
基于线性核主成分分析和XGBoost 的脑电情感识别
2021-04-01 07:24董寅冬任福继李春彬
光电工程 2021年2期
董寅冬,任福继,李春彬
1 合肥工业大学计算机与信息学院,安徽 合肥 230601;
2 情感计算与先进智能机器安徽省重点实验室,安徽 合肥 230601;
3 德岛大学工学部,德岛770-8509,日本
1 引 言
人机交互(Man-machine interface,MCI)在近年来影响着我们生活的方方面面,如人与人的交流与沟通、购物、求职、教育、医疗和娱乐等[1-2]。在交互的过程中机器可以理解人的情感状态并加以应用,我们把这种表达方式称之为情感计算(affective computing,AC)[2-4]。情感计算可以让机器具备一定的情感表达能力,并能够在系统和智能设备之间识别、解释和处理人类的情感。目前,情感识别已经成为情感计算的重要研究热点,人脸表情[5-6]、语音[7]、姿态[8]、文本[9-10]以及人类自发神经系统产生的生理信号可以用来进行情感认知的表达[11-14]。脑电信号(Electroencephalogram,EEG)的采集直接来源于中枢神经系统,它作为一种有效的生理表达能够真实地反应大脑的情感变化。由于在连续音乐视频激励下产生的EEG 信号较为稳定和持续,本文使用DEAP 数据库对脑电情感状态进行识别和分析。
众多学者对脑电情感识别的研究主要集中在特征层面和模型分类层面。在特征层面上,时域特征主要有事件相关电位EPR,统计特征(能量、均值、标准差、一、二阶差分等)、Hjorth 参数、分形维度FD 以及高阶交叉参数HOC 等;时频特征主要包括频带能量、小波(包)能量、高阶谱,希尔伯特黄谱HHS 和离散小波变换等;非线性特征包括一些基于熵的特征值(香浓熵、小波包熵、差分熵等)、C0 复杂度、相关维、李雅普诺夫指数等[15-16]。文献[17]针对经验模态分解得到功率谱密度(power spectral density,PSD)特征,并采用高斯核的SVM 单独对每个被试进行识别,取得平均68.3%的分类准确率。文献[18]采用IMF 结合对应的能量和幅值差使得在积极与消极情绪之间的识别率获得了近10%的提升。文献[19]使用非线性特征差分熵(differential entropy,DE)结合图规则化极端学习机(graph regularized extreme learning machine,GELM)在情感的四分类上获得了69.67%的准确率。文献[20]提出了一种基于PCA 融合小波能量特征、近似熵和Hurst 指数的脑电特征提取算法,针对八种情感的两两分类取得了平均85%的准确率。但这些文献在对脑电信号提取特征后没有进行非线性核的变换,且识别性能会因一些相关性较弱的特征以及特征之间的冗余而下降。从模型层面上来说,文献[21]使用自编码神经网络和LSTM 相结合的方法在四分类情感上取得了最高76.23%的分类准确率。文献[22]利用时频特征结合深度卷积神经网络(deep CNN)使脑电特征相对于传统BT 分类模型在valence 和dimension 维度上分别提高了3.58%和3.29%。文献[23]使用granger 因果关系作为脑电特征,并结合 lasso 算法进行特征选择,最后通过SVM 识别在二维情感维度上分别取得87.15%和86.60%的平均准确率。文献[24-25]使用最小冗余度最大相关(minimum redundancy maximum relevance,mRMR)对PSD 进行特征选择,在一定程度上提升了分类效果。但这些文献中特征选择过程和分类模型算法是相互孤立的,无法在算法上形成优势的互补。因此,一个合适的分类模型对脑电信号实现特征的选择和情感状态的识别尤为重要。
XGBoost 是在2014 年被Chen 提出[26]的一种集成学习算法,它具有运行速度快、计算复杂度低、易于调参、可控性强以及识别性能高等优势。一方面,该算法作为识别模型在工业、机器学习以及各种科研竞赛中都具有优异的表现[27];另一方面,此算法能够在样本训练的过程中统计各个特征的重要性度量,实现特征的选择[28-29]。因此XGBoost 能够被广泛应用于各种模式的识别和事件的预测任务等[30-32],但是针对生理信号的识别领域却鲜有研究。本文提出了一种线性核(linear kernel)核主成分分析(KPCA)结合XGBoost 模型的分类识别算法。首先,对每位被试的脑电信号在32 个通道上提取了不同频段的PSD 特征,然后使用XGBoost 对样本进行训练,并在树学习的过程中通过特征重要性指标weight 选出和情感相关的脑电特征后,经linear 核的KPCA 进行特征处理,最后利用XGBoost 对处理后的特征进行分类识别。该算法不但使脑电情感样本在高维空间变得更加线性可分,又充分利用了XGBoost 在特征选择和模式识别上的优势,从而可以达到较好的情感识别效果。
2 XGBoost 介绍
2.1 XGBoost 原理
集成学习是一种使用多个学习模型组成具有更强泛化能力的学习方法,对于大小规模数据的处理都会呈现出不错的学习效果。XGBoost 是对boosting 算法进行改进的一种有监督集成学习模型,它实际上是一个附加训练(additive training)的过程,通过迭代对预测函数增加一棵新的分类回归树f t(xi)去优化目标函数

