
基于图像序列的运动目标检测识别关键技术研究
2021-01-19 12:56于莲芝胡婵娟
计量学报 2020年12期
薛 震, 于莲芝, 胡婵娟
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
随着计算机技术、算法理论以及硬件的不断完善升级,对视频图像的运动目标检测与识别的研究也在不断深入。运动目标检测与识别是指对输入的图像序列进行图像处理、目标检测、特征提取和目标识别[1]。其中目标检测是从图像序列中检测出运动物体的位置,而目标分类识别是指判断提取出的目标属于哪种类别。
运动目标检测的常用方法包括帧间差分法、背景减除法、光流法等。帧间差分法是基于运动目标在视频中可以直观地体现动态变化的这一前提下,通过对比图像序列中相邻或相近帧的相对变化来进行的一种检测方法[2]。该方法的主要优点是算法实现较为简单,运算量较小,光线因素影响较小;缺点是易受到干扰,且目标检测的有效性难以保证,只在目标运动速度较快的情况下具有比较好的鲁棒性。背景减除法则先通过训练图像帧得到模型参数,建立背景模型,将每一幅待处理的图像与当前背景进行比较来检测目标的运动,然后根据场景的变化对模型参数进行更新;背景减除法在低速状态下的检测效果明显,但在目标移动速度较快的场合检测效果会大大降低。光流法则避免了提前了解场景信息,它既可以应用于背景运动的情况,也适用于背景不动的场合;但其条件苛刻,不仅对光照和噪声比较敏感,而且计算复杂度高,难以满足实时性的要求。光流法由于其条件的苛刻不予考虑,但帧间差法和背景减除法各有其长处以及局限性。
本文综合帧间差分法在高速运动目标的良好鲁棒性以及背景减除法在低速运动目标的准确性来考虑,将两者同时应用于目标检测中,并对检测结果进行实时比较,选取相对较优的结果。通过运动目标检测提取出图像序列中的运动目标的掩膜,然后将提取到的运动目标区域进行分类识别,提取HOG特征送入SVM分类器完成分类任务,最终得到实验结果。
2 帧间差分法原理及改进
帧间差分法是基于运动目标在视频中可以直观的体现动态变化的这一前提下,通过对比图像序列中相邻或相近帧的相对变化来进行的一种检测方法[3]。该方法用当前帧与相邻帧对应像素点的差值,通过设定的阈值T来判断运动区域。基本原理由式(1)体现:
(1)
式中:D(x,y)表示二值化后的差分图像,差分图像D(x,y)取值为1的像素点被认为是运动目标的像素点;fk(x,y),fk+1(x,y)分别为第k帧、第k+1帧坐标为(x,y)像素点的像素值;T为阈值。帧间差法示意图如图1。

图1 帧差法示意图Fig.1 Frame difference method
其中阈值的选择十分重要。阈值过小,则不能有效抑制图像中的噪声;阈值过大,又可能会抑制有效的运动区域。针对这一问题的解决方法有全局固定阈值、全局自适应阈值和局部自适应阈值。
2.1 全局固定阈值
全局固定阈值是在整个差分图像的二值化过程中采用事先预定好的阈值[4]。优点在于运算简单、速度快,但在抑制噪声和鲁棒性上较差。通过实验采用不同阈值对同一幅灰度图像进行二值化分割,结果见图2所示。

图2 不同固定阈值分割结果Fig.2 Different fixed threshold segmentation results
2.2 全局自适应阈值
当场景中的环境变化时,手动选取的固定阈值往往不能达到很好的分割效果,通过自适应全局阈值算法可以改善对变化环境场合的效果。本文主要研究最大类间方差法(Otsu)[5]。
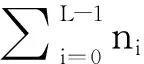
C0的概率ω0为:
(2)
C1的概率ω1为:
(3)
C0的平均值用u0表示:
(4)
C1的平均值用u1表示:
(5)
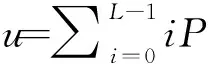
所以,全部采样的灰度平均值为:
u=ω0u0+ω1u1
(6)
则两组间的方差为:
δ2(T)=ω0(u0-u)2+ω1(u1-u)2
(7)
δ2(0)=ω0ω1(u1-u0)2
(8)
从0~(L-1)遍历T,当δ2(T)最大时即为所求的阈值T。图3为用此方法对某一灰度图像进行仿真的实验结果。从直方图4能够直观地看出Otsu阈值为146[6]。

图3 Otsu二值化Fig.3 Otsu binarization
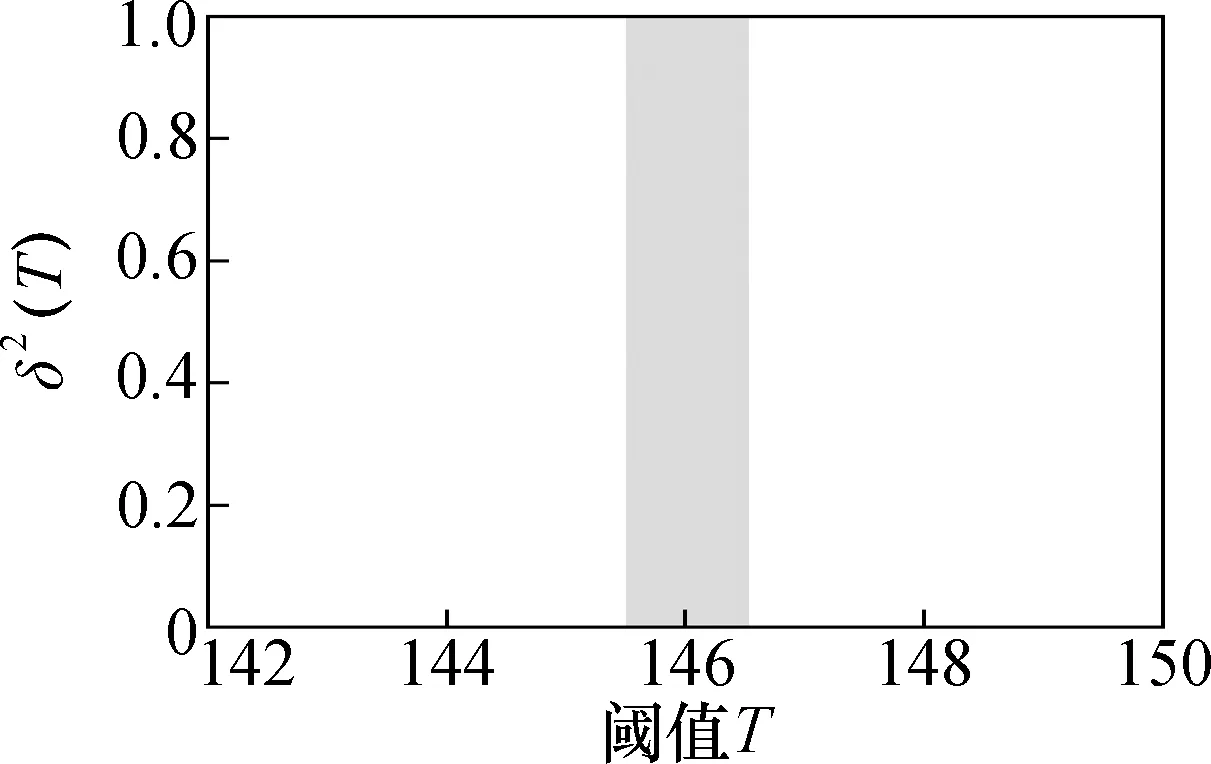
图4 Otsu阈值选取Fig.4 Otsu threshold selection
2.3 实验测试分析
