
基于改进双流卷积递归神经网络的RGB-D 物体识别方法
2021-04-01 07:24李林鹏AlexanderLazovik王文杰王晓华
光电工程 2021年2期
李 珣,李林鹏,Alexander Lazovik,王文杰,王晓华
1 西安工程大学电子信息学院,陕西 西安 710048;
2 格罗宁根大学伯努利实验室,格罗宁根 9747 AG,荷兰
1 引 言
物体识别是机器视觉中的基础核心内容之一[1]。由于现实世界场景中复杂的光照和背景变化,造成现有RGB 图像的识别算法难以满足当前智能化需求。因此,近年来结合RGB 图像与深度图像的识别方式成为提高目标识别率的新途径。同时,对如何理解和利用两者图像的识别优势提出了新的挑战[2]。当前较多的RGB-D 物体识别算法依靠先验知识进行目标特征的设定,已有的成果中:Lai 等人[1]定义了一种稀疏距离度量方法来快速分类;Bo 等人[3]将内核描述子扩展到深度图像,构造了较为丰富的特征;Blum 等人[4]提出了一种基于特征学习的K 均值描述符方法;向程谕等人[5]分别提取目标的RGB 和深度特征,结合线性SVM进行分类。上述研究在早期的RGB-D 图像识别研究中取得了一些成果,依靠先验知识的特征构建方法虽然能够在一定程度上改善RGB-D 物体识别的精度,但是该类方式不利于进行非同类数据集的扩展,且精度的提高空间有限。
近年来,深度学习在图像处理的研究中逐渐呈现出它的优势[6]。因此,科研人员将RGB 图像与深度图像相结合,并利用深度学习提升RGB-D 物体识别的准确率,这种方法开始取代基于先验知识的特征获取方法,成为当前研究者们关注的热点。Socher 等人[7]提出单个卷积层与递归神经网络相结合的网络架构。殷云华等人[8]设计了一种将CNN 与极限学习机相结合算法结构。但是浅层的网络结构并不能发挥深度学习的优势。Eitel 等人[9]提出了称为colorjet 的深度图像处理方法,将深度图像编码为与RGB 图像兼容的三通道图像,使用5 个卷积层提取RGB 特征与深度特征,通过全连接层组合两种模态的特征,该方法将RGB-D 数据集的识别结果提升到了91.3%。Aakerberg 等人[10]在Eitel 的方法上进行了改进,提出了另外一种深度图像处理方法,并将网络层数提升到了16 层。但是已有模型仅仅将RGB 图像特征和深度图像特征进行简单的拼接,仍存在RGB-D 图像有用信息缺失的可能。
为进一步提高三维目标识别精度,本文提出了一种基于深度神经网络的 RGB-D 物体识别算法(Re-CRNN),将双流卷积神经网络与递归神经网络相结合,对RGB 图像和深度图像进行端到端的训练;基于残差学习模型减小网络参数,计算深度图像每个像素点的表面法线向量,编码为三通道表示;在CNN网络顶层采用了一种新的特征融合方式,用以获得RGB-D 融合特征,融合后的特征经过GRU 递归神经网络生成特征序列;最后,在实验中对比了不同非线性激活函数在融合框架上的表现结果,在华盛顿RGB-D 数据集中验证了本文算法的性能。
2 深度图像预处理
2.1 深度图像可视化编码
当前深度学习网络大多针对RGB 图像,RGB 图像与深度图像的特征差异较大,使用深度学习网络训练深度图像依赖于深度图像编码[10-12],将单通道深度图像编码为与RGB 图像兼容的三通道表示,利用迁移学习的方法微调网络参数进行训练(如图1 所示)。本文首先使用递归中值滤波[10]减少噪声干扰,重建缺失的深度值,对单通道深度信息每个像素点计算表面法线,将得到的表面法线归一化为单位向量,根据该点的空间坐标[A1,A2,A3]被编码为A1→R、A2→ G、A3→ B 的三通道,并映射到整数值[0,255]之间,增强深度图像的三维表达能力。在对单模态深度图像的训练中,编码后深度图像的识别结果比原始深度图像提高了23%。
2.2 输入图像归一化
CNN 需要固定网络输入图像的尺寸,实现这个目标最简单的方法是将图像随机裁剪或缩放为正方形(如图2(a)所示),但是直接缩放或裁剪会损失图像原始比例,导致几何形变,如图2(b)所示。

