
中西方媒体“人物故事”文本的文体特征对比分析
2021-05-22 15:45:46黄婷婷
沈阳工程学院学报(社会科学版) 2021年2期
蔡 强,黄婷婷
(江西理工大学外国语学院,江西赣州 341000)
“讲好中国故事,传播好中国声音”是2013 年全国宣传思想工作会议上提出的新要求,《“十三五”规划纲要》提出了“讲中国故事是时代命题,讲好中国故事是时代使命”的新理念。十八大以来,党和国家领导人多次强调讲述好中国故事是国际传播的最佳方式。“讲好中国故事”的一个重要方面,就是挖掘和讲述普通而伟大、生动有趣的中国人生活和奋斗的故事。黄友义提出,面向外国受众谈及中国梦,应多围绕13 亿人的个人追求展开叙述,淡化国家梦的概念,运用国际化的表述方式和外国读者能够理解的话语体系是必备要素[1]。
2016 年12 月28 日,中国澎湃团队正式上线了全英文的互联网产品——“第六声”。该媒体包括Deep Tones(深度报道)、Rising Tones(即时新闻)、Broad Tones(特邀评论)和Vivid Tones(图像影音)四大板块,涉及115 个子话题。内容立足中国,面向海外,以“以小见大,润物细无声”的方式讲述中国故事,目标受众包括全世界的各政、商、学界和对中国怀有好奇之心的人士。“第六声”内容定位不局限于中国一线城市,关注焦点扩散至二三线城市,人物选择具有跨地域、跨阶层和跨年龄的特点。媒体机构在塑造国家形象、讲述中国故事的时候要注重内容的情感带入,情感交流是对外传播的最高境界[2]。“第六声”正是秉持着讲述“中国人的生活和人生,中国人所有的爱和情感”的宗旨,以更具人性关怀的角度和情感的温度传播中国声音。
中国在融入全球化的今天,既要在促进全球经济增长上有所作为,也要在文化上掌握一定的话语权,而为达到此,必须提升中国文化的软实力[3]。西方长期处于国际舆论格局的强势地位,拥有主流叙事模式,汇集庞大群体的共同价值观。中国如何突破困境,开辟传播中国声音的道路,以获得全世界的情感认同与价值认可,亟待我们思考与解决。“讲好中国故事”,不仅需要建立起高度的文化自信,还需在思想内容方面加强规划和深化,在语言表达和文体风格方面也应该进一步分析探索,力求让外界正确了解中国,真正提升中国文化软实力,构建融通中外的话语体系。
一、语料库文体学研究方法
文体学兴起于20 世纪初,以现代语言学原理为基础,专注于考察和描述多种主要文体在语音、句法、词汇与篇章层面的语言特征,目的在于帮助学者了解各种文体所阐释的内容和语言对场合的适合性[4]。20 世纪60 年代,语料库开始应用于语言研究,以语料收集的形式,对语言现象展开描写和分析[5]。随着计算机技术的发展,基于语料库的研究方法愈发成为一项学界认可的研究范式。语料库语言学和文体学具有共同点,它们都以语篇语言的真实状态为前提,结合了描写和阐释方法,注重研究过程和结果的客观化,共同关注形式与意义的关系。两者的进一步融合,语料库文体学应运而生。语料库文体学运用语料库的统计量化手段,对各类真实语料文本的文体特征进行定量描写和定性分析。