
一种基于6Gen 算法的IPv6 地址生成方法
2020-11-18 14:00孙亚洲胡洛林
现代计算机 2020年28期
孙亚洲,胡洛林
(中国人民解放军66018 部队,天津300380)
0 引言
随着全球IP 地址空间探测的不断推进,网络测量工作的发展日新月异,取得了很大的成就。由于IPv4地址空间的密度和规模有限,以现在的扫描速度,研究人员已经能够利用相关工具完全枚举所有可能的IPv4地址[1],从而实现对IPv4 地址空间的全面探测。然而,IPv6 具有更大的地址空间,以目前的扫描与计算能力,想用同样的办法来对它进行彻底的探测是完全不可行的[2]。保守估计,如果以每秒完成一次探测来算,完整的IPv6 探测可能需要大约50 亿年才能完成。因此,如何获得某种程度上的全面的IPv6 地址情况成为一道难题。对IPv6 网络地址生成算法的研究,能为IPv6测量提供更多更好的有效地址数据,减少对无效地址的测量,削减资源的浪费,同时还能提高效率,让研究人员获得某种程度上的全面的IPv6 地址情况。
目前IPv6 地址生成方面已有的研究工作大致可以分为三类。一是研究从可公开访问的数据源(如DNS 记录)中提取IPv6 地址的方法。Fiebig 等人通过递归查询PTR 记录中的地址前缀,从DNS 服务器中挖掘IPv6 地址[3];Gasser 等人研究从各种主动和被动来源收集更广泛的地址,这些来源包括欧洲互联网交换节点的网络分流器和慕尼黑科学网的上行链路、Rapid7和Caida 的DNS 数据集等[4]。这种方式工作量巨大且存在较大的局限性。二是识别已知地址以掌握其IPv6地址分配模式,进而获得活跃主机地址。Czyz 等人通过在Rapid7 DNS Any 数据集中对域名执行DNS A 和AAAA 查询识别出了520K 个双栈服务器,并对CAI⁃DA Ark 路由测试数据集里的主机执行相同的DNS 查找,找到了25K 个双栈路由器[5];Plonka 和Berger 提出了一种从给定的可用于扫描的地址中识别密集网络前缀的方法[6]。这种方法仅考虑了网络前缀,而没有覆盖任何地址空间区域。三是设计能够生成待探测地址的算法。Ullrich 等人开发了一种递归算法,以一组种子地址和一个阈值N 作为输入,并确定IPv6 地址范围中除N 位以外的其余所有位的值[7];Foremski 等人提出了一种在一组IPv6 地址上集中发现地址结构的Entropy/IP 算法[8]。这些算法目前看来产生了一些效果,但总体上讲效率仍不够高。
鉴于已有的几种方法存在的问题,Austin Murdock等人提出了一种6Gen 算法[9]。这种算法尽可能多地将相似的种子聚类到具有高种子密度的地址空间区域,并最终将这些区域的地址作为扫描目标输出,从而获得大量的有效IPv6 地址。实验表明该算法效率较高,逻辑简单,具有很强的实用性。
1 算法思路
通常在考虑IPv6 地址生成的算法时,一般的思路是尝试反向分析IP 分配方案[10]。然而,这种方法有几个难点:一是从有限数量的种子地址中确定IPv6 地址分配模式比较困难;二是在一个网络中同一地址空间区域的IPv6 地址可能使用了多个分配策略(例如基于主机类型等);三是难以确定不同的独立网络之间的界限。
