
基于XGBoost特征选择的疾病诊断XLC-Stacking方法
2020-09-04 03:15侯凌燕杨大利
计算机工程与应用 2020年17期
岳 鹏,侯凌燕,杨大利,佟 强
北京信息科技大学 计算机开放系统实验室,北京 100101
1 引言
随着医疗事业的进步,越来越多的疾病数据能以电子病历的方式存储。近十年来,疾病预测的研究也成为当下的研究热点[1]。学者们研究发现,疾病的早期发现有助于该病被治愈,但影响患病的因素又有很多,因此对疾病的早期诊断带来一定困难。
目前,疾病的诊断主要通过两种方式,一种是传统的医疗检测手段[2],包括X 线摄影、临床、超声、磁共振(MBI)等方式检查,缺点是图像数据维度高,存在一定噪声,人工诊断有一定难度。另外一种是基于机器学习的方法。其中包括基于特征选择的方法以及基于预测模型的方法。
1.1 基于特征选择的方法
传统的机器学习方法[3]通常是将图像数据细胞核的半径、纹理、周长、平滑度、对称性等一系列特征建立数据集,通过统计学习方法建模,改进使其更加适用于所选的数据集。疾病数据特征的高维度会影响模型分类结果,为提高分类精度,研究者考虑从特征选择层面解决分类问题。文献[4]提出基于互信息的方法选择特征,但该方法只考虑了单一特征对标签的影响,而医学疾病的病因是由多变量共同决定,导致该方法无法提取出有效特征。文献[5]采用PCA的方法解决特征冗余的问题,但对于数据分布属于非正态分布的数据,提取的主元并不是最优的。文献[6]使用RFE-SVM 来选择更加适用于分类器的特征,这是一种Wrapper式的特征选择算法,但所选特征会出现过适应的问题。医学疾病数据特征的提取是目前亟待解决的重要问题。
1.2 基于预测模型的方法
疾病数据样本小,单模型在构建中会出现过拟合的问题。文献[7]提出将逻辑回归方法应用于疾病诊断问题上,但由于样本维度高,该方法容易产生过拟合,同时精确度也有待提高。文献[8]提出用GA-CG-SVM 的方法,解决乳腺癌预测模型过拟合的问题,通过自适应的方式来搜寻最佳参数,但该模型的预测精度相对较差。集成学习不仅能够解决模型构建中的过拟合问题,还能突破单一分类器自身局限性,进一步提升分类精度。文献[9]提出将Stacking集成方法用于电力系统平衡,实验表明Stacking 集成方法可以在分类器精度很高的时候进一步提升精度。Stacking方法在众多医学领域都有所应用,迁移性强,在疾病诊断领域适用性较好[10]。
在预测模型领域较为盛行的是梯度提升决策树(Gradient Boosting Decision Tree,GBDT)[11]。文献[12]将GBDT 的第一种改进算法XGBoost 用于处理疾病数据得到了较高的精度,但XGBoost在特征排序时选择贪心策略,时间复杂度较高。文献[13]将GBDT 的第二种改进算法LightGBM 用于处理高维度的网络贷款违约问题。为了更好地处理类别特征避免过拟合问题,文献[14]提出第三种改进算法CatBoost,不仅收敛速度更快,同时在准确率、召回率等多项指标上全面赶超另外两种改进的GBDT。LightGBM和CatBoost算法在多个数据集表现良好[15-16],但在疾病识别领域还没有取得较好的结果。
单一数据层面或模型层面的改进对疾病诊断帮助有限;本文针对医学疾病中的数据特征冗余问题,提出采用XGBoost特征选择算法来提取最佳特征,并提出一种使用Stacking的集成分类方法,将包括鲁棒性较好的CatBoost分类器在内的多个基分类器的模型进行集成,使用基层分类的概率值作为高层输入,以实现对医学疾病问题的诊断。通过在威斯康星州诊断性乳腺癌公开数据集(WDBC)进行10折交叉验证,实验结果表明,本文所提出的基于XGBoost特征选择的CatBoost-Stacking方法在分类精度以及F1-Score 等多项指标上均优于主流的机器学习方法。
2 相关算法介绍
2.1 XGBoost
传统的GBDT 目标函数是将迭代后不同轮次的残差树叠加继而预测目标类别。XGBoost 对传统GBDT目标函数加以改进,在原函数的基础上加上正则项,减少了过拟合的可能同时加快了收敛速度[17]。公式(1)中是真实值yi和预测值的平方差损失函数,Ω(φ)是正则化项,公式(2)中γ表式树分割的难度系数用于控制树的生成,T表示叶子节点的个数,λ表示L2正则系数。