杨惠中认为,与传统的语篇分析相比,以语料库形式开展的篇章分析是具有批量式、静态、从形式到意义、微观与宏观互动的量化研究[6]。《语料库文体学:英语书面文本中的言语、书写与思想表达》由Elena Semino和Mick Short撰写,初步构建了语料库文体学研究的方法论,是语料库文体学领域的阶段性总结[7]。文体有广狭二义,狭义指文学文体,广义指一种语言的各类文体。大部分学者开展的语料库文体学研究大都集中于狭义的文学文体学和翻译领域,关于非文学领域的语料库文体学研究,尤其在人物故事文本方面的研究尚不多见。
本文运用语料库文体学研究方法,针对中西方媒体“人物故事”文本展开文体特征的对比分析。语料抽样来源于“第六声”和“经济学人”,前者是以英文记录“日常中国”的中国媒体,后者是以独特深度报道和精湛写作风格著称的英国媒体。首先,在这两个媒体的官网上分别下载175篇2017-2020年关于“人物故事”的文本,“第六声”的语料共涉及25 个标签,包括艺术、商业、慈善、教育、LGBT 等栏目,经济学人的语料选取自“Obituary”栏目,其名称与中文语境的“讣告”不完全对等,应理解为人物传记或趣闻。抽样的原则是收录完整的段落和句子,确保每篇的完整性。随后对收集的语料进行噪音处理和词性赋码(CLAWS),最后建成一个基于中西方媒体“人物故事”文本英语可比语料库,共350篇,计424,401词。本文使用语料库软件Wordsmith 7.0、AntConc3.5.7.0 和统计工具Chi-Square Calculator(梁茂成开发),在真实语料的基础上开展文体特征的对比与分析。
二、文体特征对比分析结果
本文基于自建的“中西方媒体‘人物故事’文本英语可比语料库”,从词汇、句法和语篇三个层面,对“第六声”和“经济学人”的“人物故事”英语文本进行文体特征的比较与分析。
1.词汇层面
(1)词汇长度。平均词长指文本中所使用词语的平均长度,以词语的字母数为计算标准。词长标准差指文本中每个单词长度与平均词长的差异。一般而言,平均词长的数值越高,表明文本中使用的复杂词就越多。陈建生分析了Brown 语料库三类不同文体的文本,发现学术类文本(平均词长4.93,标准差2.87)正式程度高于报刊类文本(平均词长4.73,标准差2.59)和小说类(平均词长4.31,标准差2.18),由此判断出平均词长和文本正式程度存在相关性[8]。将“第六声”与“经济学人”的文本分别导入Wordsmith 7.0,运行WordList 功能,得到两个语料子库的平均词长和词长标准差。从表1 数据可得,“第六声”的平均词长和词长标准差均高于“经济学人”,表明前者的用词复杂程度和正式程度相对较高。

表1 两个语料子库的平均词长及词长标准差
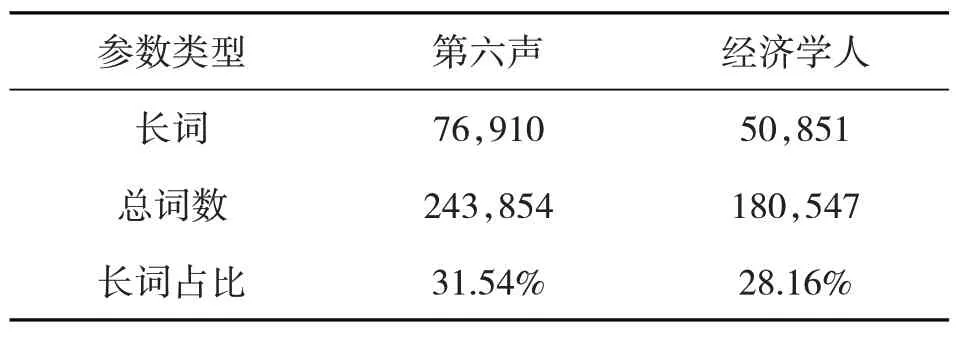
表2 两个语料子库的长词总数与占比
另外,英语中通常将6 个字母以上的词称为长词。表2 数据表明,“第六声”子库的长词占比高于“经济学人”,说明“第六声”文本使用的长词较多,也进一步证实“经济学人”更善用小词,文体更为活泼。
