
词干单元和卷积神经网络的哈萨克短文本分类
2020-09-07 01:49沙尔旦尔帕尔哈提米吉提阿不里米提艾斯卡尔艾木都拉
小型微型计算机系统 2020年8期
沙尔旦尔·帕尔哈提,米吉提·阿不里米提,艾斯卡尔·艾木都拉
(新疆大学 信息科学与工程学院,乌鲁木齐 830046)E-mail:sardar312@126.com
1 引 言
近年来,文本分类问题在许多实际应用中得到了广泛的研究和解决.尤其是随着自然语言处理(NLP)和文本挖掘方面的技术突破,越来越多的研究人员开始对开发依赖于文本分类方法的应用程序感兴趣.文本分类是NLP领域的一个重要应用.自动文本分类是根据文本的内容或主题为文本自动分配一个或多个适当类别的方法[1-3].自动文本分类在情感分析[4],实时事件检测[5],查找热门话题[6]等信息检索领域被广泛应用.文本分类中的一个关键问题是如何在计算机上有效地表示文本中的特征.
哈萨克语是一种派生类语言.哈萨克语的句子由自然分开的词组成.词是由后缀所附的词干构成,因此,哈萨克语中构词和词性变化较复杂,词汇量巨大.其中,词干是具有实际意义的词汇单元,词缀提供语义和语法功能,因此,通过对哈萨克文本的词素切分以及词干提取等预处理操作来我们可以保留有意义的和有效的文本特征,并能够有效地降低特征的反复率和维数.因此,词干提取是哈萨克文本分类任务中重要的基础性工作,如以下例子所示:
(原型)jaresta jaresneN soNGe jares nomeren alep,taNdaw jarestan jENespEn votte.
(词素切分后)jares+tajares+neN soNGejaresnomer+en al+ep,taNdawjares+tan jENespEn vot+te.
以上句子中文意思是:在比赛中取得比赛的[比赛]终局分数,胜利地通过了选赛.在中文中大括号[]里的‘比赛’这个词一般不会出现的,但在以上哈萨克句子中对应于这个词的第四个词jares是必不可少的.
以上哈萨克句子中有10个词,其中四个词的词干(被加粗部分)都是/jares/(比赛),将以上句子经过词素切分和词干提取后,四个词的主要意思能够由一个词干来表示,并且可以获取四个词特征,因此大幅降低特征的维数,如表1所示.

表1 哈萨克词语变体
哈萨克语形态结构上的多种变化以及缺乏的语言资源是哈萨克语NLP中的主要问题之一,从互联网上搜集的文本数据具有带噪声的拼写以及不确定的编码等特点,因此,对带噪声的哈萨克短文本可靠地进行提取和分类变得一种富有挑战的任务.然而,带噪声短文本数据的提取与分类是哈萨克语NLP必然的重要一环.
目前,部分学者提出了一些哈萨克文本词干提取[7,8]和分类方法[7,8,10-12].文献[7]用词干和附加成分表对训练文本的词语进行分割,并结合哈萨克语词法规则来提取词干.文献[8]用词法分析和双向全切分相结合的方法对哈萨克文本进行词缀切分和词干提取,并与预先准备好的词干表进行匹配,来试图提高词干提取的效率.以往的这些哈萨克文本词干提取有关的研究大多基于简单的词法分析和一些人工收集的规则,因此存在歧义,尤其是对于短文本而言.哈萨克语词干提取任务中一个特殊的问题是语音的和谐与不和谐,这个问题导致词形的变化,这需要句子层面的语境分析来解决.我们提出的基于句子或较长上下文的词素切分和词干提取方法[9]能够为整个哈萨克句子提供形态分析功能,能够准确地预测到带噪声的哈萨克文本中的词干与词条,并且可以有效地降低文本中的歧义.