本文用3种方法分别针对车辆和行人进行检测来验证其有效性。从图5可以看出:固定阈值的平均FPS在80左右,全局自适应阈值平均FPS为70左右,局部自适应阈值在60左右,检测速度相差不多。但从效果来说,行人移动速度较慢,目标内部变化不够明显,所以检测结果产生了空洞现象。而针对速度较快的车辆来说,局部自适应阈值更注重在边界的分割上,对于慢速行人和快速车辆的检测效果均不理想,且FPS相对较低;固定阈值由于实际检测过程中运动目标的运动会使得其最优阈值产生漂移,从而使得检测结果的准确率变得较低,所以也不适合检测。因此,Otsu法的帧差法比较适合运动目标检测。
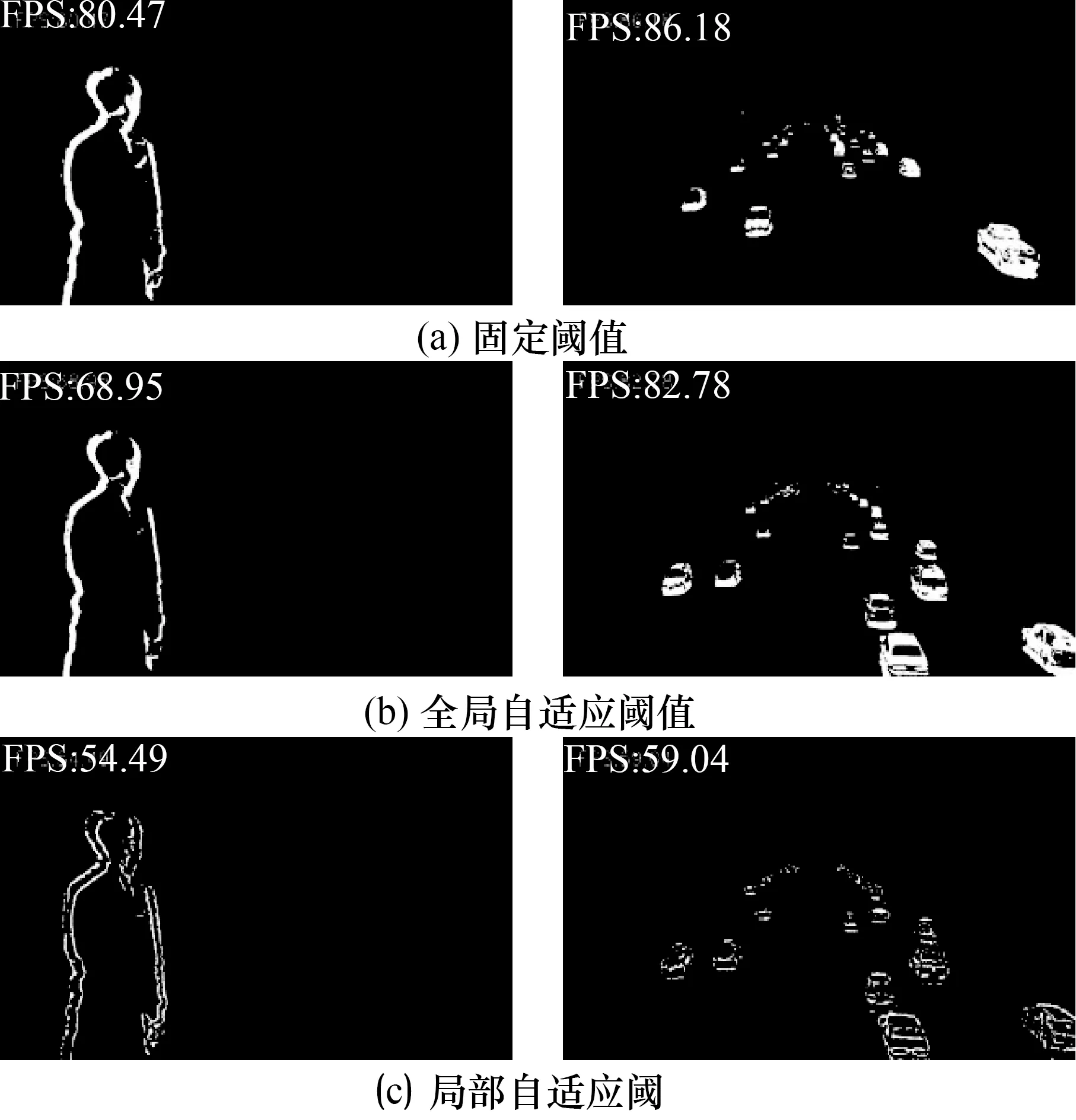
图5 3种方法的检测结果Fig.5 The detection results of three methods
3 背景减除法原理及改进
背景减除法是通过预先建立背景模型,利用图像帧的训练获得模型的参数,再将每一幅待处理图像与当前背景模型进行比较来检测目标的运动[7],并根据场景的变化动态对模型参数进行更新。背景减除法对背景的更新速度具有严格的要求:更新速度较慢会使背景减除法对场景变化的适应能力较弱,当场景发生变化时因背景更新的不及时而产生较多的虚假目标;更新速度较快虽然能够较快地适应场景的变化,但同时也加大了将运动目标更新为背景的概率,尤其是当运动目标变化较小时,容易发生漏检的现象。背景减除法的流程图如图6所示。
本文基于混合高斯模型和码本模型的背景减除法进行实验分析,以寻找最适合的方法进行目标检测。
3.1 混合高斯模型
混合高斯模型(Gaussian mixture model,GMM)[8]是指根据每个像素在时域上的分布情况用多个高斯模型构建各个像素的颜色分布模型,从而有效的描述图像直方图存在多峰的情况,改善单高斯模型在快速运动场景无法准确描述背景的缺陷。
在混合高斯模型中,对图像的每个像素点进行多个权值不同高斯分布的叠加建模,每种高斯分布对应于一个像素点可能呈现颜色的状态、权值和参数随时间推进而更新。在处理彩色图像时,假设图像像素点RGB三通道相互独立且方差相同,对于观测集(X1,X2,…,Xb),Xb为b时刻的像素样本,该样本服从混合高斯分布概率密度函数:
(9)
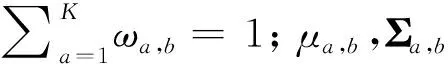
