分即是分割得到的物体,图7(d)为墙角的检测图,浅绿色圆圈部分代表墙角,这些就是初步提取出的物体语义信息。

(a)实验场景图 (b)RGB图

(c)语义分割图 (d)角点检测图
完成对RGB图中的物体检测后,便可以获得二维图像中物体的类别和位置信息,结合深度图信息获取实际距离信息从而实现三维信息的转换,图7中所示场景对应的深度图如图8所示。

(a)原深度图 (b)可视化深度图
得到彩色图与深度的对应关系后,Kinect v2相机坐标系下的点云(XK,YK,ZK)根据式(1)获取:
(1)
式中:u、v为RGB图像中分割出的物体的像素坐标值;d为深度图像中像素坐标为(u,v)的深度值;cx、cy、fx、fy为相机标定内参,分别为相机在两个轴上的焦距与光圈中心。
通过上述坐标转换可以得到所识别物体在相机坐标系下的3D点云坐标,接下来进行语义点云到二维栅格地图的映射。需要实现相机坐标系→机器人坐标系→世界坐标系→栅格地图坐标系的转换,才能完成三维语义信息到二维栅格地图上的映射。
考虑到训练模型的误检测以及点云语义生成的计算量,对初始3D语义点云进行部分滤除。对于如图9(a)所示环境中的椅子,利用训练模型实现分割后得到的彩色分割图9(c),由于其镂空式结构,分割图中有部分点云其实是椅子后面墙壁上的点云,若直接对所有这些点云进行下一步操作,得到的语义信息中会有较多的假语义。不作任何处理直接将这些3D点云映射到二维平面上,效果如图10(a)所示,通过映射图可以看出有些明显不属于椅子部分的点云,而且得到的物体投影显得较为杂乱,因此对于生成的点云数据进行相应的滤波处理很有必要。

(a)机器人场景图 (b)机器人视角图 (c)彩色分割效果图

(a)原映射图 (b)滤波后映射图 (c)最终映射图
考虑到深度相机Kinect v2的量程,对于过近或过远处的测量结果都会有较大出入,故这里设定只对0.55 m范围内的点云进行处理,该范围以外的点云被去除。为方便滤波处理,对于剩下的点云进行降维操作,先转换成二维点云(Z-X平面),再使用基于统计分析方法的滤波器从点云数据中去除噪声点(离群点)。滤波器原理为:计算输入点云集中的每个点到所有邻近点的平均距离,其结果符合高斯分布,然后计算出均值和方差,去除那些远离均值的二维点。对于图9中的椅子点云信息进行上述点云去除操作后,得到的该椅子点云二维映射效果,如图10(b)所示,可以看出生成的椅子语义信息更为准确。
为更好地表示所提取出的物体语义信息,从物体点云中提取距离机器人最近的一簇点云,相当于视角下物体的外轮廓点云。具体实现方法为:得到物体语义映射图后,提取出图像内每一列中离机器人最近的栅格点,保留下来进行后续的坐标系转换操作。椅子点云的最终映射效果如图10(c)所示。
在对相机坐标下的物体点云坐标滤波处理后,得到相机平面(XK-O-ZK)下物体外轮廓语义点云的映射坐标。利用训练的深度学习模型结合机器人平台感知所检测识别出的室内物体语义信息,通过一系列坐标转换,便可将其所对应的RGB图像坐标系下的坐标转换到二维栅格地图坐标系中。
2.3 基于增量式方法的物体语义栅格地图构建
物体语义栅格地图是和激光栅格地图同时开始构建的。首先创建一张正方形的空白栅格地图,以地图中心作为建图起点,把环境分成许多个大小相同的栅格单元,地图分辨率和前面Gmapping算法的地图分辨率设置一致,不同的是,构建的物体语义栅格地图只包含提取出的物体语义映射信息,其余无识别物投影的栅格被认为是栅格空闲状态。考虑到存在误差,对于在不同时刻、不同位置检测得到的同一个物体的相同部位,其在地图上的映射坐标可能会不一致,故而这里要结合栅格点的历史状态进行判定。如图11所示,视角1下物体语义映射结果比较准确,可当机器人从视角1移动到视角2后,映射结果出现交叉不重合的情况,从而导致构建的物体语义栅格地图不准确。为了尽可能减少这种误差,采用基于贝叶斯方法的增量式估计对栅格状态进行更新。

