
多源域适应方法综述
2024-03-25 02:10韩昌芝乔平娟
计算机技术与发展 2024年3期
李 林,俞 璐,韩昌芝,乔平娟
(1.陆军工程大学 通信工程学院,江苏 南京 210007;2.陆军工程大学 指挥控制工程学院,江苏 南京 210007)
0 引 言
在当今大数据时代背景下,人工智能技术得到飞速发展,尤其是在计算机视觉、语音识别和自然语音处理等领域中,机器学习和深度学习算法依靠大数据技术强大的计算和存储能力得到广泛应用。然而,现实情况下收集并标注大规模训练集样本使得模型充分发挥其能力是十分困难的,获取与训练集具有相同分布的测试集样本也是不切合实际的。此外,不同分布的样本在同一训练模型往往具有不同的预测结果,很难达到预想效果。
迁移学习旨在寻找源域和目标域中样本、任务或者模型之间共有的相似性,并以此为知识进行学习,实现将源域知识迁移到目标域的目的,具有触类旁通、举一反三的效果。域适应是迁移学习领域中的代表性方法,同时也是其中的研究热点和难点。域适应的核心是减小源域和目标域的分布差异,源域和目标域之间存在分布差异也归因于分布不同的域之间存在的域偏移现象(Domain Shift)[1],研究域适应的重点在于充分挖掘并利用源域和目标域之间共同的域不变特性,使从源域中提取到的特征信息发挥更大作用,进而消除或减少域偏移的影响,并从已标记的源域学习到一个能很好地推广到不同但相关的目标域的模型,从而实现对目标样本的准确预测[2]。
多源域适应是对域适应的深化拓展,更具有实用性、必要性和挑战性。早期的研究一般属于单源域适应,然而,单源域适应有其不可避免的局限性,即在现实条件下获取源域的方法和渠道多种多样,这会导致各个源域之间具有不同程度的分布差异。多源域适应是将来自多个不同数据源或领域的数据进行联合训练,以提高模型的泛化能力和适应性。随着研究者的探索,多源域适应算法[3-4]和理论[5-6]愈加成熟,更加符合现实需求,得到了广泛应用[7-9]。
现有研究主要是对域适应的各种方法展开综述,但缺少对多源域适应方法的综述工作,因此,该文对其进行总结归纳。主要内容如下:(1)系统地总结多源域适应的研究现状和最新的研究进展。(2)从迁移学习的实现方法角度,将多源域适应划分为基于分布差异的多源域适应、基于对抗的多源域适应、基于重构的多源域适应、基于样本生成的多源域适应和基于模型的多源域适应,比较各种方法的异同。(3)简述当前常用数据集,对比多种数据集下各个多源域适应方法的识别效果。(4)简述多源域方法在现实中的具体应用。(5)分析当前方法存在的问题和不足,以此为基础探讨未来可行的研究方向。
1 概 述
1.1 多源域适应基本概念和形式化定义
对多源域适应方法进行综述前,本节主要介绍多源域适应的基本概念、形式化定义和当前研究现状。
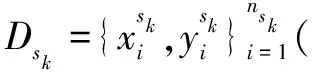
