
基于FP-Growth算法的词性标注规则获取方法*
2021-03-04 02:33莫礼平黄永琨
吉首大学学报(自然科学版) 2021年4期
莫礼平,黄永琨
(吉首大学信息科学与工程学院,湖南 吉首 416000)
词性标注是指根据上下文内容的语法关系,对句子中的各个单词进行词性判定和标注的过程.该过程是语料加工、语义分析、文本索引、文本分类、机器翻译和信息检索等自然语言信息处理应用领域不可缺少的重要环节,对于消除单词歧义、减少查询模糊性、降低索引量、提高检索效率有重要影响[1-2].词性标注方法可以分为规则类方法和统计类方法2大类:规则类方法通常采用人工方式编制复杂的词性标注规则系统,再依据这些标注规则进行词性标注;统计类方法主要利用相邻词性标签之间的同现概率及统计模型,借助标注语料库来实现词性标注.以隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)为代表的传统统计模型用于词性标注能够取得较好的标注结果,但过于依赖人工设计的特征[3-4].近年兴起的循环神经网络(Recurrent Neural Network,RNN)深度学习模型能够将词的特征表示和词性标注过程纳入到同一框架,极大地减少对人工设计特征的依赖[5].目前学术界的流行做法是,将长短期记忆(Long Short-Term Memory,LSTM)网、双向长短期记忆(Bi-directional Long Short-Term Memory,BiLSTM)网等改进型的RNN及其与卷积神经网络(Convolutional Neural Network,CNN)、CRF等模型组成的混合模型应用于词性标注研究.近年来,学者关注较多的主要有BiLSTM-CRF,CNN-LSTM,LSTM-RNN-CRF和BiLSTM-CNN-CRF等混合模型,这些模型在面向汉语、朝鲜文、维吾尔文等语言文字的词性标注系统或测试集上均展示出显著优于传统统计模型的标注效果[6-10].
无论是基于传统统计模型还是深度学习模型的词性标注方法,都依赖于训练用的标注语料库中语料的词性标注准确性.利用词性标注规则优化训练语料库,是提高训练语料质量的一种有效途径.然而,人工编制的标注规则依赖于编制者的主观意识,标注准确率有待验证.为了提高标注准确率,李晓黎等[11]根据上下文的相邻词及其词性等信息来研究词及词性组合成的模式序列对词性标注的影响,提出应用关联规则挖掘Apriori算法自动获取中文词性标注规则的方法,并将获取的规则用于优化训练语料库,在一定程度实现了训练语料质量的提升;然而,这种方法因时耗太长,仅适用于从小规模语料库中提取词性标注规则.因此,笔者尝试用FP-Growth算法从训练语料库中自动获取词性标注规则,以期为不同词级规模的训练语料库的优化提供一种实用的词性标注规则获取途径.
1 关联规则挖掘的相关定义及算法
1.1 相关定义
关联规则挖掘[12]是指,从大量事务数据中挖掘出反映事务描述数据项之间相互依存和关联的有价值的知识,发现存在于数据项或数据属性间的有意义但事先未知且隐藏的关系.现引入如下关联规则挖掘相关的定义[12]:
定义1数据库中不可分割的最小单位信息称为项目.
定义2一个数据库中所有项目构成的集合称为项集,记作I={I1,I2,…,Im}.
定义3一系列具有唯一标识的事务所组成的集合称为事务数据库,记作T={t1,t2,…,tn}.每一个事务ti包含的项集Ii都是I的子集.
定义4包含某个项集的事务个数称为该项集的频数(即支持度计数).
频数反映了项集在不同事务中出现的次数.
定义5形如X=>Y(其中XI且YI且X∩Y=Ø)的蕴含式称为关联规则,其中X称为规则前提,Y称为规则结果.
关联规则反映了Y中的项目跟随X中的项目出现而出现的规律.
定义6事务集中同时包含项集X和Y的事务数与事务集中所有事务数之比称为关联规则X=>Y的支持度,记作S.
支持度反映X和Y中所含的项在事务集中的同现频率.用户指定规则必须满足最小支持度阈值Smin,最小支持度阈值表示关联规则的最低重要性.
定义7事务集中同时包含项集X和Y的事务数与包含X的事务数之比称为关联规则X=>Y的置信度,记作C.
置信度反映Y出现在包含X的事务集中的条件概率.用户指定规则必须满足最小置信度阈值Cmin,最小置信度阈值表示关联规则的最低可靠性.
定义8若关联规则X=>Y满足S(X=>Y)≥Smin且C(X=>Y)≥Cmin,则称之为强关联规则;否则,称之为弱关联规则.
通常所说的关联规则一般是指强关联规则.
