
财政分权与政府承诺力:基于信息传递的视角
2020-10-19 09:15尹训东胡思平
中央财经大学学报 2020年10期
尹训东 胡思平
一、前言
本文中的财政分权主要是从信息传递的角度出发来研究财政支出分权的好处。在财政收入方面,主要涉及的是中央政府对地方政府的激励问题,这一激励方式大致可以分为两类。一类是官员晋升制,通过对地方政府官员提供职位晋升的渠道来激励地方官员提升GDP,从而增加税收收入;另一类是财政分成制,通过给予地方政府一定比例的税收收入,中央政府达到激励地方政府收税的目的。然而在财政支出方面,与中央政府相比,地方政府更加了解当地居民和企业的真实信息,拥有一定的信息优势,能更有效地制定财政支出计划并进行资源配置。从信息传递的角度来看,中央政府如何有效地进行财政支出分权以利用地方政府的私有信息是决定财政支出配置效率的关键。目前来说,从信息传递的角度来探讨中央政府和地方政府在财政支出方面的分权问题的文献较少,本文在一定程度上弥补了在这一领域的文献空白。
中央政府在设计最优分权机制时,必须考虑自身的承诺能力。首先考虑单期的情况,如果中央政府没有承诺能力,那么中央政府和地方政府之间进行的就是廉价磋商(cheap-talk)的博弈。地方政府有地方上的信息优势,而缺乏地方信息的中央政府掌握决策权,中央政府和地方政府两者的偏好有差异。廉价磋商博弈的均衡说明:双方之间的信息传递是有限的,存在模糊信息传递的均衡,并且双方的偏好差异越大,信息传递的越少。然后,我们考虑单期时中央政府有承诺力的情形,在双方的偏好差异不大的情况下,中央政府最优的机制就是给地方政府规定一个财政支出上限,不超过该上限,决策权完全让渡给地方政府。
在单期模型的基础上,本文重点研究了两期模型下的最优财政支出决策权的下放问题。两期模型的复杂之处在于我们考虑中央政府在不同承诺能力(commitment power)下的最优机制,即中央政府有完全的承诺能力、有限的承诺能力和没有任何承诺能力的情况。完全的承诺能力指中央政府可以在第一期承诺两期的合同;有限的承诺能力指中央政府在第一期只能承诺第一期的合同,而不能承诺第二期的合同,只能到第二期的期初制定第二期的合同;没有任何承诺能力指双方之间每期只能进行廉价磋商的博弈。本文假设两期下的真实状态信息不随时期改变。
二、文献综述
总的来说,我们可以将财政分权理论的发展分为以下两个时期:第一代财政分权理论和第二代财政分权理论。第一代财政分权理论的开始以Tiebout于1956年发表的《地方公共支出的纯理论》[1]为标志,随后经过了Musgrave(1959)[2]和Oates(1972)[3]等人的发展而成。第一代财政分权理论是从地方政府的信息优势和中央与地方的职能分工角度来阐述财政分权理论。这一理论认为地方政府间的竞争会促使地方政府提供帕累托最优的公共产品,但是却没有分析政府官员为什么会存在提供最优公共产品和提升社会福利水平的动机,即缺乏对可实施的分权机制的说明。
第二代财政分权理论将微观经济学的激励相容和机制设计理论引入了财政分权领域。该理论认为,政府官员不是完美的和无私的,作为经济个体,政府官员也会寻求自身的利益最大化,也需要外在的约束来规范其行为。一旦分权机制未给予政府足够的激励,将会滋生其寻租行为,从而降低社会福利水平。这一理论的代表性人物为Qian和Roland(1998)[4]、Qian和Weingast(1997)[5]等。
在两代财政分权理论的基础上,国内外学者进行了许多财政分权方面的实证研究。Akai和Sakata(2002)[6]利用美国50个州1988—1992年的数据分析了这一影响,他们发现当选用不同的指标来表示财政分权时,所得出的结论不同,因此Akai和Sakata并未明确阐述财政分权与经济增长之间的关系。通过用地方政府的边际留成比例来表示财政分权,林毅夫等(2000)[7]发现财政分权与经济增长之间存在正相关的关系,对此的解释是在财政分权制度下,地方资源配置得到帕累托改善,从而促进了经济增长。
在此之后,张晏和龚六堂(2005)[8]发现财政分权能促进经济增长,但这一效应存在时间上和地区间的差异,文章表明财政分权的影响在经济发达的中东部地区和经济欠发达的西部地区是不同的,同时还发现财政分权主要是通过提高各级政府之间的沟通协作能力来促进经济增长。之后,周业安和章泉(2008)[9]的研究中还讨论了财政分权对经济波动的影响,发现财政分权是导致经济波动的重要原因。
