
基于Python的中国大学MOOC网站爬虫系统设计与实现
2021-04-14 08:20邹兴宇
课程教育研究 2021年30期

【摘要】当今已进入大数据时代,网络爬虫成为数据获取的有效手段,获得广泛应用。但在教育领域,尤其是职业教育领域的相关应用较少。随着国家职教改革各项政策的逐步落实,职业教育目前正处于快速发展期,职业教育课程资源建设也显得尤为重要。本文参考Python的Scrapy爬虫框架,利用Selenium模拟浏览器执行网页操作,最终设计出一个简洁、实用的爬虫系统。对中国大学MOOC网站进行相关课程信息的爬取和分析。通过数据分析,了解职业教育线上课程资源建设情况,对未来职业教育慕课、精品课程建设提出建议。同时,本文提供了爬虫系统在教育领域应用的成功经验。
【关键词】Python 爬虫 Selenium MOOC 职业教育
【基金项目】福建省教育厅中青年教师教育科研项目(科技类)“基于Scrapy框架的网络爬虫系统的设计及其在教育领域的应用”(项目编号:JAT191700)。
【中图分类号】TP393.092;TP391.3 【文献标识码】A 【文章编号】2095-3089(2021)30-0077-02
一、Python及爬虫介绍
(一)网络爬虫
网络爬虫(Web crawler),也称为网络机器人(bot)。其是一种可以实现网页数据抓取的自动化程序,通过多种手段收集网络数据的方式,不光是通过与API交互或者直接与浏览器交互的方式。最常用的方法是写一个自动化程序向网络服务器请求数据,然后对数据进行解析,提取需要的信息。[1]网络爬虫的思维模式就是模拟浏览器向服务器发出请求,接收到请求数据后再进行解析。一般而言,基础爬虫的两大请求库urllib和requests。但是,目前越来越多的网站页面是经过JavaScript渲染的,当requests在抓取页面时,得到的结果和在浏览器中看到的将不一样。为解决以上问题,本文选择Selenium实现爬虫,它是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。[2]
(二)Python语言
随着大数据、人工智能等领域的快速发展和广泛应用,Python语言的优势凸显,变得比以往更加流行。在2021年7月的语言排行榜单升至第三位,近年来与C、Java、C++一起稳居前四。从编程语言的市场份额可以看出,一定时期内使用Python语言的人数越来越多。在爬虫领域,因其语言简单易懂、支持多平台、拥有优秀的网络爬虫库等优势,成为绝大部分网络爬虫设计的首选,可以说是网络爬虫领域的第一编程语言。
二、爬虫具体设计及实现
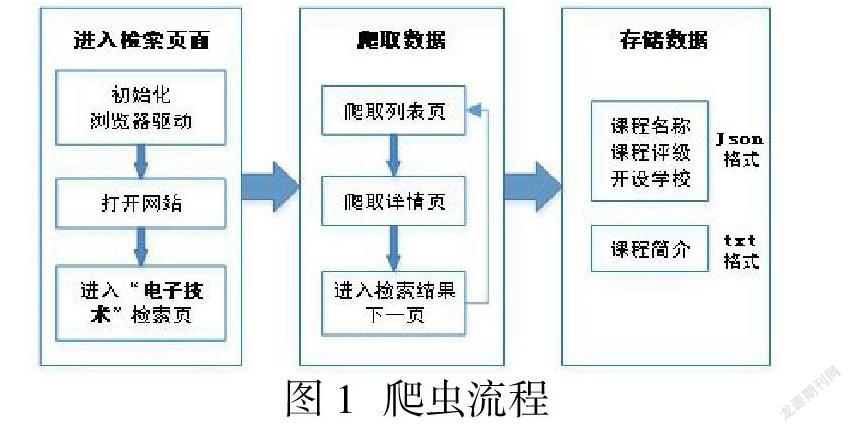
(一)爬取流程
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。其架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需求。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等。[2]
基于对Scrapy爬虫框架的学习和研究,本文自主设计了一个更加实用和简洁的爬虫流程。该设计利用Selenium抓取中国大学MOOC网站课程数据,并解析出课程的名称、评级、开课学校、课程介绍等信息,并保存为Json和txt文件形式。本爬虫系统的自动化工作流程如图1所示,分为三个阶段:进入检索页面、爬取数据、存储数据。首先,在进入检索页面阶段,利用Selenium依次完成初始化浏览器驱动、打开网页、进入指定关键词“电子技术”相关课程检索页。另外,经实际测试及性能分析,这里选用Firefox浏览器。其次,在爬取数据阶段,依次要完成检索结果列表页信息、列表页中每个课程的详情页相关信息、进入检索结果的下一页面等动作。周而复始,直到爬取完检索到的全部课程信息。最后,进入存储数据阶段,为了便于数据分析,将课程名称、课程评级、课设学校信息保存为Json格式;对于课程简介数据量大,保存为txt格式。
(二)爬虫程序设计
1.初始化。根据本设计采用的爬虫技术及数据存储方式,导入以下库及函数。例如:webdriber用于初始化浏览器;WebDriverWait用于设置浏览器响应等待最长时间;json用于将数据存储为Json格式。同时,完成相关参数的初始化。例如:logging.basicConnfig完成日志的配置;INDEX_URL完成网址初始值设置。
