
一种基于深度学习的面部视频情感识别方法
2020-11-18 14:00雷单月安建伟
现代计算机 2020年28期
雷单月,安建伟
(北京科技大学计算机与通信工程学院,北京100036)
0 引言
情感是人类交往中的重要信息。面部表情、语音语调和身体姿态等可以传达不同的情感。因此,如何让机器识别人的喜怒哀乐等不同情绪,成为影响人机交互和机器智能发展的关键因素。通常面部包含的情感信息是最直接也是最丰富的,美国心理学家埃克曼(Ekman,1984)经过大量的研究表明,尽管人类有肤色、语言、社会地位等差异,但是面部表情、面部肌肉运动的基本模式是一致的。
目前为止,基于面部表情的情感识别研究趋于成熟,大量的研究开始转向研究语音与表情、表情与姿态、表情与生理信号等双模态或多模态情感识别研究。考虑到人机交互的一些特定场景,例如课堂听讲,疲劳驾驶检测等仅能获取到人的面部表情的场景,只考虑面部特征进行情感识别是很有必要的。研究表明,面部视频中包含有心率和呼吸频率等生理信息[1]。而大多数的面部情感识别方法都只考虑了面部的表情特征,即基本的外观特征,忽略了面部蕴含的生理信息,导致识别率不能进一步提升。文献[2]文提出了一种基于面部表情和面部生理信号的双模态视频情感识别方法,该方法从面部视频中提取生理信号,再进行时频域和非线性分析,手工设计生理信号的特征。然而当视频的时长较短时,由于手工设计特征的方法提取的特征难以表示生理信号,以至于识别结果并不理想。
基于上述问题,本文提出一种基于深度学习的面部视频情感识别方法,该方法基于三维卷积神经网络,自动提取面部表情特征与面部生理特征,然后分别送入分类器,最后将两个分类器得到的结果进行决策融合。
1 相关研究
1.1 视频情感识别
传统的视频分析方法有三个步骤。首先,将将视频分为单个帧,然后,根据人脸的标志点,通过手工设计或卷积神经网络(CNN)提取人脸特征。最后,将每个帧的特征输入分类器。但是这种方法的缺点是没有考虑视频图像之间的时序关系,就像使用静态图像分类模型一样。近年来,研究者们提出视频中的时序信息是非常重要的,并做了一些相关的工作。主要有两种方法,一种是用CNN 提取图像特征,然后用长短时记忆网络(LSTM)来理解时序特征。CNN 在分类任务方面具有最先进的性能,LSTM 可以分析不同长度的视频序列。这两个强大的算法创建了一个适合于视频分析的系统。文献[3]将递归神经网络(RNN)与CNN 框架相结合,在2015 年的野外情绪识别(EmotiW)挑战中的研究结果表明,RNNCNN 系统的性能优于深度学习CNN 模型。文献[4]分两部分进行情感识别。第一部分是CNN 结构提取空间特征,第二部分利用第一部分的特征训练LSTM 结构来理解时间信息。另一种是使用文献[10]提出的三维卷积神经网络(C3D),对处理视频分析类的任务非常有效。文献[5]利用C3D 结合深度信念网络(DBN)提取音频和视频流时空特征,获得了多模态情感识别研究的先进性能。文献[6]结合RNN和C3D,其中RNN 在单个图像上提取的外观特征作为输入,然后对运动进行编码,而C3D 则同时对视频的外观和运动进行建模,显著提高视频情感识别的识别率。
1.2 融合表情与生理信号情感识别
