
基于半监督随机森林分类算法的齿轮故障诊断
2020-12-29 13:49:36魏永合尹际雄马步芳
沈阳理工大学学报 2020年4期
魏永合,尹际雄,马步芳
(1.沈阳理工大学 机械工程学院,沈阳 110159;2.航宇救生装备有限公司,湖北 襄阳 441003)
齿轮作为机械设备中用作连接和传递动力的关键部件,其健康程度决定了整个设备运行的安全性和可靠性。实际数据分析表明,齿轮箱故障中由于齿轮引起的故障比例为60%[1]。齿轮最常见的故障形式有断齿、裂纹、磨损、点蚀等,同时齿轮的运行状态好坏与齿轮振动信号有着重要联系。目前,在处理复杂的故障振动信号方面,传统的时域、频域和时频分析方法判别效率较低、实时性差,已不能满足要求。针对此情况,将时域和频域指标与判别函数相结合,利用机器学习算法对样本数据进行训练,得到不同故障的特征及故障数据的模式识别模型,其识别率和准确率都大幅提升[2]。其中基于神经网络的方法应用较广,但其结构的选择、收敛速度较慢等都制约着诊断结果的准确性。支持向量机采用结构风险最小化的原理,适用于小样本数据。但在实际工业应用中,往往获取的训练样本数量较大,当处理这些数据量较大的输入数据时,支持向量机表现出相对较差的诊断性能。随机森林[3]作为其中的一种也在不断发展,其实现过程简单,能很好的解决数据量较大的问题,且在训练样本有所缺失的情况下也能达到良好的预测准确度,既能处理离散数据也能处理连续数据,与其他机器学习算法相比有着明显优势[4]。
在机器学习和故障类别识别方面,依据训练样本是否有类别标签,可以把算法大致分为三类:监督学习、无监督学习和半监督学习[5]。传统的监督学习首先需要利用相关领域知识对输入的故障样本给出类别标签,通常需要大量标签数据;当有标签数据过少时,会存在过拟合现象,模型泛化能力较差;通常在对故障类型进行分类时要求具有较高相关领域的专业知识,需要付出大量的人力物力,还会出现瓶颈以及标签错误等问题。无监督学习的训练样本由于缺少专家先验知识,导致其算法性能低于有监督学习。半监督学习既可利用有标记数据还可利用无标记数据,在少量带标签数据的基础上,利用大量低廉的无标记数据训练模型,对分类器性能的提升卓有成效[6]。杜利敏[7]在半监督学习框架下,提出了一种针对不平衡数据的半监督分类算法,并改进该算法将其应用到无线电信号识别当中,有效解决了训练样本标签数据不足及分类不平衡的问题。石凯[8]针对传统互联网入侵检测系统中缺少大量有标记数据的问题,提出了一种基于半监督和特征选择的入侵检测方法,提高了检测准确率。
