
基于RoBERTa-Effg-Adv的实体关系联合抽取方法
2024-03-25 02:11姚飞杨刘晓静
计算机技术与发展 2024年3期
姚飞杨,刘晓静
(青海大学 计算机技术与应用系,青海 西宁 810016)
0 引 言
实体关系抽取是自然语言处理领域中一项重要的基础任务,其目的是从结构化、半结构化和非结构化数据中抽取形如<主体,关系,客体>的实体关系三元组。实体关系抽取任务是知识图谱构建、智能推荐、问答系统等众多自然语言处理任务的重要基础工具[1]。因此,实体关系抽取任务准确度的高低决定了自然语言处理领域下游任务效果的好坏。
实体关系抽取以流水线方法和联合抽取方法这两类方法为主[2]。流水线方法将实体关系抽取分为命名实体识别和关系抽取这两个独立的任务,先对实体进行识别,再对实体之间的关系进行抽取[3]。流水线方法中每个独立的子任务都依赖前一个任务的结果作为当前任务的输入,这种方法存在着曝光偏差和误差传播等问题[4]。与流水线方法相比,联合抽取方法把三元组抽取看成一个整体任务,可以进一步利用两个任务之间存在的潜在信息,从而获得更好的抽取效果[5]。因此,联合抽取方法成为了当前实体关系抽取领域研究的主流方法。
虽然上述方法在中文实体关系抽取领域取得了较好的效果,但由于中文语言本身的特点,存在嵌套实体的问题,给实体之间的关系抽取带来了挑战。为了更好地获取文本的上下文语义信息,同时更好地提取嵌套实体之间的关系信息,该文提出了RoBERTa-Effg-Adv的实体关系联合抽取模型。与传统关系三元组抽取方式不同,该模型采用实体关系五元组抽取思想,将关系抽取任务分为主客体识别,头关系抽取和尾关系抽取,模型使用多头识别嵌套实体的方式,可有效抽取中文文本中重叠三元组。模型结合PGD(Projected Gradient Descent)[6]对抗训练算法,有效提升了模型的抗扰动能力。
该文是在中文领域中进行的实体关系联合抽取研究,聚焦瞿昙寺壁画中涉及到的宗教领域中的命名实体识别与实体关系抽取。面向瞿昙寺壁画领域的实体关系联合抽取研究是瞿昙寺壁画知识图谱的建立和基于瞿昙寺壁画知识图谱的智能问答系统研究的基础任务。
主要贡献如下:
(1)通过对专业书籍扫描和手工标注数据等方式构建了瞿昙寺壁画领域的实体关系联合抽取数据集。
(2)在自制的数据集和公开的数据集上的实验证明,RoBERTa-Effg-Adv模型通过多头识别嵌套实体,并将关系三元组拆分成五元组抽取,通过对抗训练提升模型鲁棒性,在精确率、召回率和F1值指标上表现较佳,验证了模型的有效性。
1 相关工作
