
命名实体识别任务针对中文的适应性研究
2020-11-18 14:00张文涛
现代计算机 2020年28期
张文涛
(四川大学计算机学院,成都610065)
0 引言
命名实体识别(NER)是许多自然语言处理下游任务(关系提取、知识图谱等)的基础,其旨在从非结构化文本中识别命名实体,如人员、位置、产品和组织名称等。
目前,高性能的NER 模型均基于神经网络。Ham⁃merton(2003)[1]提出了基于LSTM 的模型,首次将神经网络引入NER 任务中。Lample 等人(2016)[2]提出了基于BiLSTM-CRF 的模型,获得了较好的性能。Ma 和Hovy(2016)[3]在此基础上引入了CNN 来计算字符级嵌入。由于中文的特殊性,当上述NER 模型应用于中文时存在一些障碍。
问题1:中文是一种符号语言,其字形蕴含了丰富的意义信息。现有的高性能NER 系统主要针对英文设计,无法利用中文的字形信息。
问题2:中文不存在明显的单词边界。现有的高性能NER 系统应用于中文时需要首先进行分词操作,然后对单词序列进行标记[4]。然而,中文分词系统不可避免地会产生一些错误的分词,进而对下游NER 任务产生负面影响[5]。
问题3:高性能神经网络通常需要在一个非常大的标注数据集上进行训练。目前,中文NER 数据集主要有TAC-KBP/ EDL Track(2015-2017)、ACE 2005、SIGHAN bakeoff 2006 NER MSRA、微博NER 等。总的来说,标注数据量比较少,各个数据集的内容类型(新闻、广播、微博)、标注的实体类型均有所不同。
针对问题1:本文介绍了利用字形信息的两种思路。第一种思路,从视觉角度来抽取字形信息;第二种思路,从字符的部首组成角度来抽取字形信息。
针对问题2:本文介绍了利用词汇信息的两种方法。第一种方法,基于LSTM 变体。第二种方法,基于图模型。
针对问题3:本文介绍了利用不同任务的数据集、不同域的数据集来提高中文NER 模型性能的方法。
1 利用字形信息
汉语是一种符号语言,其字形蕴含了丰富的意义信息。然而,主流的嵌入表示计算方法[6](连续词袋模型、Skip-Gram 模型等),均无法抽取中文字符蕴含的字形信息。
针对这一问题,主要有两种思路:
第一种思路,以Yuxian Meng 等人(2018)[7]为代表,从视觉角度来抽取字形信息;第二种思路,以Dong 等人(2016)[8]为代表,从字符的部首组成角度来抽取字形信息。
1.1 视觉角度利用字形信息
Yuxian Meng 等人(2018)[7]提出了Glyce 模型,从两个方面入手充分抽取字形信息。
在数据方面:汉字有着悠久的进化历史。经历数次简化的现代中文,已经丢失了大量的象形文字信息。通过收集不同历史时期(金文、隶书、篆书、魏碑、繁体中文、简体中文)、不同书写风格(宋体、草书、隶书)的文字,来整合各种象形文字的特征并提高模型的概括能力。
