
基于视觉和肌电信息融合的手势识别方法
2021-06-01 03:38彭金柱董梦超
郑州大学学报(工学版) 2021年2期
彭金柱, 董梦超, 杨 扬
(郑州大学 电气工程学院,河南 郑州 450001)
0 引言
近年来,随着人机交互技术的快速发展,利用各类传感器进行手势识别从而控制机器完成指定任务已经变得非常普遍[1]。手势动作交流具有较高的灵活性且生动形象,当将其应用于人机交互中时,对可识别手势动作的种类和手势动作信息的精准获取提出了更高的要求。
从手势信息获取方式来看,手势识别主要分为2种:通过人体手势视觉图像信息实现手势识别和获取人体手势肌电信号(EMG)进行手势识别[2]。Saha 等[3]通过Kinect视觉传感器采集人体手势图像信息,利用隐马尔可夫模型(HMM)识别手势,但该方法存在难以调参的问题,对识别时间和效率有一定影响。任彧等[4]提取方向梯度直方图(HOG)特征作为手势图像的特征描述符,基于支持向量机(SVM)多分类算法完成对手势识别模型的训练,消除了光照不均和手势角度旋转对手势识别的影响。但该方法要求背景简单,且只对有限的9类手势进行识别。Naik等[5]通过采集到的手臂EMG信号,提取信号的分维数特征,用SVM等方法进行手部运动模式的分类,识别正确率较高。张启忠等[6]提出了球均值Lyapunov指数计算的方法提取EMG信号特征,利用SVM作为分类器完成4类手势的分类,准确率达到96%。Lahiani等[7]开发了一种基于HOG和局部二值模式(LBP)特征的静态手势识别系统,对10种手势的识别正确率达到了92%。但是,受限于当前常用特征的区分能力,目前已有的大多数手势识别算法只能在手势类别数量较少时获得不错的性能。当需要处理的手势种类增多时,不同手势的类间距离迅速变小,使得这些方法的识别正确率难以保证。
针对上述问题,本文提出一种基于视觉和EMG信息融合的手势识别方法,主要分为3个部分:对单一视觉HOG特征和单一肌电信号时域特征的提取;将2种单一特征进行特征融合,得到融合特征;以融合后特征作为SVM多分类器的输入训练手势识别模型。该方法利用融合特征代替单一特征,从视觉和肌电2个角度完成对手势信息的特征描述,所需数据量远小于同等识别效果的单一HOG特征,在手势种类多达36种的情况下识别正确率达到96%。
1 特征提取