近年来,深度学习的发展推动了关系抽取方法的不断进步,基于深度学习的实体识别和关系抽取已成为主流研究手段[7]。早期,实体关系抽取以流水线的方式为主,即在命名实体识别已完成的基础上再进行实体之间关系的抽取任务。
Socher等人[8]在2012年将循环神经网络(RNN)应用到实体关系抽取领域中的关系分类,该方法利用循环神经网络对语句进行句法解析,经过不断迭代,从而得到句子的向量表示。这种方法有效地考虑了句子的句法结构。除RNN关系分类的方法外,Zeng等人[9]在2014年将卷积神经网络(CNN)应用到关系抽取领域,利用卷积深度神经网络(CDNN)来提取文本语义特征。由于传统的RNN无法处理长期依赖,以及存在梯度消失、梯度爆炸等问题,Yan等人[10]在2015年提出了基于长短时记忆网络(LSTM)的句法依存分析树的最短路径方法进行关系抽取研究。
流水线式的实体关系抽取方法中每个独立的任务的输入依赖于前一个任务的输出,因此存在任务之间丢失信息,忽视了两个子任务之间存在的关系信息[11],也可能会产生冗余信息等这些由误差传播引起的问题。实体关系联合抽取方式可以有效利用两个任务之间的潜在信息,同时也避免误差传递等问题。Wei等人[12]在2019年提出一种基于联合解码的实体关系抽取模型CasRel。CasRel是层叠指针网络结构,由编码端和解码端组成。编码端使用BERT[13]模型对输入数据进行编码,所获取的字向量能够利用词与词之间的相互关系有效提取文本中的特征;解码端主要包括头实体识别层、关系与尾实体联合识别层。该模型会先对头实体进行识别,然后在给定关系种类的条件下对尾实体进行识别。CasRel模型存在曝光偏差问题。Wang等人[14]在2020年提出一种单阶段联合提取模型TPLinker,该模型解决了曝光偏差和嵌套命名实体识别问题。与CasRel模型不同,TPLinker模型用同一个解码器对实体和关系进行解码,同时对实体和关系进行抽取,保证了训练和预测的一致性。苏剑林在2022年提出基于GlobalPointer[15]的实体关系联合抽取模型GPLinker。GPLinker模型将实体关系三元组抽取转变为实体关系五元组(Sh,St,P,Oh,Ot)抽取,其中,Sh,St表示主实体的头和尾,P表示关系,Oh,Ot表示尾实体的头和尾。与TPLinker模型相比,GPLinker模型计算速度更快,而且显存占用更少。饶东宁等人[16]在2023年提出一种基于Schema增强的中文实体关系抽取方法。该方法采用字词混合嵌入的方式融合字与词的语义信息来避免中文分词时边界切分出错所造成的歧义问题,并利用指针标注的方式解决关系重叠问题。该方法通过提取出每个数据集的Schema进行合并作为先验特征传入模型中,以解决实体冗余及关系种类迁移问题[16]。
