
雷达信号知识挖掘方法研究∗
2020-10-10 02:44
舰船电子工程 2020年8期
(中国船舶重工集团第七二三研究所 扬州 225001)
1 引言
雷达辐射源在不同量程上采用不同的信号波形完成探测功能。传统雷达通过手动切换量程方式完成量程切换,这使得雷达辐射源的信号具有稳定性的特征。而根据外场数据采集分析的结果,当前导航雷达采用近程和远程同时覆盖的方式完成探测。以提高雷达的数据率和扩大雷达的探测范围。图1为具有两个量程导航雷达信号示意图,第一个量程内采用N个参数为{RF1,PRI1,PW1}的脉冲串,第二量程内采用1个参数为{RF2,PRI2,PW2}的脉冲。
传统的信号分选方法有积累时差直方图法(CDIF)[1]、不积累时差直方图法(SDIF)[2]、序列检索法[3~4]、智能外推窗匹配法[5]、综合参数相关法[6]等方法。上述基于到达时间TOA的分选方法能够分选出导航雷达的第一个量程内的脉冲信号;而无法应对第二个量程内的脉冲信号,或者导致信号分选增批。在进行主处理时,造成信号识别性能下降,影响指战人员对战场态势的判断。
数据挖掘是从已知数据集合中发现各种模型、概要和导出值的过程[7]。传统的信号分选方法已经无法应对上述雷达信号的处理。针对雷达辐射脉冲信号中的模式,本文采用GSP(generalized sequential pattern)算法对雷达信号知识进行挖掘[8]。该算法通过传统信号分选方法,聚类出子序列,在子序列的基础上在挖掘更大尺度结构模型,增加了扫描的约束条件,有效地减少需要扫描候选序列的数量。在完成数据挖掘后,形成规则库用于对雷达辐射源的标注和识别。
因此雷达信号知识挖掘的流程如图2所示。
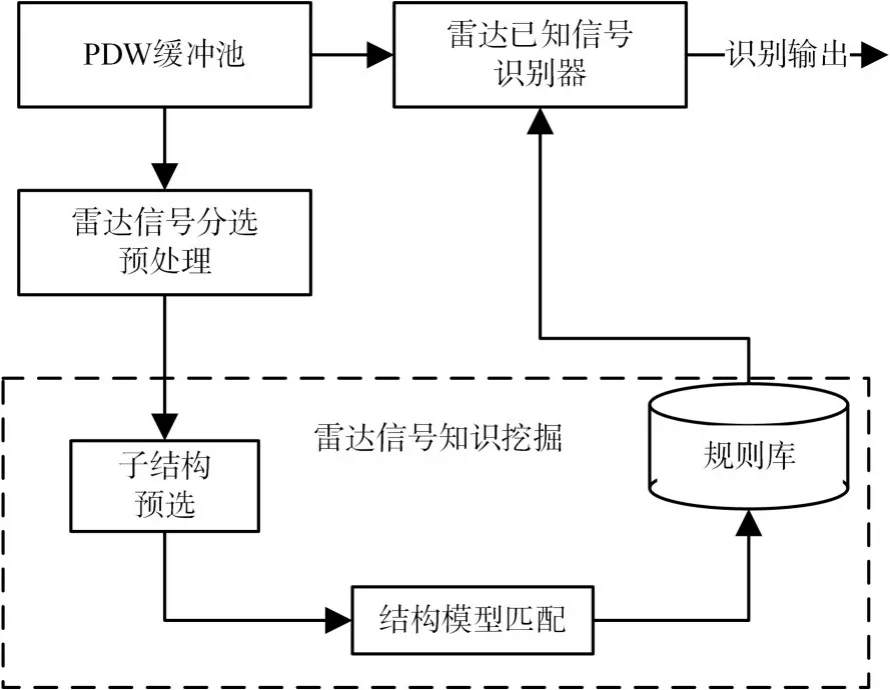
图2 雷达信号知识挖掘流程图
通过上述方法对雷达信号的模式挖掘,并形成雷达信号识别规则库,提高雷达辐射源描述的完整性和对雷达辐射源识别的准确性;降低雷达辐射源的增批。有效提高对战场雷达辐射源的态势把握。
2 雷达信号分选预处理
雷达截获接收机接收到一系列按到达时间(Time of Arrive,TOA)先后顺序排列而成的脉冲,包含了多部雷达信号发射的信号以及干扰、噪声脉冲序列。雷达信号分选就是从这种交错的脉冲流分离出各种雷达的脉冲序列,并筛选出有用信号的过程。雷达信号分选的基本方法是利用雷达信号的规律性,判断脉冲流中的每个脉冲来自于哪个雷达。
从数学上看,雷达分选过程是从接收到的脉冲序列中,发现各辐射源模式并进行分离的过程。传统的雷达辐射源信号分选预处理采用的基本方法有积累时差直方图法(CDIF)、不积累时差直方图法(SDIF)、序列检索法、智能外推窗匹配法、综合参数相关法等方法。
