
再论定量测量程序质量控制计划的设计和实施*
2021-02-10 07:49周睿王清涛首都医科大学附属北京朝阳医院检验科北京100020北京市临床检验中心北京100020
临床检验杂志 2021年12期
周睿,王清涛(1.首都医科大学附属北京朝阳医院检验科,北京 100020;2.北京市临床检验中心,北京 100020)
由国际标准化组织(International Organization for Standardization,ISO)起草的ISO 15189国际实验室认可准则规定“实验应设计质量控制程序以验证达到预期的结果质量的目标”,但是没有明确该如何实现这一目标。美国临床和实验室标准协会(Clinical and Laboratory Standards Institute,CLSI)指南类文件及国内行业标准《临床检验定量测定室内质量控制》明确了实现该目标的方案框架,但是仍无法在实验室有效实施。这是因为:第一,实验室重视质量,同时要考虑成本;第二,现今实验室关注的质量控制,准确地说是质量的符合性,即:与法规的符合性,与认可准则的符合性和与国际标准的符合。如果不清楚实验室质量究竟需要控制什么,应该如何控制,需要达到何种标准,则所说的质量控制就并非真正意义的质量控制,只能称为过程控制,甚至是“随意控制”。如何在实验室设计和实施正确、适宜的质控计划,值得认真思考。
1 基于稳定质控物的室内质控(internal quality control, IQC)
传统室内质控是医学实验室质量管理技术手段之一。目前实验室多数检测项目质控程序采用13s质控规则,在定义的24 h分析批内,测试2个水平的质控物,测试频次为1次,即不同专业、不同项目、不同设备采用相同质控程序。美国CLSI C24 A4及EP23A2技术指南提出基于风险管理思路设计和实施IQC计划,其中包括质控物数量、质控结果数量、质控规则和质控频次等关键要素。在质控实施中,以6σ为质量控制评价标准,较易实施。σ可理解为与临界系统误差(△SEcrit)相关的效能指数,公式为σ=[(TEa-biasmeas)/smeas]=△SEcrit+1.65s。其中,TEa表示测试项目的允许总误差。2014年国际共识将TEa分类3类,分别为:(1)根据临床结局确定的TEa标准,(2)根据待测物生物学变异度确定的TEa标准,(3)根据当前检测技术水平确定的TEa标准[1]。SEcrit为测试项目的临界系统误差,表示在某项目的临界系统偏移识别率为0.9或90%情况下,导致发出错误检测报告的风险为5%。σ越高,说明实验室测量程序性能越好,故质控程序可选择相对简单的单一质控规则,使用较少的质控测试数,且定义较长的分析批,就能达到理想的监控效果。例如,当测量程序达6σ时,质控批长度定义为250患者样本情况下,采用13s规则,质控测试数为2的统计学质量控制(statistical quality control,SQC)程序,误差检出率(error detection rate,Ped)仍可达1.00。而若测量程序为3σ,使用上述相同IQC程序则不能对分析过程进行有效监控。