定义9事务数据库的项集I中支持度不小于Smin的项集,称为频繁项集.
1.2 相关算法
关联规则挖掘的关键在于发现所有频繁项集.关联规则挖掘算法基于项集空间理论,该理论的核心是频繁项集的子集仍是频繁项集,非频繁项集的超集仍是非频繁项集[12].Apriori算法和FP-Growth算法是挖掘频繁项集的较经典的算法,被广泛应用于商业、网络安全等领域.
Apriori算法采用“试探”策略,通过不断地构建、筛选候选集来挖掘频繁模式集.Apriori算法原理简单,易于实现,但其瓶颈在于,获取较长的频繁模式必须以生成大量的候选短频繁模式为基础,需要多次扫描原始数据库.当原始数据量较大且存放于磁盘时,磁盘I/O次数太多,导致Apriori算法效率低下.
FP-Growth算法可以突破上述瓶颈.它根据事务包含的数据项构建FP-tree结构,对原始数据进行压缩,并使用条件模式基FP-tree挖掘频繁模式,扫描原始数据库2遍即可完成频繁模式集的挖掘任务.不同事务所共享的数据项在FP-tree中以重叠路径出现,路径重叠越多,说明数据压缩效果越好.FP-tree较小时,FP-Growth算法直接从内存中获取频繁模式集;FP-tree较大时,FP-Growth算法根据包含某个数据项的所有事务来构造投射数据库,将大数据库分解成几个可以放到内存中的小数据库,再分别对这几个小数据库执行FP-Growth算法.
2 词性标注规则挖掘问题描述
2.1 词性标注规则的相关定义
词性标注规则反映文本中相邻词及其词性之间的相互依存性和关联性,其形式可以设计为由条件和结果构成的布尔关联规则.为了便于描述,给出如下集合说明[11]:
(1)单词集W={wi|i=1,2,…,n},词性标签集T={ti|i=1,2,…,n},模式集I=W∪T,其中wi,ti分别表示第i个词和第i个词性标签.
(2)已标注文本T′={(wi,ti)|wi∈W,ti∈T},其中ti是词wi在该文本中对应的词性标签.
(4)模式集P={pi|i=1,2,…,n,且pi∈I+},其中pi是词与词性标签的组合串.
参考文献[11-12],进一步给出如下定义:
定义10给定模式A∈P,若其长度L(A)=k,则称A为k-模式.
最基本的模式是项集(即若干个项目的集合).
定义11给定模式A∈P,集合Z={B|B∈P,且L(A)=L(B)},用f(A)表示A出现的频率,f(Z)表示所有长度为L(A)的模式出现的总频率,称A在同长度模式中所占的比例为A的支持度,即S(A)=f(A)/f(Z)).
定义12给定最小支持度Smin,称集合Sfreqpatt={A|A∈P,S(A)≥Smin}为频繁模式集,其中元素A称为频繁模式.
定义13若A,B均为频繁模式,且A,B之间有关联(关联规则记为A=>B),则该规则的支持度为S(A=>B),可信度C(A=>B)=P(B|A)=f(AB)/f(A),其中f(AB)是模式A,B同时出现的频率.
定义14给定最小可信度Cmin,若C(A=>B)≥Cmin,则称关联规则A=>B是值得信赖的规则.
定义15从模式集I中取k-模式Ii=(a1a2,…,ak-1ak),其中第k个词wk的词性标签ak∈T,则词性标注规则定义为
(1)
(1)式的含义是,若串中的前k-1个词或词标签组成的序列为模式(a1a2,…,ak-1ak),则取ak为第k个词wk的词性标签.
定义16给定大于Smin的正数M,若规则A=>B的支持度S(A=>B)
2.2 词性标注规则设计
应用关联规则挖掘算法自动获取词性标注规则的过程,就是从已标注词性的训练语料库中挖掘不同长度的频繁模式,并根据挖掘结果生成共性可靠的词性标注规则的过程.规则的适用范围和可靠程度分别用支持度和可信度表示.简便起见,本研究中只讨论长度最多为3的前制约情况,即由前面的1个或2个词的词性来确定当前词的词性.表1给出了对于不同长度频繁模式生成的词性标注规则的形式及示例.