1.2 多源域适应研究现状
当具有标记的、服从不同分布的源域数量不止一个时,多源域适应方法更加贴合实际符合现实需求,能够充分利用源域多样性,充分提取多个源域的可迁移知识,因此研究多源域适应问题十分必要。图1显示了单源域适应方法和多源域适应方法的差异。多源领域自适应问题研究起源于A-SVM[10],该方法利用源特定分类器的集合来调整目标分类模型,并且已经发明了各种浅层模型来解决多源领域自适应问题。文献[3]对多源领域自适应问题的方法进行了归纳,梳理了相关理论和基础算法。文献[11]形成了一个解决多源域适应的通用框架,将多源域自适应问题的方法总结为隐式变换法和中间域生成法,隐式变换法是指对齐多个源域和目标域的特征或是减小其间的特征分布差异,具体分为基于分布差异的方法和基于对抗的方法,中间域生成法是指显式地为每个源域生成与目标域分布相似的中间适应域,并用生成的域训练任务模型。
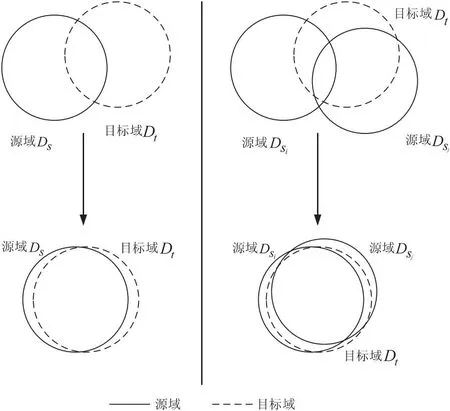
图1 单源域适应方法和多源域适应方法示意图
2 多源域适应
研究多源域适应问题的背景基本设定为具有多个已标记的源域数据集,一个未标记的目标域数据集,并且所有源域和目标域具有相同的特征空间和标签空间,因此研究的多源域适应方法大多是无监督的、同构的、在闭集上进行训练的。早期多源域适应方法主要是在浅模型中的挖掘隐式特征和学习预分类器[12]。随着深度神经网络可迁移性得到证明和应用,多源域适应方法与其相结合更能够提取高层次的特征信息,更好地完成迁移任务。该文将根据深度神经网络中迁移方式的不同,将多源域适应方法分为:基于分布差异的多源域适应方法、基于对抗的多源域适应方法、基于样本生成的多源域适应方法和基于模型的多源域适应方法。该文将对多源域适应方法研究的最新进展进行总结归纳。
2.1 基于分布差异的方法
基于分布差异的方法主要遵循学习共有特征、优化特征表达、缩小多个源域和目标域特征分布的差距以及训练分类器等步骤,逐步提升模型的迁移能力。基于分布差异的多源域适应方法通过减少多个源域与目标域之间的差异,使得多个源域与目标域的样本尽量服从同一分布,消除域偏移带来的影响,从而减小目标泛化误差。
2.1.1 最大均值差异(Maximum Mean Discrepancy,MMD)
MMD是显式测量源域和目标分布差异的度量方法,基于MMD的单源深度域适应方法运用相对成熟,领域适应神经网络(Domain Adaptive Neural Network,DaNN)、深度领域混淆方法(Deep Domain Confusion,DDC)先后将MMD方法应用于深度神经网络,计算出源域和目标域间的特征差异的MMD损失,使得源域特征和目标域特征更加相似。
