
体育视频分析中姿态估计进展的综述
2020-09-07 01:50宗立波宋一凡王熠明王东洋李英杰
小型微型计算机系统 2020年8期
宗立波,宋一凡,王熠明,马 波,王东洋,李英杰,张 鹏
(宁夏大学 信息工程学院,银川 750021)E-mail:pengzhang123@nxu.edu.cn
1 引 言
体育视频分析技术在体育比赛中有着广泛的应用,是当前计算机视觉研究的一个热点.它是体育赛事中分析和建模的过程.通过分析可以给运动员、教练员或是体育爱好者提供一定的参考,对运动员个体和团队的表现进行系统评价.随着近年计算机视觉技术的发展,计算机视觉和图像分析在体育应用中扮演越来越重要的角色.
对体育比赛视频进行智能分析主要集中在技术分析和战术分析两方面.技术分析主要针对个人能力、动作规范性和体能等方面;战术分析是针对指导和进行比赛的方法.利用视频对体育运动的技战术进行分析,是一种有效的提高运动员的竞技水平的技术手段.基于体育视频的内容分析的主要问题可分为:面向场景的分析、针对视频结构的分析、对目标进行检测与跟踪、检测感兴趣的事件、分析和理解高级语义、战术策略[1]、动作分析等方面.近年来,随着深度神经网络在姿态估计和动作识别领域的应用,姿态估计在人体动作识别和推理方面取得了不错的效果,基于姿态估计的体育视频分析快速发展.对运动员的比赛视频进行高分辨率的录制,将录制的动作经过多维度的分解,得到运动员真实的动作数据,运用分析视频的算法,科学的分解微小的动作,对其进行对比和综合,进而对比赛的表现进行评估;可以将同一动作的不同运动员的图像进行对比,辅助运动员找到与标准动作的差距,从而加速相应动作的改进和提升,降低训练的重复率,提高教学的直观性和反馈的快速性;另外,还减少了不规范的动作造成的运动损害.这样可以促进训练和比赛的水平提高.
姿态估计的研究进展发展迅速,算法由原来的基于传统方法的研究,逐步转化为基于深度学习的方法.传统方法在分析时耗费的时间较少,但是提取的特征不充分,在人体姿态有较大变化时,估计的误差较大.而深度学习的方法可以利用神经网络提取出图像的深层次特征,在复杂的条件下,对姿态的预测更为准确,这也促进了基于深度学习方法的进一步研究.
2 体育视频分析系统与关键技术进展
国外专业运动组织和国家运动队使用视频对运动进行分析,并将其作为科学训练的必备手段.在个人项目中,视频分析可以在运动员的轨迹和运动力学方面提供直观的分析,在运动成绩的提升方面效果突出;在团队项目中,视频分析系统可以对本队和比赛对手的运用战术进行分析,辅助教练选择合适的战术,最大程度上提高本队的比赛成绩.体育视频分析系统应运而生,不同的分析系统使用的技术差异较大,因此首先介绍一下国内外的商用系统.
2.1 体育视频分析系统应用现状
基于体育视频分析的训练、比赛辅助系统应用于职业体育的各个方面.TechSmith Corporation公司开发的Coach′s Eye(1)https://www.coachseye.com/应用,使用移动设备或相机记录运动员的状态,以慢动作播放视频并逐帧分析,并排分析对比动作,使用秒表等高级分析工具标注时间,高亮显示动作细节,通过角度测量,为运动员提供个性化的反馈,系统由于采用慢动作分析动作,在分析效率上需要提高;美国STATS的SportVU(2)https://www.stats.com/sportvu-football/(球员追踪分析系统)是最早将视频分析技术应用于体育比赛的系统之一,现在发展到2.0版本.它利用4K摄像头采集比赛图像,基于先进的光学跟踪技术和主动学习框架,使用统计算法提取球员和球的坐标,利用AI分析跟踪数据和事件数据,以整体的视角制定比赛策略,将比赛的数据和场外训练数据结合,减少错误动作对运动员造成的伤害.系统适用于团队项目,在追踪多名球员的时候,需要较长的时间进行分析.相较于国外的体育视频分析系统,国内的系统大多关注于对球员的数据分析和比赛数据的统计.国内的体育视频分析系统中,创冰DATA(3)http://data.champdas.com/将每场比赛进行秒级数据切片,并采用分布式计算平台对云端的数据进行多维度统计,在比赛数据统计方面比较准确,但是缺乏球员的动作分析;灵信体育赛事数据采集与分析系统(4)http://www.listensport.com/采用高速摄像机提供的足球和球员轨迹数据,采集球员运动信息,运用基于灵信体育系统模板匹配方法,对球员进行跟踪,实现球员运动数据的统计,系统记录了球员运动相关数据,通过数据分析球员的表现,在足球比赛中,对单个球员动作分析准确性有待提高.目前主流商用系统中主要是对运动员的数据进行统计和运动员个人表现的分析上,自动化程度需进一步提高,操作效率和分析的准确度有待提高.
