
一种基于桥梁横向裂缝的病害识别方法
2021-01-27 03:41马东群李宝林王秋月何先波
计算机与现代化 2021年1期
马东群,李宝林,王秋月,何先波
(西华师范大学计算机学院,四川 南充 637000)
0 引 言
关于桥梁病害自动识别的研究很多,但根据真实数据集并切实推广应用的相对较少。其中寇潇等人[1-5]采用正圆可调粗细小圆圈红外线激光模组、激光测距仪、单反相机等拍摄搜集了不同桥梁、不同位置、不同时间下的144张照片数据,通过Photoshop以及编程工具的处理后,作为数据集使用;李良福等人[6-8]使用基于人工扩增的数据及预处理的方法,将2000张桥梁裂缝图像归一化为1024×1024分辨率的桥梁裂缝图像,经滑动窗口算法,用W×H固定大小的窗口不重叠进行滑动,将窗口覆盖下的小切片作为一个ROI感兴趣区域,再把拥有桥梁裂缝的切片归纳为桥梁裂缝面元,不拥有桥梁裂缝的切片归纳为桥梁背景面元,集成为拥有7000张桥梁裂缝面元的数据集以及48000张桥梁背景面元的数据集,用这2个数据集作为桥梁裂缝训练、比对、测试的数据集;刘洪公等人[9-11]通过Raspberry Pi处理器采集图像,通过3G无线网络传输图像数据,利用服务器运用图像处理技术对釆集到的图像进行分析处理,最后使用卷积神经网络技术(CNN)对裂缝进行分类识别。
而本文所采用的数据来源,是一款公路桥梁专业定检系统下所收集的真实桥梁病害数据,在数据上具有真实性和可靠性等特点。该系统集合了不同地区、不同桥梁类型、不同环境以及不同病害位置的诸多桥梁并且进行了较好的推广应用。目前系统共有数万座桥,总共百万余条病害,其中裂缝病害数十万条,本文将在这些数据的基础上进行相关数据的研究和分析。
1 桥梁横向裂缝病害图片来源与预处理
1.1 横向裂缝病害图片来源