虽然面部表情能够直观地反应情感的变化,但是许多情感变化无法通过视觉感知,于是有学者提出通过生理信号来分析人体潜在的情感状态,弥补面部表情单模态情感识别的不足。文献[7]从皮肤电信号和心率信号中提取人的生理特征,再结合面部表情特征进行情感识别,实验结果表明皮肤电和心率信号具有与面部表情特征的互补信息,有助于情绪识别。文献[8]提取了面部表情特征和ECG 生理特征,分别在特征层融合和决策层进行了融合,实验结果表明基于决策层融合的方法识别率优于特征层融合。由于一般生理信号的采集需要受试者佩戴专业的设备,因此采集过程较为困难和繁琐且费用较高。文献[9]提出了一种提取面部血容量脉冲信号的情感识别方法,无需与人体进行接触就能获取生理信号,最终的实验结果也证明了该方法的有效性。但这也存在一定的局限性,对于生理特征的提取,文献[9]采用的是传统的时频域特征分析方法,容易受到噪声的影响,鲁棒性较差。
2 双模态情感识别方法
本文提出的方法结合视频中的面部表情特征和隐藏的面部生理特征进行情感识别。首先对面部视频进行人脸检测与裁剪,然后分别提取面部外观特征和面部生理特征,并结合两种模态的分类结果进行最终的情感分类,模型框架如图1 所示。
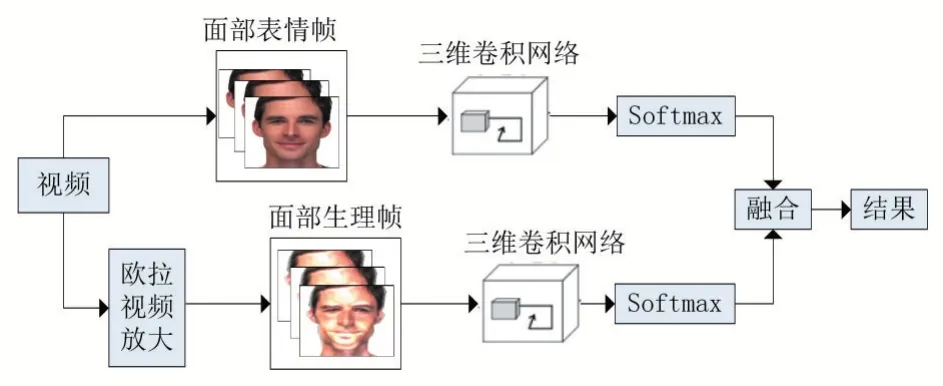
图1 双模态融合情感识别框架
2.1 视频预处理
由于原始视频尺寸太大,包含很多不必要的背景信息,对模型的训练效率和准确率都会造成一定的影响。所以首先要对视频进行人脸检测与裁剪,对裁剪后的视频进行分帧。除此之外,为了增加数据的多样性,提高模型的泛化能力,对从视频中提取的人脸图像进行数据增强处理,包括平移、翻转等操作。
由于心脏周期性地收缩和扩张,脸部血容量会发生相应的变化,根据脸部血容量和面部其他组织器官对光线吸收不同的特点,脸部血容量变化会引起脸部细微的颜色变化。为了获取面部视频中潜藏的生理信号,在视频人脸裁剪之后,采用欧拉颜色放大算法[10]对人脸视频进行颜色放大处理,使面部微弱的颜色变化得到增强,便于提取面部生理特征。
欧拉视频颜色放大首先是对输入的视频图像进行空间分解,将其分解为不同尺度的视频图像,其相当于对视频进行空间滤波;然后将空间滤波后的视频图像进行带通滤波处理,再乘以一个放大因子得到放大后的视频图像;最后将前两步得到的视频图像进行金塔重构,得到放大后的视频图像。经欧拉视频颜色放大后的图像如图2 所示。

图2 视频颜色放大前后对比图
2.2 C3D特征提取
在二维卷积网络中,卷积和池化操作仅在空间上应用于二维静态图像。而在三维卷积网络(C3D)中,添加了一个额外的时间维度,可以在时空上进行卷积和池化[11]。二维卷积将多张图像作为多个通道输入,每次输出一张输出图像的特征,因此每次卷积运算后都会丢失输入信号的时间信息。而三维卷积将多张图像叠加成一个立方体作为一个通道输入,输出多张图像的特征才能保留输入信号的时间信息,从而提取序列的时间特征。
本文训练了两个C3D 网络,一个用于提取面部表情特征,一个用于提取面部生理特征,具体结构细节在第3 节给出。
2.3 双模态融合