2.2 体育视频分析技术研究进展
随着体育视频应用需求日益旺盛,对分析技术的精度要求越来越高,促进了体育视频分析技术的发展,研究的对象也由低层次的特征转向高层次的特征.Hanna等[2]研究了视频内容的自动分类,使用视频中的颜色特征,通过隐马尔可夫模型(HMM)分类视频序列.Ouyang等[3]在跳水视频语义分析中采用本体推理的方法,利用高级语义挖掘体育视频信息.Hua等[4]对棒球进行了分析,验证了识别投球速度对事件检测和视频内容检索的作用,它可以提取感兴趣的视频,在检测事件方面具有良好的效果.Wang等[5]针对足球视频中的注释采用高级语义粗时间限制语义匹配,利用图像处理将视频和文本事件同步,结合高级特征分析视频.Stein等[6]提出可视化系统,使用轨迹和运动分析技术对足球视频中的区域、事件和球员进行相关分析,增加了分析的准确性.Yoon等[7]对篮球比赛的视频剪辑进行自动分类,同时跟踪篮球的运动,利用上下文信息跟踪球员,设计球队的战术策略,结合多模特征强化了视频中球员的跟踪分析和比赛分析.表1展示了当前研究的进展.

表1 体育视频关键技术对比
近年来,在团队运动中对战术水平的研究逐步发展.Suzuki等[8]利用深度极限学习机(DELM),在足球比赛视频中对球队战术进行分析,引入球队双方战术相关性,提高了战术估计的准确性;Decroos等[9]探讨了足球中战术分析的不足,使用专业足球比赛收集的事件流的数据,利用空间和时间信息,实现了自动战术识别;Andrienko等人[10]通过将多种信息综合分析足球比赛中的战术,利用动态聚合方法,结合灵活的查询技术,取得了不错的效果.
在单人运动中,对运动员的分析主要集中在动作分析上.Chen等[11]提出了一个瑜伽训练系统,通过集成计算机视觉技术,系统通过提取身体轮廓,骨架,主导轴和特征点,从前视图和侧视图分析训练者的姿势.然后,根据瑜伽训练的领域知识,提出了可视化的姿势矫正指令,在纠正训练者的姿势方面具有较高的准确性.Meng等[12]为了监督和分析职业运动中的运动员训练的运动姿势,使用一种深度关键帧提取方法,用于分析举重运动训练视频,并且所提出的DKFE在关键姿态概率估计和关键姿态提取方面优于对比方法.姿态估计已成为体育视频分析中的研究热点,下一节将介绍人体姿态的研究进展.
3 体育视频分析中的人体姿态估计
在体育视频分析中,通过慢动作播放视频并逐帧分析,在分析效率上需要提高.近几年,人体姿态估计的研究不断发展,在评估人体动作准确性方面有了优秀的表现.现在从基于整体部件、基于特征模型和基于单目/多目/多传感器等方面,回顾现在的人体姿态估计算法研究现状.
3.1 基于整体的方法
基于整体/部件的人体姿态估计方法可以分为基于整体的方法和基于部件的方法.其中主要使用深度学习方法对图像中的人体姿态进行映射关系的处理.
