
面向方面级情感分析的双通道图卷积网络
2024-03-25 02:04:56黎茂锋陈立伟
计算机技术与发展 2024年3期
刘 洋,黎茂锋,黄 俊,陈立伟
(西南科技大学 计算机科学与技术学院,四川 绵阳 621010)
0 引 言
在web2.0的时代背景下,互联网用户能够通过社交媒体浏览并发布大量带有情感极性的文本信息,所以,意见挖掘、情感分析[1]逐渐成为热门研究话题。而方面级情感分析(ABSA)是一种更加细粒度的情感分析任务,它能够对文本具体的方面实体所携带的情感极性进行预测,而不是简单地预测整条文本的情感极性。以“The food is good, but the service is terrible.”为例,food和 service是文本的两个方面项,两者的意见项分别是good和terrible,ABSA任务的目标就是识别出两个方面项的情感极性分别是积极和消极。
ABSA任务关键在于建立方面项与意见项之间的联系,以此来引导方面项感知情感信息。近年来,以句法依赖为基础的图神经网络在ABSA任务上取得了显著成果。然而,这些方法[2-3]忽略了上下文语义信息和单词自身所携带的情感信息对建立方面项与意见项联系的作用。而自注意力机制能有效地捕获上下文的语义相关性。受此启发,该文利用多头自注意力机制增强句法依赖图,设计了一个具有上下文语义信息的句法依赖图(SrG);整合SenticNet词典中单词的情感信息构建文本情感依赖图(SeG);最后,基于SrG和SeG两个图构建了一种双通道图卷积网络(DC-GCN),以同时利用文本的语义相关性和单词自身的情感信息引导方面项感知情感信息,并将融合双通道图卷积网络特征用于情感分类。为了验证模型的有效性,在四个公开数据集(Twitter,Rest14,Lap14和Rest16)上与多个较优的经典模型以及最新模型进行对比,实验结果表明,提出的模型取得了更好的效果。
1 相关工作
方面级情感分析(ABSA)概念由Thet等人[4]在2010年明确提出,至今已有十多年的应用与发展。早期,受限于硬件条件,大多数研究采用传统机器学习结合特征工程的方法建模方面级情感分析任务。比如在最大熵、支持向量机等经典机器学习模型的基础上结合情感词典、依赖信息等对情感进行分类[5],这些方法需要投入较大的人力成本和时间成本。而随着技术的逐渐成熟与发展,各种硬件设施越来越先进,依托于先进的设备,深度学习得到了良好的应用环境,大大降低了ABSA研究的人力成本与时间成本,所以深度学习渐渐代替了传统机器学习在方面级情感分析的研究地位。
