
基于动态自适应PSO算法的GM(1,1)融合预测模型
2021-07-09 03:50吴晓兵童百利
成都大学学报(自然科学版) 2021年2期
李 眩,吴晓兵,童百利
(安徽省铜陵职业技术学院 经贸系 安徽 铜陵 244061)
0 引 言
灰色预测法是一种对含有不确定因素的系统进行预测的方法,特别适合“少样本建模”,而灰色GM(1,1)模型是灰色系统中应用非常广泛的一种模型.但在许多应用实例中发现,GM(1,1)模型有时预测误差较大[1].如何提高GM(1,1)模型的预测精度成为学者关注的重点[2-3].针对该问题,本研究利用粒子群算法所具有的收敛速度快、设置参数少和容易实现的优点,提出了一种运用动态自适应粒子群优化(particle swarm optimization,PSO)算法来提升GM(1,1)模型精度的方法,并通过实例验证了利用改进的粒子群算法用于提高GM(1,1)模型预测精度的有效性和合理性.
1 灰色GM(1,1)预测模型
GM模型可以用来对灰色系统进行预测,其建模的基本思路是,利用原始数据序列x(0),经累加生成序列x(1),并对生成变换后的序列x(1)建立微分方程模型,即GM模型.
灰色预测模型中应用最多的是GM(1,1)模型,GM(1,1)模型在预测形式上属于单数列预测模型,只用到系统行为序列,而无外作用序列,是灰色预测的核心模型,其对于小样本、贫数据的预测在某些情况下能取得较好预测效果[2].
GM(1,1)模型的预测原理是:对某一数据序列用累加的方式生成一组趋势明显的新数据序列,按照新的数据序列的增长趋势建立模型进行预测,然后再用累减的方法进行逆向计算,恢复原始数据序列,进而得到预测结果.灰色GM(1,1)预测模型实施步骤如下:
假设原始数据数列x(0)存在n个观测值,即x(0)={x(0)(1),x(0)(2),…,x(0)(n)}.将原始数据序列x(0)通过累加生成新数列x(1),以此弱化随机序列的波动性和随机性.通过累加生成可看出灰量累积过程的发展态势,使杂乱的原始数据中蕴含规律体现出来,即,
得到新数列,
X(1)(n)={X(1)(1),X(1)(2),…,X(1)(n)}
由X(1)计算其紧邻均值等权新数列,
Z(1)={Z(1)(2),Z(1)(3),…,Z(1)(n)}
其中,Z(1)(k)=0.5x(1)(k)+0.5x(1)(k-1).
对数列X(1)与Z(1)建立白化微分方程构建GM(1,1)模型,
(1)
其白化方程为,
x(0)(k)+a*Z(1)(k)=b
(2)
式中,a和b都是模型的待定参数.
传统GM模型都是根据数据采用最小二乘法求解参数.由此,方程的解为,
GM(1,1)模型的时间响应序列为,
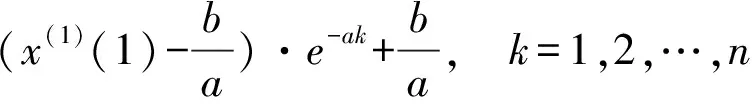
将上述结果累减还原,即可得到预测值,
(3)
GM模型的预测精度与模型参数有很大关系,所求参数解是否最优,直接影响到模型的预测精度.在参数的计算上,灰色系统理论中的传统求解方法是根据实际值与理论值的离差平方和最小的原则,然后通过偏导求解模型参数.而有理论分析和实践表明,传统的最小二乘法求解GM模型参数在数据“异常”时会失真较大[3].
2 动态自适应变参优化的PSO算法在GM模型参数求解中的应用
鉴于传统GM模型精度不理想以及误差较大的情况,有学者们从原始数据的函数变换、以x(0)(n)作为初始条件构造时间响应式以及改进背景值Z(1)(k)的构造方式等诸多方面对传统GM模型进行改进,虽然能在一定程度上提高精度,但终究避开不了在求解模型参数上存在的不足.对此,本研究对原始的PSO算法进行改进,提出一种基于动态自适应变参优化的PSO算法,并将其运用于求解GM模型最优参数,以此来提高模型的预测精度.