由于测试量的增加和检验模式的改变,现在的实验室已非以前定义的实验室。例如,测试量的增加表现为在大型医疗机构中心实验室多台检测设备测试同一检测项目,而检验模式改变表现为区域检测中心不同实验地点测试相同的检测项目。故质量控制模式也随之发生变化。ISO15189 5.6.2.2准则描述,质控频率应基于检验程序的稳定性和错误结果对患者危害的风险而确定。故无论使用何种质控技术,均应合理确定质控分析批。CLSI C24-A2定义分析批为使分析测量系统的正确度和精密度处于稳定状态的时间间隔或其间所包含的测试标本数[2]。由于实验室通过质控样本评估每个分析批的方法性能,所以评估质控结果的时间间隔可作为1个分析批。平均批长度(average run length,ARL)是指观测到质控失控报警前分析批数的平均值。CLSI C24-Ed4根据质控位点,将质控计划分为批质控(batch QC)、连续质控(bracketed QC)和关键点质控(critical control point QC)。批质控需要定义在某个时间段所有患者测试样本的起、止时间点。对于此类质控计划,质控位点设置在所有测试的起、止点以及根据测量程序稳定性确定的其他质控位点。连续质控未定义针对测试样本的起、止点,质控物定期插入患者标本进行测试。因此,对于此类质控计划,分析批的确定非常重要。关键点质控指将影响检测质量的已知关键点作为质控位点,例如定标、维护保养、试剂或定标品批号改变、试剂批次改变等。Yago、Alcover和Bayat设计的诺莫图可通过实验室计算的值,定义分析批,但是以此确定的IQC程序未考虑假阳拒绝概率(Pfr)[3-4]。总之,目前基于风险评估的传统质控技术由于缺乏有效的软件工具,连续质控和患者报告间的可操作性等问题,未能在实验室有效实施。
2 基于患者样本的实时质量控制(patient-based real-time quality control,PBRTQC)
目前,越来越多的学者认为仅使用传统质控不能准确、快速识别分析误差。首先,传统质控缺乏互换性,一方面会导致误差识别的真阳性率降低或假阳性率升高,另一方面会导致IQC靶值与仪器相关,而非待测物真实水平。第二,由于IQC假定误差是持续的,需要到下一个质控点才能检出,故该方法无法有效监控短期的系统漂移。第三,IQC可理解为在某一时间点的回顾性过程质控,而非实时质控监控。第四,IQC的测试成本问题也不容忽视。1965年,Hoffmann和Waid提出了一种基于患者数据的质控方法,称为平均正常值法(average of normals,AON),但是由于此方法数据获取困难以及计算量大,当时并未在临床得以应用[5-6]。1974年,出现AON质控方法的一种变体Bull算法,首次商业化应用于自动血液分析仪的质量控制。随后,该方法也被国际学者们不断研究并改进,涌现出一类基于患者数据的衍生算法,该类方法可以实时工作,因此被统称为PBRTQC[7]。
PBRTQC的基本原理是将一批数据转换成一个均值,然后给均值设置一个控制限范围,超出该范围判定为失控。不同PBRTQC算法的本质区别在于计算均值的方式:MA算法是计算各批次下的平均值;EWMA算法是在MA的基础上通过权重连接相邻2个批次的均值;Xbar算法与EWMA类似,通过统计批次间的波动量连接相邻2个批次的均值;MM算法是计算各批次下的中位数,比MA更稳定;HD50算法与MM类似,利用统计估计的方式选取中位数;MovSD算法是计算各批次下的标准差;MovSO算法是根据某浓度水平将数据划分为正常或者异常,在每个批次下计算异常值的个数;AOD法是计算患者2次结果的差值(delta)[8]。