2 数据集的制作
本研究制作了瞿昙寺壁画领域的实体关系联合抽取数据集REDQTTM(Relation Extraction Dataset of Qu Tan Temple Murals)。REDQTTM原始数据文本来自研究瞿昙寺壁画的相关专业书籍,对这些书籍进行扫描,并进行光学字符识别(Optical Character Recognition,OCR),从而获得机器可读的语料库。之后,按照预定义的实体和关系种类,使用标注工具对这些文本进行人工标注。标注工具选择BRAT(Brat Rapid Annotation Tool)[17],BRAT是基于Linux的一款应用于WebServer端的文本标注工具。通过对文本进行手工标注,最终得到后缀名为ann的标注文件。
实体在ann文件的格式由5列组成,第一列表示实体的编号,第二列表示实体的预定义类别,第三列表示实体在文本的开始下标,第四列表示实体在文本的结束下标,最后一列表示该实体所对应的文本。关系在ann文件的格式由4列组成,第一列表示关系的编号,第二列表示关系的预定义类别,第三列表示Subject实体的实体编号,最后一列表示Object实体的实体编号。
REDQTTM总共包含了18种实体类型。瞿昙寺壁画中的神像体系主要有以下类别,分别是佛像、菩萨像、祖师像(或称上师、尊者)、本尊像、护法神像和佛母像[18]。这些神像体系都包含在REDQTTM的实体类别中。瞿昙寺壁画对神像的刻画十分详细,包括对神像的法器、服饰、坐骑、台座等细节展示,这些在REDQTTM中都有对应的实体种类。表1给出了REDQTTM中部分预定义的实体种类。

表1 部分实体类型和举例
REDQTTM中包含11种关系类型。表2给出了REDQTTM中预定义的关系种类。
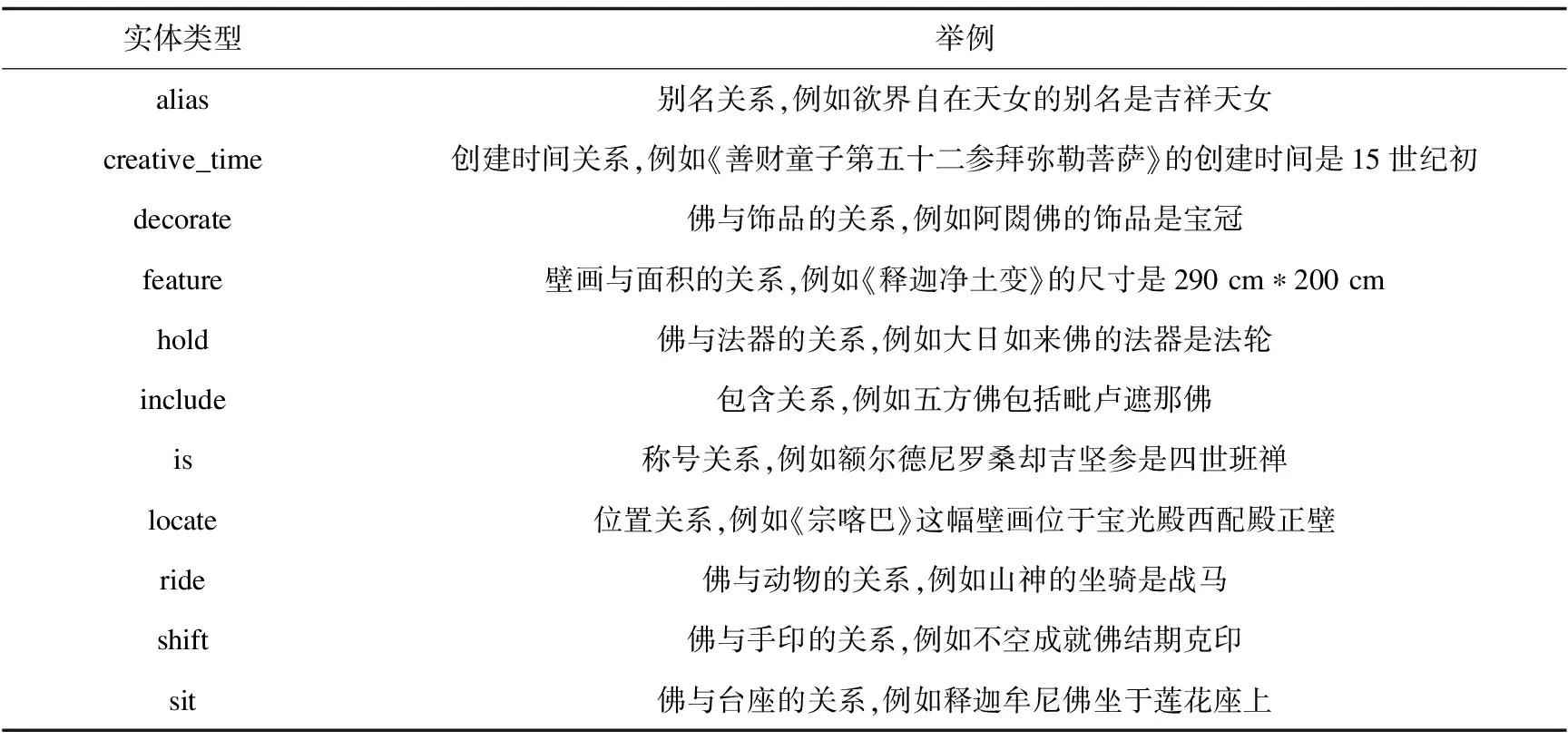
表2 关系类型和举例
通过对ann文件进行解析,最终得到本研究所需的数据集REDQTTM。REDQTTM分为训练集和测试集,三元组的比例为8∶2左右。如表3所示,REDQTTM同样采用json格式,text字段表示输入文本,predicate字段表示关系类型,object_type字段表示object实体类型,subject_type字段表示subject实体类型,object字段表示object实体,subject字段表示subject实体。

表3 A sample data in REDQTTM dataset
3 模 型
3.1 模型整体结构