在模型架构方面:相较于其他任务汉字字符图像的尺寸较小,这导致使用普通CNN 的性能不佳。通过采用适合汉字字符嵌入任务的田字格-CNN 架构,提高模型抽取字形信息的能力。
1.2 部首组成角度利用字形信息
一个汉字字符通常可以分解为多个部首。这些部首是构成汉字意义的最基本单位,是汉字的内在特征,具有附加的语义信息。含有相同部首的字符通常具有相似的意义。如“铁”、“铜”和“金”都具有与金属相关的意义,因为它们含有共同的部首“金”。利用部首信息可以使具有相似部首序列的字符在向量空间中彼此靠近。
Dong 等人(2016)[8]提出了基于BLSTM-CRF 的部首模型,将汉字字符分解为部首序列。
对于一个汉字字符:首先,将其分解为一系列较小的部首。其次,利用汉字的书写顺序,将组成该汉字的部首排成一个部首序列。再次,对部首序列应用双向LSTM 进行处理,得到两个方向的状态序列。最后,连接两个方向最后时刻的状态作为字符的嵌入。
2 利用词汇信息
目前,最先进的NER 系统通常以单词为操作单位。当应用于中文文本时,首先要使用现有的中文分词系统对文本进行分词,然后对单词序列进行标记。然而,中文分词系统不可避免地会产生一些错误,进而对NER 任务产生负面影响。
针对这一问题,主流思路为:使用以字符为操作单位的模型,同时借助词汇特征来使用单词边界信息。目前,针对该思路主要有两种建模方法:
第一种方法,以Zhang 和Yang(2018)[9]为代表,基于序列建模,使用LSTM 的一种变体。
第二种方法,以Gui 等人(2018)[10]为代表,基于图模型。
2.1 基于序列建模
Zhang 和Yang(2018)[9]介绍了一种长期短期记忆网络(Lattice LSTM)的变体(如图1 所示),联合建模字符序列及其所有匹配的单词,充分利用了词汇的边界信息。模型基于字符的LSTM-CRF 网络,借助Lattice LSTM 将单词信息集成到单词的开始字符和结束字符之间的一个快捷路径中。Lattice LSTM 中的门控单元可以将词汇信息从不同路径动态路由到每个字符,自动控制句子从开始到结束的信息流动。通过训练,Lat⁃tice LSTM 可以学会自动从上下文中查找更多有用的单词,从而获得更好的性能。
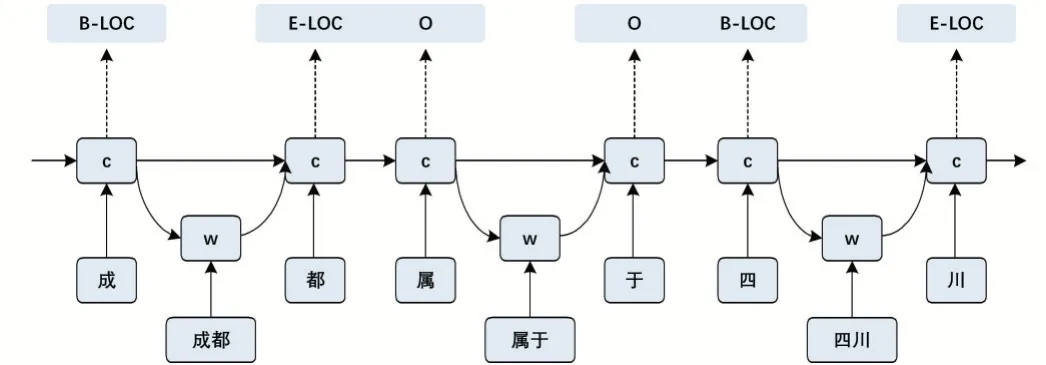
图1 Lattice LSTM模型
该模型存在着一些问题:①门机制有时无法选择正确的路径,极端情况下可能会导致模型退化为部分基于单词的模型。②每个字符都有一个可变大小的候选单词集,这意味着输入和输出路径的数量是不固定的。在这种情况下,Lattice LSTM 模型失去了批训练的能力。
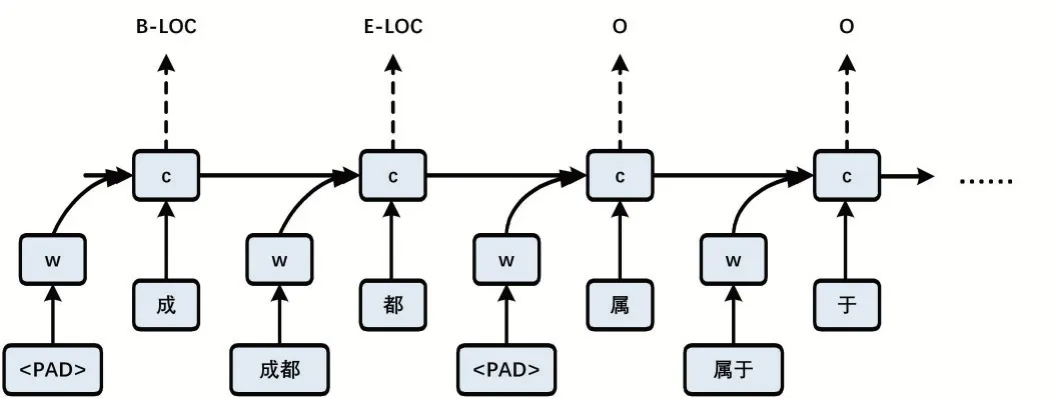
图2 WC-LSTM模型
Liu 等人(2019)[11]针对上述问题,提出了WCLSTM 模型(如图2 所示)。针对模型退化问题:直接将单词信息分配给单个字符(前向WC-LSTM 的结束字符和后向WC-LSTM 的开始字符),并确保字符之间没有快捷路径。针对批处理问题:引入四种策略从不同的单词中提取固定大小的有用信息,保证模型在不丢失单词信息的情况下进行批量训练。