桥梁横向裂缝病害数据来源于一款公路桥梁定期检测系统,首先需要对该系统进行数据库建模,关联并批量提取出桥梁横向裂缝图片数据。对数据库建模和关联的详细过程是先建立桥梁裂缝数据关系模式BDPS(BF,DF,PF,SF,HJ),其中BF表示桥梁基本信息集,DF表示桥梁病害信息集,PF表示桥梁病害图片信息集,SF表示桥梁病害标度信息集,HJ表示环境。且不同的地域、不同的气候条件、不同的外界情况导致病害也不一样。本文结合病害类型及病害类型所对应的标度信息自动识别所拍摄的病害图片。根据上文描述,特此给出如下定义:
定义1桥梁基本信息集BF。该信息集包含桥梁编号Bno、桥梁名称、桥梁类型、桥梁材质、桥梁结构、部件名称、构件名称和桥梁受力形式。用公式(1)表示:
BF=bridgeInfo(Bno,Bname,type,material,struc,comp,member,weight)
(1)
定义2桥梁病害信息集DF。该信息集包含病害编号Dno、病害标度编号Sno、病害名称、病害描述。用公式(2)表示:
DF=diseaseInfo(Dno,Sno,Dname,describe)
(2)
定义3桥梁病害示意图信息集PF。该信息集包含病害图片编号Pno、病害图片名称Pname、病害图片标题等信息。用公式(3)表示:
PF=pictureInfo(Pno,Pname,title,category,url,Dno)
(3)
定义4桥梁病害标度信息集SF,该信息集包含病害标度编号Sno、病害编号Dno、当前病害标度、病害定性描述和病害定量描述。用公式(4)表示:
SF=scaleInfo(Sno,Dno,curscale,qulitative,quantify)
(4)
定义5裂缝病害指标描述模型DD。病害所涉及的指标非常庞杂,不同的病害所涉及的指标不一样,本文主要从桥梁裂缝病害入手,一般来说,桥梁裂缝病害主要的标度有宽度、长度、深度,及构建病害总面积和最大单出面积,可用公式(5)表示:
DD=diseaseDescription(width,longth,depth,totalArea,maxArea)
(5)
根据上述定义,本文将对上述数据进行关联、抽取、优化并随机提取出该系统对应的病害位置、标度信息和1000张横向裂缝作为训练数据集。
1.2 图片预处理与数据集的建立
由于系统中提取的病害图片是由不同的设备进行采集,所以分辨率有所区别,因此将图像像素作为输入提供给神经网络之前,先将图像进行归一化处理,分别处理成分辨率为75 px、150 px和300 px。TensorFlow[12]分别提供了双线性插值法、最近邻居法、双三次插值法和面积插值法对图像进行归一化处理,其效果如图1所示。
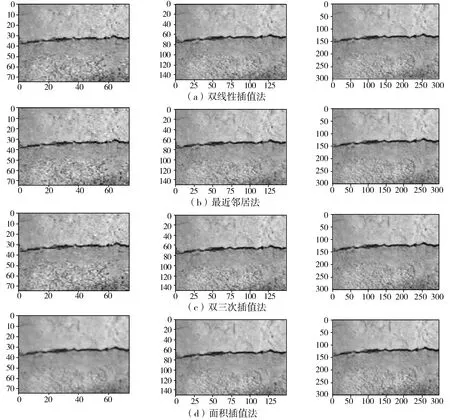
图1 分辨率为75 px、150 px、300 px的4种插值算法预处理
完成1000张横向裂缝图片的预处理后,接下来进行数据集的建立,TensorFlow提供了TFRecord标准接口读入文件,制作数据集。TFRecord是一种将数据集内容及标签放在一起的二进制文件,能更好地利用内存。本文制作数据集的流程如图2所示。
在图2中,先将预处理后的横向裂缝图片存储到文件夹hxlf中,然后将hxlf文件夹中的原始横向裂缝图片制作成TFRecord二进制文件,在TFRecord二进制文件夹中将横向裂缝图片的名称统一命名为index_samples_label格式,其中index表示图片的索引,samples表示分隔符,label表示图片的标签。最后为了验证TFRecord二进制文件的准确性,对数据集部分图片进行展示,展示的结果如图3所示。

图2 数据集的制作流程

图3 数据集的建立及验证
2 CNN模型的建立与训练
2.1 CNN模型的建立