(10)
(11)
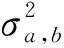
混合高斯模型虽然能解决单高斯模型的问题,但是也有如下缺点:通过少量的高斯模型来对快速变化的背景建模并不容易;学习速率太低,GMM模型会很宽泛,在模型突然改变时会很困难;学习速率过高,背景适应过快,缓慢移动前景又会被整合到背景模型中,最终导致较高的错误率。
3.2 码本模型
码本模型(codebook)背景减除法试图在不进行参数估计的情况下进行长时间采样,通过多个码元(code_element)对背景进行建模[9],该算法特点有:
(1)自适应紧凑的背景模型,能长时间获取结构化背景运动,对运动或多重变化的背景进行编码。
(2)具有处理全局或局部光照变化的能力。
(3)训练过程没有制约,运动全景可在最开始的地方。
(4)通过分层建模来表示不同的背景层次。
码本采用量化、聚类的技术,从视频开始的多帧图片中建立背景模型,为当前背景的每个像素建立codebook(CB)结构,每个codebook结构又由多个code_element(CE)组成,CB和CE形式为:
CB={CE1,CE2,…,CEr,T}
(12)
CE={LH,LL,Xmax,Xmin,tlast,tstale}
(13)
式中:r为一个CB中所包含的CE的数目,当r比较小时,能够表示简单背景,当r较大时可以对复杂背景进行建模;T为CB更新的次数;CE是1个6元组,其中LH,LL作为更新时的学习上下界,Xmax和Xmin记录当前像素的最大值,tlast是上次更新的时间,tstale是陈旧时间(记录该CE多久未被访问),用来删除很少使用的code_element。
采用CB算法检测运动目标的流程为:
(1)在视频开始选择一帧或多帧使用更新算法建立CB背景模型;
(2)通过CB模型检测前景;
(3)间隔一定时间使用更新模型,以适应场景的变化;
(4)若检测结束,转步骤(2),否则结束。
3.3 实验测试分析
为了验证上述算法的有效性,本文对行人和车辆进行实验对比,图7是2种模型下的背景减除法在不同的帧数下的检测结果。由图可以看出:无论是混合高斯模型还是码本模型,在行人检测上的效果均较好,没有出现空洞;但是在移动速度较快的车辆检测上都出现了相同的问题,不能迅速地检测出移动目标,体现出背景减除法在对于高速目标检测上的局限性。通过2种模式检测结果的观察,本文选择相对而言效果更好的基于码本模型的背景减除法来检测低速物体。