文献[11]用SVM分类器在包括五个类别的460篇哈萨克文本的语料库上进行文本分类实验,并得到87.6%的分类准确率,文中没有提到被用到的文本表示和特征选择方法.文献[7]对词频和语言信息进行简单的统计来选择特征,在包括五个类别的296篇哈萨克文本的语料库上进行文本分类实验,该实验把KNN选作为分类器,并得到84.98%的平均分类准确率.文献[10]用向量空间文本表示模型提取哈萨克文本的特征,用文本频率比值法(DFR-Document Frequency Ratio)进行特征选择,以SVM和改进的KNN为分类器,在包括五个类别的200篇哈萨克文本的语料库上进行文本分类实验,并得到82.2%的分类准确率.文献[12]用专属于维吾尔语或者哈萨克语文字的特殊字符、维吾尔语和哈萨克语字母组合方式和词缀的差异以及这两种语言发音习惯的不同而产生的字母上的差异等启发式特征对单词数不超过14的维吾尔语和哈萨克语短文本进行文本语种分类实验,并得到95.1%的精确率,该文没有对语料库文本内容所属的类别进行分类.文献[8]用DFR方法对原始特征空间进行降维,把SVM和KNN分类器相结合,先用SVM确定每个类别的支持向量,然后用欧氏距离计算测试样本和支持向量之间的距离,以此在包括八个类别的1400篇哈萨克文本的语料库上进行文本分类实验,并得到77.8%的平均分类精度,文中没有提到文本特征表示所用的方法.在哈萨克文本分类中被使用的这些方法对词的频率进行简单的统计,用传统的特征表示方法(其中部分研究中用到的文本表示方法是未知的)来表示哈萨克文本特征以及对传统的分类器做一些简单的结合来实现分类器的改进.
上述哈萨克文本分类方法是浅层的机器学习,其中文本的语义含义不明确,忽略了文本较长的上下文信息,不能够有效的捕获词语之间的语义关系,特征提取和选择需要人工完成,分类准确率低.因此,哈萨克文本分类任务迫切需要一种有效特征提取和选择的方法来提高其分类的效率.
本文提出了基于词干单元和word2vec_TFIDF以及卷积神经网络(CNN)的哈萨克短文本分类方法.通过对齐的词-词素平行训练语料库来训练统计模型,并从互联网上收集的哈萨克短文本中高效地提取其词干,用word2vec算法对词干进行向量化,并使用词频-逆文档频率(TFIDF)算法对词干向量进行加权处理,以此提取包含文本上下文之间语义关系的有效文本特征后,利用CNN作为特征选择和文本分类算法,进行文本分类实验.
2 哈萨克文本表示和分类方法
随着神经网络的兴起,许多适合自然语言的神经网络模型被提出[13,14].Bengio等人[13]2003年提出了一种基于神经网络的语言模型构建方法.在此基础上,Miklov等人[14]2013年提出了word2vec算法,并通过文本上下文信息来描述一个单词的表示,得到了可以表示单词之间的语义关系的低维的密集向量.
2.1 哈萨克文本处理
由广泛的跨语言和跨文化交流所引起的书写形式上的不确定性在给哈萨克文本带来噪声的同时,也导致新词、新概念和新表达的持续出现.这些新词大多是借用新进的外来词(OOV)或词干,以及由于拼写习惯的不同和方言的变形而引起的噪音整合而成.哈萨克语书写系统在历史上的变化是引起不确定的书写形式的另外一个重要原因之一.现代社会的哈萨克语书写形式也被这些书写系统所影响,虽然在官方媒体出现的可能性不大,但是广泛地在网上论坛和聊天工具中存在.
我们实验室开发的多语言词素切分和词干提取工具[16,17]将哈萨克语单词分割成词干和词缀等词汇单元.该工具根据哈萨克语的词素与语音规则,从对齐的哈萨克词-词素平行句子中能够自动地学习哈萨克语词语的各种表面形式与声学变化.哈萨克语具有词素边界上的音素根据语音和谐规则改变其表面形式的特点.在正确地表达词语的发音时,文本中可以明显地观察到语音和谐.一个候选词送入给该词素切分器[16,17]的搜索模块之后,通过根据哈萨克语的词素规则准备的词干和词缀列表以及语音和谐与不和谐等语音规则来迭代地运用匹配方法对候选词进行切分,该候选词被逐渐切分,分别与词干、词缀列表以及词的各种表面形式匹配,并导出所有可能的词素切分形式.然后,这些切分结果送入给统计模块,并计算所有切分结果的概率之后,从前N个最好的切分结果中选择最佳词素.该工具为有效地提取哈萨克语文本中的词干提供了可靠的依据,有效地改进了哈萨克短文本分类任务,词素切分流程如图1所示.

