
结合五笔字形与上下文相关字向量的命名实体识别
2021-03-18 08:03王铭涛陈文亮
计算机工程 2021年3期
张 栋,王铭涛,陈文亮
(苏州大学计算机科学与技术学院,江苏苏州 215006)
0 概述
命名实体识别(Named Entity Recognition,NER)是自然语言处理中的一项重要任务[1-2],其目的是在非结构化文本中识别人名、地名和组织名等专有名词[3]。NER 问题通常被转换为序列标注问题,即给序列中的每个字或词打上一个预定义的实体标签。近年来,基于有监督学习的NER 模型取得较大进展,系统性能得到大幅提升[4-6]。
传统的NER 系统主要是基于统计机器学习,如最大熵模型[7]、隐马尔科夫模型[8]和条件随机场(Conditional Random Field,CRF)模型[9-10]等。这类模型非常依赖手工特征,如上下文特征、前缀词和后缀词等。由于语言的多样性以及领域的差异性,手工特征通常需要重新设计,缺乏可迁移性。随着深度学习的快速发展,基于神经网络的方法被广泛应用于NER 任务。文献[11]使用前馈神经网络和卷积神经网络(Convolutional Neural Network,CNN)作为特征编码器,文献[12]使用长短时记忆(Long Short Term Memory,LSTM)网络作为特征编码器。这些深度学习模型不仅摆脱了对手工特征工程的依赖,而且命名实体识别性能明显优于基于统计机器学习的方法。神经网络的初始化对于深度学习模型性能影响很大,传统的词向量在训练时对上下文中的词进行预测,得到词的分布式向量表示。但通过这种方式取得的词向量都是静态的,无法体现一词多义的情况。例如,“自然”在不同上下文中具有“不造作,不呆板”或“理所当然”的含义。为了解决这一问题,文献[13]在大规模无标注语料上预训练一个语言模型,将多层上下文的隐状态通过线性加权作为词的向量表示,基于该预训练语言模型得到的上下文相关词向量在英文NER 任务中取得了较好的效果。
在中文NER 任务中,通常将字作为最小的处理单元,使用大规模无标注语料预训练字向量。汉字是一种象形文字,其中包含丰富的笔画、部首等字形信息。具有相似字形的汉字通常具有相似的语义,如“他、你、俺”都有部首“亻”,“亻”是“人”的变体,因此,这些字都包含与“人”相关的意思。虽然在大规模无标注语料上训练得到的字向量,可以在一定程度上学习到自然语言中的语法和语义特征,但是这种特征表示能力是有限的。一些研究人员尝试将汉字字形应用于中文NER 任务中,目前已取得了一定成果。文献[14]将汉字拆分成多个组件,通过双向LSTM 提取汉字的字形特征,将其与随机初始化的上下文无关字向量进行拼接并作为汉字的特征表示,该方法的NER 性能得到有效提升。但是,目前较少有学者将预训练语言模型和汉字字形相结合,从而增强字的语义表达。同时,汉字存在多种字形表现形式,如部首、五笔和笔画,其中,部首只提供汉字的部分字形信息,笔画只有横类、竖类、撇类、点类和折类等,过于简单,而五笔拆解出的汉字较完整且字形具有一定含义。因此,本文将五笔字形信息引入汉字的向量表示中,以改进中文命名实体识别效果。
