
基于领域自适应的故障诊断研究与进展
2020-12-29 13:49:38杨青,薛辉
沈阳理工大学学报 2020年4期
杨 青,薛 辉
(沈阳理工大学 自动化与电气工程学院,沈阳 110159)
随着现代化工业生产的迅速发展,在生产过程智能化和安全化的同时,工业系统的集成化和信息化程度也得到增长,每一个微小的故障都会导致重大的事故发生。为避免由微小故障而导致后续的重大事故的发生,故障检测与诊断技术[1]被广泛的应用在工业生产过程中。如何更加高效快速的对故障问题进行精确诊断,受到了越来越多的国内外研究学者的关注。
目前大多的机器学习算法,依赖于数据的生成机制不随环境改变这一基本假设。假设训练和测试数据是独立同分布的,然而,这种假设在实际工业生产中很少成立,因为数据会随着时间和空间的变化而改变,从而导致诊断模型的泛化误差难以达到实际生产的故障诊断要求。
迁移学习[2-4]放宽了传统机器学习中训练数据和测试数据必须服从独立同分布的约束,能够在彼此不同但又相互关联的两个领域间挖掘不变的本质特征和结构,还可以有效解决目标样本数据量小、数据不均衡等问题,更加体现了历史知识和信息的重用性。其中领域作为进行学习的主题,针对领域研究的领域自适应方法就变成了目前迁移学习的研究热点和重点。本文对迁移学习领域自适应在故障诊断领域中的应用进行综述。
1 迁移学习领域自适应的研究现状
根据领域自适应方面的假设基础,将其分为数据分布、特征选择和特征变换自适应三种,如图1所示。
1.1 基于数据分布的领域自适应
假设数据的特征空间相同,并且类别空间也一致,但域之间的边缘分布或条件分布不同的情况下,通过减小域之间的距离,达到自适应要求。根据数据分布的性质,分为边缘分布自适应、条件分布自适应及联合分布自适应。
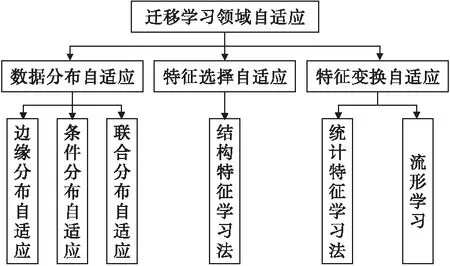
图1 领域自适应方法分类
边缘分布自适应方法的目标是减小域之间的边缘概率分布距离,从而达到自适应。边缘分布自适应的方法最早由Pan S J等[5]提出,方法名称为迁移成分分析(Transfer Component Analysis,TCA)。通过找到合适的φ,尽可能的使两个领域的条件分布P(ys|φ(xs))≈P(yt|φ(xt))。而领域之间的距离通过引入最大均值差异(Maximum Mean Discrepancy,MMD)来计算。在此之后的许多研究工作都以TCA为基础。Long M等[6]在TCA方法的基础上,将MMD扩展到多核,并且进行多层适配的计算。
条件分布自适应方法是减小源域和目标域的条件概率分布距离。中科院计算所的Wang J等[7]融入了类内迁移思想,指出现有的绝大多数方法都只是学习一个全局的特征变换,而忽略了类内的相似性;类内迁移可以利用类内特征,实现更好的迁移效果。
联合分布自适应方法主要是减小源域和目标域的联合概率分布距离。Tahmoresnezhad J等[8]在联合分布适配的优化目标中加入了类内距和类间距的计算,提出了基于视觉的领域自适应方法(Visual Domain Adaptation,VDA,)。Long M等[9]又提出了联合分布度量(Joint Adaptation Network,JAN)方法,优化了在深层网络中进行联合分布适配。
1.2 基于特征选择的领域自适应
如果两个域之间的类别空间一致,说明域之间的特征空间也相同,通过机器学习的方法,选择源域和目标域中均含有的公共特征,在这部分公共特征上构建学习模型,这就是基于特征选择的领域自适应。Blitzer J等[10]作提出了结构公共特征学习(Structural Correspondence Learning,SCL)方法,通过找到两个领域公共的特征,完成迁移学习任务。Long M等[11]提出了在优化目标中同时进行边缘分布自适应和源域样本选择的迁移联合匹配(Transfer Joint Matching,TJM)的方法,并取得不错的效果。Nannan L等[12]提出了通过共享源域和目标域特征的方法,实现无监督的领域自适应。