XGBoost 不同于GBDT,它将损失函数按照泰勒公式二阶导数展开,这样新的目标函数就会比原GBDT具有更快的收敛速度和更高的准确性。目标函数最后就变为式(3),其中为损失函数L(φ)的二阶导数,gi为损失函数L(φ)一阶导数。

2.2 Stacking
Stacking 分类方法是一种集成分类方法,它集成多个基分类器分类结果,最终交予高层分类器训练。训练过程测试过程如图1所示,输入的数据首先要划分为训练集TrainSet 和测试集TestSet,然后将经过5 折交叉验证,输出用于高层分类器训练的tr1,用于高层分类器测试的te1。
高层分类器的输入是将所有基层分类器经过交叉验证的结果进行矩阵堆叠,如图2 所示,model1 会产生用于高层训练的tr1,用于测试的te1,以此类推model6会产生tr6,te6,将tr1,tr2,…,tr6合并为train训练高层分类器,te1,te2,…,te6 合并为test 用于检测 Stacking 集成效果。

图1 单模型交叉验证

图2 高层模型输入矩阵
2.3 CatBoost
CatBoost是一种监督机器学习算法,选取决策树作为基础预测器,使用GBDT进行分类。梯度增强本质上是通过在特征空间中执行梯度下降来构建分类器集合分类。它通过局部最优方式迭代地组合较弱的模型(基础预测器)来解释如何构建强分类器。
传统的梯度增强对样本梯度计算依赖于样本自身,噪声点会使特征空间中梯度与该域真实梯度分布产生偏移,最终导致过拟合。为解决这一问题,CatBoost 计算样本梯度将不再取决于所选的样本,而是剔除该样本后的整体梯度。首先对整个数据集进行若干次排序,接着剔除第i条数据,针对前i-1 条数据,分别计算损失函数以及梯度,并建立残差树,最后将残差树累加到原模型上。
3 本文工作
3.1 疾病数据的特征选择
疾病数据数据量小,特征维度高,大量冗余特征会影响模型构建效果,因此特征选择是必要的,常用的方法包括PCA、RFE-SVM、互信息的方法。疾病数据中存在大部分方差小的特征决定样本标签,同时特征之间的关联性也没有考虑到,因此上述常用方法并不能满足疾病数据特征的提取。XGBoost 采用梯度提升的方法进行数据分类,在小样本数据中,分类效果较好,鲁棒性强,所选特征更适用于分类器。为提取疾病数据最佳特征,本文使用基于XGBoost的特征选择的方法。
XGBoost 特征选择取决于各个特征对模型贡献的重要度,重要度则是特征用于树分割次数的总和。XGBoost中树的每次分割都采取贪婪地方式选择特征,即选择当前信息增益最大的特征用于树的分割。信息增益计算如公式(4):
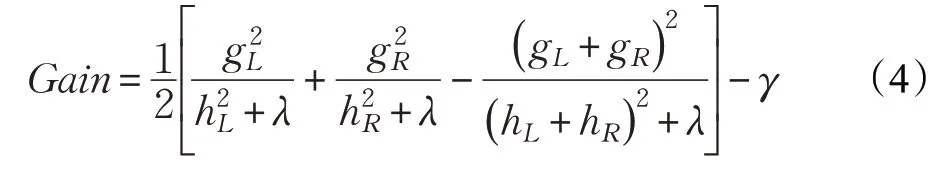
XGBoost 建模过后即可统计疾病数据特征的重要度,同时将各个特征的重要度按从高到低进行排序,建立循环,首先对第一维度特征建模,并计算准确率,随后逐渐增加用于建模的维度,同时记录准确率,准确率最高的维度即为XGBoost特征选择的维度。
原始数据的量纲问题会影响特征选择的结果,因此首先要对原始数据进行标准化,将数据映射到[0,1]的空间,再交给XGBoost 模型建模,进行特征选择。在XGBoost 模型参数设置时,考虑用网格搜索法调参,优点是方法简单,模型中涉及到模型参数设置,通过缩放法可确定最佳参数。
3.2 强GBDT权重的Stacking集成
为了增强Stacking提升效果,将CatBoost、LightGBM引入Stacking 集成中,GBDT 的三种改进算法在疾病数据上表现较好,为了增强分类效果而又不降低分类准确率,将CatBoost、LightGBM、XGBoost 一并加入基分类器,相当于间接地加大了GBDT 分类器所占的权重,而又不损失GBDT分类结果的多样性,为了增强基分类器分类结果的多样性,将基于超平面分类的SVM模型、基于距离预测的KNN 模型以及基于决策树集成模型的RandomForest加入Stacking的基分类器中,这样Stacking分类器既能保持GBDT分类的精度又能提高。
为了防止过拟合问题的发生,本文选择底层基分类器输出分类概率,本文问题是个二分类任务,因此单个底层分类器输出的结果会是一个n×2 的单模型分类概率矩阵,2列分别表示样本被预测为良性和恶性的概率,n列表示n个数据样本。底层全部分类器叠加则会产生一个n×12 的分类概率矩阵如表1所示,矩阵的12列则表示6个分类器分类的分类概率。