2.1 粒子群算法
PSO算法的基本思路是,在可行解空间(算法的搜索区域)中对粒子的速度和位置进行随机初始化,每个粒子具有位置、速度和适应度值3项指标值,适应度值由对应的适应度函数计算得到,其值的大小表示粒子的优劣.粒子在解空间中运动,通过跟踪个体极值和群体极值更新个体位置,粒子每一次更新,就计算一次适应度值,并由适应度值来决定个体极值和群体极值是否更新,粒子将参考群体当前的最优粒子和自身历史经验,并逐代进化搜索最后得到最优解[4].
标准PSO算法实现过程为:假设在M维(即有M个函数自变量)搜索域中有n个粒子组成一个群体,n代表种群规模.研究表明,种群太小则不能保证粒子群体的多样性,以致算法性能很差,即种群太大尽管可以增加寻优的效率,并阻止早熟收敛的发生,但无疑会增加计算量,造成收敛时间太长,表现为收敛速度缓慢[5].Xi=(xi1,xi2,…,xiM),i=1,2,…,n为粒子i的位置向量,粒子维数取决于待优化函数的变量数,其中xik代表粒子在第k个自变量上的取值,xik∈[L,U].在实际应用中,X每一维保证在一定的范围内,这在函数优化问题中相当于是自变量的定义域,L表示第k个自变量的取值下限,U表示第k个自变量的取值上限.Vi=(vi1,vi2,…,viM)为粒子i的速度向量,它们都是M维的,vik∈[vmin,vmax],vmin表示粒子在第k维方向上的最小速度,vmax表示粒子在第k维方向上的最大速度.在每一代寻优中,粒子将根据粒子自身找到的历史最优位置和群体找到的历史最优位置来调整自己的飞行方向和方位[6].
记Pi=(pi1,pi2,…piM)是粒子i自身找到的具有最佳适应值的位置,记Pg=(pg1,pg2,…,pgM)是整个粒子群搜索到的最优位置,设f(x)为适应度函数,粒子i的个体最佳位置为,