委托代理问题的研究源于20世纪70年代,在最开始的研究中,学者们假设委托人可以通过转移支付来激励代理人,根据代理人的业绩表现给予不同的报酬。其基本的结论是委托人为了获取代理人的私人信息,必须给予代理人一定的信息租金。还有一类激励机制,委托人不能使用转移支付来激励代理人,而是通过让渡决策权来激励代理人,比如政府上下级之间的决策问题,很多时候并不涉及用薪酬来激励下级的行为,而是上级衡量是否把决策权下放给下级,以便让下级更有效地利用当地的信息。如果不下放决策权,下级可能会为了自身的利益谎报(或瞒报)其私人信息,而如果下放决策权,下级根据自己的私人信息所选择的行为通常并不是上级最偏好的。这种决策权的分配和信息传递的矛盾构成了是否下放决策权的关键。本文基于没有转移支付的激励理论,从信息传递的角度,研究中央政府最优财政决策权的下放机制,即最优财政分权的理论。
一般的委托代理模型中,委托人可以给予代理人转移支付来激励代理人按照自己的偏好行动,根据不同的结果,给予不同的报酬,以便激励代理人进行合意的行动。但Holmstrom(1977)[10]开创了另外一类的代理关系,在这种代理关系中,委托人由于某种限制而不能使用转移支付对代理人进行激励,为了利用代理人的私人信息,委托人不得不让渡自己的决策权给代理人,让代理人根据自己掌握的信息自由选择行动。本文研究的代理关系属于后面这种情形。
当只存在一期的代理时,Melumad和Shibano(1991)[11]以及Martimort和Semenov(2006)[12]求出了静态最优代理机制,也就是给出了在一定条件下为代理人的决策设置一个上限是最优的。之后,Martimort和Koessler(2012)[13]将这一研究延伸至多维代理问题。之后的文献包括有Dessein(2002)[14],Alonso和Matouschek(2008)[15],Ambrus和Egorov(2017)[16]。在本文的分析中,我们假设在任何时候,代理人的最理想的决策总是与委托人的最理想的决策不同,也就是代理人和委托人之间总是存在偏好上的偏差。上述文献都只研究了一期下的委托代理问题,然而在现实生活中,这种代理关系通常是多期的,本文的目的也是将政府在不同承诺力下的两期代理问题引入财政分权问题。
在有限承诺力的两期代理问题下,我们假设委托人不能对自己第二期的行为做出承诺,委托人在第二期将根据在第一期获得的信息做出自身最优的决策,从而可能损害代理人的效用,这将导致代理人在第一期不愿意暴露自己的信息。Raphael和Tracy(2011)[17]也分析了动态代理问题,但他们假设在每一期,真实信息是独立且均匀分布的,代理人知道真实信息的分布状况但不知道具体数值,而委托人连分布状况也不可知。他们认为在这种情形下,学习的能力是至关重要的。与上述文章不同的是,本文假设真实信息在两期是相同的,且都是均匀分布,委托人想获取真实信息的唯一途径就是给予代理人足够的激励,促使其揭露真实信息。另一个不同之处在于他们的文章只考虑了委托人有完全承诺和完全没有承诺的两种情形,而本文考虑的是委托人的有限承诺。本文的模型借鉴了Yin(2012)[18]的研究,需要指出的是,本文的模型并不仅限于运用在财政分权领域中,也可以运用于其他类似的委托代理情况,因此具有一定的通用性。但在财政分权中,本文所采用的模型具有针对性,在中央政府拥有决策权的情形下,中央政府的主要目标是充分利用地方政府的信息优势,因而从信息传递的视角来研究财政分权就非常恰当。
三、理论模型
本文从信息传递的角度构建模型,在以下所有模型中,我们假设地方政府更了解当地的具体信息,比如当地居民对各种公共物品的真实偏好、当地的风俗习惯和当地的经济水平等等。根据这些信息,可以得到当地的最优财政支出结构,比如地方政府的财政支出在经济发展和文化娱乐发展两方面的比例。一般来说,一个地方的发展要同时兼顾物质和精神两方面,物质方面就是指经济水平,精神方面包括文化娱乐设施和文化娱乐活动等。我们假设当地的这些信息是地方政府的私人信息,而中央政府只知道信息的概率分布。