1.1 视觉HOG特征提取
HOG最早由Dalal于2005年提出,具有几何不变矩的特性,多用于行人检测中,并取得了较好的效果[8]。HOG依据一幅图像的形状、外观等特征能够被梯度或边缘的方向密度分布很好地描述的原理,来适应光照变化和目标旋转。
视觉HOG特征提取过程:首先利用Kinect视觉传感器获取手势图像并对其进行图像中值滤波、颜色空间转换等预处理操作;然后基于YCbCr颜色空间的椭圆模型完成对手势区域的分割;最后对图像进行灰度化操作,计算并提取手势HOG特征。HOG特征提取过程如图1所示。
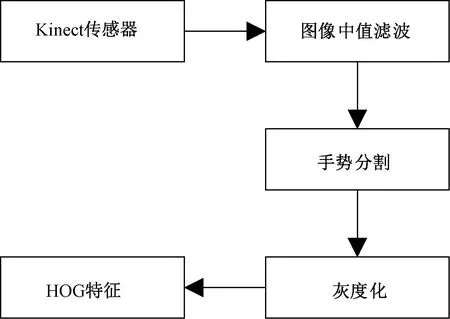
图1 HOG特征提取流程Figure 1 Flow chart of HOG feature extraction
1.1.1 手势分割
手势分割是把人的手势区域从完整的图像中分割出来,减少背景带来的训练识别过程的计算量冗余。
椭圆模型是一种在YCbCr颜色空间下的手势分割模型。研究表明:把人体手势肤色像素投影到CbCr子空间上,其投影近似在一个椭圆范围内[9]。通过计算图像中像素点的投影位置是否在椭圆范围内,判定当前像素点是否是人体手势像素点[10]。椭圆模型的表达式为:
(1)
(2)
式中:Cx=109.38;Cy=152.02;θ=2.53 rad;eCx=1.60;eCy=2.41;a=25.39;b=14.03。
椭圆模型具有计算速度快和检测准确率高等特点,所以本文选用椭圆模型完成对手势的分割。图2为基于YCbCr颜色空间的椭圆模型手势分割效果。
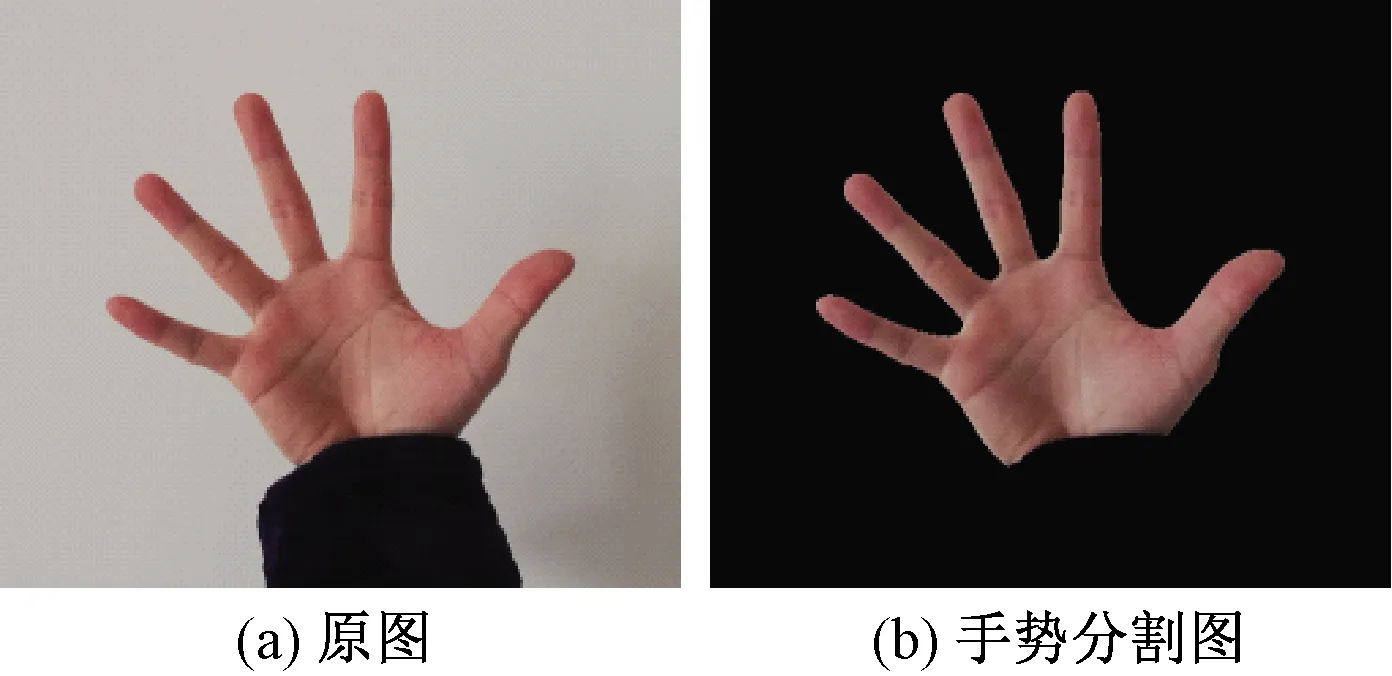
图2 椭圆模型手势分割效果Figure 2 Ellipse model gesture segmentation renderings
1.1.2 HOG特征计算
与其他图像几何特征不同,HOG特征将图像细分为多个小的细胞单元(cell),然后计算所有细胞单元中各像素点的梯度或边缘的方向直方图。为提高性能,将若干个细胞单元组成一个区间(block),图像变为由若干个区间组成的连通图,然后在这些区间内对各细胞单元的梯度进行归一化,取得最终的梯度方向向量。
图像的梯度方向向量数由图像大小、cell大小、每个cell所取梯度维数等因素决定。计算式为:
(3)
式中:Bn=(Bs-Bt),Bt表示block移动步长,Bs表示block大小;Cs表示cell大小;Cd表示cell维数;w与h分别表示图像宽与高。
1.2 肌电信号时域特征提取
EMG的时域特征提取过程:首先利用Myo臂环获取手势动作信号并进行去噪等预处理操作;其次,对预处理后的肌电信号进行有效活动段检测;最后完成对EMG的时域特征提取。EMG信号的时域特征提取过程如图3所示。
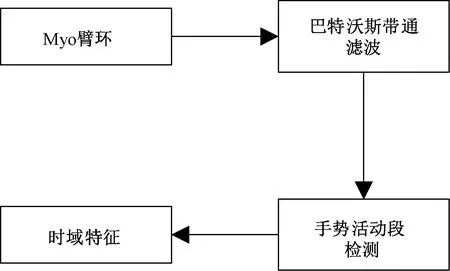
图3 EMG时域特征提取流程Figure 3 Flow chart of EMG time domain feature extraction
1.2.1 有效活动段检测
使用4阶巴特沃斯带通滤波器对EMG进行滤波处理[11],然后,对手势动作的肌电信号进行活动段检测,找到手势动作的有效起止点,从而能快速完成手势动作的特征提取,且能够提高特征提取的准确度。
移动平均法可以在一定程度上减轻随机波对时间序列信号整体走势的影响,因此,选用移动平均法进行有效活动段检测。对获取到的时间序列信号设定一定宽度的时间窗和滑动步长,按顺序叠加平均,计算此时间窗内的采样数据点,进而获得一个新的时间序列信号[12]。对手势肌电信号进行有效活动段检测时,分别对8通道肌电信号数据进行移动平均处理,具体操作步骤如下。
(1)定义每个通道表面肌电信号Sk(t),k=1,2,…,8。对各通道表面肌电信号Sk(t)进行平方处理,从而获得EMG瞬时能量的时间序列E(t):
(4)
(2)在采样频率为1 000时,设定窗口大小W=64,在滑动步长为16时,对EMG能量时间序列E(t)进行滑动平均计算,进而获得滑动平均后的时间序列EM(t):
(5)
通过观察,设置合适的阈值,比较EM(t)和阈值的大小,从而确定手势动作肌电信号有效活动段的起止点。具体方法是:将时间序列EM(t)大于阈值且之后的2个连续点数据值都大于阈值的点确认为有效活动段的起始点;将时间序列EM(t)小于阈值且之后的2个连续点数据值小于阈值的点确认为有效活动段的结束点。
1.2.2 时域特征提取