为了充分利用大规模无标注语料,本文将中文特有的字形信息和预训练语言模型相结合,提出2 种结合五笔字形的上下文相关字向量表示方法。第一种方法分别训练得到2 个语言模型,一是基于字序列训练一个基于字的语言模型,二是将文本转换为五笔编码序列,训练一个基于五笔的语言模型。第二种方法是将五笔字形作为辅助特征拼接到字向量表示中,将两者信息直接融合,训练一个基于字与五笔字形的混合语言模型。通过这2 种方法得到2 种结合五笔字形的上下文相关字向量,并以此构建中文NER 系统。
1 相关工作
目前,序列标注任务主要通过基于神经网络的方法来完成。文献[11]去掉特征工程和先验知识,使用语言模型中训练的词向量替换手工设计特征,在词性标注、分块以及NER 任务上取得了较好的效果。文献[15-16]分别使用CNN 和双向LSTM 以捕获英文单词内的拼写特征,结果验证了字符级特征的有效性。借鉴英文中提取单词拼写特征的思想,文献[14]将汉字拆分成多个组件,通过双向LSTM提取组件级别的特征,然后和上下文无关字向量相拼接,以改进中文NER 的性能。文献[17]通过CNN对汉字五笔进行编码,然后与上下文无关字向量相拼接以作为NER 模型的输入。此外,为了提取命名实体的前缀和后缀特征,文献[17]使用多个卷积核模拟传统的n-gram 特征。由于LSTM 在处理序列时无法并行运算以及传统卷积感受野受限,因此文献[18]使用空洞卷积增大感受野从而进行命名实体识别,该方法在未降低识别性能的同时显著缩短了模型训练时间。为了降低人工标注语料的成本,文献[19]提出了一种利用对抗网络在众包数据上进行命名实体识别的方法。为了避免分词错误,很多研究人员都以字为处理单元。文献[20]建立一种Lattice-LSTM 模型来引入序列中所有潜在的词信息,其在NER 任务中取得了很好的效果。
除了对NER 模型进行改进外,自然语言处理的一个重要任务是学习文本中较好的特征表示。研究表明,在大规模无标注数据上预训练学习得到的词向量可以捕获语法和语义信息,使得预训练的词向量成为自然语言处理模型的一个基本组成部分[21]。文献[22]利用汉字的上下文和部首信息来训练上下文无关字向量,并将其应用于汉字的相似性计算任务和中文分词任务中,且取得了较好效果。文献[23]基于五笔将汉字转变成五笔序列,使用CBOW 模型预训练五笔的上下文无关向量,在中文分词、短文本分类以及网页排序任务中,该方法的效果优于基于传统特征的机器学习方法。文献[24]在SkipGram 和CBOW 模型中,将汉字的组件信息融合到字向量的预训练中,在文本分类中取得一定效果。文献[25]在预训练上下文无关词向量时,同时考虑词、字和部首三者的信息,在词相似性和词推理任务中的结果验证了上下文无关词向量的有效性。文献[26]根据汉字的图像表示,通过CNN 提取汉字的可视化特征。上述方法虽然在一定程度上丰富了字向量的表示,但多数是对上下文无关向量的改进。此外,很多研究仅聚焦于字或词级的语义任务,未在句子、文档等自然语言处理的高层任务上进行延伸。
