
基于改进蚁群求解特征子集的入侵检测方法
2021-07-16 08:03梁本来
计算机应用与软件 2021年7期
梁本来 朱 磊
1(中山职业技术学院信息工程学院 广东 中山 528404) 2(西安理工大学计算机科学与工程学院 陕西 西安 710048)
0 引 言
网络流量的激增,对入侵检测系统(Intrusion Detection System,IDS)的性能提出了更高的要求[1],为解决这一问题,机器学习在IDS的应用研究是当今的一个趋势[2]。网络流量包含大量的特征信息,其中包含与检测目标关联度较低的特征,以及与其他特征相关性较高的特征,这两类特征可以统称为冗余特征[3]。冗余特征过多,会导致IDS检测算法的时空复杂度增加,降低IDS的检测性能。因此,在原始的特征点中筛选出最优特征子集,保留数据中贡献度较大的特征,去掉一些冗余特征甚至噪声特征[4],以提高IDS分类器性能,是当今IDS领域的一个研究热点和难点[5]。
随机搜索算法及启发搜索算法是目前选择网络特征子集的两大方法,其中随机搜索算法采用穷举法,策略简单,但计算机量大,对于海量数据的处理效率过低,难以满足IDS的实时性要求[6]。启发式搜索速度快,目前的研究文献主要集中在蚁群算法(Ant Colony Optimization,ACO)、粒子群算法(Particle Swarm Optimization,PSO)等生物智能算法。Mehdi等[7]提出了利用ACO求解特征子集的方法,较为完整地介绍了ACO在特征向量图中搜索特征子集的过程。但该方法并未对ACO进行改进,容易陷入局部最优且不稳定。王峰[8]提供了改进传统ACO的思路,引入同数量级参数优化转移概率,设置优先级优化信息素挥发系数。但该文献对网络流量特征分析较少,没有描述特征拓扑的构建过程,对蚂蚁的起始位置和搜索过程介绍较为笼统,实验数据样本的构造也较为简单。肖国荣[9]提出一种改进ACO和支持向量机(SVM)网络入侵检测方法ACO-SVM,采用动态随机抽取的方法来确定目标个体引导蚂蚁进行全局搜索,优化SVM模型参数。但该算法重在SVM分类器参数的确定,并未求解网络特征子集。朱丽[10]提出了一种基于蚁群分类规则挖掘算法的网络入侵检测方法(ADM-ACCRMA),用改进ACO挖掘网络攻击的分类规则,再对网络流量进行分类规则的检测,提供了一个较好的IDS检测思路。但该文献对于网络流量的分类较为笼统,实验较为理想化,实际上网络流量特征复杂,分类规则的设计是一个难点。袁琴琴等[11]提出一种基于改进ACO和遗传算法(Genetic Algorithm,GA)组合的网络入侵检测方法IACO-GA,采用遗传算法对网络入侵的特征进行快速选取,再利用改进ACO选取特征子集。