
融合信任度值与半监督密度峰值聚类的改进协同过滤推荐算法
2020-09-07 01:48李昆仑王萌萌于志波翟利娜
小型微型计算机系统 2020年8期
李昆仑,王萌萌,于志波,翟利娜
(河北大学 电子信息工程学院,河北 保定 071000)E-mail:likunlun@hbu.edu.cn
1 引 言
随着互联网时代的到来,面对过载的信息与资源,用户难以快速找到有用的信息,个性化推荐系统应运而生,继而出现了多种推荐算法,常用的有基于内容、基于用户的协同过滤的推荐算法[1]等.协同过滤推荐算法是当前各类算法研究中应用最多且推荐效果最好的算法之一.因此,协同过滤推荐算法广泛应用于各大电子商务平台与网站中,例如淘宝、京东、亚马逊等.但是随着用户和项目数量的剧增,导致用户评分数据稀疏性问题严重影响到推荐系统的推荐质量[2].
用户之间的关注度作为社交信息中的一个重要特征信息,为系统推荐提供了新的依据[3].文献[4]提出采用概率矩阵分解来对评分进行预测,在构建用户特征模型时加入社交信任,并对用户特征向量本身进行扩展,该方法能够在数据稀疏情况下提高推荐精度;文献[5]提出一种带偏置的专家信任推荐算法,在形成评分时融合专家的评价可信度、活跃度、评价偏差度,因此在数据稀疏时可以提高推荐精度;文献[6]提出一种新的双层邻居选择,通过选择最具影响力和最值得信赖的邻居来提高邻居选择的质量,故在数据稀疏的情况下能够提高推荐精度;文献[7]提出利用社交网络特征,在传统矩阵分解模型的基础上加入信任特征矩阵,能够达到提高系统推荐精度的目的.然而多数社交信息并没有给出用户之间的信任度值,如何度量用户之间信任度值是当前有待解决的问题.
针对推荐系统中存在的数据稀疏性问题,本文提出了一种融合信任度值与半监督密度峰值聚类的改进协同过滤推荐算法,该算法将约束对的半监督信息[10-12]融入到密度峰值聚类算法[8,9]中,提高算法的在线推荐效率;同时将用户的信任信息融入到评分预测中为目标用户产生推荐,改善由数据稀疏性导致的推荐精度不准确等问题.本文算法进行了相关的理论分析,并在不同数据集上与其他算法进行了相关的实验对比,本文算法在平均绝对误差方面和均方根误差方面均表现优异.
2 传统的基于用户的协同过滤推荐算法
传统的基于用户的协同过滤推荐算法的关键是快速准确的定位目标用户的邻居集,这将直接影响到推荐算法的推荐效率和推荐精度.一般推荐过程分为三个步骤,具体如下:
Sept1.获取用户-项目评分信息,建立用户-项目评分矩阵n*m,如表1所示.
Sept2.根据表1,计算全体用户之间的相似度,得到用户相似度矩阵,依据相似度大小确定目标用户的最近邻居集.
Sept3.根据最近邻居集中的用户对目标项目i进行评分预测.
传统的协同过滤推荐算法在寻找最近邻居集时对所有用户进行相似度计算,相似度的计算量大,导致算法的推荐效率下降;在处理稀疏数据时,其推荐精度也急剧下降.因此本文引入相似度聚类以提高算法的在线推荐效率,并结合社交信息改善由数据稀疏性导致的推荐质量差等问题.下面本文将针对改进部分进行详细介绍.
3 改进的协同过滤推荐算法
3.1 半监督密度峰值聚类算法的改进
本文引入半监督密度峰值聚类算法,根据相似度进行聚类,将兴趣相同的用户分为一类,并建立用户兴趣度集合Iu.在线推荐时,仅需对Iu中的用户进行相似度计算,继而减少相似度的计算量,提高算法的推荐效率.