该文提出的RoBERTa-Effg-Adv模型包括4个部分:RoBERTa-wwm-ext[19]编码层,Efficient GlobalPointer[15]命名实体识别模块,关系抽取模块和对抗训练。模型整体结构如图1所示,RoBERTa-wwm-ext编码层负责将输入的文本转化为词向量,作为模型后续部分的输入。在实体识别方面,使用Efficient GlobalPointer对主体和客体进行抽取。在关系抽取方面,将关系实体三元组拆分成五元组来处理,利用Efficient GlobalPointer处理S(sh,oh|p),其中sh表示主实体的头,oh表示尾实体的头,p表示关系。对于嵌套命名实体识别,需要同时指定起点和结束位置。同理利用Efficient GlobalPointer处理S(st,ot|p),其中st表示主实体的尾,ot表示尾实体的尾。模型引入对抗训练来提升模型性能,对抗训练算法使用PGD对抗训练策略,该对抗训练算法采用“小步走,走多次”思想找到最优策略。

图1 模型整体结构
3.2 RoBERTa-wwm-ext编码层
编码端主要负责将输入文本转化为词向量,所获取的词向量能够利用词与词之间的相互信息提取文本中的特征信息。BERT预训练模型的架构为Transformer[20]中的Encoder,是目前使用最广泛的编码端模型,但原始的BERT模型不是最佳选择。文中编码端使用RoBERTa-wwm-ext预训练模型,该模型是在RoBERTa[21]模型的基础上做了一些优化,相比BERT预训练模型,能达到更好的编码效果。
(1)RoBERTa-wwm-ext预训练模型在预训练阶段采用wwm(whole word masking)策略进行mask,而BERT模型是随机进行mask,采用wwm策略的效果更好,具体示例如表4所示。

表4 wwm策略和BERT原始策略
(2)RoBERTa-wwm-ext预训练模型取消了NSP(Next Sentence Prediction)任务。取消了NSP任务后,模型性能得到提升。
(3)RoBERTa-wwm-ext预训练模型采用更大的 Batch Size,这样有助于提高性能。ext(extended data)表示增加了训练数据集的大小。
3.3 Efficient GlobalPointer命名实体识别模块
