
基于机器学习的UGC数据分析模型及应用实践
2021-06-24 07:24:48王涛周艺雯
微型电脑应用 2021年6期
王涛, 周艺雯
(同济大学浙江学院 电子与信息工程系, 浙江 嘉兴 314000)
0 引言
科技技术的快速发展以及市场的快速扩张,使得企业间竞争愈发猛烈。以往,人们依靠路边发传单、电视放广告等作为营销策略,现如今,企业营销策略不断改进,精准营销依靠分析受众特征,优化产品策略赢得企业经营者的青睐。UGC(User Generated Content)在线评论,是新媒体平台人们对商品数据的反馈心得。在线评论能反映用户对当前购买商品质量的态度[1]。电商评论网页上,购买过产品的消费者对产品进行评价,这些评价对产品口碑起决定性作用。在产品服务的过程中,用户不仅仅是接受者,也是产品消费过程中的信息提供者。作为商品的销售方,如何分析用户产生的数据,例如用户对产品的评论数据等,在此基础上,商家可以修正不足,改进服务,提升用户满意度。故而,基于在线评论的文本挖掘吻合供需双方需求,受到越来越多用户的青睐。本文通过采集分析携程网民宿数据,建立基于UGC数据分析模型。数据模型分为爬虫模块和分析模块。爬虫模块采集房源数据和对应评论数据,分析模块负责对评论数据集的数据清洗、分词、特征提取、贝叶斯分类和情感分析。
1 爬虫模块
网络爬虫向目标网站发送请求的过程是爬虫程序模拟浏览器发送请求的过程[2]。发送http请求过程[3]如下。
(1) 浏览器发送Request请求,获取目标网址中的html文件数据代码,服务器把Response发送给浏览器;
(2) 浏览器解析收到的数据,引用JS、CSS、Images源文件,浏览器再次发送请求,获取过程中这些代码用到的文件,完成渲染;
(3) 若请求失败则对应栏目显示错误;
(4) 当前数据接收成功后,浏览器会根据当前的HTML代码,渲染前端页面。
互联网中,不是所有网页都可任意爬取。Robots 协议是网络爬虫中网站限制爬虫的协议[4]。协议允许下,为高效准确爬取数据,反爬虫技术应运而生[5]:(1) 基于Headers字段。网站检查Headers字段User-Agent,如图1所示。

图1 用户字段
网站基于用户浏览器版本、浏览器内核及操作系统版本渲染网页。爬虫过程,修改User-Agent字段,欺骗服务器,绕过检查,完成响应。(2)基于模拟用户行为。当前主流网站通过检测用户访问网站的频率来判断访问状况。若某账户短时间频繁访问,会被网站要求验证码访问,或页面收到响应状态码“429 Too Many Requests”,甚至被网站拉入“黑名单”。为规避上述情况,一般通过RANDOM_DELAY函数设置随机延时范围,或使用IP代理。(3)基于动态页面。一些网站的动态页面通过AJAX或JS请求生成数据,不可直接爬取,这便需要基于动态页面的反爬虫策略。如果能找到AJAX请求,分析请求中的隐含信息,可以间接获取目标数据。当出现无法直接获取AJAX请求时,可尝试使用框架selenium+ phantomjs[6]。