多模态数据的融合可以通过不同的融合方法来实现。应用适当的融合方法,例如在低层(信号层的早期融合或特征融合)、中间层或高层(语义、后期融合或决策层的融合),以达到最佳精度。特征融合是一种常用的方法,它可以特征连接成一个高维特征向量,然后送入分类器。但是随着组合特征中添加了大量的信息,训练效率和计算资源都会受到很大影响。而决策融合是给不同特征训练得到的分类器分配融合权重进行融合,得到最终的判别结果,既融合了不同模态的结果,又不会增加训练负担。
决策融合关键的一步是如何分配不同模态的权重,常见的融合准则有最值准则、均值准则和乘积准则,但这些方法都是依据简单的数学计算,并没有考虑到准则以外的其它权重分配的可能性。针对双模态融合的权重分配,本文提出一种自动权重寻优方法,从足够多数量的权重组合中,找出两种模态的最佳权重分配方案。双模态融合结果的计算公式如下,
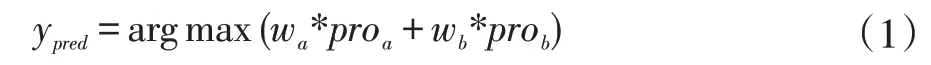
其中,y 表示预测类别,wa表示表情特征识别结果的权重,wb表示生理特征识别权重,且wb=1-wa,proa为表情特征预测结果的类别概率,prob为生理特征预测结果的类别概率。
自动权重寻优策略的步骤如下,具体的测试结果在第4 节给出。
(1)初始化权重wa,分别提取两个模态的类别预测proa、prob,以及真实的标签值ytrue;
(2)从wa=0.0 开始,以0.001 的步长增加,最大为1.0,wb=1-wa,共1000 组权重;
(3)循环计算预测类别ypred=arg max(wa*proa+wb*prob),同时保存权重;
(4)循环将预测标签ypred与真实标签ytrue对比,计算准确率;
(5)选择最高的准确率,并得到最高准确率对应的权重,即最优权重。
3 实验与分析
3.1 实验数据集
eNTERFACE'05 数据集包含44 名受试者,每个受试者表达愤怒、厌恶、恐惧、快乐、悲伤和惊讶六种情绪,数据库总共包含1166 个视频序列。
RAVDESS 是一个多模态情感语音和歌曲视听情感数据库,该数据集由24 位专业演员(12 位女性,12位男性)录制,包括平静、快乐、悲伤、愤怒、恐惧、惊奇和厌恶中性8 种情绪,实验选取1440 个只包含视频的数据集。
3.2 实验环境与参数
本文实验在64 位的Ubuntu 18.04 操作系统上进行,使用NVIDIA GeForce RTX2080Ti 显卡进行GPU 加速。网络的输入大小为3×16×112×112,其中3 表示三种颜色通道,16 表示一次输入的帧数量。在文献[12]设计的C3D 网络结构的基础上进行微调,该网络有8个卷积层、5 个最大池化层和3 个完全连接层。各卷积层的卷积核数量。8 个卷积层的卷积核的数量分别为64、128、128、256、256、512、512、512;卷积核大小均为3,步长为1。池化层的核大小均为2,步长为2;前两个全连接层的输出特征数量为4096,第三个全连接层输出特征数量为数据集的类别数。使用经过预先训练的C3D 模型进行训练,损失函数为交叉熵函数,采用随机梯度下降算法优化损失函数,使用20 个视频片段的小批量训练网络,初始学习率为0.0001,每10 个epoch后,学习率缩小10 倍,一共训练50 个epoch。
3.3 实验结果与分析
为了验证本文提出的双模态情感识别方法的性能,分别在RAVDESS 数据集和eNTERFACE'05 数据集上,对单模态模型与双模态方法进行了实验,比较了面部表情模态、面部生理模态和双模态融合的识别准确率。