图7 混合高斯模型和码本模型检测结果Fig.7 GMM and codebook model test results
4 本文改进运动目标检测方法
针对上述实验得出结论:在运动目标移速较慢的场合,背景减除法发挥较好;在目标移动较快的场合,帧间差分法相对较好。因此本文融合2种算法,并做出如下改进:基于全局自适应阈值帧间差分法和基于码本模型的背景减除法,同时对同一运动目标进行检测,通过2种方法相或得出最终结果。运动目标较大时帧间差分法起主要作用,较小时背景减除法起主要作用[10]。算法的流程图见图8。
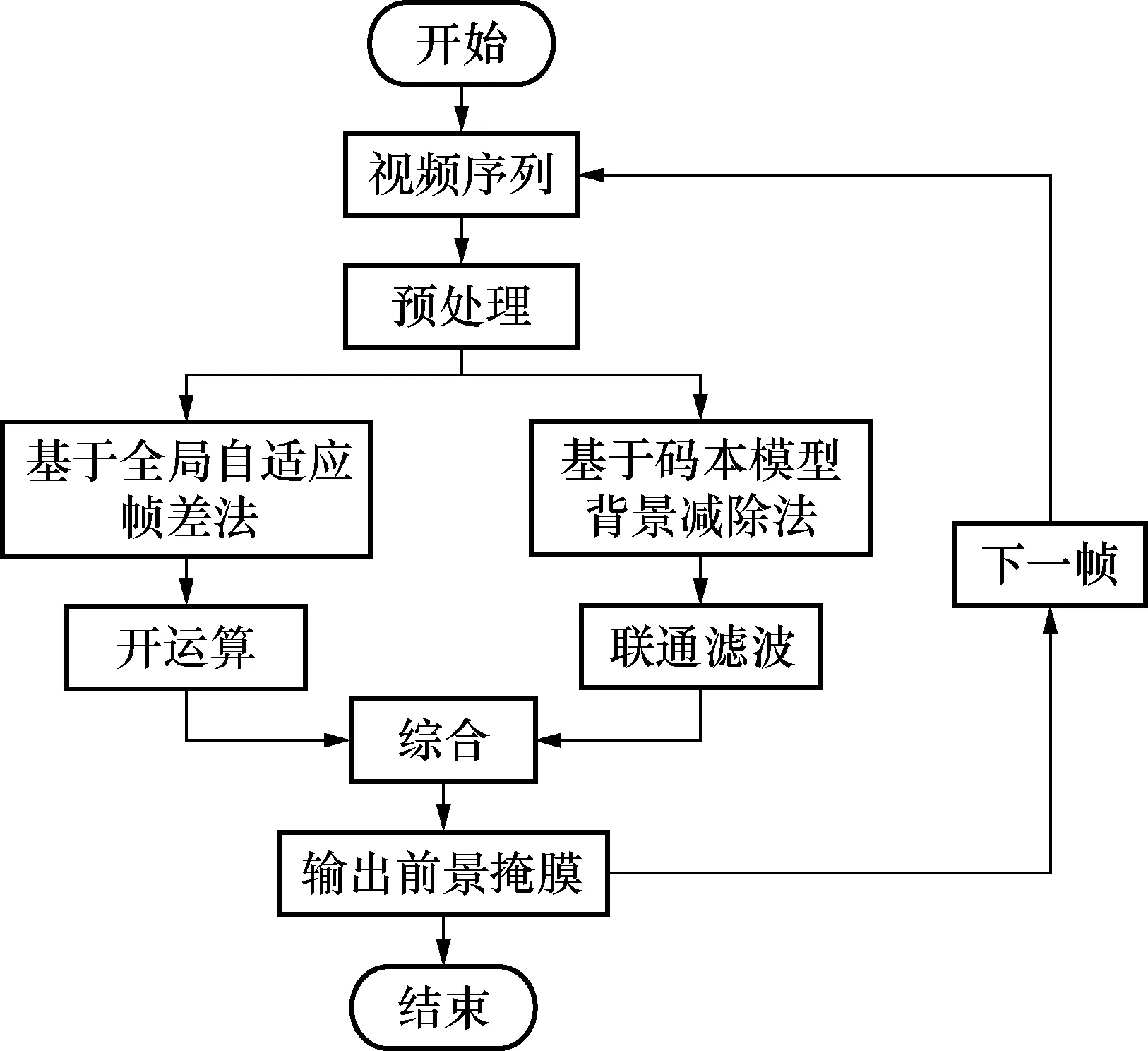
图8 本文改进运动目标检测流程图Fig.8 The improved flow chart of moving target detection
通过本文方法分别对车辆和行人进行检测,图9为检测结果。由图9分析可得出:目标在2种运动状态中均能取得较好的检测结果,行人检测和车辆检测的FPS稳定在30左右,且都没有出现空洞现象。证明了本文提出方法的有效性,该方法为目标识别的准确率提升带来了积极的作用。

图9 本文方法检测结果Fig.9 Test results of the proposed method
5 目标识别方法
通过对运动目标的检测提取到了运动目标的掩膜[11],然后对掩膜进行外界矩形分析,得到包围运动目标的矩形框;再将矩形框内的图片截取出来,并调整图片的大小,提取出图片的特征;通过训练好的SVM分类器对检测目标进行分类。识别系统框图见图10。
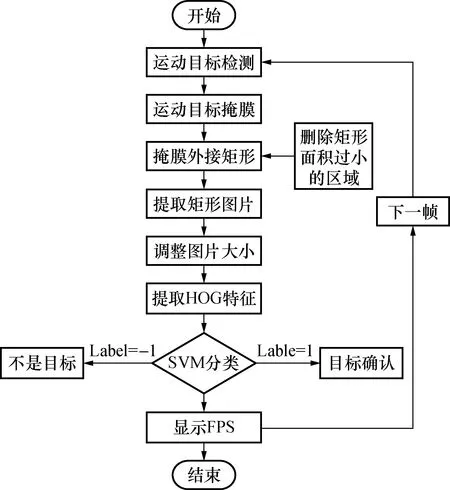
图10 本文目标识别方法Fig.10 Target recognition of the proposed method
5.1 分类方法