(2)词汇密度。词汇密度由Ure 提出,指文本中的词项数量(即实词数量)与该文本的单词总量之比[9],计算方法为:词汇密度=实词数/词汇总数×100%。英语中的实词指名词、实义动词、形容词和副词。Halliday 表示,词汇密度是评定书面文本复杂程度的计量参数[10]。同时,实词具备传递信息的主要功能,因此文本中实词的占比反映该文本信息负载量的大小。“信息负载”最早由Nida 于1964 年提出,将其定义为“信息难度”[11]。利用CLAWS 软件对“第六声”和“经济学人”两个语料子库进行词性标注后,运行AntConc3.5.7.0 的Word List 可得两个语料子库的实词总数,随后根据计算公式得出词汇密度。为区别两个语料子库数据之间的差异是否具有统计学意义,因此引入卡方检验。卡方检验可以检测两个或多个分类变量之间相关性是否显著,若卡方值越大,二者偏差程度越大;反之,二者偏差越小。R·A·Fisher 提出的p 值(p-value)也常用于检验组间的数据是否具有显著性差异。通常会设定显著性水平为0.05,若p 值<0.05,差异具有显著统计学意义,若p 值>0.05,表明两个变量无显著性差异。通过梁茂成开发的卡方检验软件,将数据导入后可直接得出卡方值与p值。

表3 两个语料子库的实词总数及词汇密度
由表3 数据可知,两个语料子库统计的各组数据差异显著(卡方检验p=0.000<0.05)。“经济学人”词汇密度数值高于“第六声”,表明其实词占比较多,其信息负载和文本难度也相对较大,这也符合“经济学人”的目标读者主要为精英阶层的缘由。而“第六声”作为外宣的新兴媒体,面向更宽泛的读者群体,因此撰稿人可能考虑到受众广泛性,为提高文本易读性,适当降低文本阅读难度,以便拓宽读者受众群体。
(3)类符/形符比。语料库语言学中,类符是文本中所使用的不同词汇的种类,形符是文本中所有词汇的总数量。类符/形符比(type/token ratio,TTR)是指文本中所使用的不同词语的数量与词语总数量间的比值,计算公式为类符/形符比=(类符数/形符数)×100%。由于常用的不同词汇数量有限,文本长度可能会有较大的差异,因此Scott提出采用标准化类符/形符比(standardized type/token ratio,STTR)作为计量标准,计算方式以一个文本中按每1000 词算出一个TTR,然后再取所有TTR的平均值[12]。标准化类符/形符比值越大,表示该文本词汇重复率低,使用不同词汇的数量越多,词汇变化性和多样性程度高,反之亦然。
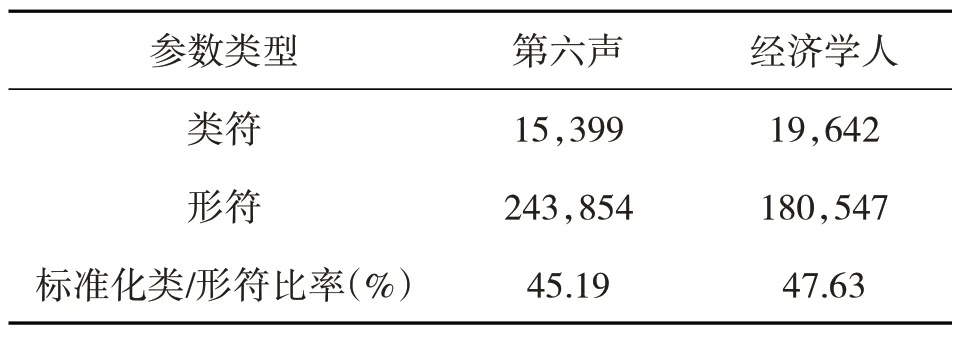
表4 两个语料子库的类符与形符比
根据Wordsmith7.0 中的WordList 功能,研究者得到两个语料子库的类符与形符数及标准类符与形符比率。表4 数据表明,“第六声”文本的标准化类符/形符比低于“经济学人”,说明“第六声”所使用的不同词汇量相对较小,词汇重复率高,词汇多样性程度低于“经济学人”。