本文在比对了市面上同类型民宿租房网站,包括携程、去哪儿、飞猪、途牛、爱彼迎等民宿租房网站后(alexa 网站2020年5月数据),选择携程网作为目标网站。本文的爬虫程序步骤如下。
(1) URL获取。依照行政区获取房源列表界面的各个行政区下的房源URL。
(2) 房源页面下载。获取房源页面的详细信息和对应房源评论数据集。
(3) 网页解析及结构化。解析网页源码得到结构化数据。
(4) URL管理。判断URL是否爬取。
(5) 数据入库。存储结构化的房源数据。
本文最终采集房源数据10 767条,评论数据102 550条,其中房源数据项包括:名称、尺寸、类型、分数、评论数目、房源户型、床数、临近地点以及热门属性,如图2所示。

图2 房源数据(部分)
通过初步分析发现,可能是受当前评分刷单风气影响,评分不能较好反映该栏目对应房源的评分。房源数据综合评分项评分中满分占比高达85.23%,选择评分数据作为参考意见时,容易出现偏离真相的情况[7]。针对这种情况,本文以评论数据为基础,拆解评论数据,为评论数据重新打分。
2 数据分析模块
文本数据挖掘(Text Mining)是指从文本数据中抽取有价值的信息和知识的计算机处理技术。文本数据挖掘通过高效获取含有隐藏价值的信息,指导人们的理论基础和社会实践。本文文本挖掘过程如图3所示。
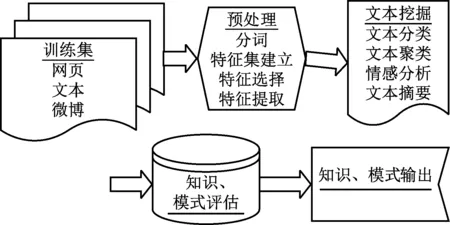
图3 文本挖掘流程
(1) 训练集获取。训练集一般由经过预先训练的特征向量组成,每条文本有一个类别编号。本文训练集的编号即为房源的评分分值。
(2) 数据预处理。文本数据往往不能直接进行文本挖掘,对脏数据进行清理、中文分词、进行相似度度量并建立特征集并提取是正式进行文本挖掘前必不可少的步骤。
(3) 文本挖掘。本文通过评论数据进行房源数据重打分,打分区间位于0.0-1.0,精度为0.1。这实质上是一种文本聚类(Cluster)分析,在综合比较后本文选择朴素贝叶斯模型进行情感分析。
(4) 模式输出。为便于直观展现,本文选择python的Matplotlib进行图表可视化。
本文程序框图如图4所示。
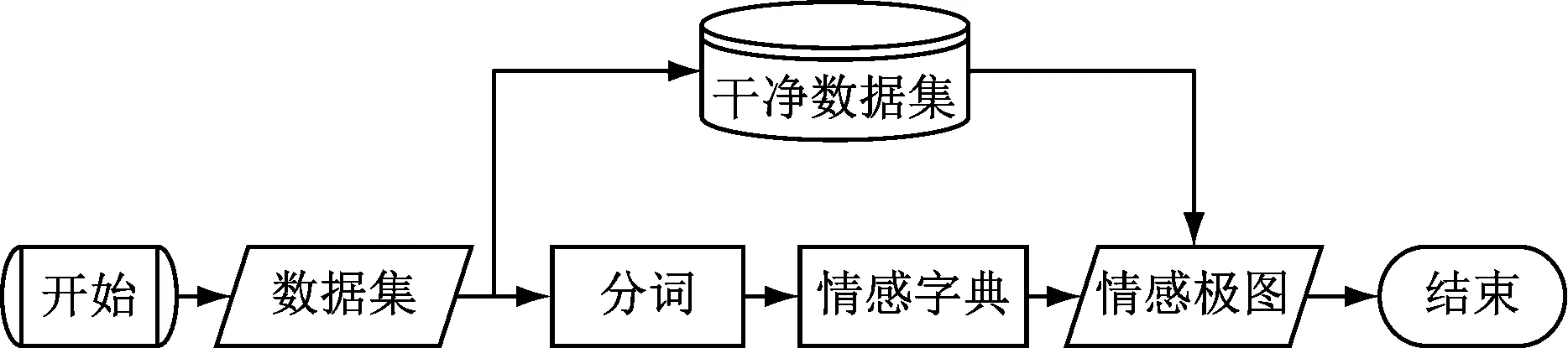
图4 程序框图
2.1 数据预处理
数据预处理是文本挖掘中承上启下的环节,预处理清除网络爬虫过程中的脏数据,将文本分词。预处理结果将直接影响后续特征提取及分类器分类结果。
2.1.1 数据清洗