图1 词素切分流程
本文中用该词素切分工具[16,17]在5000个哈萨克词-词素平行训练句子上训练统计模型(其中80%的部分用于训练,剩余部分用于测试),并进行词素切分与词干提取实验,最终得到95.87%的词干提取准确率,如图2所示.这是通过切分工具所得到的与人工切分的词素完全匹配的结果.

图2 词素切分结果
通常,网上收集到的文本语料库中不同文本所包含的单词数是不一样的.因此,为使语料库中的文本词数相等,以便生成随后输入到CNN网络中的文本矩阵,我们对文本集执行填充操作来修改文本中的词数.本文对语料库每个原始文本中的单词数量进行了统计,如图3所示(图3中,横轴表示文本中的单词数量,纵轴表示不同单词数量对应的文本数量).

图3 实验文本词长统计
从图3可以看出,文本集中的文本大概包含60到120个词左右,其中词数约在100个左右的文本数量最多.所以,本实验中输入给CNN的所有文本的标准词数选为100.词数不到100的文本,则后向补零处理.同理,从文本集中提取词干,并形成词干序列文本集之后,选择了每篇文本中的前100个词干为CNN的输入,如果词干数不到100,则后向补零处理,以生成CNN所需的输入矩阵.
2.2 基于word2vec_TFIDF的文本表示
2.2.1 词向量学习方法
词(词干)嵌入是通过word2vec技术从训练语料库中生成的以词出现的上下文为基的实数向量[18].Word2vec训练所生成的词干向量可以用作许多自然语言处理任务.两个词干之间的语义相似度可以通过计算这两个词干的词干向量之间的距离来容易地被判断.Word2vec中有两种主要的学习算法:CBOW(连续词袋)算法[19]和Skip-gram算法[20].
CBOW是根据上下文词干st-c,s(t-c)-1,…,st-1,st+1,st+2,…,st+c来预测当前的词干st出现的概率p(st|st-c,s(t-c)-1,…,st-1,st+1,st+2,…,st+c).CBOW模型通过c个上下文词干来表示当前的词干st,c是预选窗口的大小,用CBOW算法对文本进行训练后得到词干st的词干向量,如图4所示.本文使用CBOW算法进行词干向量的训练.

图4 CBOW模型结构
与之相反,Skip-gram 是根据当前词干st来预测上下文词干st-c,s(t-c)-1,…,st-1,st+1,st+2,…,st+c的出现概率p(st-c,s(t-c)-1,…,st-1,st+1,st+2,…,st+c|st).
我们通过计算采用word2vec工具所形成的词干向量之间的余弦距离来能够判断词干之间的语义相似度.词干向量之间的余弦距离值越大,则词干的语义相似度越高;反之,语义相似度就越低,如表2所示.
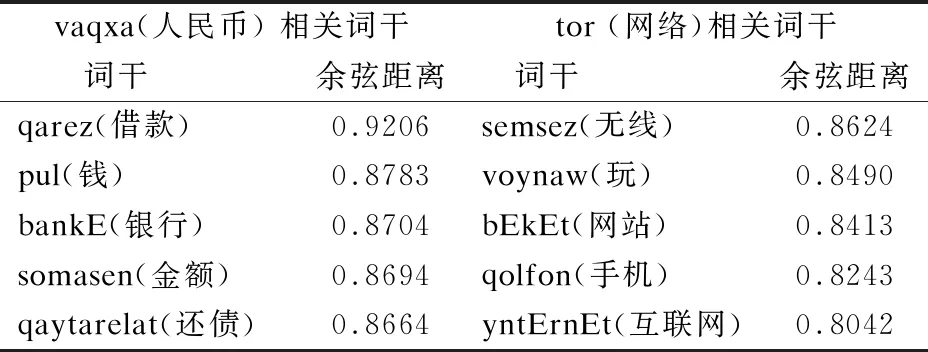
表2 词干向量语义相似度
从表2可以看出,通过词干向量之间余弦值的计算,获得的与哈萨克词干vaqxa(人民币)和 tor(网络)语义相似度最高的五个词干.