群体所有粒子找到的全局最佳位置为,
pg∈{[p1(k),p2(k),…,pM(k)]|f(pg)
=min(f(p1(k),p2(k),…,pM(k)))}
第t代的第i个粒子进化到第t+1代时,第j维的速度和位置用如下的进化方程计算,
vij(t+1)=w×vij(t)+c1×r1×[pij(t)-xij(t)]+c2×r2×[pgj(t)-xij(t)]
(4)
xij(t+1)=xij(t)+vij(t+1)
(5)
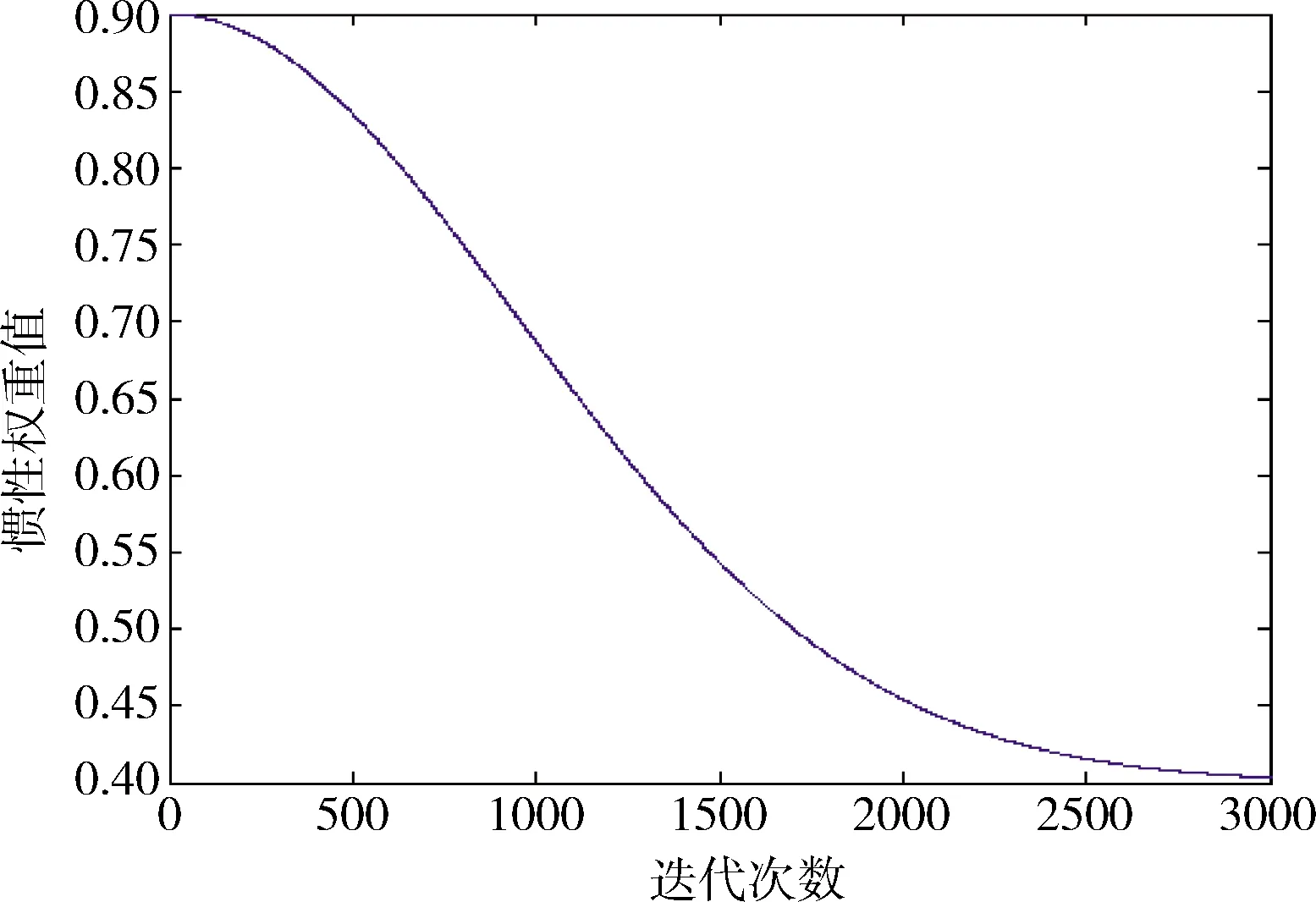
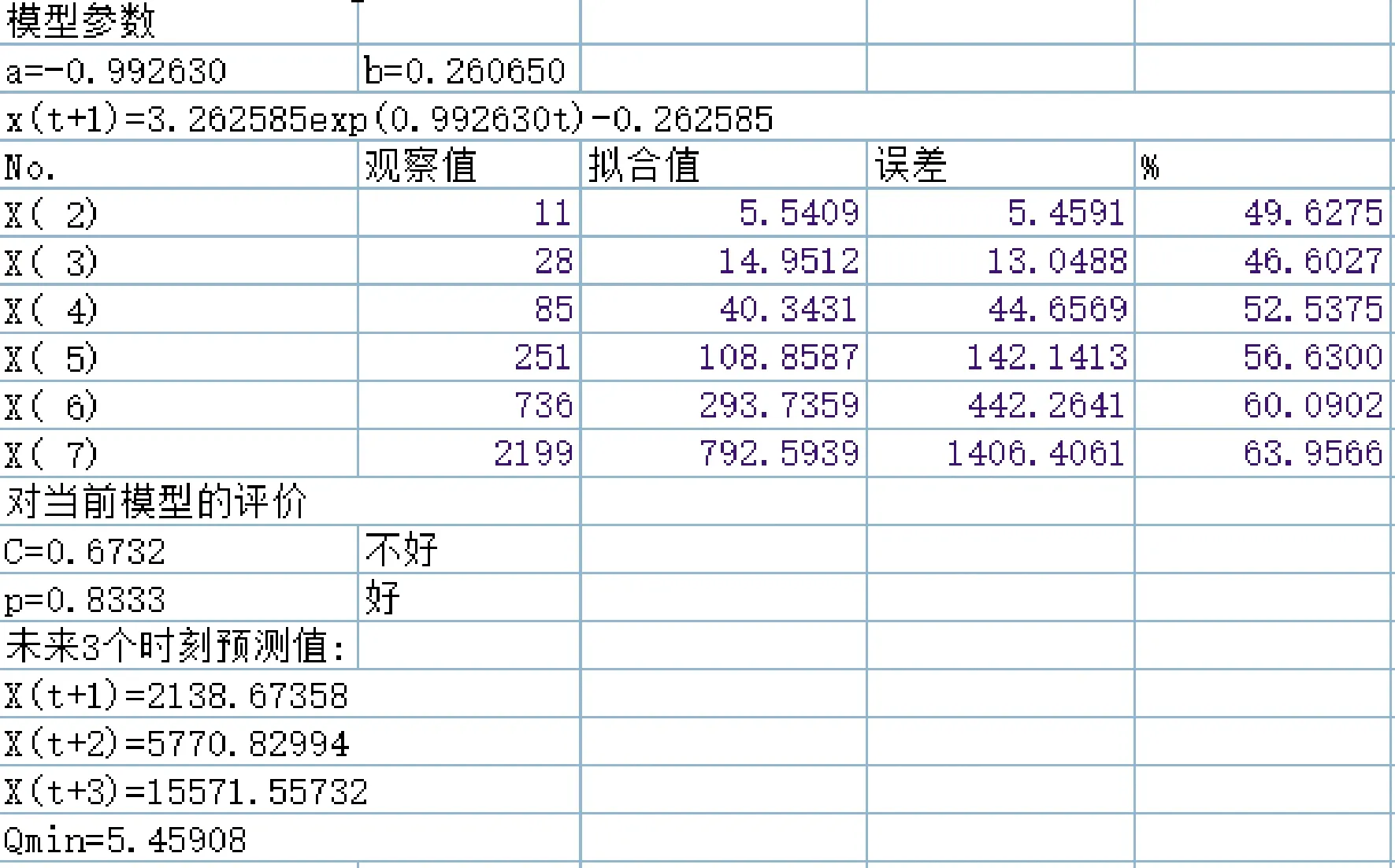
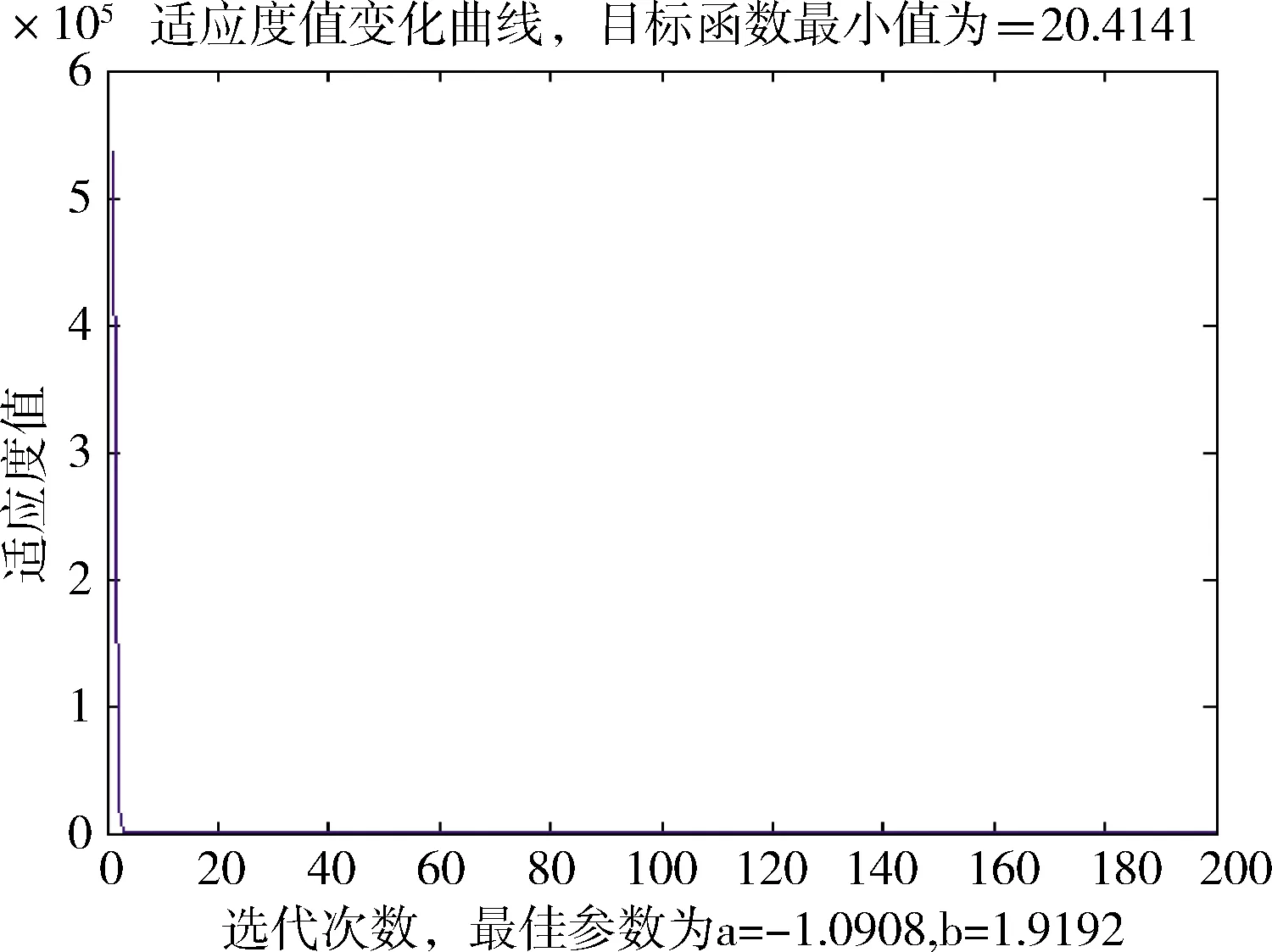
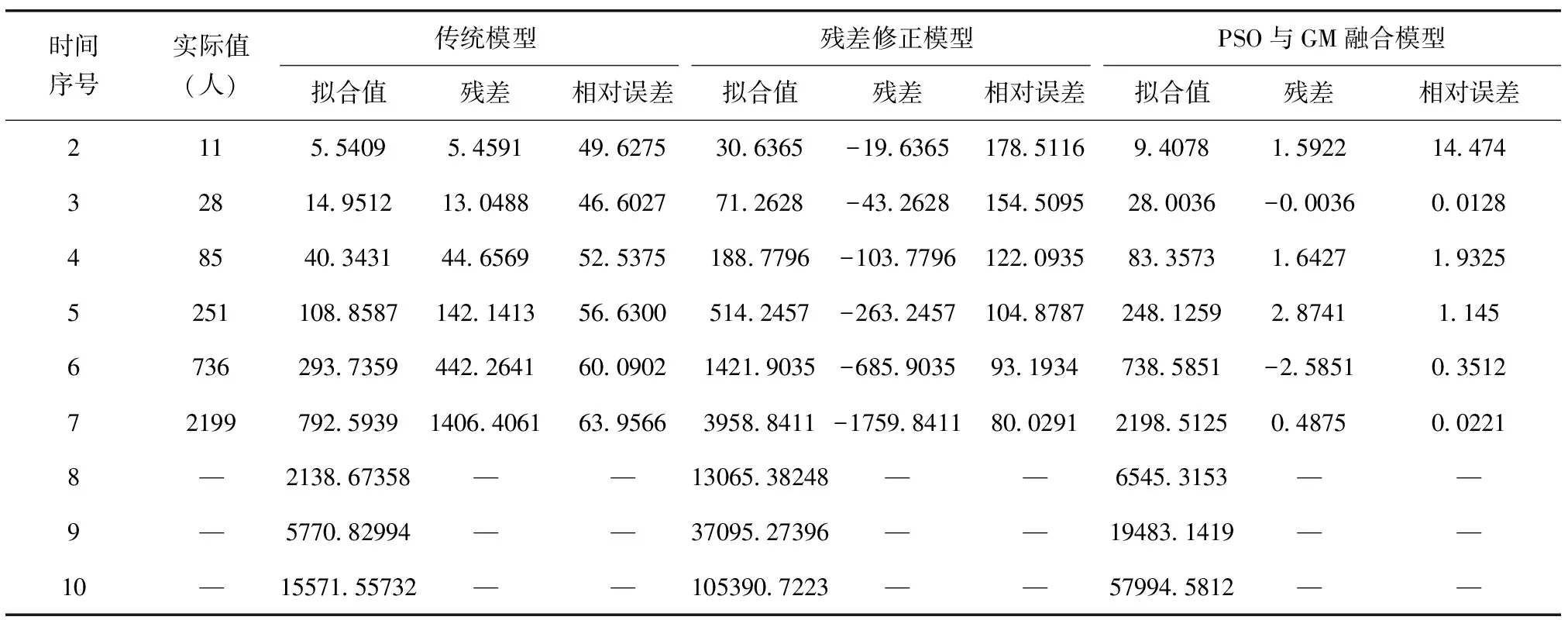
每一维粒子速度和位置的都会被约束在一个范围内,如果超过边界条件,则按如下方法处理,这样可防止粒子逃遁出解空间的可能性:vij>vmax,xij 算法搜索性能对参数有较高的依赖性,算法涉及3个参数,惯性权重w、加速因子c1及c2,该3个参数设置为定值或者线性变化会对算法寻优及效率带来不利影响[7].另外,在优化前期,粒子具有较大速度可以提高搜索全局最优解的能力,而在后期接近最优解时为了不使粒子速度过大偏离最优位置区域错失全局最优解陷入局部最优,因此在后期接近全局最优区域时,位置更新幅度不宜过大,应对粒子速度进行有效掌控和约束,不能忽视后期粒子可能因速度过大俯冲脱离全局最优区域的这种情况出现[8].