循环神经网络(Recurrent Neural Network,RNN)对序列信息有良好记忆功能,所以其对文本这种具有序列特征的信息具有良好的建模性能。长短时记忆网络(Long Short Term Memory,LSTM)和门控神经网络(Gated Recurrent Units,GRU)在传统RNN的基础上融入门控基础,提高了网络对上下文数据的记忆性能,从而改善了传统RNN存在的梯度爆炸和梯度弥散等问题。Tang等人[6]提出了两个改进模型(TD-LSTM和TC-LSTM)用于ABSA任务,整合了方面项与上下文知识,比直接使用LSTM对文本进行建模取得了更好的效果。注意力机制能根据文本的特征计算得到上下文的语义相关性[7],所以,研究人员结合注意力机制和LSTM网络在ABSA任务上开展了大量研究。Wang等人[8]基于方面项的词嵌入和注意力机制构建了ATAE-LSTM模型,在ABSA任务上取得了良好的成果。Tan等人[9]针对文本中具有冲突意见的意见项,提出了一种双重注意力网络,以识别文本中方面项的冲突情感。另外,Devlin等人[10]提出的基于注意力机制的BERT预训练模型也一度刷新了NLP领域的各大任务成果。Sun等人[11]提出构造辅助句的方式微调BERT模型,从句子对分类的角度考虑ABSA任务,取得了良好的效果;Xu等人[12]针对ABSA任务提出了一种基于BERT的后训练微调方式,提升了BERT预训练模型在微调ABSA任务上的性能。虽然以上方法使用循环神经网络对上下文序列信息建模,并结合注意力机制在ABSA任务上取得了良好效果,但是这些方法不能学习到文本的外部结构信息。
而利用文本的句法依赖知识有助于在方面项和文本上下文单词之间建立联系。遵循这一思路,基于句法依赖知识的图神经网络(Graph Convolutional Networks,GCN)被广泛应用于ABSA任务。Lu等人[13]设计了一种星形图,并提出基于节点和基于文档的分类方法,在情感分析上取得了良好效果;Zhang等人[14]提出ASGCN模型,首次使用文本句法依赖构建图卷积神经网络并将其用于ABSA任务;Liang等人[15]提出一种依赖关系嵌入式图卷积网络(DREGCN),并且设计了一个简单有效的消息传递机制,以充分利用语法知识和上下文语义知识,在ABSA任务上取得了良好的效果;Pang等人[16]基于句法依赖树和多头注意力机制分别生成句法依赖图和语义图,构建了动态多通道图卷积网络(DM-GCN)来有效地从生成的图中学习相关信息;Tang等人[17]利用依赖关系标签构建了一个潜在的文本依赖图,并设计了一个情感细化策略引导网络捕捉方面项的情感线索;Liang等人[18]通过整合SenticNet词典的情感信息来增强句子的句法依赖,在ABSA任务上取得了良好效果;Li等人[19]提出一种双图卷积神经网络同时对语法知识和语义知识进行学习,并提出了正交正则化器和差分正则化器鼓励句法知识和语义知识相互感知学习;Xing等人[20]提出了DigNet模型,设计了一种局部全局交互图,将句法图和语义图结合在一起,实现两个图中有益知识的相互交换。