特征提取的目的是利用手势携带的特定信息将不同手势动作区别开来,这对后续不同手势肌电信号的分类有至关重要的作用。目前,肌电信号特征提取在信号分类方面具有较好的效果,其方法包括:时域分析方法、频域分析方法、时频域分析方法及非线性动力学方法。从国内外学者的研究来看,相较于其他分析方法,时域分析方法在表征手势特征方面效果更好,且计算简单、获取迅速、实时性高。
由于EMG属于生理信号,是一种随机性较大、不易重复的生物电信号,所以一种特征参数并不能实现肌电信号的全面描述。本文选用时域统计学特征来作为不同手势的分类标准,5个时域统计学特征如下:均方根值(RMS)、波形长度(WL)、平均绝对值(MAV)、过零点数(ZC)、斜率变化数(SSC)。5个时域统计学特征的数学定义如表1所示。

表1 时域特征的定义Table 1 Definition of time domain feature
2 特征融合及分类器设计
2.1 特征融合
相比其他技术,多传感器信息融合技术最大的优势在于能够获得其他单一传感器不能得到的被感知物体的完善的基本特性,并且多传感器信息融合技术在信息融合后具有较强的可靠性、时效性、鲁棒性[13]。同一被感知物体在不同背景下,表现出来的特征信息其实都不相同,但是对于多传感器信息融合来说,一般都是在同一个级别下完成的。根据被感知物体信息抽象程度,将多传感器信息融合分为像素级数据融合、特征级数据融合和决策级数据融合[14]。
选择特征级数据融合作为多传感器信息融合的融合结构,串行特征融合是直接将来自2类传感器的特征向量进行首尾相接,从而获得包含不同特征类型的高维特征向量。假设样本空间为Ω且A、B对应不同的特征空间类型,任意选择一个样本ζ∈Ω,其所对应的2类特征向量分别是α∈A,β∈B,那么ζ的串行融合特征向量φ定义为:
φ=αβ。
(6)
提高特征向量有效数据维数是对当前样本更细致的特征描述,可以增加不同样本之间的可区分性。提高单一特征向量的有效数据维数从而细致刻画不同样本在当前特征下的差异,是一种提高识别正确率的方法[15]。但是该方法在数据量上的增加,会给计算量带来量级上的增大,甚至带来维数灾难问题;其次,有效数据维数提高存在瓶颈期,当数据维数高到一定量级时,再持续增加特征向量维数,对结果提升不明显。