3.1.1 密度峰值聚类
用户对项目的具体评分Rnm,表示用户对该项目的兴趣程度,因此本文采用密度峰值聚类算法对用户的评分矩阵进行相似度聚类,构建用户的兴趣集合.将每个用户评分作为一个样本点,算法如下:
1)计算两两样本点之间的距离dij,修正余弦相似度在计算中减去用户所有评分项目的平均值消除评分的差异问题,因此本文采用修正余弦相似度的度量方式.如式(1)所示:

(1)
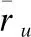
2)计算每个样本点的密度,ρi为该样本截断距离dc内的样本总数,为防止不同样本点的ρi相同,采用dc内样本点高斯核函数之和的倒数代替,式(2)所示:
(2)
3)计算每个样本点的距离δi,δi分两种:一种情况,该点到高密度点之间的距离;另一种情况,该点为局部密度最大点,则该点的距离表示与其它点之间的最大距离.如式(3)所示:
(3)
4)选取聚类中心,根据ρi和δi绘制决策图,在决策图中选取簇的聚类中心,通常选取ρi和δi均为较大的点作为簇的聚类中心,即在决策图中处于右上角与其它点分离明显的部分点,如图1所示.

图1 ρ-δ决策图
5)分配剩余各点,确定聚类中心后将剩余点分配到距离最近的密度比其大的点所属的类.
3.1.2 约束对信息嵌入
由于密度峰值聚类算法对dc过于依赖,且聚类后的数据无法服从真实数据的分布,因此本文在原算法的基础上提出约束对限制的半监督聚类算法.约束对限制包括正关联约束(must-link)和负关联约束(cannot-link),即对必须在同一簇中而没有被分到同一个簇中的数据实行must-link约束,对不该在同一个簇中却被错误的分到同一个簇中的数据实行cannot-link约束.这两种约束具有两种性质.
对称性:
(xi,xj)∈must-link⟺(xj,xi)∈must-link(xi,xj)∈cannot-link⟺(xj,xi)∈cannot-link
(4)
传递性:
(xi,xj)∈must-link&(xj,xm)∈must-link⟹(xi,xm)∈must-link(xi,xj)∈cannot-link&(xj,xm)∈cannot-link⟹(xi,xm)∈cannot-link
(5)
根据各点之间的相似度值,构造n个用户之间的相似度矩阵S,用n*n的矩阵表示:

相似值s(i,j)越大,则表示两个样本之间越相似,若s(i,j)=1,则表示i和j完全相同,在计算数据集相似度矩阵时,保存所有样本对之间的最大相似度Smax.
在获得数据集相似度矩阵的基础上,将已知的某些样本对之间的两种类型的must-link和cannot-link信息嵌入矩阵中.实验中采用Random函数随机产生成对约束对进行约束,若属于同一簇加入must-link约束集;反之,加入cannot-link约束集.基于must-link和cannot-link具有对称性和传递性,可以对矩阵中的其它样本间的相似度进行调整扩展,进而充分地挖掘样本对之间隐藏的约束对的约束关系.
将约束对监督信息嵌入数据集的相似度矩阵中,会生成已知的某些样本对之间的两种类型的成对点限制中满足must-link和cannot-link约束的样本对,以及由初始的must-link和cannot-link约束集的性质进行扩展得到新的must-link和cannot-link约束.由于采用修正余弦相似度计算样本间的相似度,如果两个样本属于同一簇则为must-link约束,将其相似度值设置为数据集所有样本对之间的最大相似度Smax;如果两个样本不属于同一类,则为cannot-link,则令其相似度值为0.步骤如下:
1)根据最初加入的成对约束建立数据集成对约束标记矩阵M,矩阵大小为样本的总数,定义如下:
(6)
2)在成对约束标记矩阵的基础上利用改造的Floyd算法求解成对约束扩展情况,算法如下:
输入:成对约束标记矩阵M,样本总数n
输出:经过扩展的成对约束标记矩阵Mextend
Sept1.对矩阵M进行三次嵌套遍历循环i,j,k
Sept2.任意点之间的相似度为s(i,j)=1,且s(j,k)=1,则点s(i,k)=1
Sept3.任意点之间的相似度为s(i,j)=-1,且s(j,k)=-1,则点s(i,k)=-1
3)根据扩展后的成对约束标记矩阵Mextend修正数据集相似度矩阵S中样本对之间的相似度值,计算如下:
(7)
3.2 信任度值计算的改进
为缓解推荐算法数据稀疏性问题,利用社交网络信任信息给目标用户匹配精准邻居用户以提高推荐精度.在社交网络中,用户之间的关注度反映了用户之间的信任程度,如图2所示,本文通过用户之间的关注度计算用户之间信任度值并构造信任度集合Tu.

