
基于姿态的时装图像合成研究
2020-11-18 14:00徐俊哲陈佳何儒汉胡新荣
现代计算机 2020年28期
徐俊哲,陈佳,2,何儒汉,2,胡新荣,2
(1.武汉纺织大学数学与计算机学院,武汉430000;2.湖北省服装信息化工程技术研究中心,武汉430000)
0 引言
近年来,人工智能在服装设计上的应用得到迅速发展,例如在虚拟现实、可穿戴技术和虚拟试衣间等方面的应用。为了吸引在线购物者并提供丰富和直观的在线体验,销售商努力提供高质量和信息丰富的服装图片。在线购物者通常希望从不同的角度看到多件服装商品的照片,或者从不同角度或以不同姿势看到穿着同一服装的时装模特的多张照片,在这种情况下,可以利用图像合成技术来增强购物者的购物体验并降低零售商的成本。时尚服装对款式、颜色、风格和纹理等搭配具有较高要求,姿势引导的图像生成最近引起了极大的关注,它在保持外观细节的同时,将人的姿势更改为目标姿势。
传统的服装图像合成技术只能处理简单的纹理,规则图像的合成。随着深度卷积神经网络的出现,变分自编码器(VAE)[1]的提出,在一定程度上提高了合成图像的质量。Goodfellow 等人[2]提出的生成对抗网络进一步提升了图像合成的真实性。然而这些方法主要着重于保持服装的纹理和外观的固有属性,忽略了在实际中人体不同姿态下着衣的效果,因此本文引入一个由姿态引导的服装图像合成框架,能够很好地展示目标姿态下服装的效果。
该方法首先设计了一种新型的语义编码器,将原图像的语义掩模图和目标姿态以及目标姿态mask 作为输入,提取语义特征,然后使用纹理编码器提取纹理特征,最后将纹理特征和语义特征进行充分融合得到逼真的服装图像。本文方法有效利用了以人体语义掩模图为引导,完成目标姿态下的人体服装图像生成,有效地简化了输入与输出的形状映射关系学习,并对保持衣物的原始属性(纹理、风格、款式等)提供了先验知识。
1 相关工作
针对服装图像合成问题,根据处理的方法不同可分为两类:①基于传统卷积神经网络的方法,例如Gatys[3]等人利用卷积神经网络将不同风格通过迁移学习到图像的语义内容,通过内容和风格的结合重构出新的风格图像;②基于生成式对抗网络的方法,由Goodfellow 等人在2014 年提出的一种无监督的学习方法,使用两个神经网络相互对抗博弈,利用反向传播实现端到端的更新训练,改善了生成模型的效率和训练难度。Bousmalis 等人[4]提出一种基于GAN 的非监督的图像合成方法,引入基于特定任务的损失函数和内容相似性损失函数来学习生成图像。由于GAN 的训练问题比较复杂,Park 等人[5]提出利用真实图像与生成图像间的流形进行匹配以获得良好的生成效果。Sang⁃kloy 等人[6]提出利用纹理信息约束的生成网络来完成图像的合成。
为了帮助消费者能在不同姿势条件下看到穿着同一服装的时装模特的多张图片,并且能够降低零售商的成本,因此本文提出基于生成对抗网络和姿态相结合的服装图像合成框架。该框架能将指定服装映射到新姿势上,生成目标姿态下的人体服装图像,而且同时保持人体服装图像的外观特征。