融合特征向量有效数据维数的提高是基于增加样本特征描述的类别,通过不同特征下样本差异性的累加来提高其可区分性。考虑到2种特征融合占比的均衡性,为了更直观地展现融合特征给正确率带来的提升,本文融合特征向量γ(184维)由HOG特征向量α(144维)和EMG时域特征向量β(40维)串行融合而成。相比于对单一特征细致描述产生的数据量,融合特征数据量增加较少且给样本之间加入另一特征下的差异描述,性价比更高,且多特征的提升空间更大,能有效解决瓶颈期问题。
2.2 SVM多分类器设计
SVM通过建立一个分类超平面作为决策面,使不同类之间的隔离边缘最大化,从而实现分类。基础的SVM仅针对二分类问题,不能满足实际问题中多分类问题的需要。为将SVM良好的分类性能运用到多分类问题,专家提出一对多[16]、一对一[17]、基于有向无环图[18]以及基于决策树[19]等方法构建组合式SVM多分类器。本文采用基于一对一方式实现的组合式SVM多分类器解决手势识别问题。
对于一个具有N(N≥2)个类别的分类问题,此方法共构建N(N-1)/2个SVM分类器,每个分类器实现对2个类别的分类,使得N个类别中任意2类都有其相对应的分类器。假定N=3,对应的3分类组合式SVM分类器结构如图4所示。
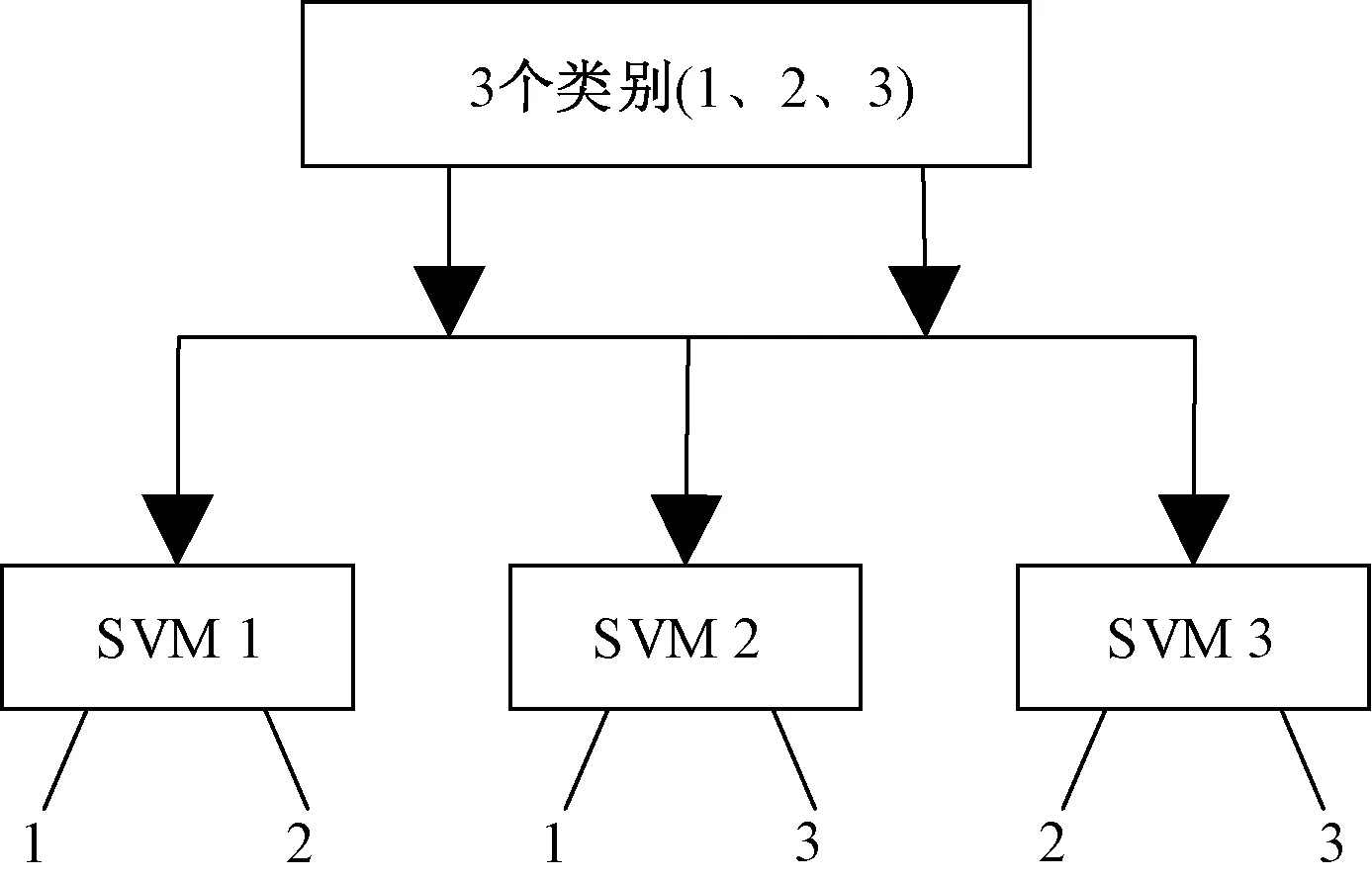
图4 3分类SVM结构Figure 4 3 classification SVM structure chart
每个分类器对输入样本进行非此即彼的分类判定,采用投票策略对输入样本进行最终识别,即票数最多的一类为输入样本所属类别。当出现多个类别票数相同的情况时,由算法判定类别序号最小的类别为输入样本最终所属类别。
基于一对一方式实现的组合式SVM多分类器中每个SVM面对的都是2个类别的分类问题,易于训练,充分发挥了SVM解决二分类问题的优势。本文使用的SVM分类器的类型是C-SVC。选用径向基核函数(RBF)作为核函数,其具有较宽的收敛性,易于调参,可以在一定程度上消除高维空间中的复杂内积运算。通过网格搜索法对惩罚系数以及核参数进行寻优。
3 实验结果及对比
本文以图像HOG特征与肌电信号时域特征组成的融合特征作为手势的特征描述符,基于SVM多分类算法实现对36种手势(包含10个数字和26个英文字母)的识别。由于识别手势种类的多样性以及多特征融合的方法在当下没有合适的公开数据集供研究使用,所以采用自制的手势数据集完成相关研究工作。
