
藏文情感词典构建的现状分析
2024-03-25 02:04:52才让东知尼玛扎西
计算机技术与发展 2024年3期
才让东知,杨 杰,尼玛扎西,3
(1.藏文信息技术教育部工程研究中心,西藏 拉萨 850000;2.西藏大学 信息科学技术学院,西藏 拉萨 850000;3.西藏信息化省部共建协同创新中心,西藏 拉萨 850000)
0 引 言
近年来,基于深度学习的多特征融合情感分析法在情感分析领域取得了较好的效果,其中融合情感词特征的方法更能使模型提取文本的深层情感信息。陈钊等人[1]提出了一种结合情感词典和卷积神经网络的情感分类方法。该文提出的相关方法在中文倾向性分析评测COAE2014数据集上取得了比当时主流的卷积神经网络以及朴素贝叶斯、支持向量机更好的性能。韩普等人[2]提出了基于多特征和多通道的情感分析方法(MCMF-A),实验中融合了情感词的词性特征和位置特征,并结合CNN、BiLSTM以及多注意力机制进行了情感极性判断,最终准确率达到了90.45%。周宁等人[3]提出了一种基于混合词嵌入的双通道注意力网络中文文本情感分析模型(RCBN-BM),其中RCBN通道中融合了情感词特征,RCBN-BM在三种不同中文语料上的分类准确率均达到了90%以上。2023年朱宇雷等人[4]在基于图神经网络结合预训练模型的藏文短文本情感分析研究中提出了融合句子中情感词表征的图神经网络模型,其实验结果证明了融合情感词表征的藏文情感词分类模型的准确率达到98.60%,优于其它基线模型。上述研究方法中情感词扮演着重要角色,因此构建一部高质量的情感词典是其主要的前提工作之一。
藏文情感分析起步较晚,现阶段没有公开的藏文情感词典。想要通过上述融合情感词特征的方法研究藏文情感分析,需要自行构建藏文情感词典,此过程中应当了解藏文情感词典构建的研究现状。目前,藏文情感分析的综述文献很少,尤其针对藏文情感词典构建方面的综述文献极少,但藏文情感词典构建方面的文献不少。2017年李苗苗[5]在中文情感词典的基础上利用机器翻译方法构建了基准词典,随后利用word2vec、KNN扩充等算法进行基准词典的扩充后构建了一部包含5 846个情感词的藏文情感词典。2018年孙本旺和田芳[6]利用词典匹配算法和人工构建方法构建了包含10 433个词的藏文情感词典,同时构建了程度副词、转折词、否定词等辅助词典。2019年孙本旺[7]在此基础上将情感词扩充至27 361个。同年张瑞[8]也构建了包含15 543个词的藏文情感词典。2023年朱宇雷等人[4]收集了10 995个情感词。
为了在正式构建藏文情感词典的过程中找到合理的构建方法和避免不必要的重复工作,该文将通过对比和统计的方法分析藏文情感词的词汇类别、词典构建的方法以及已有藏文情感词典的词汇量和词汇构成等内容来了解藏文情感词典构建的研究现状,希望能给未来构建藏文情感词典的研究人员提供一些参考。
1 情感词的分类研究