IPv6 网络地址生成算法试图挖掘已知地址的分布结构,并以此生成其他候选地址。二者之间极可能是依赖的,也可能是独立的。在依赖模型中,种子地址之间存在依赖关系。因此,种子集里某个特定地址的存在可能影响了某些非种子地址是否是活跃地址的概率。在这种情况下,一个简单的思路是算法可以对种子或者每个网络前缀根据线性模型来产生目标地址。在独立模型中,种子集被视为现实中活跃主机地址的独立同分布(IID)随机样本。可以认为在这种情况下,现实里活跃地址密度最高的空间区域在种子集里也具有最高的种子密度。与依赖模型不同的是,独立模型对特定种子的观察并不影响其他潜在的活跃地址的状态。
6Gen 算法考虑到了上述问题,它采用了独立模型,并假设种子的稠密区域与现实中活跃地址的稠密区域是正相关的,将种子地址视为活跃地址的独立同分布随机样本[11]。算法识别种子的密集区域。这种方法与假设种子地址之间存在依赖关系的方法明显不同,它可以使IPv6 地址生成更简单和更灵活。
6Gen 算法的原理可以概括如下:算法尽可能多地将相似的种子地址聚类到具有高种子密度的地址空间区域,并最终将这些地址区域内的地址作为生成地址输出。该算法可以迭代操作,首先识别最相似的种子,然后将能够形成最密集区域的种子聚集在一起,直到聚集区域的规模增长到超过事先设定的扫描预算[12]。也就是说,算法将扫描预算分配给具有许多类似种子的“热点”区域。在种子密度与活跃主机密度正相关的假设下,这样可以使生成的IPv6 地址的有效性大大提高。此外,目前的6Gen 算法没有学习模式[13]。
需要注意的是,6Gen 算法并不是纯密度驱动的。它首先要识别相似的种子,然后才将它们聚集成密集区域。事实上,也许在距离较远(即相似度不那么高)的种子之间聚类可能产生更高密度的区域,但6Gen 优先考虑相似性。之所以如此,主要是为了节约预算,因为越相似的种子形成的集群区域越小,消耗的预算也更少。
2 算法分析
2.1 概念定义
2.1.1 距离度量
为了聚类相似的地址,6Gen 算法定义了一个地址相似性的度量。这个度量使用地址之间的nybble(半字节)级的汉明(Hamming)距离来表示。
该度量计算两个地址之间不同的nybble 位置数。为了计算IP 地址空间中两个区域之间的距离,算法定义其他数字与通配符(?)的距离为零。例如:
3002:db6::73 和3002:db6::71 之间的距离是一;
3002:db6::73 和3002:db6::7?之间的距离是零。
可以看到,如果将两个地址聚集在一个范围内,产生的新的动态地址的数量等于Hamming 距离的数值。如:3002:db6::73 和3002:db6::7?之间的距离是零;将这两个地址聚集在一个范围内后可以用3002:db6::7?来表示,此时产生的新的动态地址的数量也是零。二者在数值上是相等的。
直观地说,这个度量可以表明地址之间的相似程度,如果距离度量很大,则显然我们需要更大的区域来封装它们。
图1 中的地址有三个nybbles 不同,可以形成3 个动态地址,可以用一个范围4::?:?0?来表示。
算法在nybble 粒度上计算距离的原因是寻址方案可能在这个程度上进行分配[14]。同时,nybble 粒度可以帮我们找到位级汉明距离一样时,直观上看起来不太相似的地址对。例如,2::20 和201::相隔两位,2::和2::3也是相隔两位。然而直观上看第二对更为相似,因为它们都在2::?这个范围内[15]。
2.1.2 簇范围
如图1 所示,6Gen 使用一个地址范围将种子封装在集群(即簇)中。虽然用通配符(?)能接受任何合法值来表示IPv6 地址的范围,但是算法也允许使用有界值的通配符,即用[1-2,8-a]这种语法表示特定的nybble值范围[16]。
图2 展示的是用通配符创建和发展地址范围的过程。