同时,中央政府和地方政府的偏好不同,也就是各自对于当地的最优财政支出结构的偏好不同。对于地方政府而言,当其自身激励与居民福利相契合时,其最优支出结构就是最大化居民效用的支出比例;但是中央政府要考虑的不仅是某个区域的利益,更是全国整体的利益,因此中央政府需要统一协调全国各地的公共产品供给,实现资源在全国范围内的最优配置。正是由于两者的角色不同,中央政府与地方政府在当地财政支出水平上必然存在不同的偏好,双方的效用函数存在差异。当决策权分别掌握在中央政府和地方政府手中时,两者将根据各自获得的信息和偏好决定当地的财政支出结构,也就是决策y。
地方政府观测到当地的真实信息为t,这一真实信息只有地方政府了解,中央政府只知道t均匀分布于[0,1]区间。地方政府根据真实状态t向中央政府传递信息r,r同样是位于[0,1]区间,中央政府根据传递的信息做出决策y。此时中央政府的收益函数为-(y-t)2,地方政府的收益函数为-(y-(t+b))2,b>0表示中央政府与地方政府之间的收益偏差,两者的收益都受到真实状态t和实际决策y的影响。当真实状态为t时,中央政府的最优决策为y=t,而地方政府的最优决策水平为y=t+b。正是由于地方政府的最优决策水平与中央政府不同,所以当最终的决策权掌握在中央政府手中时,地方政府才有动机使传递的信息r偏离真实状态t,从而使中央政府的决策偏向于y=t+b。
(一)单期情况下的模型
本文先讨论单期情况下的模型,包括没有信息传递的中央集权模型、中央政府完全没有承诺能力的廉价磋商模型、中央政府有承诺能力的财政分权模型。在单期模型的基础上,本文重点研究了两期模型下的最优财政支出决策权的下放问题。
1.无信息传递:中央集权模型。
在中央政府集权的情况下,中央政府和地方政府之间不存在信息传递,此时中央政府唯一已知的信息是真实状态t均匀分布在[0,1]区间,给定中央政府关于t的分布信息和其收益函数的形式,我们可以证明其最优选择为y=1/2。证明如下:
将t在[0,1]区间上的中央政府的收益进行积分:
(1)
对于中央政府而言,在没有任何信息的情况下,最优的决策是y=1/2。总的来说,我们发现,在中央集权模型中,当完全由中央政府决定财政支出水平时,由于中央政府不清楚地方的真实信息,只知居民的真实信息均匀分布于[0,1]区间,此时中央政府的最优选择为区间的中间值1/2。当中央政府与地方政府之间的偏好差异较大时,对于中央政府而言,y=1/2的决策是最优的。但当两者之间的偏好差异较小时,信息传递的缺乏就会导致双方的福利损失,且随着偏差越小,造成损失的可能性就越大。
2.完全无承诺能力:廉价磋商模型。
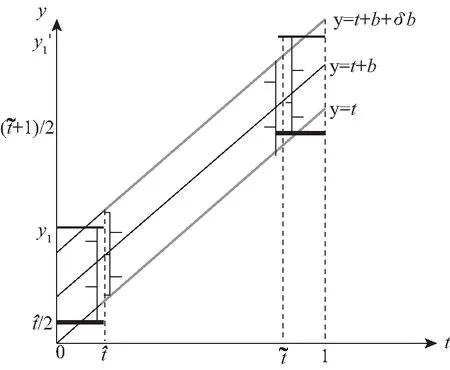
现在我们考虑中央政府根据地方政府传递的信息进行决策的情况。我们假设中央政府保留决策的权力,并要求地方政府汇报其关于地方上的私有信息,然后中央政府再根据此汇报的信息选择地方上的财政支出水平。我们可以应用Crowford和Sobel(1982)[19]的模型来求解这种情况下的信息传递和最优决策,其基本结论是当中央和地方的偏好差异比较小的时候,在均衡时,存在模糊的信息传递或者部分信息传递。简言之,在均衡的时候,地方政府会根据真实的t值所在的不同区间,传递不同的信息。真实状态t均匀分布在[0,1]区间,地方政府会将该区间划分成K个不相交的区间。令t0=0,tK=1,当t0≤t Kt1+2bK(K-1)=1 (2) 举例来说,如图1所示,这是当1/24≤b<1/12,K=3时中央政府的决策。当0≤r 我们可以很容易证明,廉价磋商下的中央政府收益高于中央集权下的收益。当K越大时,区间的划分程度越高,地方政府与中央政府之间的信息传递也越精确,此时中央政府在廉价磋商下的收益更高于中央集权下的收益。 图1 廉价磋商的解(分三段的情况) 3.完全承诺能力:财政分权模型。 对于中央政府来说,在单期下有更好的决策机制吗?现在我们考虑财政分权模型:中央政府给予地方政府完全的自由选择权,不需要向上报告,不需要隐瞒,此时地方政府将选择对自身来说最优的决策,即当真实状态为t时,其决策为y=t+b,而中央政府的收益始终为-b2。 我们可以将这一结果与上述的中央政府集权和廉价磋商模型的结果进行对比,我们可以先考虑最简单的两阶段廉价磋商模型,具体来说,图2描绘了当1/12≤b<1/4时廉价磋商和财政分权两种模型下中央政府的收益。接近横轴的水平直线为-b2,表示财政分权模型中每种状态下中央政府的收益,扇形曲线表示廉价磋商模型中每种状态下中央政府的收益。由于真实状态t均匀分布于[0,1]区间,因此财政分权模型下中央政府的期望收益为横轴与水平直线之间矩形面积的负数,廉价磋商模型下中央政府的期望收益为横轴与抛物线之间面积的负数。 