(4)高频词参数。高频词指反复出现的一定数目的相同词汇,即语料库中出现频率较高的词。Laviosa 将高频词界定为“一个词项出现频率至少占库容的0.10%以上的词”[13]。参照此定义,设定高频词所占比例的数值≥0.10%。借助Wordsmith 7.0 制作词表,查询Frequency 列表,得出“第六声”和“经济学人”的高频词数据。
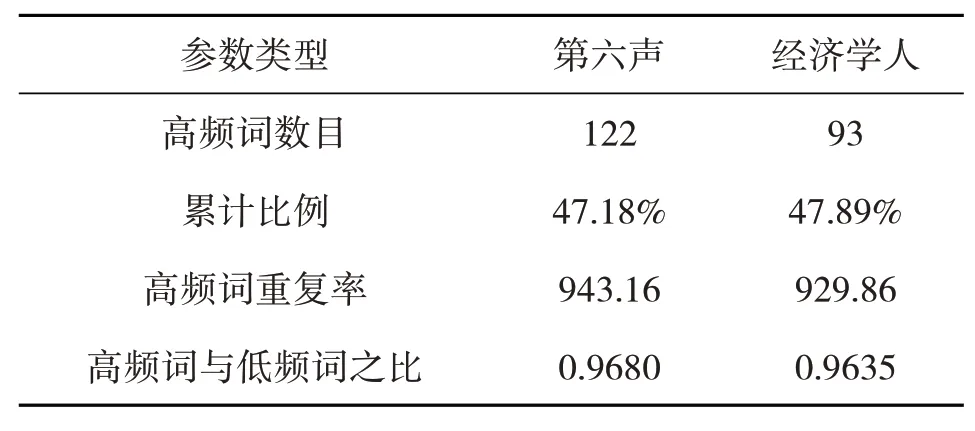
表5 两个语料子库的高频词数据
根据表5,两个语料子库高频词的数目存在一定差距,“第六声”的高频词重复率要高于“经济学人”子库(943.16>929.86),同时“第六声”子库的高频词与低频词之比也要高于“经济学人”子库(0.9680>0.9635)。数据结果与标准类符/形符比的结果相符合,“第六声”标准化类符/形符比较低,同时包含更多高频词,表示其词汇重复率比经济学人高,词汇变化幅度较低。
2.句法层面
(1)平均句长。平均句长指一个篇章中的句子含有词语数量的平均值,计算公式为:平均句长=形符数/句子数。句长标准差指句子的长度在平均句长左右浮动的程度,标准差值越高,表明文本中句子长短变化越大,句式更为灵活,可读性也就越强。平均句长和句长标准差是常用来衡量作者文体风格的参数类型[14]。句子长度与可读性存在相关性。借助Wordsmith 7.0 的统计功能,得出两个语料子库的平均句长。“经济学人”的平均句长数值,说明“第六声”文本使用长句更为频繁。此外,“第六声”的句长标准差数值低于“经济学人”的句长标准差,说明第六声的句子长短变化幅度小,句式不如经济学人灵活多变,可读性相对较差。李长栓指出“简明英语”的两项基本原则:使用简单句型以及限制句子长度[15]。结合“第六声”更常用长句以及句子长短变化程度低的特点,“第六声”需多考虑句子内部的设计,注意句式长短结合,以增强可读性。

表6 两个语料子库的平均句长数据
(2)句子结构类型。英语句子按其结构可分为简单句、并列句和复合句。简单句只有一个主谓结构,并列句用并列连词将两个或两个以上的简单句连在一起,复合句由从属连词将两个或两个以上简单句连接在一起。英语连词具有结构连接和语义连接两种主要功能[16]。在故事撰写层面,使用连词可适当缩小阅读难度,让文章更连贯、更清晰。将经过词性赋码的两个语料子库导入AntConc3.5.7.0,运行其Word List功能,检索并列连词(CC* CCB*)和从属连词(CS* CSA* CSN*CST*CSW*)的数量。
数据显示,“第六声”文本使用从属连词和并列连词的占比低于“经济学人”,表明“经济学人”更善?于使用并列句和复合句衔接文本,其信息单元之间的逻辑和语义关系更加紧密和清晰,也有利于读者更有效地理解句段和语篇。前文研究得出“第六声”的平均句长要长于“经济学人”,但其句子内部架构却相对松散,逻辑不如“经济学人”连贯,可读性相对较弱。
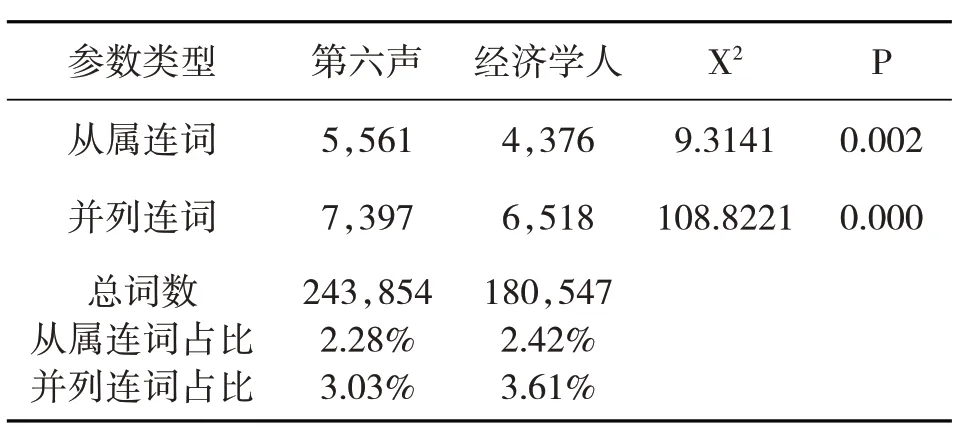
表7 两个语料子库的相关连词数据
3.语篇层面