2 基于姿态的服装图像时尚性研究
2.1 服装图像合成框架
系统测试时的结构如下:首先将服装图像x(q)及其关联的语义掩模图m(q)映射到纹理特征t(q)和语义特征s(q)。然后,使用编辑模块F++逐步的将t(q)和s(q)更新为t++和s++,以提高服装的时尚能力。最后,基于t++和s++,系统会生成通过编辑后的服装x++的伪图像。具体步骤如图1 所示。
图1 展现了本文设计的一种新型服装图像合成框架,此框架考虑到姿态和纹理两个方面,在右上方虚线方框中通过引入姿态,提出了一种服装图像的语义特征提取框架,将目标姿态Pt 与目标姿态掩模图Mpt 融入到语义编码器Es 中,进行语义特征的提取。
2.1.1 生成纹理特征
输入图像x(q)是一张穿衣服的人的真实全身照片。伴随着区域映射m 将每个像素分配给衣服或身体部位的区域。本文使用在Chictopia10k[8]定义的n=18个唯一区域标签:脸、头发、衬衫、裤子、衣服、帽子等。首先将x 输入到一个学习的纹理编码器Et:X→V中,该编码器输出特征图v。编码部分采取VGG16 网络提取服装的纹理特征。令ri为与标签i 相关联的区域,并对ri进行平均池化操作来获取纹理特征整个服装的纹理特征表示为t:=[t0;…;tn-1]∈ℝn·dt。
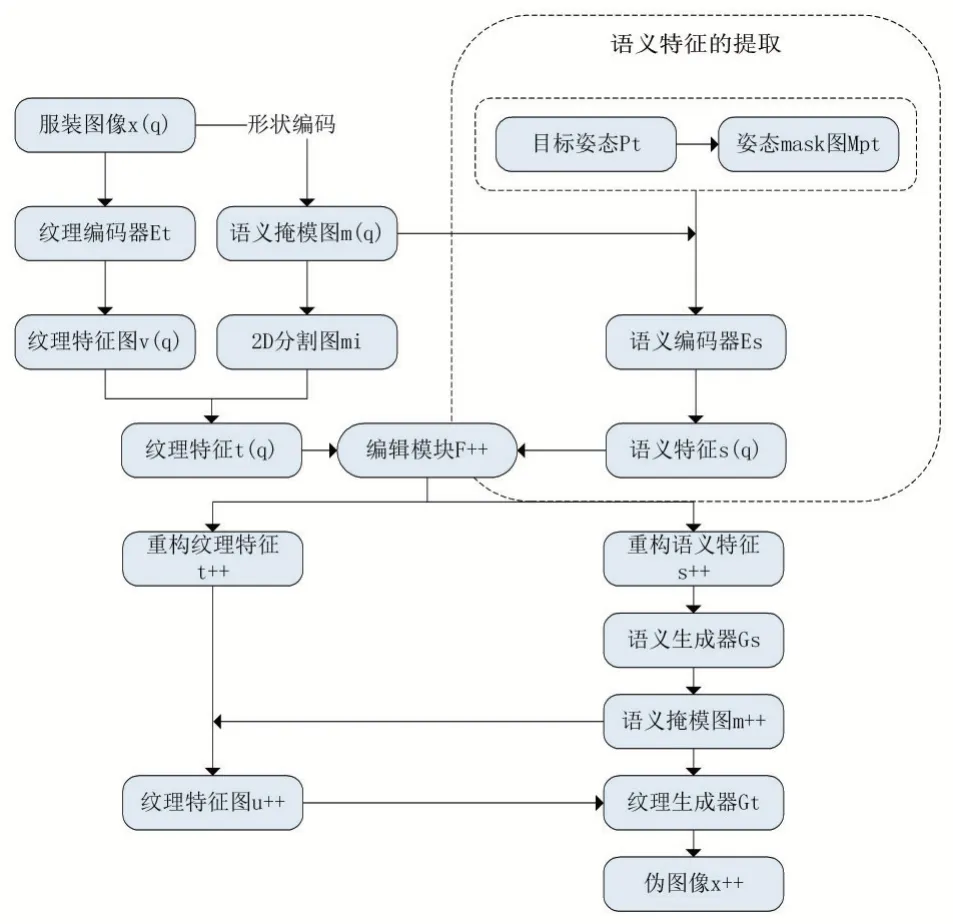
图1 服装图像合成框架
2.1.2 目标姿态嵌入并编码
为了避免昂贵的姿态注释,本文利用了最新的姿态估计器[9]来获取近似的人体姿态,即目标姿态pt。模型学习将每个关键点映射到人体的某个位置,将姿态pt 编码为若干个heatmaps,每个heatmaps 在对应关键点周围半径为4 的像素中填充1,其他位置则填充0(请参看图2,目标姿态)。由于只有语义掩模图和目标姿态作为输入,如果目标人体服装图像和原人体服装图像背景不同,则模型生成背景较困难。为了减轻背景变化的影响,于是添加了另一个姿态掩模图Mpt,从而赋予了人体比背景更多的权重。姿态掩模Mpt 的前景设置为1,背景设置为0,是通过将人体部位和运用一组形态学运算计算得出,以便使其易于覆盖目标图像中的整个人体(参看图2)。
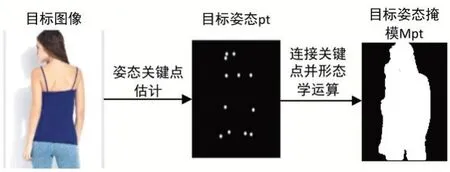
图2 目标姿态图和目标姿态掩模图
2.1.3 编辑模块
由2.1.1 产生的纹理特征t(q),2.1.2 产生语义的特征s(q),使用一个编辑模块F++逐步的将t(q)和s(q)更新为t++和s++,以提高服装的时尚能力。编辑模块是一种用于编辑操作的时尚性分类器(MLP),其结构定义为:fc256、fc256、fc128、fc2。其中fck 表示具有k 个fil⁃ters 的完全连接层。为了进行时尚性分类器编辑,使用学习率为0.1 的SGD 优化器。