Guo等[13]利用点到集合的距离度量关系进行建模,将MMD方法用于提取多个源域混合专家特征,以达到最小化源域和目标域边缘分布的差异的目的。Zhu等[14]提出了一种同时对齐分布和分类器的多源领域自适应方法(Multiple Feature Spaces Adaptation Network,MFSAN)。MFSAN的网络结构共包括三部分:公共特征提取器F,领域特定的特征提取器H和领域特定的分类器C。首先对齐各个领域特定的特征,使用MMD的方法将不同的源域和目标域的分布对齐放在不同的特征空间中;其次,对齐各个源域的分类器,减小分类器输出的差异,明确一致性正则项。模型总的损失函数包含三部分:分类损失Lcls、特征对齐损失Lmmd和一致性正则化项Ldisc,损失函数表示如下:
Ltotal=Lcls+λLmmd+γLdisc
(1)
2.1.2 矩距离
Peng等[15]利用计算各域之间的矩距离判断域间差异,动态对齐特征分布的矩距离,以此提出多源域适应矩匹配网络(Moment Matching for Multi-Source Domain Adaptation,M3SDA)。
Fu等[16]基于各域间的差异提出一种部分特征选择对齐方法(Partial Feature Selection and Alignment,PFSA)。该方法利用多个源域与目标域的相似度出特征选择向量,即从多个源域中部分选择符合与目标域对齐的特征,通过最小化同一类别样本聚类的损失、最大化不同类别之间的距离差异来联合对齐所选特征。
2.1.3 Wasserstein距离
Wasserstein距离也被称为推土机距离(Earth Mover’s Distance,EMD),用来计算两个分布的相似程度,可以衡量源域样本分布移动到目标域样本分布时所需要移动的平均距离的最小值。
Li等[17]为便于在多个域间进行成对匹配操作,率先使用Wasserstein距离减小域间差异,并确定域间关系。Wu等[18]根据不同源域到目标域的条件Wasserstein距离计算不同源域的转移权值,并使用传递的权重来重新加权源数据,最终确定各源域在迁移过程中的比例。Wang等[19]构造了一个类再平衡的Wasserstein空间(Class-rebalanced Wasserstein Distance,CRWD),考虑到各源域间类别差异,更好地利用标签信息,减轻了类间样本不平衡的影响,更精确地度量了多个域之间的差异。
2.1.4 混合距离
文献[20]指出每种距离都有其独特的物理含义,单一使用某种距离并不能确定多个源域和目标域间的差异,因此提出一种基于多种距离混合的DistanceNet模型。该模型使用L2距离、余弦距离、MMD、Fisher线性判别器和CORAL集成的方法。
混合距离定义为:
(2)
其中,k表示第k种距离,αk表示使用第k种距离的权重系数。模型损失函数表示为:
Ltotal=LXE+βDm(Xs,Xt)
(3)
其中,LXE为分类损失,β为正则化项系数。
2.1.5 图准则方法
基于图准则的方法主要是考虑领域分布结构,使用图论的思想构建一个表示源域和目标域的图结构。该方法将样本视为点,样本间相似度作为边,数据集即为一个无向图,通过计算不同节点之间的相似性来量化两个领域之间的差异性。减小源域图和目标域图之间的差异可确定哪些特征可以被迁移,若源域图和目标图之间差异较小,则认为源域模型具有较好的泛化能力。
Wang等[21]以图神经网络为基础,设计一种基于图模型的学习组合多源域自适应框架(Learning to Combine for Multi-Source Domain Adaptation,LtC-MSDA)。该框架通过聚合多个源域学习到的知识构建知识图,并以此为根据约束全局类别间的关系依赖性和局部各类别特征的紧密性,从而达到对目标域进行预测的目的。Xu等[22]在LtC-MSDA方法的基础上进行优化和改进,推导出条件随机场多源域适应(Conditional Random Field for MSDA,CRF-MSDA)和马尔可夫随机场多源域适应(Markov Random Field for MSDA,MRF-MSDA)两种不同类型的图模型,有效解决多个源域和目标域组合建模的问题,明确各域实例和类别间的依赖关系。
2.2 基于对抗的方法
基于对抗的多源域适应方法是将对抗生成网络(Generative Adversarial Network,GAN)[23]博弈的思想引入域适应问题中,其目的是特征提取器通过训练可以学习到欺骗域判别器的域不变特征,域判别器通过训练可以不断提升鉴别源域和目标域样本的能力。基于对抗的方法在单源域适应上较为成熟的方法有单对抗的方法,比如领域对抗神经网络(Domain Adversarial Neural Network,DANN)、对抗判别域适应(Adversarial Discriminative Domain Adaptation,ADDA),以及多对抗的方法,比如多对抗域适应(Multi-adversarial Domain Adaptation,MADA)、条件领域对抗网络(Conditional Domain Adversarial Networks,CDAN)。
多源域适应的方法与对抗的方法相结合,可以从多个源域样本间提取与目标域样本相同的域不变特征,保证了域不变特征的可靠性。文献[24]提出一种深度鸡尾酒网络(Deep Cocktail Network, DCTN),采取多路对抗的方式混淆多个域判别器,使其无法判断样本来源,并使用加权组合的方式给予各源域混淆系数,进而训练各源域分类器。
