
基于CatBoost算法的面向对象土地利用分类
2020-11-13 02:02姜琦刚杨秀艳杨长保赵振贺
吉林大学学报(信息科学版) 2020年2期
姜琦刚, 杨秀艳, 杨长保, 赵振贺
(1. 吉林大学 地球探测科学与技术学院, 长春 130026; 2. 北方自动控制技术研究所, 太原 030006)
0 引 言
实时精确的获取土地利用的动态变化对社会经济的快速发展至关重要。遥感技术具有快速、动态和综合获取土地利用信息的特点, 目前已被广泛地应用于土地利用规划中[1-3]。传统的监督分类大多是基于像元信息的提取, 利用光谱信息将像元归为某一类, 孤立地考虑单个像元的归属问题, 忽略了影像的拓扑关系和空间特征等信息, 分类结果不可避免地会产生“椒盐”现象[4]。面向对象的遥感信息提取方法以含有更多语义信息的多个相邻像元组成的对象为处理单元, 综合考虑了光谱统计特征、 形状、 大小和纹理等因素, 能有效地区分“同物异谱”和“同谱异物”现象, 实现较高层次的遥感影像分类和目标地物的提取[5-6]。
结合机器学习算法与遥感数据进行土地利用分类一直是国内外学者的研究热点。李爽等[7]基于决策树对遥感影像进行了分类方法研究。决策树在逻辑上易于解释, 而且对于输入数据空间特征和分类标识具有很好的鲁棒性, 但该算法非常容易过拟合, 导致泛化能力不强; Pal等[8]将支持向量机应用于遥感分类中。在小样本数据集上能得到很好的效果, 但是如果数据量很大, 则所需的训练时间较长; Castelluccio等[9]通过卷积神经网络进行了土地利用分类, 研究表明它具有良好的泛化能力, 但是训练需要大量参数, 而且训练网络的效率比较慢; 马玥等[10]利用随机森林算法对农耕区土地利用进行了分类研究, 在降低数据维度的同时有效地保证了分类精度, 但是在某些噪音较大的分类问题上容易出现过拟合, 而且随机森林模型过程是很难解释清楚的黑箱。
CatBoost(Category Boosting)是由俄罗斯搜索巨头Yandex在2017年开发的一款梯度提升机器学习库, 主要用于排列任务、 预测和提出建议。它易与谷歌的TensorFlow和苹果公司的CoreML等深度学习框架相结合, 不需要像其他ML(Machine Learning)模型那样进行广泛的数据训练, 而且为更多的描述性数据格式提供了强大的“开箱即用”的支持。目前国外学者已将其应用在商业预测[11]、 健康科学[12]、 社交网络[13]、 基准测试[14]和地理数据质量评估[15]等诸多领域。笔者尝试将CatBoost算法应用于Sentinel-2影像的面向对象土地利用分类研究中, 并将该方法与RF(Random Forest)算法、 AdaBoost算法进行比较, 验证该方法在土地利用分类中的可行性。
1 研究区概况与数据源
1.1 研究区概况
研究区位于黑龙江省齐齐哈尔市西部龙江县(见图1), 地理坐标为47°10′33″N~47°23′47″N、 123°3′17″E~123°16′30″E。该区位于黑吉蒙3省区交汇处, 是大兴安岭-内蒙古地槽褶皱区、 小兴安岭-松嫩地块、 龙江隆起带与松嫩中断(坳)陷带相接的过渡地段。龙江县地形自西向东依次为低山-丘陵-平原, 属于中温带大陆性季风气候, 日照充足, 雨热同季, 全年日照时数约为2 661.1 h, 年平均气温和降水分别为4.6°C和469.8 mm, 有利于发展农业。龙江县作为全国粮食生产基地, 耕地面积较大, 主要以旱地为主, 土地利用类型丰富, 主要包括草地、 林地、 河流、 其他水域、 建设用地、 旱地、 水田和沼泽。
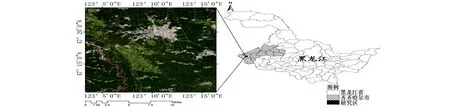
图1 研究区位置图Fig.1 Location map of study area
1.2 数据源及预处理
Sentinel-2卫星是高分辨率多光谱成像卫星, 为欧洲哥白尼环境监测计划的组成部分, 主要用于包括陆地植被、 土壤以及水资源、 内河水道和沿海区在内的全球陆地观测, 可用于气候变化、 应急响应、 森林监测、 土地利用变化、 植被健康监测、 产量预测和食品安全管理等[16], 其主要任务是对全球陆地表面进行高分辨率多光谱成像。该卫星获取的多光谱数据包含13个波段, 不同波段的空间分辨率也略有不同, 包含10 m、 20 m和60 m[17]。在光学数据中, Sentinel-2数据是唯一一个在红边范围含有3个波段的数据, 这对监测植被健康信息非常有效[18]。
研究区采用的Sentinel-2遥感影像数据的获取时间是2018年9月9日, 通过欧空局的数据发布中心进行下载(https://scihub.copernicus.eu/dhus/#/home), 研究区范围内的数据质量良好, 清晰无云, 可用作后续研究。所有数据均为已经进行过几何校正处理的Level-1C级大气顶反射率数据, 因此, 只需对影像数据进行大气校正, 获得Level-2A级地表反射率数据[19]。笔者使用SNAP软件中的Sen2Cor模块进行大气校正, 得到空间分辨率为10 m的蓝、 绿、 红和近红外4个波段。
2 模型与方法
2.1 多尺度分割与光谱差异分割
影像分割是面向对象遥感影像分类中的基础步骤, 分割的理想结果是影像对象内部的异质性最小, 影像对象间的异质性最大, 过分割和欠分割都可能导致分类精度下降[20-21]。笔者采用多尺度分割(MS: Multiresolution Segmentation), 并借助ESP(Estimation of Scale Parameter)尺度评价工具获取适宜分割参数, 通过ESP工具获取的对象最优分割尺度为45, 形状因子和紧致度因子分别为0.5和0.6。以上分割步骤均在eCognition 9.0软件中实现。
2.2 特征选择
分割后的影像对象包含很多不同的信息, 面向对象分类就是以对象为单位进行特征信息的提取, 以此划分地物[22]。遥感影像特征主要包括光谱、 指数、 几何和纹理特征。笔者从原始特征中挑选具有代表性的特征共48个(见表1), 其中光谱特征14个, 指数特征3个, 几何特征13个, 纹理特征18个。

