
基于单样本学习的多特征人体姿态模型识别研究
2021-04-01 07:24李国友李晨光王维江杨梦琪杭丙鹏
光电工程 2021年2期
李国友,李晨光,王维江,杨梦琪,杭丙鹏
燕山大学工业计算机控制工程河北省重点实验室,河北 秦皇岛 066004
1 引 言
人体姿态识别是计算机视觉研究的热门课题,为人机交互、虚拟现实等领域的发展提供技术支持[1]。人体运动动作的时变性以及运动场景的复杂变化性,导致人体姿态识别的实时性、准确性和鲁棒性不理想。因此,如何实时准确地捕捉和识别人体姿态在计算机视觉领域引起了极高的关注。
目前,人体姿态识别研究方法主要有基于统计的算法[2](隐马尔科夫模型(HMM)、动态贝叶斯网路(DBN)),基于模板的算法(模型、动态规划、动态时间规整[3](DTW)),以及基于语法的算法(有限状态机(FSM)、上下文无关文(CFG))。在针对人体姿态研究的算法中,基于模板匹配相比其他算法具有更好的识别准确性和鲁棒性,但是模型的建立需要大量数据且特征计算复杂[4]。李红波等[5]提出了基于Kinect 骨骼数据的静态三维手势识别,通过获取手部角度特征向量确定待测姿态模板,待测姿态与姿态模板进行最佳姿态匹配,由于行为时间间隔的持续性和图像噪声影响,每帧图像无法实时地检测识别。Zhe 等人[6]提出了零件相似性的实时多人人体姿态识别,该算法采用自下而上(down-top approach)方法,首先对人体关键点进行检测,其次建立矢量场推测关键部位并进行连接,最后采用深度学习网络结构构建特征图像集进行姿态预测;但该算法存在一定的局限性,只考虑了肢体关键点的位置信息,忽略了旋转、尺度不变性,因而只能在局部区域进行姿态预测连接。Pfitscher 等人[7]提出了基于卷积神经网络和FastDTW 的Kinect 手势控制机器人的移动,对从Kinect 上捕捉获取图像的每帧关节信息进行提取和处理,建立姿态动作所有帧派生图像,采用联合训练和个人训练进行卷积神经网络(CNN)训练,最后将移动机器人系统添加到训练好的系统中,根据姿态算法的分类结果控制机器人的移动。赵海勇等人[8]提出了基于视频流的运动人体行为识别,采用帧间差分法和改进C-V 模型算法进行运动人体分割,检测运动目标的轮廓曲线,对分割的轮廓进行加权运动串分类,构建动作串时对不同的姿态赋予不同的权重,最后通过对全局运动信息和局部特征信息的异常行为进行识别,该方法可有效地将全局信息和局部特征信息进行互补加权串联融合,特征点更加明显,识别效果更好。Xu 等人[9]提出了多级深度运动图的人体动作识别,使用多级帧选择采样模型(MFSS),首先将输入的深度图像投影到三个正交的笛卡尔平面上,其次采用动态图和静态图(MSM)映射方法获得动态历史图像和静态历史图像来表示姿态,利用LBP 提取块的MSM 的特征信息和使用Fisher 内核整合块,最后采用极限学习机(KELM)分类器进行姿态识别。Vinyals等[10]提出了小样本学习匹配网络,设计了匹配网络(matching networks,新的神经体系结构),该网络将标记的实例映射到已标记的小型支持集,且标记的样本无需调整就能适应新的类型,并且损失函数使预测值和真实值的误差最小化。现阶段人体姿态识别的研究取得了不错的成果,但基于模板匹配的研究忽略了姿态的时序性,对于姿态的瞬变性仍然存在技术漏洞。
现阶段对人体姿态识别仍然存在未定义姿态干扰等技术缺陷,导致识别的实时性和准确性在一定程度上没有达到预期效果。因此,本文针对模型特征提取和模型数据集训练,基于单样本学习对获取的图像进行映射训练,采用关节点向量角度和距离特征以及关节点成角平面与Kinect 的XOZ平面夹角,保证姿态特征的不变性,同时在姿态识别过程中保证特征点的高契合度。该方法对定义好的姿态模型识别准确率达到98.29%,实时性也有所提高。
2 人体骨骼数据集
2.1 人体关节点简介
KinectV2 获取深度图像的原理是采用飞行时间(TOF)技术[11],传感器发射红外光通过物体反射的时间和相位差来确定深度信息。尤其在骨骼检测和跟踪方面有着强大的功能,可捕捉到25 个关节点信息,这25 个关节点能实时有效地反映出人体任意姿态[12],25个骨骼关节点如图1 所示。
图中蓝色标注代表姿态的角度和距离特征的相关关节点,这些关节点依次为SpineBase(脊柱基部)、HandLeft(左手)、ElbowLeft(左肘)、ShoulderLeft(左肩)、ShoulderRight(右肩)、ElbowRight(右肘)、HandRight(右手)。姿态的特征计算基于标注关节点的三维坐标实时信息。
2.2 人体动作识别数据集
KinectV2 动作数据识别数据集[13]可分为五种类型,每种类型既有相通性又有区别性,GAMING DATASRTS-G3D 数据集定义规划了20 个游戏动作;UTKINECT-ACTION3D DATASET 数据集基于RGB、深度和骨架节点位置定义了10 种动作;FLORENCE 3D ACTIONS DATASET 数据集定义了9 个动作;MSR ACTION3D 数据集通过记录人体动作序列,按动作的时序性记录了20 个动作;NTU RGB+D ACTION RECOGNITION DATASET 数据集利用RGB 视频、深度图序列、3D 骨骼数据和红外视频捕捉动作,但是该数据集依赖于三个KinectV2 摄像机同时捕捉,捕捉难度和数据处理分析难度大。动作类型如图2 所示。