赵振等人[21]提出基于关系交互的图注意力网络模型,将关系特征融入到注意力机制中,使用一个新的扩展注意力来引导信息从方面项的句法上下文传播到方面项本身;阳影等人[22]在句法依赖树上融合情感知识,并与文本的语义相关性进行有效交互,提出SKDGCN双通道GCN模型,在多个公开数据集上表现优异;杨春霞等人[23]提出基于注意力与双通道的模型TCCM,实现了通道内信息的残差互补,有效结合了句法与语义关联信息。以上基于图卷积网络的方法使用句法依赖、情感知识增强句法依赖来聚合文本的句法结构特征;使用注意力得分矩阵、句法解析标签聚合文本的上下文特征,这些方法在ABSA任务上取得了良好的效果。
而文中方法通过将上下文语义信息与句法依赖进行结合,从而将上下文语义信息融进句法依赖中,以此来引导方面项聚合具有上下文语义性的句法信息;并且使用文本自身的情感知识来引导方面项聚合上下文的情感信息;最后使用双通道的图卷积神经网络将具有上下文语义性的句法信息和上下文情感信息进行融合,用于最终的情感分类。
2 模 型
该文提出一种融合具有上下文语义信息的句法依赖知识和文本情感知识的双通道图卷积网络模型(DC-GCN),如图1所示。该模型主要由以下三个模块构成:(1)词嵌入与BiLSTM模块;(2)具有上下文语义信息的句法依赖图(SrG),整合SenticNet词典情感信息构建的一个文本情感依赖图(SeG)构造模块;(3)双通道图卷积网络(DC-GCN)特征融合与情感分类模块。
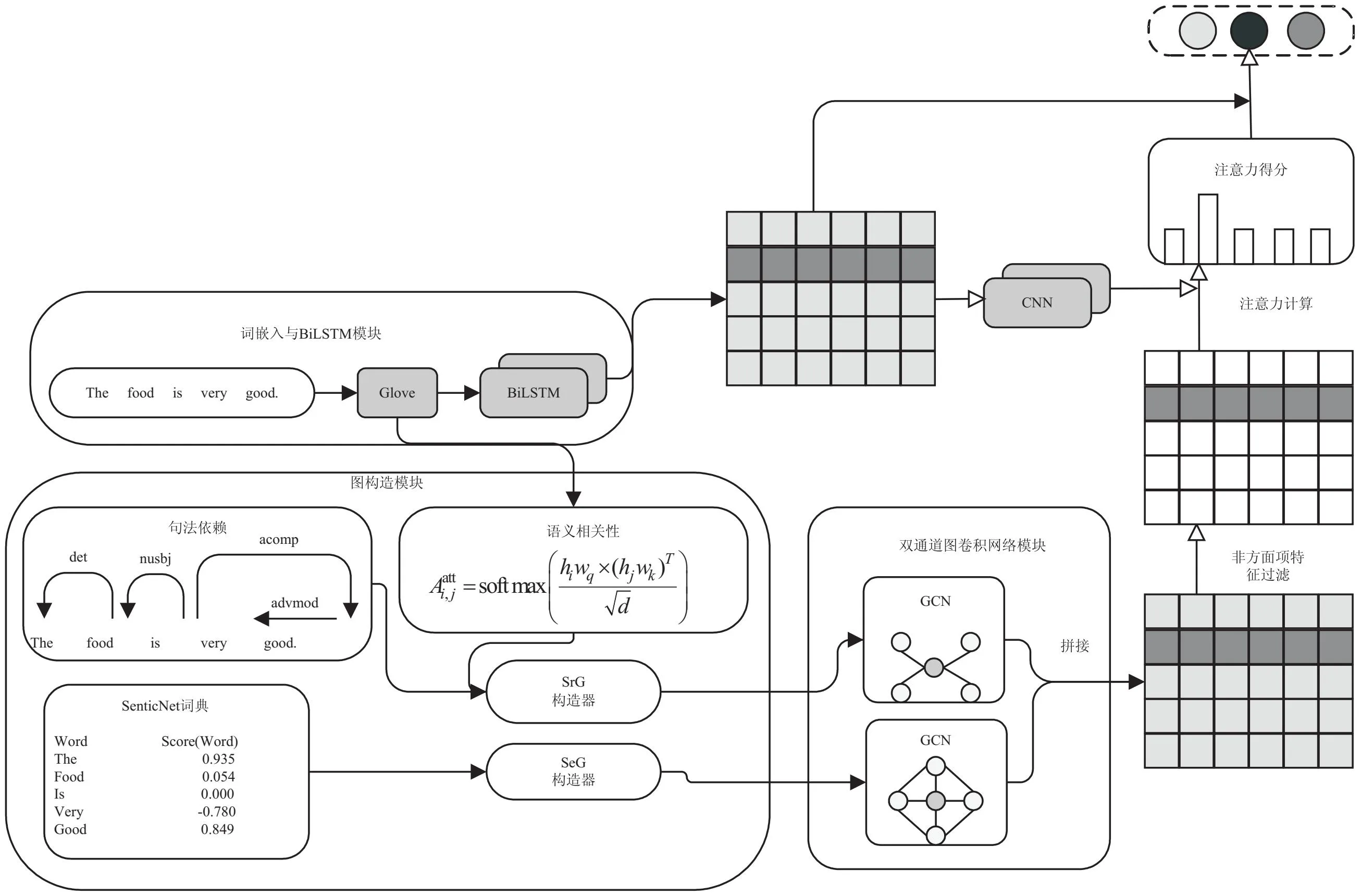
图1 DC-GCN模型
2.1 词嵌入与BiLSTM
使用Glove将文本S={w1,w2,…,wn}的每个单词都映射成一个三百维的词向量,然后使用BiLSTM中对其进行训练,生成了包含丰富上下文信息的文本词向量矩阵E={e1,e2,…,en}。
2.2 图构造模块
2.2.1 具有上下文语义信息的句法依赖图(SrG)构造
首先,使用Spacy依赖解析器提取文本的句法依赖树,以文本“The food is very good.”为例,将有向句法依赖转换成无向句法依赖,并考虑单词的自循环,示例如图2所示。

图2 有向句法依赖(左)与无向句法依赖(右)
(1)
其中,i,j分别表示某一天评论数据中的第i,j个单词。
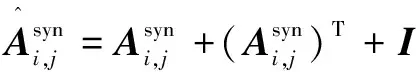
(2)
(3)
其中,hi和hj分别表示数据本经过BiLSTM层的第i和第j个单词的词向量,wq和wk是两个可训练的参数矩阵,d表示词向量的维度。
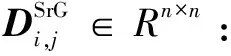
(4)
2.2.2 整合SenticNet词典情感信息构建的一个文本情感依赖图(SeG)构造
该文基于SenticNet词典构建了潜在的文本情感依赖图(SeG),其中SenticNet词典是由单词及其单词的情感得分组成,示例如表1所示。

表1 SentiNet词典示例
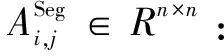
(5)
另外,为了使网络对方面项的关注度增加,增大了方面项的情感得分:
(6)
(7)
2.3 双通道图卷积模块
2.3.1 特征提取
该文基于SrG和SeG两个文本依赖图构建了双通道的图卷积神经网络,以同时利用文本上下文单词的语义相关性和单词自身的情感信息来提取增强后的句法特征和情感知识特征。
(8)
(9)
(10)
(11)
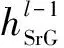
2.3.2 特征融合
首先使用拼接的方式,将双通道图卷积网络输出的文本特征进行融合:
(12)
再使用平均池化提取特征的重要信息并对特征进行降维:
(13)
2.4 非方面项特征过滤
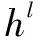
(14)
(15)
2.5 获取文本最终特征表示
2.5.1 方面项局部特征提取
使用卷积神经网络提取方面项的具局部特征,并过滤掉文本中非方面项特征,实现的方法如下:
(16)
(17)
(18)
2.5.2 方面项权重计算
首先运用双通道图卷积网络输出的方面项特征和卷积神经网络输出的方面项特征进行计算,并在特征维度上做加法,得到最终方面项及非方面项的权重:
(19)
(20)
2.5.3 最终特征表示
最后将特征权重反馈到BiLSTM中,使得富含多种依赖信息的方面项特征感知到上下文的情感信息,以获取最终的文本特征表示:
(21)
其中,ei是BiLSTM输出的文本第i个单词的向量表示。
2.6 情感分类
在获取到文本的最终特征表示后,将其馈送进一个全连接层并使用softmax进行归一化,得到情感极性的概率分布p∈R(dp×2dh):
p=softmax(Wpr+bp)
(22)
其中,dp是情感类别的维度,dh是向量的维度,Wp和bp分别是一个可训练的参数矩阵和偏置。
文中模型选择具有交叉熵损失和L2正则化的标准梯度下降算法进行训练:
(23)
其中,D表示数据集,t表示标签,pt表示标签t的概率,θ表示所有可以训练的参数,λ表示L2正则化的系数。
3 实 验
3.1 数据集与实验环境
3.1.1 实验数据集
在四个公开的数据集上进行了实验,Twitter数据集是从Twitter上收集整理的一些评论数据;Rest14数据集和Lap14数据集来自于SemEval-2014方面级情感分析大赛;Rest16数据集是SenEval-2016方面级情感分析大赛提供的公开数据集。每个数据集都提供了方面项及其相应的情感极性,数据集详细统计如表2所示。
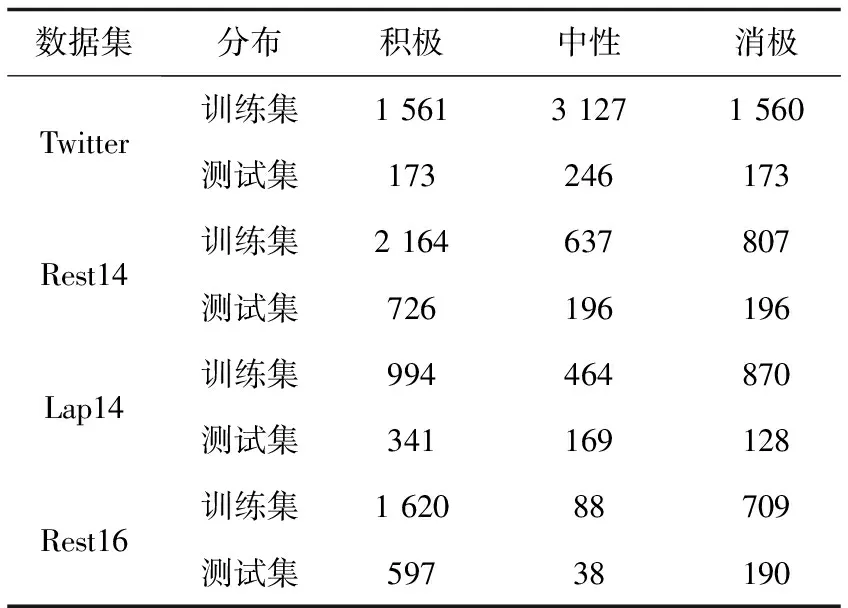
表2 数据集
3.1.2 实验环境
实验环境如表3所示。

表3 实验环境
3.1.3 实验评价指标
为了便于与对比模型作比较,以体现文中模型的有效性,选择ABSA任务模型性能的通用评价指标─准确率Acc和Macro-F1,两者的计算过程如下所示:
(24)
(25)
(26)
(27)
(28)