PBRTQC为仅利用实验室生成的患者结果数据监测分析系统性能改变的质控方法,其性能受数据分布及实验室操作等因素影响,常见于:(1)病理、生理导致的个体生物学变异;(2)待测物整体人群中的不同亚组,如儿童、性别、孕产期等;(3)实验室操作的影响,例如1周内会有某天实验室检测透析室患者,当天肌酐检测数量标本数增多,导致该时段的平均肌酐浓度的检测值升高;(4)对于某些测试,因临床解释不同导致的样本结果错误诊断和分类[9]。因此,在应用前需要对数据进行严格清洗,选择相对稳定的患者人群的检测结果,排除分析系统改变以外的“噪音”。可以选择实验室有代表性的至少1年的数据,分年龄、性别、临床服务、医嘱申请科室、日期和时间绘制散点图,观察数据分布情况、单位时间内测试数量等,用于数据筛选。
清洗后数据用于实施PBRTQC,包括4个关键步骤:(1)数据拦截与转态,(2)计算平均值,(3)确定控制限,(4)实施监控。关于步骤1,通过数据拦截进一步去极值,通过转正态使得数据在偏态、峰态上呈现正常的分布,这2个环节对于某些算法来说非必要步骤,如图1所示,依算法原理而定。步骤2中利用滑动窗口长度(步长)及适宜的PBRTQC算法,将样本队列换算为浮动基准队列。在步骤3中,针对浮动基准队列作相应的统计分析,从中筛选上、下控制限(control limits,CLs)。PBRTQC算法中CLs的计算,可选取不同计算方式[7]。在步骤4实际监控的环节即通过CLs判断状态,报警后需验证报警信息的有效性,排除分析系统改变以外因素,尽量减少误报警。验证方法包括但不限于:(1)更换设备,比对患者样本;(2)测试质控样本;(3)测试能力验证或室间质评样本;(4)审核患者信息及检测结果等。
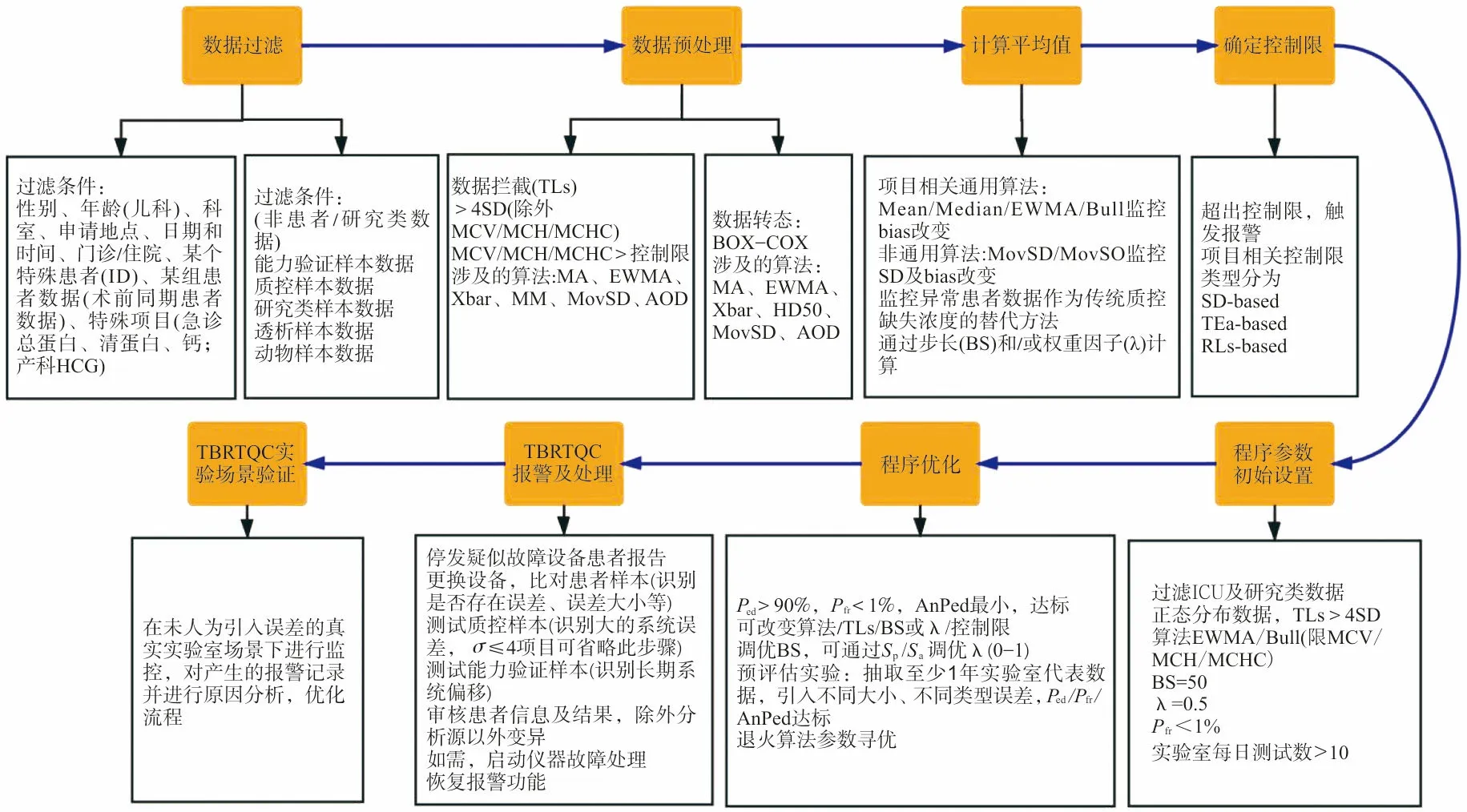
图1 PBRTQC实施流程
PBRTQC作为一种新型质控技术,虽然不能完全替代传统IQC,但是可以建立联合IQC策略,有效弥补传统IQC的不足,并可使质控物的测试量减少75%~85%[8]。
3 基于机器学习技术的新型质控方法
机器学习(machine learning,ML)作为人工智能领域的一个分支,在语音识别和计算机视觉等方面得到飞速发展,在医疗领域的应用也逐渐成熟。近年来在互联网大数据这一环境下,ML的发展为医疗与健康服务带来了变革与创新。目前,ML技术主要集中于对医学图像、电子病历、药物研发和基因组学的分析等,被广泛应用于疾病预防控制中心(The Centers for Disease Control and Prevention,CDC)的预防医学及临床医学。ML中的分类算法适用于实验室质控监控场景,即可以将仪器稳定状态下的患者检测数据认定为无偏数据,将仪器异常改变转态下的患者数据视为有偏数据,利用ML的分类算法区分这2类数据。由于质控的研究对象是单个检测项目,而机器学习算法需要多个特征信息,因此需将患者结果数据按批次组队,以批为1个整体,既引入了序列化特性,又满足了机器学习算法的需求,由此完成将医学问题向数学问题的转化。实验过程中将所有收集的无偏样本均认定为“0”类,人为引入不同大小、不同类型误差后的各组有偏样本均认定为“1”类。通过的大量数据迭代,将2类数据的分布规律归纳成超曲面,最终将2类数据加以区分。