式(1)为模型的函数定义,k为树的数目,F则为分类回归树(CART)的所有可能性集合,fk是F空间的子函数。q表示树的结构函数,Ω(f)为定义为树的复杂度,它是由树的叶子结点数T以及每个叶子结点的得分w的L2 模平方决定的,用来作为正则化项的惩罚模型,γ和λ为需要调参的系数。
使用二阶泰勒展开对目标函数进行近似定义:


式中Ij为第j个叶子结点的样本集合。

在树的生成过程中,通过在特征上枚举所有可能性划分,然后使用精确贪心算法(exact greedy algorithm)得到最佳切分点,从而寻找出一棵最优结构的树,这样可以通过计算结点分裂前后的增益值G作为是否进行分裂的依据。由下式(8),一个结点被分解得到左叶子结点分数和右叶子结点分数。对于某一特征,找到增益值最大的结点作为分裂结点。

2.2 特征重要性度量指标
根据特征在叶子结点的分割过程,可以看出每个特征在结点处的分裂次数weight 影响着整个树模型的构建,因此,本文选取weight 作为特征重要性度量。另外,和XGBoost 相关的特征重要指标还包括gain、cover、total gain 和total cover。Gain 表示的是特征在切割树的结点过程中产生的平均增益。Cover 表示特征在树中的平均覆盖范围。Total gain 表示特征在所有树中每次分裂节点所产生的总增益,Total cover 则表示特征在所有树中每次分裂节点所覆盖的全部样例的数目。
3 特征处理
3.1 特征提取
本文采用大多数研究中使用频段能量特征提取方法对脑电信号提取功率谱密度(PSD),PSD 是单位频域内信号功率的分布。具体过程是在不同的子频段采用短时傅里叶变换(STFT)并结合汉明(Hamming)窗口函数对信号进行分解。4 Hz~45 Hz 的频段被分成了五个频段,分别是theta:4 Hz~8 Hz,alpha:8 Hz~12 Hz,beta low:12 Hz~18 Hz,beta high:18 Hz~25 Hz 以及gamma:25 Hz~45 Hz,本文取各个子频段的PSD 特征。
3.2 特征正则化
本文对PSD 特征进行正则化(normalization)处理,以便后面使用核来规范样本间的相似性。Normalization 是先按照式(9)计算每个样本的p-范数,再从样本中的每个元素除以此范数,从而使得每个样本缩放到单位范数。本文使用L2-norm 进行正则化。

3.3 核主成分分析(KPCA)处理
当样本在特征空间中难以进行线性分割时,可以试图通过选择特定的核函数对特征进行升维,使之在高维空间变得线性可分,然后使用PCA 算法对高维空间的特征分量进行降维。本文通过实验对比,选取线性核进行KPCA 处理可以达到最佳的识别效果。
4 算法的实施
本文使用两种实施方案来验证脑电情感识别效果。第一种方案是在每个被试内部先进行3-Fold 交叉验证,最后取所有被试情感识别的平均准确率。这种方案一般可以得到较高的准确率,但是仅仅是针对每个被试的内部特征进行训练,模型无法学习到所有被试的共性特征,本文把这种方案称为被试单独依赖(subject single dependent,SSD)。第二种方案是对所有被试的脑电信号段样本进行随机打乱,然后使用XGBoost 进行5-Fold 的交叉验证,这种处理方式使用多个被试样本参与模型的训练和测试,更适用于情感脑机接口的分析和应用,本文把这种实施方案称为所有被试参与(subjects all participation,SAP)。
文中对脑点信号进行窗口大小为1 s 的PSD 特征提取,窗口之间非重叠,这样做可以避免数据样本的重复。本文在SAP 的情况下,由于样本数目较多,使用5 折交叉运算;在SSD 的情况下,使用的是3 折交叉运算。在特征选择方面,本文使用XGBoost 随机选择70%比例的样本特征进行训练,并根据特征重要性指标weight 统计每个特征在每棵树上的分裂次数,把每棵树在此特征上的分裂次数的总和作为特征的得分,当阈值(threshold)被固定为某一数值,得分排名靠前的特征将会被选择,然后利用线性核主成分分析(KPCA)方法在高维空间进行特征处理,最后使用XGBoost 模型对4 类情感状态进行分类。训练过程中主要参数有:生成树的最大数目(n_estimator),学习率(learning_rate),结点分裂需要最小损失函数的下降值(gamma),权重L2 的正则化项(reg_lambda)和树的最大深度(max_depth),另外,使用softmax 做多分类,分类数目设置为 4。本文使用网格搜索法GridSearchCV 对XGBoost 进行调参,最终参数设为n_estimators:1080(SAP),n_estimators:500(SSD),learning_rate:0.05,gamma:0.1,reg_lambda:0.05,max_depth:9(SAP),max_depth:4(SSD),objective:'multi:softmax',num_class:4。图1 为本文的算法流程图。