表1 特征参数统计
2.3 样本选择
相关研究表明, 为了保证分类精度, 一般要求每种地物类别所选取的训练样本数据应包括10n(其中n为特征维数)个以上的样本点[23-24]。笔者选取了各地物类别至少为特征维数的10倍的训练样本量进行分类研究。通过计算J-M(Jeffries-Matusita)距离和转换分离度(TD: Transformed Divergence)衡量训练样本(ROI:Region Of Interest)的可分离性, 两者的数值均大于1.8, 说明样本间可分离性好, 属合格样本, 能满足分类实验要求。
2.4 分类方法
2.4.1 CatBoost算法原理
CatBoost是一种支持类别特征、 基于梯度提升决策树的机器学习方法。所有现存的梯度提升(GBDT: Gradient Boosting Decision Tree)算法都存在统计学上的问题: 经过多次提升的预测模型F依赖于训练样本的目标变量, 这会导致训练样本中Xk的F(Xk)|Xk分布与测试样本中X的F(Xk)|Xk分布发生偏移, CatBoost算法能很好地解决原始GBDT中的各种数据偏移问题, 鲁棒性较好[25-26]。


(1)


图2 特征重要性Fig.2 Feature importance
CatBoost使用次序原则, 将TS值的计算依靠目前已经观察的样本集。基于贪婪算法选择树的结构, 找出所有可能的分割方式, 计算每种方式的惩罚函数, 选择最小的, 将结果分配给叶节点, 后续叶节点重复此过程, 在构建新树前进行随机重排, 按梯度下降方向构建新树, CatBoost在不同的梯度提升步中使用不同的排列。CatBoost算法利用
计算特征变量的重要性。其中c1,c2为叶节点中的文档数,v1,v2为叶节点中计算公式的值。通过计算48个特征变量的重要性, 并根据其重要程度提取前20个特征变量(见图2)对高维数据进行降维, 减少信息冗余, 降低模型的时间复杂度。
3 结果与分析
3.1 CatBoost分类结果
建立CatBoost模型对研究区的主要土地利用类型, 即建设用地、 旱地、 水田、 草地、 林地、 河流、 沼泽以及其他水域进行分类, 结果如图3a所示, 并与RF模型(见图3b)和AdaBoost模型(见图3c)的分类图对比可知, CatBoost算法仍然能清晰地区分各类地物以及在CatBoost特征选择下的RF和AdaBoost模型均达到较好的分类效果。

