
基于问答交互的答案句选择算法
2021-01-27 03:42侯佳正张绍阳
计算机与现代化 2021年1期
侯佳正,张绍阳,鱼 昆
(长安大学信息工程学院,陕西 西安 710064)
0 引 言
答案选择任务是自然语言处理中句子匹配任务(NLSM)的一个子任务,用来评估问题-答案对之间的相关性,最终输出问答对的匹配得分,是完成问答系统[1-2]、文本处理等任务的基础。问答系统的答案处理模块需要确定问题与答案之间的相关性,根据相关性得分对答案句进行排序,最终向用户返回相关性最高的一个或几个答案;文本处理任务中需要根据问题句、主题句去剔除文本中与问题、主题无关的句子。其精度直接影响整个系统的好坏,所以提高答案选择任务的准确率具有十分重要的意义。
传统答案选择算法利用词法、句法等一些特征来计算问答对的匹配程度。Yih等人[3]利用单词匹配、WordNet和词汇之间的相似度、命名实体匹配等丰富的词汇级别的语义特征进行答案句的选择。Barron-Cedeno等人[4]使用自然语言处理工具包提取问答对的命名实体匹配、关键词匹配、单词长度等特征,然后将这些特征输入SVM进行分类,从而实现答案的选择。Yao等人[5]利用依存句法分析,构建问题与候选答案句的语法分析树,最后使用逻辑回归模型判断问题和答案之间的依存关系。基于特征匹配的答案选择算法,特征固定,可移植性差,并且只聚焦于句子的浅层特征,没有关注句子的整体语义信息。
随着深度学习在自然语言处理领域的发展,有很多学者将目光开始投向于深度学习算法,提出了基于Siamese结构[6]的网络,在该结构中,相同的神经网络编码器(CNN或RNN)被应用在问答对上,将问句和答句编码到相同嵌入空间的句子矢量中,然后仅根据这2个句子向量进行相关性的判断。栾克鑫等人[7]使用BiLSTM[8]分别对问答句进行编码,对输出的正向和反向编码级联,输出问答句每个时间步的结果,然后分别对问答句的隐层输出进行平均池化,再分别对问句和答句的输出和平均池化的结果应用注意力机制计算出句子的编码,最后在问答句的句子编码的基础上使用全连接层输出问答句匹配的结果。Tan等人[9]提出的QA-LSTM with attention模型首先使用BiLSTM分别对问答句进行编码,对输出的正向和反向编码进行级联,输出问答句每个时间步的结果,然后对问句的输出使用平均池化、最大池化得到句子编码,再将该句子编码与候选答案句中的每个时间步的隐层输出进行联合计算,得到候选答案句每个时间步的权值,对每个时间步的输出加权求和,得到候选答案句的句子编码,最终使用余弦定理计算这2个句子编码向量的相关性。余本功等人[10]提出的CA-LSTM模型,首先使用BiLSTM分别对问答句进行编码,输出问答句每个时间步的编码结果,然后将答句的所有时间步的编码结果分别与问句的每个时间步的编码结果进行点乘操作,进而计算得到答句每个时间步对应的权重系数,对答句每个时间步的编码结果进行加权求和得到答句的句子向量,最后将根据问句每个时间步得到的答句的句子向量进行求和得到最终答句的句子编码;问句的编码和上面操作类似,根据答句每个时间步的输出计算出问句最终的句子向量;将问答句的句子向量进行级联,再通过一个全连接层输出问答句最终的匹配结果。Yin等人[11]提出的ABCNN模型将注意力机制融入CNN中,对2个句子分别进行卷积和池化操作,最终输出2个句子的向量表示,然后对这2个句子向量做匹配。使用该网络结构的优点是参数共享使得模型更小,更容易训练,并且句子向量可以用于可视化,句子聚类和其他目的,但是上述参考文献尚存在问答句之间没有进行交互或交互性差的问题,这可能会导致一些重要信息的丢失。