文献[13]提出基于语言模型的上下文相关词向量表示方法,其在多个英文自然语言处理任务中取得了较好的效果。但是,该方法不能直接应用于中文NER 任务,因此,本文在中文语料上训练一个基于字的语言模型。此外,为了更好地挖掘中文的字形信息,本文建立2 种结合五笔字形的预训练语言模型,并在此基础上分别构建2 种结合五笔字形的上下文相关字向量表示模型。
2 LSTM-CRF 模型
LSTM-CRF 已经成为命名实体识别中最主要的模型之一。本文采用LSTM-CRF 构建基准系统(baseline),如图1 所示。整个模型主要由输入层、编码层和解码层3 个部分组成。baseline 模型的输入为传统的静态字向量,使用双向LSTM 对序列的特征进行编码。在解码层,本文使用CRF 模型。
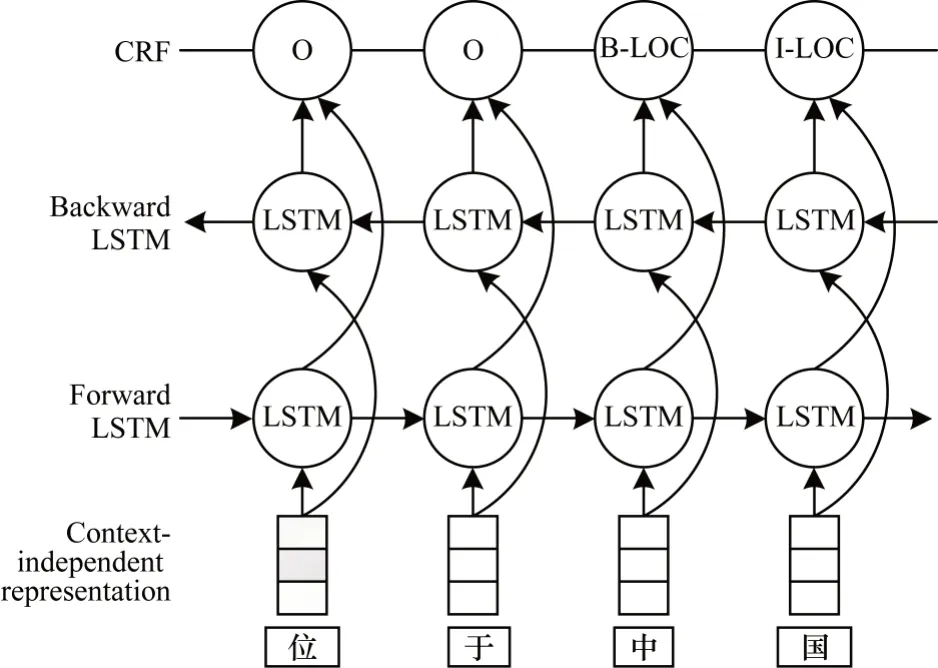
图1 LSTM-CRF 模型Fig.1 LSTM-CRF model
2.1 输入层
假设LSTM-CRF 模型的输入为一句话s=c1,c2,…,cn,ck表示句子中的第k个字。对每个字ci,通过word2vec 预训练字向量将其嵌入为连续稠密向量表示,本文使用xk表示LSTM-CRF 模型第k个字向量的输入,
2.2 编码层
本层使用LSTM 对特征进行编码,LSTM 单元能够处理当前时刻的信息,也可以处理历史信息,非常适合对序列问题进行建模。LSTM 单元通过输入门、遗忘门和输出门来控制单元的隐状态,可以有效捕获长距离依赖信息。LSTM 单元的实现方式如式(1)~式(3)所示:
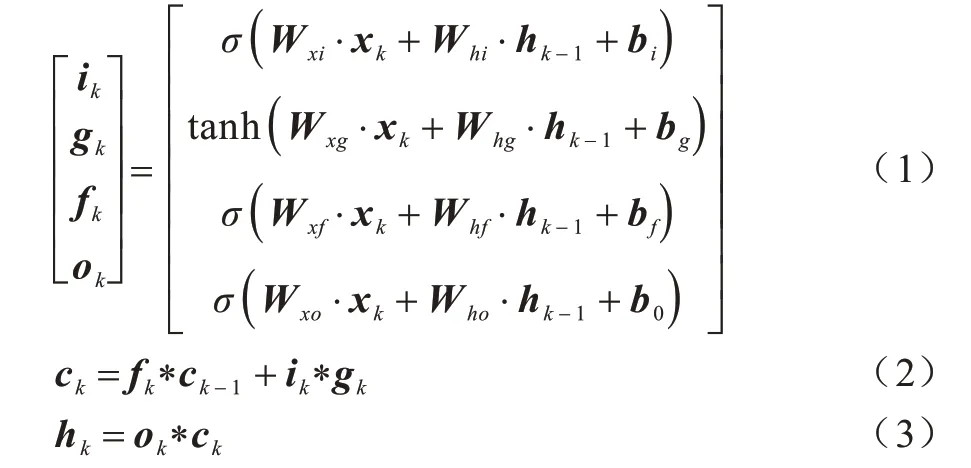
其中,σ是sigmoid 函数,*代表元素乘,W是权重矩阵,b代表偏置。
在序列标注任务中,上下文特征对于标签决策很重要。由于LSTM 只能对序列的一个方向进行编码,因此本文使用双向LSTM(BiLSTM)对输入进行特征编码,将BiLSTM 的2 个前后向隐状态相连接以作为最终的特征编码。输入序列(x1,x2,…,xn)经过BiLSTM编码后可以得到特征序列(h1,h2,…,hn)。
2.3 解码层
根据BiLSTM 提取到的第k时刻的特征hk,可以直接对每个字的输出进行独立的标签预测。但是,由于标签之间存在一定的相关性,如B-ORG 后面不能跟着I-PER,因此本文使用CRF 对标签序列进行一些约束。定义矩阵O是对隐层表示H={h1,h2,…,hn}进行线性变换所得表示第k个字是yk的得分,O的表达式如式(4)所示:

其中,Wo和bo是矩阵O的参数。对于标签序列y={y1,y2,…,yn},本文通过式(5)计算其概率:

其中,T是转移矩阵表示所有可能的标签序列。
在训练过程中,给定N个句子的命名实体识别数据,使用梯度反向传播算法来最小化损失函数loss,如式(6)所示:

在训练完成后,需要对模型输出进行解码,通过式(7)来找到得分最高的标签序列:
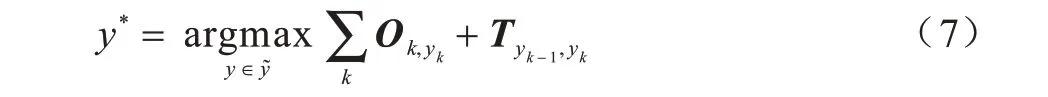
3 结合五笔字形的上下文相关字向量表示
本文建立2 种上下文相关字向量表示系统。第一种是在基于字的语言模型和基于五笔的语言模型的基础上所构建,第二种是在基于字与五笔的混合语言模型的基础上所构建。
3.1 基于字与基于五笔的语言模型
将字和五笔的信息分开,分别训练基于字的语言模型和基于五笔的语言模型,在这2 个语言模型的基础上构建本文所提第一种结合五笔字形的上下文相关字向量表示系统。
3.1.1 基于字的语言模型
本文使用ELMo(Embeddings from Language Model)作为基于字的语言模型的训练框架。作为传统上下文无关词向量的一种替代方法,ELMo 已经在解决一系列句法和语义NLP 问题上取得了成功。与文献[11]系统不同,本文系统构建基于字的ELMo 框架。对于字序列(c1,c2,…,cn),前向语言模型通过式(8)计算序列概率:
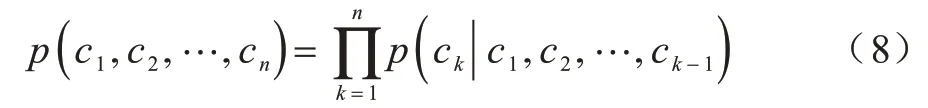
前向语言模型只能编码一个字的上文信息,因此,还需要一个后向语言模型来编码字的下文信息,如式(9)所示:

训练的目标是最大化前向语言模型和后向语言模型对数似然概率,如式(10)所示:
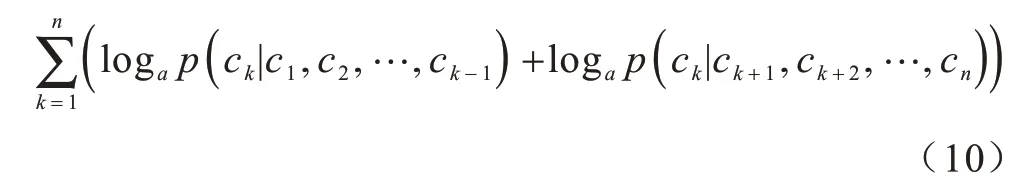
前向语言模型和后向语言模型互相独立,即参数不共享。同时,较低的层可以学到更多的语法特征,而较高的层能够学习上下文特征。因此,本文前向语言模型和后向语言模型均采用两层LSTM 堆叠的结构,如图2 所示。
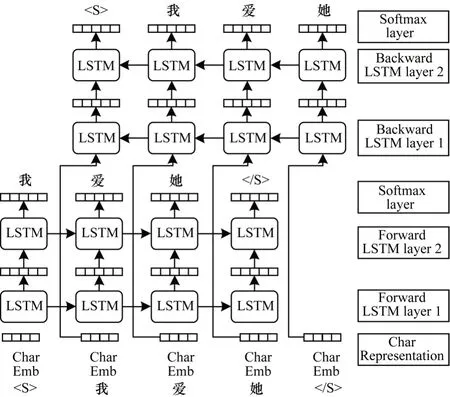
图2 基于字的语言模型Fig.2 Character-based language model
不同于传统的上下文无关字向量,上下文相关字向量直到整个句子被构造出来才确定。因此,每个字向量都是上下文相关的,一旦预训练完成,通过双向语言模型就可以得到上下文相关字向量。对于第k个时刻,前向语言模型的隐状态为,后向语言模型的隐状态为。因此,对于第k个时刻,L层双向语言模型可以得到2L+1 个向量表示,如式(11)、式(12)所示:
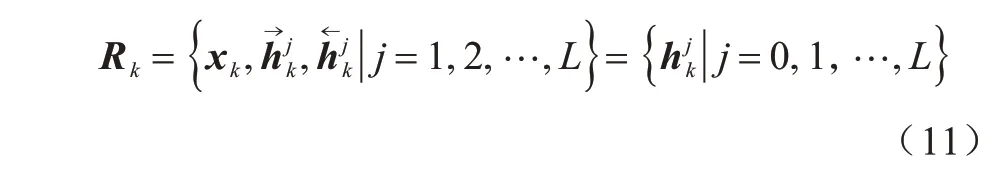


3.1.2 基于五笔的语言模型