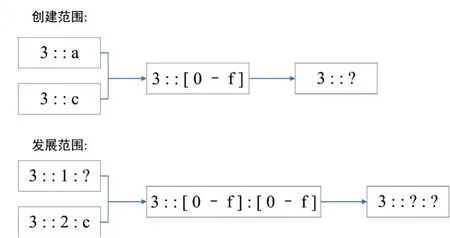
图2 生成范围
2.2 算法描述
2.2.1 簇初始化
6Gen 接受一组种子地址输入,并以此产生一组集群。集群由一个能包含该集群中种子的地址空间区域范围和一个位于集群范围内的种子集构成。算法为每个种子实例化一个集群,包括单个种子的集群。集群的生长是独立的。在每次连续的迭代中,算法都计算集群添加下一个最紧密的种子后会产生的影响。此外,算法不会合并类似的集群。相反,它允许种子属于多个集群。如函数InitClusters 所示。
代码1:


2.2.2 簇的生长
算法首先根据Hamming 距离来识别离每个集群最近的种子,如函数FindCandidateSeeds 所示。
代码2:

算法考虑将所有最小等距的非簇种子作为候选种子。每个候选种子的潜在簇将开始增长,簇范围将扩大,潜在地将候选种子之外的其他种子也包含进来,从而使簇种子集生长。用生长的簇的完整种子集大小除以其范围大小,即可计算此时该簇的种子密度:
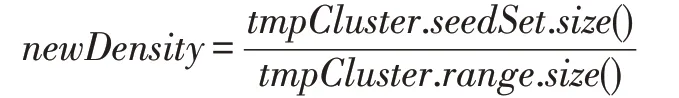
迭代结束时,算法生成一个能产生最高种子密度的簇和候选种子对。当多个增长选项可以导致相同的最大密度时,算法优先考虑选择范围较小的生成簇,因为消耗的预算更少。
这个过程如函数GrowtCluster 所示。
代码3:


2.2.3 生成地址
6Gen 算法会一直迭代,直到簇范围大小之和等于事先提供的探测预算或者所有种子都已属于某个集群。如果最后产生的那个集群超出了探测预算,算法会通过随机选择新增长的簇中不在已有簇预增长范围的地址来精确消耗预算。
需要指出的是由于簇在潜在增长时每个非簇种子都会被考虑,而且簇的增长是独立的,所以算法产生的簇可能会有重叠区域。此外,算法没有将部分重叠的簇合并,因为这可能会导致最后产生的簇的密度显著降低。算法6Gen 允许簇部分重叠,但会删除那些被另一个簇完全包含的簇。算法会将一个新生成的簇的范围与所有其他簇的范围进行比较,以确保不存在任何严格子集(真子集)。
代码4:


3 实验结果分析
3.1 实验环境
为了验证6Gen 的有效性,实验基于Python 语言初步实现了文中的算法原型。实验设定探测预算bud⁃get 为16 的5 次幂,即约100 万。实验选取P.Forems⁃ki 等人在Entropy/IP 算法中评估使用的Reports for Servers、Reports for Routers 的10 个数据集作为种子地址[17]。
每个种子数据集中包含50 个种子地址,其情况如
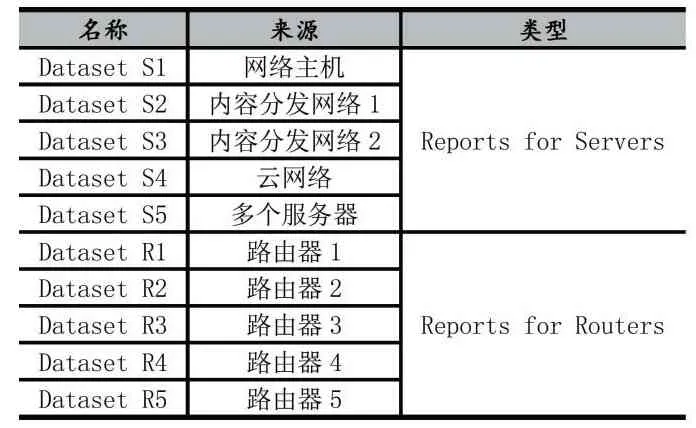
表1 种子集
3.2 实验结果及分析
对上述10 个数据集分别运行算法,得到的实验结果如表2 所示。
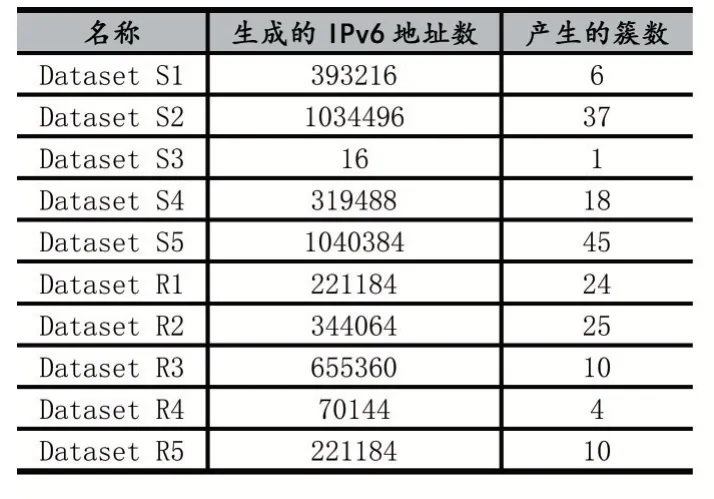
表2 运行6Gen 后的实验结果
例如,数据集Dataset R3 在运行算法后产生的簇有:
2001:0db8:00??:000?:000?:0000:0000:0012
2001:0db8:??0?:000?:0000:0000:0000:0001
2001:0db8:?10?:000?:000?:0000:0000:1fd8
…
等10 个,生成的IPv6 地址有:
2001:0db8:0000:0000:0000:0000:0000:0001
2001:0db8:0000:0001:0000:0000:0000:0001