情感词是人们表达自己情绪、观点、态度最常用的词语[9]。情感词的分类研究能使情感语料标注体系变得更加标准化,情感词典分类粒度会影响情感分类的效果。如果类别划分过粗,就不能全面、细致地描述语言的复杂现象;但如果类别划分过细、标注信息过于庞大,不但会增加标注难度、降低标注效率,关系之间只有细微差别的情况也会使标注结果呈现严重的不一致性[10]。情感词主要分布在名词、动词、形容词中。情感词最简单的分类方法就是褒贬或积极、消极、中性,目前常见的情感词典中使用的分类方法也是这种粗粒度的分类方法。
在英文情感词分类方面,Plutchik等人(1960)的情感学说中,有八种主要的感情。Ekman[11]在其所述的情绪理论中将情感划分为六类,并将这些类别整理归纳成五大类。
中文情感词分类的研究最早开始于中国古代西汉时期,其中针对各种礼仪论著加以辑录对人的七情有了提及[12]。汉语《礼记·礼运》中提出了七情。《乐记》中也将情绪分为七种。中国著名文学家刘勰的《文心雕龙》和韩愈也把情绪分为七种,在不同著作中对情感的分类有细微的差别但都大同小异。近几年在情感词典构建工作中经常会出现7大类21小类和8大类21小类这种分类方法。心理学家林传鼎[13]将情绪化分为18类。许小颖[14]等人将情感词汇划分为两大类:基于心理感受和表现力,其中将基于心理感受的词汇又划分为24类,将基于表现力的情感词汇划分为态度词、品性词、声音词和其他。文献[15]把人脸面部情感表现情感分为6类。文献[16]将情感分为8种。文献[17]将微博情感划分为7类。文献[18]中指出7大类21小类。


表1 国内外情感分类方式对照
根据这些情感划分,很多情感词典研究者提出了情感词的分类标准。但在现阶段,对藏文情感词没有统一的分类标准,这给情感词典研究工作带来了很大的阻碍。
2 藏文情感词典构建方法
情感词典的构建方法大致可分为两种方式:人工构建和人机结合构建。目前,藏文情感词典构建的基本步骤是先根据已有中文情感词典利用机器翻译、词典匹配等方法构建基准词典,再利用词向量、KNN、SO-PMI、SVM、语义相似度等方法进行对基准词典的扩充工作,最后通过人工校对和筛选来提高藏文情感词典的精度。人机结合的构建方法受研究者的青睐,也最为常见。
2.1 基准词构建方法
基准词典的构建是情感词典构建的基础,常用的基准词典构建的方法主要有纯人工收集、机器翻译、词典匹配算法等。
纯人工构建的方法耗时耗力,但有较高的可信性,现在这种方法使用的很少。闫晓东和黄涛[23]从藏语大词典中人工选择带有情感色彩的词,并分5个强度构建了藏文情感词典。基于机器翻译的方法是把现有中文情感词典中的情感词翻译成藏文的方式构建基准词典。李苗苗[5]和巴桑卓玛等人[22]先后根据大连理工大学中文情感词汇本体库来构建一部藏文基准情感词典。机器翻译方法虽然可行,但它对机器翻译系统的依赖度很高。比起机器翻译方法,词典匹配算法的效果更好。这是因为词典匹配是通过两部或多部由专业人士构建的词典中通过关键词查找对应词,因此其专业度也比机器翻译得出的情感词典的专业度高。张震[17]利用匹配算法从包含15万常用词的藏汉网络词典中与大连理工大学情感词典匹配的词对,构建了基准词典。