发动机 ....................................................................4.0升水平对置6缸自然吸气
2.2 基于图建模
Gui 等人(2019)[10]介绍了一种图神经网络(如图3所示),利用词汇信息将句子转换为有向图,并将中文NER 作为节点分类任务来实现。
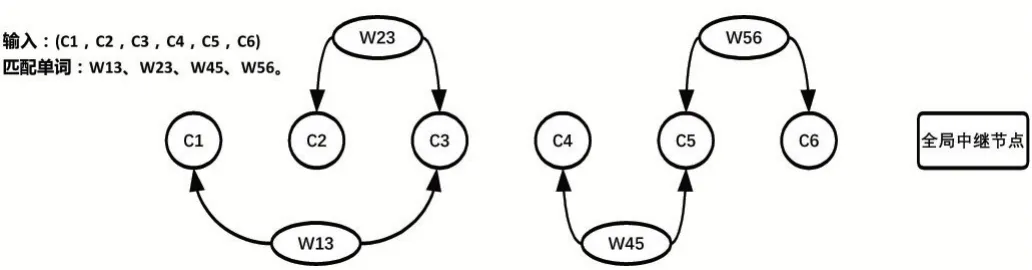
图3 基于词汇的图神经网络模型
给定词典和输入句子,将句子转换为有向图分为三个步骤:第一步,找出句子中与词典匹配的单词集合。第二步,将每个字符作为有向图的节点。第三步,对于匹配的每个单词,将其第一个字符和最后一个字符连接起来作为有向图的边。
有向图中每个节点的状态表示文本序列中对应令牌的特征,每个边的状态表示对应的匹配单词的特征。有向图中还存在一个全局中继节点,其连接所有节点和边,收集句子的全局信息。
3 利用跨域跨任务信息
目前,最先进的NER 系统通常基于神经网络。高性能神经网络通常需要在一个非常大的标注数据集上进行训练。在命名实体识别中,通常没有足够的领域内标注数据来直接训练模型。现有的中文NER 数据集包括TAC-KBP/EDL Track(2015-2017)、ACE 2005、SIGHAN bakeoff 2006 NER MSRA、微博NER 等。总的来说,中文NER 数据集的总量较少,各个数据集的内容类型(新闻、广播、微博)和标注的实体类型不尽相同。
针对这一问题,主要有两种思路:
第一种思路,利用其他域的标注数据集。目前,中文NER 主要集中在正式文本(新闻)、非正式文本(微博、邮件等)两个领域。因为标签分布的差异,不能直接将源域上训练的模型应用到目标域。借助领域适应技术,充分利用源领域丰富数据,提高目标领域的性能。
第二种思路,利用其他任务的标注数据集。与NER 相比,中文分词(CWS)的标注训练数据量非常丰富。鉴于两个任务存在一些相似性,可以尝试使用中文分词任务的信息来改进中文实体识别任务的性能。
3.1 利用其他域的标注数据集
第一种方法(如图4 所示):以Lee 等人(2017)[12]为代表,目标域和源域使用相同结构的模型。具体步骤为:首先,使用来自源域的标注数据来训练模型;然后,使用学习到的参数来初始化目标模型;最后,使用来自目标域的标注数据来优化初始化的目标模型。
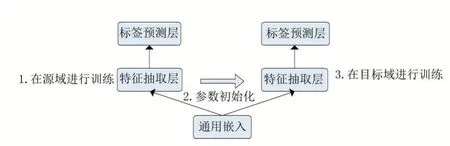
图4 参数初始化方法
第二种方法(如图5 所示):以Yang 等人(2017)[13]为代表,基于多任务学习,使用目标域和源域的标注数据同时训练两个模型。除CRF 层外,两个模型在训练过程中共享其他参数。
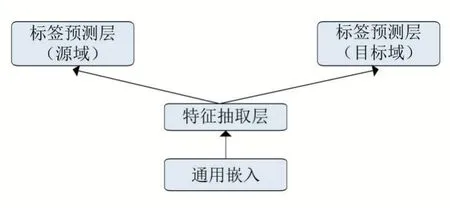