图2 廉价磋商下中央政府的期望收益与财政分权下中央政府的期望收益 因此,当中央政府与地方政府的偏好差异不是太大时,中央政府将财政决策权交由地方政府,允许地方政府自主决定其财政支出,将有效地利用本地的信息,此时我们发现对于中央政府来说,财政分权模型总是优于中央集权模型和廉价磋商模型,从而证明了财政分权体制的合理性和优越性。 以上我们考虑的是完全财政分权下的情况,也就是说不管地方真实信息如何,中央政府总是将决策权完全下放给地方政府。然而实际上,我们发现,中央政府可以采取有条件的财政分权,在满足对地方政府的激励相容的情况下最大化自身的效用。这一有条件的财政分权机制就是静态最优代理机制:如果t≤1-2b,则y1=t+b;如果1-2b≤t≤1,则y1=1-b。证明如下: 地方政府的真实信息为t,向中央政府传递的信息为r,中央政府根据传递的信息做出的决策为y(r)。我们知道中央政府的目标为最大化自身的收益,即Maxy(r)-[y(r)-t]2,地方政府的目标也是最大化自身的收益,即Maxr-[y(r)-t-b]2。此时对于地方政府来说,说实话的策略是激励相容的,因此激励相容的一阶条件为2[y(r)-t-b]·y′(r)|r=t=0,具体来说有[y(r)-t-b]|r=t=0或y′(r)|r=t=0。由此我们可以得到中央政府的最优机制必须满足的条件为y(t)=t+b或y(t)=C,也就是说中央政府要么任由地方政府选择其自身的最优水平,要么采取一个常数值。 在满足条件的机制中,我们发现最优的代理机制结构如图3所示:粗线条表示中央政府的最优机制设计,具体来说,当地方政府的最优水平足够低时,即t≤1-2b时,中央政府将下放决策权,任由地方政府选择其最优水平;反之,当地方政府的最优水平超过一定的数值时,即t>1-2b,中央政府将收回决策权,独立做出选择。这一结果可以由简单的代理集合求得,中央政府不需要直接运用显示机制或与地方政府沟通,而是可以向地方政府提供一系列选择并让地方政府在这一范围内自由决策。当地方政府的决策水平未达到中央政府设置的边界时,地方政府拥有完全的自由选择权,可以选择自己的最优水平;当触及中央政府的边界时,地方政府的自由选择权将被剥夺,中央政府将收回这一决策权并做出自身最优的选择。 与之前所述的完全由地方政府采取自身最优水平的财政分权相比,这个最优代理机制反映了利用地方信息(即地方政府根据真实状态t做决策)和控制权丧失(地方政府获取决策权)之间的权衡。当决策权完全掌握在地方政府手中时,地方政府有足够的动机总是采取策略y=t+b,而边界的设置限制了地方政府的自由选择权并减少了控制权的丧失,但也就没办法利用地方政府的私有信息了。显然,b越小就意味着中央政府和地方政府之间的利益冲突越小,图3中粗横线部分就越短,即地方政府的自由选择权越大。 图3 静态下的最优代理机制 然而,如果我们考虑中央政府与地方政府的两期代理问题,我们会发现,最优静态代理规则将不再适用于这一情形。在两期博弈中,最优静态机制下地方政府有动机在第一期高报其真实信息,从而降低自身第二期的效用损失。 现在我们考虑一个更具现实意义的两期代理模型,在这个模型中,我们仍然假设只有地方政府了解当地的真实信息。跟之前模型的设置一样,我们假设中央政府和地方政府的收益函数不同,且两期下两者的收益函数不变,两者的偏好差异不变,地方的真实状态t也不变。 正如之前所述,在两期模型中,我们仍然假设中央政府和地方政府的偏好不同,也就是各自对于当地政府的最优财政支出水平的偏好不同。因为对于地方政府而言,当其自身激励与居民福利相契合时,其最优支出水平就是最大化居民效用的公共产品供给水平;但是中央政府要考虑的不仅是某个区域的利益,而是全国整体的利益,因此中央政府需要统一协调全国各地的公共产品供给,实现资源在全国范围内的最优配置。正是由于两者的角色不同,中央政府与地方政府在当地财政支出水平上必然存在不同的偏好,双方的效用函数存在差异。 在第一期,地方政府了解到地方真实信息t,中央政府只知t值均匀分布在[0,1]区间;在第二期,中央政府将根据地方政府在第一期的决策行为形成对真实信息t的推断。此时中央政府的最大化目标为: Maxy1(t),y2(t)[-(y1(t)-t)2-δ(y2(t)-t)2] (8) 其中:y1(t)表示第一期的决策,y2(t)表示第二期的决策,有yi∈Y,其中Y是R的紧空间;δ表示对第二期的折现。