自制手势数据集共由10位实验者提供组成,其中男女人数比例为1∶1。36种手势与所代表含义的对应关系如图5所示,每人每种手势采集3张图片以及相对应的3组手势肌电信号,即每种手势共分别得到30组有效数据。
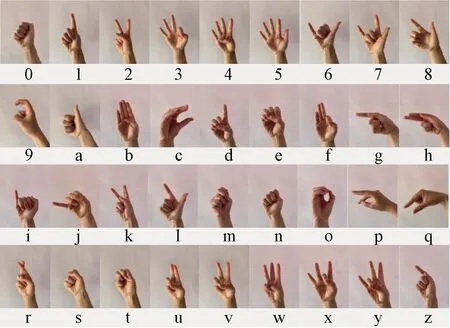
图5 手势对应关系Figure 5 Gesture corresponding chart
本文实验硬件平台配置:Inter i5-4460处理器,8 G内存(1 600 MHz)。SVM多分类算法在MATLAB 2020b平台基于Libsvm功能包实现。
使用十折交叉验证评价算法的分类性能,并记录每个类别手势的识别正确率,总体正确率为每个类别的正确率之和与总类别数的比值。采用融合特征的36种手势识别的正确率如表2所示。
相同实验条件下,分别对单独HOG特征(144维)、单独EMG时域特征以及基于SLMF(score-level multifeature fusion)方式[20]的特征融合(144维HOG特征与EMG时域特征的融合)进行36种手势的识别实验,并将得到的手势识别正确率与本文提出的特征融合做对比,对比情况如图6所示。该方法的实验结果在图6、8和表3中由HOG144+EMG(S)表示。

表2 特征融合识别正确率Table 2 Feature fusion recognition accuracy
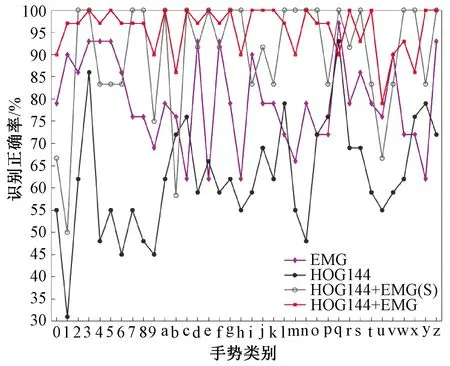
图6 特征融合前后分类识别正确率比较Figure 6 Comparison of classification accuracy before and after feature fusion
本文在基于SLMF方式的特征融合实验中,自制数据集的60%作为训练集,40%作为测试集;由训练集样本训练不同特征类型对应的模型,记录样本识别分数并计算不同特征类型对应的权重;测试得到测试集样本的识别分数,结合不同特征对应的权重,完成特征融合过程。
对比上述实验结果发现,本文提出的特征融合的手势识别方法在36种手势识别正确率方面明显高于单一特征,其中33种手势识别正确率在90%以上,更有14种达到了100%。特征融合对视觉上相似手势0、m、n、s、t的识别正确率有24%~53%不等的提升,表明EMG时域特征的融合增加了相似手势之间的差异性;对EMG时域特征识别正确率较差的手势c、e、h、y等有良好的识别效果,正确率都在90%以上,其中c、e、y等的正确率提高到了100%。