图5 类多任务学习方法
上述两种方法存在一个共性问题:针对源域和目标域进行训练时,模型使用通用的嵌入。这样的操作基于一个假设:输入特征空间没有发生域移位。然而,当两个领域具有明显不同的语言风格并且涉及大量领域特定的术语时,这样的假设可能是错误的。
针对这一问题:第一步,我们在源域和目标域的标注数据集上分别进行训练,得到两个领域特定的嵌入。第二步,引入单词适应层(Lin 等人,2018)[14],将目标域嵌入空间中学习到的嵌入内容投影到源域嵌入空间中。
3.2 利用其他任务的标注数据集
中文分词(CWS)的任务是识别单词边界。中文NER 的任务可以分解为识别单词边界和判断实体类型两个部分。两个任务存在一定的相似性,也存在着一些差别。
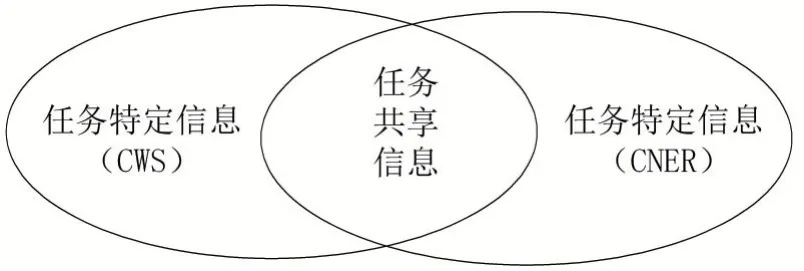
图6 中文分词任务与中文命名实体识别任务
将两个任务共享的信息称为任务共享信息,将任务单独使用的信息称为任务特定信息。我们的目标是最大化的利用中文分词任务中的任务共享信息,同时过滤掉中文分词任务的任务特定信息。
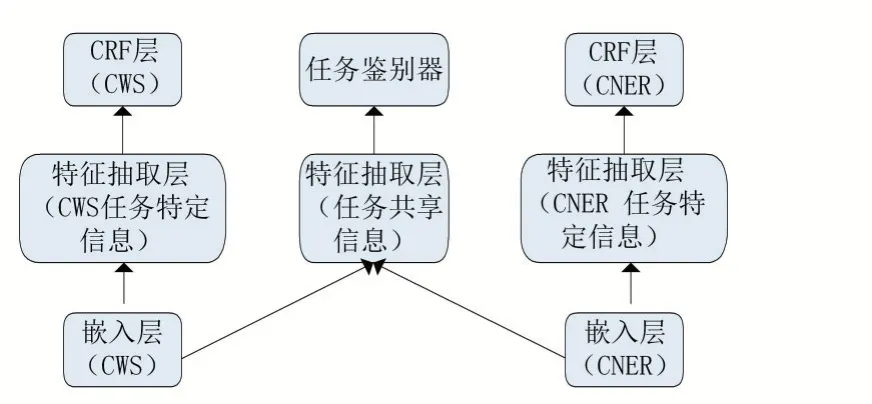
图7 对抗性迁移学习模型
针对这一目标,以Cao 等人(2018)[15]为代表,提出了对抗性迁移学习模型(如图7 所示)。模型由四个部分组成:分别为嵌入层、特征抽取器、CRF 层、任务鉴别器。
嵌入层将输入的字符序列转换为嵌入表示序列,两个任务各自使用独立的嵌入层。
特征抽取层使用BLSTM 和注意机制进行信息抽取,由任务特定信息(中文分词)、任务特定信息(中文NER)、任务共享信息三个部分组成,分别抽取两个任务的任务特定特征、任务共享的单词边界特征。
任务特定CRF 层使用特征抽取层抽取的任务特定信息和任务共享信息进行标签预测,由任务特定CRF 层(中文分词)、任务特定CRF 层(中文NER)两部分组成。两个任务各自使用独立的CRF 层。
任务鉴别器使用任务共享信息来判断句子来自于哪个任务的数据集。当任务鉴别器无法判断句子的来源时,意味着模型已经将任务特定信息和任务共享信息区分开来。
4 结语
在针对中文的NER 算法中,研究人员已经提出了各种算法来解决中文的特殊性。本文介绍了,利用中文字符字形信息的嵌入表示方法、利用中文词汇信息的模型架构和利用其他任务、其他域的标注数据的方法。未来如何进一步提高中文NER 任务的性能,值得研究人员进一步去探索。
猜你喜欢
小学生学习指导(低年级)(2021年3期)2021-07-21
校园英语·月末(2021年13期)2021-03-15
电脑知识与技术(2019年29期)2019-12-16
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
作文周刊·小学二年级版(2019年12期)2019-04-26
课堂内外(初中版)(2018年12期)2018-03-08
学苑创造·A版(2014年7期)2014-11-15