混合算法为求解特征子集提供了比较好的思路,但该文献并未对改进ACO及GA的关键参数做具体分析,事实上算法参数对IDS分类器性能的影响很大,如何确定算法参数是研究难点。Nguyen等[12]提出了利用遗传算子优化PSO的特征选择方法(CMPSO),利用遗传算子提高PSO的搜索性能,但因遗传算子中交叉、变异概率是固定的,容易陷入局部最优。张震等[13]提出改进粒子群联合禁忌搜索的特征选择算法IPSO-TS,采用遗传算子求得特征选择初始最优解,然后进行禁忌搜索得到特征子集全局优化解,思路较好,但该方法采用KNN作为分类器,KNN不能处理特征维度太高的数据,另外该方法的复杂度较高,导致求解特征子集的时间较长。
综合分析以上文献的优缺点,本文提出一种基于改进ACO求解特征子集的入侵检测方法(IDM-FS-IACO),该方法可以在初步提取的特征点中进一步求解特征子集,并在训练阶段优化改进ACO及SVM的参数。实验证明,相比其他方法,IDM-FS-IACO的F-Measure值有一定提升,测试时间显著减少。
1 IDM-FS-IACO思路
(1) 对KDD CUP 99数据集特征属性做预处理,通过信息熵理论求得初步提取的特征点,并构造特征拓扑。
(2) 由改进ACO进一步求解特征子集。在改进ACO中,蚂蚁的初始位置、启发函数、信息素更新策略及状态转移概率函数均做了优化。
(3) 采用KDD CUP 99数据集[14],通过十折交叉验证法训练及优化改进ACO及SVM的参数,并测试该入侵检测方法的性能。
IDM-FS-IACO方法的流程如图1所示。
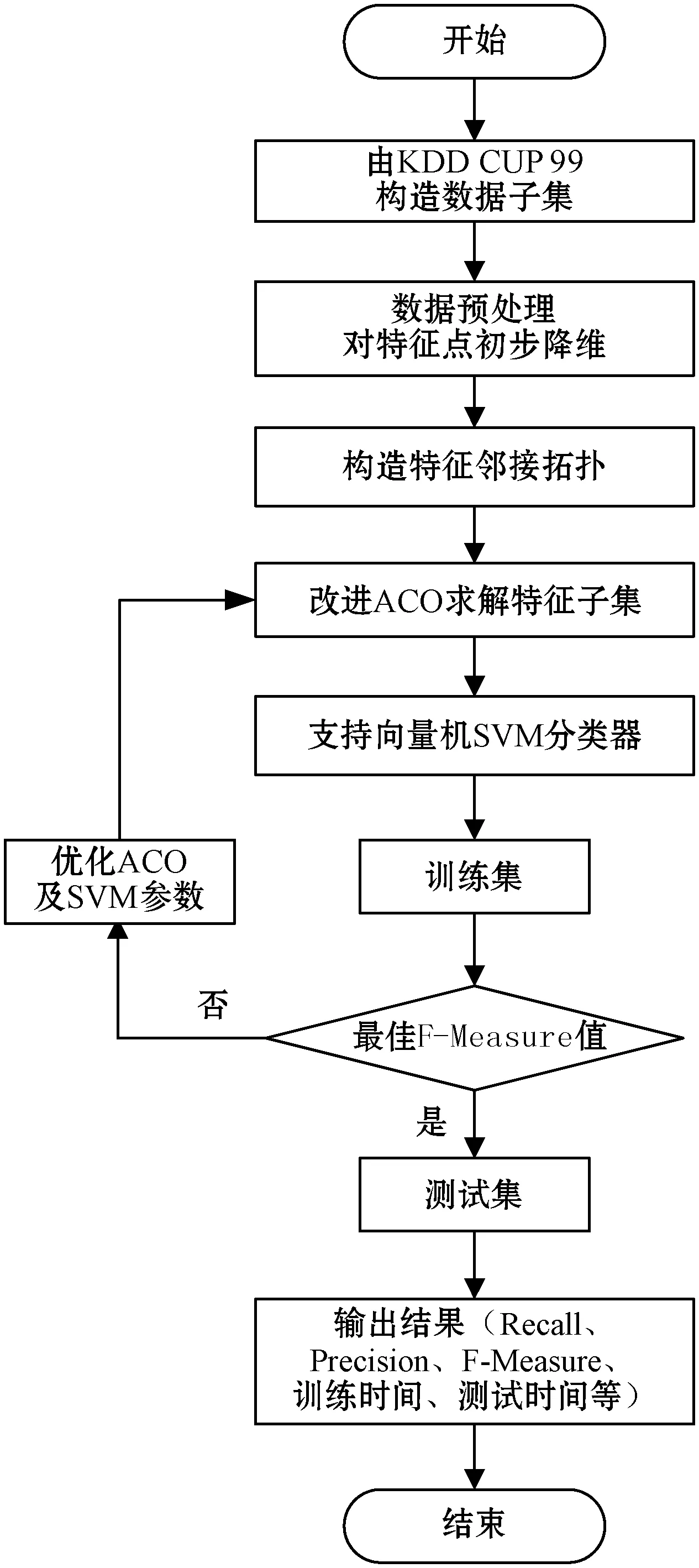
图1 IDM-FS-IACO流程
2 数据预处理及构造特征拓扑
2.1 构造数据子集
采用KDD CUP 99的10%,按照原始比例分别选出四类入侵样本和正常样本,混合构成四个数据子集:DoS+Normal,Probe+Normal,U2R+Normal,R2L+Normal,再分别将这些数据集十等分,十等分后各数据子集的样本类别及平均数量如表1所示。

表1 各数据子集的样本类别及平均数量
2.2 数据归一化处理
不同特征属性的取值范围差异较大,对数据分析结果有较明显的影响,因此应先进行数据的归一化处理,具体公式如下:
(1)
式中:x′i表示归一化后的特征值;xi表示原始特征值;max(xi)和min(xi)分别为该特征属性的最大取值和最小取值。归一化处理后,所有的特征属性取值范围为[0,1]。
2.3 数据离散化
因KDD CUP 99数据集中,既有离散化数据,也有连续型数据,因此采用信息熵的离散化方法,将连续型数据进行离散化。
假设I为一个连续实数区间,L(I)为该区间长度,A为该区间内所有的样本集合,|A|为集合A的样本总数,D(I)为集合A在区间B上的密度,公式如下:
(2)