孙本旺和田芳[6]通过关键词匹配算法构建了基于Hownet词典和《藏汉大辞典》的藏文情感词典(Tibetan Sentiment Dictionary,TSD)。孙本旺[7]利用现有的中文情感词典资源和汉藏大辞典通过匹配算法等自动构建汉藏双语情感词典,弥补了汉藏双语情感词典的空白。张瑞[8]先基于汉藏词典、知网Hownet进行机器翻译和关键词匹配方法构建基准词典,然后通过人工筛选方式完成情感词典的构建。黄晨晨等[9]通过词典匹配方法基于中文情感词典、台湾大学NTUSD词典和《藏汉大辞典》构建了约18 000词条的藏汉情感词。
2.2 词典扩充方法
情感词典扩充指的是增强基准情感词典的词汇量。情感词典的扩充方法主要有基于词向量的语义相似度扩充、KNN、SO-PMI、SVM、取近反义词、深度学习方法等。
李苗苗[5]和巴桑卓玛等人[22]对比了w2v词向量扩充、KNN扩充算法、权重增益法、SVM法的扩充效果,最终发现KNN的效果最佳。张震[17]用word2vec训练出微博语料词向量,并用语义相似度算法找出微博表情相似的情感词完成对基础词典的扩充工作。杨志利用SO-PMI算法计算候选词与种子词的相似度来扩充基准词典。上述大多数都是基于机器学习的扩充方法,而单睿康[24]提出了基于BiLSTM-ATT-CRF的深度学习藏文情感词扩充方法,他使用BIOS标签标注语料,再利用BiLSTM-ATT-CRF模型实现了藏文情感基准词典的扩充。藏文情感词典构建方法的对比见表2。

表2 现有藏文情感词典构建方法对比
观察表2可以看出大多数基准词构建方法选择了词典匹配算法,扩充方法基本上是选择基于SVM、KNN等算法,但近期也有研究者提出了基于深度学习的情感词典扩充方法。
3 藏文情感词典词汇对比
情感词典的词汇量影响着情感特征提取的性能。在较好的词汇质量前提下情感词典的词汇越多,越能挖掘文本情感信息。由于藏文情感语料匮乏,很多藏文情感词典都是在中文情感词典基础上通过机器翻译或词典匹配算法等方式构建。因此,中文情感词典的词汇量对藏文情感词典的词汇量的影响很大。表3中列出了四个中文权威性情感词典的词汇信息,表中可发现中文情感词的类别以褒贬中或褒贬两性为主,词汇量分布在9 153至27 466之间。

表3 中文情感词典的词汇信息
在藏文情感词典方面,2018年孙本旺和田芳[6]利用现有中文情感词典和汉藏大词典通过匹配算法得出10 433个藏文情感词,其中包含192个程度副词、17个否定词、11个转折词、13个双重否定词,其词汇构成较为丰富。2019年孙本旺[7]利用同样的算法得出27 361个藏文情感词,其中包含220个程度副词和385个停用词,这是现有藏文情感词典中总词汇量最多的词典。张瑞[8]构建的词典有15 543个藏文情感词。张震[17]构建的词典有9 870个情感词,其中有115个表情词。这些是现有藏文情感词典中词汇量较多的词典。为了细致地观察藏文情感词典的词汇信息,该文根据现有文献内容整理了藏文情感词典词汇信息(见表4)。