其中,TP表示成功预测的正样本数,FP表示错误预测的负样本数,FN是错误预测的正样本数,TN表示成功预测的负样本数,P为精确率,R是召回率,F1为精确率与召回率的调和平均,C是情感类别数,F1υ为第υ个类别的F1值。
3.2 基线模型及结果分析
ATAE-LSTM[8]:利用方面嵌入和注意力机制进行方面级情感分类。
IAN[24]:在BiLSTM的基础上利用交互注意力机制,实现方面项与上下文信息的交互。
RAM[25]:使用多层注意力和记忆网络学习句子表达,用于方面级情感分析。
MGAN[26]:结合粗粒度和细粒度的注意力机制,设计了一个方面对齐损失实现不同方面项与上下文之间的词级交互。
TNet[27]:将BiLSTM词嵌入转换为特定方面项嵌入,并用CNN提取用于分类的特征。
ASGCN[14]:首次提出基于句法依赖树的图卷积神经网络用于方面项情感分析。
CDT[28]:利用基于句法依赖树的GCN来学习文本特征。
BiGCN[29]:提出基于词共现信息和句法依赖树的层次图卷积网络。
kumaGCN[30]:使用潜在的图结构信息来补充句法特征。
CPA-SA[31]:设计了两个不对称的上下文权重函数来调整方面项特征的权重。
IAGCN[32]:使用BiLSTM和修正动态权重对上下文进行建模,GCN对句法信息编码,再利用交互注意力机制学习上下文和方面项的注意力,将上下文信息和方面项进行重构。
该文选取的对比模型涵盖了方面级情感分析从2016年到2022年期间在方面级情感分析上取得良好效果的经典模型以及最新的模型。对比实验结果如表4所示。
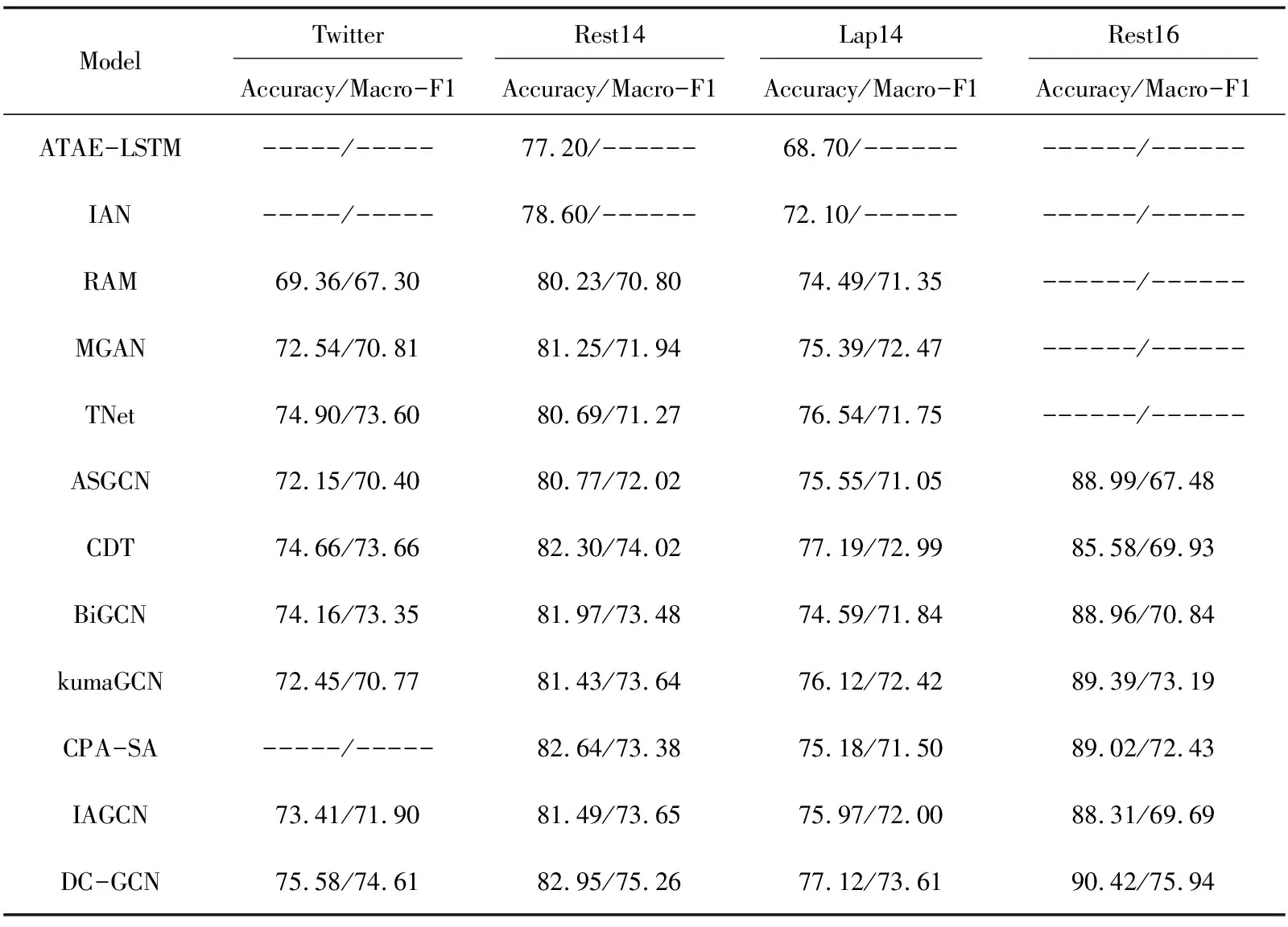
表4 对比实验结果 %
分析表4结果发现,与基线模型中取得最好效果的模型作对比,总体上文中模型取得了更优的效果,在四个公开数据集(Twitter,Rest14,Lap14和Rest16)上Macro-F1分别比对比模型中最好的结果高出0.95百分点、1.24百分点、0.62百分点、2.75百分点;在Twitter,Rest14,Rest16上Accuracy分别比对比模型中最好的结果高出0.68百分点、0.31百分点、1.03百分点,但是在Lap14上Accuracy比CDT模型低0.07。对比了Lap14和Twitter,Rest14,Rest16的差别,发现Lap14中的数据对方面项隐式表达情感的样本相较于其他三个数据集占比更高,这会导致模型更难根据文本依赖图引导方面项感知上下文情感信息,从而影响模型的性能。
另外,在训练过程中,文中模型在BiLSTM和GCN网络中均使用正则化来防止模型出现过拟合现象。为探究不同的正则化系数对实验结果的影响,以Lap14为例,设置了5组正则化系数(在BiLSTM和GCN的正则化系数分别为0.7与0.4,0.7与0.5,0.7与0.6,0.6与0.5,0.8与0.5)展开对比实验,结果如图3所示。

图3 不同正则化系数下的模型效果