为了解决Siamese结构网络2个句子交互性较差的问题,提出了基于匹配聚合[12-13]结构的网络,这种结构的网络首先对2个句子之间的单元做匹配,匹配结果通过一个神经网络(CNN或LSTM[14])聚合成一个向量,最后根据这个向量做判断。这种方式可以捕捉到2个句子之间的交互特征。Chen等人[15]提出了ESIM模型,该模型首先使用BiLSTM对句子对进行编码,输出每个时间步的隐层状态,然后使用对齐机制计算2个句子中时间步的语义匹配程度,得到一个匹配矩阵,根据计算结果,使用答句中所有时间步的输出对问句的每个时间步进行表示,将该结果与问句通过BiLSTM的输出结果进行级联、按位减、按位乘操作,将匹配结果输入另一个BiLSTM中得到一个向量表示,对答句的操作类似,最终也得到一个向量,最后通过一个全连接层输出最终的匹配结果。Wang等人[16]将问句通过BiLSTM输出的每个时间步上正反2个方向的向量分别与第二个句子对应方向上的向量在不同的粒度上进行匹配,答句进行同样的操作,然后将问答句得到的匹配结果依次输出另一个BiLSTM进行特征的聚合,最终将聚合得到的所有向量通过一个全连接层输出最终的匹配结果。该网络结构参数多,训练速度慢。
本文针对现有的Siamese结构的网络模型问答句交互性较差的问题,提出一种新的基于问题-答案交互的答案句选择模型,该模型首先使用BiLSTM对问答句进行编码,然后利用Feed-Forward注意力机制[17]得到问句的句子向量,同时利用基于问答交互的注意力机制计算候选答案句中每个词与问题词的语义相关性,进而得到候选答案句中每个词的注意力权值,再对每个词进行加权求和得到候选答案句的句子编码。该方法可以捕捉问答句之间隐藏的更多的信息,增强模型的特征抽取能力。最终和词共现特征相结合实现答案句的选择,使模型既易于训练又能提高模型的准确率。
1 基于问答交互的答案选择算法
1.1 模型概述
本文提出一个基于问答句交互的候选答案选择模型来估算问答句的相关性Pr(y|Q,A)。该模型属于Siamese结构的网络。模型主要分为5个部分:词表示层、上下文表示层、注意力层、聚合层和预测层。模型结构图如图1所示。

图1 基于问答交互的候选答案句选择模型结构图
图1中:⊕表示Feed-Forward注意力机制,⊗表示问答句交互的注意力机制。
1)词表示层:使用word2vec[18]或者Glove[19]进行预训练得到每个单词对应的固定矢量,用预训练好的词向量对句子中的每个词进行初始化。问句长度为m,输入[q1,q2,…,qi,…,qm],通过该层得到一个m×d的输出矩阵,其中d为预训练词向量的维度,输出矩阵表示为[Q1,Q2,…,Qi,…,Qm]T;答句输入[a1,a2,…,aj,…,an],输出一个n×d的矩阵[A1,A2,…,Aj,…,An]T。
2)上下文表示层:编码层使用一个共享权重的BiLSTM结构,将上下文信息合并到问答句的每个时间步骤的表示中,并将每个时间步前向输出与后向输出进行级联。如公式(1)~公式(3)所示。