图2 社交网络有向图
其中箭头指向表示该用户为目标信任用户,如0→1,表示用户0信任用户1.
定义1.令Ttrust表示信任度,例如用户u0对用户u1的信任程度,记为Ttrust(u0,u1).
定义2.令Lij表示传递路径,例如用户u0到用户u1的传递路径,记为L01(u0,u1).
3.2.1 直接信任度值计算的改进
传统观念认为,用户之间的信任是等价的,即用户u0信任用户u1,则用户u1也信任用户u0,两者信任程度等价.然而现实生活中,用户u0和用户u1之间的信任程度通常并不等价,如果用户u0信任用户u1,不能代表用户u1也一定信任用户u0.因此本文引入信任权值,如式(8)、式(9)所示:
(8)
(9)
其中I(u0),I(u1)分别表示用户u0,u1关注的用户的集合,|I(u0)∪I(u1)|表示用户I(u0)或者用户I(u1)关注的用户的集合的数量.式(8)、式(9)分别计算了用户u0对用户u1的信任权值和用户u1对用户u0的信任权值.
定义3.令Dtrust表示直接信任,根据用户关系矩阵T,对于任意u0,u1,如果用户u0关注了用户u1,则存在Dtrust(u0,u1),记作u0→u1.
直接信任计算公式如式(10)、式(11)所示:
(10)
(11)
其中|I(u0)∩I(u1)|表示用户I(u0)和用户I(u1)共同关注的用户的集合的数量.
3.2.2 间接信任度值计算的改进
为给目标用户匹配更多的邻居用户,需要利用社会网络信任传递性质,将更多没有直接关联的用户联系起来.
定义4.令Itrust(u,v)表示间接信任,若u信任w,w信任v,则存在Itrust(u,v),反之,不存在间接信任关系.
随着间接信任用户的增加信任度减小,所以本文采用两级路径传播,如图2所示,用户u0到用户u5的信任度传递为L025,L015,每条路径的间接信任度计算如式(12)、式(13):
L025=Dtrust(u0,u2)*Dtrust(u2,u5)
(12)
L015=Dtrust(u0,u1)*Dtrust(u1,u5)
(13)
u0到u5存在两条路径传递,每条路径信任值不同,对应的权重值也不同,因此引入等效电阻理论的距离度量方式[13],计算间接路径的信任度.如图3所示.

图3 两个用户间的电路图
令:
R1=L025
(14)
R2=L015
(15)
间接信任方式计算公式如式(16)所示:
(16)
综合用户直接信任Dtrust(u,v)和间接信任Itrust(u,v)得到用户总的信任Trust(u,v),将Trust(u,v)作为用户信任的相似度值,记作sim_t(u,v),如公式(17)所示:
sim_t(u,v)=

(17)
其中Dtrust(u,v)和Itrust(u,v)均不为零时,sim_t(u,v)表示综合用户的直接信任度值和间接信任度值;Itrust(u,v)=0时,sim_t(u,v)表示用户之间只存在直接信任度值;Dtrust(u,v)=0时,sim_t(u,v)表示用户之间只存在间接信任度值.
3.3 综合用户兴趣度与信任度关系的评分预测
根据用户兴趣度和信任度的关系,通过设置推荐权重δ,平衡用户兴趣度和信任度的权重,可以提高识别邻居的能力,不同应用情况,对两种信息依赖程度不同,通过调整δ的取值调节两种信息对预测评分的影响,避免出现兴趣度或信任度权重较大的问题.如公式(18)所示:
wu,v=
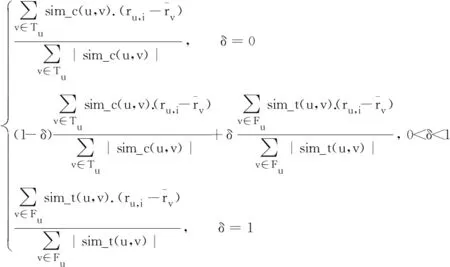
(18)
其中δ=0时,wu,v仅表示用户的兴趣相似度值;δ=1时,wu,v仅表示用户的信任相似度值;0<δ<1时,表示综合用户兴趣相似度值和信任相似度值.