对于中央政府来说,给定地方真实状态t,其最优选择为y1(t)=y2(t)=t。 地方政府的最大化目标为: Maxy1(t),y2(t){-[y1(t)-(t+b)]2-δ[y2(t)-(t+b)]2} (9) 从上式我们可以看出,对于地方政府来说,最优决策水平为y1(t)=y2(t)=t+b,其中b值仍表示中央政府与地方政府之间的偏好偏差。正如之前所述,这种二次型收益函数广泛应用于许多学者的经典文章中,比如Crawford和Sobel(1982)[19]、Holmstrom(1977)[10],再从2000年开始到现在的文献,都是采取的这一经典形式。此外,在本文中,二次型的收益函数形式也符合我们的模型要求,同时也能求出显示解,因此我们依然沿用这一函数形式。 1.完全无承诺能力和完全承诺下的情况。 由之前的证明可知,在单期的情况下,中央政府完全没有承诺能力的结果就是廉价磋商均衡。在廉价磋商模型中,有2bK(K-1)<1,即地方政府传递信息的精确度(也就是中央政府划分信息区间的个数K值)取决于两者的收益偏差b值。总的来说,b值越小,K值越大,也就是中央政府与地方政府的收益偏差越小,则信息的传递就越精准。 当中央政府两期均没有承诺能力时,两期下的情况实际上就是单期的廉价磋商模型的两期重复。同样地,当中央政府两期均有完全承诺能力时,两期下的情况就是单期的财政分权模型的两期重复。由之前的证明可知,在单期下,对于中央政府来说,财政分权下的结果总是优于廉价磋商的结果,那么两期下的情形也依然如此。 2.有限承诺下的情况。 本文的重点就是分析中央政府有限承诺下的情况。与之前模型不同的是,在中央政府只有有限承诺能力的情况下,中央政府在第一期放权,但在第二期收权。也就是说,在第一期时,由地方政府独立决定其财政支出水平;在第二期,中央政府根据地方政府第一期的决策推断地方真实信息并独立做出决策。此时由于地方政府预期到中央政府的这一行为,为了避免中央政府第二期的决策损害其利益,地方政府有动机在第一期选择偏离其最优的支出水平,避免揭露其真实信息。而考虑到地方政府的反应,中央政府将寻求两期下激励相容的最优合同设计。 与传统静态模型不同的是,在本文的有限承诺下的两期代理问题中,中央政府不能在第一期决定y2(t),只能在第二期的开始决定。如果地方政府在第一期揭露其真实信息t,那么中央政府便会在第二期做出决策y2=t,而预期到中央政府在第二期的行为,即使地方政府在第一期有决策权,也不会做出揭露其真实状态的决策。这个博弈的时间顺序如图4所示:在0期仅有地方政府获知真实状态t;在第1期,地方政府根据其收益函数做出决策,向中央政府传递信息r1;在第2期,中央政府根据第1期地方政府的行为和贝叶斯法则更新其信念并做出决策。 图4 两期代理下的时序 接下来的定理1证明,在两期有限承诺的动态博弈下,静态最优代理机制将不再是激励相容的,因为此时地方政府有动机在第一期报告错误的信息。定理2与定理3证明存在连续的完全分离均衡可以使得地方政府在第一期揭露其真实信息,并且提升中央政府的效用。但是对于中央政府来说,这一完全分离策略虽然能在完全混同策略的基础上提高自身效用,但并不是最优的。因为在这一策略下,中央政府为了让地方政府在第一期揭露其真实信息所付出的代价太大。 定理1:对于任何δ>0的两期代理来说,静态最优代理机制是激励不相容的。 证明:假设最优静态代理机制是可行的,我们取子区间t∈[t1,t2]⊂[0,1-2b],此时若地方政府在第一期选择其最优水平y1=t+b,则中央政府可以通过这一行为了解到真实信息为t,因此在第二期中央政府的决策为y2=t,此时地方政府的效用为U=-δb2。现在我们考虑在第一期时地方政府不揭露其真实信息,而是向中央政府报告t′=t+ε,ε>0时的情况。在这种情况下,中央政府的决策为y1=t+b+ε,y2=t+ε,此时地方政府的效用为U′=-ε2-δ(b-ε)2。通过简单的计算可知,如果ε<2bδ/(1+δ),则有U′>U,已知δ>0,b>0,则有2bδ/(1+δ)>0,即ε>0存在。也就是说,当t∈[0,1-2b]时,静态最优代理机制下地方政府的决策为y1=t+b,但此时地方政府可以通过在第一期偏离其真实信息来提高收益。也正是因为地方政府不会在第一期揭露其真实信息,我们才认为静态最优代理机制是激励不相容的。 上述结论成立的前提是我们假设地方政府的收益函数-(y1(t)-t-b)2-δ(y2(t)-t-b)2是严格凸函数。