在基于整体的方法中,Alexander等[13]提出了一种基于深度神经网络(DNN)的人体姿态估计方法,作者将姿态估计表示为针对身体关节的基于DNN的回归问题,通过一系列的DNN回归量,得到了高精度的姿态估计值.与其他方法相比,该方法具有以整体方式推理姿态的优点,网络架构如图1所示;Fan等[14]使用双源深度卷积神经网络(DS-CNN)从单张图像中估计2D人体姿态,整合局部部分外观和每个局部部分的整体视图,通过联合检测确定图像块是否包含身体关节,借助联合定位,找到在图像块中关节的确切位置,该方法利用整体视角进行学习,如图2所示;Yang等[15]将领域先验知识纳入框架,并且结合DCNN和可变形混合部分实现了端到端的人体姿态估计,可以应用于循环模型或树形结构模型.基于整体的方法在关节点定位上,受归一化的距离影响较大,需要选择合适的归一化距离,强化定位关节点的准确性.
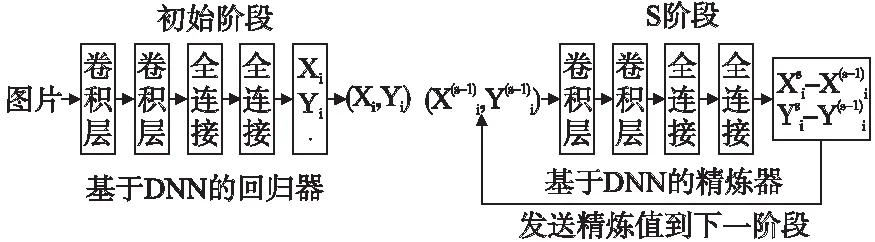
图1 基于DNN的姿态回归的示意图[13]
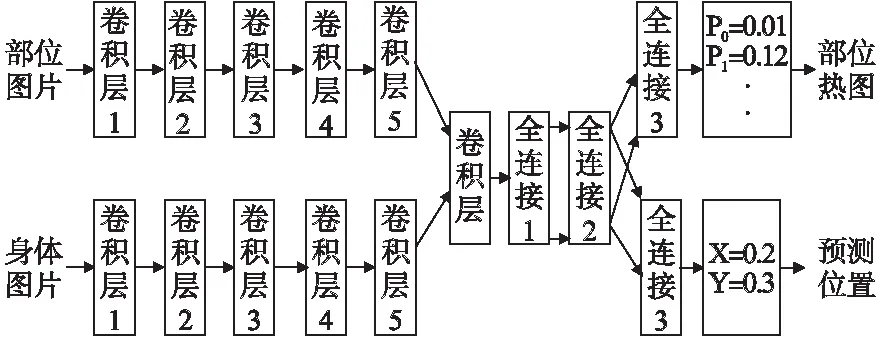
图2 DS-CNN架构[14]
3.2 基于部件的方法
由于基于整体的方法需要领域先验知识的支持,具有一定的局限性,而基于部件的方法可以不需要先验知识,通过将部件整合连接成人体姿态,增加姿态估计的准确度.最先进的基于部件的方法在它们的关联方法上是不同的.cao等人[16]将关节与部分亲和力场和贪婪算法联系起来,该方法使用非参数表示(部分亲和字段(PAF))来学习将身体部位与图像中的个体相关联.该体系结构对全局上下文进行编码,允许贪婪的自下而上解析步骤,无论图像中的人数如何,都能保持高精度,同时实现实时性能,见图3;Papandreou等人[17]检测个别关节并预测关联的相对位移,生成一种基于单镜头模型的无框自底向上的多人图像姿态估计和实例分割方,方法中的PersonLab模型使用基于部件的建模处理语义级推理和对象-部件关联,基于全卷积架构,并允许有效的推理,对出现在场景中多人姿态估计具有较好的效果;kocabas等人[18]将多任务和MultiPoseNet结合可以联合处理人员检测、关键点检测、人员分割和提出的估计问题,并且通过姿势残差网络为检测到的人分配关节,形成自底向上的多个体姿态估计体系结构,在多人场景中效果超过MPII MultiPerson基准的方法.基于部件的方法中,容易丢失跟踪的人体信息,并且自底向上方法会误检关节点,采用将视频帧间的时间顺序与部件模型结合方法,可以有效提高检测的准确率,进而提高人体姿态估计的精度.