图1 算法整体流程图Fig.1 Overall flow chart for the algorithm
5 实验结果和分析
5.1 实验数据库
本文在DEAP 数据库[33]中对脑电情感信号进行研究。32 名身心健康的被试者(男女比例各占50%,平均年龄为26.9 岁)被邀请参与实验数据的采集。一共有40 导的数据被记录,其中脑电信号为32 导,其余8导为外周生理信号。收集的信号以512 Hz 的采样频率被记录,预处理后被降采样到128 Hz,经滤波到4 Hz到45 Hz 的频段范围内。32 名被试被安排在40 段不同情感状态的音乐视频前进行生理信号的记录,每段视频时长为1 min。每段视频开始前,被试会有3 s 的基线准备时间,这时被试者处于平和状态。在每个视频播放完毕后,被试将会有足够的时间对刚播放的视频在三维模型(效价、唤醒度、优势度)上进行1 到9的离散评估。本文选择了效价和唤醒度两个情感维度,并把情感维度评估分数大于等于5 的划分为高(High),分数小于5 的情况指定为低(Low)。因此可以划分四种情感类别,包括HVHA(high valence high arousal),LVHA(low valence high arousal),HVLA(high valence low arousal)和LVLA(low valence low arousal),分别对应着欢乐/高兴、生气/厌恶、放松/平静、抑郁/悲伤四种情感。
5.2 特征数目对识别效果的影响
本文在对样本进行训练的过程中,使用阈值(threshold) 对脑电特征维度进行选择,当threshold∈[0.004,0.011],所选择的特征数则由160 逐渐减少到0。实验中图2 分别给出了SAP 下阈值的变化对识别效果的影响,当特征数目选择较少时,无法全面地表征情感的变化;当特征数目选择过多,特征之间将会出现过多的冗余,进而影响到模型的泛化性。当threshold=0.0072 时,情感分类的准确率最高达到78.38%。图3 给出了SAP 情况下特征重要程度排名前50 的特征,纵坐标如7_(25-45)是通道编号为7,频率在25 Hz 到45 Hz 之间的PSD 特征表示,横坐标则为特征的得分表示。从图中可以看出,重要性度量靠前的特征在频段上基本都集中在gamma 频段,这说明gamma 频段能量变化对脑电情感识别具有较大的区分度,这和文献[19]的研究结果是一致的。同时,在gamma 频段下基本所有的通道特征都在树的模型学习过程中进行了多次的分裂,这说明gamma 频段下每个通道对情感的识别都具有一定的贡献。结合图4 可以看出,gamma 频段下(红色数字)中央、顶叶以及右枕区在gamma 频段的特征尤为重要,可以给脑电的情感分类提供更多的有效信息;另外,颞区(蓝色圈)左右两侧、顶叶和中央左处的特征分别在alpha、beta、gamma 频段和theta、beta、gamma 频段保持活跃,这些特征不仅对分类很重要,同时每次在随机选取的样本进行训练中表现的较为稳定,从而有利于在多人被试中借助模型进行共性学习。

图2 SAP 下准确率在不同阈值下的趋势Fig.2 Accuracy under different thresholds in SAP

图3 SAP 情况下特征重要性排序Fig.3 Ranking of feature importance in SAP

图4 脑电信号整体分布和特征重要性分布图Fig.4 Overall distribution and feature importance distribution of EEG signals
图5 和图6 是在SSD 下分别选出被试中识别效果最好(01,23)和最差(04,22)的四个被试的部分重要特征排名和每个被试的识别结果,对应的这四个被试的准确率分别是96.24%、94.62%和84.81%、86.07%。从图5 中可以观察到不同的被试所表现的特征重要性排序是不同的,这说明不同的被试所呈现的个性表达存在较大的差异性。分析发现,01 号被试和23 号被试名靠前特征也都集中在gamma 频段,这和SAP 情况下的分析相一致,从而进一步说明gamma 频段的能量特征是脑电情感识别的一个很重要的指标。从通道空间上看,通道3、11 和32 能够同时在识别性能最好的两个被试和SAP 下的多人被试中呈现的特征重要程度保持基本一致,说明三个通道在情感特征的共性识别方面是稳定的;编号04 和22 相对于其他被试得到的识别效果较差,从图5 中可以看出,他们的频率和通道重要性度量排序都较为混乱,可能是特征的无规则性对被试个体的识别效果产生了负影响,不同被试所具有的个性化通道和频段特征在多人被试中不能有效的区分情感状态,因此很难被应用针对脑机的情感系统中。