与串行融合特征相似,基于SLMF方式的手势识别正确率总体上高于融合前单一特征。由图6可以看出,该方法虽然部分字符识别的正确率较高,但是有11种手势的正确率下降明显,如手势1的正确率比融合前单一EMG时域特征识别方法下降了40%,手势b的正确率下降了16%。其原因是,当分类类别过多以及类别之间差异性不大时,分类器无法对正确的类别做出坚定的选择,使得正确类别与相似类别的评判分数相近。以SLMF为代表基于权重系数的决策级特征融合无法有效处理上述情况,甚至会因为权重而提高相似类别的评判分数,使其大于正确类别,导致融合后正确率的降低。
串行融合方式的特征融合则会提供更多的特征,增加相似样本之间的差异性,促使分类器做出正确的选择。串行融合特征下唯有手势q的正确率相对于单一特征下降了7%,正确率降到90%,特征的融合对极个别手势的差异性带来一定损失。
特征融合后与特征融合前的总体正确率对比如表3所示。本文串行融合特征总体识别率相对于单一HOG特征提高了33%,相对于EMG时域特征提高了16%。相对于SLMF融合方式提高了9%。基于串行融合方式,融合特征的手势识别方法对手势识别正确率有明显提升。

表3 总体正确率对比Table 3 Comparison of overall accuracy
为验证串行融合特征的高效性,提高手势图像信息单一HOG特征的有效维数到576维和2 304维,与串行融合特征进行对比实验,不同种类手势的识别正确率和总体正确率如图7、表3所示。
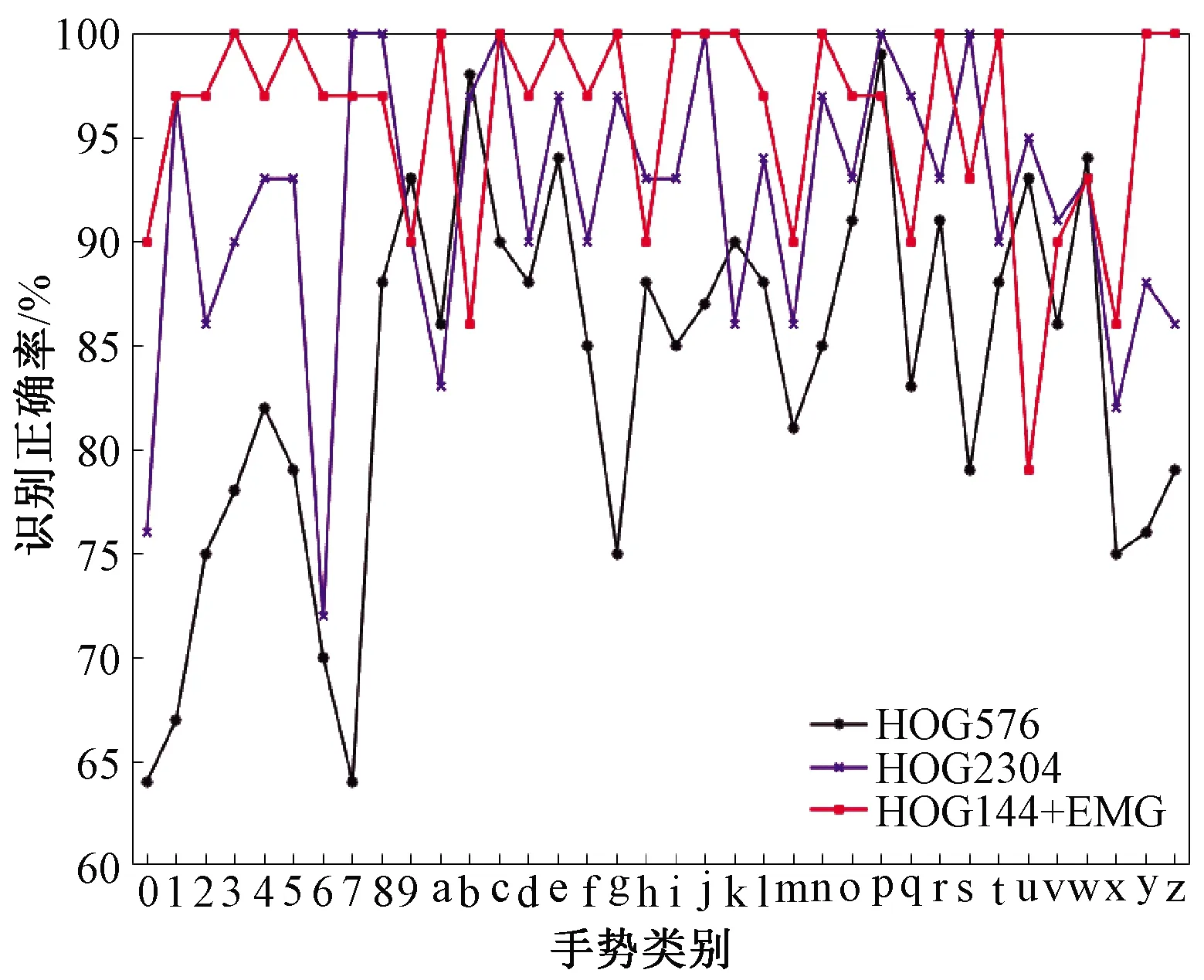
图7 与高维HOG特征的分类识别正确率比较Figure 7 Comparison of classification accuracy with high-dimensional HOG features
对比上述实验结果可知,随着HOG特征数据维数的增加,识别正确率虽然也在提高,但是提高幅度越来越小。相较于576维的HOG特征,串行融合特征向量只有184维,分类别手势识别正确率普遍有提高,总体正确率比其要高了12%。直至HOG特征向量达到2 304维,此时HOG特征的数据量是串行融合特征的12倍,其总体正确率仍比特征融合低4%。