图1 深度图像编码。(a) RGB 图像;(b) 原始深度图像;(c) 编码后深度图像Fig.1 Depth image encoding.(a) RGB image;(b) Original depth image;(c) Encoded depth image

图2 图像预处理。(a) 原始图像;(b) 直接缩放图像;(c) 短边扩充图像Fig.2 Input image preprocessing.(a) Original image;(b) Direct zoom image;(c) Short edge extended image
实验过程中发现这种忽略被识别物体的比例特征会降低物体的空间几何信息识别性能,与文献[9]中实验结论相同。所以,本文对样本图像进行归一化预处理:目标图像长边保留原始比例缩放为256 pixels,短边按照长边缩放后的像素差值进行额外边界创建,并沿短边轴扩充获得256 pixels×256 pixels 的图像,原始目标于扩展图像居中位置,如图2(c)所示,白色的虚线框中保留图像的所有原始信息,框外为扩充的边界。
3 Re-CRNN 算法模型
本文算法结构主要由三部分组成:①主干网络基于改进残差学习的双流卷积神经网络,每个数据流网络参数设置相同,分别对RGB 图像和深度图像进行训练,提取高阶特征;② 一个新的特征融合单元,将CNN 顶层的RGB 特征和深度特征跨通道信息整合;③GRU 递归神经网络。网络架构具体如图3 所示。预训练阶段分别使用ImageNet 数据集上的预训练权重来初始化RGB 图像和深度图像,并根据华盛顿RGB-D 数据集微调网络参数,生成RGB 层和Depth层的参数模型。由于数据集中样本数量有限,对所有的图像进行旋转、缩放、随机裁剪进行数据增强,保留原始图像标签,丰富样本空间。
3.1 残差学习
在RGB-D 图像的特征学习过程中,如果用两个数据流网络同时训练RGB 图像和深度图像,则参数计算量较大。为了提高模型的计算速度,借鉴残差神经网络(ResNet50)[13],基于残差学习对本文网络模型进行改进。ResNet 的思想是通过恒等映射(identity mapping)的跳跃式连接,将学习目标分解为多个求残差的过程,从而减小网络的学习参数,解决深层卷积神经网络的梯度弥散问题。原始残差学习网络第一层卷积核的大小为7×7。为提高网络的复用率,使3 个3×3 的卷积核进行替换,卷积后的感受野与一个7×7 的卷积核卷积的感受野大小相同,并降低了第一个卷积过程中的采样损耗,提取了更多的细节信息。本文中RGB 与深度两个数据流网络采取相同的方案。

图3 网络模型Fig.3 Network model
假定网络层的输入为s,经过中间层的期望输出为H(s),残差学习通过恒等映射跳过中间层将s作为初始输出,此时中间层需要学习的特征F(s)=H(s)-s,学习目标不再是完整的H(s),而是一个残差H(s)-s,通过多条支路使当前层的输入直接传输到更深的网络层,有效地减少了计算参数。相较于VGG-16[11]的153 亿次浮点运算,50 层的ResNet 仅包含38 亿次浮点运算,降低了网络的复杂程度。
残差单元表示为
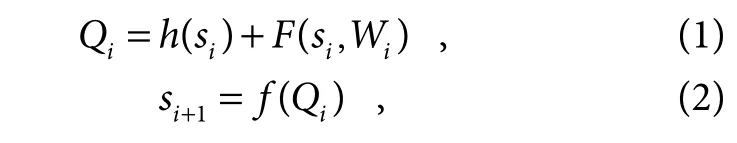
式中:si表示第i个残差单元的输入,si+1表示si的输出,即下一个残差单元的输入;F是学习的残差,iW代表第i个残差单元的卷积操作,当h(si)=si时表示恒等映射,f代表激活函数。当h(si)=si,f(Qi)=Qi时可以计算出层到深层I所学习到的目标特征:

通过链式求导计算出反向过程的梯度:

式中:第一个偏导∂floss/∂si是Loss 函数floss到I的梯度,另一项偏导代表通过权重层传播的梯度,常数1保证了快捷连接机制中梯度即使不断衰减也不会完全消失。
3.2 特征融合单元
为了避免已有的深度学习网络中:决策层获取每种模态的识别率[14],问题注重单独模态的识别结果,忽略了RGB 图像和深度图像的潜在互补特征;以及全连接层组合时,在一定程度上提高了识别结果,但是简单的拼接特征并不能利用两种模态的全部信息。所以在网络中构建了一个特征融合单元,如图4 所示。将ResNet 提取的高层次特征融合为新的RGB-D 特征。去掉了ResNet 的最后一个全连接层,在特征融合前将两个数据流网络中conv5_x 输出的feature map 合并起来,组合新的fusion feature map,使用递归神经网络生成融合特征的高阶表示。4.2 节中的实验结果证明了本文方法优于文献[9]提出的全连接层融合的方式。

图4 特征融合单元Fig.4 Feature fusion unit
特征融合单元增加了一个1×1 卷积层、一个批量归一化层、ReLU 激活函数和全局均值池化层。文献[15]使用1×1 的卷积对不同层的特征图进行升维降维。融合层加入1×1的卷积对RGB特征和深度特征跨通道信息整合,并调整维度。用Krgb=[K1,K2,…,Ki]和Gdepth=[G1,G2,…,Gi]表示多模态网络的输入样本,i是输入的样本标签,Ki和Gi分别对应输入的RGB 图像和深度图像。生成的map 充分融合为新的fusion feature map。经过批量归一化和一个ReLU 非线性激活函数提高网络泛化能力,对所有feature map 进行全局均值池化,并将输出的结果排列起来,第i个标签对应的RGB 图像和深度图像生成的融合特征被表示为

3.3 递归序列
最近研究表明,卷积递归相结合在多模态深度学习中具有优势[16]。RNN 中先前序列的所有输入会共同作用当前序列的输出,卷积神经网络可以提取深层次的语义信息,RNN 重复利用CNN 提取到的融合特征生成更好的特征表示,学习RGB-D 图像中的潜在互补信息。传统递归神经网络在梯度传播的过程中先前输入序列的权重会逐渐减小,易出现梯度消失的问题。本文使用递归神经网络改进模型,被称为GRU 递归神经网络[17],GRU 递归神经网络通过两个门循环控制单元实现网络的长期记忆,更新门Zt(update gate)控制从先前隐藏状态到当前状态的信息,避免参数的丢失,其表达式:

式中:α为sigmoid 激活函数,x为时刻t输入的特征向量,ht1-为t-1 时刻的隐藏状态,MZ和UZ是所学习的权重矩阵。
重置门(Reset gate)Rt对融合特征进行过滤,减少冗余信息,增加鲁棒性,其表达式:

式中:MR和UR对应于不同时刻的权重矩阵,候选状态与当前状态ht分别表示为

式中β是tanh 激活函数。重置门输出值较低时,遗忘先前的隐藏状态并使用当前输入复位,从而有效地忽略不相关的信息,生成更紧凑的特征表示。
4 实验及结果分析
验证实验使用两个公开的RGB-D 数据集,在Ubuntu16.04 操作系统下6 核i7-6700 CPU、单个NVIDIA 1080GPU、8 根16 G 内存条的深度学习工作站进行,并使用Tensorflow 框架作为网络模型融合的基础。
4.1 数据集
1) RGB-D object dataset
华盛顿大学的Lai 等人[1]公开的RGB-D 对象数据集包含300 个对象、51 个类别,总计约250000 张RGB-D 图像。验证实验中,每隔5 帧对数据进行二次采样,生成41877 幅RGB 图像和对应的深度图像。随机抽取每个类别的一种对象用于测试,得到大约35000张训练图像和7000 张测试图像。RGB-D 数据集中的部分样本如图5 所示。
2) RGB-D sence dataset
本文在背景更复杂的RGB-D 场景数据集[18]上验证本文算法对于不同数据集的有效性。该数据集包含8 个不同的场景近6000 张RGB 图像和深度图像,所有的数据样本通过Kinect 采集,该数据集的部分样本如图6 所示。
4.2 模型分析