假设特征F在区间A上所有的取值升序排列后为f1,f2,…,fn,则有如下分割点bi:
(3)
以分割点bi为例,可以将集合A划分为两个子集A1i和A2i,对应的两个子区间为I1i和I2i。
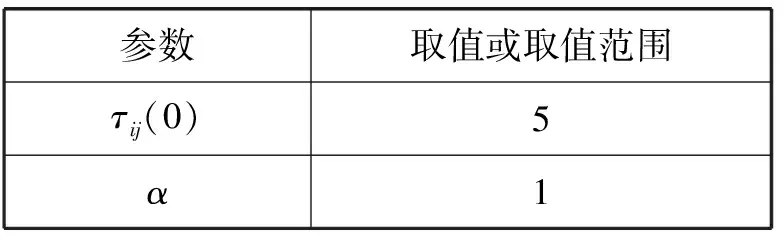
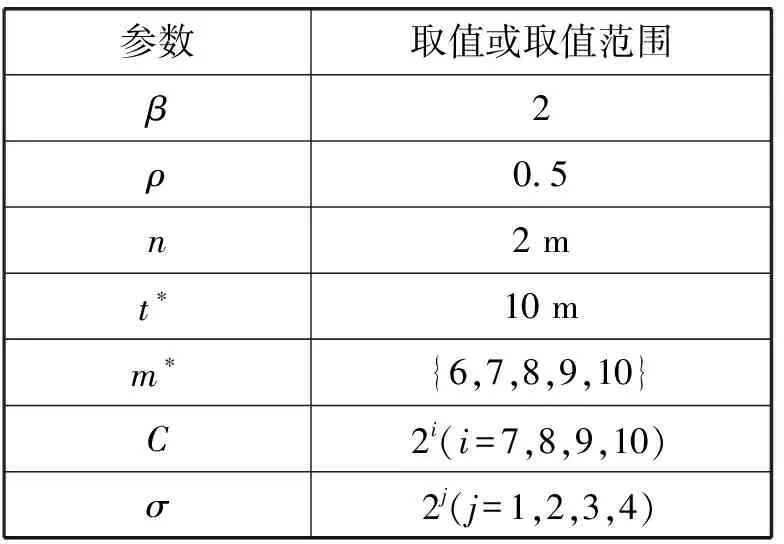
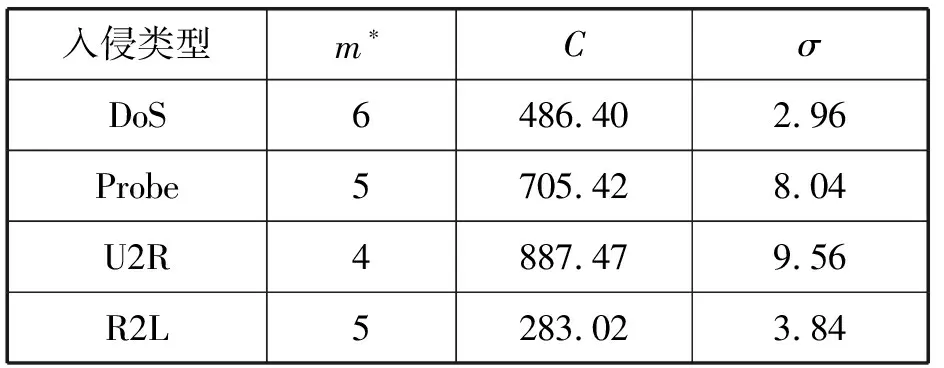
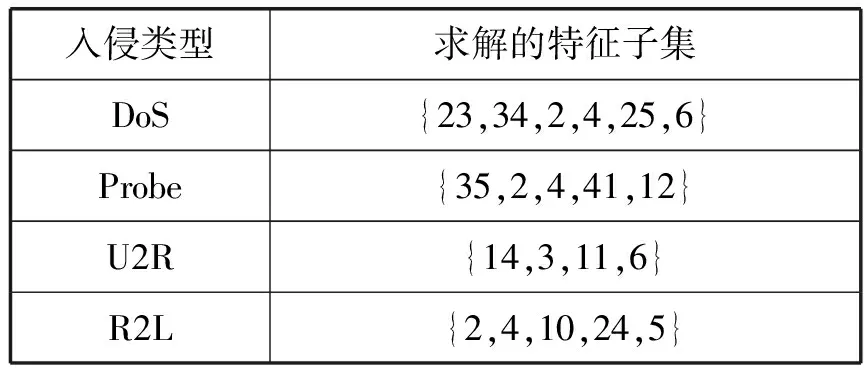
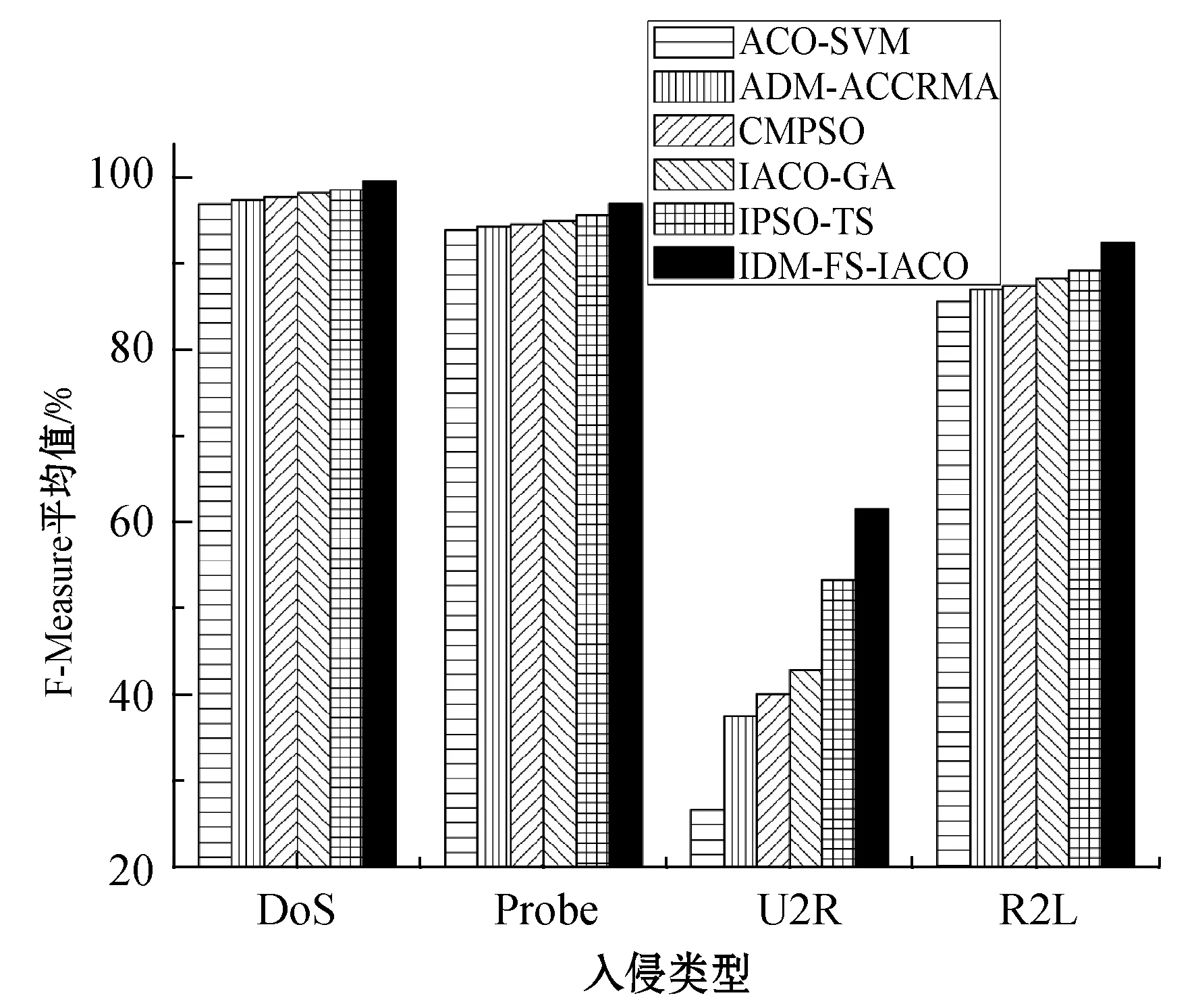
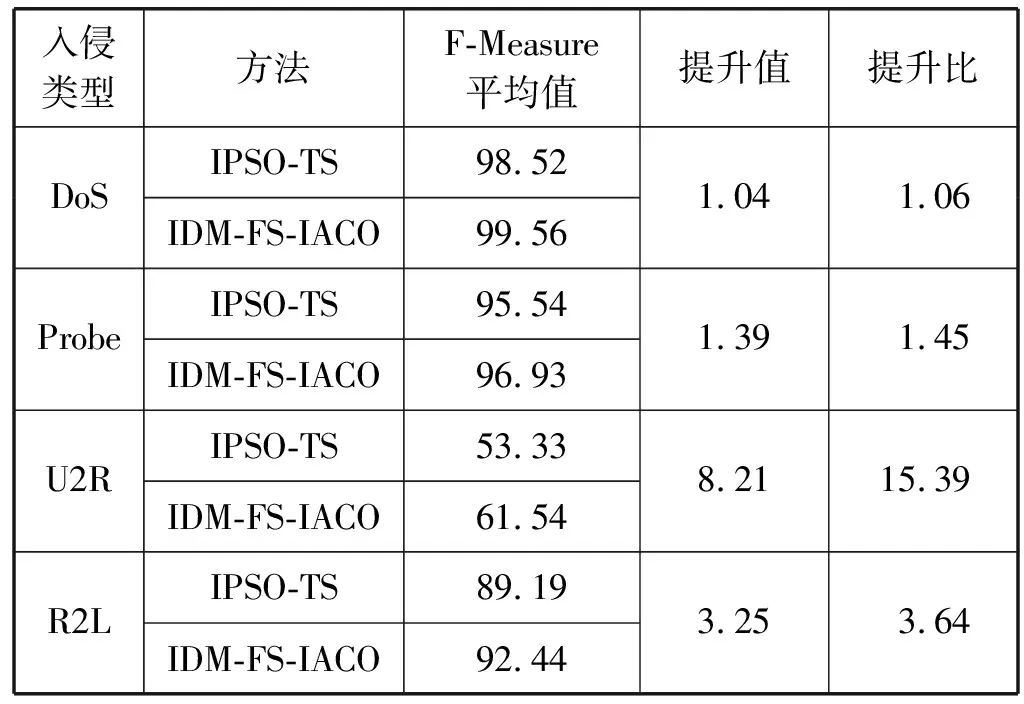
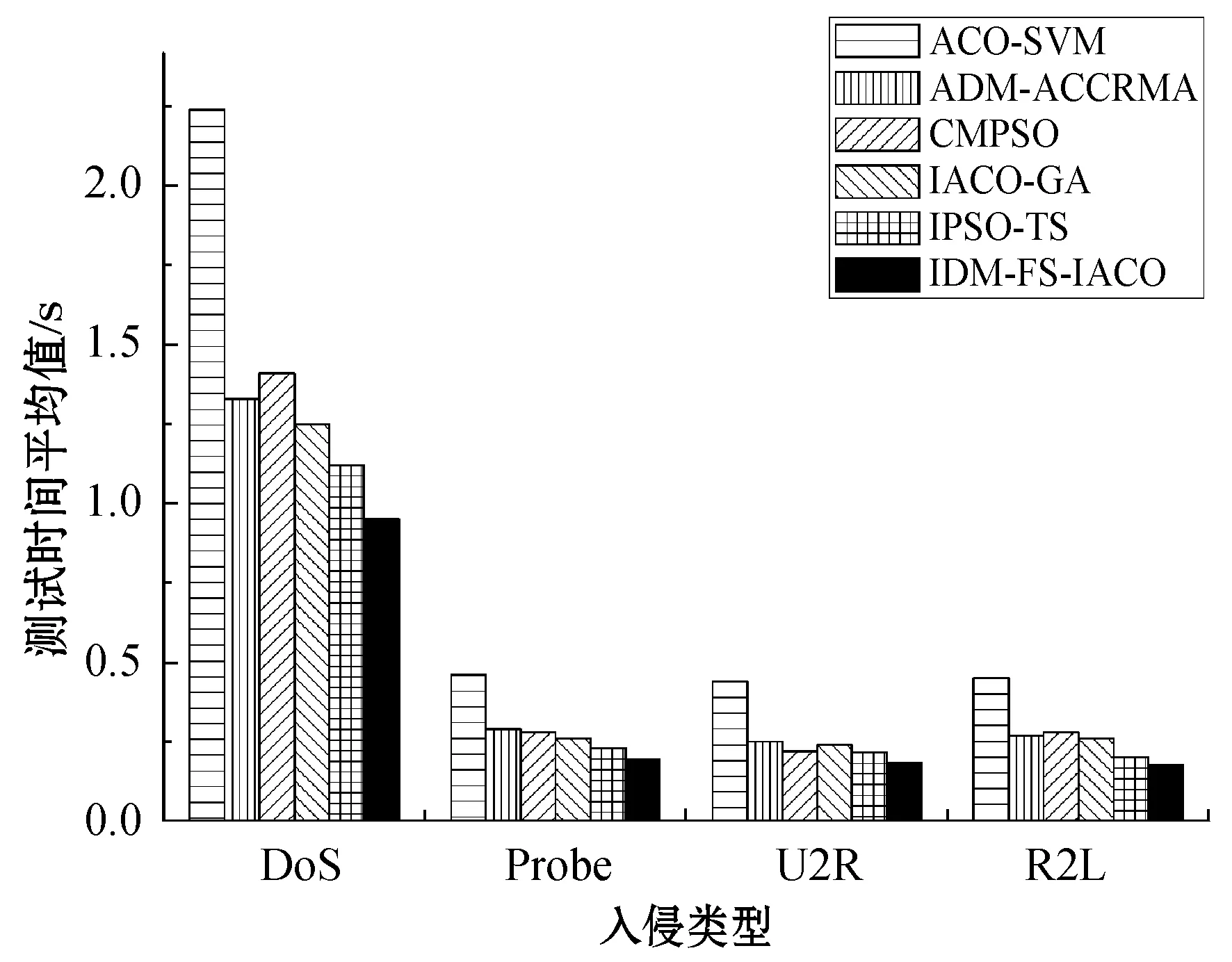
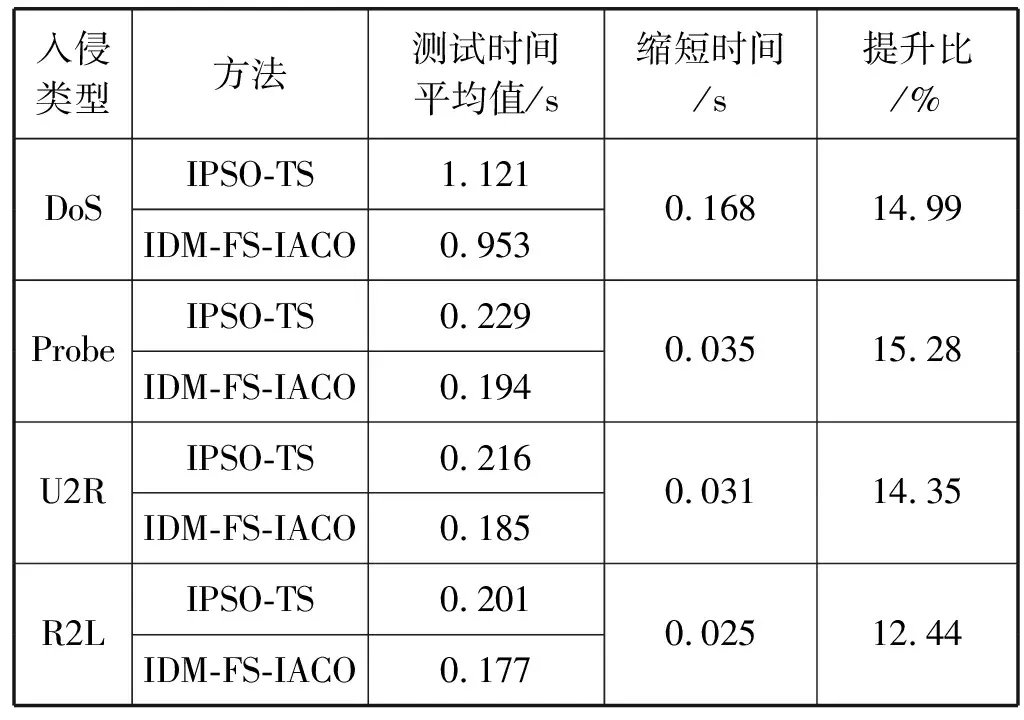
A1i={a∈A|AF (4) A2i={a∈A|AF≥bi} (5) 式中:AF表示特征F在集合A上的取值。 计算以上两个子集的信息熵,公式如下: (6) (7) 式中:Pkj为类别j的样本个数在Ak中所占的比例。记bi为b,则划分后的两个子集为A1和A2,对应的两个区间为I1和I2,信息熵阈值计算如下: ∂i=D(Ii)·E(A)i=1,2 (8) 如果E(A,bi)>∂i,对区间Ii按照如上方法递归地进行划分。 根据信息熵理论对特征属性进行初步提取分析,信息熵的取值可以反映不同特征属性间的差别。 pxy表示第x个特征属性取第y个值的概率,nxy表示第x个特征取第y个值的样本个数,nx表示第x个特征的全部取值个数(相同取值个数也累加),mx表示第x个特征的不同取值个数,Ex表示第x个特征的信息熵,CVx表示第x个特征的差异系数,则有如下公式: (9) (10) CVx=1-Ex (11) 得出第x个特征属性的权重系数Wx如下: (12) 式中:N表示数据对应的全部特征个数。 将所有特征属性按其权重系数按降序排列,按式(13)选取权重较大的特征属性。 (13) 式中:δ=0.80;m取最小值,将前m个特征属性提取出,其余特征属性删除。按照此方法对实验所用的表1中的数据样本特征进行初步提取分析,得出各类入侵类型样本对应的主要特征个数、权重、对应的特征属性如表2所示。 表2 初步提取后的特征属性及权重比例 分析表2,经过初步提取,仅保留了13~15个特征,但这些特征权重比例超过了80%,保留了绝大部分的有效信息,同时大幅度减少了后续的数据处理量。 根据图论知识,系统中多个元素之间的关系可由图来表示,令图G={V,E,W},其中:V表示点集;E表示边集;W表示每条边的权重集合,此处边的权重描述两个节点的选择期望,在后面启发函数的改进中有详细分析。 