
基于云遗传算法优化BP神经网络的轨道客流预测
2021-08-20 09:03:12唐秋生
桂林理工大学学报 2021年2期
唐秋生, 王 川
(重庆交通大学 交通运输学院, 重庆 400041)
0 引 言
目前, 单一的神经网络预测模型不能满足客流预测的需求。需要优化神经网络模型以提升预测算法的准确性[1]。 董升伟以北京市城市轨道交通4号线的历史客流数据作为历史数据库, 将城市道路交通客流预测方法应用到城市轨道交通的客流预测中, 利用前馈(back propagation, BP)神经网络的一些特点并结合聚类分析和相关性分析, 对城市轨道交通的客流预测进行分析, 仿真结果表明该方法提升了客流预测的精度[2]; 邹巍等对于城市轨道交通客流变化具有的非线性和不确定性进行研究, 将遗传算法和小波分析相结合, 建立了一种全局搜索最优的组合神经网络预测模型, 解决了选择神经网络预测时容易造成过拟合的问题, 仿真结果表明, 该算法的预测结果比单一的神经网络更加接近于真实值[3]; 毛静针对支持向量机算法的单一核函数的一些缺点进行改进, 将支持向量机算法的核函数从一维改进成多维, 由于径向基函数(radial basis function, RBF)神经网络与支持向量机算法在单项预测法上的诸多优点, 将两种算法进行组合形成组合预测模型, 并以清明假期的客流数据进行仿真分析, 得出组合预测模型优于单一预测模型的结论[4]; 李少伟等将卡尔曼滤波算法和Elman神经网络进行组合, 先用混合神经网络进行客流的初步预测, 然后使用卡尔曼滤波算法对初步预测的结果进行校准, 从而得到最后的预测结果, 对上海轨道交通客流数据进行仿真[5], 该算法比单一的混合神经网络预测算法的预测精度提升了0.8%; 刘韵[6]将免疫粒子群算法(immune particle swarm optimization, IPSO)引入神经网络, 同时引入生物免疫中的浓度选择机制, 在保证粒子多样性的同时, 确保粒子群快速收敛, 然后将优化处理后的权值带入神经网络模型结构中, 提高模型的运算速度与精度; 齐璐[7]利用狼群算法对小波神经网络进行优化, 在预测前使用狼群算法计算小波神经网络的最优权值和小波因子, 据此构建小波神经网络模型, 随后对历史误差值进行预测与结果相加, 结果表明, 该模型提高了小波神经网络的预测精度;卢献健等[8]将遗传算法(GA)和粒子群算法(PSO)的寻优过程进行融合, 利用GA的全局性和PSO收敛速度快的特点, 通过迭代选取最优的粒子作为BP神经网络的连接权值和阈值, 以减小网络输出误差, 提高其收敛速度和加强网络泛化能力; 刘林波等[9]利用影响雾霾的主要因素作为预报因子, 采用遗传算法优化后的BP(GA-BP)神经网络建立了PM2.5质量浓度预测模型, 并对其进行可靠性分析。