本文通过运动目标检测提取出运动目标的掩膜,用矩形框架选取目标,提取特征后送进SVM分类器进行识别[12~14]。相对于传统的多尺度滑动窗口检索,该方法在实时性上具有显著提高。在提取特征的部分上,本文拟采用HOG特征,但是HOG特征具有维度大的特点,对目标检测的实时性有加大的影响[13]。所以本文在HOG特征的基础上,通过线性插值对每个cell中的梯度方向进行投票,并用多种尺度的block调整HOG结构,最后对生成的block进行特征挑选,最终组成多尺度的block。
5.2 自举法
用训练好的分类器进行实验在识别出车辆的同时也会造成很多的误检,将收集的负样本原图送SVM分类器[15]识别,会在多张图片上出现难例,如图11所示。

图11 负样本误检图Fig.11 Negative sample misdiagnosis
为减少难例的数量,可通过自举法解决相似问题:将检测为难例中的矩形框内容截取出来放入到初始的负样本集合中,再重新进行SVM分类器的训练。经试验验证,此类方法可有效减少误报。
6 仿真实验及结果
为验证本文算法的有效性,借助OpenCV计算机视觉库[16],实现车辆的未分类目标识别,并与传统的HOG+SVM多尺度检测算法就实时性和准确率进行对比。本次实验的硬件为CPU Core(TM)i7 6700HQ,显卡GTX1050Ti,8G内存。软件平台则是使用Visual Studio 2013开发环境以及开源计算机视觉库OpenCV2.4.11。
图12、图13是分别用传统的HOG+SVM多尺度检测算法和本文的运动目标检测识别算法对运动车辆的检测识别结果[17]。从实时性上来看,本文提出的检测识别算法平均FPS在20左右,传统算法在4~5,在实时性上本文提出的算法具有明显提升。

图12 车辆检测识别算法比较Fig.12 Comparison of vehicle detection and recognition algorithms
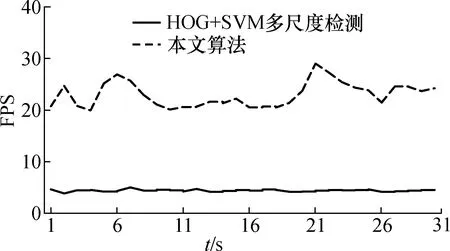
图13 2种算法视频监测实时性比较Fig.13 Real-time comparison of two algorithms
为了验证算法的实用性,本文在不同场景下对运动车辆进行检测,实验结果如图14所示。依据图中结果显示:在不同场景下依照本文算法都可将运动车辆很好地识别出来。证明本文算法具有普遍适用性。检测准确性和其他比较参数如表1所示。

