
生物特征识别系统算法性能指标概述
2020-11-18 14:00高乾坤张鹏徐平徐骁张照星陈洁施一琳
现代计算机 2020年28期
高乾坤,张鹏,徐平,徐骁,张照星,陈洁,施一琳
(公安部户政管理研究中心,北京100070)
0 引言
生物特征识别系统是通过可测量的身体或行为等生物特征进行身份识别的系统。近年来,随着人工智能和大数据技术蓬勃兴起,生物特征识别技术方兴未艾,其识别准确性和识别速度得到很大提升,已经在社会各领域广泛使用。目前,在生物特征识别技术研究领域,学者们对不同生物特征提出了大量识别算法模型,他们在评价比较模型时也会使用不同评价指标。但相比较而言,关于生物特征识别系统算法评价评测体系方面的研究就很少,算法评测指标也不够系统全面,有些评测指标也仅停留在概念叙述阶段而没有形成具体化公式,甚至有些指标本身定义也有歧义或重复。本文通过收集国内外算法评价指标方面的文献和标准,试图将生物特征识别技术领域的算法评价指标全面化、一般化、公式化和形象化,并详细介绍具体指标的定义、意义和具体计算公式等,希望能对具体生物特征识别算法的评价评测和初次接触生物特征识别技术的人员有所帮助。识别比对准确性是整个生物识别系统的核心,因此相关指标是评价识别系统算法性能的主要参考。本文,我们首先介绍准确性的基本指标量,然后引出准确性的综合指标,最后介绍一些其他评价指标。
1 准确性基本指标量
对某一测试样本集,我们将在模板库已经注册对应身份的样本称为正样本(Positive sample),在模板库中没有注册对应身份的样本称为负样本(Negative sam⁃ple),那么测试样本集就由正样本和负样本两类组成。参考有关文献[1],并将阈值T 和比对结果分值排名k 引入进行改进,我们定义:
TP(T,k)为所有待测试正样本,经过算法比对,输出结果的前k名比中该测试正样本,且比中时分值大于等于阈值T情况的数量。
TN(T,k)为所有待测试负样本,经过算法比对,输出结果的前k名比对分值均小于阈值T情况的数量。
FP(T,k)为所有待测试负样本,经过算法比对,输出结果的前k名比对分值存在大于等于阈值T情况的数量。
FN(T,k)为所有待测试正样本,经过算法比对,输出结果的前k名中未比中该测试正样本或比中了但比中分值小于阈值T情况的数量。
当阈值T 给定、排名k 给定或不考虑排名时,我们将这四个值分别简记为TP、TN、FP和FN。
根据有关文献[1-3],我们将介绍以下与准确性相关的基本指标量。有些指标量的名称不同,但具体公式相同,我们将其归为一类;有些仅语言描述的也将其公式化。
1.1 正确率与错误率
正确率,也称为精确率或准确率,是指通过算法预测正确的样本在测试样本集中的占比,记为rateaccuracy,具体公式如下:
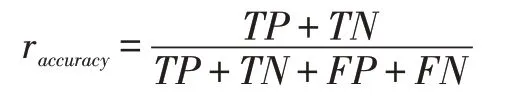
正确率是我们最常见的评价指标,通常来说,正确率越高,算法越好。但很多特殊场景还需考虑其他评价指标。
与之相对的是错误率,是指通过算法预测错误的样本在测试样本集中的占比,记为rerror。
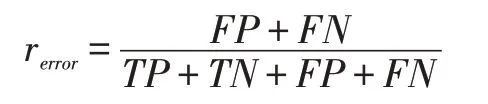
1.2 查准率
查准率,也称精度(Precision),是指所有被算法预测为正样本中确实是正样本的占比,记为P,具体公式如下:
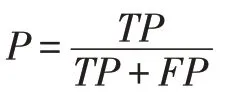
1.3 查全率
查全率,与召回率(Recall)、命中率(Hit Rate)、灵敏度(Sensitivity)和真正例率TPR 是同一个概念,是指所有正样本中,被算法预测为正样本的占比,记为R,具体公式如下:
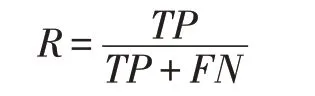
查全率用来衡量算法对正样本的识别能力,是算法覆盖面的一个度量。
1.4 假正例率与特效度
假正例率(False Positive Rate),简记为FPR,是指负样本被错误预测为正样本的数量在所有负样本中的占比,也称为错误预警率(False Alarm Rate),具体公式如下:
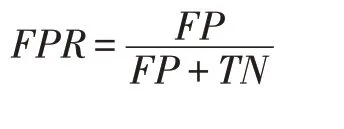
与之相对的是特效度,它是指所有待测负样本被算法预测为负样本的数量在所有负样本中的占比,用来衡量算法对负样本的识别能力,记为rspecificity,具体公式如下:
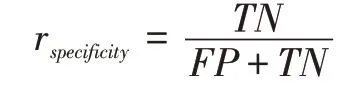
1.5 错误接受率与正确接受率