因此,以m个特征属性对应构造m个特征点,其中m的取值见表2。m个特征点之间两两相连,构造邻接拓扑。四种不同的入侵类型,对应四个不同的特征邻接拓扑。特征点m较多时,特征拓扑相对复杂,下面是以5个特征点为例构造的特征邻接拓扑,如图2所示。 图2 特征邻接拓扑 传统ACO通常用来求解最短路径,而本文提出的改进ACO用来求解特征子集,两者类比分析如表3所示。 表3 改进ACO与传统ACO的类比分析 在改进ACO求解特征子集的过程中,第1次迭代时,n只蚂蚁被平均分配到m个特征点上,以免漏掉重要的特征点。在第i(i=2,3,…,t*)次迭代时,按照以下方法初始分配蚂蚁。 假设每只蚂蚁求解的特征子集中特征点的数量为u,n只蚂蚁第i-1次迭代后求解得到的n个特征子集中,特征点vj(j=1,2,…,m)总共出现的次数记为Ci-1(vj)。第i次迭代时,按照Ci-1(vj)的降序对特征点vj进行排列后,依次为特征点vj初始分配的蚂蚁数量计算如下: (14) 按照式(14),将nj只蚂蚁分配到特征点vj上,如果剩余的蚂蚁数量小于nj时,则将剩余的蚂蚁全部分配到特征点vj上。 启发函数ηij(t)用来描述t时刻,蚂蚁从特征点vi到vj的选择期望。ηij(t)的数值大小取决于特征点vi和vj的相似性,相似性越低,则两个特征之间具有互补性,两个特征全部被选中的概率也就越大,ηij(t)也就越大;反之,两个特征点的相似性越高,则ηij(t)也就越小,ηij(t)计算公式如下: ηij(t) = 1 -prij (15) (16) 第t+1次时刻,特征点vi到特征点vj的信息素更新函数如下: τij(t+1)=(1-ρ)·τij(t)+ρ·Δτij(t) (17) (18) (19) 在传统蚁群算法中,t时刻第k只蚂蚁从特征点vi转移到vj的状态转移概率函数公式如下: (20) 式中:α和β表示两个权重参数,分别反映蚂蚁在运动中所积累的信息素和启发函数值对蚂蚁选择下一跳时的影响;Aki表示允许蚂蚁k从节点i跳到的下一特征点的集合。式(20)容易导致蚂蚁过早收敛至局部最优解,为解决此问题,将状态转移概率函数改进如下: (21) (22) 式中:Random表示返回在该区间内随机生成的一个实数。 (23) 改进的状态转移概率函数不仅有φ的概率按照Pk(ij)(t)搜索下一跳,同时还有γ的概率随机进行搜索,目的是防止过早收敛至局部最优。特别是在早期迭代时,t数值较小,Pk(ij)(t)相对不够科学,因此γ取值不可忽略,可以凸显出随机搜索的相对重要性。但随着蚂蚁迭代次数累加,t数值逐渐增大时,Pk(ij)(t)相对更具科学指导意义,因此γ取值逐渐趋近于0,蚂蚁搜索下一跳更依赖于Pk(ij)(t),以便可以最终收敛至最优解。 算法1改进算法 输入:G,m,n,m*,α,β,λ,t*,τij(0)等。 