GlobalPointer将实体的首尾视为一个整体去识别。如图2所示,在“欲界自在天女是一位出世间护法神”这句话中,对于实体类型“佛母”,该类型实体在文本中只有一个,是“欲界自在天女”;对于实体类型“称号”,该类型实体共有两个,分别是“出世间护法神”和“护法神”,从这里可以看出,GlobalPointer可以识别嵌套类型实体。综上所述,假设待识别文本序列长度为n,待识别实体个数为k,那么在该序列中会有n(n+1)/2个候选实体。在GlobalPointer中,命名实体识别任务可以看成“n(n+1)/2选k”的多标签分类问题。如果一共有m种实体类型需要识别,那么可以看成m个“n(n+1)/2选k”的多标签分类问题。GlobalPointer是一个token-pair的识别模型,用一种统一的方式处理嵌套和非嵌套命名实体识别。
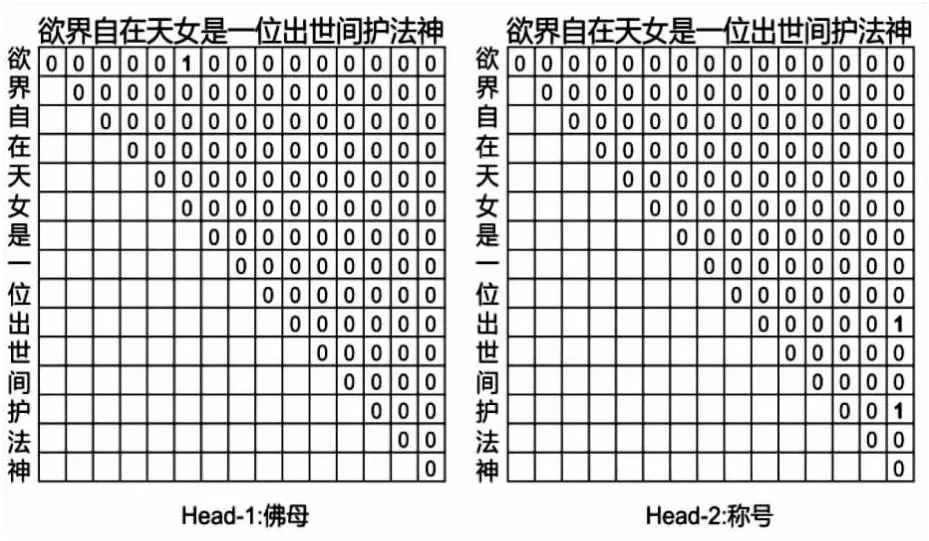
图2 GlobalPointer多头识别嵌套实体示意图
定义:
(1)
式1作为从i到j的连续片段是类型为α的实体的打分函数。其中,qi,α=wq,αhi+bq,α和ki,α=wk,αhi+bk,α是长度为n的输入t经过编码后得到的向量序列[h1,h2,…,hn]变换而来。得到用于识别第α种类型实体所用的序列[q1,α,q2,α,…,qn,α]和[k1,α,k2,α,…,kn,α]。
Efficient GlobalPointer主要针对GlobalPointer参数利用率不高的问题进行改进,优化了打分函数,达到了降低GlobalPointer的参数量的效果。
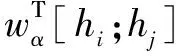
(2)
对于抽取部分,所有实体类型共享这部分参数,所以在公式2的基础上,记qi=wqhi,ki=wkhi,用[qi;ki]来代替hi以此进一步地减少参数量,此时
(3)
得到的公式3作为Efficient GlobalPointer最终的打分函数,相比于公式1来说,参数利用率得到提升,参数量也降低了。
3.4 关系抽取模块
GPLinker模型将实体关系三元组抽取转变为实体关系五元组(Sh,St,P,Oh,Ot)抽取,其中,Sh,St表示主实体的头和尾,P表示关系,Oh,Ot表示尾实体的头和尾。关系抽取流程如图3所示。
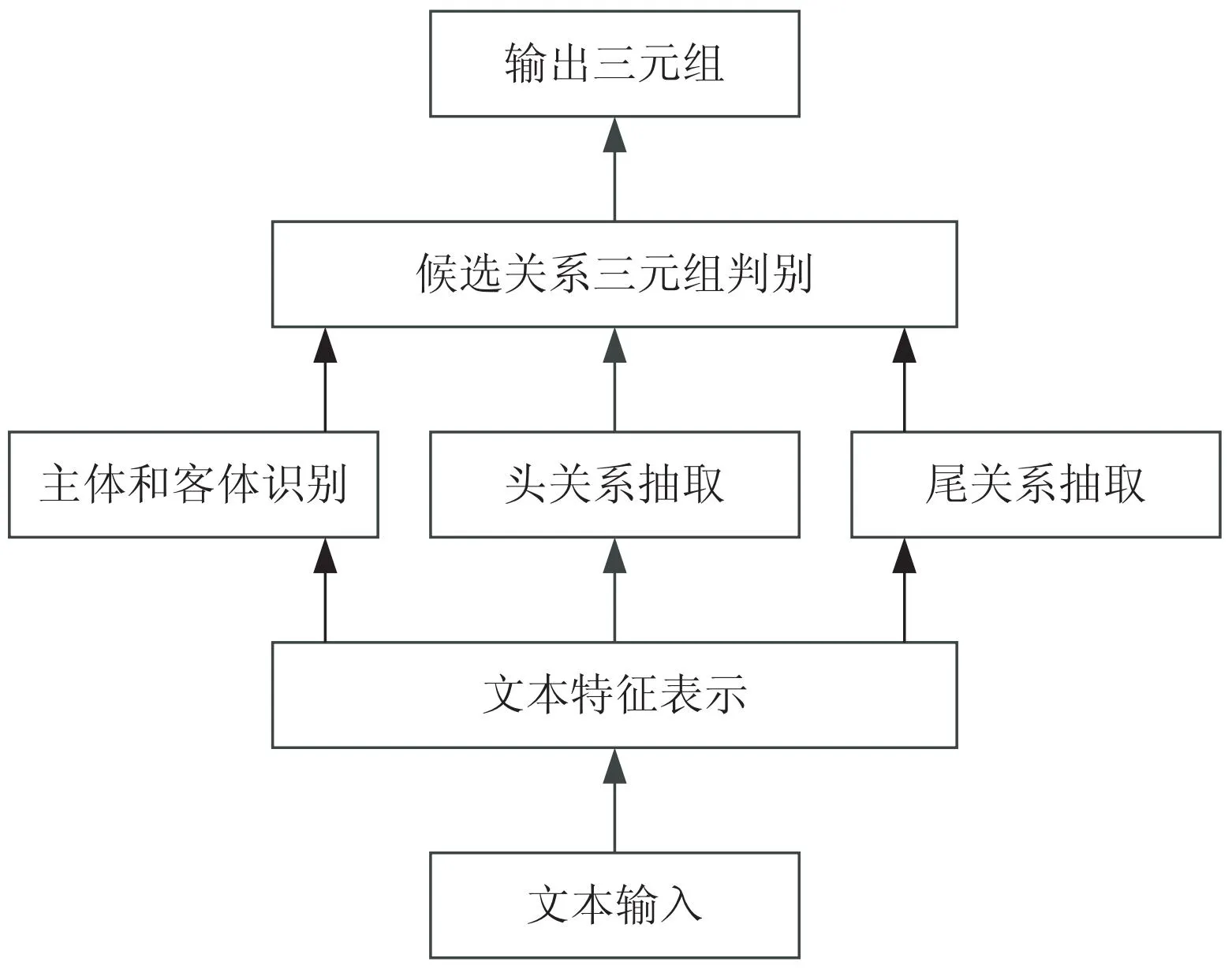
图3 关系抽取流程
S(sh,st,p,oh,ot)=S(sh,st)+S(oh,ot)+S(sh,oh|p)+S(st,ot|p)
(4)
模型训练时,对于标注的五元组让公式4中S(sh,st),S(oh,ot),S(sh,oh|p)和S(st,ot|p)皆大于0,其他五元组这四项皆小于0。模型预测时,枚举所有可能的五元组,找出S(sh,st)>0,S(oh,ot)>0,S(sh,oh|p)>0和S(st,ot|p)>0的部分,取它们的交集部分。