针对齿轮故障振动信号的非平稳、非线性特点以及有标签故障样本稀缺的问题,本文提出一种基于半监督随机森林分类算法的齿轮故障诊断方法;首先在利用变分模态分解算法(VMD)[9]对采集到的齿轮信号进行信号预处理的基础上,结合随机森林的特征重要性选择方法,根据相关性强弱删除冗余特征,筛选出敏感特征,以提高模式识别分类准确率。
1 改进的半监督学习自训练算法
1.1 传统的自训练算法
自训练模型的优点在于其自身是一种算法框架,任何一种有监督学习分类算法都可以通过引入无标签数据进行训练,同时不需要对有监督分类算法的内部算法流程做任何调整。具体步骤如下:首先输入少量有标签数据训练模型得到初始分类器;再利用得到的分类器对大量无标签数据进行类别标记,将置信度较高的无标签数据扣除并放入训练集,再次训练分类器;重复上一步骤,直到满足预定的停止条件。
由上述可知,自训练模型有一个很大的缺点,在迭代过程中,如果未标注的数据预测类别错误,就会在后续的迭代过程中造成误差积累[4]。
1.2 改进的自训练算法
针对上述问题,本文采用重复标记无标签数据优化自训练算法。具体计算步骤如下。
式中:L表示有标签数据;xi表示i第个样本数据;yi表示第i个样本的类别标签;U表示无标签数据;l表示有标签数据总数;u表示无标签数据总数。
1)利用有标签数据L训练初始分类器。
2)用分类器预测U得到伪标签数据,从中挑选出满足阈值的高置信度数据样本加入训练集。用扩充后训练集训练分类器,不减少无标签数据。
3)重复步骤2),直到满足预设的停止条件。
其中本文分类器选择随机森林,每次迭代从中取出满足条件的数据,无标签数据量不变。算法流程图如图1所示。
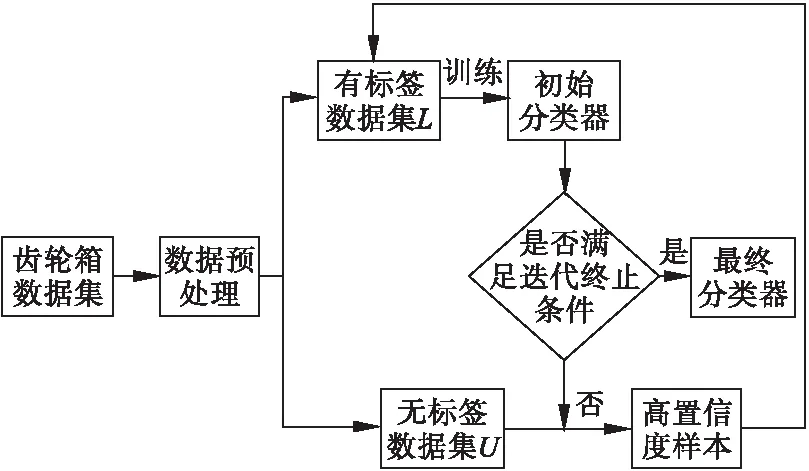
图1 改进的自训练算法流程图
2 基于随机森林和改进自训练方法的齿轮故障诊断模型
2.1 随机森林算法基本原理