故本研究在PSO算法中引入非线性变化的收缩因子ρ(t),与惯性权重相比,其更能有效管束粒子的飞行速度并改善算法的收敛能力. 为有效利用自适应变化的参数提升粒子群算法性能,本研究不仅对惯性权重和加速因子进行动态时变调整,同时引入动态时变的控制因子来约束粒子的位置更新幅度.因为参数的非线性时变调整能比线性调整获得更佳的算法性能,这几项参数的调整皆采取非线性的动态自适应时变调整策略[9].惯性权重的动态非线性指数递减的调整公式如下, (6) 式中,k为控制因子,控制w关于t函数曲线的平滑度.随着自变量的增加,函数值递减的速度逐渐下降.指数函数改进的非线性递减的惯性权重符合PSO算法的要求,在迭代次数过程中,惯性权重的值前期减少的速度比较慢,后期减少的速度较快,使得算法在搜索后期仍有较大惯性,在前期保证收敛速度的同时保证了搜索能力,有效避免陷入局部最优[10].wstart=0.9,wend=0.4.当t=0时,w(t)=wstart=0.9,当达到最大迭代次数tmax时,w(t)=wend=0.4.k取5,后期变化步长较小有较好表现,算法能取得较好的稳定性. 为了防止粒子速度过快俯冲脱离最优解,对粒子位置更新幅度进行控制,并在位置更新式(5)中引入动态自适应时变的控制因子ρ(t),对算法后期粒子位置更新幅度进行约束.其变化规律按如下函数进行调整, (7) 式中,ρmax设为1.8,ρmin设为0.4,α为常数,设为0.009.如此,粒子位置更新公式调整为, xij(t+1)=xij(t)+ρ(t)×vij(t+1) (8) 仅仅减小w会使得算法一旦陷入局部陷阱内就很难跳出,极易收敛到局部极值点,而加速因子c1(t)、c2(t)对算法全局和局部寻优能力也有重要影响,所以需要同时对这2个加速因子进行非线性的时变动态调整.