序列检测法相当于数据挖掘算法中的Apriori-All算法,其基本思想为首先遍历PDW(Pulse Description Word)生成候选序列并利用Apriori性质进行剪枝得到频繁序列。每次遍历都是通过连接上次得到的频繁序列生成新的长度加1的候选序列,然后扫描每个候选序列验证,与最小值尺度进行对比,判断其是否为固定模式。
CDIF,SDIF方法是对序列检测法的改进。它在频率、脉宽、方位上进行一致性约束,而在时间序列上对雷达辐射源的模式挖掘进行约束。SDIF由于不需要进行累计,因此具有更小的计算量和更快的计算速度。SDIF分选方法分为PRI(Pulse Recurrence Interval)的估计和序列搜索两部分组成。
首先,计算相邻两脉冲TOA的差形成第一级差值直方图,计算门限,然后进行子谐波检测,如果有一个超过检测门限值,则把该值作为可能的PRI进行序列搜索,如果没有超过门限的值,则计算下一级的差值直方图,然后对可能的PRI进行序列搜索。若能成功的分离出相应的序列,则从采样序列中扣除,并且对剩余的脉冲从第一级开始形成新的差值直方图,在经过子谐波检验后,如果不止一个峰值超过门限,则从超过门限的峰值所对应的最小间隔起进行序列搜索,最后进行参差鉴别。SDIF算法不对不同级的差值直方图进行累积,而只检测当前级的差值直方图。SDIF算法的最佳检测门限为
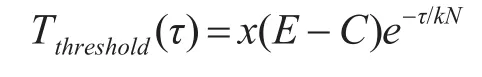
其中,E为脉冲总数,C为直方图阶数,N为直方图的PRI个数,k为小于1的正常数,常数x由实验确定(与丢失脉冲的概率有关)。
设待分选的信号是三列交织在一起的脉冲串,PRI1=1041us,PRI2=1210us,PRI3=1350us。仿真结果如图3所示。
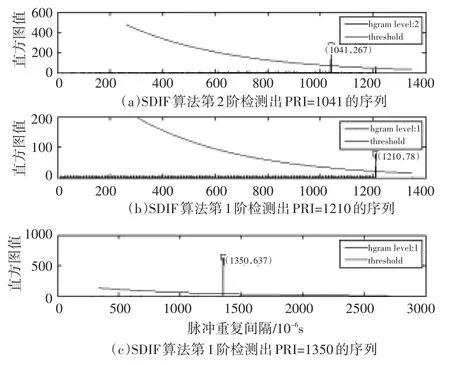
图3 SDIF仿真结果
CDIF,SDIF进行信号分选时进行频率、脉宽、方位一致性的假设。在该假设的前提下在进行雷达模式的提取。而随着雷达技术的发展对雷达的频率和脉宽进行一致性假设已经不符合实际的情况。因此需要在更高的层次上挖掘模式。传统的信号分选方法针对近远程同时兼顾的雷达信号的处理结果如图4所示。
图4中红点为已分选脉冲,白点为未分选脉冲。其中脉冲宽度较宽的脉冲是远程探测时采用的脉冲波型信号。导致其未分选的原因是该脉冲与近程模式下的脉冲参数不满足一致性要求,该脉冲不会进入SDIF的处理流程。
3 雷达信号知识挖掘的约束
雷达信号知识挖掘可以通过类似AprioriAll算法的序列检索法进行挖掘。在进行序列检索法进行数据挖掘时需要考虑以下几种约束。
1)计算复杂度:ESM(Electronic Support Measures)设备对信号处理具有实时性处理的要求,因此要求算法具有计算复杂度小的特点。整个序列的总数要进行限制,否则由于计算复杂度的提升导致算法无法使用。