2.2.2TFIDF权重
对于包M含个文本的集合D,其中Di(i=1,2,…,M),通过CBOW模型得到词干向量.对于文本中的每个词干,通过TF-IDF算法计算其权重值tfidf(t,D),它是指词干t在文本Di(i=1,2,…,M)中的权重值.TF-IDF考虑单个文本中的词干频率tf和整个文本集的词干频率idf.TF-IDF的计算公式如公式(1)所示:
(1)
其中,tf(t,Di)是词干t在第i个文本中的出现频率,分母是归一化因子.idf(f)是词干t的逆文档频率,计算公式如公式(2)所示:
(2)
其中,M是训练集中文本总数,nt是词干t在训练集中的出现频率.
每个词干的词干向量被tfidf值加权来表示一个文本,如公式(3)所示:
(3)
vec(Di)指的是每个文本Di的词干向量,wt表示词干t的N维词干向量,tfidf(t,Di)表示词干t在文本Di中的TF-IDF权重值.
2.3 卷积神经网络框架
CNN是Lecun等人[21]提出的一种深度学习模型,Kim[22]首次把CNN用于文本分类.CNN可以在词干向量的基础上自动提取和学习句子的特征,从而减少了对人工选择特征的依赖性,并优化了特征选择的效果.CNN在结构上的主要特点是卷积层和最大池化层的交替累积.本文中用的CNN模型由4个不同的层组成,分别为:输入层、两个卷积层、两个池化层和全连接层,如图5所示.

图5 CNN框架
1)输入层.CNN的第一层是输入层,其中输入参数是文本预训练后得到的词干向量.输入矩阵的形式是(n,s,k),其中n是文本的数目,s是固定的文本长度(CNN输入文本的长度需要相同),k是词干向量的维数.v(wi)∈Rk表示对应于第i词干wi的k维子词干向量.在这种情况下,输入文本可以表示为公式(4).其中,⨁是级联运算符号.
t1:s=v(w1)⨁v(w2)⨁…⨁v(ws)
(4)
2)卷积层.卷积层是网络的核心部分.该层通过卷积核来对网络前一层的特征图进行卷积运算,以此生成新特征.卷积运算采用卷积矩阵窗口w∈Rk×h来生成一个新的特征图.其中,k是词干向量的维数,h是窗口内词干的数目.每个新生成的特征值可以从公式(5)中获得.
ct=f(w·Wi:i+h-1+b)
(5)
在公式(5)中,ci是由一个窗口词干wi:i+h-1所生成的一个新特征,b是偏置项,算子“·”是指卷积运算,f()是激活函数.当卷积矩阵窗口移动一步时,所有输入矩阵由窗口(w1:h,w2:h,…,ws-h+1:s)卷积,并生成相应的特征映射c=(c1,c2,…,cs-h+1).
3)池化层.池化层的输入是在卷积层中生成的特征矩阵.池化层的功能是对由卷积层所生成的特征图进行采样.本文使用最大池化方法,因为它能够使模型提取最突出的特征,如公式(6)所示.在公式(6)中,ci表示在卷积层中产生的特征图,m是特征图的数目.