1.3 基于特征变换的领域自适应
通常假设源域和目标域数据在变换后的子空间中会有相似的分布。按照特征变换的形式,将子空间学习法分为:基于统计特征变换的统计特征对齐方法,以及基于流形变换的流形学习方法。
Sun B等[13]提出了子空间分布对齐(Subspace Distribution Alignment,SDA)方法,该方法在子空间学习(Subspace Alignment,SA)的基础上,加入了概率分布自适应;同年又提出二阶特征对齐的方法,对两个领域进行二阶特征对齐,通过学习二阶特征变换矩阵,使得源域和目标域的特征距离最小。Ghifary M等[14]从增量学习中获得启发:把源域和目标域看成高维空间(即格拉斯曼流形)中的两个点,在这两个点的测地线距离上取d个中间点,然后依次连接。这样,源域和目标域就构成了一条测地线的路径。只需找到每一步中合适的变换函数,就能从源域变换到目标域。Gong B等[15]提出了一种基于核学习的测地线流式核(Geodesic Flow Kernel,GFK)的方法,利用路径上无穷个点的积分,解决了如何确定中间点的个数问题;又提出根据领域秩的度量,解决了多源域与目标域的距离。
2 领域自适应在故障诊断领域的研究
随着迁移学习的价值不断得到挖掘,机械设备故障诊断的研究主要集中在复杂工况下和数据不平衡条件下的诊断预测问题。
2.1 数据分布自适应在故障诊断中的应用
目前,针对变工况下机械设备的故障诊断预测研究主要集中于如何消除或优化变工况情况下的数据分布不一致的问题。
在复杂工况下,机械设备的特征空间和类别空间一致的基础上,沈飞等[16-17]提出一种基于自相关矩阵奇异值分解的特征提取和迁移学习分类器相结合的方法,用于变转速、变负载条件下的电机故障诊断。陈超等[18]针对复杂工况环境导致的目标诊断数据无法直接获取、训练与测试数据分布特性存在差异的问题,提出基于地柜定量分析和改进最小二乘支持向量机相结合的方法。谭俊杰等[19]以无监督迁移成分和深度信念网络结合的方法,提高样本识别精度。顾涛勇等[20]针对航空维修保障的故障概率预测领域提出自适应权重的插值拟合迁移学习算法,自适应的调整插值、拟合各部分的比例,规避了数据贫化所带来的预测风险,同时减少了负迁移现象。Ding Z等[21]提出了一种鲁棒度量学习框架,消除了样本空间中两域的分布差异。Long M等[22]提出一种深度迁移学习与自编码结合的诊断方法,实现领域自适应。Wen L等[23]建立了一种新的深度迁移学习故障诊断方法,提出的方法通过不同工况条件下的轴承数据进行验证。Zhang X S等[24]提出了一种鲁棒转移度量学习方法(RTML)框架,消除了样本空间中两个域的边界分布和条件分布差异。
2.2 特征选择自适应在故障诊断中的应用
在域类别空间一致的基础上,将采集到的机械设备的特征数据迁移到工业现场设备所部署的智能模型中,完成不同机械设备之间监测数据的特征知识迁移。
Lu W等[25]采用了最大均值差异法进行域自适应训练,建立了相应的特征迁移模型,提升模型在不同域间的泛化能力。郭亮等[26]提出基于特征知识迁移的故障诊断方法,在所采集的足量的特征基础上,构建工业现场的特征模型,达到故障监测的效果。
2.3 特征变换在故障诊断中的应用