2.检索结果首页面的加载及跳转。爬取网页的初始地址为“https://www.icourse163.org/search.htm?search=电子技术#type=30&orderBy=0&pageIndex={page}&courseTagType=null”,经分析发现检索结果的每一页地址的page参数呈现1、2、3…累加规律。同时,考虑到爬虫过程受到网络情况的影响,设置页面加载最长等待时间及超时报错。但是,经实际测试MOOC网站发现,通过更新page参数获得新地址,無法实现页面的跳转。所以调整策略为通过Selenium模拟点击“下一页”按钮实现页面跳转。
同时,在检索结果的每一页,进行数据的初步解析,爬取当前页检索课程名称、课程评级等信息。
3.爬取每一门课程的详情页。进入每一门课的详情页后,分析网页源码,利用CSS选择器定位到“课程描述”。爬取后关闭详情页,再重新定位回当前的检索结果列表页。然后,重新进入新课程的详情页爬取数据。如图2所示,在分析检索结果及HTML代码时发现,部分检索结果并非常规课程,可能是讲座、考试辅导等等,如何识别这部分的检索结果和避免其对爬虫数据的影响呢?本文在代码设计时,因此类非常规课程未提供“课程描述”部分,所以利用这一点,在代码中加入try-except模块进行处理,成功达到目的。
4.数据存储。本设计通过构建字典的形式存储信息,其中将课程名称、课程评级(国家精品或职业教育课程)存储为JSON格式、课程描述存储为txt格式。具体实施步骤为数据提取、数据存储。
5.问题解决。(1)爬取策略过滤了培训、讲座等非课程的信息,保证了数据的有效性;(2)有效规避了网站的反爬限制,保证了爬虫的顺利进行;(3)实现模拟网页操作、数据抓取、存储、数据分析的全流程。
三、实验分析
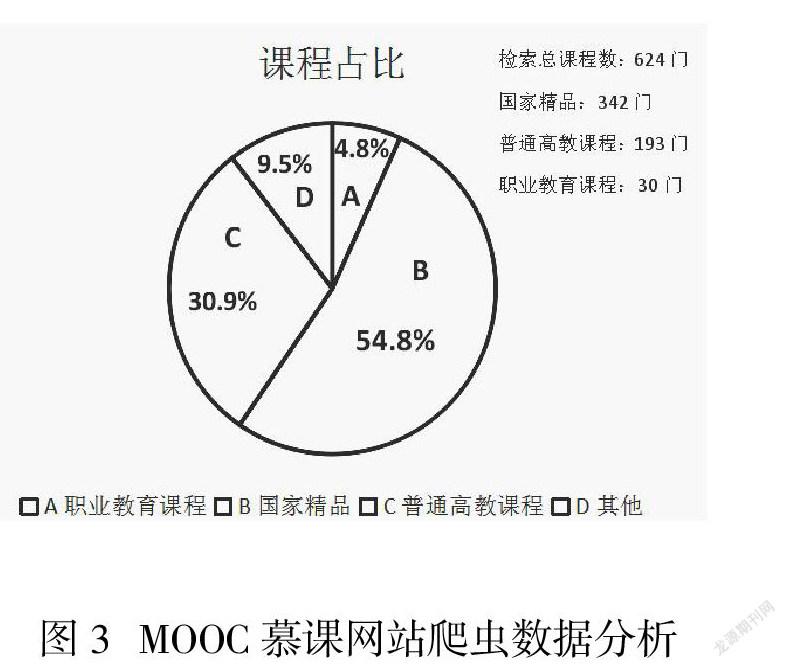
本文在中国大学MOOC慕课网站,检索指定关键词“电子技术”相关课程信息。利用网络爬虫对检索的全部课程信息进行数据抓取。如图3所示,检索相关课程共624门,其中国家精品课程为342门,占相关课程的54.8%;获得职业教育课程认定的仅为30门,占相关课程4.8%。数据表明,普通高等教育的慕课资源建设已非常成熟,拥有一大批优质课程。但是,针对职业教育的课程资源严重偏少。且绝大部分是高职课程,中职慕课资源更加匮乏。
新时代国家大力推动职业教育的发展,职业教育已经成为和普通教育同等地位的类型教育,未来将在服务国家产业和经济发展方面提供有力支撑。按照国家政策,中等职业技术学校入学人数增加,高职近几年也在不断扩招,接收职业教育的人數将越来越多。所以打造和丰富相关职业教育的学习资源,必须提上议程,以适应新时代的发展需求。同时,国家推动一师一优课,一课一名师。作为职业教育的教师,应努力践行三教改革,打造精品课程、开发出更多的优质教学资源。
四、总结
综上所述,本文设计了一个简洁、实用的基于Selen⁃
ium技术的爬虫系统,实现对中国大学MOOC网站课程信息的有效爬取。通过数据分析发现职业教育的优质慕课资源相对偏少,仅占到整个调研数据的14%,尤其是中职的更加匮乏,通过此研究结果凸显了职业教育慕课资源建设的紧迫性。最终,本文的研究成果拓展了网络爬虫在教育领域的应用,一定程度上促进了爬虫技术的发展和职业教育课程资源建设。
参考文献:
[1]瑞安·米切尔.Python网络爬虫权威指南[M].北京:人民邮电出版社,2020:56-57.
[2]刘宇,郑成焕.基于Scrapy的深层网络爬虫研究[J].软件,2017,38(7):32-33.
作者简介:
邹兴宇(1984年-),男,汉族,黑龙江绥化人,讲师,硕士研究生,研究方向为物联网、人工智能。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
电子测试(2018年1期)2018-04-18
电子制作(2017年9期)2017-04-17
职业(2016年10期)2016-10-20
职业(2016年10期)2016-10-20
考试周刊(2016年76期)2016-10-09
科技视界(2016年20期)2016-09-29