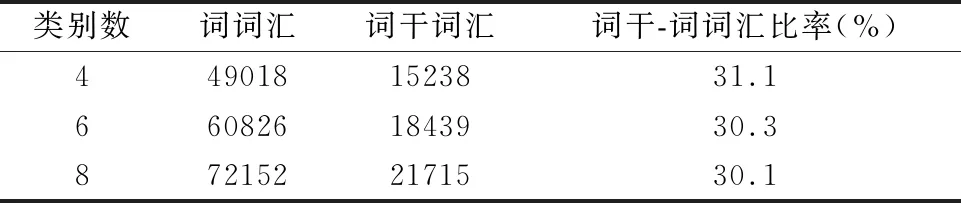
cmax=max(ci) 0 (6) 4)全连接层.CNN的最后一层是全连接层,它将所有的特征和输出值连接到分类器.该层使用Softmax分类器对来自池化层的特征向量进行分类操作,并输出最后的分类结果. 对于文本集Di(i=1,2,…,N),利用CBOW模型对文本进行训练后得到文本向量vec(Di).然后,对所有得到的文本向量进行修改,以形成卷积神经网络处理所需的矩阵.CNN的输入文本可以表示为公式(7).其中,T1:n表示所有的输入文本,⨁是级联运算符. T1:n=vec(D1)+vec(D2)+…vec(Dn) (7) 因为哈萨克文本分类处于初级研究阶段,没有公开的哈萨克文本语料库,所以构建哈萨克文本语料库需要从网上下载文本,才能进进行实验. 本文通过爬虫官方哈萨克文网(1)kazakh.people.com.cn,从网上下载哈萨克文本来建立实验语料库.该语料库包含旅游、教育、科技、文华、经济、法律、娱乐和体育等8个类别,每个类别有900篇文本,共7200篇文本.本文用75%文本作为训练集,10%文本作为验证集,其余部分作为测试集. 哈萨克文本因受其它语言的影响以及个性化等原因,从网络上下载的文本容易出现拼写错误.所以我们编写了哈萨克文字拼写检查程序.该程序是通过对哈萨克语音节的结构形式和规则进行分析,从而能够找到存在拼写错误的大部分哈萨克词汇和不规则的外来词,这样我们便能更正给定词汇中的拼写错误.拼写检查程序流程如图6所示. 图6 哈萨克文本拼写检查程序流程 尽管Unicode是默认的编码方案,但不同的操作系统和组织仍在使用不同的编码.因此,我们建立一个代码映射表,将语料库中的文本集从各种不同的编码形式转换成统一的拉丁文字母编码形式,然后用词干提取工具从所有的文本中提取词干,以构建词干序列文本语料库.基于统计模型的哈萨克文本词干提取方法可以有效地减少文本特征空间的维数,其中,除掉停用词后(停用词数为1085),词干词汇的数量明显地下降到词词汇数量的30%左右,如表3所示. 表3 词干提取引起的特征空间维数的减少 从语料库的文本集中提取词干后,通过CBOW算法对此进行训练,生成词干向量;同时,对于语料库的文本没有进行词素切分和词干提取的情况下,通过CBOW算法直接在词序列构成的原始文本上进行训练,以此生成词向量.在word2vec训练时,词与词干嵌入维度和训练窗口的尺寸都设置为默认值,即,分别是100和5,迭代次数设置为5,batch_word设置为10000.取得词与词干向量之后,用TFIDF算法分别对所取得的词与词干向量进行加权. 常用于评价文本分类器性能的指标有准确率、精确率、召回率和F1分数等,对于某一个类别Ci的分类结果而言,如果正确分为该类的文本数目是a,错误划归为该类的文本数目是b,将该类文本错误划归为其他类的文本数目是c,属于其他类的文本正确分为所属类的文本数为d,则可以得到这些指标的计算公式如下: (8) (9) (10) (11) 本文使用准确率和宏F1分数评测了所提出方法的性能.宏F1分数是一个全局性指标,它同时兼顾了分类模型的精确率和召回率.计算宏F1分数时,先要计算每个类别的F1分数,然后计算它们的算术平均值作为宏F1分数. 本文实验使用Pytorch在具有GPU支持的Linux CentOS-7操作系统上实现CNN框架.本文将通过词素切分工具对文本集进行切分,并提取其词干之后,通过word2vec及TFIDF算法对词干进行向量化和加权,用KNN[7,8,10]、NB、SVM[7,8,11]和CNN等方法进行了比较实验.其中,在KNN、NB、SVM等传统方法中,通过x2特征选择方法对文本的特征维数进行降维,并把x2值最大的前100到2000之间的词干项选作为新的特征,以此分别进行了实验,如表4所示. 表4 基于传统方法的分类结果 基于CNN的方法中,本文用word2vec算法从文本集中分别生成100×100的词与词干两种向量,并用TFIDF算法对此进行加权之后,输入给CNN,做了基于词与词干的分类实验.本文实验了包括2个、4个和6个卷积层的多种CNN模型结构.从这些实验中发现,对本文的文本分类任务而言,最好的CNN模型结构由两组卷积层组成,每个卷积层后面跟着一个最大池化层.本文通过反复实验来确定在每个卷积层上设计尺寸为5×100的128个卷积核的效果最好.