F++返回编辑后的版本:

2.1.4 构建服装图像
本文首先使用语义生成器Gs 接受全身语义特征s并生成一个图片大小的区域映射m∈M。然后执行区域范围的广播,将ti广播到带有标签i 所有在映射m̂上的位置,获得纹理特征图u=F_broad(t,m)。最后,再将u 和映射m̂进行通道连接,来构造纹理生成器Gt 的输入,生成最终的服装图像x++。生成器Gt 和Gs 学习重建以纹理和语义特征为条件的服装图像。
2.2 语义编码器和生成器
针对服装语义特征提取和语义掩模图重建网络模型(参看图3),本文提出一种新型VAE-GAN 结构(如图4),属于一种基于自编码器的GAN,能够通过GAN来强化自编码器,以便生成清晰的图像。语义编码器采用pix2pixHD[10]网络结构提取语义特征,语义生成器采用BicycleGAN[11]网络结构生成语义掩模图。
语义编码器的网络结构定义为:p3,c7s1-16,d32,
d64,d128,d128,d128,d128,d128,R128,R128,R128,R128,R128,R128,R128,R128,R128,fc8;语义生成器的网络结构定义为:d128,d128,d128,d128,d128,d64,d32,d16,p3,c7s1-18。其中c7s1-k 表示一个具有k 个filters 且步幅为1 的7*7 卷积块,dk 表示一个具有k 个filters 且步幅为2 的3*3 卷积块,Rk 表示一个残差块,包含两个具有k 个filters 的3*3 卷积块。pk 表示在所有边界上的填充3。fck 表示具有k 个滤波器的完全连接层。
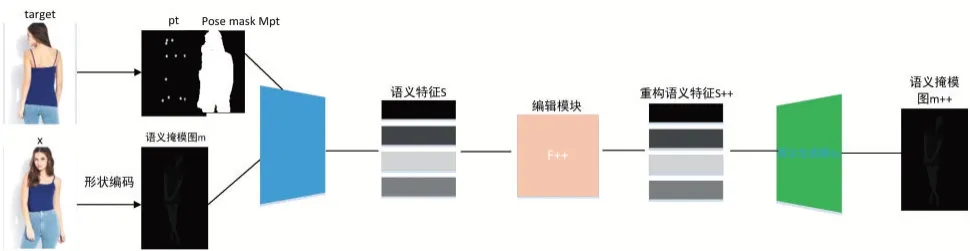
图3 服装语义特征的提取及语义掩模图重建模型
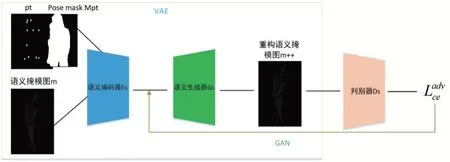
图4 服装VAE-GAN模型

在训练过程中的损失函数主要包括交叉熵函数和对抗损失函数。其中,交叉熵损失函数用来监督转换后的语义掩模图的生成,对抗损失函数能使生成的语义掩模图在视觉效果上更加真实。
交叉熵损失函数可以描述为:
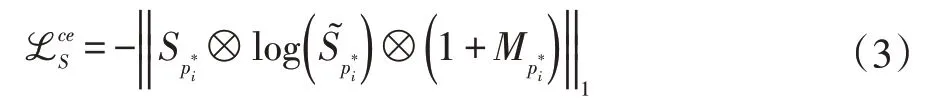
使用带有鉴别器的对抗损失来生成更加现实的视觉风格语义图:
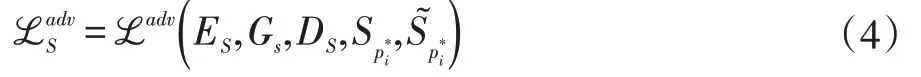
因此,整个语义模块的损失函数写为:

2.3 纹理生成器
对于图像合成部分,本文采用一种基于cGANS[12]的方法,该网络采用分割标签映射和相关特征映射来生成逼真的图像。将纹理编码器Et和纹理生成器Gt与鉴别器D 相结合,形成了一个cGAN。Gt(m,u)生成图片,其中u=F(Et(x),m),并且F 是池化、全部i与F_broad 的合并操作,鉴别器D 的目的是区分真实图像和生成图像。Et,Gt 和D 通过极大极小对抗博弈方式同时学习。