(1)文本长度。文本长度在一定程度上可以反映篇章文体特征。一般而言,同一体裁,不同文本的篇幅可以说明信息负载的大小。

表8 两个语料子库的平均篇长数据
表8 数据显示,“第六声”的平均篇长和篇长标准差数值均高于“经济学人”,表明“第六声”更倾向于用长篇幅撰写人物故事,每篇长度上下浮动幅度较大。结合先前研究得出“第六声”实词数量比“经济学人”少,即词汇密度低于经济学人,信息负载量较小,这与文本长度越长,信息负载量越大的结论有所冲突。综合判断可知,就“第六声”而言,其文本长度比“经济学人”偏长,但实词数量却占比小,说明其人物故事撰写的信息量不够充分,内容的翔实度还有待增加。
(2)语篇衔接。韩礼德指出,衔接是语义概念,指语篇语言成分之间的语义联系,利用衔接手段可实现语篇上下文的逻辑连贯[17]。逻辑联系语,作为一种可以表示句间多种语义关系的衔接手段,呈现方式包括词、短语或分句。词包括连词和连接副词,分句包括非限定分句和限定分句。逻辑联系语是各种逻辑意义的连接手段,可实现语篇中两个或多个句子之间的逻辑联系。本文选择以词语为衔接机制的逻辑联系语为检索项,将词性赋码的两个语料子库导入AntConc3.5.7.0,运行其Word List 功能,检索以连词(并列连词与从属连词)和连接副词(RGQ*RGQV*RL*RRQ*RRQV*)为衔接形式的逻辑联系语数量。

表9 两个语料子库的逻辑联系语数据
数据表示,两个语料子库在从属连词、并列连词和连接副词都存在显著差异。“第六声”的逻辑联系语占比低于“经济学人”,说明“第六声”在篇章的衔接性方面不如“经济学人”。综合以上数据调查,“第六声”文本使用并列句、复合句和逻辑联系语的频率低于“经济学人”,说明其句子、段落和篇章层面的连贯性不及“经济学人”,篇章的衔接性及紧凑性有待加强。
(3)叙事视角。叙事视角是语篇构建的基础,文本的撰写会基于不同的叙事角度,实现其故事主题与情感的传递。人称代词是语篇连贯的一种手段,一般而言,第一人称视角有助于增强故事的真实性,搭建真实性与主观情感融合的叙事结构。第二人称视角使篇章的叙事更具有互动性。第三人称视角则是以旁观者的视角进行观察与叙述,具备客观性的同时也融合了经历者本身的声音。申丹认为叙事视角可归为四类:零视角指传统的全知叙述视角,即作者掌控、洞察一切;内视角包括第一人称的经历型叙事视角和第三人称的有限视角;第一人称外视角指第一人称叙述者追忆往年的回顾型视角和处于故事边缘的第一人称见证人视角;第三人称外视角指外部观察者视角[18]。基于语料库的叙事视角研究侧重于分析叙事作品中人称代词和动词应用趋势,并基于此来考察作品采取的叙事角度[19]。本文选择通过检索人称代词在两个语料子库的数量,判断各自所属叙事视角的特点,以人称代词为检索项,将词性赋码的两个语料子库导入AntConc3.5.7.0,运行其Concordance 功能。检索项目包括第一人称(I,we)、第二人称(you)和第三人称(he,she,they)。

表10 两个语料子库的人称代词