(a)当前视角RGB图 (b)映射结果图
对于栅格地图,用Q(s)表示栅格状态,它由栅格被占据概率p(s=1)和栅格空闲概率p(s=0)决定:
(2)
当接收到传感器数据后,得到一个新模型测量值z,观测值的状态只有两种(0或1),要对栅格状态Q(s|z)进行更新,由式(2)可得:
(3)
因此,观测值为z时栅格被占据和空闲的概率分别为:
(4)
根据式(3)和式(4)可得:
(5)
在式(5)左、右两边同时取对数可得:
(6)
由式(6)可以看出,状态更新后的栅格概率值仅第一项与测量值相关,第二项为更新之前的栅格状态值。对上式进行相似化处理,栅格更新前、后状态分别用Qt-1、Qt表示,模型测量值项用Δq表示,得到下式:
Qt=Δq+Qt-1
(7)
利用上述方法进行物体语义栅格地图构建时,对于初始空白地图,每个栅格对应初始状态值Q0=0,根据不同类物体的检测准确率值设置不同的状态更新增量Δq,并设定栅格阈值Dq,当最终栅格状态值大于Dq时才表明此栅格上存在物体,在构建的地图中才会更新显示该栅格被占据的状态。
在进行物体语义映射图栅格状态更新的同时,还利用Bresenham直线段扫面算法获取语义栅格点到机器人所处位置栅格点的连线经过的所有栅格点,对这些栅格点进行状态更新,全部设置为空闲状态。
建图过程中,当传感器数据更新时,即机器人位姿发生改变时,才利用上述方法对栅格状态进行更新,以避免将同一帧数据重复作为测量值进行栅格状态更新。
上述基于增量式估计的方法可以有效消除由于某些帧的误检测分割而带来的“假语义”,比如图12所示,当机器人识别周围的物体时,在某一帧中将木方块误分割成了门,若是直接将识别到的物体进行语义映射,得到的结果中就会存在不正确的语义信息,如图12(c)所示效果。结合增量式估计方法进行建图时,操作机器人在不同位置对误识别处进行多次检测,可消除误识别处栅格概率值,得到准确的物体语义,如图13所示效果。

(a)RGB图 (b)物体检测分割图 (c)结果映射图

(a)RGB图 (b)物体检测分割图 (c)结果映射图
在明确了每一帧图像数据中扫描到的栅格点及其状态后,根据移动机器人不同时刻的位姿状态和传感器信息重复获取以上数据,同时根据贝叶斯估计原理更新栅格地图坐标系中每一个栅格单元状态,完成机器人使用环境的遍历后,根据每个栅格最终的物体概率值是否大于所设定阈值来判断该栅格中是否存在某一类物体,进行室内物体语义栅格地图的创建。
利用Gmapping算法得到二维环境栅格地图,基于深度学习和增量式估计方法构建物体语义栅格地图,将两张地图进行信息融合,便可得到室内环境的二维语义栅格地图,完整的地图构建流程如图14所示。
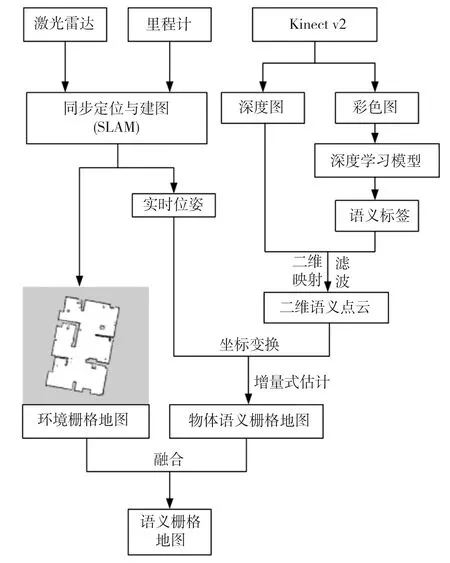
图14 语义栅格地图的构建流程
3 实验与结果分析
为了验证所提出的语义栅格地图构建方法的有效性,下面借助机器人实验平台在实际室内环境下进行操作。在实验室中摆放方形障碍物模拟室内环境,并放置柜子、垃圾桶、椅子等物体,如图15所示。