在这种二次函数形式下,通过向中央政府传递信息t+ε,其一阶效应为正,二阶效应为负,且一阶效应占优二阶效应,因此偏离真实值的信息可以提高地方政府的效用。 现在我们想知道当中央政府了解到在这种两期的有限承诺代理模型下,地方政府在第一期的信息传递是有偏差的,中央政府是否还能通过机制的设计,在第一期知悉地方政府的真实信息,若中央政府能了解到地方政府的真实信息,那么在第二期就能采取最优决策y2(t)=t。在接下来的定理中我们给出了中央政府能在第一期知悉地方政府真实信息的代理机制,且这一代理机制在整个信息区间是连续的。 定理2:激励相容的全分离连续代理机制为:y1(t)=t+b+δb,y2(t)=t。 证明:如果地方政府在第一期的决策y1=y1(t)揭露了真实信息,则中央政府第二期的决策为y2(t)=t。一个激励相容的代理机制应该满足以下条件:对于地方政府来说,任意偏离真实值的t′带来的收益都小于传递真实值t带来的收益,即: -[y1(t′)-t-b]2-δ(t′-t-b)2≤-[y1(t)-t-b]2-δb2 (10) 则我们有:t=argmaxt′-[y1(t′)-t-b]2-δ(t′-t-b)2。 如果s-δb≠0,则有[1+δb/(s-δb)]ds+dt=0,该方程的一般解为s+δbln|s-δb|+t=C,其中C为常数。因为s(t)=y1(t)-t-b,所以此解也可以用y1(t)表示为y1(t)+δbln|y1(t)-δb|-b=C。 如果s-δb=0,则s为常数,此时方程有特殊解为y1(t)=t+b+δb。因为此解是一个闭合解且更容易执行,所以我们主要关注这个特殊解。 由此我们得到了一个第一期的均衡结果,即y1(t)=t+b+δb,当中央政府设计并执行这一机制时,地方政府有动机在第一期揭露其真实信息。此时对于地方政府而言,一阶效应消失,只剩下负的二阶效应,因此传递偏离真实值的信息不再有利可图且不再是激励相容的。同时,上述定理告诉我们如果存在使中央政府能知悉地方政府真实信息t的子区间,在这个区间内,有y1(t)=t+b+δb。 我们将这一均衡结果称为完全分离均衡,因为中央政府可以通过这一机制知悉地方政府的真实信息,将真实信息进行完全分离识别。在单期代理模型中,静态最优代理机制下中央政府无法识别地方的真实信息,只能为地方政府的决策设置一个上限,避免地方政府的决策水平过于偏离中央政府的最优水平。在两期代理模型中,我们可以找到这样一个完全分离均衡,使得地方政府有足够的动机揭露其真实信息,从而让中央政府在第二期能采取最优决策。当然,在两期代理下,中央政府也可以选择在第一期采取完全混同,在第二期采取静态最优代理,在之后的定理中,我们将比较这种策略与完全分离策略下中央政府的收益,从而明确完全分离均衡是否能提升中央政府的效用。 Laffont和Tirole(1988)[20]认为在有限承诺的两期委托代理模型中,任何一个区间都不存在完全分离均衡,在他们的文章中,如果高类型的代理人在第一期故意传递一个向下偏离ε∈(0,1)的信息,那么他只需在第一期承受一个二阶损失ε2,若委托人认定他为低类型的人,那么就会为他在第二期带来一个一阶收益ε,因此高类型的代理人可以传递错误的自身类型信息,从而获得一个正的租金。然而对于低类型的代理人来说,这个正的租金是不存在的,因此低类型的代理人将会在第一期谎称自己是高类型,并在第二期结束与委托人的关系,这就是“拿了钱就跑”(take-the-money-and-run)的策略。在Laffont 和Tirole的文章中,参与约束允许这种“拿了钱就跑”的策略的实现,但是在本文中,考虑到中央政府对地方政府的强力约束,我们认为地方政府很难在第二期“拿了钱就跑”,所以没有加入这个参与约束,因此这种策略是不可行的。 到目前为止,我们已经求出了一个完全分离均衡y1(t)=t+b+δb,y2(t)=t。当中央政府采取这一策略的时候,地方政府有动机在第一期揭露其真实信息。但是我们也发现,在完全分离均衡下,中央政府在第一期的决策水平较大地偏离了其最优水平,也就是说,中央政府为了在第二期做出最优决策,在第一期要付出较大的成本。事实上,我们可以找到在完全分离均衡基础上进一步提升中央政府效用的代理机制,本文将在之后的定理中具体分析这一改进方式。 