(1)
(2)
(3)
其中,“‖” 表示级联。
3)注意力层:使用注意力机制获取问答句的句子编码,这是本文模型的核心。使用Feed-Forward注意力机制⊕对问句进行编码;使用基于问答句交互的注意力机制⊗对A进行句子编码:将答案A的每个时间步长与问题Q的所有时间步长进行匹配。将在1.2节中详细介绍这2个操作。该层的输出是问句Q和答案句A的句子编码。
4)聚合层:为了能够捕获问答句之间更多的局部信息,本文使用相加、相乘、级联的方式对问答句的句子向量进行拼接。
5)预测层:该层的目的是计算问答句的相关性Pr(y|Q,A)。为此,本文使用2层前馈神经网络作用于聚合层的输出上,并在输出层中应用sigmoid函数,最终输出句子的匹配得分。
1.2 问题与答案联合建模
1.2.1 Feed-Forward注意力层
如何有效地对通过BiLSTM输出的每个时间步的信息进行进一步的提取,一般对于序列数据模型(RNN、GRU[20]、LSTM)使用最大池化或者平均池化[21]来进行提取操作,但是很容易丢失掉重要的信息,最大池化提取的东西很可能不是人们想要的信息,平均池化会弱化想要的信息,故本文使用Feed-Forward注意力机制,对BiLSTM输出的每个时间步的信息进行进一步的提取,从而获得句子向量。Feed-Forward网络结构图如图2所示。

图2 Feed-Forward注意力机制的网络结构图
本文对问句使用Feed-Forward注意机制,基于Feed-Forward注意力机制进行特征提取公式如下:
M=tanh(QW1+b)
(4)
α=softmax(MW2)
(5)
(6)
其中,Q∈Rm×d,W1∈Rd×f,W2∈Rf×1,b∈Rf,b为偏置。W1,W2,b是随机初始化可训练的矩阵。Q通过公式(4)和公式(5)计算出每个时间步的权重系数,采用公式(6)对通过BiLSTM输出每个时间步的向量进行加权求和,最终得到问句的向量表示。
1.2.2 基于问答交互的注意力层
问句与候选答案句之间进行充分的交互,可以获取更多隐藏的特征,可以进一步提高答案选择任务的准确性。所以本文利用注意力机制在词粒度上对问句和候选答案句进行联合建模。具体操作如图3所示,最终输出与问句交互后的候选答案的句子向量。
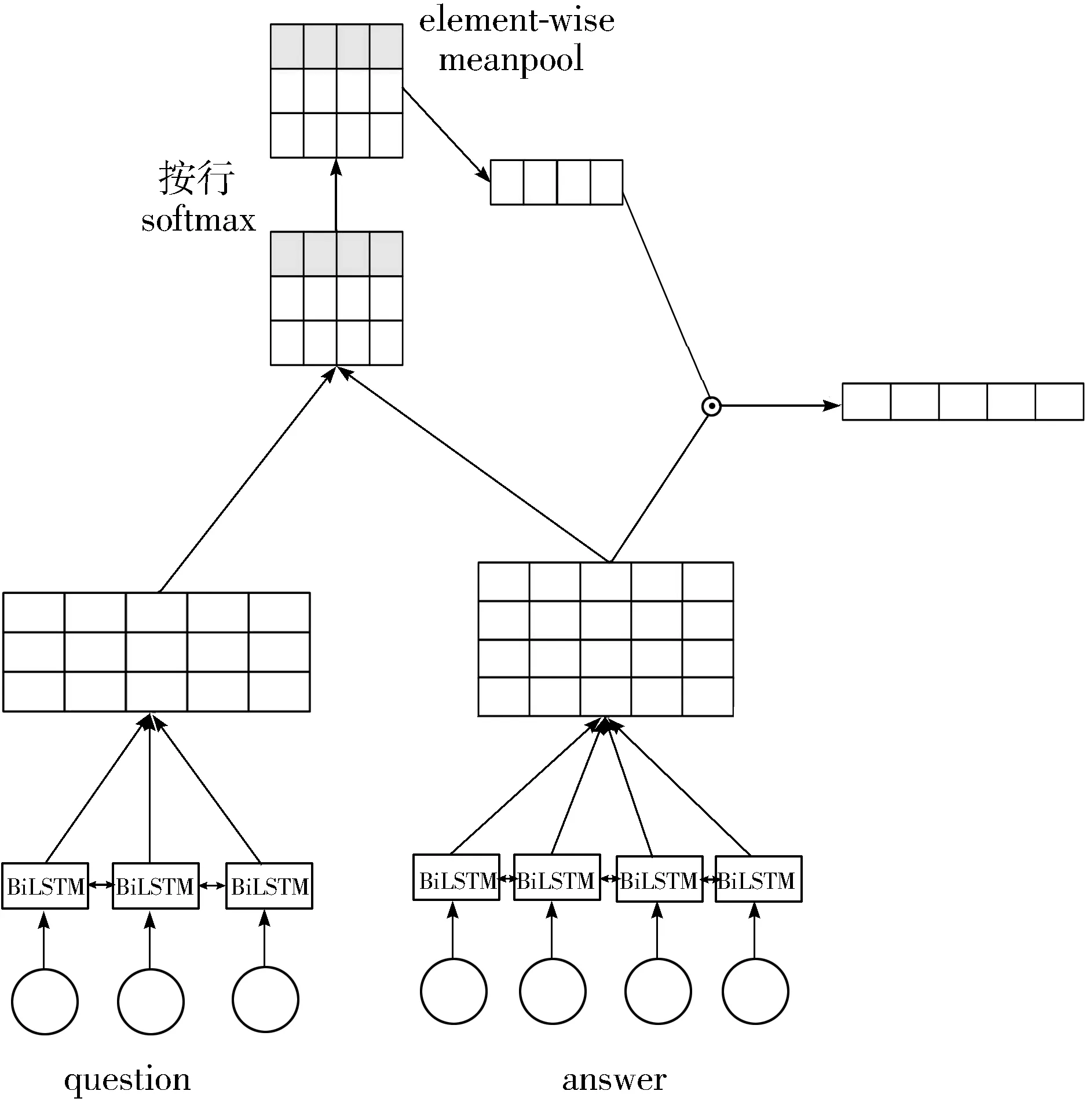
图3 基于问答交互的注意力机制示意图

(7)
通过这种方式,计算得到问题句中的单词与候选答案句中的单词两两组合的一个匹配矩阵M,其中M∈Rm×n,第i行第j列的值由M(i,j)填充,行数为问题Q的长度m,列数为答案A的长度n。
在计算完成匹配矩阵M后,应用逐行softmax函数来获得每行的概率分布,每行看作是候选答案句的注意力系数,可以得到m个候选答案句的注意力系数。
αt=softmax(M(t,1),…,M(t,j),…,M(t,n))t=1,…,m
(8)
α=[α1,…,αi,…,αm]
(9)
在得到m个候选答案句的注意力系数后,对其进行平均,计算出最终的候选答案句的注意力系数,如公式(10)所示。
(10)
为了更充分地利用问题和答案文本之间的互信息,在计算完候选答案句的注意力系数之后,基于注意力向量αfinal和候选答案句在上下文表示层的输出得到与问句交互后的候选答案句的句子向量表示。