图5 部分被试(01,04,22,23)特征重要性排序Fig.5 Features’ importance ranking for selected subjects(01,04,22,23)
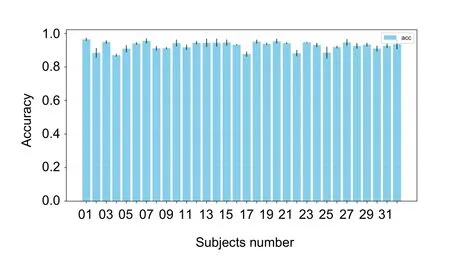
图6 32 名被试的识别准确度对比Fig.6 Comparison of recognition accuracy for 32 subjects
5.3 关于KPCA 的特征处理分析
图7 给出了各种组合算法在固定主成分数目(n_components)后的识别效果对比。图中SVM(RBF,Linear)表示支持向量机分类模型采用径向基核或者线性核。图7(a)显示的是SAP 情况下选择的特征个数为30,可以看出,当n_components 在100 到150 的范围内,本文算法分类效果最佳且识别效果相对稳定。图7(b)是SSA 情况下各个算法识别情况,由于每个被试下样本数目相对较少,这里统一把阈值设置为‘1.4×mean’,mean 为训练过程中有效阈值范围的平均值,选择的特征数目将会在14 到35 的范围波动。从图7(b)可以看出,当n_components 在70 到160 的范围内,算法的识别效果也会达到稳定和最佳状态。综合发现,无论是SAP还是SSD 情况下,n_components个数在70 以内,随着n_components 的增加,识别准确率呈明显上升的趋势,然后逐渐趋于稳定;另外,相对于PCA 和径向基RBF 核KPCA 对特征的处理,线性Linear 核的KPCA 处理可以使识别性能得到较大的提升,这说明KPCA 处理以及核的选择对识别效果影响较大。最后,可以看出要取得较好的识别效果,n_components 的数目应大于所选择的特征数目,这可能是因为脑电情感信号在低维度无法有效地表征非线性特征。

图7 不同方法下主成分个数的识别性能对比Fig.7 Recognition performance comparison for different components
5.4 相关文献对比
为了进一步证明本文算法的有效性,表1 给出了本文算法与其他模型及一些相关文献的识别效果对比。从表中可以看出,本文提出的Linear 核KPCA 特征处理结合XGBoost 脑电情感识别方案在SAP 的情况下的准确率为78.376%,分别比文献[19,21]提高了8.71%和1.56%,识别性能远高于各单一模型的分类方案;同时在SSD 的情况下,文中算法获得了92.583%的准确率,相对于文献[17]提高了24.28%。文献[23]分别是在Valence 和Arousal 进行二分类识别,本文在四分类识别也取得了相对更高的准确率。

表1 各种算法识别效果的比较Table 1 Comparison of recognition performance for various algorithms
6 结束语
本文对脑电信号情感的识别方法进行研究,针对脑电信号情感识别效果较低并且每个被试的情感表达差异性问题,设计了一种使用线性核主成分分析进行特征处理,并结合XGBoost 算法的情感分类识别模型。实验结果证明,通过线性核的主成分分析可以在高维空间实现特征向量的非线性变换,进而更有利于脑电情感的分类,和XGBoost 的结合可以发掘出情感相关的共性特征。在SAP 和SSD 的情况下,与其他文献相比,识别准确率得到了较大的提升。因此,本算法对于改善脑电情感识别系统的性能是有效的。另外,本文提取的脑电信号特征使用的是传统的PSD,但这种特征仅仅反映了被试在大脑不同区域所呈现的能量变化,忽略了脑电信号在空间各个不同区域之间的非线性联系,如何探究脑区之间的非线性关系并进一步改进情感分类模型的性能是本研究要关注的下一个方向。
猜你喜欢
电子制作(2021年14期)2021-08-21
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
地震研究(2021年1期)2021-04-13
数学物理学报(2018年1期)2018-03-26
现代电生理学杂志(2016年3期)2016-07-10
现代电生理学杂志(2016年4期)2016-07-10
现代电生理学杂志(2016年1期)2016-07-10
CHIP新电脑(2016年3期)2016-03-10
现代电生理学杂志(2015年1期)2015-07-18
电子设计工程(2014年12期)2014-02-27