电商评论的数据质量经常参差不齐,有些数据价值密度较低,有些刷单数据会影响统计结果,使最终分析结果不真实。数据清洗的目标:(1) 文本去重,减少刷单、用户操作失误、爬取重复评论的评论文本。(2) 压缩去词,删除将评论中连续重复表达的词汇。(3) 格式错误,如对房源尺寸数据“20 m2”,将其改成“20”。
2.1.2 中文分词
对人类,根据语境判别句子含义是自然而然的,但对计算机十分困难。英文文本存在含独立语义的最小语言单位[8],通过空格就可分隔,但对无空格分隔的中文分词,将完整的中文句子分解成多个具有语义的词汇,是中文自然语言处理中基础但重要的环节。
自然语言建模是自然语言问题转化成机器学习问题的关键,建模的目的是将单词向量化,将词语映射成实数向量[9]。2013年,谷歌研究团队提出从大量文本语料库中学习含有特定语义信息的低维度词向量无监督学习方式语义模型[10],Word2vec词向量研究模型。Word2vec利用神经网络,将独立词语转化为词向量,统计计算向量与向量间空间距离,实现非结构型文本转化为向量空间的向量运算。Word2vec模型包含两种重要模型:CBOW(Continuous Bag-if-Words)模型和Skip-gram (Continuous Skip-gram)模型,这种方法训练出来的模型,训练步骤被相对简化、合成方式被优化,同时词向量质量较高,还降低了运算复杂度[11]。
假设已知输入词语W(t),预测输入词语W(t)周围上下文2n个词语的模型称为Skip-gram 模型[12]。如果已知w(t)的上下文wct,存在未知词语w(t),预测词语w(t)的模型称为 CBOW 模型,如图5所示。

图5 模型示例
分别为Skip-gram模型和CBOW模型的模型示例,此时n=2,模型包含三个层级:输入层、投影层、输出层。
上下文的定义如式(1)。
wt=wt-n,…,wt-1,wt+1,…,wt+n
(1)
式中,c表示词语wt的前后词语数量。Skip-gram模型和CBOW模型的优化目标函数分别为式(2)、式(3)。
(2)
(3)
式中,C表示包含所有词语的语料库;k表示当前词语w(t)的窗口大小。
以Skip-gram模型为例,假设语料库中句子“农业现代化受到限制”,选定词语“受到”,上下文:农业、现代化、限制。要使得条件概率值达到最大,给定w(t)前提下,使得单词t距离2n的上下文概率达到最大:P(农业|受到)、P(现代化|受到)、P(限制|受到)[13]。
当前的分词工具一般基于Word2vec,目前较为成熟的开源中文分词有LTP、Jieba、THULAC、NLPIR等[14]。本文通过LTP分词工具实现分词,LTP提供了以下模型文件,如表1所示。

表1 LTP模型文件
基于LTP分词提供的cws.model模型文件,实现分句和词性标注,部分LTP代码如下。