在基于五笔的语言模型中,将字转换为其对应的五笔编码形式,将句子转化为五笔编码序列。如文本表示“爱国家”,其对应的五笔序列表示为“epdclgyipeu”。本文基于五笔的编码方式将句子转换为五笔字符串r1,r2,…,rm。汉字的五笔表示包含多个五笔码元(用英文字母表示),每个五笔码元刻画汉字的字形信息,汉字与汉字的五笔编码之间使用特殊字符“”分隔。本文不再将字或词当成一个最小的处理单元,而将五笔的码元当成最小的语义单元。
预训练一个基于五笔序列的语言模型(简称五笔语言模型),该语言模型的目标是学习一个五笔序列分布p(r1,r2,…,rm),根据前一个五笔码元序列预测后一个五笔码元。在基于五笔的语言模型中,对于输入序列“epdclgyipe”,其对应的输出序列为“pdclgyipeu”,与基于字的语言模型类似,基于五笔的语言模型同样通过堆叠的LSTM 来训练前后向的语言模型。
与基于字的语言模型得到上下文相关字向量表示不同,本文利用预训练的五笔语言模型的内部状态来产生一种新型的上下文相关字向量。在五笔语言模型训练完成后,根据五笔的前向语言模型和后向语言模型中最后一层的隐状态创建字的向量表示。图3 中的“国”对应的五笔编码“lgyi”,通过前向语言模型中“lgyi”前的“”隐状态和后向语言模型中“lgyi”后的“”隐状态的拼接,并作为“lgyi”的向量表示。这种字向量在没有任何明确的字或词的概念下训练,从根本上将字建模为五笔码元序列。此外,其可以随着上下文码元的不同而变化。在本文中,对于第k个字,基于五笔语言模型得到的上下文相关字向量为
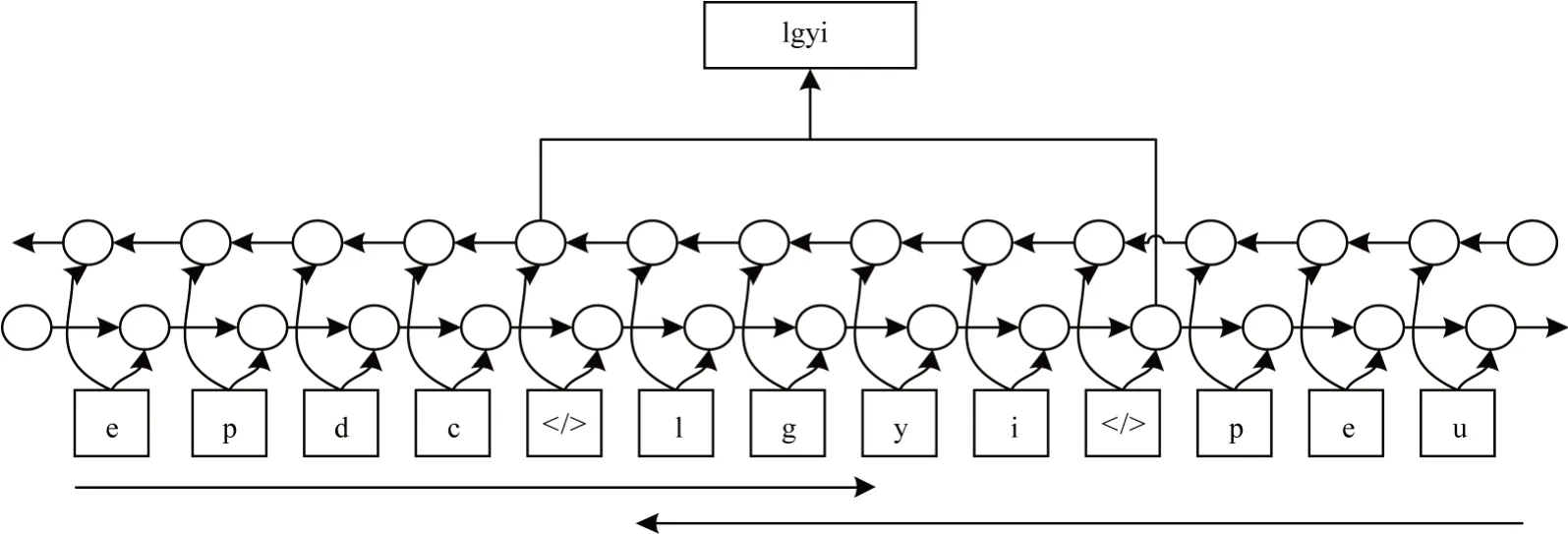
图3 基于五笔的上下文相关字向量表示Fig.3 Contextualized character embeddings representation based on Wubi
将上述基于字的语言模型和基于五笔的语言模型相拼接,得到本文第一种结合五笔的上下文相关字向量表示
3.2 基于字与五笔的混合语言模型
将字信息和五笔信息相结合,基于字和五笔混合语言模型构建本文所提第二种上下文相关字向量表示。在混合语言模型的训练过程中,字的嵌入表示和五笔编码表示相拼接作为语言模型的输入。对于句子c1,c2,…,cn,第k个时刻的输入包含字的嵌入表示和五笔表示,字的嵌入表示不作介绍,本文主要关注五笔表示。
图4 所示为五笔信息的获取方式,将句子中的每个汉字表示成五笔编码形式,如“爱国家”对应的五笔形式为“epdc lgyi peu”。对于“国”的五笔编码“lgyi”,利用多个卷积核从不同角度对其进行卷积以提取特征,然后通过最大池化进一步提取特征。为了防止网络过深导致梯度弥散从而难以训练,本文加入高速网络,高速网络的输出即为五笔编码的最终表示。
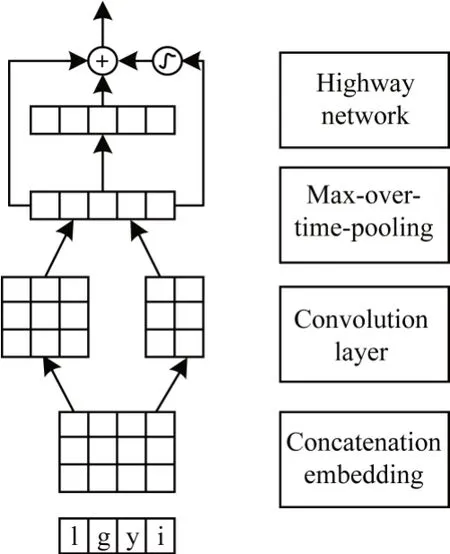
图4 五笔信息的获取方式Fig.4 The way of obtaining Wubi information