ML质控实验流程如图2所示,算法模型训练及测试的主要步骤如下。首先,通过特征工程对ML模型训练前的所有数据进行预处理,主要涉及单位量纲转化、数据滤过、数据标准化及队列组织。可通过异常控制比例这一超参数控制数据过滤的比例,相当于数据拦截。再对洗涤后数据进行正态性转化,并将转化后的数据组织成一个定长待测队列。根据临床应用场景,可以按照不同大小的误差因子训练模型。将数据按8∶2划分为训练集和测试集,训练集用来提供模型的学习样本,测试集用来验证模型的质量。通过调节步长大小和算法内参,对模型进行优化。重复上述步骤,可以根据不同的误差大小为节点训练多个模型。系统误差包括比例误差、恒定误差,误差节点统一按照比例误差的百分比因子来划分:系统误差<20%的,按照“±20%,±16%,±12%,±8%,±4%,±1%”的异常大小进行模型训练;针对随机误差数据分布特性的缘故,训练节点按照“±50%,±40%,±30%,±20%,±16%,±12%,±8%,±4%,±1%”的异常大小进行模型训练。检测过程中,针对每个项目,将所有节点模型平行部署,其中1个模型输出异常便算作该组样本异常。实验证明,在相同假阳性率的情况下,ML算法对质控失控识别准确度和识别效率显著优于传统PBRTQC算法。

图2 ML质控实验流程
4 适合于当前检验模式下复合型质控策略探讨
IQC实施过程应根据仪器性能及应用场景确定关键评价指标的质量规范要求,例如,误差检出率、错误拒绝率、平均分析批长度等,以满足临床的预期用途,见表1。实际场景中,根据应用地点转移,可分室内质控和室内质控室间化;根据患者样本测试/报告模式不同,可分为连续质控、批质控模式以及关键点质控模式;根据使用功能不同,可分为起始点质控(start-up QC)和过程质控(monitor QC);根据质控物特征差异,可分为基于质控物QC和基于患者结果QC。

表1 质控方法差异性比对
有文献报道,当σ≤4时,PBRTQC质控效能优于传统质控物QC,可作为传统质控物QC补充[10]。其次,对于传统质控物效期短或质控物浓度水平不足的情况,也可选择PBRTQC质控。新型的ML质控,对于临床小误差场景或质量要求高的项目,例如,hs-cTnT/I或者tPSA项目,其误差识别的精准度显示出不可替代的优势,见图3。

图3 传统IQC/PBRTQC/MLQC复合质控策略流程
对于实际场景中用于实验室内批报告模式,质控模式最低设置为起始点质控与关键点质控组合。对于连续报告模式,建议采用连续质控模式。但是无论哪种报告模式,质控监控过程均应确定适宜的分析批,保证受影响的患者样本数(ANPed)最小化,而PBRTQC质控是监测分析批稳定的最佳质控方式。
室内质控室间比对也是目前质控技术的又一研究热点,可以帮助实验室利用同组室间比对数据发现实验室内部的分析源改变。以PBRTQC为例,相对于其室内质控监控功能,在实施PBRTQC的室间监控时,变异因素更多,数据过滤仍是关键。建议考虑以下几个关键点。(1)数据过滤:选择门诊患者数据,实验室可自定义步长、时间窗口长度、过滤周末及节假日患者数据功能。(2)算法考量:建议采用统计学更为稳定的MM算法,可计算每日中位数或浮动中位数。(3)分组原则:建议按照专业、项目设计分组方法,如血常规项目可以按照仪器分组,生化项目可以按照方法学分组。对于实验室数少或仪器数量少的组,可以按缺省组处理;或通过散点图区别显示方式,若实验室所使用的仪器有别于其他实验室,散点图中对该实验室数据颜色加以区分,该实验室数据仅用于监测,不参与均值和CLs计算。