S(sh,st)、S(oh,ot)分别是subject实体、object实体的首尾打分函数,通过S(sh,st)>0,S(oh,ot)>0来得到所有的subject实体和object实体。至于函数S(sh,oh|p)和S(st,ot|p),则是predicate关系的匹配,S(sh,oh|p)表示以subject和object的首特征作为它们自身的表征来进行一次匹配,考虑到存在嵌套实体,需要对实体的尾再进行一次匹配,即S(st,ot|p)这一项。由于S(sh,st),S(oh,ot)是用来识别subject,object对应的实体的,用一个Efficient GlobalPointer来完成;至于S(sh,oh|p),它是用来识别关系为p的(Sh,Oh)对,也可以用Efficient GlobalPointer来完成,最后对于S(st,ot|p)这一项,处理和S(sh,oh|p)原理相同。
3.5 对抗训练
对抗训练是一种引入噪声的训练方式,可以对参数进行正则化,提升模型的鲁棒性和泛化能力[22]。对嵌入层的字向量添加一些较小的扰动,生成对抗样本,将获得的对抗样本再反馈给模型,从而提升模型的抗扰动能力。本研究使用的是PGD对抗训练算法。该算法通过多次迭代,以“小步走,走多次”的策略找到最优策略,并且通过设置扰动半径来防止扰动过大。扰动项radv的计算公式如下:
radv=ε·g(x)/‖g(x)‖2
(5)
g(x)=∇xL(θ,x,y)
(6)
其中,x表示输入,y表示标签,θ表示模型参数,ε表示扰动半径,L(θ,x,y)表示单个样本的loss。
PGD算法步骤如下所示:
(1)计算x前向loss,然后反向传播计算梯度并备份;
(2)对于每个步骤t:根据embedding层的梯度,计算其norm,然后根据公式计算出radv,再将radv累加到原始embedding的样本上,即x+radv,得到对抗样本;
(3)如果t不是最后一步,将梯度归0,根据x+radv计算前后向并得到梯度;
(4)如果t是最后一步,恢复步骤1时的梯度值,计算最后的x+radv并将梯度累加到步骤1上,跳出循环;
(5)将被修改的embedding恢复到步骤1时的值;
(6)根据步骤4时的梯度对模型参数进行更新。
3.6 损失函数
损失函数选择稀疏版多标签分类的交叉熵损失函数。P,N分别是正负类的集合,A=P∪N,S为对应的分数。
(7)
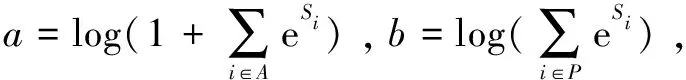
(8)
4 实 验
4.1 实验环境及参数设置
实验在Linux集群环境下进行,机器配置为5块NVIDIA A100 80GB PCIe显卡,代码使用Python语言编写。