Zhao等[25]基于理论[26]确定多源域的泛化边界,在对抗网络中加入任务学习部分,并以此为基础构建两个版本的多源对抗网络模型(Multi-Source Domain Adversarial Networks,MDAN)。Wang等[27]考虑到不同任务的特殊性,引入任务特定分类器,提出了一种任务特定多源域适应方法(Task-specific Multi-Source Domain Adaptation Method,TMDA)。Rakshit等[28]认为多源域间的类别相关性十分重要,由此提出了一种对抗训练对齐的多个源域类别特征方法(Deep Adversarial Ensemble Learning,DAEL)。
2.3 基于样本生成的方法
基于分布差异的方法和基于对抗的方法大多都是对高级特征进行处理,却忽略了样本本身的原始特性。基于样本生成的多源域适应方法是指使用多个源域样本生成带有标签的目标样本,并使用生成样本训练网络模型的方法。该方法不仅将问题转化为有监督的方法提高模型性能,还可以直观地观察到生成样本与目标样本的差异,具有很好的可解释性。
基于样本生成的多源域适应方法多运用生成对抗网络(GAN)或是以GAN为基础的改进模型。Russo等[29]使用CoGAN的方法训练生成器,在像素层次上将目标域与每个源域进行对齐;Zhao等[30]使用CycleGAN的方法训练生成器,设计子域判别器和跨域循环判别器,生成不同的适应域(Adapted Domain),将目标域与适应域的集合进行对齐;Lin等[31]将变分自编码器(VAE)与CycleGAN相结合,把所有源域和目标域映射到同一特征空间,在此空间生成适应域,而后目标域与生成的适应域进行对齐。
Zhao等[32]设计了一种端到端模式的多源对抗域聚合网络(Multi-Source Adversarial Domain Aggregation Network,MADAN)。首先,结合动态语义一致性的原则为每个源域生成相应的适应域;其次,设计子域聚合判别器和跨域周期判别器使不同的适应域更紧密地聚合;最后,将不同的适应域与目标域进行特征对齐。
2.4 基于模型的方法
随着深度神经网络的发展,可以通过改变深度神经网络结构的方法提升识别效率。基于模型的多源域适应方法的核心思想是明确源域模型的哪部分有助于提高目标域模型性能。
文献[33]从深度网络结构的角度考虑,提出一种多源域对齐层(Multi-Source DomaIn Alignment Layers,MS-DIAL)替换归一化层的方法。该方法可以在任何给定网络中嵌入域对齐层来减少多个源域和目标域之间的域偏移,因为除了嵌入的域对齐层之外,其他网络参数都在所有域之间共享,因而节省了时间和空间。