综上, 现有研究主要集中在优化神经网络结构与其他算法进行结合, 通过算法互补来提高神经网络模型的预测精度。本文根据云模型及遗传算法自身的特点, 提出一种基于云遗传算法优化BP神经网络的客流预测模型, 应用重庆轨道交通3号线客流数据及Matlab编程工具, 对3号线的交通流量进行预测, 并与传统BP神经网络与遗传算法优化BP神经网络的预测结果进行比较。
1 理论模型
1.1 云理论
1995年, 中国工程院院士李德毅提出了云模型的概念, 云模型是处理定性概念与定量描述的不确定转换模型[10]。定义如下: 设T为论域u上的语言值, 映射CT(x):u→[0, 1], ∀x∈u,x→CT(x), 则CT(x)在u上的分布称为T的隶属云, 简称“云”, 当CT(x)服从正态分布时, 简称正态云模型[11]。如图1所示。
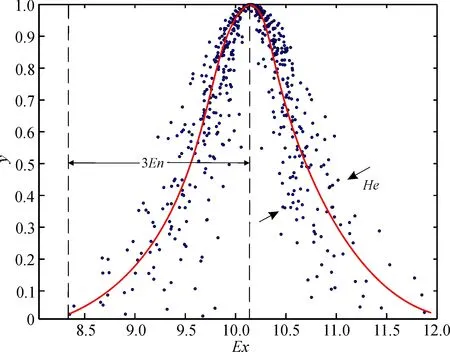
图1 正态云分布
云的数字特征用期望Ex、 熵En、 超熵He3个数值来表示。期望Ex(expected value): 云滴在论域空间的分布期望, 就是最能代表定性概念的点, 也是这个概念量化的最典型样本[11]。熵En(entropy): 定性概念的不确定性度量, 由概念的随机性和模糊性共同决定[11]。超熵He(hyper entropy): 是熵的不确定性度量, 即熵的熵, 由熵的随机性和模糊性共同决定[11]。
云发生器[12]是从定性概念到定量表示的过程, 也就是由云的数字特征产生云滴的具体实现, 包括正向及逆向正态云发生器以及X条件发生器和Y条件发生器。
1.2 云遗传算法
遗传算法(GA)是借鉴生物进化中“适者生存”自然规律的特征, 随机产生可行性解, 并通过一定的机制进行选择、 交叉和变异操作产生最优解或近似最优解的随机优化算法。标准遗传算法(SGA)在交叉和变异操作算子中采用确定性的固定概率进行, 算法存在未进化至最优解时已经收敛或者收敛的速度太慢, 使算法的实际应用性不强。
云遗传算法结合遗传算法思想, 沿用传统遗传算法的交叉、 变异操作概念, 由正态云模型的X条件云生成算法生成迭代过程中的交叉概率Pc和变异概率Pm。正态云模型具有随机性和稳定倾向性的特点, 随机性可以保持个体多样性从而避免搜索陷入局部极值, 而稳定倾向性又可以很好地保护较优个体从而对全局最值进行自适应定位, 从而满足快速寻优的能力, 并根据其随机性能避免陷入局部最优。生成遗传算法的交叉概率、 变异概率具体算法如下所示。