图14 不同场景下车辆检测识别Fig.14 Vehicle detection and recognition under different scenes
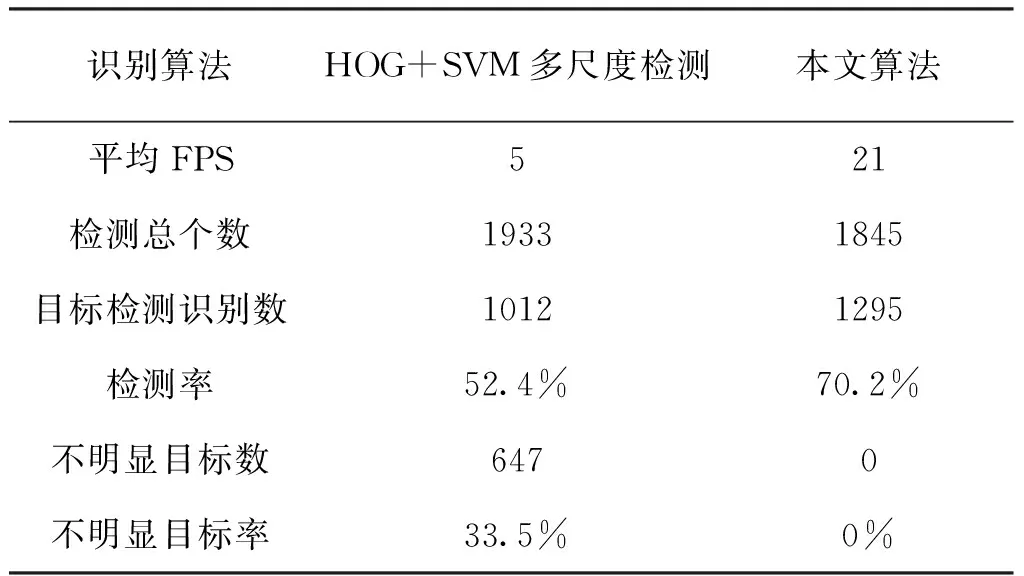
表1 2种算法检测识别效果对比Tab.1 Comparison of detection and recognition effects
表1中不明显目标率是指检测边界框中虽然有目标,但不是主要部分的概率,可能是误检,或是不确定的部分。这种情况在多尺度检测中会发生,但本文检测识别算法不存在这种情况。由表1可以看出:对于传统目标检测算法,本文识别算法提升了近20%。说明本文算法在准确性上相对是有提升的。
7 结束语
本文研究了基于视频的运动目标检测与分类识别,提出一种运动目标检测提取前景,送入SVM分类器的算法。该算法先对运动目标同时使用基于全局自适应阈值的帧间差分法和基于码本模型的背景减除法来进行检测,提取出运动目标的掩膜,然后通过掩膜外接矩形来提取目标矩形图片,通过多block调整HOG结构提取矩形图片的特征,最终放入SVM分类器进行分类识别。在检测过程中针对难例问题使用自举法成功解决。实验结果表明,本文算法在实时性和准确率上均优于传统的目标检测识别算法。但是本文算法在识别相互遮挡的运动目标时,由于目标区域不全,SVM分类器往往不能正确识别出车辆目标,从而影响了准确性。所以遮挡物体的运动目标检测与识别是一个值得研究和解决的发展方向。当前,高效的深度学习检测识别算法已成为主流和发展趋势,但是就学术研究而言,传统的目标检测方法作为基础仍然具有研究和学习的意义。
猜你喜欢
南京邮电大学学报(自然科学版)(2022年4期)2022-09-20
中国民航大学学报(2021年3期)2021-08-04
通信学报(2020年3期)2020-04-06
制造技术与机床(2019年9期)2019-09-10
成都信息工程大学学报(2019年5期)2019-05-21
西南交通大学学报(2018年6期)2018-12-18
通信技术(2018年1期)2018-01-19
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
探测与控制学报(2015年4期)2015-12-15