混合语言模型的训练同样是最大化前向语言模型和后向语言模型的概率分布。在混合语言模型训练完成后,通过类似ELMo 的方式获得第k个时刻包含五笔和字信息的上下文相关字向量
4 实验结果与分析
4.1 实验设置
4.1.1 实验数据
本文实验数据分为无标注数据和命名实体识别数据2 类。对于无标注数据,使用Gigaword(https://catalog.ldc.upenn.edu/LDC2003T09)训练基于word2vec的上下文无关字向量和语言模型。对于命名实体识别数据,为了从不同领域评估本文模型的性能,选取来自新闻领域的数据集Ontonotes 和社交媒体领域的数据集Weibo,2 个数据集的句子数和字数统计如表1 所示。
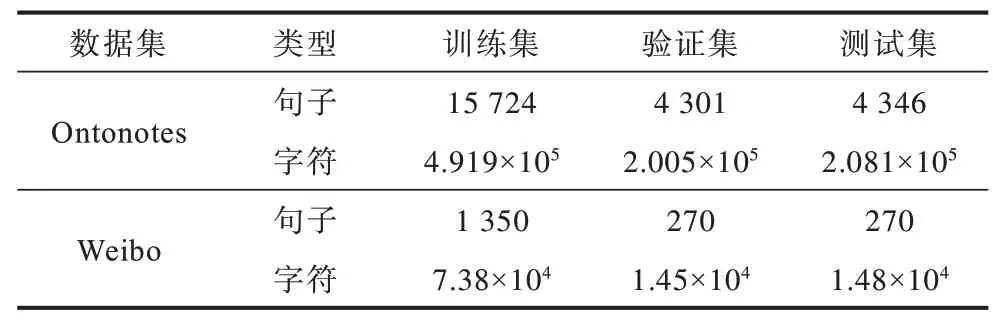
表1 数据集信息统计结果Table 1 Statistical results of datasets information
4.1.2 评价指标
实体识别需要同时识别实体的边界和类别,只有当实体边界和类别都识别正确时结果才算正确。本文实验使用综合指标F1 值来衡量模型性能,F1 值计算公式如下:

其中,N表示模型预测出的实体数目,M表示模型预测正确的实体数目,K表示标注数据中包含的实体数目。
4.1.3 标签框架
实验采用BIO 标签框架,B 即Begin,表示当前字是实体的第一个字,I即Inside,表示当前字是实体内的字,O 即Other,表示其他。对于某种具体类型(Type),某个字可选标注集合为{B-Type,I-Type,O}。
4.1.4 模型训练和参数设置
实验采用pytorch 深度学习框架,使用NVIDIA GeForce GTX 1080 Ti 加速模型训练。在BiLSTMCRF 模型中设置LSTM 隐层维度为200。采用Adam优化器更新神经网络的参数,对LSTM 输入向量和输出向量采用dropout 策略,概率设置为0.5。为防止模型过拟合,总训练轮次设置为50 轮,当连续迭代10 轮模型在开发集上的性能不再提升时模型停止训练。预训练语言模型均采用2 层BiLSTM,Embedding 映射维度为512,负采样窗口大小设置为8 192。其中,基于字与五笔的混合语言模型中使用256 个n-gram 卷积滤波器进行特征抽取。预训练语言模型的迭代次数设置为10,当模型困惑度在开发集上不再明显降低时停止训练。
本文实验中的对比模型具体如下:
1)LSTM-CRF:即本文baseline 模型,其将双向LSTM 作为编码器,CRF 作为解码器,输入为传统字向量,即
2)LSTM-CRF-char:在baseline 的基础上,输入增加基于字语言模型得到的上下文相关字向量,即输入为
3)LSTM-CRF-wubi:在baseline 的基础上,输入增加基于五笔语言模型得到的上下文相关字向量,即输入为