1)Pc的生成算法

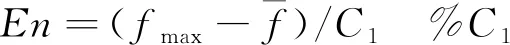

Enn=normrnd(En,He);
2)Pm的生成算法
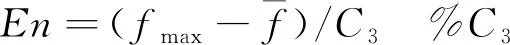

Enn=normrnd(En,He)
其中,f′为交叉操作中较大的适应值;f为变异操作中父代染色体的适应度值;k1、k2、k3、k4为[0, 1]内的常数。在云遗传算法中可取初始C1=C3=6Q(Q为初始种群的大小), 并且随进化代数逐渐增大, 在此设置C1=C3=6Q(T+1),其中T为进化代数[13]。为了算法运行初期扩大搜索空间, 运行后期提高搜索精度,He可以先大后小的设置[13], 如C2=C4=15-(T-Q/2)2。
2 基于云遗传算法的BP神经网络
2.1 基本思想
BP神经网络有很多固有缺陷, 如结构难确定、 初始权值选择的盲目性导致训练速度慢、 容易陷入局部最优等。遗传算法是基于自然选择和遗传学机理的迭代自适应概率搜索算法, 经云模型优化后的遗传算法具有全局寻优、 快速收敛等优点, 利用云遗传算法的这些特性, 可以解决神经网络的上述缺点, 有益于交通量预测准确性的提高。
本文将云遗传算法和BP神经网络结合起来, 提出基于云遗传算法的BP神经网络模型, 基本思想是由云模型的X条件云发生器生成遗传算法中的交叉概率和变异概率, 利用改进后的遗传算法对BP神经网络的初始权值和阈值进行优化。云遗传算法优化得到的最优个体, 即BP神经网络的最优初始权值、 阈值。利用得到的最优初始权值、 阈值和历史数据来训练BP神经网络预测模型以求得最优解。算法流程如图2所示。

图2 算法流程图
2.2 算法设计
算法的基本步骤如下:
(1)参数初始化。首先, 初始化遗传算法参数, 包括初始种群大小Q、 最大进化代数G等; 其次, 云模型控制系数初始化,C1=C3=6Q(T+1),C2=C4=15-(T-Q/2)2; 最后, 确定神经网络的结构, 包括输入输出及隐含层节点数、 学习率、 权值wi和阈值bi初始化等。
(2)编码。本文采用实数编码方式对神经网络的初始权值和阈值进行编码, 将wi和bi统一编码到每个个体当中, 每个个体就代表一组神经网络初始权值和阈值。
(3)产生初始种群。按照编码方式, 随机产生大小为Q的初始种群。
(4)计算适应度。本文选用平均绝对误差作为适应度函数
其中:Ei为第i个体的均方误差;n为训练样本总数;ti为第i个体的预测值;yi为第i个体的实际输出值。