本研究采用动态自适应时变调整策略,按照算法对加速因子的变化要求,c1先大后小、c2先小后大,以指数函数为基础构造变化关系式,使其分别呈现递减和递增变化,以此让算法获得较好的全局寻优性能.其调整函数如下, (9) 式中,c2max设为2.0,c2min设为0.6,c2max设为2.0,c2min设为0.6,α为常数,设为0.009.各参数变化曲线如图1所示. (a)惯性权重变化曲线 粒子群中的每个粒子对应优化问题的潜在可行解,根据适应度值进化迭代找到的最优粒子则找到了对应问题的最优解.在PSO算法中用适应度值来评价粒子的优劣,并作为以后粒子速度和位置更新的依据,使得随机初始解逐步向最优解进化.由此可见,粒子群算法的适应度函数设计是粒子群进化寻优的关键. (10) 式中,a,b是待求的GM模型参数,其是适应度函数的2个自变量. 自变量的取值范围(即粒子的搜索范围),可根据具体问题进行适当设定.范围设置过大,则需算法把搜索范围遍历一次,会降低算法的执行效率;范围设置过小,则没有把具体问题的最优解包含在内,会造成算法不成熟收敛或者不收敛,得到的是问题的局部最优解或无解.对此,本研究在GM模型参数的求解问题上,在参考传统GM模型近似解的基础上来设置算法的搜索范围. 本研究以指数级高增长数据序列的拟合与预测为例,利用提出的动态自适应变参PSO改进的GM模型来进行数据的拟合与预测,并在精度和误差上与传统模型和残差修正模型进行对比,以此来验证基于PSO优化的GM模型在预测方面的优越性.在实例分析中,采用最小二乘法求得的GM参数虽是近似解,但最优解肯定在近似解附近.同时,利用PSO算法搜索最优解时,可以在参考近似解的基础上来设置算法的搜索区域,即自变量的取值范围,这样有助于粒子群有针对性地展开精细搜索. 