在第二个最大池化层之后,用一个dropout策略来避免发生过拟合现象,其dropout值设置为0.5.然后,附加一个长度为64的全连接层,后面跟着第二个dropout策略,最后的全连接层有八个节点,代表八个类别,每个节点的输出通过 softmax 函数后可以归一化,softmax 输出值可以理解为这八个类别的概率分布,如图5所示.CNN通过迭代计算获得权重,经过多次迭代后得到理想的参数,本次实验中,本文做了150次迭代运算,实验结果如表5所示. 表5 基于CNN的分类结果 从表4和表5可以看出,基于KNN、NB和SVM的分类准确率最高时分别达85.49%、92.07%和93.64%.基于CNN的实验中,不论是基于词单元还是基于词干单元,其分类准确率都随着迭代次数的增加而提高,并分别达到93.71%和95.39%后,大概收敛于93.4%和95.2%左右.本文提出的方法与传统模型相比,分类准确率分别高出9.9%、3.32%和1.75%.基于词干的分类准确率比基于词的分类准确率高出1.68%,证明对于粘着性语言的文本分类任务而言,基于词干的分类方法能够提高其分类的效果. 为了验证本文中利用的word2vec_TFIDF融合特征表示方法在文本分类任务中的性能,本文在没有对词与词干进行预训练和用word2vec算法分别对词与词干进行预训练情况下,将CNN作为分类器,分别在词单元和词干单元上进行了文本分类实验,并与本文中提出的方法分类结果进行了比较.在CNN+rand方法中,CNN模型结构保持不变,但没有对词与词干进行预训练来表示文本特征,而分别直接输入给CNN,输入的分布式特征将按高斯分布随机初始化,然后在训练过程中被修改的;在CNN+word2vec方法中,CNN模型结构还是保持不变,但将用word2vec算法分别对词与词干进行预训练来表示文本特征,并分别把训练所得到的词与词干向量输入给CNN.本次实验中,为了公平比较,本文用了150次迭代运算,比较实验结果如表6所示. 表6 基于不同文本表示方法的分类结果 从表6可以看出,基于word2vec_TFIDF融合特征的词与词干单元文本表示方法所得到的分类准确率分别比基于没有预训练的和基于word2vec预训练的词与词干单元分类准确率分别高出3.87%、4.16%和0.52%、0.44%.基于词干和word2vec_TFIDF融合特征的分类损失值明显地小于其它两种方法的分类损失值.由此可知,基于word2vec_TFIDF的融合文本表示方法能够在考虑词频重要度的基础上有效地获取文本上下文之间的语义信息,以提高文本的分类准确率. 文本分类已经成为处理海量信息的主要手段,特别是对具有噪声数据的低资源语言而言,可靠的文本分类方法至关重要.哈萨克语是一种粘着性派生类语言,词是由多个后缀所附的词干构成,后缀提供语义与句法功能,这一性质在理论上产生了无限的词汇量.所以,词素切分与词干提取是哈萨克语NLP的必要途径.Word2vec词嵌入技术可以将语言单元映射成基于上下文的顺序向量空间.从上下文信息中获取和预测OOV是一种有效的方法.本文讨论了一种基于词素与语音规则的哈萨克文本词干提取方法,以及一种基于word2vec_TFIDF融合特征和CNN的文本分类方法.本文中,哈萨克文本分类任务分别用不同的特征表示方法在不同的词汇单元上实现.实验结果显示,本文提出的基于词干单元和融合特征表示以及卷积神经网络的方法可以获得95.39%的分类准确率,与基于其它词汇单元和文本表示的文本分类方法相比,本文的方法中分类性能显著提高.可见,对于哈萨克语等派生类粘着性语言的自然语言处理任务而言,有效的词素切分和词干提取方法能够提高其效率.3 实验结果及分析
3.1 实验语料库

3.2 评价指标

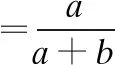

3.3 实验结果及分析



4 总 结
猜你喜欢
外语学刊(2021年1期)2021-11-04
师道·教研(2017年11期)2017-12-10
课程教育研究·新教师教学(2016年1期)2017-04-10
青春岁月(2017年1期)2017-03-14
艺术评鉴(2016年19期)2016-12-24
科技视界(2016年16期)2016-06-29
科教导刊·电子版(2016年13期)2016-06-28
山东青年(2015年4期)2015-12-09
改革与开放(2010年6期)2010-06-04