4)LSTM-CRF-concat:在baseline 的基础上,增加基于字的语言模型和基于五笔的语言模型得到的2 个上下文相关字向量的拼接,对应本文所提第一种结合五笔的上下文相关字向量表示,即输入为xk=
5)LSTM-CRF-hybrid:在baseline 的基础上,输入增加基于字和五笔的混合语言模型得到的上下文相关字向量,对应本文所提第二种结合五笔的上下文相关字向量表示,即输入为
4.2 结果分析
表2、表3 所示为Ontonotes 和Weibo 2 个数据集上的实验结果。从表2、表3 下半部分可以看出,模型在增加上下文相关字向量(LSTM-CRF-char)后,命名实体识别的性能在Ontonotes 和Weibo 数据集上分别提升9.04 和6.19 个百分点。从表2、表3 最后两行可以看出,本文所提2 种结合五笔的上下文相关字向量(LSTM-CRF-hybrid 和LSTM-CRF-concat)在2 个数据集上的F1 值相比基于字的上下文相关字向量(LSTM-CRF-char)有了进一步提高,在Weibo 上尤为显著,最高提升3.03 个百分点,说明在预训练语言模型中引入五笔字形信息具有有效性。此外,LSTM-CRF-concat 比LSTM-CRF-hybrid 效果更好,原因是基于五笔的语言模型不仅可以学习到汉字本身的字形信息,而且可以学习到上下文的码元信息。
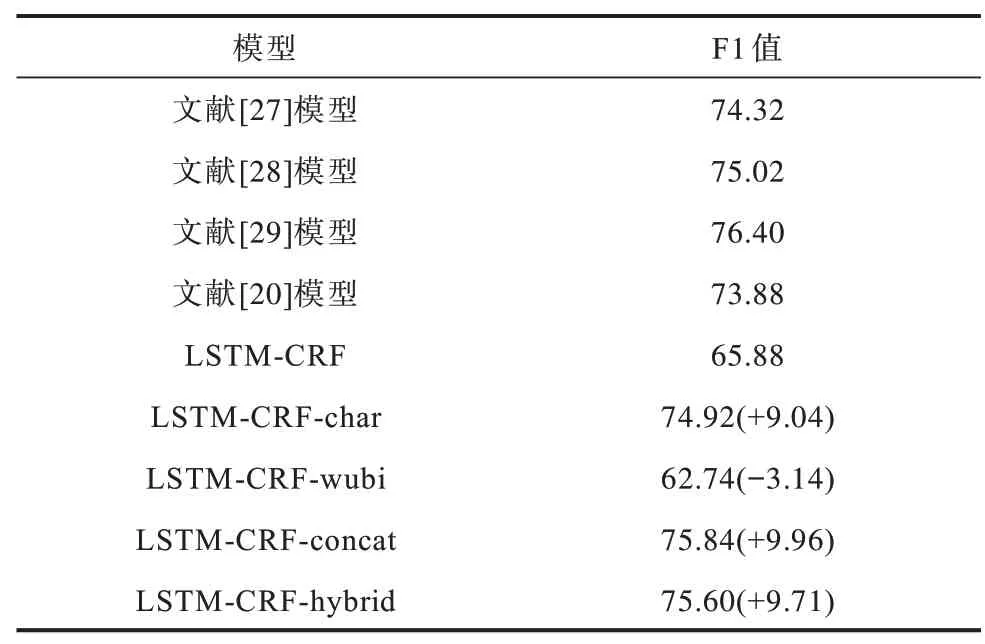
表2 Ontonotes 数据集上的实验结果Table 2 Experimental results on Ontonotes dataset %
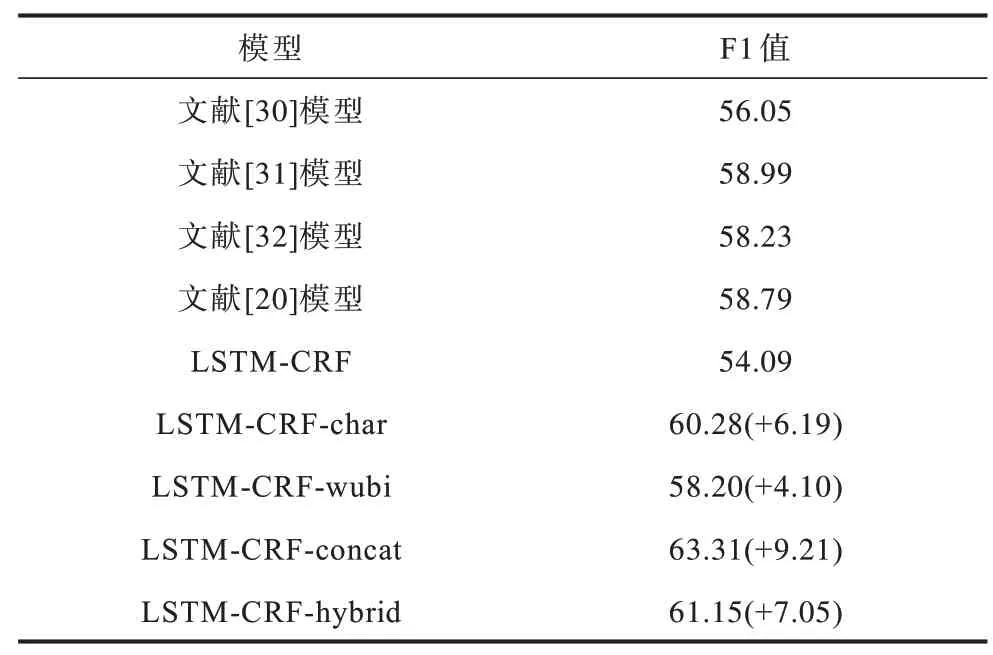
表3 Weibo 数据集上的实验结果Table 3 Experimental results on Weibo dataset %
在表2 中,文献[27]模型使用一种基于中英双语语料的方法,LSTM-CRF-char 在没有借助英文语料的情况下F1 值仍然比其高0.6 个百分点,说明上下文相关字向量能大幅提升语义表征能力。文献[27]模型通过结合基于多种手工特征以及外部资源的CRF 和基于神经网络的LSTM-CRF 模型,使得命名实体识别性能达到76.40%。相比之下,LSTMCRF-concat 完全没有使用手工设计特征和模型融合,但是F1 值仅比文献[29]模型低0.56 个百分点。在表3 中,文献[31]模型和文献[20]模型分别利用分词和外部词典来更好地判断实体边界,本文方法的F1 值比文献[31]模型高4.32 个百分点。Weibo 数据集来自社交媒体领域,文本的表达通常是非正式的,包含很多噪声,从表3 可以看出,模型在Weibo 数据集上的结果与Ontonotes 结果一致,说明结合五笔增强的上下文相关字向量在社交媒体领域同样有效,而没有因为领域的不同导致命名实体识别系统性能下降。
