
粒子群算法在金融风险模型中的研究与改进
2020-11-13 07:49:52宋振铭赵佳琪
吉林大学学报(信息科学版) 2020年2期
孙 艺, 宋振铭, 赵佳琪
(1. 北京邮电大学 软件学院, 北京 100876; 2. 中国标准化研究院 标准评估部, 北京 100191)
0 引 言
近年来, 因为全球经济逐步一体化、 导致金融领域的创新层出不穷, 国内金融市场发展迅速, 财富膨胀的同时也伴随着各种危机, 大多数的金融机构受到多方不利因素的影响。因此很多研究人员基于多方面的考虑提出了不同的金融风险预测模型, 试图在金融系统的各个方面, 最大程度地降低风险。目前金融行业中, 普遍采用的风险评估模型有以下3种: 决策树、 支撑向量机和基于深度学习神经网络预测方法。相对而言粒子群算法实现较为简单, 优化比较方便, 并且参数少, 优点相对突出, 所以经常被用于多个经济领域。例如在供应链领域的金融信用风险评价[1]、 在经济调度问题中的应用[2]、 证券市场分析[3]、 求解经济负荷分配[4]、 金融风险预警[5]和产销不平衡现象领域[6]。在粒子群算法中, 每个粒子个体的位置被设置为一个问题的可优化解, 并且站在整个群体的角度下, 采取信息共享和合作方式, 按照有序的方式和规律引导粒子逐步演化, 从而得到最优解。
以往传统方法中, 大多是以线性分析方法为基础的金融理论, 很多没有考虑金融系统的非线性, 对金融系统中存在的相互作用的复杂程度和内部的不稳定性都没有明确考量, 导致对金融风险无法进行有效的预测和控制。而且粒子群算法会随着迭代次数的增多, 容易出现种群多样性降低、 陷入局部最优、 收敛速度减慢和全局收缩能力降低等问题, 因此在传统金融风险模型中, 粒子群算法的应用方式是无法确定其最大参数比的[7]。笔者通过对随机惯性权重的调整、 个体位置的变异等方式, 提出了一种改进的算法, 并基于文献[7]将改进后的粒子群优化算法应用于金融风险系统中, 通过实验说明笔者算法的最优参数配比, 从而降低金融系统的总风险值。
1 金融风险系统模型
针对系统风险的演变, 提出了一种新颖的金融风险系统[8]。设定3个阶段: 第1阶段存在两种影响, 分别来源系统内部和外部; 第2阶段对系统的影响来源不同金融网络之间的传染效应; 第3阶段的影响来源各种金融机构对市场的变化和监管机构对金融风险的控制。该模型的动力学方程为
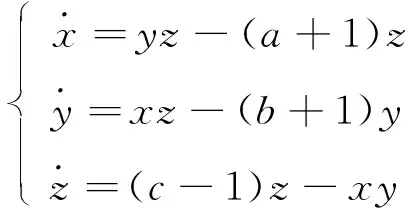
(1)
其中x表示系统内部和外部影响下的风险值;y表示第2阶段金融系统网络之间传染总风险值;z表示第3阶段对金融系统的风险控制值。a、b分别表示前两个阶段的风险程度,c表示第3阶段的控制力度,a,b∈R+,c>1。由于c表示金融监管机构针对金融市场的调控力度, 根据模型可以看出, 随着c值的逐步降低, 系统会逐渐进入混沌状态, 当调控力度较小时, 系统容易进入一种失稳状态, 严重影响系统运行。由于x变动较大, 导致与之相关的周期运动状态下的总风险值变化的规律无法明确, 进而无法确定c的最优值。最大程度降低系统的总风险值的关键就是确定一个最优值, 由于x是不断变化的, 文献[7]提出把目标函数x的均方根和最大值设置为加权函数, 则
L=ρ1rms(x)+ρ2max(x)
(2)
其中, rms代表均方值根, max代表最大值,ρ1,ρ2代表加权系数。
2 基于标准粒子群算法的金融风险系统模型
传统的粒子群优化算法主要源于对生物种群行为的研究, 通过分析个体之间行为的相互作用, 从而搜索种群空间中的最优位置。每个粒子代表一种潜在可行的解决方案, 并且每个粒子有两个属性: 当前位置xi和速度vi, 把个体粒子最优位置记为pbest(i),gbest(i)表示整个群体的最优位置。由此得出每个粒子位置和速度之间的关系如下
vi+1=ωvic1rand(j)(pbest(i)-xi)+c1rand(j)(gbest(i))
(3)
xi=xi+vi
(4)
其中c1,c2是常量, 代表粒子的影响因子, rand()随机取值,j定义域在[0,1],ω代表惯性权重, 可以反映粒子的惯性与速度之间的关系。在前期阶段, 为了增大全局搜索能力, 分配较大的惯性权重, 但后期阶段的目的是局部搜索的精度, 所以采用较小的权重, 根据ω的变化策略, 提高搜索能力, 则ω的表达式为
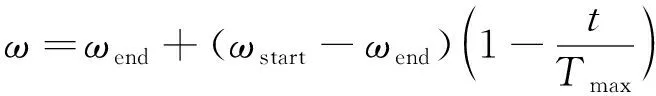
(5)
其中ωend=0.4,ωstart=0.9, 当前的迭代次数记为t,Tmax为迭代过程中允许的最大迭代次数。
假设在a、b固定的情况下, 通过引入粒子群算法从而寻找一组最优的控制参数c, 得到最小化的风险总值, 获取最小化目标函数。为明确表示粒子群和式(1)中的金融风险模型的映射关系, 笔者提出将粒子群中每个个体的位置表示为一组可控的参数c, 通过不断迭代, 粒子可以找寻到最优位置, 从而搜索出一组最优参数c, 最终实现风险值x的最小化, 起到对金融风险非线性系统模型优化的目的。
标准粒子群算法虽然有诸多优点, 但在迭代过程中, 当粒子对代表自身的迭代参数: 自身的位置、 单体历史最优位置、 整个群体最优解等都采用同样的更新方式时, 粒子容易出现后期停滞, 或是过早找到最优解等问题, 由此导致金融风险模型中的参数无法快速地产生下一个最优结果。因此笔者提出更改惯性权重设置方法, 采用随机数动态的代表惯性权重, 并引入鸽群算法对粒子位置的变异进行表示, 从而推断参数c跳出最优位置, 不仅有利于跳出局部最优, 而且在最大程度上保证种群的多样性, 同时避免出现过早收敛的结果。
3 粒子群算法改进
3.1 惯性权重的优化
通过式(3)可以推断, 历史信息对迭代更新的影响程度, 由惯性权重控制, 而传统算法中, 惯性权重大多采用线性递减策略, 导致搜索效率低下、 过早的引起局部最优。为了改善这些问题, 很多学者提出了多种方式: 采用固定惯性权重[9]、 权值递减策略[10-11]、 模糊惯性权值策略[12]、 随机惯性权重策略[13]、 基于幂函数的非线性权值递减策略[14]、 动态惯性权值策略[15]及改进粒子群优化的BP(Back Propagation)算法[16]等。这些方式中, 随机性策略较为优秀, 在保持种群多样性的基础上, 针对性地提高了算法的全局搜索能力, 使粒子跳出局部最优, 避免粒子陷入早熟收敛。随机权重的定义为