表1 对于不同长度频繁模式生成的词性标注规则的形式及示例
3 词性标注规则获取方法设计
3.1 基本原理
利用关联规则挖掘FP-Growth算法获取词性标注规则,本质上就是以词性标注训练语料库作为事务数据库,从事务数据库中挖掘由词与词性标签的组合串构成的强关联规则的过程.该过程可分为候选模式集计算、频繁模式集获取和关联规则生成3个阶段.首先,用FP-Growth算法扫描事务数据库,构建用于存储候选模式集的模式前缀树FP-tree,获取训练集中每个句子各个长度的模式,以得到候选模式集;然后,构建条件模式基FP-tree,从候选模式集中挖掘大于Smin的各种长度模式的频繁模式集;最后,按定义15对每个频繁模式构建形如“(a1a2,…,ak-1ak)=>(wk,ak)”的关联规则,若该规则满足C((a1a2,…,ak-1ak)=>(wk,ak))>Cmin,则得到一条有效的词性标注规则,将其加入规则库.
3.2 过程描述
Step 1 若S′为空集,则转step 7.
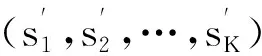
Step 4 若K-L+1>M,则取出“(wL,tL),… ,(wL+W-1,tL+W-1)”,L←M;否则,取出“(wL,tL),… ,(wK,tK)”,L←K-L+1,继续构建模式前缀树.
Step 5 Forj=2 TOL循环执行“从模式前缀树中取长度为j且包含(wL,tL)的模式串P;Pcount←Pcount+1;Scandpatt←Scandpatt∪{P};Nsum[j]←Nsum[j]+1”.
Step 6L←L+1,转step 3.
Step 7 若Scandpatt为空集,则转step 10.
Step 8 取P∈Scandpatt,构建条件模式基树,Scandpatt←Scandpatt-{P}.
Step 9 从条件模式基树根出发,逐个检查i-模式,若(Pcount/Nsum[i])>Smin,则执行Sfreqpatt←Sfreqpatt∪{P},再转step 7;否则,直接转step 7.
Step 10 若Sfreqpatt为空集,则算法结束.
Step 11 任取P=(a1a2,…,ak-1ak)∈Sfreqpatt,Sfreqpatt←Sfreqpatt-{P}.
Step 12 若ak∈T且C(a1a2,…,ak-1ak)>Cmin,则先将“if (a1a2,…,ak-1ak) then (wk,ak)”加入到词性标注规则集,再转step 10;否则,直接转step 10.
Step 1~6对应候选模式集生成步骤,step 7~10对应频繁模式集计算步骤,step 11~12实现从频繁模式集中提取词性标注规则并加入到规则集.
4 仿真对比实验
为了验证基于FP-Growth算法的词性标注规则获取方法(方法1)的可行性和有效性,将其与基于Aprior算法的词性标注规则获取方法(方法2)进行对比实验.实验在Intel(R)Core(TM)i7-4720 HQ CPU @ 2.60 GHz、8G 内存、Win10 操作系统条件下进行,采用 Python3.8.5 编程实现算法;训练语料库选用来自 https:∥github.com/liwenzhu/corpusZh的已标注词性的中文语料库corpusZh.支持度和可信度均设置为0.7,针对0.1万、0.2万、1万、10万、100万词级规模的训练语料库得到的对比实验结果见表2.

表2 对比实验结果
由表2可知:
(1)对于 0.1万、0.2万和1万词级规模的训练语料库,方法1和方法2获取的词性标注规则条数相等,但耗时存在万倍以上差别.
(2)对于10万和100万词级规模的训练语料库,方法2在本实验环境下运行时出现内存异常现象,无法获取任何规则;但方法1在754 s内从10万词级语料库中成功获取3 741条规则,在697 834 s内从100万词级语料库中获取35 286条规则.
显然,方法1可行且效率优于方法2.
5 结语
为了提高词性标注模型所需的训练语料的质量,笔者设计了一种基于FP-Growth算法的词性标注规则自动获取新方法,并以中文词性标注规则自动获取为例,将新方法与基于Apriori算法的词性标注规则获取方法进行了对比实验.实验结果表明,新方法能够有效弥补基于Apriori算法的词性标注规则获取方法因多次扫描数据库而导致的耗时长、效率低,且仅适用于万词级以下小规模语料库的不足,即使是面对百万词级语料库,依然可以在合理的时间内获取有效的词性标注规则.显然,基于FP-Growth算法的方法适用于从较大规模、已标注的训练语料库中以关联规则的形式获取词性标注知识,能为后续词性标注技术的研究提供新思路.
猜你喜欢
节能与环保(2022年7期)2022-11-09
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
外语学刊(2021年1期)2021-11-04
计算机技术与发展(2019年7期)2019-07-23
计算机技术与发展(2019年7期)2019-07-23
师道·教研(2017年11期)2017-12-10
电脑知识与技术(2017年27期)2017-11-20
计算技术与自动化(2017年3期)2017-10-26
科技创新与应用(2017年3期)2017-02-18
外语教学理论与实践(2014年4期)2014-06-13