由之前的定理结论可知除了上述的完全分离均衡之外,中央政府也可以采取完全混同策略:在第一期选择混同策略y1=1/2;在第二期选择静态最优代理机制(当t≤1-2b时,则y2=t+b;当1-2b≤t≤1时,则y2=1-b)。接下来我们将给出第一期时完全分离均衡优于完全混同均衡的条件。 定理3:如果(1+δ+δ2)b2+4δb2/3<1/12,则在第一期时有完全分离均衡优于完全混同均衡。 证明:在完全分离均衡中,中央政府在两期的决策为y1(t)=t+b+δb,y2(t)=t,此时中央政府的效用为: (11) 在完全混同均衡中,中央政府在两期的决策分别为y1(t)=1/2,如果t≤1-2b,则y2=t+b;如果1-2b≤t≤1,则y2=1-b。此时中央政府的效用为: (12) 这个定理给出了在第一期完全分离策略优于完全混同策略的条件,然而在两期代理模型中,中央政府除了可以采取上述的完全分离策略和完全混同策略,还可以采取两区间代理策略。两区间代理策略是指中央政府在第一期将真实信息t划分为两个区间,分别在两个区间上采取完全混同策略。接下来我们可以证明,当b满足一定条件时,中央政府可以通过将第一期的信息类型划分成两个区间来提高自身效用。下面的定理证明了在两期代理模型下,两区间均衡优于完全混同均衡却仍被占优于完全分离均衡的条件。 定理4:两区间代理策略优于完全混同策略却仍被占优于完全分离策略的充分条件为:b值满足(1+δ+δ2)b2+8/3δb3<1/48。 (13) 对这一策略的直观解释是:对于中央政府来说,第一期的信息分离之所以能提高效用,是因为能使其在第二期做出最优决策,但是这一分离的成本是第一期的决策极大地偏离最优水平,且这一偏离程度越高,成本就越高。通过混同低类型的信息,中央政府可以降低第一期决策的偏离程度。因为在完全分离策略中,第一期的决策水平为y1=t+b+δb,当t足够小时,对于中央政府来说,在第一期采取比y1=t+b+δb更接近其最优水平y=t的策略y1(t)=y1,此时提升的第一期的效用足以弥补第二期混同策略下的效用损失。 在我们的模型中,我们假设在上述临界值的左侧,中央政府在两期均采用完全混同策略。事实上,如果中央政府在第二期采取静态最优代理策略,可以进一步提高自身效用,但也会使得我们的计算更加复杂。本文重点在于说明存在不连续的代理策略优于完全分离策略,即使在左侧只是最简单的两期完全混同策略也能优于完全分离策略,那么更复杂形式下的不连续代理策略就更占优了。 (14) 因此有: (15) 通过整理,我们可以将UD-US>0写成如下形式: (16) (17) 对于上述单侧不连续代理策略占优于完全分离策略,我们有较为直观的解释。在完全分离策略下,中央政府为了让地方政府揭露其真实信息,第一期的决策水平过于偏离其最优水平,由此导致了过多的效用损失。而在单侧不连续代理策略下,中央政府在左侧信息区间内采取两期的完全混同策略,虽然这将导致第二期的效用损失,但也将大量减少第一期的效用损失,最终仍然能提升中央政府的效用。 图5 左侧不连续下的两期代理机制 图6 两侧不连续下的代理机制 证明:和定理5的证明类似,在此省略。 对于上述双侧不连续代理策略占优于单侧不连续代理策略,我们有较为直观的解释。在单侧不连续代理策略下,中央政府仅在左侧低类型信息区间上采取两期的完全混同策略,但在右侧的高类型信息区间上,仍然存在进一步的改进空间。在右侧的高类型信息区间上,为了让地方政府揭露其真实信息,第一期的决策水平过于偏离其最优水平,由此导致了过多的效用损失。而在双侧不连续代理策略下,中央政府在右侧信息区间内采取两期的完全混同策略,虽然这将导致第二期的效用损失,但也将大量减少第一期的效用损失,最终仍然能提升中央政府的效用。 定理7:最多存在一个连续区间[t1,t2],在该区间内完全分离策略是最优的,其中t1>0,t2<1,并且,从中央政府的角度来说,该区间内决策水平y是关于t的非减函数。 此时中央政府的期望效应为: 因此中央政府的目标为: 上式可简化为: 拉格朗日方程为: 由此可得: 本文从信息传递的角度出发,一方面构建了多个不同信息传递机制下的理论模型,包括中央集权、廉价磋商和财政分权,通过对不同模型结果的比较,从而验证了财政分权体制的合理性、优越性和局限性。另一方面探讨了更具有现实意义的两期下的中央政府与地方政府的博弈,构建了中央政府有限承诺下的两期代理模型。首先我们给出了在两期动态博弈下中央政府的连续最优激励机制,该机制使得地方政府有动机在第一期揭露其真实信息,从而使得中央政府可以在第二期采取最优决策水平。