图15 实验环境
首先控制机器人在实验场景内移动,利用Gmapping算法进行环境栅格地图创建,同时通过机器人搭载的Kinect v2结合深度学习模型对场景内环境进行感知和提取物体语义,并基于增量式方法进行物体语义栅格地图创建,直至机器人遍历完整个环境。
建立的激光栅格地图见图16(a),在语义地图中,非黑色部分表示为物体,不同颜色的投影部分代表不同类型的物体,如图16(b)所示。图17为该实验环境对应的语义地图。在得到的初始墙角语义地图中,墙角投影点比较杂乱,需要通过图像形态学操作对地图进行联通区域分析,去除一些细小的孤立点区域,连接靠近主体部分的孤立点,提取各部分中心点,以其为圆心绘制一定大小的实心圆代替角点,得到如图17(b)所示优化后的墙角语义图。
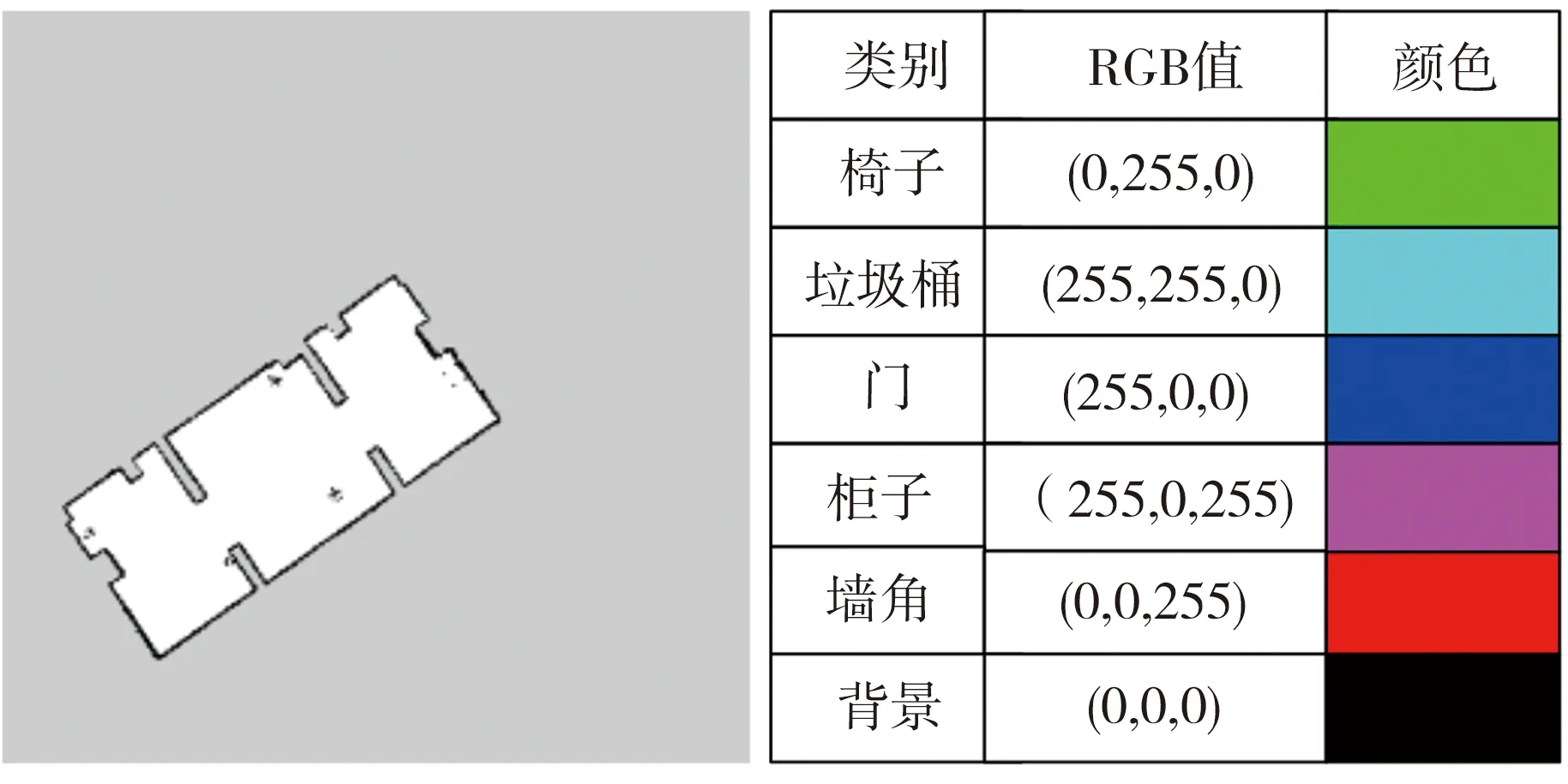
(a)激光栅格地图 (b)语义地图颜色对应说明