(11)
1.3 词共现特征的引入
1.3.1 背景
对于候选答案选择任务,如果只使用词法或句法等浅层特征来进行答案的选择,需要投入大量的人力去设计要进行匹配的特征,存在适用范围较小,识别准确率不高的问题。使用神经网络的方法利用大量的不同领域的数据进行学习,可以减轻人力的消耗,提高识别的准确率。但是如果只是用神经网络的方法,同样也存在一定的问题,如许多专有名词并不在词表当中;目前网络学习到的只是由单词组成的特征,没有引入其他特征例如词性特征、词频特征等,不利于模型效果的进一步提升。本文将浅层特征和神经网络模型进行结合,来提升模型的准确率。
1.3.2 浅层特征的使用现状
目前有人将文档倒数特征[7]、词相似度特征[7]、词匹配特征[22-23]与神经网络模型相结合,来提高模型的准确率。使用频次最高的还是词匹配特征。如张学武[22]预先构建了一个词典,问句和候选答案中的词出现在词典中,在相应的位置设置为1,否则记为0,最终生成2个与词典大小相同的向量,将得到的这2个向量依次通过一个全连接层,得到问题和答案的全局上下文特征表示,并与神经网络相结合共同完成候选答案的选择。熊雪等人[23]为了解决专有名词没有出现在此词表中的问题,构建了一个专用词表,将问题句与答案句中的词与专业词表中的词进行匹配,匹配上了记为1,否则记为0,最终得到2个词匹配向量,两者拼接后经过线性变化训练得到一个一维向量,再与层叠注意力机制提取的特征进行拼接后通过softmax分类器得到最终结果。但是使用词匹配特征需要预先手工构建一个词典,词典构建过大,会导致问答句生成向量过大,占用过多的内存,甚至会造成内存溢出;如果构建的词典过小,会导致能够提取到的特征过少,不利于模型准确率的提高;如果只构建一个专业词汇表,会导致模型的可迁移性变差,更换专业领域后,又需要重新构建专业词典。
1.3.3 词共现特征的引入
为了避免预先构造人工字典带来的一系列问题,本文引入词共现特征。词共现特征无需提前构建人工词典,只去比较当前问答对中出现相同单词的个数。考虑到语气词、助词、连接词等一些高频词几乎在每句话中都会出现,其并没有实际的含义,应该忽略这些词的影响。本文对问答对使用Jieba分词后发现,这些没有什么实际含义的高频词,如“的”、“是”、“这”等词经分词后会与其他实词分开,而一些具有重要含义的词一般都是由2个及以上的字组成,故可以统计问答对中同时出现过的含有2个及以上字的单词个数。
计算词共现特征完成后得到一维的向量,将其和神经网络最终的输出进行级联,在此基础上再构建一个全连接层,输出最终的匹配得分。这样就构建完成了一个融合了词共现特征的答案选择模型。
2 实 验
2.1 数据及预处理
2.1.1 数据集介绍
本文使用的是NLPCC在2016年4月发布的基于开放域文档的数据集,简称为DBQA数据集。该数据集中的正负样本比例接近1∶20。语料格式如图4所示,第一列为问题句,第二列为候选答案句,第三列表示问答句的相关性,如果候选答案句是问题的正确回答,标记为1,否则标记为0。

图4 DBQA数据集中的部分样例
2.1.2 数据集预处理