2)物理限制约束[9]:雷达辐射源为完成其探测功能。在参数选取上根据其技术体制进行选区。这些技术体制决定了雷达辐射源的参数。对于恒频脉冲波形信号来说,设脉冲持续时间为τ,重复间隔为PRI。则其最大非模糊距离为
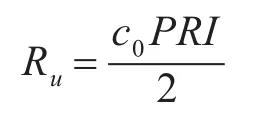
盲距区间长度为

距离分辨率为
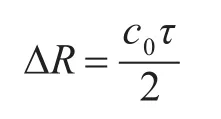
多普勒分辨率为
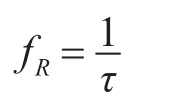
径向速度分辨率为
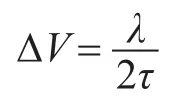
而这些参数是相互制约的,因此对雷达辐射源的信号来说,其参数选取是根据物理约束进行的。因此在进行数据挖掘和频繁项剪枝时需要考虑这些物理约束。
因此在备选模式选择时,形成一系列的物理约束条件,不满足这些物理约束条件的备选项,不进行被选模式的选择。在最终剪枝时,将不符合物理约束的模式项剪除。
因此对雷达信号的知识掌握越多,则雷达信号挖掘的复杂度越小,算法的实时性越高,挖掘出来的雷达知识越准确可靠。
4 雷达信号知识挖掘流程
根据AprioriAll算法的基本思想[10],在此基础上增加序列长度的限制,SDIF预分选子结构预选,最大贪婪子序列扩展,结构模型匹配最终形成针对雷达信号的 GSP(generalized sequential pattern)算法。其算法流程如下所示。

1)利用传统SDIF算法进行信号分选,SDIF将具有重频具有固定规律(固定,参差,抖动等类型)的雷达信号分选出来。以分选出来雷达参数信息作为基本子序列。经过SDIF后选择为基本子序列的结构如图5所示。
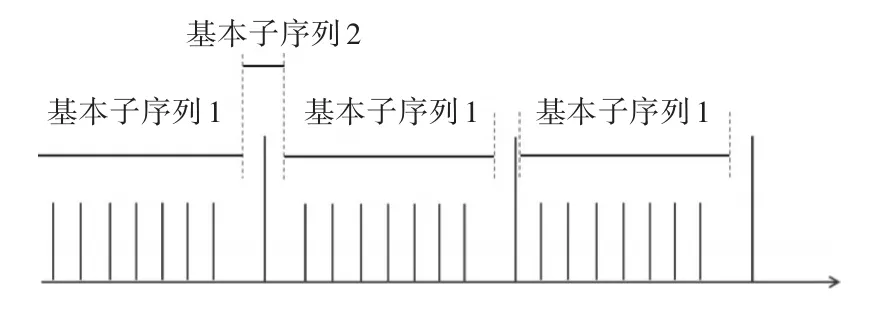
图5 基本子序列结构
2)根据子序列间脉冲数量确定子序列可以扩展的最大值。降低搜索的空间,减少不必要的空间搜索。
3)根据备选的K序列利用最大贪婪子序列扩展方法,对所有的子序列进行由大到小的扩展,避免子序列合并的工作。
4)构造扩展子序列时序和脉宽绝对差值累积匹配模型,通过模型匹配检测扩展后的相邻子序列是否匹配,如果匹配则相应的支持度增加。
5)如果扩展子序列的支持度大于最小支持度门限,则进行物理约束检验。物理约束检验主要通过雷达支持的最小、最大参数及信号处理方式带来的约束上进行。
6)根据生成的雷达信号模式生成正则表达式规则。正则表达式的表达方法为
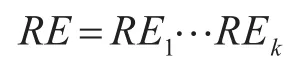
其中每一个正则表达式的结构为该子结构的正则表达式结构。
子结构的正则表达式采用雷达载频参数(包括载频参数、重复间隔参数、脉宽参数、调制参数等参数)通配符进行表达的方法进行。
5 雷达已知信号识别