(5)选择、 交叉、 变异。①选择: 轮盘赌选择个体。②交叉: 利用X条件云发生器生成交叉概率, 如果父代中较大的适应度值大于种群的平均适应度值, 那么根据云模型生成的交叉率进行交叉操作; 否则, 按照固定交叉率进行交叉。交叉方式为两染色体对应基因段交叉。③变异: 利用X条件云发生器生成变异概率, 如果该染色体的适应度值大于种群的平均适应度值, 那么根据云模型生成的变异率进行变异操作; 否则, 按照固定变异率进行变异。变异方式是染色体某基因点变异。
(6)判断是否满足要求。判断交叉变异后的个体是否达到要求(最大进化代数Q或适应度值在允许的误差范围内)。如果满足要求, 则输出最优个体, 再解码得到BP神经网络的最优初始权值和阈值; 否则, 重新回到步骤(4), 直到满足条件为止。
3 算例分析
采用BP神经网络预测模型(BP)、 遗传算法优化BP神经网络预测模型(GA-BP)、 云遗传算法优化BP神经网络预测模型(CGA-BP)3种预测方法对重庆市轨道交通3号线的客流进行预测。 先对数据进行归一化处理, 将数据处理到[0, 1], 再将其中80%的数据用于训练, 10%的数据用于验证, 剩下10%的数据用于测试。实验误差评价采用平均绝对误差MAE和均方误差MSE。
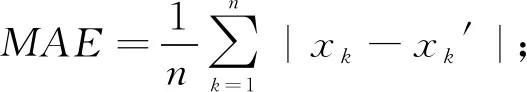
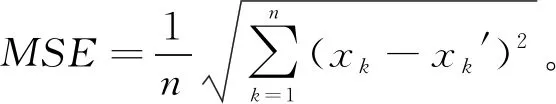
其中:n为交通流数据个数;xk为交通流真实数据;xk′ 为交通流预测数据。
3.1 参数分析确定
3.1.1 BP神经网络参数的确定 本文设计只有1个隐含层的BP神经网络预测模型, 神经网络的输入为预测天前一天、 预测天和上一周与预测天同星期的日客流量3个输入向量, 输出向量为预测天的日客流量。例如, 预测天为第10周星期四, 则输入变量为: 第10周星期三、 星期四、 第9周星期四日客流量。隐含层节点数目h选择根据经验公式来确定
其中:m和n分别是输入层和输出层节点的数目,a为[1, 10]内的调节常数。根据上述公式得到隐含层节点范围为[3, 12], 将学习率定为0.1, 设定训练次数上限为1 000次, 目标误差为0.001, 隐含层激活函数采用tansig, 输出层激活函数采用logsig。比较几种网络的训练时间和误差, 相关数据见表1。

表1 节点数、训练时间与准确率统计
可知, 随着隐含层节点的增加, 训练时间会逐渐增加, 准确率大致呈现一个先升后降的趋势, 所以本文选取隐含层节点数为6, 其准确率最高, 而且训练时间适中。