计算目标用户u对未评分项目i的预测值,其评分Pu,i预测如公式(19)所示:
(19)
3.4 本文算法步骤
本文的主要思路是根据用户-项目评分矩阵M,使用基于约束对的密度峰值聚类将用户进行分类,并采用TOP-N方法构建兴趣度集合Iu,提高对目标用户的在线推荐效率;再依据用户关系矩阵T度量用户之间的信任度值,采用TOP-N方法构建信任度集合Tu;最后将两个集合的预测值进行线性加权.具体步骤如下:
输入:用户-项目评分矩阵M,用户关系矩阵T.
输出:前N个推荐项目.
Sept1.根据矩阵M,使用半监督密度峰值聚类将用户按兴趣度分类,计算ρi和δi,并根据公式(1)将用户进行相似度分类.
Sept2.根据公式(1)计算目标用户u和聚类中心的相似度,并将用户u0加入到相似度高度的簇.
Sept3.根据公式(1)计算目标用户u与簇内所有用户的相似度,得到用户兴趣相似度的sim_i(u,v)值,并采用TOP-N方法建立兴趣度集合Iu.
Sept4.根据用户关系矩阵T,利用公式(10)、(11)、(16)、(17)计算目标用户u与T中的信任度值sim_t(u,v),并采用TOP-N方法建立信任度集合Tu.
Sept5.删除Iu和Tu集合中目标用户已评分的项目,构建评分预测候选集Cu.
Sept6.对集合Cu中的项目,通过式(19)计算预测评分值,将预测评分值降序排序,给目标用户u提供前N个推荐项目.
4 实验分析
4.1 实验环境及数据集介绍
本文实验均在CPU为i7-7700HQ,2.80GHz,内存为8.00GB的计算机上运行,实验软件为python 3.7.本文实验采用三个经典的包含信任关系数据集:Epinions数据集、Filmtrust数据集和Ciao数据集,数据集的具体评分信息和信任信息如表2所示.
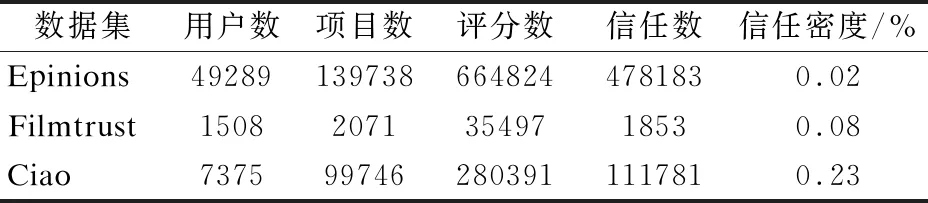
表2 三个不同数据集的统计信息
4.2 评价标准
本实验将数据集按照80%和20%的比例分为两部分,前者作为训练集使用,用来构造推荐模型,后者作为测试集使用,这样可以保证训练集和测试集数据都是随机的且都来自同一数据集.本实验采用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Squared Error,RMSE),这两种评价指标通过计算真实评分与预测评分之间的误差来衡量推荐结果的准确性,差值越小,表示偏差越小,推荐效果越好,如公式(20)、公式(21)所示:
(20)
(21)
4.3 δ参数的选择
本文相似度计算由用户兴趣度和信任度两部分组成,δ作为调节因子.δ的取值为[0,1],间隔0.1.δ取值分为三种情况,δ=0时,算法仅依据用户兴趣度产生推荐;δ=1时,算法仅依据用户信任度产生推荐;0<δ<1时,算法综合兴趣度和信任度产生推荐,且δ越大则信任度占比越大.