例:假设某地发生传染病暴发情形,其在某周感染人数的日报数据如下, x0=[3,11,28,85,251,736,2199] 从数据的增长趋势可以看出,该数据呈近似指数级增长.利用传统GM模型和残差修正GM模型在软件中建模,其拟合与预测结果数据截图如图2所示. (a)传统GM模型计算结果 从图2数据可以看出,传统模型和残差修正模型对指数级增长数据序列的拟合与预测结果非常不理想,误差较大.下面采用改进PSO算法融合GM(1,1)模型来对该指数级增长数据序列进行预测,在参考传统GM模型求得参数值的基础上设自变量范围为[-4,4],初始粒子数目N设为100,迭代次数T设为500,在Matlab运行动态自适应变参PSO程序,得到适应度进化曲线如图3所示. 图3 适应度函数值变化曲线 图3结果显示,PSO算法收敛相当快.Matlab程序求得的GM模型参数分别为:a=-1.0908,b=1.9192.得到的PSO优化的GM模型的预测值时间响应式为, k=1,2,…,n 利用上述3种模型的时间响应式计算得到不同时间的拟合预测值及误差结果见表1. 表1 3种模型的拟合值、预测值、误差对照表 由表1数据可知,基于动态自适应PSO算法与GM融合模型的预测结果远优于前2种GM模型,在原始数据的拟合上误差较小,而且在后续的时间预测数据的变化趋势也非常吻合原始数据序列的变化趋势,效果较为理想.传统GM模型在指数级高增长数据序列的数据拟合上,误差较大,且在后续时间预测上,预测数据的变化也明显不吻合指数级高增长的特征.而在数据序列高增长,非平稳变化时,残差修正模型反而增大GM模型的拟合数据的误差,在后续时间的预测数据变化趋势也明显大大高于原始数据的近似指数级的增长特征.