图1 人体骨骼关节点示意图Fig.1 Schematic diagram of human bone joints
3 骨骼信息的多特征人体姿态模型识别
3.1 基本流程
人体姿态识别的核心内容为:首先,进行姿态捕捉、特征提取并标定,其中特征标定是将姿态动作标记为一个静态标签的过程,一个静态标签对应一个特定的姿态。其次,采用单样本学习模型匹配算法将待识别特征样本与训练完成的特征模板库进行角度和距离特征匹配计算,并根据设定的阈值范围进行契合度对比,阈值范围通过多次实验确定。最后,显示识别结果的过程。图3 为人体姿态识别流程图。
3.2 人体姿态特征提取
由于骨骼信息的时变性,如何将不稳定的骨骼信息进行特征标定并转换得到构建模型的特征信息是模型识别的关键。为使获取的特征信息具有良好的鲁棒性,本文提出了角度特征和距离特征。

图2 动作类型示意图Fig.2 Schematic diagram of action types

图3 人体姿态识别流程图Fig.3 Flow chart of gesture recognition
3.2.1 角度特征
由于人体运动具有高自由度和非刚性的特点,导致人体骨骼关节点运动随意性很大,没有特定的姿态作为匹配对象很难去识别,因此选取骨骼信息作为技术支撑[14]。在KinectV2 骨骼坐标系下的25 个关节点都有独立的三维坐标信息,若直接采用25 个关节点的三维信息构建人体姿态,数据集维度达到75 维,姿态表征信息冗余,计算难度非常大。过多的关节点表征使识别结果容易错乱而达不到预期效果。角度特征的提取是基于骨骼结构的不变性,关节点向量之间可以随机组合成不同的向量角,向量角既可以高度表征姿态信息,又可以将与姿态动作无关的信息进行剔除,减少了数据集维度,可有效利用骨骼信息,从而使识别准确性更高。
本文选取角度组合数量多的上肢进行特征提取,基于关节点的三维坐标值构建关节点向量,然后对关节向量组合成的夹角进行计算。本文选取HandLeft-ElbowLeft-ShoulderLeft 构建左上肢向量角和ShoulderRight-ElbowRight-HandRight 构建右上肢向量角,对两个关节向量角分别设定不同的角度构建姿态特征模板库。关节向量角如图4 所示,θ1为构建的左上肢向量角,θ2为右上肢向量角。
图5 为构建的左上肢向量角示意图,计算过程如下:
1) 获取关节点三维坐标信息如下:
HandLeft (a1,b1,c1),ElbowLeft (a2,b2,c2),ShoulderLeft (a3,b3,c3);
2) 构建关节点向量,定义左手肘到左手关节向量及左手肘到左肩膀关节点向量如下:
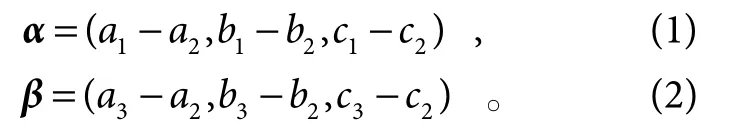