之后我们研究了对这一连续激励机制进一步优化的方法,从而发现在信息区间上存在不连续的代理机制,可以在完全分离均衡的基础上进一步提升中央政府的效用。 在所有模型中,我们假设中央政府和地方政府的偏好不同,也就是各自对于当地的最优财政支出水平的偏好不同。对于地方政府而言,当其自身激励与居民福利相契合时,其最优支出水平就是最大化居民效用的公共产品供给水平;但是中央政府要考虑的不仅是某个区域的居民利益,更是全国整体的利益,因此中央政府需要统一协调全国各地的公共产品供给,实现资源在全国范围内的最优配置。正是由于两者的角色不同,中央政府与地方政府在当地财政支出水平上必然存在不同的偏好,因此双方的效用函数存在差异。 然而本文证明了完全分离策略并不是最优的,因为在完全分离策略下,中央政府为了让地方政府揭露其真实信息,第一期的决策水平过于偏离其最优水平,由此导致了过多的效用损失。之后本文证明了总是存在不连续代理策略占优于完全分离策略,在不连续代理策略下,中央政府将在某些信息区间内采取两期的完全混同策略,虽然这将导致第二期的效用损失,但也将大量减少第一期的效用损失。 中央政府拥有两期的承诺能力是很有利的,但因为种种原因,现实中中央政府很多情况下的承诺能力是有限的,本文的模型给出了政府在不同承诺力下的最优机制,具有重要的理论和现实意义。 本文并未考虑两期代理模型下地方真实状态t值在两期不同的情形,同时本文假设中央政府和地方政府对于两者之间的收益偏差b值的信息是一致的,后续研究可以从上述这两点进行拓展。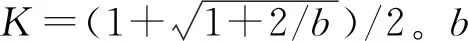

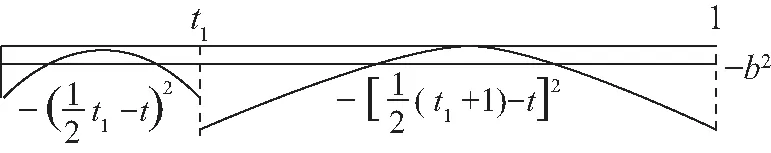

(二)两期情况下的模型
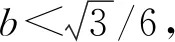
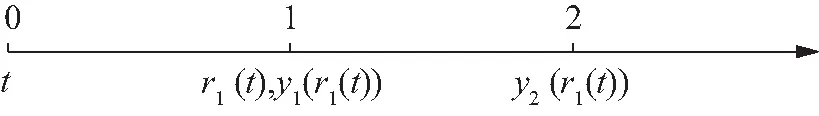
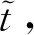
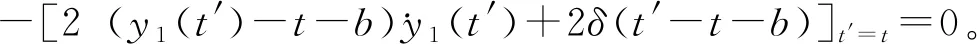
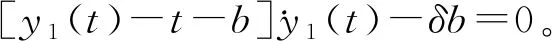
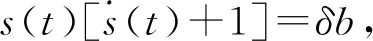
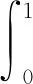
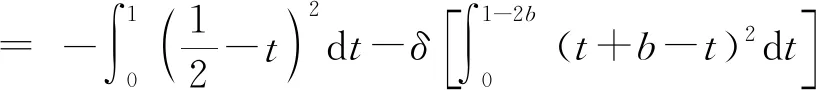
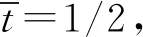
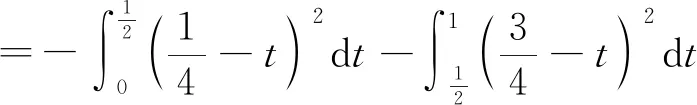

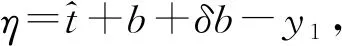
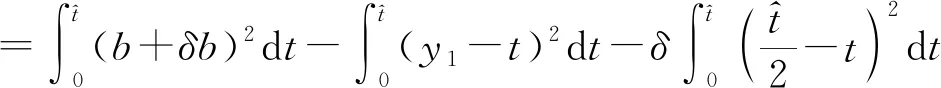



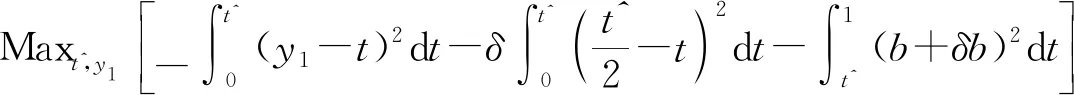
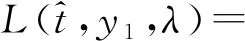


四、结论
 猜你喜欢
当代工人(2022年5期)2022-03-31中国管理信息化(2021年20期)2021-11-23环球时报(2019-06-26)2019-06-26科技经济市场(2016年6期)2016-09-03中国市场(2016年44期)2016-05-17学生天地·小学中高年级(2016年8期)2016-05-14西南政法大学学报(2014年4期)2014-09-26中国火炬(2014年8期)2014-07-24中国火炬(2014年1期)2014-07-24中国火炬(2012年2期)2012-07-24
猜你喜欢
当代工人(2022年5期)2022-03-31中国管理信息化(2021年20期)2021-11-23环球时报(2019-06-26)2019-06-26科技经济市场(2016年6期)2016-09-03中国市场(2016年44期)2016-05-17学生天地·小学中高年级(2016年8期)2016-05-14西南政法大学学报(2014年4期)2014-09-26中国火炬(2014年8期)2014-07-24中国火炬(2014年1期)2014-07-24中国火炬(2012年2期)2012-07-24