输出:S*(t*)。 1. Lett=1,Sk(t)={} //开始迭代,初始化特征子集为空 2. while(t≤t*) 3. {Place ants with formula(15); //确定蚂蚁位置 4. For each antk(k=1,2,…,n) 5. {Updateηijandτijby formula(15)and(17); //更新参数 6. From current feature nodevi,select the next feature nodevjby formula(21); //寻找下一特征点 7. Add feature nodevjtoSk(t);} //添加特征点到特征子集 8.t=t+1;} 9. End while 10. Return the best subsetS*(t*) //返回最佳特征子集 (1) 改进蚁群收敛性分析。因传统ACO的收敛性已经得到证明,可参见文献[16],本文只需证明,式(21)随着t的增加,收敛于传统ACO的状态转移概率函数即可。 根据式(22)和式(23),可以得出: (24) (25) 由式(24)、式(25),可以得出: (26) 因此,随着迭代次数的递增,改进的状态转移概率函数收敛于传统ACO的转移函数,证毕。 (2) 时空复杂度分析。分析算法1可以得出,时间复杂度最高的语句应为6,即蚂蚁k执行式(21)的复杂度,这与集合Sk(t)及Aki都直接相关,也就是取决于邻接拓扑G的特征点个数m,因此,算法1中语句6的时间复杂度应为O(m2)。 因蚂蚁数量为n,所以n个蚂蚁执行完一次全局搜索,时间复杂度为O(m2·n)。假设改进蚁群算法收敛完毕需总共执行t*次,则改进ACO的完整时间复杂度应为O(t*·m2·n),并没有增加原ACO的时间复杂度。 因特征节点数量为m,则邻接拓扑G及信息素变量各需要一个m(m-1)/2的二维数组来存储数据,此处空间复杂度为O(m2);两个集合Sk(t)及Aki中的元素均为G中的节点,因此空间复杂度为O(m),考虑到蚂蚁数量为n,此处空间复杂度为O(n·m)。因此,ACO的空间复杂度应为O(m2)+O(n·m)。 但考虑到本文的改进蚁群算法,在每次迭代前要按照式(14)重新分配蚂蚁,此处的空间复杂度为O(m)。综合以上分析,改进蚁群算法的空间复杂度为O(m2)+O((n+1)·m),基本等同于原ACO的空间复杂度O(m2)+O(n·m)。 定义1实例类别。TP(True Positive):真正类,实际为入侵样本并且被成功检测为入侵的样本数量;FN(False Negative):假负类,实际为入侵样本但没有被成功检测出,即漏报的样本数量;FP(False Positive):假正类,实际为正常样本但被检测为入侵,即误报的样本数量;TN(True Positive):真负类,实际为正常样本并且没有被误报的样本数量。 