(4)CLs设置:基于患者数据的室内质控室间比对的CLs宜小于该项目的常规室间质评标准,而大于室内质控标准。可选择基于生物学变异的偏移标准或采用同组标准差倍数方式设置CLs,两者取较大值。在实际操作中可根据项目的稳定性进行适当调整。(5)提供信息:实验室可按照单个实验室、同实验室组或所有仪器组提供长期中位数、长效精密度、同组偏移或所有设备靶值等信息。
5 实验室质控信息化
虽然PBRTQC方法已被证明方法的有效性,ML算法也在仿真中证实了优势,但是,实验室的信息技术如果缺乏一定的交互性和扩展性就会限制其实施。实验室应能访问满足用户需要和要求的服务所需的数据和信息[11]。因此,有必要为实验室信息学开发人员提供推荐规范的实施方式,以考虑将其纳入相应产品,同时为实现后续实验室QC的常规实践提供优化空间。所开发的信息系统包括作为实验室设备功能组成的计算机系统和适用通用软件(如生成、核对、报告及存档患者信息和报告的软件、文字处理、电子制表和数据库应用)的独立计算机系统。
建立QC系统的第一步是熟悉实验室数据和单个实验室内的运转模式。所有操作尽量通过数据可视化来展现,如散点图、直方图。可视化尽量体现多维信息,如果超过三维,可使用平行数轴法将不同维度横向铺设,通过使用颜色来区分多维数据。实验室信息学应包括简单的描述性统计工具来直观展现数据库、样本集的分布形态,以及平均值、中值、百分比值、标准偏差等统计量的计算。此外,用户可以自由根据拦截方式过滤数据,之后自动清洗整合,每个操作之后都可以通过统计描述曲线展示[12]。
对没有开展能力验证、室间质评的检验项目,应通过与其他实验室(如已获认可的实验室、使用相同检测方法的实验室、使用配套系统的实验室)比对的方式,判断检验结果的可接受性。在绘制室内质控图时,可使用Levey-Jennings质控图和(或)Z分数图。质控图应包括质控结果、质控物名称、浓度、批号和有效期、质控图的中心线和CLs、分析仪器名称和唯一标识、方法学名称、检验项目名称、试剂和校准物批号、每个数据点的日期和时间、干预行为的记录、质控人员及审核人员的签字这些信息。应制定程序对失控进行分析并采取相应的措施,应检查失控对之前患者样品检测结果的影响。允许将PBRTQC和IQC一起显示,或者单独显示。允许用户定义的不同演示模式选项,如显示连续每日、每台仪器、同一仪器多个项目、不同仪器同一项目、整个实验室或定义部门的监测情况[13]。
6 结语
复合质控策略可以更为合理地解释测量质量内在联系,更好地保证测试结果的可靠性、体现实验室的检测能力及分析测量系统的稳定性。该复合质控策略使用患者数据用于室内及室间监控,适用于现代实验室质量管理模式,能够为临床提供更为准确的检测结果。该复合质控策略的转化将成为实验室转化医学及患者关怀的典型范例。
猜你喜欢
今日农业(2021年17期)2021-11-26
电子竞技(2019年22期)2019-03-07
电子竞技(2019年21期)2019-02-24
电子竞技(2019年20期)2019-02-24
电子竞技(2019年19期)2019-01-16
领导决策信息(2018年16期)2018-09-27
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