2001:0db8:0000:0002:0000:0000:0000:0001
…
等655360 个。
分析表2 中的实验数据,可以看到,除Dataset S3外,几乎所有种子数据集在经过6Gen 算法运行之后,都生成了大量的新的IPv6 地址。其中在Dataset S5 数据集上更是生成了1040384 个IPv6 地址,这是原种子集中地址数目的约2 万倍。此外,与生成的IPv6 地址数量相比,簇的数量很少。运行算法后产生簇最多的是Dataset S5,有45 个,最少的为Dataset S3,仅有1 个。
不同类型和来源的种子集运行算法后的结果也有差别。如表3 所示,总的来说,来自服务器的种子集产生的地址数目要多于来自路由器的种子集。二者平均生成的IPv6 地址数相差超过了25 万,平均产生的簇相差6.8 个。需要指出,这些数据的计算都包含了Da⁃taset S3,如果将其排除,二者的差距将更加巨大。

表3 不同来源种子集的实验结果
根据实验结果,总的来说,6Gen 算法平均可以生成原种子集地址数量的8599.1 倍的IPv6 地址。其中,来自服务器的5 个种子集(Reports for Servers)平均生成的IPv6 地址数量是原来种子集地址的11150.4 倍,来自路由器的5 个种子集(Reports for Routers)平均生成的IPv6 地址数量是原来种子集地址的6047.7 倍。图3 可以直观地看出两种数据集在6Gen 算法下生成IPv6 地址的能力。
图3 生成IPv6地址能力的比较
在实验中,Dataset S3 仅仅产生了一个簇,生成了16 个IPv6 地址,这个结果显然存在异常。经过分析,可能是由于该种子集中地址分布较为特殊,导致算法在生成簇范围的过程中只产生一个簇就停止了迭代。这也说明算法在簇的产生方面还有待进一步优化。
4 结语
针对IPv6 地址生成存在的问题,研究了一种基于6Gen 算法的IPv6 地址生成方法。算法定义了一个使用地址之间的nybble(半字节)级汉明距离来表示地址相似性的度量,并使用一个地址范围将种子封装在集群(即簇)中。算法接受一组种子地址输入,并以此产生一组簇。算法迭代操作,首先识别最相似的种子,然后将能够形成最密集区域的种子聚集在一起,直到聚集区域的规模增长到超过事先设定的扫描预算。算法尽可能多地将相似的种子地址聚类到具有高种子密度的地址空间区域,并最终将这些区域内的地址作为生成地址输出。实验结果表明,6Gen 算法平均可以生成原种子集地址数量的8599.1 倍的IPv6 地址,这大大提高了IPv6 地址生成算法的效率。不同类型和来源的种子集运行算法后的结果也有差别,来自服务器的种子集产生的地址数目要多于来自路由器的种子集。下一步将根据实验结果中发现的问题,对算法在簇的产生方面进行进一步优化,同时对生成的地址结果进行活跃检测,以进一步评估算法的有效性。
猜你喜欢
农业工程学报(2022年11期)2022-08-22
北京航空航天大学学报(2021年4期)2021-11-24
小学生导刊(2018年34期)2018-12-18
思维与智慧·上半月(2018年11期)2018-11-30
知识就是力量(2017年2期)2017-01-21
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
母子健康(2015年1期)2015-02-28
延河(下半月)(2014年3期)2014-02-28