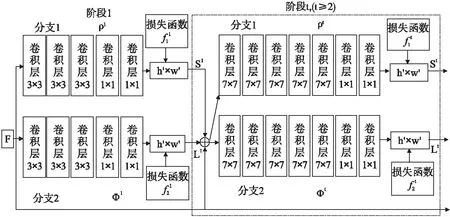
图3 双分支多级CNN的体系结构[16]
3.3 基于特征的方法
在基于特征/模型中,传统的方法分为基于人体特征和基于模型的方法.基于人体特征的方法不需要明确的身体模型,也不需要标记身体部位,可以通过图像轮廓恢复人体姿势.
在基于人体特征的方法中,Taylor等[19]采用一种基于邻域分量分析(NCA)框架学习非线性嵌入的方法,每张图片是由两个卷积、子采样层和一个全连接层处理,见图4,通过卷积扩展到真实大小的图像,解决了视觉上匹配相似姿势但具有不同衣服,背景和其他外观变化的人的复杂问题;Arjun等[20]提出了一个两阶段的过滤方法,改进低层次特征检测器,结合全局定位改善了不受约束的人体姿态估计效果;Rodrigo等[21]在RGB图像上使用2D多层次的外观特征表示,利用基于CNN的身体部位检测器可以检测不同层次的部位,提高了自下而上部位检测器的性能.基于人体特征的方法,需要选择合适的人体特征,同时需要大量的人体关节点的标注,在网络训练的时间上花费较大,采用弱监督的训练方式可以提升训练效率,减少训练时间.
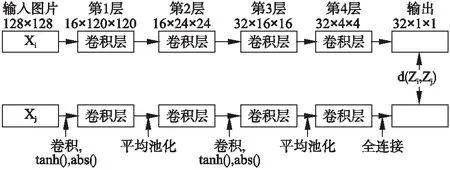
图4 卷积NCA回归(C-NCAR)[19]
3.4 基于模型的方法
由于人体是非刚性的,运动比较灵活、复杂,具有不规则性,基于模型的方法被提出,解决基于特征的不稳定性.Yang等[22]采用基于零件模型表示的静态图像中的人体姿态估计方法,使用每个部分的模板混合捕获零件之间的上下文共现关系,增强了编码空间关系的标准弹簧模型,提高了姿态估计的准确率和速度;Chen等[23]将深度卷积神经网络(DCNN)和图形模型结合,由于局部图像测量既可用于检测部分(或关节)以及预测它们之间的空间关系(图像依赖成对关系),采用DCNN来学习图像块内部件的存在及其空间关系的条件概率,提升了在LSP和FLIC数据集上的准确度;chu等[24]等使用双向树结构模型判断人体各关节在特征层面的关系.基于模型的方法可以对人体关节出现的位置进行限制,减少将背景检测出关节点的几率,提升关节位置检测的准确性.然而却解决不了关节间的遮挡问题,可以引入先验知识和关节点的统计信息,提高遮挡的关节点检测率.
3.5 基于单目/多目/多传感器融合的方法
根据采集视频的方式可以分为单目、多目、多传感器融合的方法,单目采集的视频是彩色图像;多目采集的视频是3D图像;多传感器融合采集的视频包含彩色图像和深度图像.不同的输入图像采用了不同的姿态估计算法.
3.5.1 基于单目的方法
在基于单目的方法中,将单目视频作为输入进行人体姿态估计.代钦等[25]使用单目静态图像作为输入,对相邻像素中类似的图像进行整合,在人体部位搜索时通过超像素完成,利用可变形部位模型实现部位识别,有效降低了在部位识别中背景的干扰,在姿态估计中获得了较好的结果;肖澳文等[26]采用的实验模型使用单目视频输入源,通过改进的顺序化卷积神经网络提取人体空间信息和纹理特征,确定头部和四肢关节点的位置,将节点投影到三维空间,降低了人体姿态估计的误差;Pavlakos等[27]使用人体关节提供的序数深度提供的监督训练卷积网络,利用单幅图像的输入,有效的提高了准确度.基于单目的视频输入的方法,虽然取得了较好的效果,但是在光照、颜色、纹理的变化中,单目视频缺少足够的信息解决问题,尤其是在体育运动中,运动员之间由于剧烈运动,造成的遮挡比较严重,对多人之间的姿态估计产生影响,而基于多目的方法可以较好的解决问题.