CNN模型[13]的构建过程可以描述为:输入层→[[卷积层]×M→池化层?]×N→[全连接层]×T,也就是M个卷积层叠加,然后叠加一个池化层,重复这个结构N次,最后叠加T个全连接层。本文建立的CNN模型是由2层卷积、2层池化、2层全连接层和1个分类器组成的卷积模型,模型架构如图4所示。
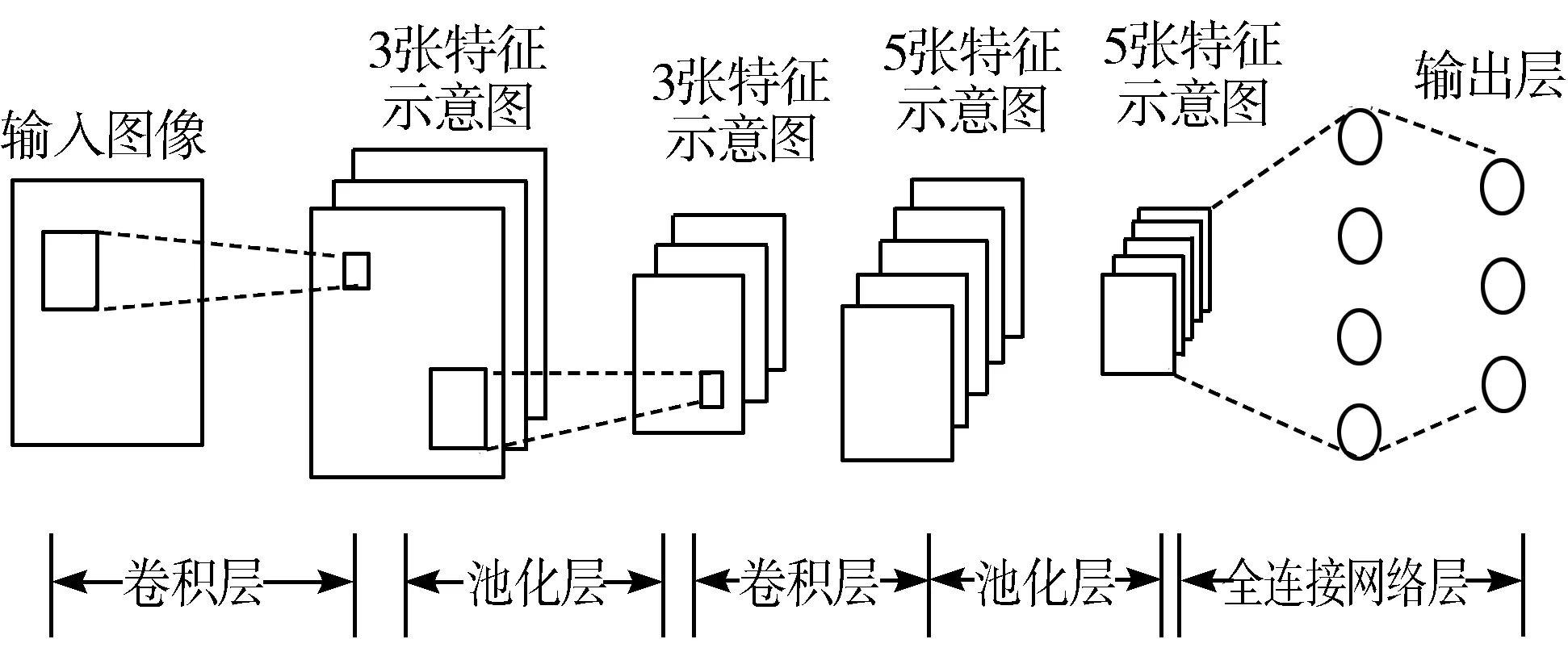
图4 CNN的模型架构图
在图4中2层卷积加池化层进行图片的特征提取,全连接层进行图片的特征分析和识别,最后用softmax激活函数分类输出识别结果。该模型的卷积算法如公式(6)所示。
(6)
式中,xm,n表示训练图像第m行第n列像素;wi,j表示CNN卷积层中卷积核第i行第j列权重,b表示CNN卷积层中卷积核的偏置;ym,n表示特征图第m行第n列输出值;g表示激活函数。
2.2 CNN模型的训练
CNN具有很强的学习能力和泛化能力[13-20],它的训练方式是找到训练数据集真实值与目标函数之间的映射关系,该映射关系主要是通过CNN模型的训练来实现,其训练的主要工作是更新模型的权值和偏置,具体训练流程如图5所示。
在图5中,CNN模型的训练分为2个过程,第一个过程是将1000张横向裂缝数据集按照4∶1的比例分为训练数据集和测试数据集,把训练数据集作为输入样本,输入到CNN中进行训练。训练过程中首先通过正向传播算法得到目标样本的预测值,然后计算目标样本真实值与预测值之间的差值,该差值被称为误差(也叫损失),用公式(7)表示。接下来对误差进行评估,若满足要求则直接通过全连接层进行分类输出,若不满足要求则进入第二个过程反向传播过程,反向传播算法主要是做模型参数的更新,也就是对权值和偏置进行更新,通过更新权值和偏置的方法来减小误差值,如公式(8)所示,而更新模型参数最常用的算法是随机梯度下降算法(Stochastic Gradient Descent, SGD),如公式(9)所示。
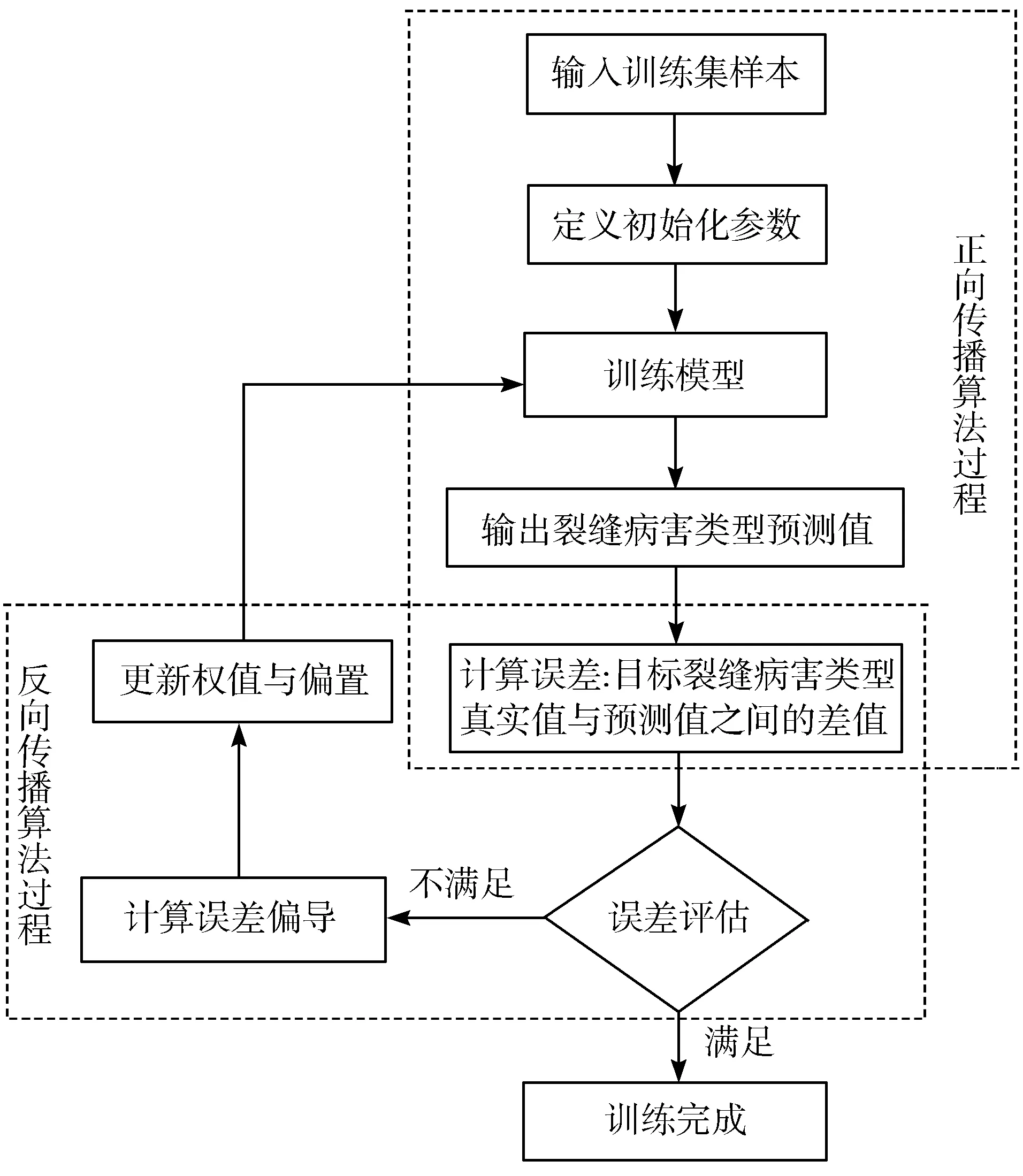