实验主要参数设置如表5所示。

表5 实验主要参数设置
4.2 实验数据集
为了验证文中方法的有效性,先后在REDQTTM和DuIE[23]数据集上进行实验。其中DuIE的训练集含有173 108条句子,验证集含有21 639条语句。
4.3 评价指标
使用精确率(Precision)、召回率(Recall)和F1值作为评估模型性能的指标。其中,精确率是模型预测正确的关系三元组数与预测出的三元组总数的比值;召回率则是模型预测正确的关系三元组数与实际三元组数的比值;F1值是精确率和召回率的调和平均值,可以对模型的整体性能进行综合评价。Precision,Recall和F1值的计算方式如公式9~11所示。
(9)
(10)
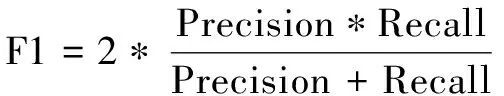
(11)
其中,TP表示正例预测为正例的数量,FP表示负例预测为正例的数量,FN表示正例预测为负例的数量。
4.4 REDQTTM数据集检测结果分析
该文选择多个基线模型在REDQTTM数据集上进行对比实验,这些模型包括CasRel模型、PRGC模型、TPLinker模型和GPLinker模型。
(1)CasRel:一种基于联合解码的实体关系抽取模型。该模型首先对头实体进行识别,然后在给定关系种类的条件下对尾实体进行命名实体识别。
(2)PRGC[24]:基于潜在关系和全局对应关系的实体关系抽取模型,将关系抽取分解为关系判断、实体抽取和主客体对齐三个任务。
(3)TPLinker:一种单阶段联合提取模型,该模型解决了曝光偏差和嵌套命名实体识别问题。TPLinker模型保证了训练和预测的一致性,因其用同一个解码器对实体和关系进行解码,同时对实体和关系进行抽取。
(4)GPLinker:基于GlobalPointer的实体关系联合抽取模型。GPLinker模型将实体关系三元组抽取转变为实体关系五元组(Sh,St,P,Oh,Ot)抽取。GPLinker模型有着计算速度快、显存占用少等优点。
从表6可以看出,在REDQTTM数据集上,提出的方法无论是在Precision,还是在Recall和F1上都是最优的。相比GPLinker模型,在Precision上提高了2.4百分点,在Recall上提高了0.9百分点,在F1上提高了1.6百分点。可见,提出的方法在瞿昙寺壁画实体关系联合抽取任务上取得了较好的效果。

表6 实验结果
为了验证各个模块的有效性,在REDQTTM数据集上进行了消融实验。-RoBERTa-wwm-ext表示不使用此预训练模型,改为使用BERT;-Pgd表示不使用对抗训练;-Efficient GlobalPointer表示不使用此模块,改用GlobalPointer。实验结果如表7所示,去掉各模块后的性能都有所下降,验证了各模块的有效性。