图3中横坐标B_0.7/G_0.4表示BiLSTM和GCN中的正则化参数分别设置为0.7和0.4,其余四个横坐标的含义以此类推;纵坐标表示准确率和F1值;经图3可知,正则化参数对模型最终的性能有影响,在BiLSTM和GCN网络中的正则化参数选择取得最好效果的0.7和0.5。
3.3 消融实验
为验证具有上下文语义信息的句法依赖图、基于情感知识构建的文本情感依赖图对提升模型性能的有效性,以及使用CNN提取方面项局部特征对更新方面项权重的有效性,在保持参数一致的情况下开展消融实验,结果如表5所示。

表5 消融实验结果 %
DC-GCN:表示该文提出的完整的模型,使用了具有上下文语义信息的句法依赖图(SrG)、情感知识构建的文本情感依赖图,并使用CNN提取的方面项局部特征用于更新方面项权重。
DC-GCN w/o SrG:表示在完整的模型中移除了具有上下文语义信息的句法依赖图(SrG)。
DC-GCN w/o SeG:表示在完整的模型中移除了基于情感知识构建的潜在的文本依赖图(SeG)。
DC-GCN (SrG w/o Att):表示不使用自注意力机制对文本的句法依赖进行增强。
DC-GCN w/o CNN:表示在计算方面项权重的过程中不使用CNN提取方面项的局部特征参与方面项权重更新过程。
根据表5中消融实验的结果证明:在移除具有上下文语义信息的SrG、移除基于情感知识构建的SeG、移除SrG中的上下文信息、不使用CNN提取方面项的局部特征参与方面项权重更新过程,均会导致模型性能的下降。由此证明了所提方法在方面级情感分析上的有效性。
4 结束语
设计了具有上下文相关性的SrG和SeG,并基于两个图构建了一个双通道的图卷积神经网络(DC-GCN),实现了对文本特征的优化以及多种文本特征的有效融合,提升了模型在ABSA任务上的性能。通过大量实验证明该方法相比于基线模型有更好的效果。
虽然提出的模型在ABSA任务上取得了不错的效果,但模型仍有进一步改进的空间。一方面,可以设计更有效的特征融合方法以提升模型的性能;另一方面,需要将模型扩展到更多的数据集上进行训练,以增强模型的鲁棒性。
猜你喜欢
中华诗词(2021年3期)2021-12-31 08:07:22
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
大连民族大学学报(2021年2期)2021-07-16 05:41:42
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
中华诗词(2018年3期)2018-08-01 06:40:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中华诗词(2018年11期)2018-03-26 06:41:32
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