定义2召回率指标Recall和查准率指标Precision: (27) (28) 定义3F-Measure评价指标。仅考虑召回率及查准率,并不能准确评估入侵检测方法性能,因此采用调和函数F-Measure进行评价,公式如下: (29) 在本文中,θ=1,均衡考虑召回率及精确率。 本文采用径向基RBF函数作为SVM核函数,将IDM-FS-IACO的参数优化数学模型描述如下: maxF(S,P) (30) 式中:(S,P)是一个混合向量,S表示改进ACO求解特征子集的参数,包括初始时刻信息素τij(0)、信息素挥发系数ρ、信息素更新权重参数α、启发函数权重参数β、蚂蚁数量n、最大迭代次数t*、特征子集中特征的个数m*,P表示SVM参数,包括误差惩罚参数C和RBF核参数σ;F表示IDS模型的F-Measure值。 参考文献[17-18],确定改进ACO的参数取值或取值范围,其中m的取值见表2;参考文献[19-20]确定SVM的参数取值范围,详见表4。 表4 IDM-FS-IACO的参数取值或取值范围 续表4 服务器采用HP ProLiant ML10,内存16 GB,Xeon四核3.1 GHz主频CPU,Windows 10 64 bit操作系统,采用林智仁教授的Libsvm-3.23实现仿真实验。采用表1中十等分后混合的数据子集,通过循环十折交叉验证求取平均值的方法进行训练并优化参数。具体参数取值计算公式如下: (31) 将四个数据子集训练及测试获得最佳F-Measure值时,对应的参数列入表5。 表5 IDM-FS-IACO的参数优化结果 表6 改进ACO求解的特征子集 分析表6,改进ACO对初步提取的特征(见表2)进行了进一步精简,仅保留了4~6个有效特征,大幅度减少了冗余特征。 采用与4.3节相同的实验环境,采用林智仁教授的Libsvm-3.23实现仿真实验。通过十折交叉验证求取平均值的方法对表1中十等分后的数据子集进行测试实验,综合对比文献[9]方法ACO-SVM、文献[10]方法ADM-ACCRMA、文献[11]方法IACO-GA、文献[12]方法CMPSO、文献[13]方法IPSO-TS,以及本文方法IDM-FS-IACO,将测试实验的Recall平均值及Precision平均值结果列入表7。 表7 不同方法的Recall和 Precision平均值 分析表7,对于DoS、Probe入侵类型样本,以上6种方法的实验结果表现都较好,Recall平均值及Precision平均值均达到90%以上,其中IDM-FS-IACO的Recall平均值相比IPSO-TS分别提升1.87百分点、2.19百分点。 