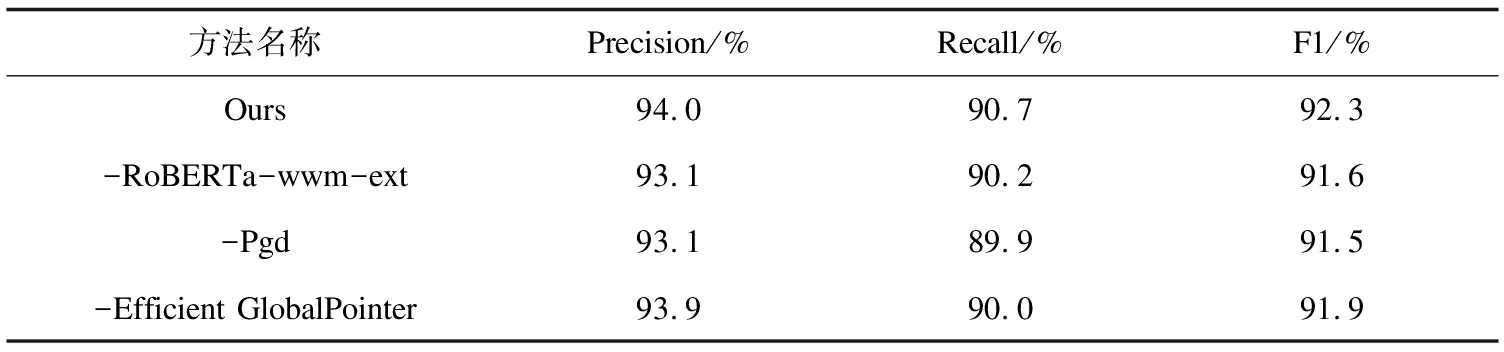
表7 消融实验结果
将相关文本输入到模型,抽取文本中的实体关系三元组。表8展示了模型对关系三元组的抽取效果。三元组的抽取是建立瞿昙寺壁画领域知识图谱的关键步骤。

表8 三元组抽取结果部分示例
4.5 DuIE数据集检测结果分析
文中模型在DuIE训练集上训练,在验证集上进行评估。MultiR[25]、CoType[26]、指针标注模型[27]、FETI[28]、CasRel、字词混合模型[29]和BSCRE[30]模型的实验结果来自禹克强等人[30]的实验结果,如表9所示。
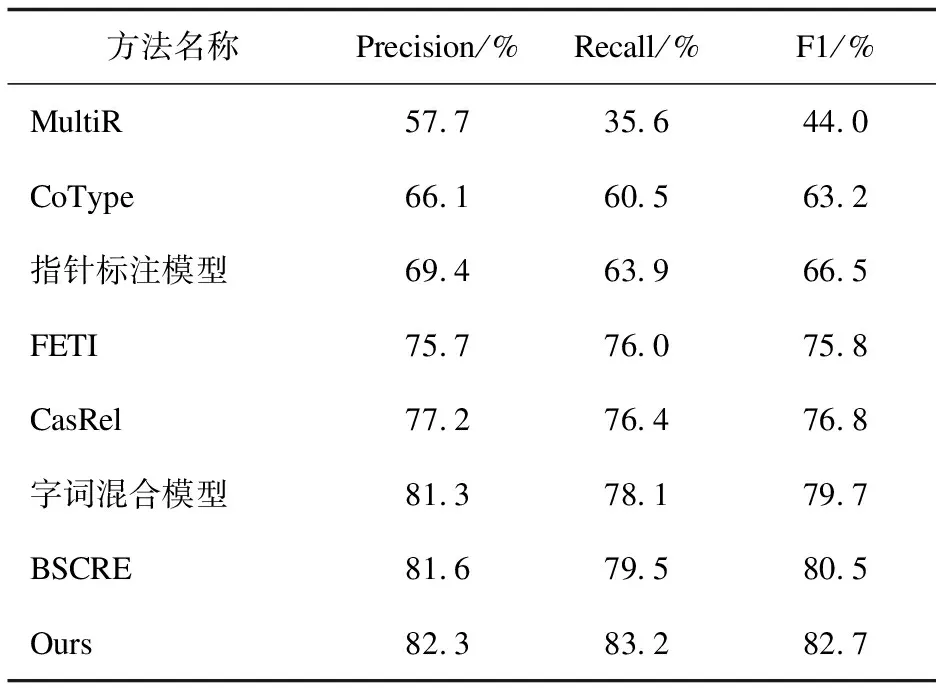
表9 DUIE数据集上的实验结果
从表9中可以看出,该文提出的方法相较于禹克强等人提出的BSCRE模型,在DuIE训练集上,Precision,Recall和F1值分别提高了0.7百分点,3.7百分点和2.2百分点。验证了RoBERTa-Effg-Adv模型在其它中文领域的实体关系联合抽取任务的有效性。
5 结束语
该文自建了瞿昙寺壁画领域的实体关系联合抽取数据集REDQTTM,其中包含18种实体类型和11种关系类型。针对瞿昙寺壁画领域的实体关系联合抽取任务,提出了一种实体关系联合抽取模型RoBERTa-Effg-Adv,其编码端使用RoBERTa-wwm-ext预训练模型,并采用Efficient GlobalPointer对命名实体进行识别,总体上使用实体关系五元组策略进行实体关系联合抽取。再结合对抗训练,提升模型整体的鲁棒性。由于该数据集包含的实体关系数量较少,后期会增加更多的预定义实体关系类别和数量来扩充数据集,也会在该实体关系联合抽取的基础上,开展建立瞿昙寺壁画领域的知识图谱、基于瞿昙寺壁画知识图谱的智能问答等研究。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31
系统工程学报(2021年4期)2021-12-21
山西大学学报(自然科学版)(2021年1期)2021-04-21
中国外汇(2019年18期)2019-11-25
五邑大学学报(自然科学版)(2019年3期)2019-09-06
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
现代防御技术(2014年6期)2014-02-28
计算机工程(2014年6期)2014-02-28