由此可见,传统GM模型与残差修正模型非常不适合指数级增长非平稳数据序列的预测与拟合. 针对GM(1, 1)模型的应用的局限性,尤其在数据序列变化非平稳时,模型拟合与预测的精度较差的情况,提出了利用改进的PSO算法与GM融合模型来提高模型的预测精度.通过实例分析表明,本研究提出的基于动态自适应PSO算法的灰色GM模型,对于传统与修正GM模型不适用的非平稳序列,具有较高的拟合与预测精度,对于指数级增长的非平稳序列预测精度提升效果尤为明显,在模型的适用性上较传统GM模型和残差修正模型更具有优势.2.2 动态自适应变参策略在PSO算法中的应用
2.3 基于GM(1,1)模型的适应度函数设计

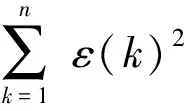
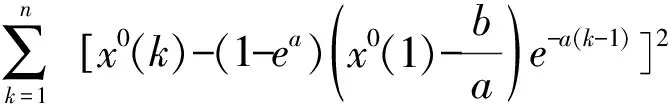
3 优化PSO算法与GM(1,1)融合预测模型的实例分析
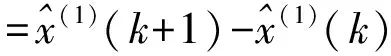
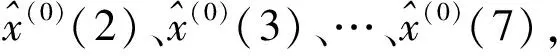
4 结 语
猜你喜欢
计算机仿真(2022年8期)2022-09-28
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
环球慈善(2019年6期)2019-09-25
测控技术(2018年10期)2018-11-25
郑州大学学报(工学版)(2018年2期)2018-04-13
浙江工业大学学报(2017年5期)2018-01-22
中国塑料(2016年11期)2016-04-16