随机森林(random forest,RF)是由Leo Breiman提出的一种包含多个弱分类器的组合学习算法[3]。随机森林算法秉承了Bagging的思想,以构建单一决策树为基础,引入两个随机属性;其基本原理是利用多棵决策树对样本进行训练并预测,其中每棵树的输入数据是随机子集,每棵树构建所需的特征从全体特征中随机选取,最后用票选法选择最可能的分类结果。随机森林具有拟合速度快,方便处理大规模数据、易于实现、可以避免过拟合等优点。
随机森林是典型的机器学习算法之一,具体流程如下。
(1)用有放回的抽样方法从样本集中选取n个样本作为一个训练集。
(2)利用训练集产生一棵决策树,在决策树的每一个节点随机不重复的选择d个特征,通过这些特征划分训练集,搜寻最合适的划分特征(可用基尼指数、信息增益或信息增益比判别)。
(3)重复步骤(1)到步骤(2)共f次,f即为随机森林中决策树的个数。
(4)根据得到的随机森林预测测试数据,最终通过票选法获得结果。
2.2 特征重要性度量
随机森林的一个重要特性是给出特征重要性评分,计算某个特征的重要性,可以此来进行特征选择,剔除冗余特征。RF的基本思想是:计算每个特征对随机森林中每棵树的重要性,对特征之间的重要性进行比较、排序。特征重要性通常用基尼指数或袋外数据误差率作为评价指标来衡量[9]。
2.3 齿轮故障诊断模型
本文提出的基于随机森林和改进自训练方法的齿轮故障诊断模型如图2所示。

图2 基于半监督随机森林分类算法的齿轮故障诊断模型
基于半监督随机森林分类算法的齿轮故障诊断模型主要包含以下几个步骤。
(1)齿轮产生的信号是由多个信号分量组合而成的复杂信号,其中夹杂着由自身及周围环境引起的大量噪声信号。齿轮故障诊断模型首先将原始振动信号通过VMD分解为一系列频率从低到高的本征模态函数(Intrinsic mode Function,IMF)[10],各个分量包含了不同频率的齿轮故障信息。利用相关系数法求得原始信号和各模态分量之间的相关系数[9],包含原始信号有效特征信息越多的分量,相关系数就越大,根据结果进行排序,选择前H个模态分量进行特征提取。
(2)对相关性较高的前H个IMF进行传统时频域的信号分析,提取m个时域特征和n个频域特征,其中时域特征包括i个有量纲特征和j个无量纲特征,共提取m+n个混合域特征[11],即样本维数为m+n的初始特征集合。