3.5.2 基于多目的方法
在基于多目的方法中,Steven等[28]提出了一个用于多个人的多视图3D姿态估计的管道,其结合了最先进的2D姿势检测器和利用信任传播优化的3D肢体约束的因子图.该系统明显优于先前的最新技术,具有更简单的肢体依赖模型,增加了人体姿态估计的鲁棒性;Fang等[29]使用多个摄像机的2D姿势利用姿势语法解决3D姿态估计的泛化问题.Dong等[30]使用多路匹配算法在所有视图中聚类检测到的2D姿势,将得到的聚类在不同视图上编码同一人的2D姿势及关键点的一致对应,进而推断出每个人的3D姿势,通过实验验证了所提出的方法的有效性;Wei等[31]给定一组不同视角的2D关节位置,利用视图一致性的约束提高3D人体姿态估计性能;Qiu等[32]结合多视图几何先验的跨视图融合方案,从多视图中高性能的恢复3D人体姿态.基于多目的视频输入方法,可以解决轻微遮挡、形变、人体尺度和采集角度等干扰问题,提供较为准确的3D信息.但是,在体育运动中,存在的严重遮挡和球员衣服的干扰,使基于多目的人体姿态估计效果变差.可以引入如红外传感器等的多种传感器,减少遮挡和干扰,提高体育运动中的人体姿态估计精度.
3.5.3 基于多传感器的方法
近年来,随着多传感器的技术发展,提供更加精确的人体姿态信息的多传感器技术应用于人体姿态估计领域.韩丽等[33]使用运动捕捉系统通过基于特征平面相似性匹配的方法计算模型各关节的运动数据参数,在人体姿态分析中具有较高的准确性和鲁棒性;Yang等[34]使用图像、集合描述符、彩色图和深度图等多个输入源通过对抗性学习框架预测的3D的人体姿态估计,提高仅具有2D姿势注释的野外图像的姿态估计;Tang等[35]使用基于稀疏特征点校准彩色图和深度图,得到三维关节点的信息恢复人体姿态.在基于多传感器方法中,受室外环境的影响较大,对环境的要求较高,可以应用于室内体育运动,减少光照条件的干扰.
4 姿态估计数据集及算法性能对比分析
在本节中,首先介绍用于姿态估计的数据集和评价指标.然后将近年比较主流的方法的性能结果进行了对比分析.
4.1 姿态估计相关的数据集
目前研究所用的主流人体姿态数据集包括2D和3D两类.其中2D人体姿态数据集如表2所示[36].常见数据集包括MSCOCO[37],MPII[38],LSP[39],FLIC[40],PoseTrack[41]和AI Challenger[42].

表2 2D人体姿态数据集[36]
现有的3D人体姿态数据集大多来自于室内采集,一般对拍摄环境有较高的要求,包括 Human3.6 M[43]和MPI-INF-3DHP[44]等,如表3所示.