对于R2L入侵类型样本,IDM-FS-IACO的实验结果表现更好,相比IPSO-TS,Recall平均值及Precision平均值分别提升4.43百分点和2.09百分点。 对于U2R入侵类型样本,因实验所用数据集中该入侵类型的样本很少,实验结果表现均不好,但IDM-FS-IACO的Recall平均值仍达到了80%,Precision平均值相比IPSO-TS提升10百分点。 仅考虑Recall平均值及Precision平均值并不能科学地评价以上方法的性能,根据式(29)计算F-Measure平均值,该结果对召回率及查准率进行了调和平均,可以全面科学地反映算法模型的性能,对比结果见图3。 图3 不同方法的F-Measure平均值 分析图3,对于DoS、Probe、U2R、R2L四种不同入侵类型样本,本文方法IDM-FS-IACO的F-Measure平均值相比其他5种方法均有一定程度的提升,特别是对于U2R及R2L入侵类型样本,性能提升明显。另外,IPSO-TS的性能表现也较为优秀,现具体对比分析IDM-FS-IACO及IPSO-TS的F-Measure值,结果如表8所示。 表8 IDM-FS-IACO及IPSO-TS的F-Measure平均值% 定义如下公式: 提升值= IDM-FS-IACO的F-Measure平均值- IPSO-TS的F-Measure平均值 提升百分比=(提升值/IPSO-TS的F-Measure平均值)×100% 分析表8,尽管IPSO-TS方法的F-Measure值比较优秀,但相比本文方法IDM-FS-IACO仍有一定差距,特别是对U2R和R2L入侵样本,IDM-FS-IACO的F-Measure值提升较为显著。 不同方法的训练时间平均值如图4所示,可以看出,ACO-SVM的训练时间最长,原因是该方法重在SVM分类器参数的确定,并未去除冗余特征;而IACO-GA、IPSO-TS、IDM-FS-IACO的训练时间则相差不大,因IDM-FS-IACO在训练实验时需对算法参数进行优化,因此训练时间上没有明显优势。但训练时间处于离线阶段,不会增加系统的在线检测时间[21]。 图4 不同方法的训练时间平均值 不同方法的测试时间平均值如图5所示,可以看出,因未去除冗余特征,ACO-SVM的测试时间最长;IDM-FS-IACO的测试时间相比其他方法均有所减少。另外,IPSO-TS方法在测试时间的表现上也较为优秀,现具体对比分析IDM-FS-IACO及IPSO-TS的测试时间,结果如表9所示。 图5 不同方法的测试时间平均值 表9 IDM-FS-IACO及IPSO-TS的测试时间详细对比 定义如下公式: 缩短时间= IDM-FS-IACO的测试时间平均值- IPSO-TS的测试时间平均值 提升比=(缩短时间/IPSO-TS的测试时间平均值)×100% 分析表9,尽管IPSO-TS的测试时间表现优秀,但相比IDM-FS-IACO仍有一定差距,实验证明IDM-FS-IACO的测试时间显著减少,表现优秀。 