错误接受率(False Acceptance Rate),简记为FAR,是指被预测为正的负样本在所有预测为正的样本中的占比,具体公式如下:
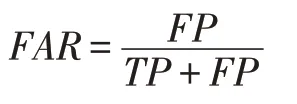
与之对应的是,正确接受率(True Acceptance Rate),简记为TAR,是指被预测为正的正样本在所有预测为正的样本中的占比,具体公式如下:
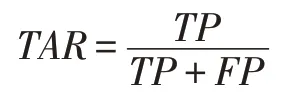
1.6 错误拒绝率与正确拒绝率
错误拒绝率(False Rejection Rate),简记为FRR,是指被预测为负的正样本在所有预测为负的样本中的占比,具体公式如下:
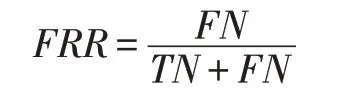
与之对应的是,正确拒绝率(True Rejection Rate),简记为TRR,是指被预测为负的负样本在所有预测为负的样本中的占比,具体公式如下:
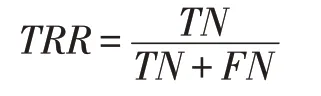
值得注意的是,在阈值T 给定情况下,我们可以通过某个或某些指标的概率来评价算法准确性;但当阈值T 未给定情况下,单独比较某个指标概率毫无意义。这时我们可以预先设定某个指标概率值,得到满足该指标概率值的不同算法的阈值T,再根据阈值T通过另一指标概率值的大小来评价算法准确性,如错误预警率十万分之一下的正确率等。
2 准确性综合指标
我们经常使用上述指标绘制成的相关曲线和一些其他综合指标来更加客观全面形象地评价算法性能。最常用的绘制曲线有P-R 曲线[4]、ROC 曲线[1,3-8]、DET[3,5-8]曲线和CMC 曲线[3]等,其他综合评价指标还有等错误率[4-8]和类内类间差异评价指标[9]等。
2.1 查准率-查全率曲线
查准率-查全率曲线(Precision-Recall curve)简称P-R 曲线,它以查全率R为X 轴,以查准率P为Y轴。对给定排名k或不考虑排名,通过对算法设定不同的阈值T 会得到不同的R(T,k)和P(T,k)值,将这些点(R(T,k),P(T,k))绘制到直角坐标系上就得到了P-R曲线。P-R 曲线下的面积为1 时则说明模型算法性能最为理想,往往不能达到最理想效果。当不同算法的P-R 曲线交叉时,难以判断哪个算法性能好。通常的做法是计算每种算法P-R 曲线下的面积,面积越大认为算法性能越好。但这个面积不太容易计算,这时可以引入平衡点BEP(即y=x与P-R 曲线交点的横坐标值)作为度量,BEP 越大认为算法性能越好。还有一个整体评价查准率和查全率的指标:F1值(F1-score),即查全率和查准率的调和平均数:
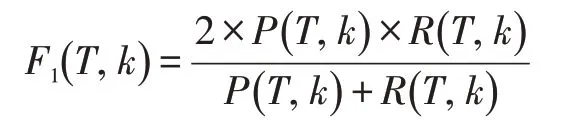
对给定的阈值T或排序k,比较不同算法F1值大小,值越大认为算法性能越好。
2.2 受试者工作特征曲线
受试者工作特征曲线(Receiver Operating Charac⁃teristic curve)简称ROC 曲线,它以假正例率FPR 为X轴,以真正例率TPR 为Y 轴。对给定排名k或不考虑排名,通过对算法设定不同的阈值T 会得到不同的FPR(T,k)和TPR(T,k)值,将这些点(FPR(T,k),TPR(T,k))绘制到直角坐标系上就得到了ROC 曲线。ROC 曲线反映了算法成本(假正例)和收益(真正例)间的权衡关系。ROC 曲线越靠近y=1 算法性能越好。在实际应用时不同算法的ROC 曲线可能会有所交叉,仅从曲线趋势上难以判断算法优劣。这时我们用ROC 曲线下的面积(Area Under Curve),即AUC,来进行评价[10]。AUC 理论上在[0,1]上取值,AUC 值越大算法性能越好。但个别时候会出现AUC 大但算法识别性能较差的情况,这时还要综合考虑其他指标进行评价。
在实际数据集中经常会出现正负样本数量差异巨大的现象,而且测试集中正负样本的分布也可能随着时间变化。这时ROC 曲线有一个很好的特性,即当测试集正负样本分布变化时同一算法的ROC 曲线趋势能够保持不变,而P-R 曲线没有这一特性。但ROC 曲线这一很好的特性却无法体现数据集结构巨大变化时不同算法识别性能的差异,而P-R 曲线能够反映此时算法的真实性能。
2.3 检测错误权衡曲线