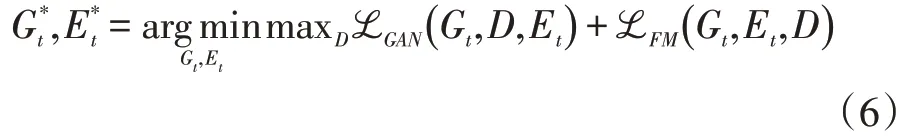
其中L_GAN:
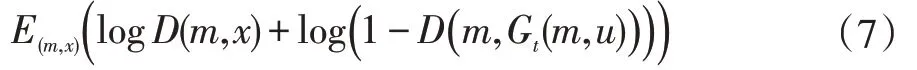
对于所有训练图像x,ℒFM表示特征匹配丢失。
3 实验
3.1 数据集
为了测试该模型的效果本文使用DeepFashion[13]数据集中的In-shop Clothes Retrieval Benchmark 数据集。它包含大量具有各种外观和姿势的服装图像,分辨率均为256×256。DeepFashion(In-shop Clothes Re⁃trieval Benchmark)数据集由52712 个店内衣服图像和200000 个交叉姿势/尺度对组成。选择146600 对图像作为训练集,每对数据集是由同一人但姿势不同的两个服装图像组成,并从测试机中随机选择12000 张图像进行测试。In-shop Clothes Retrieval Benchmark 数据集如图5 所示。
本文还尝试了更具了挑战性的重新识别数据集Market-1501[14],其中包含从六个不相交的监控摄像机捕获的1501 人的32668 张图像,图像的分辨率为128×64。该数据集中的人在姿势、光照、视点和背景各不相同,这使得人的生成任务更具挑战性。选择439420 对数据作为训练集,每对数据集是由同一个人但姿势不同的两个服装图像组成,并从测试集中随机v 选择12,800 对进行测试。

图5 服装数据集示例图
3.2 实验结果
为了体现本文采用得方法在服装图像合成上的性能优越性,进行了一系列对比实验。本文使用ADAM[15]优化参数,将学习率设置为0.0002,批次大小为30。
3.2.1 评价指标
在图像合成中,通常采用初始得分(IS)[16]和结构相似性(SSIM)两个重要指标来衡量图像合成质量。对于在Market-1501[17]数据集中,条件图像和目标图像会有不同的背景,对图像合成结果的评估会产生影响。针对这个问题,就需要采用mask-IS 和mask-SSIM[18]。
3.2.2 与最新方法比较
为了验证本文提出的方法在图像合成质量上有更好的效果,选择了在图像合成方面常用的一些方法进行实验对比,该文使用了PG2[18],Def-GAN[19]和UPIS[20]这三种最新方法进行了定性比较。PG2和Def-GAN 是需要配对训练数据的监督方法。UPIS 是基于无监督的方法,该方法本质上采用CycleGAN[21]。