4.2.1 五笔信息与WC-LSTM 相结合对识别结果的影响
基于字的命名实体识别方法虽然取得了较好的效果,但是其未利用句子中词的信息。词的边界往往也是命名实体的边界,词的边界信息可以帮助基于字的命名实体识别方法确定命名实体的边界。文献[33]提出一种可以同时整合字和词信息的WCLSTM(Word-Character LSTM)模型。为了进一步验证本文所提方法的有效性,在WC-LSTM 模型的输入中增加结合五笔的上下文相关字向量表示,从而同时对五笔、字和词的多个层面进行特征表示。
从表4 可以看出,增加了基于五笔的上下文相关字向量的WC-LSTM 模型,命名实体识别性能进一步提升,性能优于表2 中的文献[29]模型,这说明词、字、五笔携带的信息不同,对中文命名实体识别具有不同的作用。

表4 Ontonotes 数据集上的模型性能对比Table 4 Performance comparison of models on Ontonotes dataset%
4.2.2 训练数据规模对识别结果的影响
为了验证在训练不充分的情况下基于五笔的上下文相关字向量对命名实体识别性能的影响,本文从Ontonotes 训练数据中分别随机选取5%、10%、20%、50%和100%比例的数据作为训练集,固定验证集和测试集,然后进行对比实验。从表5 可以看出,训练数据规模越小,基于五笔的上下文相关字向量对模型性能提升越大,这说明基于五笔的上下文相关字向量可以在一定程度上缓解模型在小数据集上的欠拟合问题。

表5 数据规模对模型性能的影响Table 5 The impact of data size on models performance%
5 结束语
中文预训练语言模型在命名实体识别时仅对字符进行建模而较少关注中文特有的字形信息。本文考虑中文五笔字形的优势,将其作为额外的输入信息,提出2 种融合字形信息的上下文相关字向量表示方法。第一种方法在预训练语言模型中引入额外的五笔编码器以丰富字向量表示,第二种方法对五笔序列进行建模从而抽取字向量表示。实验结果表明,2 种方法在实体识别任务中取得了较高的F1 值,且结合五笔的上下文相关字向量表示方法的性能优于基于字的上下文相关字向量表示方法。语言模型BERT[34]具有更强的特征编码能力,在各项识别任务中取得了较好效果。下一步考虑在BERT 中结合五笔编码特征提取来增强语义表达,以获取更高的命名实体识别性能。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
小学阅读指南·低年级版(2017年4期)2017-04-24
小学阅读指南·低年级版(2017年1期)2017-03-13
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