检测错误权衡曲线(Detection Error Trade-off curve)简称DET 曲线,它以错误接受率FAR 为X 轴,错误拒绝率FRR 为Y 轴。对给定排名k或不考虑排名,通过对算法设定不同的阈值T 会得到不同的FAR(T,k)和FRR(T,k)值,将这些点(FAR(T,k),TPR(T,k))绘制到直角坐标系上就得到了DET 曲线。这时曲线越接近y=0,算法性能越优越。类似于ROC 曲线,我们也可以用曲线下的面积来评价算法的整体性能,这时曲线下面积越小,算法性能越好。
2.4 累计匹配特性曲线
累计匹配特性曲线(Cumulative Match Characteris⁃tic Curve)简称CMC 曲线,它以排序k为X 轴,以前k名命中率top(T,k)为Y 轴。对给定阈值T,通过排序k从小到大变化得到不同的top(T,k) 值,将这些点(k,top(T,k)) 绘制到直角坐标系上就得到了CMC 曲线。CMC 曲线越接近y=1,算法识别性能就越好。
2.5 等错误率
等错误率(Equal Error Rate)简记为EER,它虽然是一个具体数值,但需要利用错误接受率曲线FAR 和错误拒绝率曲线FRR 来求得。具体过程是:对给定排名k 或不考虑排名,先将阈值T的取值范围归一化至区间[0,1],以阈值T为X 轴,T取一组0 到1 之间的等差数列,分别得出点(T,FAR(T,k))和点(T,FRR(T,k)),这样就可以画出曲线FAR 和曲线FRR,两条曲线的交点对应的纵坐标值就是等错误率EER。等错误率EER越小,算法的识别性能就越高。
2.6 类内类间差异评价指标d'
这里是对某一测试样本集中样本的所有比对进行评价的。将两个同一身份的样本间的比对得分称为真实匹配得分(genuine match score),将不同身份的样本间的比对得分称为虚拟匹配得分(imposter match score),那么可以计算d':
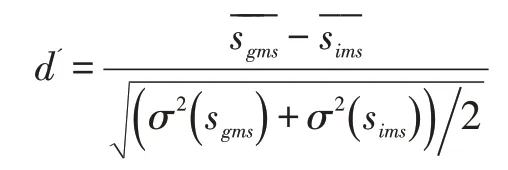
指标d'反映了类内匹配得分和类间匹配得分之间的差异情况。值d'越大,说明类内差异和类间差异区分度越明显,算法效果也越好。
2.7 鲁棒性评价指标
鲁棒性指标用来评价识别系统处理缺失值和异常数据的能力。文献[11]用初始增强鲁棒性(Robust Initial Enhancement)RIE 这一指标来评测识别算法的鲁棒性。
3 其他相关指标
整个生物特征识别系统一般由数据采集注册、数据传输、数据处理、数据存储、识别比对和决策反馈等过程组成,每一阶段都有对应的评价指标。采集注册过程经常使用注册失败率、采集失败率、采集用时和平均无故障时间等来评价采集设备的性能。数据传输过程就会涉及到计算机网络方面的一些评价指标,如传输速率、吞吐量、时延、往返时间、利用率等指标。数据处理阶段会涉及特征提取相关的评价指标。数据存储阶段会涉及到数据库性能方面的指标。识别比对阶段除了上述指标外,还会涉及到比对速度、算法的可扩展性、可解释性等指标。决策反馈过程评价指标会涉及到决策反馈时间和吞吐量等相关指标。总体上,在系统应用过程中还要考虑整体实时性、安全性、兼容性、稳定性等指标。因此,生物特征识别系统评价将涉及到各个领域,是一个复杂的过程。
4 结语
生物特征识别系统是一个复杂的系统,本文回顾总结了生物特征识别系统算法性能指标和算法评测方面的最新研究进展,详细介绍了相应算法评价指标的定义、实现过程及意义,不仅总结了现有的基本指标量并将其一般化公式化,更具体描述了P-R 曲线、ROC曲线、DET 曲线、CMC 曲线、等错误率EER 和类内类间差异评价指标d'等综合性指标的绘制实现过程及相关属性意义。最后,还对生物特征识别系统相关的其他指标进行了简单介绍。
目前,随着识别算法准确性的不断提高,生物特征识别技术的应用市场更加广阔,汇聚的公民生物特征的种类和数量也越来越多,这就对实时性、抗规避性和安全性等提出了更高要求。实时性方面可能涉及到分布式存储、大规模并行计算和网络传输等方面;抗规避性方面要从采集、传输、存储、比对和反馈等过程防止篡改攻击等;安全性涉及到公民个人隐私保护和信息安全。因此,评价指标将不仅仅限于识别算法准确性本身,本文最后也对这些指标进行了介绍描述。今后,我们将重点关注这些指标,以期能够成体系地评价整个生物特征识别系统。
猜你喜欢
出版人(2022年8期)2022-08-23
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
英语文摘(2020年6期)2020-09-21
智能计算机与应用(2020年4期)2020-08-31
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
Coco薇(2015年10期)2015-10-19