图4给出δ在不同数据集上的变化趋势,随着δ的增加,MAE和RMSE均呈现先减小后增大,表明兴趣度和信任度的占比不同会直接影响该算法的推荐结果,从图4(a)中可以得到,在Epinions数据集上,MAE值在δ=0.5时取得最小值,RMSE值在δ=0.6时取得最小值,综合用户兴趣度和信任度在MAE值和RMSE值的考虑,取δ=0.55时,该算法有最佳推荐结果.从图4(b)可以得到,在Filmtrust数据集上,MAE值和RMSE值均在δ=0.6取得最小值,综合兴趣度和信任度的MAE值和RMSE值的考虑,当δ=0.6时,该算法有最佳推荐结果.从图4(c)可以得到,在Ciao数据集上,MAE值和RMSE值均在δ=0.7时取得最小值,综合兴趣度和信任度的MAE值和RMSE值的考虑,当δ=0.7时,该算法有最佳推荐结果.Epinions数据集的信任密度为0.02%,δ取值0.55;Filmtrust数据集的信任密度为0.08%,δ取值0.6;Ciao数据集的信任密度为0.23%,δ取值0.7,说明信任密度越大,信任度占比越重.
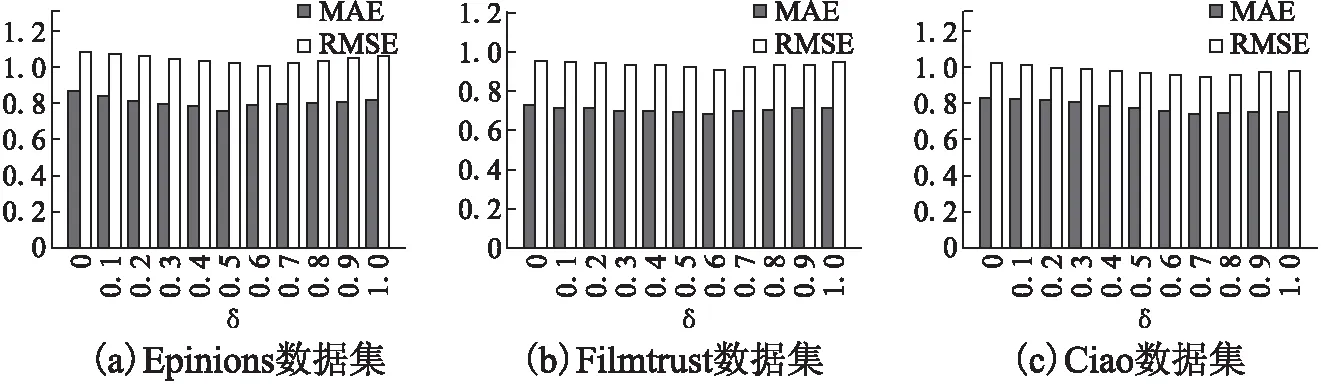
图4 不同数据集对δ值的影响
4.4 信任度值的推荐效果比较
为能更清晰地分析信任度在推荐系统中的作用,将本文算法进行信任效果对比,即不加信任、加直接信任以及加入间接信任时的三种方法进行对比分析.
如图5所示,图5(a)、(d)为本文算法在Epinions数据集上的运行结果,图5(b)、(e)为本文算法在Filmtrust数据集上的运行结果,图5(c)、(f)为本文算法在Ciao数据集上的运行结果.根据实验结果图纵向对比分析,当加入直接信任度值时的MAE值和RMSE值始终小于不加入信任度值计算的MAE值和RMSE值;加入间接信任度值计算的MAE值和RMSE值始终小于仅加入直接信任度值计算的MAE值和RMSE值.根据实验结果图的横向对比分析,通过图5(a)、(d)可以分析,在Epinions数据集上,当推荐数量N=35时,本文算法的MAE值和RMSE值均为最小,即当推荐数量为35时,该算法有最佳推荐结果,能够充分挖掘用户之间的信任信息;通过图5(b)、(e)可以分析,在Filmtrust数据集上,当推荐数量N=25时,本文算法的MAE和RMSE值均为最小值,即当推荐数量为25时,该算法的推荐结果最佳,能够充分挖掘用户之间的隐式信息;通过图5(c)、(f)可以分析,Ciao数据集上,当推荐数量N=30时,本文算法的MAE和RMSE值均为最小值,即当推荐数量为30时,该算法的推荐结果最好,可以充分挖掘用户之间的信任信息.因此当该算法同时考虑直接信任度值和间接信任度值时能够有效降低MAE值和RMSE值,提高对目标用户的推荐质量,同时也说明该算法在不同的数据集上有不同的最佳推荐数量.