3.1.2 GA-BP神经网络参数的确定 GA-BP神经网络是在上述BP神经网络模型的基础上采用遗传算法(GA)对BP神经网络权值阈值的优化。在遗传算法部分, 编码方式为实数编码, 种群规模为10, 最大进化代数为10, 交叉率为0.3, 变异率为0.5。
3.1.3 CGA-BP神经网络参数的确定 在传统遗传算法中, 交叉率、 变异率为一固定值, 算法搜索速度慢, 容易早熟, 为了克服这一问题, 本文在GA-BP的基础上用云模型的X条件云发生器生成交叉率和变异率, 具体见1.2节Pc、Pm的生成算法。在CGA-BP模型中, 当该染色体的适应度小于平均适应度时, 交叉率和变异率为一固定值, 根据上述对遗传算法固定交叉率和变异率的设置, 令k3=0.3、k4=0.5,k1和k2为0~1间的常数, 图3为k1、k2不同取值对模型准确率的影响, 其中不同颜色表示k1的取值。
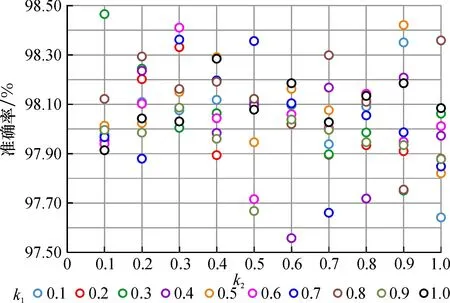
图3 k1、 k2对准确率的影响
模型准确率在97.5%~98.5%。k1、k2取值对模型的准确率有较大影响: 当k1=0.4、k2=0.6时, 模型准确率最低为97.56%; 当k1=0.3、k2=0.1时, 模型的准确率最大为98.47%, 两者准确率相差0.91%。故本文设定k1=0.3,k2=0.1。
3.2 模型对比
根据上述对3个模型相关参数的分析, 可得各模型参数如表2所示。
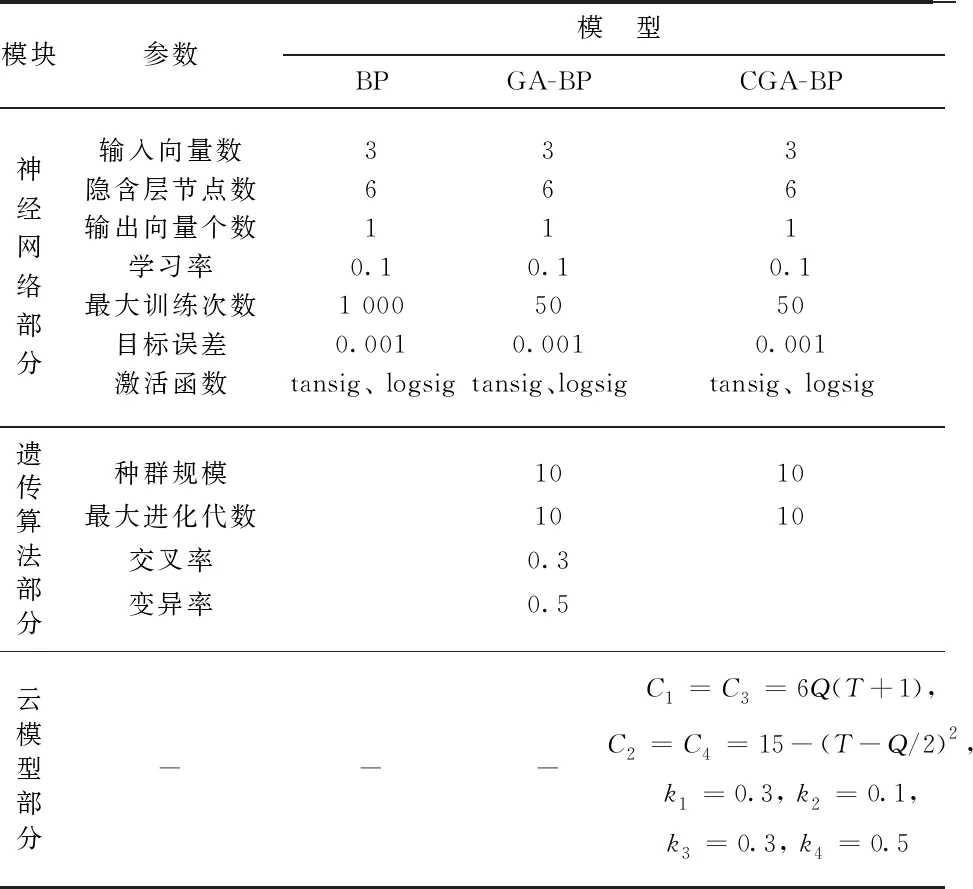
表2 3个模型参数设置
应用重庆轨道交通3号线的客流数据对3个模型进行训练, 将训练好的模型用来预测重庆轨道交通2019年3月1—10日的客流, 其真实值与各模型的预测值如图4所示。 可知, BP神经网络模型的拟合能力较差, GA-BP神经网络能够比较准确地拟合数据, CGA-BP神经网络能够准确地反映出历史数据的走向, 预测精度更高。
3个模型的平均绝对误差(MAE)、 均方误差(MSE)、 计算时间和准确率见表3。可知, GA-BP和CGA-BP的准确率较BP来说都有较大提高, 但是BP运行时间最短; CGA-BP的准确率在GA-BP的基础上提高了1.9%, 同时运行时间减少了40%。两者适应度曲线如图5所示, 经云模型优化后的遗传算法搜索速度及适应度值下降速度加快、 种群最佳平均适应度和终止进化代数减少。
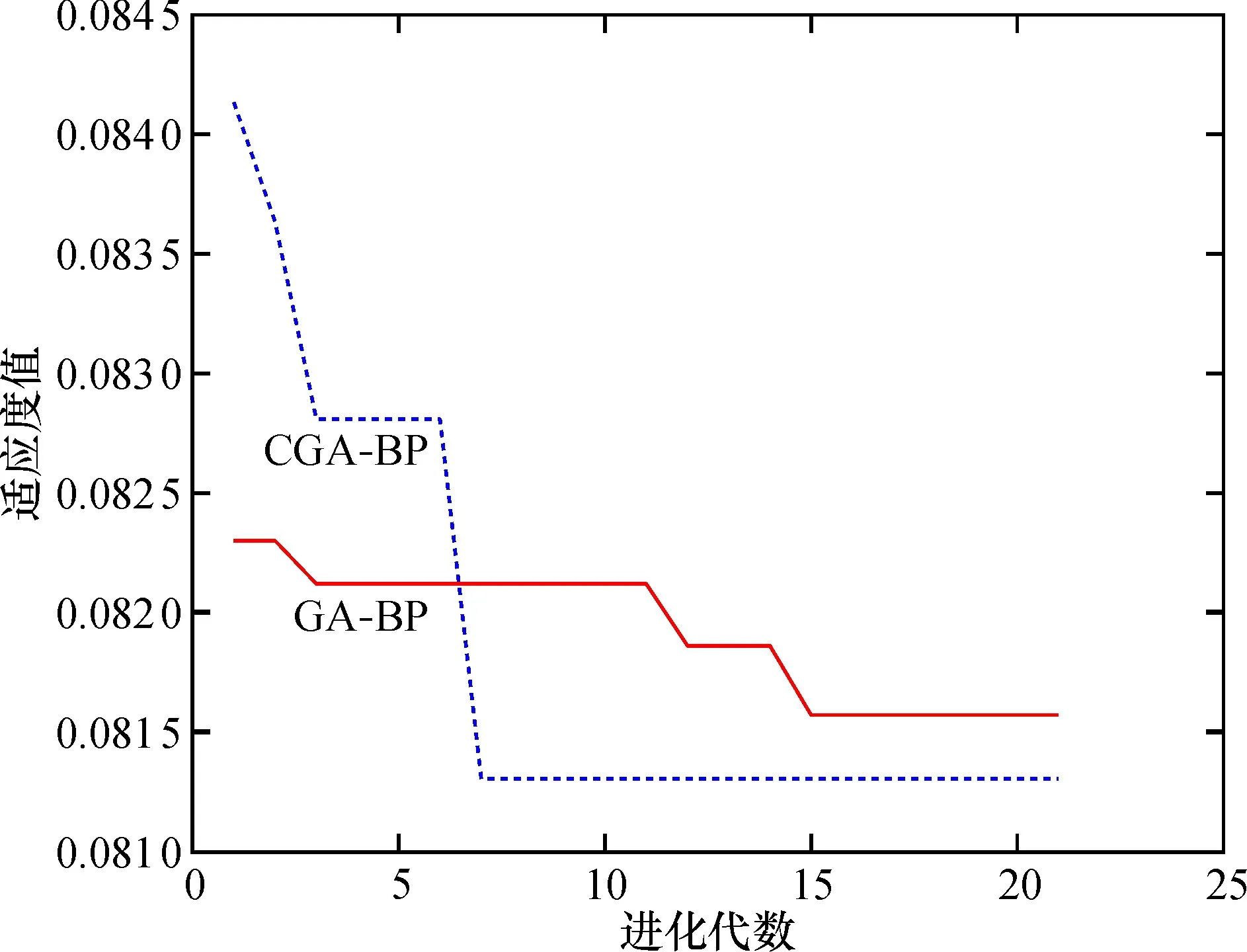
图5 GA-BP、 CGA-BP适应度曲线
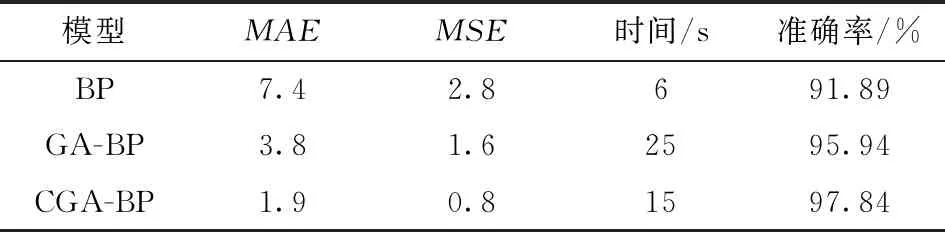
表3 不同模型评价