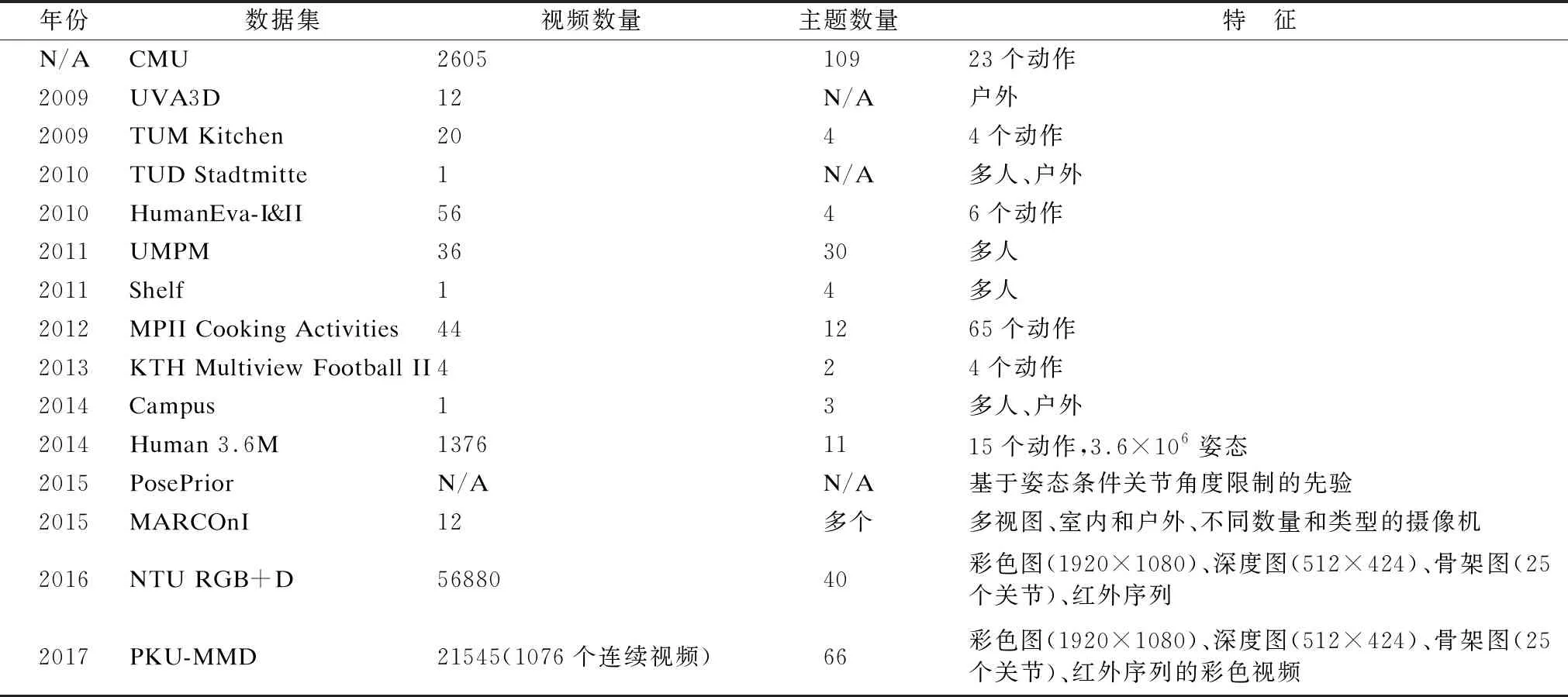
表3 3D人体姿态数据集
4.2 评价指标
在2D姿态估计中,使用的评价指标是正确估计的身体部位百分比(PCP)和mAP.
PCP选择肢体长度作为基准,评估头部,躯干,上臂,下臂,大腿和小腿的检测精度.PCK选择归一化距离作为基准,评估七个关节的检测精度,包括头部,肩部,肘部,腕部,髋部,膝部和踝部.PCKh@0.5意味着在头部尺寸的0.5的阈值内认为关节的检测是成功的.mAP反映了所有关节的平均PCKh检出率.
与2D姿态估计的评价指标不同,3D姿态估计的评价指标采用MPJPE(关节平均误差),它以毫米为单位测量预测和真实关节位置之间的平均距离.MPJPE的值越小,3D姿态估计越准确.
4.3 性能比较分析
从2D和3D方面分别比较了各个方法的性能.表4中列出的方法显示了在MPII和LSP数据集上通过PCP和mAP评估的所有关节的平均准确度.
基于表4,在PCP评价指标下,基于整体的方法,Fan等[14]提出的DS-CNN方法取得了最高的准确度;在基于模型的方法中,Chen等[23]提出的方法利用图像依赖成对关系,提升了在LSP上的准确率;在mAP的评价指标下,Cao等[16]采用多分支的CNN取得了优秀的准确度.在2D姿态估计中,使用多分支的CNN可以提升检测的准确度.