在各类别手势中随机选取10组样本数据,共计360组样本数据,分别放入6种不同特征类型对应的模型中,记录不同特征类型下360组样本数据计算识别过程所需时间,每组样本数据的平均计算耗时如图8所示。

图8 计算耗时比较Figure 8 Comparison of calculation time
图8实验结果中,本文串行融合特征下对每个样本的平均识别时间是0.274 ms,融合前144维单一HOG特征是0.272 ms,2 304维HOG特征是2.709 ms,基于SLMF方式的特征融合的平均耗时是0.607 ms。结合图8计算耗时与表3中总体正确率,有以下分析:①本文串行融合方法的计算耗时与融合前144维单一HOG特征相近,总体正确率却由63%提升至96%;②提升单一HOG特征至2 304维,单一HOG特征比串行融合特征总体正确率低4%,计算耗时是本文串行融合特征的将近10倍;③以基于SLMF方式为代表的决策级特征融合由算法特性决定,需要多个模型参与识别,其计算耗时是多个模型计算识别时间的总和,故该算法虽然与本文串行融合特征维数相同,但计算耗时是本文方法的2倍多。相对于本文串行融合特征96%的总体正确率,该方法为87%,比本文方法低9%。
4 结论
本文提出一种融合视觉HOG特征和肌电信号时域特征进行手势识别的方法,实验结果表明:在识别手势种类多达36种的情况下,特征融合后的识别正确率明显高于融合前单一特征。与高维HOG特征对比表明,特征融合能够以较少的特征数据量完成对手势信息更完善的描述,减少计算量,有效提高正确率。
猜你喜欢
电声技术(2022年7期)2022-09-23
医学食疗与健康(2022年3期)2022-04-23
哈尔滨工程大学学报(2021年10期)2021-11-05
红领巾·萌芽(2019年9期)2019-10-09
军事运筹与系统工程(2019年4期)2019-09-11
宇航计测技术(2019年1期)2019-03-25
小学阅读指南·低年级版(2017年6期)2017-06-12
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
数学大世界·小学低年级辅导版(2010年9期)2010-09-08