图5 CNN模型训练流程图
(7)
(8)
x(i+1)=x(i)-μL(w)
(9)

(10)
(11)
训练过程中全连接层权值、偏置每一步的变化如图6~图8所示。

图6 300 px全连接层权重和偏置变化

图7 150 px全连接层权重和偏置变化
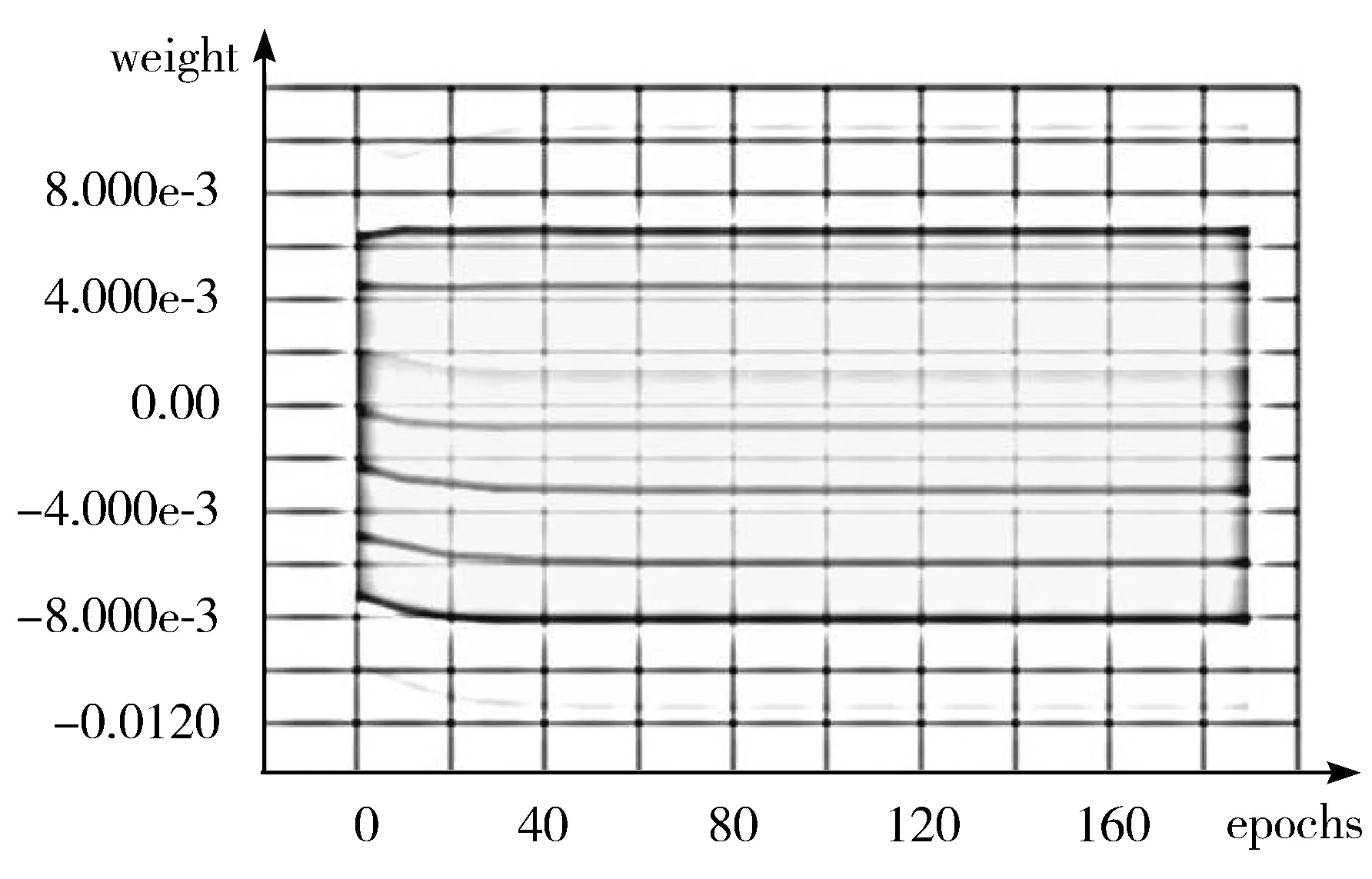
图8 75 px全连接层权重和偏置变化
2.3 训练结果分析
为了获取训练的效果,按照相同的迭代轮数(epochs)和输入图片的batch数量分别对分辨率为75 px、150 px和300 px的横向裂缝图片进行训练,得出在不同分辨率情况下横向裂缝病害的训练精度、收敛性和效率如图9~图11所示。

图9 收敛性
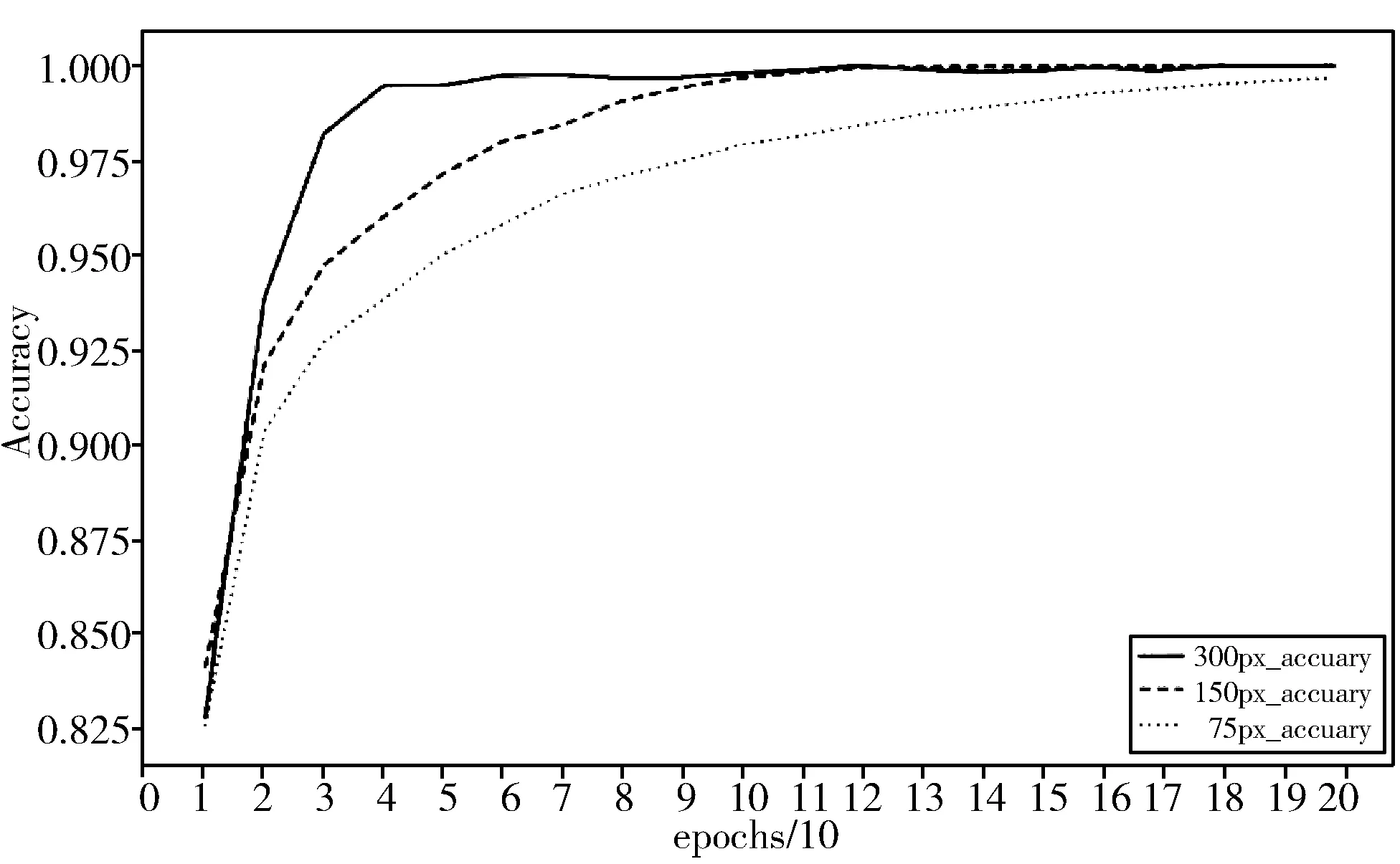
图10 训练精度

图11 训练效率
在图9~图11中,迭代轮数为200,黑色实线表示分辨率为300 px训练的结果,黑色虚线表示分辨率为150 px训练的结果,黑色小圆点表示分辨率为75 px训练的结果。通过对3种不同分辨率的横向裂缝图片训练,可得到以下实验结论:
1)分辨率为300 px的预测精度率先接近1。如图10,分辨率为300 px的横向裂缝图片在训练轮数为30时,预测精度就接近1,并保持稳定;分辨率为150 px的横向裂缝图片在轮数为90时训练精度接近1并保持稳定;分辨率为75 px的横向裂缝图片在轮数为200时训练精度才趋近于1。
2)分辨率为300 px的收敛速度比分辨率为75 px和150 px的更快,如图9所示,分辨率为300 px的横向裂缝图片在迭代轮数为80时基本达到收敛,分辨率为150 px的横向裂缝图片在迭代轮数为130时达到收敛,分辨率为75 px的横向裂缝图片在迭代轮数为200时达到收敛,分辨率为300 px的收敛速度比分辨率为150 px和75 px的分别快出38.46%和60%。