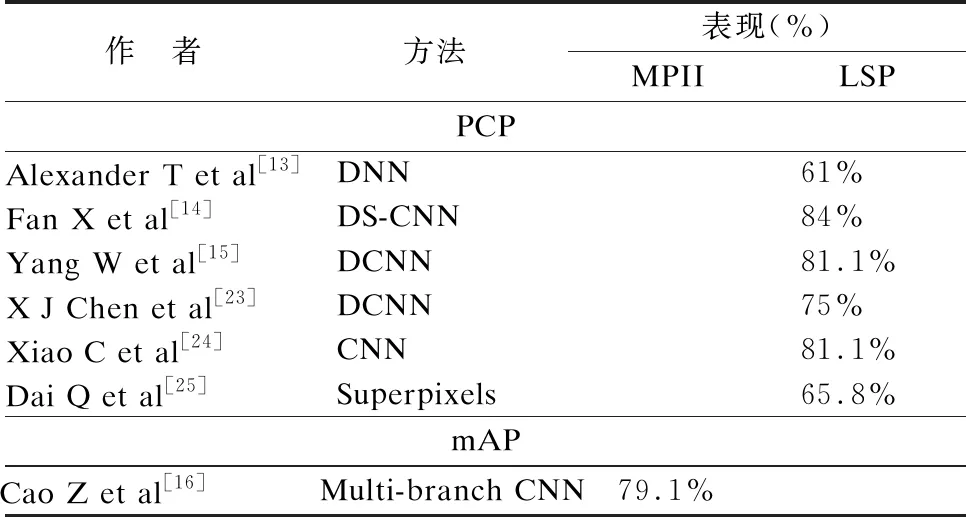
表4 2D人体姿态估计方法的比较
虽然基于2D的姿态估计算法取得了不错的效果,但是在体育运动中,由于人体的身高、衣服和背景遮挡的影响,降低了姿态估计的准确性.基于3D的姿态估计可以有效减少上述问题的影响.
3D姿态估计的算法性能对比如表5所示.在基于单目的方法中,Pavlakos等[27]提出的方法在数据集上实现56.2%的MPJPE,由于大多数的3D数据集是在室内环境下采集,不能实现2D人体数据集的可变性,而在体育运动中,人体的形变更加剧烈,作者使用2D人体姿势数据集上的序数深度的附加注释,减少了对精确3D真实值的需求;在基于多目的方法中,Wei等[31]使用视图不变的3D人体姿态估计的方案实现了56.6%的MPJPE,在体育运动中,捕捉视角的多样性和人体姿态的灵活性对于姿态估计来说是一些挑战,作者通过视图不变判别网络强化对身体关节的约束,显著提高3D人体姿态估计的性能;在基于多传感器的方法中,Yang等[34]实现了58.6%的MPJPE,虽然深度卷积神经网络(DCNN)在受约束的实验室环境中的数据集上取得了显著进步,但是在体育运动中很难获得3D姿势注释,作者使用对抗性学习框架,它将完全注释的室内数据集中学习的3D人体姿势结构提炼为2D姿势注释的室外图像,可以有效提高室外体育运动中的姿态估计性能.特别值得一提的是Qiu等[32]提出的跨视图融合方法大幅度改进了MPJPE,实现了26.21%的MPJPE,在室内数据集上利用可见视图的特征融合和RPSM,改进独立计算的2D姿态,虽然在室外的体育运动中环境影响较大,仍然可以将多视图融合改进2D姿态估计的思路运用在体育运动中的3D姿态估计.

表5 3D人体姿态估计方法的比较
5 结束语
本文对最近几年的体育视频分析系统和人体姿态估计算法进行了较全面的综述.最后给出了未来的研究方向.由于体育运动的连续性,姿态分析与时间的关系越来越密切,引入时序可以有效解决遮挡;体育姿态数据集需求明显增加,准确注释的数据集将会是提升人体姿态估计准确性的重要基础;基于多模态信息和将几何先验知识加入到网络特征融合中,促进网络结构的改进,提升3D姿态估计的准确率,这是未来体育运动中3D姿态估计的重要方向,为以后体育视频分析性能的提升提供了新的方法.
猜你喜欢
小哥白尼(趣味科学)(2022年1期)2022-04-26
大科技·百科新说(2021年10期)2021-12-31
学生天地(2020年3期)2020-08-25
小猕猴学习画刊·下半月(2019年6期)2019-08-13
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
试题与研究·中考数学(2016年4期)2017-03-28
电脑知识与技术(2016年13期)2016-06-29
诗选刊(2015年4期)2015-10-26
新高考·高一物理(2014年1期)2014-09-18