(a)物体语义图 (b)墙角语义图
如图18所示,将激光地图和物体语义地图进行融合可得到合成语义地图,由于物体栅格地图和环境栅格地图是同步构建的,二者栅格分辨率相同,因此生成的两幅地图中相同物体间的尺寸是一样的,它们的方向也一致,只需两幅地图姿态对齐,合并过程就可方便进行了。具体过程如下:首先利用基于Gmapping算法建立的环境栅格地图文件,获取地图中心(建图原点)的位置;生成的物体栅格地图为图片格式,它的中心即为图片中心;将环境栅格地图中心与物体栅格地图的中心对齐,保持方向不变,然后进行地图合成,实质上是对图片进行操作,可以使用OpenCV软件作为工具遍历读取物体栅格地图的非黑色区域(即目标物),将该区域的颜色加入到环境栅格地图对应的位置中,期间两幅图的中心和姿态要保持一致,遍历完物体栅格地图中所有像素点后,环境栅格地图中的颜色区域也添加完毕,最后生成的环境栅格地图即为合成的语义栅格地图(图18(b))。为了更好地表达出环境中的高层次语义信息,要对构建的语义图进行优化,使用不同形状的彩色块代替环境中某一区域内的不同物体,得到如图18(c)所示结果,具体实现过程如下。
在所合成的语义地图(图18(b))中,不同颜色的标记代表不同类别的物体,首先对其进行图像形态学处理:通过腐蚀操作去除地图中每个物体映射的离散投影点;通过膨胀操作连接断点,得到较完整的物体投影;对地图进行灰度化处理或二值化处理,利用图像库函数查找出图中每一条连续标记线的轮廓,再绘制每个轮廓的最小包围矩形或圆形,矩形、圆形的中心即作为该物体的投影中心。本文使用最小包围矩形代替柜子、门,最小包围圆形代替垃圾桶、椅子、墙角。对合成的语义地图中每一个物体提取中心位置,将它们在地图中的坐标存储到相应的描述文件中,与构建的语义地图一起保存,以便后续利用其实现语义图中物体位置的查询,完成更高层次的定位导航任务。由合成语义地图可以看出,物体与栅格地图中的对应障碍物基本重合,物体位置表达准确,能正确反映环境语义信息,至此包含墙角信息的二维语义栅格地图创建完成。
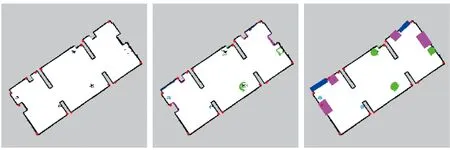
(a)环境中墙角语义图 (b)包含语义的栅格图 (c)优化语义地图
4 结语
本文提出了一种包含墙角信息的语义地图构建方法。首先利用激光SLAM算法进行栅格地图创建,得到环境中空间尺度信息,同时获得机器人在建图过程中的实时位姿;利用语义分割和目标检测数据集训练模型,再对图像中的目标进行检测分割,识别墙角并提取语义,得到相应的像素标签;将带有标签的各像素点利用已标定好的Kinect v2相机参数转换到相机坐标系下,对3D点云进行高斯滤波,去除明显孤立点云,得到最终的物体3D语义信息;结合建图时获取的机器人实时位姿,对3D语义信息完成世界坐标系下的二维映射;通过基于贝叶斯估计的增量式方法对栅格点状态进行更新,融合语义信息和环境栅格地图,并将得到的语义地图表示出来。最后借助于搭载LMS111激光雷达和Kinect v2相机的机器人实验平台验证了该构建方法的有效性。
猜你喜欢
科技创新与应用(2021年31期)2021-11-09 13:11:18
开放教育研究(2020年2期)2020-03-31 01:54:14
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
现代语文(2016年21期)2016-05-25 13:13:44
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
弹箭与制导学报(2015年1期)2015-03-11 15:32:23
大连民族大学学报(2015年2期)2015-02-27 08:28:11
雷达学报(2014年4期)2014-04-23 07:43:13
哈尔滨工程大学学报(2013年5期)2013-06-05 09:00:36