基于统计特征变换的统计特征对齐方法作为特征变换的故障诊断领域中的主要方法之一,在预测性维护领域中,得到广泛使用。由于设备处于故障状态的时间较少导致故障样本数量稀缺,以至于收集到的故障样本数量远小于正常样本数量。同时,同类或相似设备的结构差异、运行条件差异等因素导致某设备故障样本很难适用于其他设备,造成行业内故障数据的稀缺。迁移学习通过构建辅助故障分类器或利用特征空间映射来训练半监督或无监督模型。
康守强等[27-28]针对滚动轴承变工况条件下较难获取大量带标签的振动数据,以致诊断准确率低的问题,提出基于变分模态分解及多特征构造和半监督迁移成分分析方法相结合的滚动轴承故障诊断方法。张根保等[29]提出基于栈式稀疏自动编码器和高阶相对熵结合的故障诊断模型,利用少量的数据就可以适应新的工况。张振良等[30]针对航空发动机轴承故障诊断过程中预测精度不足以及过拟合的问题,提出了基于迁移学习的半监督集成学习。
由此可见,迁移学习在故障诊断数据分析和制定决策的过程中作用显著,最主要的是可有效解决变工况和数据量少的问题,为故障诊断领域的研究提供了新的思路。
3 未来发展趋势
针对迁移学习的特点和目前在预测性故障诊断领域的研究现状,未来可能的研究方向有
(1)迁移强化学习
强化学习可以通过边获得样例边学习的方式,利用特定的反馈函数决定最优决策。迁移学习则可以利用其他数据上训练好的模型帮助训练。将迁移学习和强化学习结合,可以进一步利用小规模数据,训练出同数据量下其他方法所不能达到的更好的模型。目前迁移强化学习已经有了一定的进展,如何将二者更好结合,并应用在故障诊断领域中,大大减少故障数据不足所引发的模型准确率下降的问题,是下一步研究的重点。
(2)在线迁移学习
目前大多数迁移学习都采用离线方式进行,既源域和目标域数据都已经获取完成,但真实的场景往往是数据(目标域)会以数据流的形式不间断的输入。目前来说,在线迁移学习在多源域和目标域上自适应及在线特征选择上有一定的研究,但应用在故障诊断领域方面的研究工作总体较少。与深度网络结合在线迁移学习,如果可以应用在工业现场的故障预测方向,会大大提高机械设备的实时稳定性,更早更快的发现问题,降低工业事故的风险。
4 结束语
迁移学习在近几年的发展中,已经发展成一种分类详细、方法众多的学习方法,可极大的提高模型的泛化能力,并能改善小样本下模型的训练精度。将迁移学习应用到故障诊断领域,通过数据分布、特征选择和特征变换等方法,克服了传统机器学习变工况或小样本数据下精度过低的弊端,可有效提高复杂工况下的设备诊断精度,并能一定程度上加快在线故障诊断的训练过程,减少模型训练时打标签等过程消耗的人力物力,可以更及时的反应工业现场中的故障问题。但目前在故障诊断领域的应用仍处于探索阶段,在不同工况或复杂工况下模型的适应能力及实时数据实时诊断或故障预测上还有很大的空间丞需研究和解决。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
计算机技术与发展(2020年11期)2020-12-04 07:50:46
青年生活(2019年23期)2019-09-10 12:55:43
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
电子与信息学报(2015年12期)2015-08-17 11:14:42
中共南宁市委党校学报(2015年4期)2015-02-28 11:48:10
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
机械与电子(2014年1期)2014-02-28 02:07:31
河南科技(2014年3期)2014-02-27 14:05:48
中国音乐教育(2014年7期)2014-02-06 21:46:15