由于DBQA语料过于不平衡,在训练时需要进行语料的平衡。随机采样主要分为2种——随机欠采样和随机过采样。为了避免丢弃过多的负样本,本文采用对问题中的正例进行16倍过采样、负例进行随机采样的方法[8]使正例和负例的样本数达到均衡。
2.2 评价标准
MRR评价准则:将标准答案在模型给出的排序结果中的位置的倒数作为评价指标,然后对所有的问题取平均。其计算公式如式(12):
(12)

MAP(Mean Average Precision):首先计算出每个问题中标准答案的平均准确率,再对所有问题计算得到的标准答案的平均准确率求平均。MAP的计算公式如式(13):
(13)
其中,AveP表示平均准确率;k表示模型返回的n个预测答案中的排名;m为标准答案的数量;n为预测答案数量;若min(m,n)=0,设置AveP(C,A)为0;P(k)为截止到第k个时的预测精确率;rel(k)表示第k个预测答案是否为正确答案,如果是,记为1,否则记为0。
不同的系统有不同的评价指标,如在文本处理中对候选答案句选择模型的评价指标就不同于问答系统中对候选答案句选择模型的评价指标。为了能更全面地反映出模型的表现,本文还使用了Precision、Recall、F1、acc指标对模型进行衡量。由于DBQA测试集中的数据同样存在正负样本不均衡的现象,直接在测试集上计算这些指标值并不能真正反映模型的效果,本文在已经得到标注结果的测试集上,从每个问题句中抽取一个正例样本和一个负例样本,最终得到了一个包含7570个正负样本的子数据集,在该数据集上进行Precision、Recall、F1、acc指标的测试。
2.3 实验设置
使用训练不好的词向量给下游任务提供语言表示,下游任务的表现会变差,所以应该选择与自然语言任务同领域的语料,本实验使用DBQA提供的训练集、开发集和测试集中的语料利用Gensim工具预训练一个100维的word2vec单词向量,用来初始化单词表示层中的单词嵌入;在训练时剔除了出现频次小于5次的单词;将BiLSTM层的隐藏大小设置为200;将Dropout应用于上下文表示层,并将丢失率设置为0.5;Feed-Forward注意力机制中隐藏层的大小设置为128;由于模型只有一个输出,使用二分类交叉熵作为损失函数;在训练过程中使用ADAM优化算法[24]更新参数,将学习率设置为0.0001;在训练期间,不更新预先训练的词嵌入。主要参数设置如表1所示。

表1 模型关键参数的设置
2.4 消融实验
为了论证聚合层对问答句向量操作的有效性,每次消除一个聚合策略,最终构建3个消融模型(没有按位加、没有按位乘、没有级联)。表2显示了模型在测试集上的性能。通过表2可以看到,消除任何聚合策略都会损害性能,说明本文的设置是合理的。
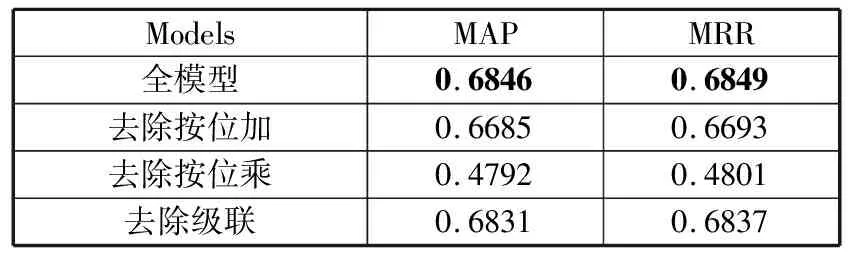
表2 模型在测试集上的消融实验
2.5 实验结果与分析
在本节中,将本文的模型与候选答案任务其他模型进行比较,在DBQA数据集上进行实验。为了有效地验证模型的有效性,构造了几个基准模型,用于进行对比试验。