(3)利用随机森林的特征重要性评分,计算初始特征集合中每个特征在所有特征变量中的重要性,并按降序排序,评分越高表示该特征越重要。根据基尼指数和袋外误差率,选择前p个特征作为新的敏感特征集合。
(4)选取不同比例的标记数据和未标记数据,利用改进的半监督自训练算法结合随机森林算法,训练得到最终分类器,对测试数据进行模式识别。通过实验数据验证该方法的有效性。
3 实验验证及结果分析
3.1 齿轮原始信号的采集
本文选用旋转机械振动分析及故障诊断实验平台系统,模拟齿轮正常状态、齿面点蚀、齿面磨损及齿根断齿三种故障状态。该平台齿轮箱输入轴小齿轮齿数为z1=55,输出轴大齿轮齿数为z2=75,齿轮模数m=2。实验中设定电机转速为750r/min,采样频率为2560Hz,采样点数为2048。计算得到小齿轮转频为12.5Hz,大齿轮转频为9.17Hz,啮合频率为687.5Hz。利用加速度传感器采集四种状态下相对应的振动信号,传感器安装在输出轴轴承端盖上。
3.2 特征提取与特征选择
在进行特征提取之前,通常要对输入数据进行归一化处理,目的是为了消除指标之间的量纲影响,以解决数据指标之间的可比性,使得各指标处于同一数量级。利用VMD将预处理后的信号分解为多个本征模态函数,分解层数k=8,惩罚因子α=1700。以齿面点蚀故障为例,图3为齿面点蚀状态下的振动信号,时域波形图如图3a所示,振动信号的VMD分解结果如图3b所示。分解结果的好坏并不能单从时域图中看出,结合图4振动信号VMD的分解频谱图可以看出,VMD可将故障信号的频率实现自适应分解为8个模态分量,有效提取齿轮故障特征信息,抑制了模态混叠现象。
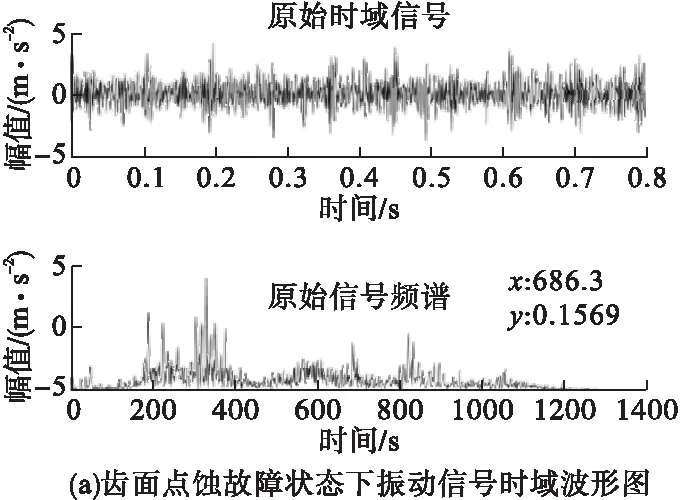
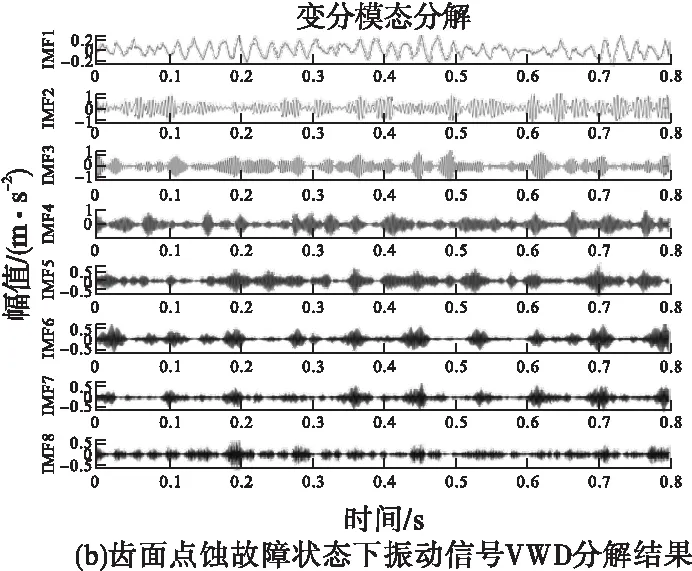
图3 齿面点蚀故障状态下振动信号
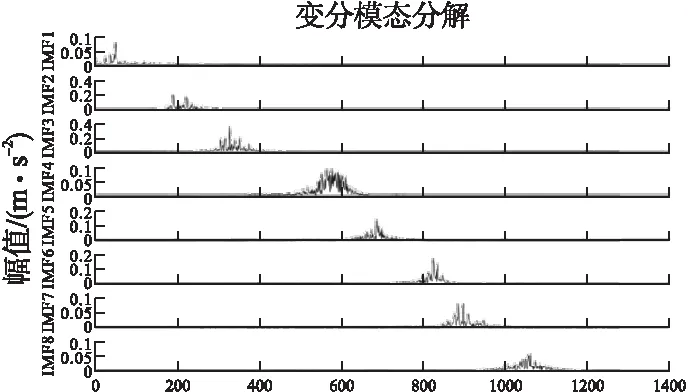
图4 齿面点蚀故障状态下振动信号VMD分解频谱图
根据皮尔逊相关系数法,通过计算得到各模态分量和原始信号的相关性,如图5所示,剔除相关系数小于0.3的伪分量。选用齿轮的第1~4阶模态分量进行信号重构,这样保留了原始信号的敏感信息,去除噪声对信号的影响。利用传统时频域的信号处理方法,从重构后的各阶模态分量中提取出11个时域特征、3个频域特征、3个能量特征。此时,特征提取后得到由17个特征指标构成的高维样本空间。