如图6 所示,对于DeepFashion,首先将本文的方法与PG2比较可以看出,本文的方法生成的服装图像更自然,并且能够保留衣服纹理。其次与Def-GAN 进行比较,本文的方法成功地渲染了条件图像中看不见的部分纹理,并且在保留衣服纹理方面更出色。最后与UPIS 方法对比,本文的方法合成的图像更自然真实。对于Market-1501(参看图7),使用相同的方式比较,与PG2方法相比,本文方法生成的人体形状更清晰。与Def-GAN 方法比较,本文方法可以产生更清晰的身体形状,并更好地保持衣服的属性。与UPIS 方法比较,本文的方法生成的图像视觉上更自然,伪像更少。因此,在DeepFashion 和Market1501 数据集上,本文的方法在保持服装纹理和产生更好的人体轮廓方面具有更好的优越性。
为了验证该方法在图像合成质量上的优越性,评估了不同的服装图像合成方法合成图像的质量。在表1 中,使用初始得分(IS)和结构相似性图像测量(SSIM)进行定量评估。对于Market-1501 数据集,为了减少背景对评估的影响,还采用了mask-IS 和mask-SSIM,在计算IS 和SSIM 时不包括背景区域。为了公平比较,标记了每种方法的训练数据要求。总体而言,即使与其他方法相比,本文提出的模型也能在两个数据集上实现最佳的IS 值,这与更真实的细节和更好的身体形态相吻合。该方法的SSIM 得分略低于其他方法,这可以通过以下事实来解释:模糊的图像始终可以获得较高的SSIM,但照片逼真度较低。
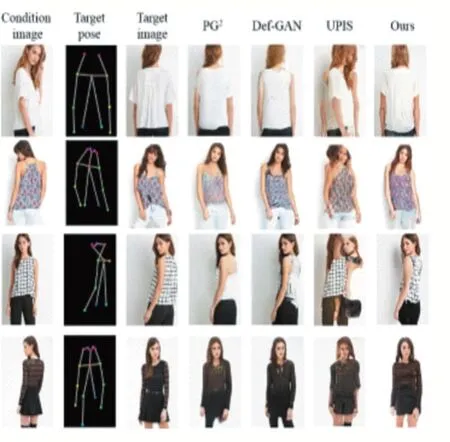
图6 在DeepFashion 上通过不同方法(PG2、Def-GAN 和UPIS)比较示例图

图7 在Market-1501 上通过不同方法(PG2、Def-GAN 和UPIS)比较示例图
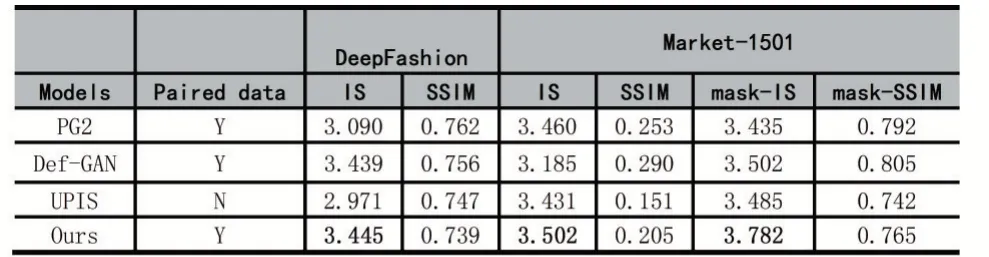
表1 本文的方法与PG2、Def-GAN 和UPIS 方法合成服装图像的定量比较结果
从表1 中可以得出,在DeepFashion 和Market-1501 数据集上,本文的方法在初始得分值(IS)上优于PG2、Def-GAN 和UPIS 三种方法,证明本文方法能合成更加高质量的逼真的服装图像。
4 结语
本文提出基于姿态的服装图像合成模型,以解决通过人体服装图像和目标姿态来进行合成的新任务,来满足合成图像从原姿态向目标姿态的转换。实验表明,本文所提出的模型能够在保留服装属性和塑造人体形状上生成就具有更高视觉质量的图像。在未来的工作中,我们计划在人体姿态和服装属性上产生更多可控和多样的人体服装图像。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
学生天地(2020年3期)2020-08-25
保健与生活(2019年7期)2019-07-31
小资CHIC!ELEGANCE(2018年33期)2018-11-08
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
长江学术(2016年4期)2016-03-11
诗选刊(2015年4期)2015-10-26
长江学术(2015年1期)2015-02-27
电影新作(2014年5期)2014-02-27