云遗传算法优化后的BP神经网络和遗传算法优化的BP神经网络训练误差变化如图6所示。虽然在训练误差上都没有达到目标误差, 但CGA-BP比GA-BP的最佳训练误差更小, 在一定程度上提高了算法的准确度。
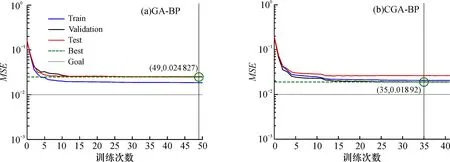
图6 GA-BP(a)、 CGA-BP(b)训练误差
综上, 3种模型求解结果均与真实值存在误差, 但是云遗传算法优化BP神经网络(CGA-BP)比遗传算法优化BP神经网络(GA-BP)和BP神经网络的预测精度都高, 这得益于云自适应遗传算法中动态改变的交叉变异率, 使算法的初期能够比较快地产生优秀个体, 算法的后期保护最优个体, 全局搜索能力增强。与GA-BP相比, 在提升精度的同时也减少了运行时间。
实验表明: 本文设计的基于云遗传算法优化BP神经网络在全局搜索和收敛方面优于传统BP神经网络和遗传算法优化BP神经网络, 能够保证轨道交通客流的预测精度。
4 结束语
针对云模型、 遗传算法和BP神经网络的的特点, 将三者结合起来建立云遗传算法优化BP神经网络的轨道客流预测模型。该模型既利用了云遗传算法能并行计算且能快速、 全局搜索的优点, 解决了神经网络固有的搜索速度慢且易陷入局部早熟的缺点, 又利用了神经网络描述问题能力强、 对不完全信息具有良好的适应性的优点, 弥补了遗传算法编码困难的缺点。将此方法用于重庆市轨道交通3号线的日客流量预测, 与相同条件下的BP神经网络模型、 遗传算法优化BP神经网络模型的预测结果进行对比发现, 基于云遗传算法优化BP神经网络的客流预测模型在预测精度上比BP神经网络预测模型和遗传算法优化BP神经网络模型都更具优势, 说明本文设计的预测方法是可行的。
猜你喜欢
环球时报(2022-12-12)2022-12-12 17:14:03
计算机仿真(2022年8期)2022-09-28 09:53:02
初中生世界·八年级(2019年6期)2019-08-13 18:41:18
小学生导刊(低年级)(2016年6期)2016-07-02 22:17:33
中国塑料(2016年11期)2016-04-16 05:26:02
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:37
计算机工程(2015年8期)2015-07-03 12:19:54
中央民族大学学报(自然科学版)(2015年2期)2015-06-09 08:45:20
振动、测试与诊断(2014年6期)2014-03-01 01:14:47
都市快轨交通(2014年4期)2014-02-27 08:35:03