3)如图11所示,时间效率上分辨率为75 px的最快,每迭代10轮大概用时40 s;其次是分辨率为150 px,每迭代10轮大概用时100 s;分辨率为300 px的横向裂缝图片用时最长,每迭代10轮大概用时1200 s。
3 测试结果分析
本文对3种分辨率的横向裂缝图片训练结果做测试分析,如表1~表3所示,前3张横向裂缝图片是经过预处理的测试集图片,后2张是实际环境中拍摄的横向裂缝图片。

表1 分辨率为300 px的横向裂缝病害图片识别结果

表2 分辨率为150 px的横向裂缝病害图片识别结果

表3 分辨率为75 px的横向裂缝病害图片识别结果
从表1~表3可以得出如下测试结论:
1)对于测试集中的横向裂缝图片,分辨率为300 px的识别效果最好,但识别时间最长;分辨率为75 px和150 px的次之。
2)对于实际环境中拍摄的横向裂缝图片,分辨率为300 px的识别效果最好;分辨率为150 px的次之,而分辨率为75 px的横向裂缝图片能正确识别,但识别的准确率较低。识别时间上像素越低的用时越短,像素越大的用时越长,但单张图片识别时间相差并不太大。
因此,在具体的工程项目中,需结合实际情况,选用识别效果最好的模型作为工程应用中使用的模型。
4 实验结果对比
刘洪公等人[9]提出了一种基于CNN的图形图像识别算法,该模型是一种基于LeNet卷积神经网络的深度学习模型,本文采取该算法对相应的数据集进行模拟仿真对比,在数据、参数和运行环境一致的情况下其收敛性和训练精度对比结果如图12和图13所示。

图12 2种模型收敛性比对

图13 2种模型训练精度比对
在图12和图13中,黑色实线表示本文模型训练的结果,黑色虚线表示刘洪公等人提出的算法模型训练的结果。通过2种不同模型间的性能比较,可得到以下实验结论:
1)本文的预测精度高于刘洪公等人提出模型的训练精度。如图13,本文在训练轮数为120时,预测精度在99%以上,并且保持稳定;而刘洪公等人提出模型的训练精度在轮数为200时,预测精度才达到96%左右,本文的预测精度比刘洪公等人提出的模型预测精度高出约4个百分点。
2)本文的收敛速度比刘洪公等人提出的模型收敛速度快,如图12所示,本文在迭代轮数为120时达到收敛,而刘洪公等人提出的模型收敛速度在迭代轮数为200时还未达到收敛。
5 结束语
本文主要对桥梁横向裂缝病害数据进行了分析与识别,建立了相应的数据模型,并根据病害图片特征详细地描述了针对具体病害图片如何进行目标检测和病害的自动标识过程和方法。在具体的工程中,该方法得到了相应的应用,并且取得了良好的效果,大大减轻了检测人员的工作量。本文在实验上比较单一,下一步将进行拓展,做更深入的研究,将所有种类的裂缝病害都用来做深度学习,学习所有裂缝病害的特征,实现所有裂缝病害的自动识别,再结合《公路桥梁技术状况评定标准》(JTG/T H21-2011)[21]对桥梁裂缝病害做定位、定因和定性判断,然后结合现有的公路桥梁定检系统对桥梁进行专业技术评定和自动生成评定报告并给出相应的维护建议。
猜你喜欢
今日农业(2022年3期)2022-06-05
今日农业(2021年8期)2021-11-28
北京航空航天大学学报(2021年9期)2021-11-02
烟台果树(2021年2期)2021-07-21
今日农业(2020年19期)2020-11-06
数学物理学报(2019年3期)2019-07-23
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年9期)2018-11-02
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年5期)2017-05-14