图5 RGB-D 对象数据Fig.5 RGB-D object dataset

图6 RGB-D 场景数据集Fig.6 RGB-D scene dataset
在RGB-D object dataset 上通过模型变化调整网络的最优性能。对比了不同非线性激活函数tanh、elu、sigmoid、ReLU、softplus 对融合网络的影响,结果如图7 所示。tanh 函数在零点梯度为1,有利于网络中梯度的传播,提升模型的非线性表达能力;其次是elu激活函数,正区间的线性部分在一定程度缓解了梯度消失,负区间的软饱和性可以增加对于输入的变化和噪声的鲁棒性。对于RGB 图像和RGB-D 图像tanh 激活函数得出了最好的结果,在深度数据上elu 函数的表现最优,对于RGB 模态和融合结果低于tanh 函数,总体差异较小可以忽略不计,因此,本文使用tanh 作为融合网络非线性激活函数。
本文使用后期融合的方式组合RGB 图像和深度图像的高阶特征。为了验证后期融合在本文算法的有效性,分别将RGB-ResNet 和Depth-ResNet 的第二组到第五组(conv_2、conv_3、conv_4、conv_5)卷积特征作为特征融合单元的输入,得到不同层级融合的识别结果。图8 所示为不同层级的融合结果对比,深层网络要比浅层网络对特征的抽象程度要高,conv5_x 层的特征进行融合准确率更高。表1 中对比了全连接层融合(Fc-RGB-D)、特征融合层分类(Fu-RGB-D)与本文融合方式(Re-CRNN)的实验结果:conv5_x 生成的卷积特征作为特征融合单元的输入,特征融合层中1×1 的卷积通道数为256,分类器为Softmax。与本文融合方法相比,全连接层简单的拼接融合方式遗漏了两种模态之间的信息交互,随着网络层数的增加识别率接近饱和。特征融合单元的跨模态的交互过程生成新的递归序列后,GRU 的循环过程进一步扩大了RGB-D 图像的特征表达效果,准确率得到了进一步的提高。

图7 不同挤压函数对网络的影响Fig.7 Influence of different extrusion functions on the network

图8 层级输出对比Fig.8 Level output contrast

表1 特征融合方式对比Table 1 Comparison of feature fusion methods
4.3 实验结果及分析
4.3.1 RGB-D 对象数据集
对象识别广泛处理两个不同的问题:实例识别和类别识别。实例(咖啡杯)代表独特的对象,而类别(杯子)代表共享相似特征(形状或结构)的实例[12]。按照4.1所述的10 个随机分割进行了实验,训练前需对所有的深度图像进行可视化编码,然后将RGB 图像和深度图保持原始比例缩放。实验设置预训练在ResNet50 上获取RGB 图像和深度图像的初始化模型,此阶段RGB图像和深度图像保持相同设置,初始学习率0.0001,冲量0.9,权重衰减0.0001,批量32,每种模态迭代50000 次获得初始化模型,所需的时间为2 h。融合网络使用SGD 优化器训练我们的模型,取10 次的平均值为实验结果,融合网络优化过程所需的时间约为6 h。表2 对比了其他算法在华盛顿RGB-D 数据集上的分类结果。
表2 中可以看出,RGB-D 图像的识别结果高于单独模态,证明融合RGB 特征和深度特征可以进一步提高物体识别的准确率。本文提出Re-CRNN 深度学习模型和融合方法在RGB-D 数据集上获得了更好的识别结果,在类别识别中,RGB 图像的平均识别率为90.3%,优于其他方法。深度图像的识别结果略低于文献[10],结果相差较小,而RGB图像和融合后的RGB-D图像识别结果均表现出明显的优势,相较于文献[7]提出的CNN-RNN 模型类别准确率提高了7.3%。
图9 展示了各类别分类结果的混淆矩阵(数据来源于第一个随机分割),行的索引给出了RGB-D 数据集中所有类别的真实标签,列的索引给出了各类别的预测结果,对角线的结果表示正确分类的总体占比,可以清晰地看到容易错分的对象。图10 列举了总数据集中部分容易分错的样本,容易错分的对象存在于颜色和纹理都相似的物体,具体集中在以下几个类别:橙子类(orange)和桃子类(peach)、球类(ball)和大蒜类(garlic)、蘑菇类(mushroon)和大蒜类(garlic)等。