首先在两个数据集上分别进行单模态情感识别实验,然后将两个数据集上单模态的分类概率分别进行基于权重的决策融合,图3 和图4 为本文提出的自动权重寻优策略在两个数据集上寻找最优权重分配的结果,横轴表示面部表情的权重,则面部生理特征的权重为1 减去面部表情权重。由图可知,当面部表情的权重分别为0.465 和0.455 面部生理特征权重分别为0.535 和0.545 时,两个数据集上取得最佳识别率0.8873 和0.6122。
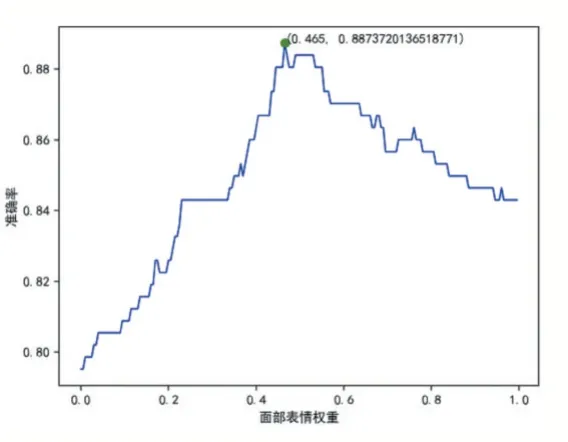
图3 权重寻优结果(RAVDESS)
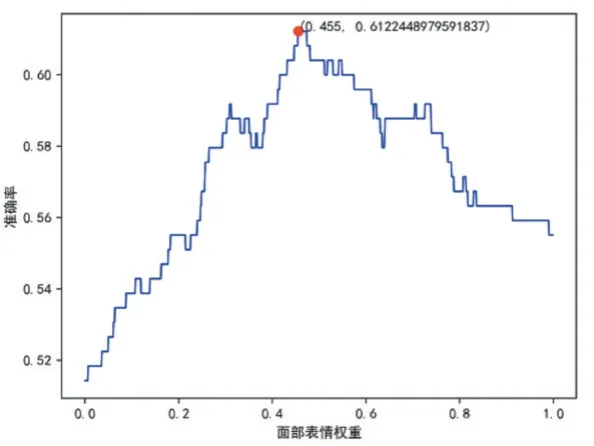
图4 权重寻优结果(eNTERFACE’05)
如表1 所示,本文的方法在RAVDESS 数据集上面部表情单模态识别率82.04%,面部生理信号单模态识别率为79.0%,基于决策层融合后,识别率为88.7%。在eNTERFACE’05 数据集上面部表情单模态识别率55.9%,面部生理信号单模态识别率为48.3%,基于决策层融合后,识别率为61.22%。相较于单模态情感识别,进行双模态融合后在RAVDESS 和eNTERFACE’05 上的识别率分别提升了6.66%和5.32%,验证了在只考虑面部信息的情况下,面部表情和面部蕴含的生理信号具有互补的情感信息。
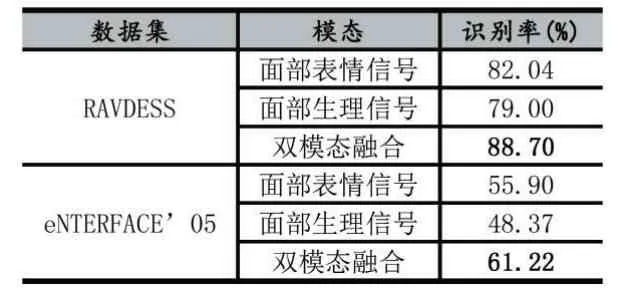
表1 不同模态的识别率
图5 和图6 分别为两个数据集上测试集的双模态融合结果的混淆矩阵,在两个测试集上,相对于其他类别,“伤心”类别的分类错误最多。

图5 双模态混淆矩阵(RAVDESS)
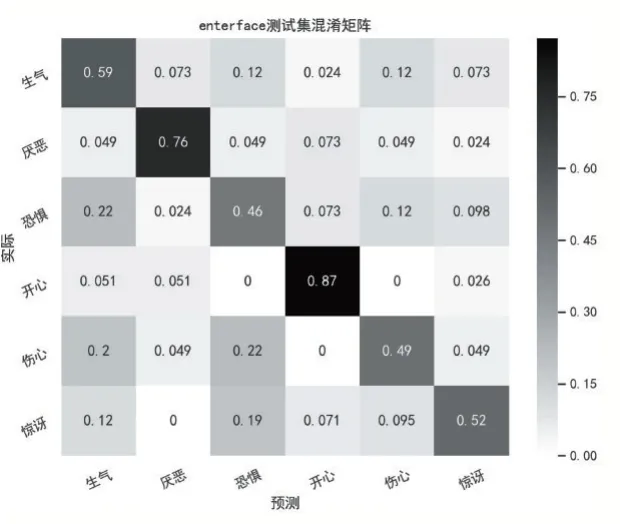
图6 双模态混淆矩阵(eNTERFACE’05)
本文最后对比了其他方法得到的识别率,如表2示。结果表明本文的方法优于文献[13-16],进一步证明了本文方法的可行性。
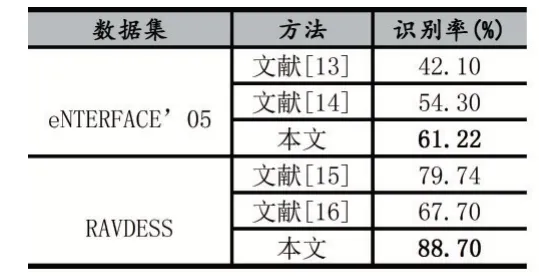
表2 不同面部视频情感识别方法识别率
4 结语
目前情感识别领域仍然是一个具有挑战性的问题,如何只利用视频中的面部信息进行有效的情感识别是实现人机交互的关键。为了充分利用面部包含的情感信息,本文提出使用三维卷积网络分别提取面部表情特征和面部生理特征进行训练和分类,在决策层给不同模态分配相应的权重进行结果融合。实验结果证明使用卷积神经网络能够提取面部表情与面部生理信号的互补特征。由于本文没有对特征提取方法做详细研究,在未来的研究中我们将探索如何使用更好的特征提取方法提取更具有代表性的特征。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
中国药学药品知识仓库(2022年9期)2022-05-23
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
江苏农业学报(2019年1期)2019-09-10
Coco薇(2017年5期)2017-06-05
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