Li等[34]设计了一种聚合残差矩阵和静态卷积矩阵建模的动态传输模型(Dynamic Residual Transfer,DRT)。该模型可以将多源域适应问题转化为单源域适应,简化了多源域与目标域之间的对齐。Deng等[35]认为每个源域的样本具有细微的实例特性,因此设计了具有多尺度自适应卷积核的动态神经网络,提出一种动态实例域适应方法(Dynamic Instance Domain Adaptation,DIDA-Net),可以有效提取与领域无关的分类特征。
Nguyen等[36]提出了一种基于最优传输和模仿学习理论的多源数据分析新模型(Optimal Transport for Student-Teacher Learning,MOST)。该方法由一个教师分类器和一个学生分类器组成,其中教师分类器利用多个源域内的知识提取专家特征,因此目标域的学生分类器可以模仿源域的教师分类器进行预测分析。文献[37]基于师生模型提出一种学生-教师集成多源域自适应(Student-Teacher Ensemble Multi-Source Domain Adaptation,STEM)模型。该模型使用共享的生成器学习到各源域的专家特征,并使用域判别器学习各源域专家特征的预测系数将多源域专家特征进行组合,而后对源域分类器进行训练,形成一个多源教师网络。结合对抗学习的思想,将多源教师网络与目标域学生网络映射到同一特征空间,因此目标域学生分类器可以有效模仿教师分类器进行分类预测。
2.5 小 结
本节对多源域适应方法进行了综述,按照域适应实现方法的不同对多源域适应方法进行分类。基于分布差异的多源域适应方法是当前主流方法,可以使用不同的距离度量标准来量化不同分布之间的差异;基于对抗的多源域适应方法能够准确对应多个源域和目标域间的关系,并据此进行分布对齐,取得了良好的迁移效果;基于样本生成的多源域适应方法更加注重样本本身的细粒度特征,通过生成有标记的样本实现有监督的域适应;基于模型的多源域适应方法充分利用深度网络模型提取高级特征的能力和优势,从结构上解决多个源域与目标域分布对齐的问题。
3 相关数据集和评测
本节首先对多源域适应常用公开数据集进行介绍,随后展示具有代表性的多源域适应方法在数据集上的性能。
3.1 数据集
本小节使用的公开数据集有:Digits-five[24],DomainNet[15]和Office-31[24]。
3.1.1 Digits-five
Digits-five由五位数据集组成:MNIST (mt),MNIST-M (mm), USPS (up), SVHN (sv),Synthetic Digits (sy)。每个域中有10个类,对应0至9的数字。实验时,训练集包括MNIST,MINST-M,SVHN和Synthetic Digits中25 000张图像,测试集采集9 000张图像。因为USPS数据集总共只包含9 298张图像,所以将整个USPS数据集作为一个域。
3.1.2 DomainNet