表2 与其他方法对比Table 2 Compared with other methods

图9 RGB-D 对象数据集的混淆矩阵Fig.9 Confusion matrix on RGB-D object dataset

图10 RGB-D 数据集中容易错分的对象Fig.10 Examples of misclassification in RGB-D object dataset
以上数据表明,首先,较少的实例会影响分类结果,如蘑菇类仅有3 个实例,训练样本的单一化导致可学习特征类与量均受到限制,网络无法泛化新增添的数据,是造成错误的分类的原因之一;其次,具有RGB 视觉分层上的相似数值的实例,在分类过程中较难被辨别,使结果产生偏差。深度图像的分类依据是物体的几何形态,上述对象高度的类间几何相似性使得深度图像的区分度降低,也会影响到最终的识别结果;此外,受传感器性能影响,已有的RGB-D 数据集中图像的分辨率普遍不高,且深度图像中物体边缘部分深度值缺失,也可能对结果造成干扰。
4.3.2 RGB-D 场景数据集
室内场景识别是典型的多分类问题,场景图像更加密集地记录了场景中的所有物体。本文在RGB-D 场景数据集上进行了额外实验来验证本文算法的普适性,对不同的室内场景进行分类,从该数据集中抽取1434 张RGB 图像和深度图像,共8 类场景,每类场景中包含多种相似物体。将所有的图像尺寸调整为256×256,并对深度图像完成表面法线编码。从每类场景中随机挑选80%的样本用于训练,剩余的20%用于测试。其它实验设置与RGB-D 对象数据集相同,该数据集上的分类结果如表3 所示。
实验结果显示,本文方法在RGB-D 场景数据集上的实验结果比之前的结果提高了4.5%,说明面对更加复杂的场景,深度学习的算法比手工设计特征描述子更有竞争性,Re-CRNN 可以在复杂的图像中有区别地提取RGB 信息和深度信息,并且能够有效地完成RGB特征与深度特征的融合。实验结果同时表明,对于背景杂乱的场景分类问题,不同模态的信息互补是提高分类准确率的有效途径。场景数据集中分类结果的混淆矩阵如图11 所示。
其中,纵坐标表示真实样本标签,横坐标表示预测标签。容易错分的场景主要存在于desk_2和desk_3,table_small_1 和table_small_2,分析其原因,在场景识别中最具有区别性的有用特征是不同的目标对象,根据这些对象的分布和包含的不同语义特征进行分类。而错分的场景中包含许多种相似的物体,如笔记本电脑、易拉罐、食品盒、杯子等,不仅具有相似的颜色信息,也包含相似的纹理信息,易产生检测数据的混淆,造成错误识别;深度图像采集时目标深度值相近且缺少明显的标志性数据特征,也会对识别结果造成一定影响,错分的场景示意如图12 所示。

表3 RGB-D 场景数据集分类结果Table 3 RGB-D scene dataset classification result

图11 RGB-D 场景数据集的混淆矩阵Fig.11 Confusion matrix on RGB-D sence dataset

图12 RGB-D 场景数据集错分实例Fig.12 Examples of misclassification in RGB-D sence dataset
5 结 论
本文提出了一种基于双流卷积递归神经网络的RGB-D 物体识别算法Re-CRNN,利用中值滤波去噪重建深度图像缺失的深度值,引入特征编码提高识别效果,数据样本通过数据增强获得扩充。使用两个并行的深度卷积神经网络对RGB 图像和深度图像进行特征提取,基于残差学习的思想对模型效率进行提升。将CNN 网络顶层提取的特征映射到一个公共空间,生成融合特征的高阶表示。最后在不同的数据集上与其他方法进行了实验对比,实验结果表明:RGB-D 图像比单模态RGB 图像具有更好的识别效果,Re-CRNN在华盛顿大学的 RGB-D 数据集识别准确率可达94.1%。通过多个数据集的实验,证明本文算法具有较好的普适性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
北京航空航天大学学报(2018年1期)2018-04-20
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