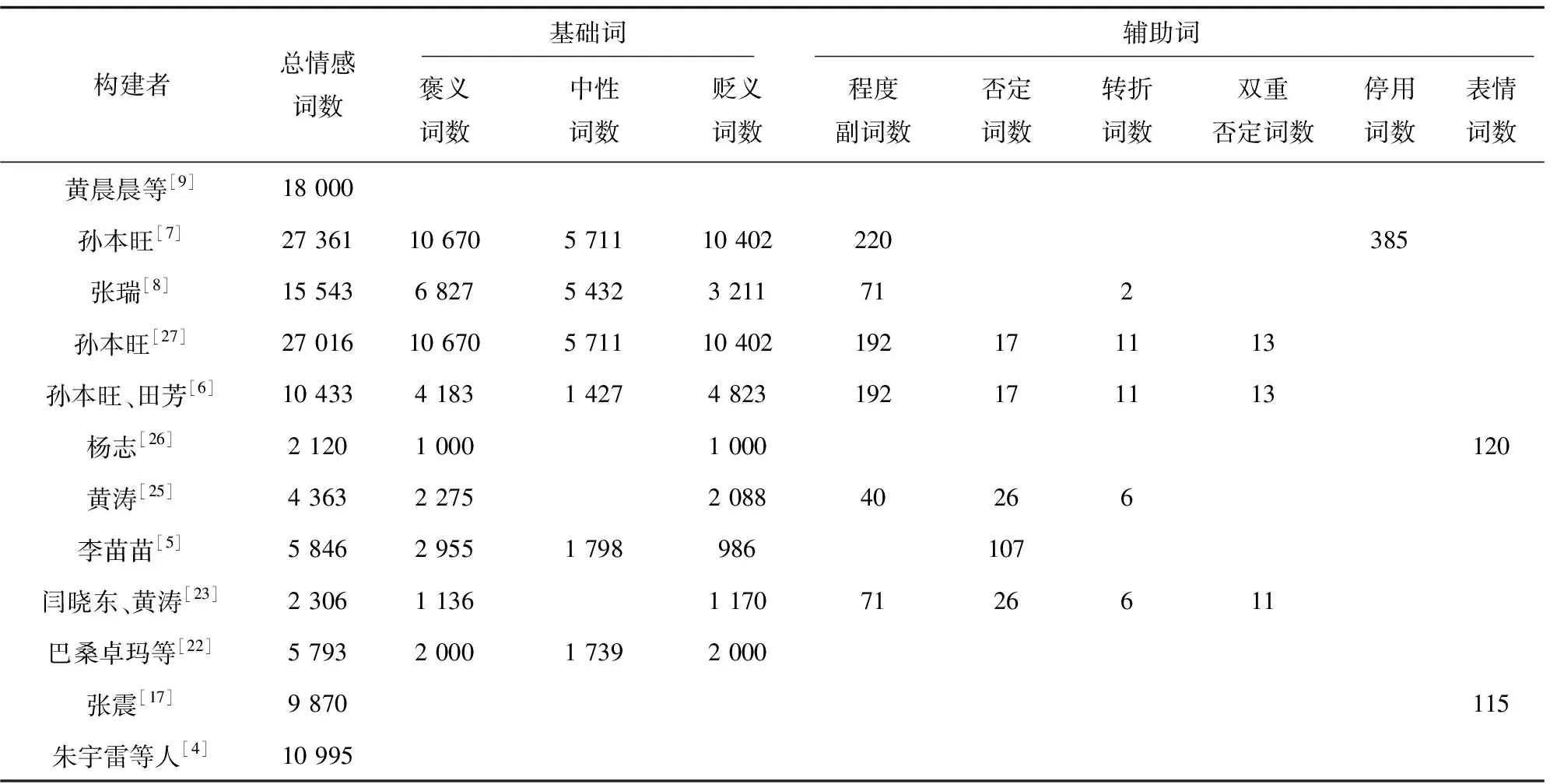
表4 藏文情感词典词汇信息
由表4可以看出,从词汇量角度分析,藏文情感词典中词汇量达到1万以上的文献有四个,它们的词汇量接近中文权威性情感词典,但情感词典的词汇质量是否达到相对成熟的中文情感词典的水平还得深入研究。
从词典构成分析,大多数藏文情感词典除了情感词外,还包含了程度副词、否定词、双重否定词、转折词、表情词、停用词等辅助词。从时间维度分析,着力构建情感词典的时间段在2019之前,随着深度学习技术的发展,情感词典构建工作逐渐退缩。
4 藏文情感词典构建中存在的问题
通过观察藏文情感词典构建现状,发现了藏文情感词典构建中存在的几个问题:
(1)藏文口语情感词典目前处于空白状态,导致对语法规则不正规文本的口语化句子的识别率较低,可以从藏文已有口语词典《藏汉对照拉萨口语词典》《安多藏语口语词典》《藏语康方言词汇集》中筛选口语情感词;
(2)词典扩充过程中用深度学习方法的很少,深度学习方法应该更能准确抓住种子词的特点,应该能提高情感词的自动扩充性能;
(3)没有统一的情感词分类标准和标注标准,希望将来相关研究机构和研究人员同心协力来制定分类标准和标注标准;
(4)相关研究机构和研究者之间缺乏共同意识和共创意识,导致难以构建出权威性或官方性质的情感词典;
(5)藏文目前缺乏特定领域的情感词典,若能构建政治、经济、教育、新闻、交易、文学、体育等特定领域的藏文情感词典,会提高藏文情感分析的整体水平。
5 结束语
该文根据近10年藏文情感词典构建的相关文献分析了藏文情感词典构建的研究现状,主要从情感词的分类、词典构建的方法、已有藏文情感词典的词汇量和词汇构成等角度进行了研究。情感词分类研究中通过对比国内外相关情感分类理论后用表格的方式统计了主流分类方法。藏文情感词典构建方法研究方面,统计了11种相关文献中的基准词构建方法和词典扩充方法。已有藏文情感词典的词汇量和词汇构成方面,统计了已有藏文情感词典的词汇数量和词汇构成。
未来将以文中的研究内容作为理论依据,灵活使用归纳出的情感词分类方法和情感词典的构建方法来正式构建一部藏文情感字典,为后续的藏文情感分析奠定基础。
猜你喜欢
布达拉(2020年3期)2020-04-13 10:00:07
文苑(2019年24期)2020-01-06 12:06:50
新世纪智能(英语备考)(2019年10期)2019-12-16 09:07:54
西夏学(2019年1期)2019-02-10 06:22:34
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
科学与财富(2016年21期)2017-03-02 00:14:03
西藏大学学报(自然科学版)(2016年1期)2016-11-15 05:23:31
新闻传播(2016年17期)2016-07-19 10:12:05
外语教学理论与实践(2014年2期)2014-06-21 08:34:30