DomainNet是六个不同领域的公共对象的数据集,在首次引入后就已成为MSDA中最具挑战性的数据集。所有领域包括345类物品,大约60万张图片,如手镯、飞机、鸟和大提琴。这些域包括Clipart (clp):剪贴画图像的集合;Real(rel):照片和真实世界的图像;Sketch(skt):特定物体的草图;Infograph(inf):带有特定对象的信息图图像;Painting(pnt):以绘画的形式对物体进行艺术描绘;Quickdraw(qdr):以绘画和快速绘制的形式对物体进行艺术描绘。
3.1.3 Office-31
Office-31包含三个领域的31个对象类别:Amazon(A)、DSLR(D)和Webcam(W)。Amazon(A)域的样本来自线上商家的网站,平均每个类包含90张图像,总共包含2 817张图像;DSLR(D)包含498张低噪声高分辨率图像(4 288×2 848);Webcam(W)显示低分辨率的795张图像(640×480)。
3.2 多源域适应方法的实验结果
本小节在上述数据集上对具有代表性的多源域适应方法的识别性能进行分析,表1~3中实验数据来自于原论文。
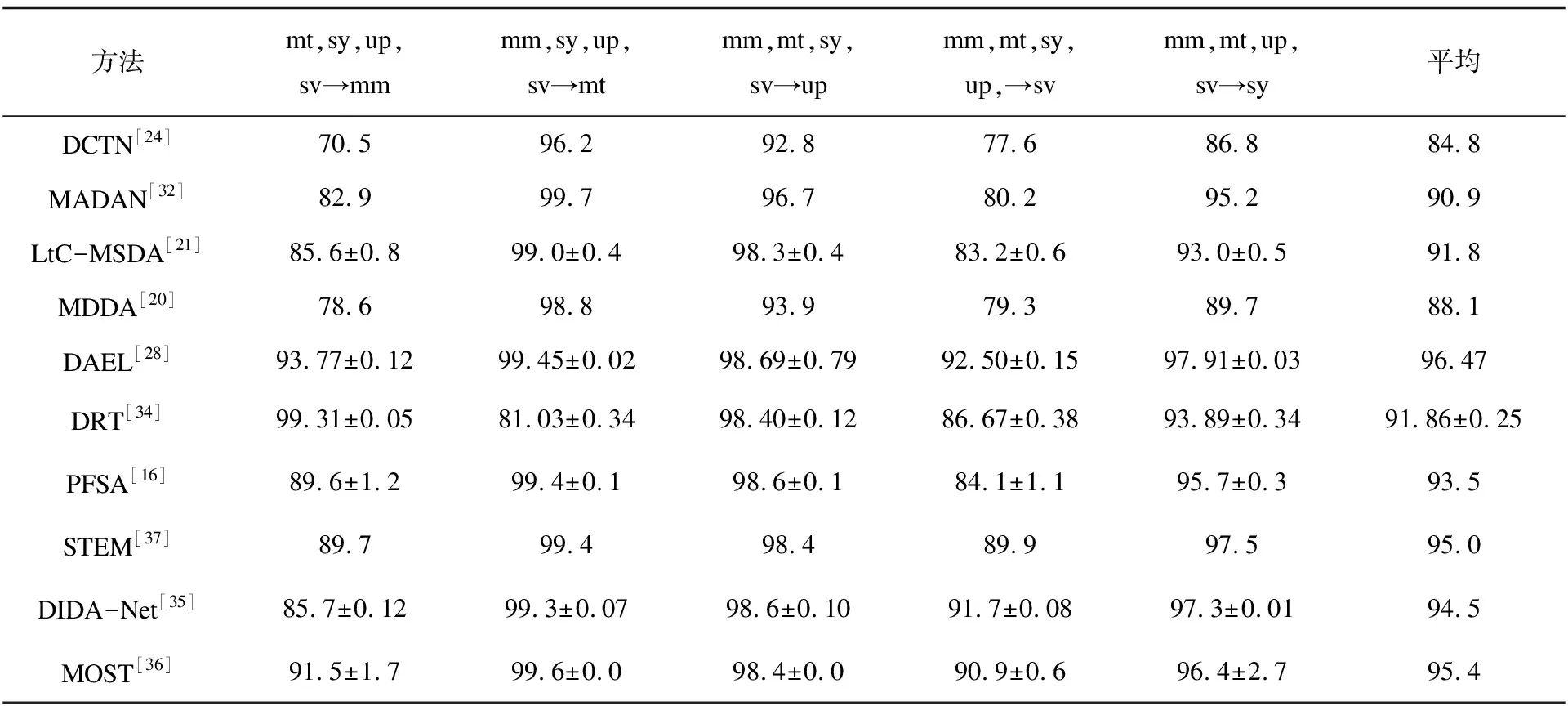
表1 在Digits-five上各多源域适应方法的准确率 %
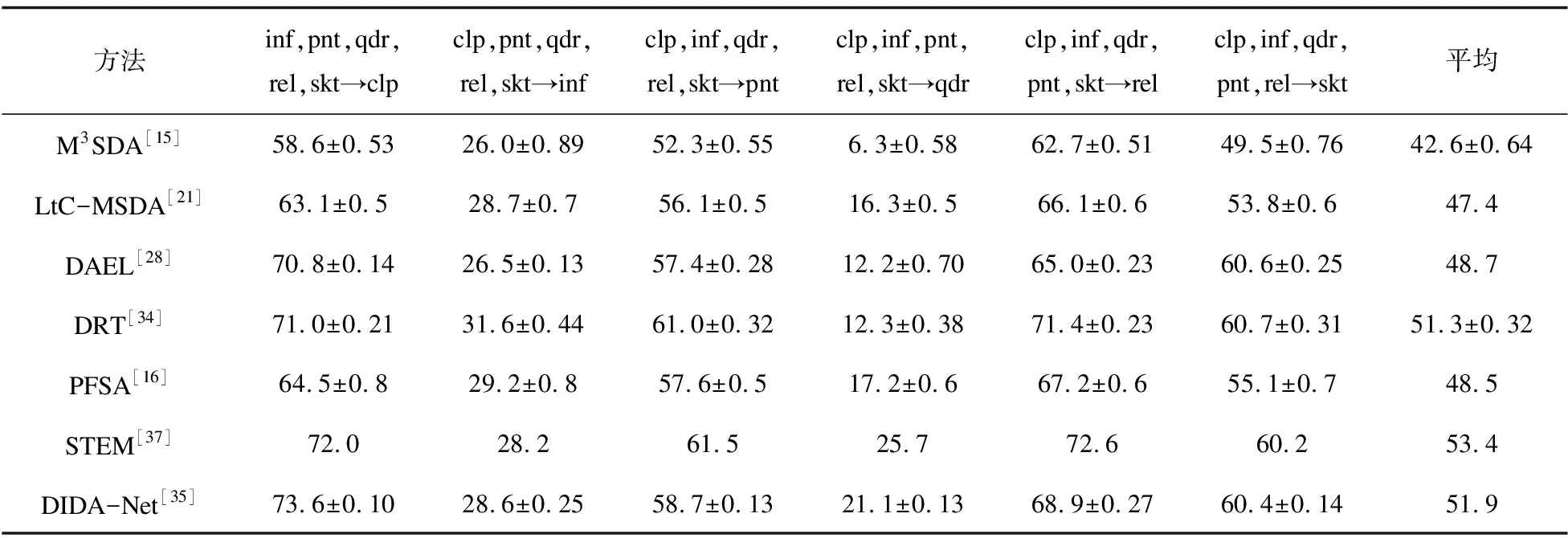
表2 在DomainNet上不同多源域适应方法的准确率 %
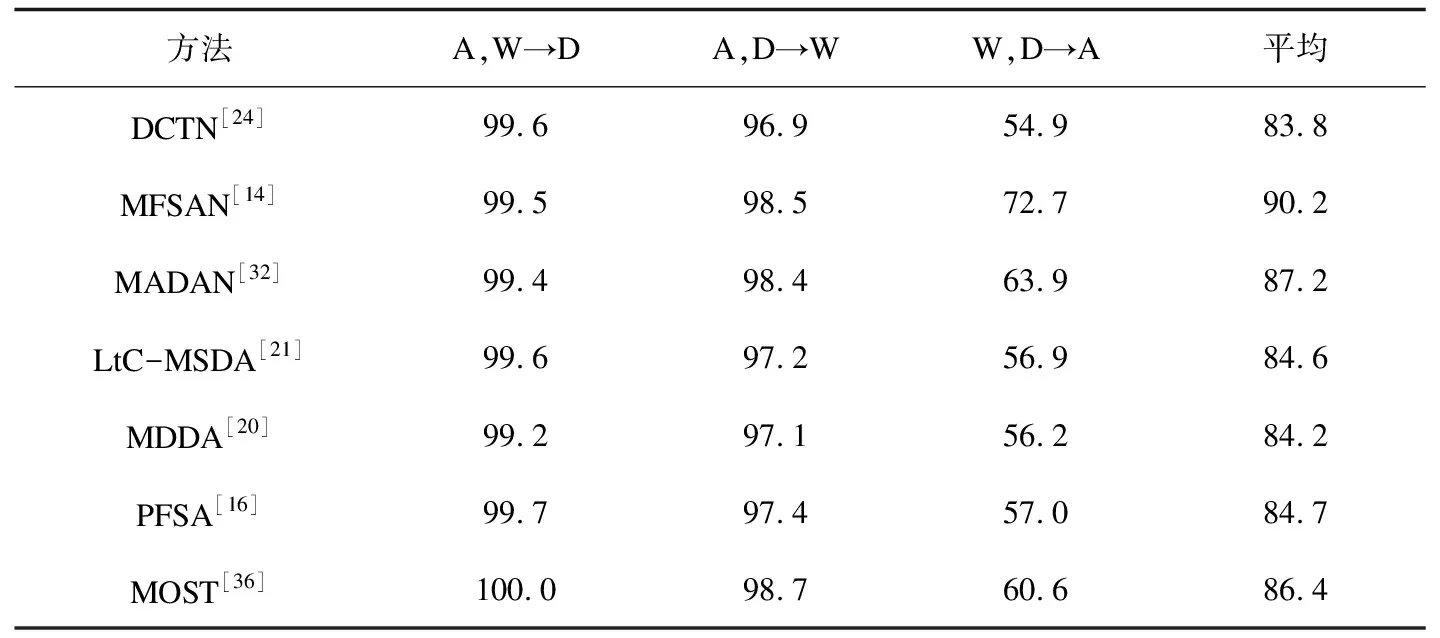
表3 在Office-31上各多源域适应方法的准确率 %
4 多源域适应的相关应用
多源域适应方法具有极为广泛的应用价值,因此研究多源域适应问题具有十分重要的现实意义。
4.1 计算机视觉
当前的多源域适应方法在计算机视觉(Computer Vision)领域应用较为成熟,不仅应用在图像分类任务中,还可以应用在目标检测(Object Detection)、语义分割(Semantic Segmentation)、人脸识别(Face Recognition)和行人再识别(Person Re-Identification)等任务中。第2节所述方法均可以用来对图像进行识别和分类。文献[8]率先将多源域适应方法应用到目标检测任务中,针对不同层次特征信息不同的特点,提出了分层特征对齐的方法。文献[30]结合语义分割任务特性,研究了不同域的图像在语义上的相似性。
4.2 自然语言处理