图4 关节向量角示意图Fig.4 Schematic diagram of joint vector angle
3) 计算向量α和β组成的向量夹角θ值:

基于式(1)~式(5)的计算提取角度特征构建人体姿态数据集[15],在姿态匹配识别过程,设定阈值d,当θ计算值满足取值范围(θ-d)≤θ≤ (θ+d),即识别成功。
3.2.2 距离特征
角度特征可以有效地描述人体姿态类型,但在某些情况,采用距离特征能简单快速地描述出姿态,而且能准确标记出人体关节点的相对位置,避开了角度特征的干扰性。基于关节点特征的提取,本文选取了人体骨骼比较稳定的躯干和上肢关节点,也是识别效果最佳的关节点。
本文选取 SpineBase(脊柱基部)作为参考点,Neck(脖颈)作为平面映射点,HandLeft(左手)和HandRight(右手)为距离点进行距离标定,然后计算距离点到参考点三维坐标距离。由于距离特征维度上的差异性和分离性,采用了X方向上的距离作为特征,距离特征如图6 所示。
特征距离计算过程如下:
1) 获取关节点的三维坐标信息如下:
SpineBase (x1,y1,z1),Neck (x2,y2,z2),HandLeft(x3,y3,z3),HandRight (x4,y4,z4);
2) 计算X方向上的距离,选取脖颈为脊柱基点映射点,X方向上的坐标一致,只需计算手部位置到脖颈的距离。即距离特征x1=x2,计算如下:
左手到脊柱基点的距离:


图5 左上肢向量角Fig.5 Vector angle of left upper limb
右手到脊柱基点的距离:

3) 设定定值f1和f2,比较(L1>f1) ∪(L2<f2)或(L1<f1) ∪(L2>f2),若满足设定条件即特征对比成功。本文采用综合角度特征和距离特征结合的方法,对人体姿态进行准确的标定和描述,具有旋转缩放不变性,满足了不同人、不同角度和不同位置的姿态识别。
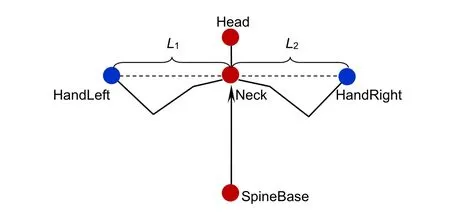
图6 距离特征示意图Fig.6 Schematic diagram of distance characteristics
3.3 姿态识别算法
在人体姿态识别过程中,姿态特征提取和动作识别尤为重要。本文提出了基于人体姿态关节点角度和距离特征的单样本学习的模型匹配算法进行动作识别。该算法的核心思想是监督学习领域的单样本学习归类,对小样本进行训练归类,即训练一个数据端到另一个数据端的分类器[16],训练的样本库模型具有高度不变性,模型匹配方法将训练完成的数据库模板与识别过程的静态数据做欧氏距离计算,选择契合度最高的样本模板所属类型作为识别结果。该算法具有计算复杂度低、实时性和准确性高的特点。
单样本学习作为小样本学习的特殊情况,每种类别只需提供一个样本作为参考模板无需依赖海量的样本数据。在单样本学习的训练集中设定了多种类型,每种类型对应一个样本,在训练过程中,随机抽取训练集中的C种类型,每种类型一个(one)样本(所有的特征点集合)构建meta-task[17],作为模型的support set(支持集)[18]输入;然后从设定的类型数据抽取batch(批)样本作为模板的batch set[19](预测对象),这种训练模式称为one-way one-shot 单样本学习。经过多次训练,可得到包含一个类型所有特征点的meta-task。单样本学习模型结构如图7 所示。
对建立好的模型结构进行参数转换,寻找已训练数据集和将要预测实验数据集的相似度,算法流程如下:
1) 训练过程:定义一个包含多个样本数据的支持集:

将测试样本数据进行分类进而得到他们各自的标签,即:

其中:a用来计算度量测试样本和训练样本的契合度,即:

其中:f为模型结构中测试样本编码,g为训练样本编码,c为计算测试样本到训练样本的匹配距离[22]。
定义一个支持集到测试数据映射为

输入一个测试数据,计算测试数据到支持集S的距离度量[23]:

将支持集样本数据嵌入模型g反复优化,也可通过修改测试样本嵌入模型f将提取的特征反复优化后得到每个姿态在不同情况下的数据集,即训练过程结束。
2) 编码样本集:对于训练样本数据集映射到预测数据的序列问题,本文选取长短期记忆(LSTM),旨在解决训练样本冗余数据的干扰、匹配过程中动作间隔和延迟时间的问题[25]。模型结构中g(θ) 是一个双向LSTM,作为单输入(对应支持集S中的每个样本(x0,x1,x2,⋅⋅⋅)双输出(mi,ni)的典型递归神经网络,将xi输入到LSTM 进行第一个编码记为g′(xi),然后对于支持集S中的样本xi进行递归编码:

图7 单样本学习模型结构Fig.7 One-shot learning model structure
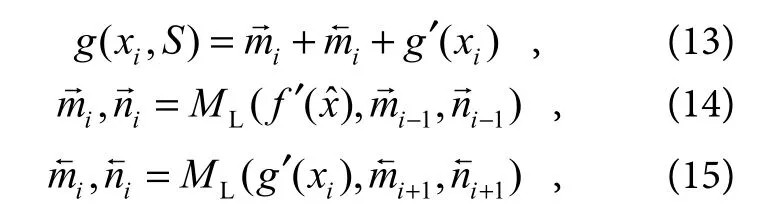
其中:ML表示长短期记忆函数,mi,ni为双向编码支持集。
3) 编码测试集:考虑到支持集S中样本xi的随机性,可能在一定程度上出现序列紊乱现象,因此设定一个嵌入函数f(θ) :

在迭代的每一步中,嵌入层f′(x) 输出值不变,保证了测试数据的完整性。
4 实验验证和分析
4.1 实验环境
本次实验硬件基于Windows 10 企业版的64 位操作系统,处理器为Intel(R) Core(TM) i5-6400 CPU 主频2.71 GHz,搭配内存为8 GB,显卡为NVIDIA GeForce GTX 750 Ti,二代Kinect for Windows 体感摄像头;软件基于Visual Studio 2017,Kinect SDK2.0,OpenCV3.4.1 视觉库。
4.2 实验设计
本文通过对人体主要骨骼关节点进行特征提取,建立模板库,采用单样本学习的模型匹配算法,实现人体姿态识别。基于角度和距离特征定义了7 种姿态,通过姿态识别结果验证本文算法的准确性、实时性和鲁棒性。
4.3 姿态识别实验
本次实验对定义的姿态进行识别验证,为了使识别效果更好,经过多次实验校正,角度特征阈值d=20,距离特征高度f1=0.45,f2=0.2时,偏差在设定值范围之内,识别效果最佳。角度特征姿态实验结果如图8 所示,图中左侧字母代表姿态标记,圆框代表模板库样本姿态,骨骼和彩色图像代表实时测试姿态,方框显示动作名称。
距离特征姿态识别实验结果如图9 所示,图片显示内容和角度特征一致,距离特征只需计算左右手关节点到脊柱基部的设定距离,即可完成姿态识别。

图8 角度特征姿态识别结果示意图Fig.8 Schematic diagram of recognition results of angular features

图9 距离特征姿态识别结果示意图Fig.9 Schematic diagram of distance feature pose recognition results
4.4 实验结果分析
本文定义的姿态动作标记为A(举起双手)、B(手臂成一字型在胸前)、C(双手叉腰)、D(左手向左伸直)、E(右手向右伸直)、F(左手举起成90°右手自然下垂)、G(右手举起成90°左手自然下垂)7 种。为验证本文算法的准确性、实时性和鲁棒性,实验过程中5 人进行不同位置、不同身高体型、不同角度的实验,姿态动作10 次/人,实验结果如表1 所示。
从表1 中可看出,动作F 和G 识别错误率相对较高。通过分析可知原因有两点:1) 特征点少,存在匹配误差;2) 测试者没有做出识别范围内的动作。实验结果表明,本文基于角度特征和距离特征的平均识别率高达98.29%,准确率较高。
4.5 算法对比
针对算法的识别率和实时性,选取六种算法作为对比对象,对比算法如下:
1) 算法1:文献[26]提出的通过提取梯度局部自相关(GLAC)特征来表征动作相对应的运动历史图像(MHI)和静态历史图像(SHI)联合表征动作的算法。
2) 算法2:文献[7]提出的基于CNN 和FastDTW进行联合训练和个别训练的方法。
3) 算法3:文献[21]提出的姿态图像生成特征代表特定的身体部位,然后将生成的特征馈送到SVM 中生成姿态学习,识别预定义姿态模型的算法。
4) 算法4:文献[20]提出的基于分割技术将动态表示和骨架特征序列匹配的识别方法。
5) 算法5:文献[24]提出的使用Gabor 小波提取图像纹理特征和梯度空间边缘分布(SEDG)计算形状特征构建扩展多分辨特征(EMRF)模型的方法。
6) 算法6:文献[27]提出的定义一个由三元素组成的姿态描述符,使用Fisher Vector(FV)对描述符进行编码的算法。
为证明本文提出算法的优异性,本文提出的算法与六种算法的平均识别率和平均识别时间进行对比,对比结果如表2 所示。
从表2 对比可得出:

表1 七种姿态识别结果Table 1 Recognition results of seven gestures

表2 七种算法识别率对比Table 2 Comparison of recognition rates of seven algorithms
1) 算法1 的平均识别率为97.3%,该算法通过联合使用运动历史图像(MHI)和静态历史图像(SHI)两种功能的动作表示方法,首先对提取的动作进行12-正规化协作表示分类器(12-CRC),然后对测试动作评估识别。该算法主要提取图像的纹理特征,将特征传递给GLAC 构建数据集,但该算法容易混淆特征相似的动作,且数据集的构建需要大量的数据作为支撑。
2) 算法2 的平均识别率为90.78%,该算法利用姿态的所有帧创建图像,进而卷积神经网络训练,在匹配控制中运用FastDTW 进行识别。虽采用CNN 对姿态训练,有效地解决了训练过程特征点丢失和冗余,但实时性和准确性并没达到预期效果。
3) 算法3 的平均识别率逼近本文识别率,为98.14%。该算法采用了主成分分析对姿态特征评估,将评估的特征馈送到SVM 生成姿态学习。该算法的高识别率依据了主要关节点的提取和评估,但同一主关节点不同姿态存在干扰性,出现误识情况。
4) 算法4 的平均识别率为97.80%,该算法将骨架特征序列划分为关键姿态和运动段姿态,构建高置信度的框架集,最后利用形状动态时间规整(shapeDTW)测量两个特征序列的运动特征段距离。该算法有效地分割骨架特征,高置信度的框架集提高了识别率,但骨架特征信息具有连续性和瞬变性,影响运动特征段的提取。
5) 算法5 的平均识别率为96.16%,该算法通过模糊推理模型从视频序列中选取单个关键图像,然后计算选取图像的纹理和形状特征,构建多分辨率的特征描述模型并通过SVM 分类器进行识别的算法。该算法对特征进行分类提取,且构建的多分辨率特征模型消弱了场景的干扰,但处理图像旋转缩放性能力和实时性较差。
6) 算法6 的平均识别率为93.07%,该算法使用3D 骨架信息构建三元素姿态描述符,使用极限学习机(ELM)对编码的描述符进行训练。该算法采用时空动作描述符构建人体姿态框架,解决了姿态识别过程中序列丢帧问题,但编码描述符的计算复杂,三元素的特征提取一定程度上导致识别时间增加,实时效果减弱。
本文算法的平均识别率相对高了几个百分点,针对算法1 特征点相似,本文从角度和距离特征进行识别,拓展了姿态动作集,且对特征相似的姿态进行标定区分;有效的特征点提取解决了算法2 数据丢失和冗余现象;解决了算法3 中姿态互扰问题;解决了算法4 关键特征提取问题,且本算法的容错率更高;针对算法5 受场景影响,本算法排除了场景的干扰且具有旋转缩放不变性,解决了算法6 中对框架模型依赖性高,且本算法特征计算量小。通过对比平均识别时间,本文算法识别时间只有32 ms,识别时间更短。本算法不仅提高了识别率,且实时性更好。
5 结 论
本文基于KinectV2 采集骨骼数据,通过对获取骨骼关节的三维坐标信息进行角度和距离特征提取,采用单样本学习的模型匹配方法,解决了特征提取和特征向量构建的问题,运用数学矢量角和余弦值将构建的特征向量组合成角度,每个姿态特征向量角设定一个匹配阈值,匹配过程中测试姿态特征向量角在阈值范围之内则匹配成功。实验结果表明,本文算法提高了人体姿态识别的抗干扰性、准确性、实时性和鲁棒性。
猜你喜欢
科学技术创新(2021年19期)2021-07-16
沈阳航空航天大学学报(2020年6期)2021-01-27
学生天地(2020年3期)2020-08-25
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
中国交通信息化(2018年3期)2018-06-13
军营文化天地(2017年6期)2017-06-28
智能系统学报(2017年1期)2017-06-01