(6)
其中ωmax表示随机权重最大值,ωmin代表最小值,t为当前的迭代次数,Tmax为最大迭代次数, rand(j)为[0,1]均匀分布的随机数,σ为方差, rand(j)为正态分布的随机数。
3.2 基于改进鸽群算法的个体位置变异
在PSO(Particle Swarm Optimization)算法中, 不同粒子的最优位置变化趋势会随着迭代次数的增加描绘出一条轨迹链, 可表示最优位置值, 但粒子过多的聚集与局部区域, 会出现过早收敛现象, 所以此时算法的搜索能力较弱。笔者通过改变粒子位置的变异策略, 完成粒子跳出局部最优, 由此提出一种改进鸽群算法。
鸽群算法使粒子的搜索方向明确、 提升搜索速度, 且具有计算精度高等优点, 但其中的地图罗盘算子和地标算子变异策略不够清晰, 这两个算子处于两个不同的运行阶段; 地图罗盘算子引入的目的是初始阶段的粒子位置和速度; 而地标算子的作用是针对远离目标的粒子, 每次迭代过程对这些粒子减半去除[17]。因为地图罗盘算子是一种平衡因子, 是关联搜索速度和开发能力的, 所以具有针对性的提出了一种优化方式[18], 引入了线性变异策略, 可以动态表示地图罗盘算子的变化趋势
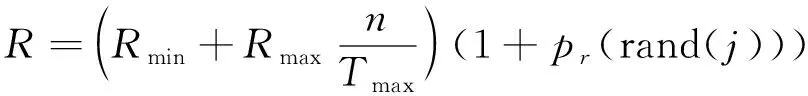
(7)
其中Rmax,Rmin代表罗盘因子的最大值和最小值,pr表示线性变异概率。在此基础上, 提出了一种搜索算子