for sentence in cont:
if sentence.strip() != ’’:
words= segmentor.segment(sentence)
for word in words:
f1.write(word+’ ’)
f1.write(’ ’)
word1=segmentor.segment(sentence)
postags = postagger.postag(word1)
for word,tag in zip(word1,postags):
if (tag == ’n’ ):
f.write(word+’ ’)
f.write(’ ’)
else:continue
2.2 基于贝叶斯分类的情感分析
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。本文根据类别于词之间的联合概率在已知条件概率和先验概率的基础上,去计算其后验概率的分类。朴素贝叶斯算法的前提条件是类别具有独立性,一个类别的属性值对于给定类别的影响应该独立于该类别的其他属性值。通过分类来计算一组给定样本属于特定类别的概率[15]。本文分类算法的具体过程描述如下。
(1) 对数据样本进行标记;
(2) 对不同类别的样本数据进行中文分词和降噪;
(3) 将词条组合成特征组并分析词条频率信息;
(4) 根据词条频率信息来计算其先验概率;
(5) 对样本数据进行中文分词及降噪形成样本特征组;
(6) 将词条的先验概率代入公式计算其后验概率,所属的文本类别就是其中最大的概率。
本文通过上述分类算法,将数据文本分成8个主题,价格、特色、体验、餐饮、服务、环境、设施和交通,去掉无关的数据后,然后将此8个主题文本各分成五类(按照满意度降序排列),总共四十个类别。“价格”主题评分如表2所示。
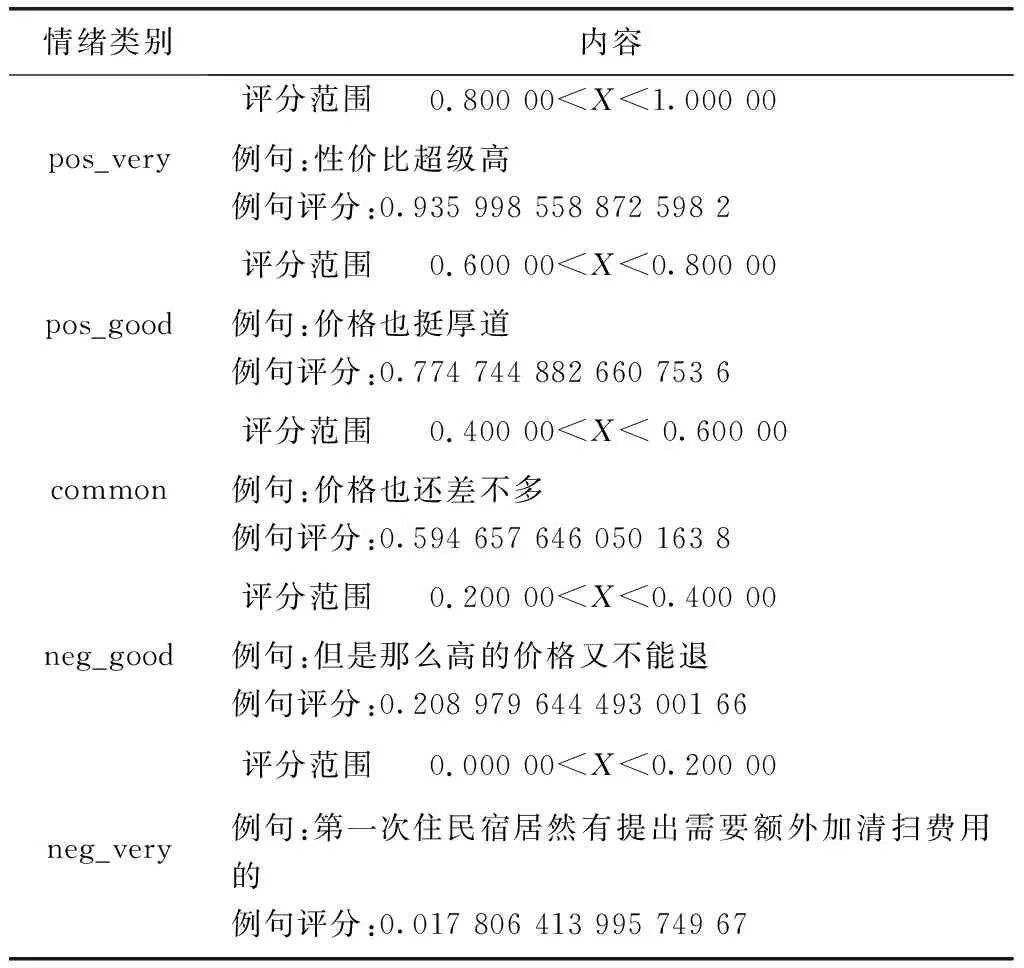
表2 模型评分“价格”主题
为便于理解情感趋势,绘制基于评论评分的可视化图表,将评论数据与初始房源评分数据进行对比就可以发现,初始房源评分数据以好评居多,很难从中得到更多有用信息,但是通过评论数据,综合分析,就可以对当前地区的民宿经营状况提出以下方面建议。
(1) 提高民宿的餐饮尤其是早餐的服务质量
餐饮-情感字典如图6所示。
由图6可知,排前五名的词汇为:早餐、味道、菜、早饭、饭, 这表示住客对早餐的关注度较高,提示经营者如果提高早餐质量,可以调高服务评价。
(2) 提高民宿的硬件设施和日常维护
设施可视化如图7所示。
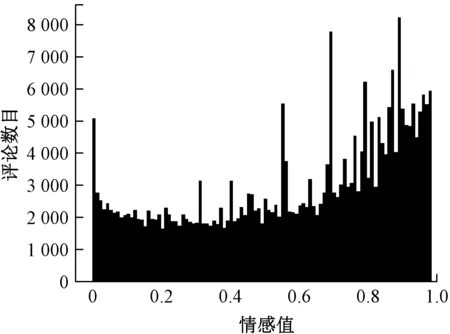
图7 设施可视化
总体来说,消费者对民宿的硬件设施满意度不高,给出极低评价的不占少数。通过观察情感词典,提及频率较高的硬件设施相关的词语依次是房间、床、卫生间、空调等,民宿的经营者可以着重提高这些设施的档次,同时做好即有基础硬件设施的维护工作。