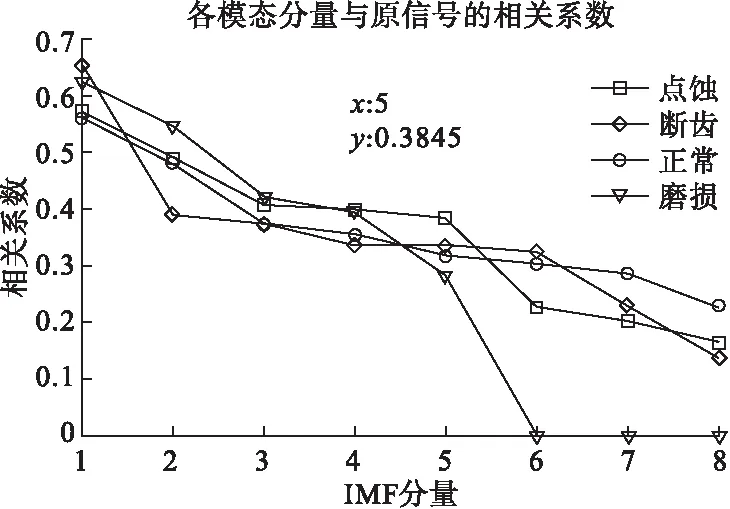
图5 VMD分解后的本征模态分量相关系数图
由于直接使用提取出的17个特征构成的高维样本空间难以得到满意的故障诊断结果,因此需要进行近一步的特征选择。研究证明随机森林算法对异常值和噪声有很强的容忍度,适合处理维数较高的数据,去除相关性较低的特征进行特征筛选[12]。本文利用随机森林的特征重要性评分特性,对特征提取后的高维数据进行特征选择,保留前6个特征,部分数据如表1所示。结合模式识别方法通过实验验证其有效性。
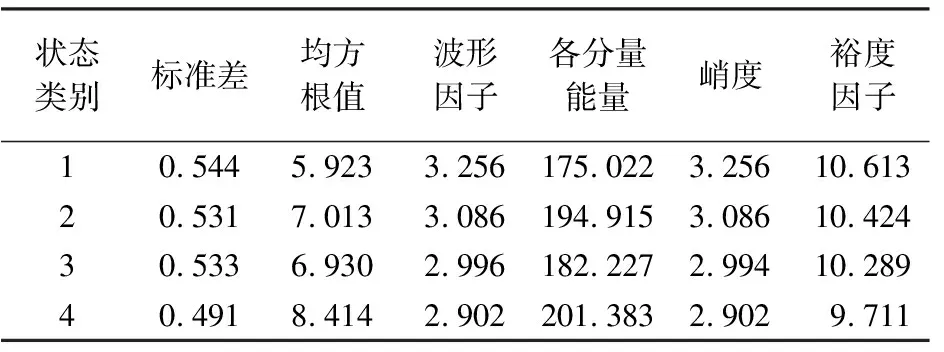
表1 部分齿轮点蚀故障的样本特征向量
3.3 故障诊断
半监督学习算法能够有效利用未标记数据中蕴含的大量数据分布等信息,而本文利用改进后的半监督学习自训练算法可有效避免误差积累的缺陷。随机森林算法则通过引入两个随机性,使其具有较强的抗噪声干扰能力,预测能力强方差小、不易陷入过拟合、适合处理维度较高的数据等优点。与半监督学习算法相结合可以获得分类结果更准确、表现更稳定的故障诊断模型[4]。
在进行特征选择后,对输出齿轮状态进行编码,编码1、2、3、4分别代表齿轮正常状态、齿面点蚀、齿面磨损和齿根断齿。从四种齿轮运行状态中分别选取750个样本数据,样本总数为3000个。随机将数据集分为训练集和测试集,其中训练集占比90%,测试集占比10%。为测试半监督学习中有标签数据和无标签数据不同比例对分类器的影响,把训练集中的少量数据作为初始化分类器的标记样本,剩余部分去除标记作为无标记样本,实验中设定标记样本与未标记样本的三种比例分别为1∶8、2∶7、4∶5,依次测试不同分配情况下分类器的分类精度,并与改进前的自训练分类器进行对比研究。
3.4 实验结果
图6为标记样本与未标记样本的三种不同比例下迭代次数与准确率的关系曲线。