数据显示,三组数据的p 值都小于0.05,说明各组间的数据具有显著差异。“第六声”选用第一人称的数量明显多于“经济学人”,说明其文本的撰写携带更多主观性因素,更倾向于透过人物主角的口吻,直接地呈现人物故事。第一人称的使用场景多以直接引语形式展开,同时以带有主观性的叙述为主,其中包括许多人物本身的追忆片段。相较而言,“经济学人”的第三人称数量多于“第六声”,说明其更善于使用第三人称,即叙述者从第三方更为客观的角度撰写人物故事。两个语料子库的第二人称数量都相对较少,说明这两类媒体较少使用互动性的文笔撰写人物故事。
总体而言,根据申丹对叙事视角的分类方法,“第六声”倾向于第一人称叙事外视角和第三人称外视角相结合,第三人称外视角居多。“经济学人”选用第三人称的数量远远多于第一人称和第二人称的数量,说明其叙事视角主要基于外部观察者视角,属于第三人称外视角。叙述者选择减少主观性的叙述,转而采用客观的、自由度更高的叙事视角。
三、结语
本文从词汇、句法和语篇三方面,针对“第六声”和“经济学人”中的人物故事文本的文体特征进行了比较与分析,结果显示两者差异较大。“第六声”具有词汇相对复杂、正式,词汇多样性程度较低,文本难度和信息负载量相对较小,句式不够灵活、紧密,逻辑连贯性较差,篇章衔接性和可读性较弱,整体语言表达不够地道等特征。
要“讲好中国故事”,除了文本选材和编撰上坚持原创性和真实性外,还需要掌握英文的叙事语境,在词汇、句法和语篇等微观层面向西方媒体学习并借鉴。在词汇层面,“第六声”需要学习“经济学人”善用小词,增强文体的活泼性,提高实词占比,传递饱满的文本信息,丰富词汇的多样性。在句法层面,“第六声”应多采用长短句结合的形式撰写故事,增强句子内部的弹性变化,使文章错落有致。英语常用连接词,属于形式化程度高的语言,为符合国外受众表述方式,“第六声”应适当增加连接词,提高可读性。在语篇层面,“第六声”需要丰富文本的详实度,关注篇章内部搭建,学习运用衔接手段,增强语篇的紧凑性和逻辑性。“第六声”善于把描述镜头转向普通且平凡的小人物,以较为客观的角度观察民众的生活百态,有其自身的禀赋优势,但在具体表达层面,仍需要专注创造优质文本,增强传播能力,吸引西方受众更大的阅读兴趣。
猜你喜欢
疯狂英语(双语世界)(2023年3期)2023-11-16 02:24:36
金秋(2022年15期)2022-11-17 07:46:58
疯狂英语·初中天地(2021年4期)2021-06-09 06:50:58
老年博览·上半月(2020年7期)2020-07-20 06:36:01
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
西夏学(2016年1期)2016-02-12 02:24:02
女性天地(2015年7期)2015-05-30 10:48:04
首都外语论坛(2014年1期)2014-03-20 15:21:28
37°女人(2013年12期)2013-06-10 06:29:36
当代修辞学(2012年2期)2012-01-23 06:44:12