(8)

为了避免粒子在迭代后期出现局部最优的现象, 引入表示位置变化的变异因子。因为虹吸效应, 导致大量粒子聚集出现在某个最优位置, 则对其中符合变异条件的粒子进行操作: 将变异粒子单独划出, 这不仅保证了种群的多样性, 而且增加了全局搜索能力。对式(8)改进后如下

(9)
c=min(b1-a1,b2-a2,…,bn-an)
(10)
其中c代表变异过程中的变异因子, 阈值范围在所有粒子中最小, 第i个粒子的定义域用bn-an代表。粒子变异率用pm表示。为了解决粒子在后期种群多样性较低的问题, 保证种群多样性和全局能力, 将迭代初期的变异率设置较高, 将迭代后期的变异率设置较低[19], 变异率的计算公式为

(11)
其中pm,min,pm,max分别代表最小和最大变异率, 迭代次数用k表示, 最大迭代次数使用N表示。
3.3 基于改进鸽群算法和EMPSO算法的个体最优位置更新
在解决粒子过早收敛问题的过程中, 引入了机电学科概念[20]中的类电磁机制, 提出了一种混合集中的优化算法EMPSO(Expectation Maximization and Particle Swarm Optimization)。用电荷量的值分别表示个体最优粒子和群体最优粒子, 从而可明确表示粒子间相互作用, 避免出现过早收敛情况。具体电荷量和合力计算方法如下

(12)

(13)
结合鸽群算法式(8)得到个体最优位置的计算方式为

(14)
其中RRNG为一个代表可行步长的向量, 其分量分别表示对应的面向上边界或下边界移动。
4 算法流程
改进后的算法首先对各个参数进行初始化, 确定粒子最优点以及种群最优点, 然后进行更新, 并与变异率比较, 判断是否需要变异、 是否满足条件, 进而决定继续迭代还是结束算法。改进后的算法流程如下。
步骤1) 对粒子的属性: 大小、 位置, 速度、 惯性权重和迭代次数初始化后, 可以确定粒子的变异率;
步骤2) 确定各个粒子的最优点pbest, 并表示“最好”的粒子位置gbest;
步骤3) 根据式(4)更新粒子的权重;
步骤4) 根据式(9)更新粒子的变异率, 然后和rand(j)比较, 若大于rand(j), 使用式(7)更新对粒子的位置进行变异; 若小于rand(j), 采用标准粒子群算法更新位置;
步骤5) 根据式(10), 式(11)计算粒子q以及作用力, 重新计算粒子最优位置, 比较前后两次最优位置, 取较优的p;
步骤6) 判断停止条件, 如果满足, 则停止迭代; 否则转到步骤3), 继续迭代。
5 实验仿真
为验证改进后算法对性能方面的影响, 采用测试函数: Sphere函数、 Rastrigrin函数、 Sumsquares函数和Zakharov函数分别对两种算法进行仿真实验, 验证两种算法的性能。4个基准函数的标准定义如下。
Sphere函数
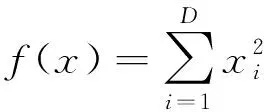
(15)
Rastrigrin函数