从图6a可以看出,随着迭代次数的增加,改进后的模型准确率变化较为稳定。图6b反映了改进后有特征选择的模型具有较高的准确率。图6c所示,随着未标记数据的加入,改进前的模型准确率有明显下降趋势。以上实验结果表明,改进后的自训练算法对有标签数据的需求程度较低,无标签数据的比例变化对其分类准确率影响较小,一定程度上解决了半监督学习中误差积累的问题以及齿轮故障振动信号中有标签样本稀缺的问题。
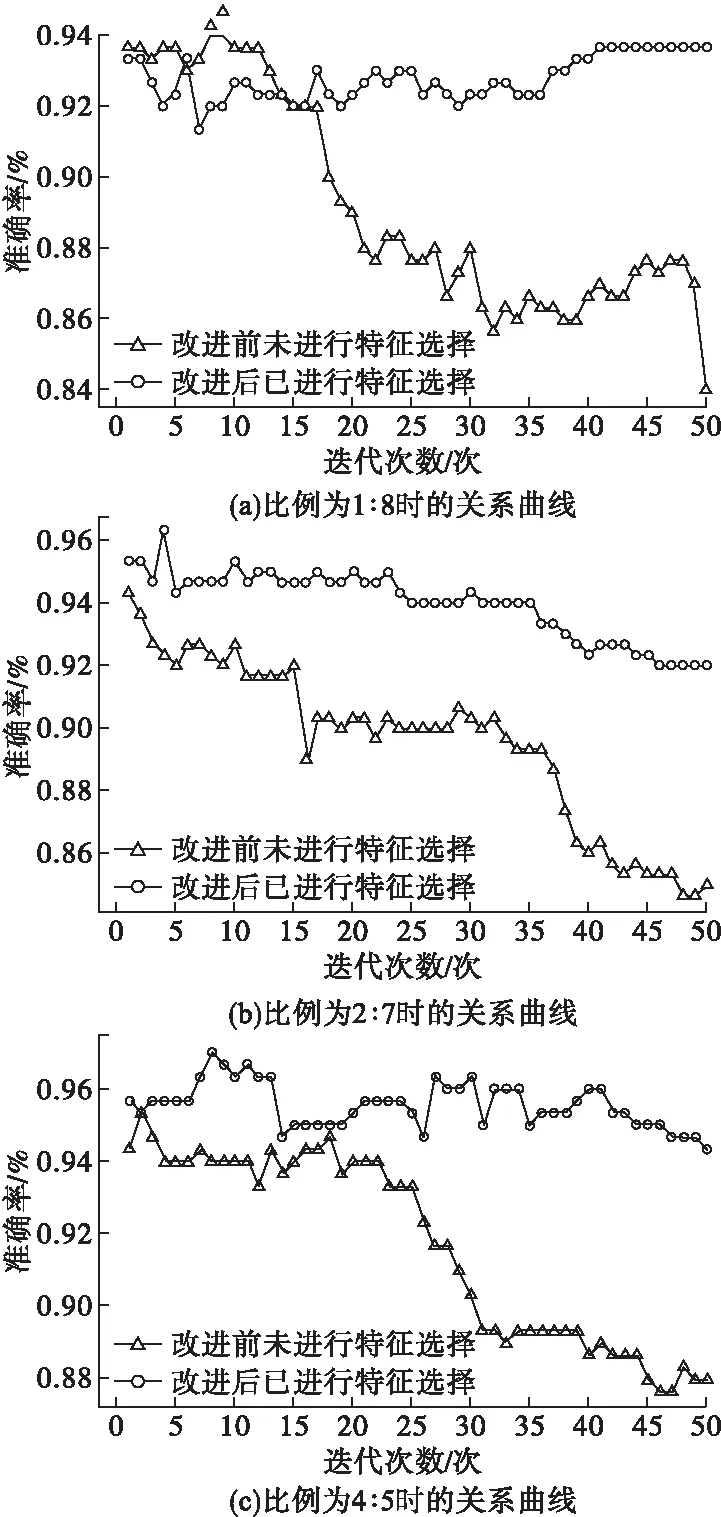
图6 不同标记比例下迭代次数与准确率的关系曲线图
为验证随机森林进行特征选择能有效提高模型的预测准确率,结合改进后的半监督自训练算法,对特征筛选前后的分类准确率进行比较。根据训练样本中标记和未标记数据不同比例,进行了三次比较,表2是比较结果。
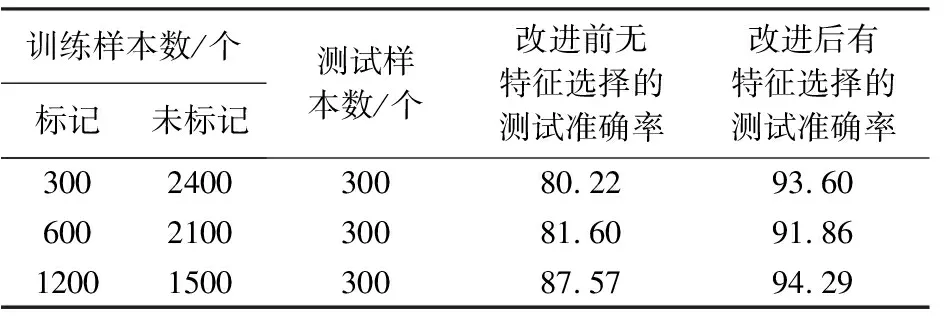
表2 特征选择与算法改进前后相结合的测试准确率 %
由表2可以看出,改进后的自训练算法结合随机森林进行特征选择后准确率提高了7%~14%;当训练样本中标记数据与未标记数据比例为1∶8时,利用改进后的算法结合特征选择后测试准确率提升较大,为13.38%。
4 结束语
提出了一种基于半监督随机森林分类算法的齿轮故障诊断模型。通过迭代训练不断加入高置信度样本扩充训练样本,在解决了半监督学习中误差积累问题的同时提高了分类器的泛化性能,与传统的自训练算法相比精度提高7%~14%左右。最后通过改进的半监督学习自训练算法结合随机森林分类算法进行模式识别,利用大量无标签数据,规避其他半监督学习算法中常见的误差积累问题,达到较高的故障诊断精度。
猜你喜欢
内燃机工程(2021年6期)2021-12-10 08:07:46
少儿科学周刊·少年版(2020年9期)2020-03-04 11:38:12
少儿科学周刊·少年版(2020年9期)2020-03-04 11:38:12
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
电子测试(2018年1期)2018-04-18 11:52:35
制造技术与机床(2017年3期)2017-06-23 08:11:52
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
公民与法治(2016年10期)2016-05-17 04:12:58