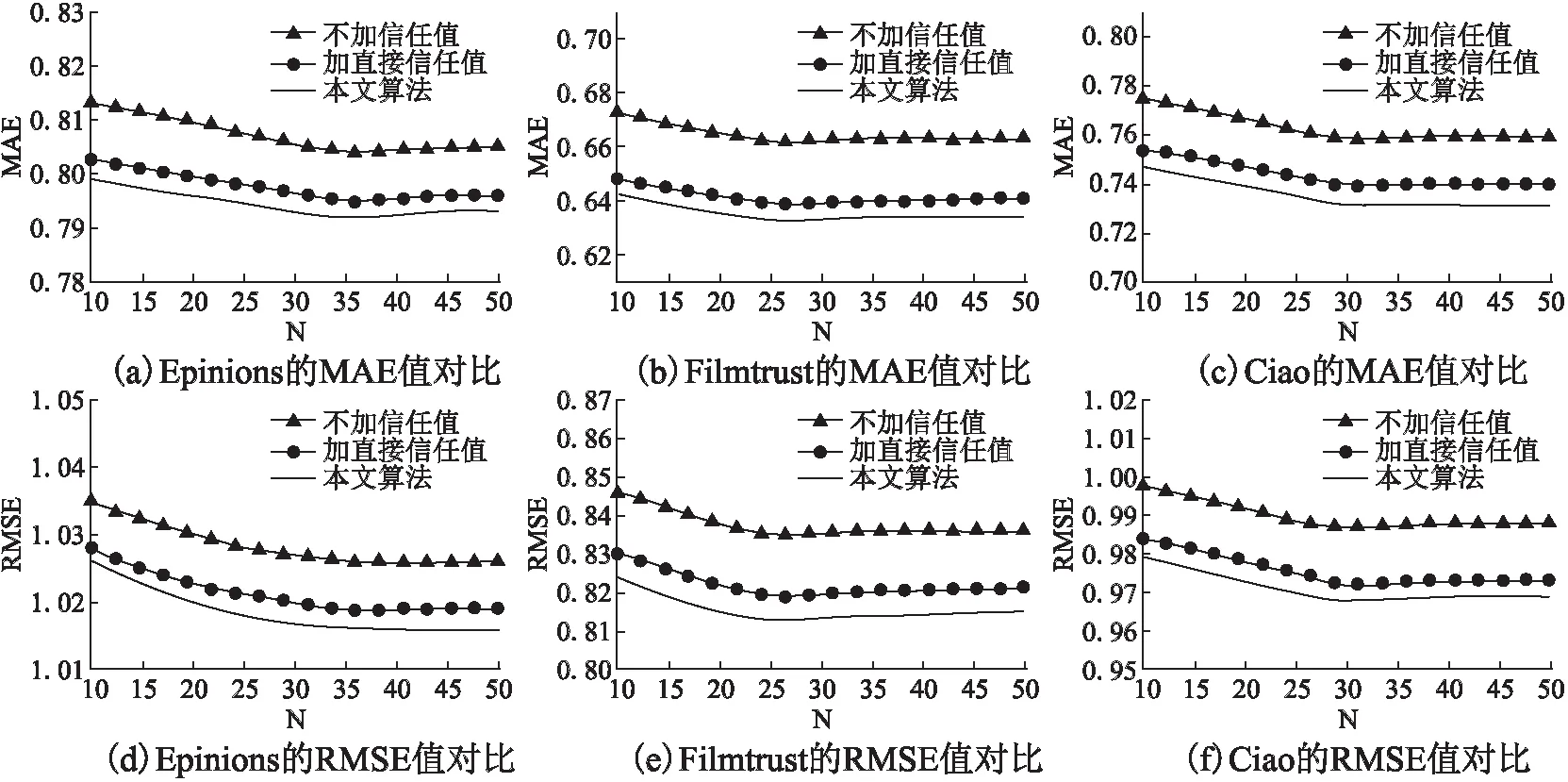
图5 三种信任度值在不同数据集上的对比结果
4.5 几种算法的推荐效果比较
为更直观地分析本文算法的推荐质量,本文选用一个传统的算法模型和三个改进的且带有信任度值计算的算法模型,分别是基于用户的协同过滤算法模型(UBCF)[14]、基于社交网络矩阵分解的推荐算法模型(SRM-MF)[15]、基于用户信任和商品评级的推荐算法模型(TrustSVD)[16]以及融合用户信任的协同过滤推荐算法模型(SUPTserCF)[17],与本文提出的算法模型进行对比分析.