(3) 优化民宿的服务体系
服务可视化如图8所示。

图8 服务可视化
虽然有一部分用户相当满意民宿的服务,但多数顾客将评分置于0.6—0.8,这意味着民宿的服务勉强使其满意,此外抱有消极态度的用户不在少数。初步猜测这是有别于酒店拥有一套完整服务体系,民宿虽然具有自由神秘的特点,但也使得房东对于租客的态度比较自由随性。酒店具有一套成熟的服务体系来提供基本的前台接待及住房导引服务。而民宿经营者通过网络来履行服务责任,大多不与用户面对面联系:交付费用、钥匙告知、住房期间问题解决等。这意味着用户一旦出现紧急问题而无法得到及时满意的解决,如空调制冷、热水器不热等问题。这就需要经营者在基础设施上下功夫,提高服务质量。
3 总结
随着互联网经济和电子商务的急速发展,产生了越来越多的融合数据,更多的传统行业将电子商务纳入到其他业务体系中,双十一的交易金额也在逐年增长。这些融合数据的价值挖掘将在未来的发展中具有广大的前景和实用价值,为产品的发展和生产决策提供重要的参考依据。本文通过爬取了携程网民宿房源数据和在线评论作为原始的数据集,应用传统的文本分析方法,分析房源数据和评论数据的特点,应用贝叶斯分类完成了基于独立主题的情感分析。根据爬取房源数据的特点,在以下方面展开了研究:(1) 房源数据爬虫,通过分析房源网页结构,分析待爬节点,解析网页。(2) 中文文本预处理,中文文本降噪、去重和分词。(3) 8类主题评论文本划分,通过Word2vec原理,建立8类主题情感字典,基于8类情感字典完成评论文本划分。(4) 对房源数据进行朴素贝叶斯模型情感分析,通过数据可视化得出直观结果。
针对本文研究,只使用了朴素贝叶斯算法对评论语料进行分类分析,如果可以通过比较更多其他模型算法对其进行分析,可能会有更好的结论。
猜你喜欢
理财周刊(2023年2期)2023-02-26 16:33:53
房地产导刊(2022年10期)2022-10-18 08:03:52
现代信息科技(2021年21期)2021-05-07 02:54:12
中国房地产·综合版(2020年8期)2020-10-28 08:46:16
——基于信号理论视角
江苏科技大学学报(社会科学版)(2020年2期)2020-07-25 06:57:50
智富时代(2019年6期)2019-07-24 10:33:16
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
高中生·天天向上(2016年9期)2016-11-22 09:10:34
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