为了快速识别出战场中的雷达辐射源信号信号一般将正则规则的匹配过程在高速并行的可编程逻辑器件上进行实现[11~12]。可编程逻辑器件由于可以同时完成很多路的信号的匹配和跟踪。雷达已知信号识别的工作流程如图6所示。
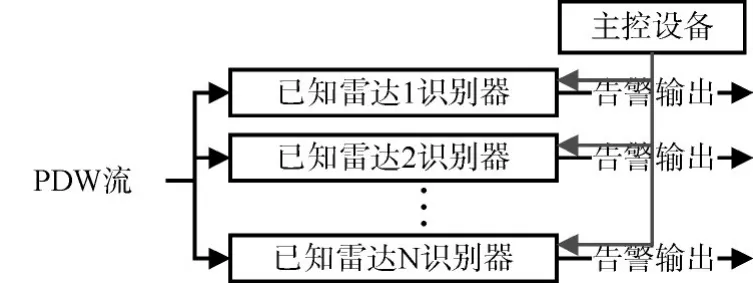
图6 雷达已知信号识别流程
主控设备完成N个已知雷达识别器的规则装订,并负责已知雷达识别器的启停控制工作。PDW流被同时送到N个已知信号识别器进行识别。
单个已知信号识别器工作的流程如图7所示。

图7 单个已知信号识别器工作流程
在进行单个已知信号识别器进行工作时,首先并行对K个子规则进行匹配。然后进行总规则进行合法性检查。当检测到符合总规则的脉冲序列时立即启动告警输出,完成已知信号的识别工作。
6 试验结果
本节利用外场采集的导航雷达数据进行试验验证。该导航雷达为远近程同时探测的机械扫描雷达。在信号采样时,采样频率Fs=1GHz,中频频率为1.100GHz。该雷达采用两种信号样式来对远近程同时探测。在进行模式匹配时,所选择的最小支持数为4。
通过雷达知识挖掘,挖掘出雷达远近程兼顾的雷达信号模式。挖掘后的结果如图8所示。

雷达信号挖掘前效果图
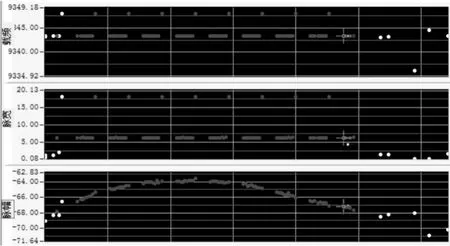
图8 雷达信号挖掘后的效果图
如图所示,雷达信号挖掘前依赖于传统的序列直方图分选方法分选,远程模式下的雷达参数被丢弃作为未处理脉冲。雷达信号挖掘后挖掘出雷达完整的工作模式,并形成了完整的雷达辐射源模式规则。用于雷达辐射源识别。根据采样的信噪比估计,该方法在雷达信号的信噪比大于4dB时有效。
7 结语
本文采用 GSP(generalized sequential pattern)算法对雷达信号知识进行挖掘。利用SDIF分选算法预选出子序列,在子序列的基础上在挖掘更大尺度结构模型。对扫描的脉冲总数和序列扩展的最大长度进行了限制;对挖掘出来的模式进行物理符合性验证。并将挖掘出来的模式形成正则关系表达式,用于对对雷达辐射源的已知信号识别中。实现了一种低计算复杂度,高效的雷达信号知识挖掘方法。通过外场真实数据试验验证表明,本算法可以在较低信噪比条件下实现对雷达信号知识的有效挖掘。本算法满足实时性要求,适合于雷达电子对抗装备中应用。
猜你喜欢
舰船电子工程(2022年7期)2022-09-06
军民两用技术与产品(2021年7期)2021-10-13
北京航空航天大学学报(2020年10期)2020-11-14
舰船电子对抗(2020年1期)2020-04-27
影像视觉(2018年12期)2018-11-29
中学生数理化·高一版(2017年2期)2017-04-25
初中生世界·八年级(2017年3期)2017-03-24
理科考试研究·高中(2016年8期)2016-05-14
基层建设(2015年36期)2015-10-21
现代电子技术(2015年15期)2015-08-14