图3 不同分类方案土地利用分类图Fig.3 Land use classification maps with different classification methods
计算混淆矩阵, 对应的各类地物的制图精度、 总体分类精度和Kappa系数如表2所示。CatBoost分类模型的总体精度为92.79%, Kappa系数为0.911 4, 建设用地、 旱地、 水田、 草地、 林地、 河流、 沼泽及其他水域的制图精度分别为95.00%、95.45%、98.63%、73.91%、92.96%、90.00%、50.55%和93.33%。其中沼泽的分类情况较差, 主要是由于在草相对茂盛的区域, 沼泽与草地有相似的光谱特征, 而且部分沼泽与林地的边界模糊, 研究区所选取的沼泽的样本与河流和林地相邻, 混合像元的数量相对较多, 这也是导致沼泽和草地错分、 漏分现象的主要原因; 在本次研究中将内陆滩涂与河流划分为一类, 一定时期内的内陆滩涂与少量农作物长势较差的旱地有相似的纹理与光谱特征, 从而导致河流与旱地存在部分混淆; 其余地物间的混淆主要由于光谱特征的相似性造成。但在总体评价上, 该模型的分类精度较高, 适用于研究区的土地利用分类。

表2 不同分类方法精度对比
3.2 不同分类方案精度评价与比较
为验证CatBoost算法对土地利用分类的可行性, 将其与RF算法和AdaBoost算法的分类效果进行对比, 3种分类方案采用统一的分割尺度、 相同的特征变量以及同一拆分策略的训练集和测试集, CatBoost、 RF和AdaBoost 3种模型均选择构建1 000棵树。采用混淆矩阵量化3种模型的分类精度, 对应各类地物的制图精度、 总体分类精度和Kappa系数如表2所示, 分类结果如图3a~图3c所示, 错分误差与漏分误差如图4a、 图4b所示, 可得出以下结论。
1) CatBoost分类模型与RF分类模型的总体分类精度相等; CatBoost的Kappa系数比RF略高出0.04个百分点; 在CatBoost分类较差的沼泽分类中, RF模型表现良好, CatBoost模型的漏分现象严重; 在建设用地、 水田、 草地、 河流和其他水域的分类中, CatBoost模型的分类精度均较RF模型有不同程度的提高; RF模型的错分现象比较严重, 在草地、 河流和沼泽中尤为明显; 由于部分沼泽易与草地混淆, 存在的混合像元数量较多, 导致在CatBoost模型中沼泽的分类效果最差, 在一定程度上也降低了草地的分类精度。
2) CatBoost分类模型比AdaBoost分类模型在总体分类精度和Kappa系数上分别高出11.2个百分点和13.62个百分点。在各地物类别的分类中, CatBoost模型均较AdaBoost模型表现好, AdaBoost分类模型的漏分现象严重, 林地的错分误差达到57.75%, 总体的分类效果较差, 而CatBoost模型的总体分类精度和Kappa系数均在91%以上, 分类结果具有较高的可信度, 从而验证了CatBoost模型在土地利用分类中的适用性。

图4 不同分类方案误差对比Fig.4 Comparisons of classification errors with different methods
4 结 论
笔者结合机器学习算法与遥感数据进行土地利用信息提取, 以黑龙江省齐齐哈尔市西部龙江县的Sentinel-2影像为数据源, 尝试应用CatBoost算法进行面向对象的土地利用分类, 并与RF和AdaBoost分类方法的实验结果进行比较, 得出以下结论:
1) CatBoost算法在面向对象的土地利用分类中取得较好的分类效果, 对各地物分类的总体精度和Kappa系数分别为92.79%和0.911 4, 具有较高的分类精度;
2) CatBoost算法在降低了数据维度的同时有效地保留了特征信息, 降低了模型的时间复杂度, 在同样的分割尺度及特征变量的情况下使CatBoost、 RF和AdaBoost算法Kappa系数均在0.77以上。
综上, CatBoost算法适用于面向对象的土地利用分类, 而且在遥感各领域的应用存在巨大潜力。
笔者主要研究应用CatBoost算法对Sentinel-2遥感影像进行面向对象的土地利用分类。由于CatBoost算法是新兴的机器学习算法, 并且影响分类的因素有很多, 所以今后还需从以下方面进行深入研究。
1) 文中仅对Sentinel-2影像的红、 绿、 蓝、 近红外4个波段进行分类, 如果加入其他波段是否能在同等条件下提高分类精度还有待研究。
2) CatBoost算法擅长处理类别型特征, 在今后的研究中增加对遥感类别方面的特征的收集与提取, 例如尝试添加遥感影像元数据类信息等。
猜你喜欢
电子制作(2019年7期)2019-04-25
中国资源综合利用(2017年4期)2018-01-22
自然资源情报(2017年4期)2017-11-26
剑南文学(2016年11期)2016-08-22
中国老区建设(2016年8期)2016-02-28
遥感信息(2015年3期)2015-12-13
中国交通信息化(2015年6期)2015-06-06
时代英语·高三(2014年5期)2014-08-26
中国舰船研究(2014年4期)2014-05-14
中国土地科学(2014年4期)2014-03-01