如图6所示,图6(a)、(d)为各个算法在Epinions数据集上的对比结果,图6(b)、(e)为各个算法在Filmtrust数据集上的对比结果,图6(c)、(f)为本文算法在Ciao数据集上的运行结果.从实验结果图中可以分析,在Epinions数据集、Filmtrust数据集上和Ciao数据集上,UBCF算法的MAE值和RMSE值均远大于其他四种算法模型,说明其他算法模型在不同的数据集上均可以有效地提高推荐算法的推荐精度.如图6(a)、(d)所示,在Epinions数据集上,根据实验结果的横向对比分析,SRM-MF算法、TrustSVD算法、SUPTserCF算法以及本文算法均在推荐数量N=35时平均绝对误差最小,且随着推荐数量的增加MAE值趋于平稳不再有大的波动,说明随着推荐数量的增加各个算法的平均绝对误差不会再减小,该数据集的最佳推荐数量为35.如图6(b)、(e)所示,在Filmtrust数据集上,通过实验结果的横向对比分析,SRM-MF算法、TrustSVD算法、SUPTserCF以及本文算法均在推荐数量N=25时MAE值和RMSE值均为最小值,此后随着推荐数量的增加,MAE值和RMSE值不会再降低,且略有上升,说明随着推荐数量的增加各个算法的MAE值和RMSE值不会再下降,该数据集的最佳推荐数量为25.如图6(c)、(f)所示,在Ciao数据集上,通过实验结果的横向对比分析,SRM-MF算法、TrustSVD算法、SUPTserCF以及本文算法均在推荐数量N=30时MAE值和RMSE值均为最小值,此后随着推荐数量的增加,MAE值和RMSE值不会再降低,该数据集的最佳推荐数量为30.在不同的数据集上对实验结果进行纵向对比分析,当推荐数量N值相同时,在Epinions数据集、Filmtrust数据集和Ciao数据集上本文算法的MAE和RMSE值均小于其它对比算法,证明本文算法在提高推荐精度上有良好的效果.
5 总 结
本文针对传统协同过滤推荐算法在数据稀疏情况下的不足,提出了一种融合信任度值与半监督密度峰值聚类的改进协同过滤推荐算法.该方法通过半监督密度峰值聚类将用户按兴趣分类建立用户兴趣度集合;并结合社交网络的信任关系,通过计算直接信任度值和间接信任度值建立用户信任集合.在基于用户的兴趣度集合和信任度集合分别选择邻居用户,根据邻居集合为用户产生推荐.该算法降低了在寻找目标用户集合的时间损耗并为用户匹配精准邻居集合,提高了系统的推荐效率和推荐精度.
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
计算机研究与发展(2022年1期)2022-01-19
环球时报(2018-01-23)2018-01-23
小学阅读指南·低年级版(2017年1期)2017-03-13
文苑(2015年9期)2015-09-10
人生十六七(2015年6期)2015-02-28
IT经理世界(2014年5期)2014-03-19
新课程学习·中(2013年3期)2013-06-14
计算机辅助工程(2012年5期)2012-11-21