本文方法可以在对数据特征初步提取的基础上,由改进ACO进一步求解特征子集,从而减少冗余特征。采用KDD CUP 99数据集,通过十折交叉验证法进行训练及测试实验,结果表明,相比其他方法,IDM-FS-IACO方法的性能较优,F-Measure值有一定提升,测试时间显著减少,为提升IDS性能提供了一条新的思路。但IDM-FS-IACO的训练时间并未显著减少,如何优化智能入侵检测方法的训练时间是今后的研究重点。2.4 特征的初步提取
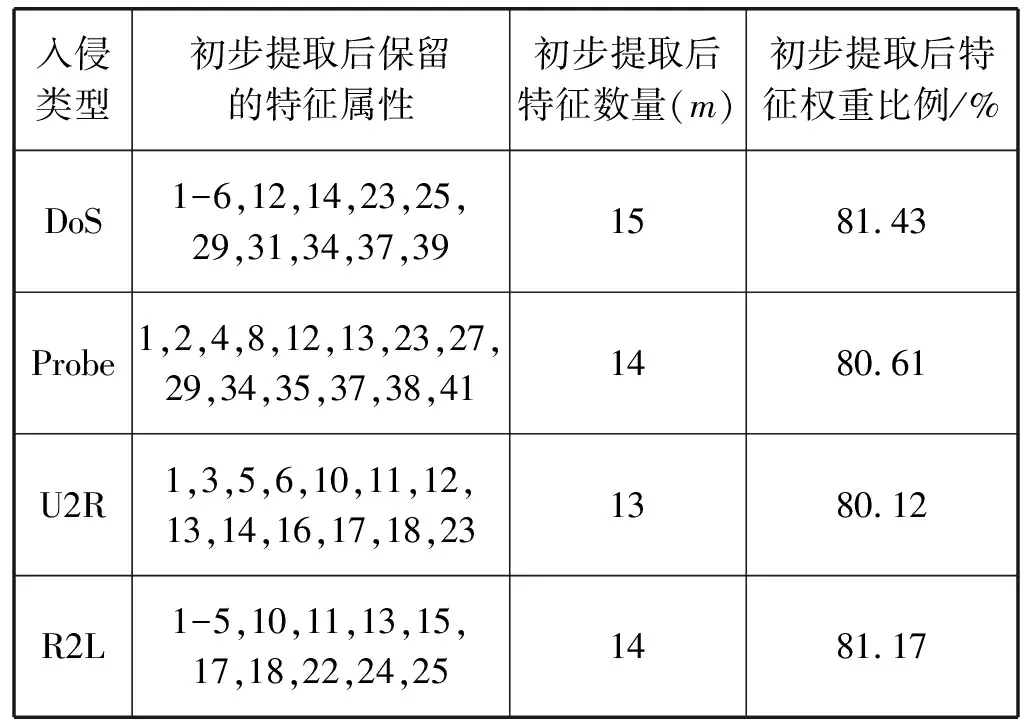
2.5 构造特征邻接拓扑
3 改进ACO求解特征子集
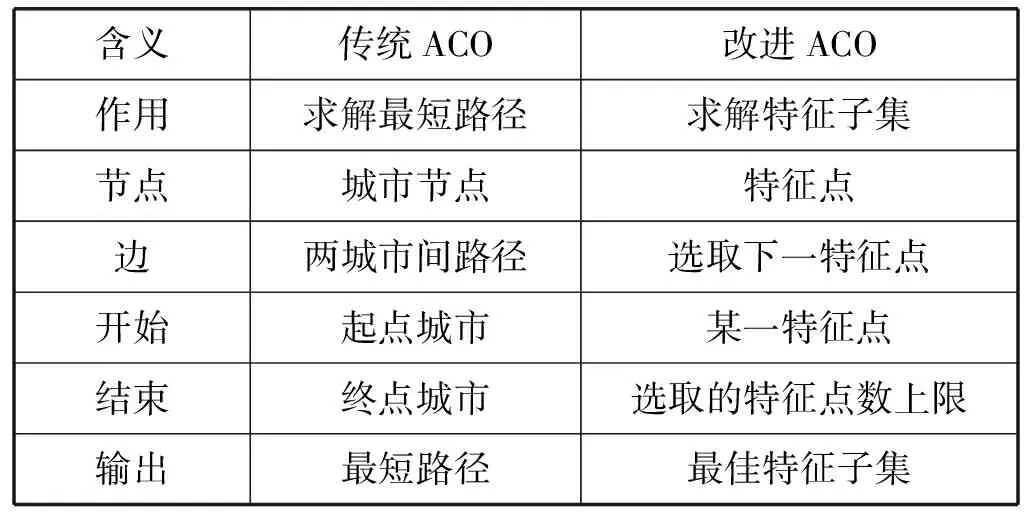
3.1 改进ACO与传统ACO的类比
3.2 蚂蚁初始位置的改进
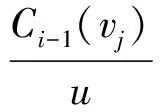
3.3 启发函数的改进
3.4 信息素更新策略的改进
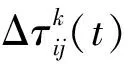
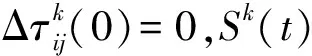
3.5 状态转移概率函数的改进
3.6 改进ACO伪代码
3.7 改进ACO的收敛性及复杂度分析
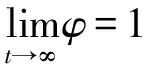
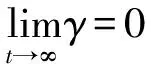
4 评估指标及参数的训练优化
4.1 评估指标
4.2 IDM-FS-IACO参数优化模型
4.3 IDM-FS-IACO的训练优化
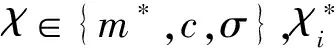
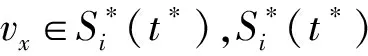
5 测试实验结果对比分析
5.1 Recall和Precision结果的对比分析

5.2 F-Measure结果的对比分析
5.3 训练时间及测试时间的对比分析

6 结 语
猜你喜欢
北京大学学报(自然科学版)(2022年4期)2022-08-18
中学生数理化·高一版(2022年1期)2022-04-05
社会科学战线(2022年2期)2022-03-16
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
新课程·下旬(2018年7期)2018-01-19
数学教学通讯·初中版(2015年5期)2015-06-17
文理导航(2015年14期)2015-05-22
都市丽人(2015年4期)2015-03-20
中学数学杂志(高中版)(2014年2期)2014-05-26