多源域适应方法可以有效解决自然语言处理(Natural Language Processing,NLP)中存在大量数据不足和训练样本、测试样本特征分布不一致的问题,取得了较好的效果。文献[20]基于NPL中的文本分类(Text Classification)任务,探索了不同距离对域之间相似性的影响。文献[31]研究了面向视觉情感分类(Visual Sentiment Classification)的多源域适应问题,使用基于对抗的方法,将多个源域和目标域映射到一个统一的情感潜在空间,解决了单源域情感信息有限的问题。
4.3 其他领域
除上述领域外,多源域适应方法以其能够解决多种不同数据之间的差异和显著提升模型泛化性的优势,广泛应用在工业制造领域的工业质量监控、设备故障检测等任务中,还可以应用在金融领域风险评估、信用评估等任务中。
5 现存挑战及未来研究方向
当前研究多源域适应的背景约束性较强,多数仍是在源域和目标域样本量充足、源域与目标域标签空间已知且一致的条件下,复杂情况下的多源域适应方法值得深入研究。
5.1 部分多源域适应
在当今大数据时代,收集并标注的数据越来越多,不仅存在源域样本处于多种特征空间的情况,而且会导致源域样本的类别大大增加,此时目标域的标签空间可能是源域标签空间的子集。在此背景下,研究部分多源域适应(Partial Multi-Source Domain Adaption)问题尤为必要。
5.2 开集多源域适应
与上述部分多源域适应的背景相似,虽然获取到源域样本具有很多类别,但与目标域样本分布相似的类别很少,这就会导致多个源域的样本空间可能是目标域样本空间的子集,即目标域中会存在源域中未知的私有类别,此类问题称为开集多源域适应(Open-Set Multi-Source Domain Adaptation)。
5.3 域泛化
域泛化(Domain Generalization,DG)是近几年非常热门的研究方向。域适应问题假设是有多个源域和目标域均可访问,而域泛化是指目标域未知的,只有可用来训练的源域数据。域泛化是对域适应的进一步扩展和深入,更具有挑战性和实用性,但难度也大大增加,这就要求模型具有极强的泛化性能。
6 结束语
多源域适应主要研究源域样本来源并不唯一且多个源域样本之间特征分布存在差异的问题。该文结合多源域适应问题产生的背景,阐述其研究现状,从迁移方式不同的角度对多源域适应方法进行分类,并归纳其中的代表性研究成果。最后,对多源域适应发展中面临的主要问题进行描述分析和说明,对下阶段的研究方向进行了展望和预测。
猜你喜欢
计算机技术与发展(2020年11期)2020-12-04
小学生导刊(2018年34期)2018-12-18
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
山东青年(2016年3期)2016-02-28
电子与信息学报(2015年12期)2015-08-17
母子健康(2015年1期)2015-02-28
电测与仪表(2014年15期)2014-04-04
延河(下半月)(2014年3期)2014-02-28