首先,本文构造了2个Siamese结构的基准模型:BiLSTM-MeanPooling和BiLSTM-MaxPooling。这2个模型除了与本文模型的注意力层不同外,其他部分完全相同。BiLSTM-MeanPooling对问答句通过上下文表示层的输出分别使用MeanPooling来得到这2个句子的编码;而BiLSTM-MaxPooling模型则是使用MaxPooling得到问答句的句子向量。为了验证Feed-Forward注意力机制的优越性,本文构造了问答句均使用Feed-Forward注意力机制的模型:对问答句通过上下文表示层的输出分别使用Feed-Forward注意力机制来得到问答句的句子向量,其他部分与上述2个模型完全相同。上述3个模型问答句之间没有进行交互,独立编码。其次,本文复现了Tan等人[9]和余本功等人[10]构建的模型,他们的模型同样属于Siamese结构的模型,问答句之间进行了一定程度的信息交互,将其与本文的模型进行对比。这2个模型具体实现已在引言中进行了详细的介绍。
表3显示了所有基准模型和本文模型的性能。通过表3可以得出,BiLSTM-MeanPooling模型在各个指标上均优于BiLSTM-MaxPooling模型,表明平均池化对特征提取的效果要优于最大池化的提取效果。将BiLSTM-Feed-Forward模型与BiLSTM-MeanPooling模型进行对比发现:除了Precision指标之外前者在各项指标上要优于后者,反映了Feed-Forward注意力机制能够关注到句子中较为重要的词,给其分配较大的注意力权值,对句子特征的提取优于平均池化的方法,故本文对问句特征抽取使用的Feed-Forward方法是行之有效的。本文模型与前3个没有问答交互的模型相比较,效果有了进一步的提升,可以反映出本文使用的基于问答交互的方法有助于模型效果进一步的提升;与后3个有问答交互的模型进行对比发现,本文的方法对答案句选择的效果带来了较大的提升,本文方法能够更好地捕捉问题句与候选答案句之间的语义关系,该模型是有效的。为了使模型效果能够更趋理想,本文构建的模型在此基础上添加了词共现特征,融合了词共现特征的模型,在MAP、MRR和Recall这3个指标上有了1~2个百分点的提升,可以反映出词共现特征能够有效地提升问题和正确答案的相关性得分,进而提高了模型的召回率以及能够更加有效地筛选出正确答案,说明引入词共现特征在一定程度上也是有助于答案选择任务效果提升的。在引入词共现特征后,发现模型的Precision、F1、acc指标有轻微的下降,这是因为词共现特征不仅可以提升正确答案句的得分,也能提高部分非正确句子的相关性得分。当非答案句中含有过多的问句中的词语时,该答案句可能会被误判成正确答案。

表3 在DBQA测试集上模型的表现
3 结束语
本文使用Feed-Forward注意力机制计算出问句的句子编码,使用基于问答交互的注意力机制计算出候选答案句的句子编码,将2个句子编码通过不同的方式进行聚合,最后通过一个全连接层输出最终的匹配得分。通过实验表明,该方法能够有效地提升答案选择任务的效果。本文还充分考虑了句子的浅层特征,将问答句的词共现特征与神经网络模型进行融合,通过实验表明,使用引入词共现特征的答案选择模型有助于任务更好地被完成。在未来的工作中,可以尝试使用ELMO[25]或BERT[26]对句子中的单词进行更加精确的向量表示;尝试引入更多的浅层特征,例如句子长度特征、句法结构信息等,从而更进一步提升模型效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