(16)
Sumsquares函数

(17)
Zakharov函数
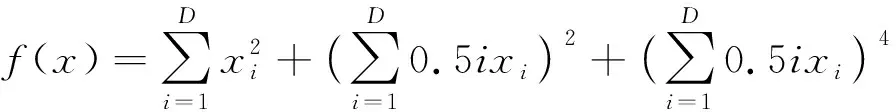
(18)
Sphere是单峰二次函数,f(x)=0表示全局最小值, 因为只有一个极小值点, 所以在寻优上比较困难; Rastrigrin是多峰函数, 可以采集大量的局部极值点; Sumsquares和Zakharov函数同样都是具有多峰的函数。对于实验仿真过程, 惯性权重的变换范围为[0.4,0.9],pmax=0.6,pmin=0.3, 随机函数的阈值为(0,1), 迭代次数最高100次。Spehe、 Sumsquares、 Rastrigrin、 Zakharov函数非常清晰地表示了迭代次数与适应值之间的趋势变换, 如图1~图4所示。

图1 Sphere函数适应值变化趋势 图2 Rastrigrin函数适应值变化趋势 Fig.1 The change trend of the adaptation Fig.2 Variation trend of fitness value of the Sphere function value of Rastrigrin function

图3 Sumsquares函数适应值变化趋势 图4 Zakharov函数适应值变化趋势 Fig.3 Variation trend of fitness Fig.4 Variation trend of fitness value of Sumsquares function value of Zakharov function
从图1~图4的结果中可以看出, 优化后的算法具备更快的收敛速度, 在很大程度上解决了陷入局部最优的问题。从图1中可以看出, PSO算法相较于改进后的算法较慢的达到最优适应值。从图2中可以看出, 在传统的算法中, 开始阶段下降较快, 局部最优现象也很快出现, 但改进后的算法通过对惯性权重等值的改进, 使粒子很快跳出了局部最优陷阱, 从而更快地达到了最优。在图3中, PSO算法在开始阶段适应值较低, 但收敛速度较慢。而改进后的算法虽然陷入了局部最优, 但很快通过变异策略跳出, 从而加快了收敛速度, 在图4中效果更为明显。
从仿真结果得出, 笔者采用的策略粒子惯性权重的改变力度、 粒子位置变异方式以及种群中粒子最优位置的变化, 很大程度上能帮助粒子跳出局部最优、 解决后期收敛减慢的问题, 并且表现了较好的收敛性。
6 结 语
笔者在传统方法的基础上, 在金融风险模型中引入粒子群算法, 通过对粒子的属性: 惯性权重, 个体位置、 个体最优位置变异等关系的优化, 找出粒子群算法中的粒子位置和风险模型中控制因子c的映射关系, 获取最优的控制因子, 在最大程度上降低风险系统中的总风险值, 使粒子群在保持种群多样性的基础上, 不但解决了局部最优的问题, 而且在后期依然能保持良好的速度。
猜你喜欢
中学生数理化·八年级物理人教版(2023年3期)2023-03-21 00:40:16
中学生数理化·八年级物理人教版(2022年3期)2022-03-16 05:55:06
趣味(数学)(2020年4期)2020-07-27 01:44:16
大社会(2020年3期)2020-07-14 08:44:16
支部建设(2020年15期)2020-07-08 12:34:32
当代陕西(2019年15期)2019-09-02 01:52:08
辽宁经济(2017年12期)2018-01-19 02:34:01
中学生数理化·八年级物理人教版(2017年3期)2017-11-09 03:05:23
小学科学(学生版)(2016年1期)2016-10-09 01:53:02
山西农经(2016年3期)2016-02-28 14:23:54