表1 分类概率矩阵
在高层分类器的选择上,由于底层分类器的输出结果与最终的分类标签呈线性相关,因此选择更加适用于线性关系并且易于解释的逻辑回归模型。如图3 所示为基于XGBoost的CatBoost-Stacking流程图。

图3 基于XGBoost的XLC-Stacking流程图
4 实验与结果分析
4.1 数据集
实验数据集选自UCI公开数据集威斯康星州诊断性乳腺癌(Wisconsin Diagnostic Breast Cancer,WDBC),它具有医学疾病数据小样本高维度的共性,数据主要描述了用于乳腺肿瘤诊断的核特征,数据总共32维,其中一维描述病人的id,另一维度为标签,描述了病人所患肿瘤为良性还是恶性,剩余30 维度分别描述了患者的细胞核10 个特征的(最大值,均值,最小值);其中包括细胞核的半径、纹理、周长、区域面积、平滑度、紧凑型、凹度、凹点、对称性、分形维数,本数据集中一共有实例569 例,其中包含 212 例恶性,357 例良性,不平衡比例为1∶1.6。
4.2 评价标准
单一的准确率指标,召回率指标并不能准确反映出病患的重要性,因此要综合正负类识别的准确率以及召回率判定,本文乳腺癌识别是一个二分类任务,因此选择F1-Score作为评价标准综合预测的准确率以及召回率。
本文研究的是乳腺癌肿瘤患者良性恶性的识别,因此TP真阳性即为乳腺癌良性样本被预测为良性的实例数量;FP假阳性即为乳腺癌良性样本被预测为恶性的实例数量;TN真阴性即为乳腺癌恶性患者被预测为恶性的实例数量;FN假阴性即为乳腺癌恶性样本被预测为良性的实例数量。

Accuracy即为所有预测中预测正确的样本所占比例。
Precision即所有被预测为乳腺癌恶性的实例中真实为恶性的实例比例。
Recall即所有乳腺癌恶性患者的实例中预测为恶性的实例比例。
F1-Score即考虑准确率以及召回率乳腺癌识别的综合影响,常用作不平衡二分类数据分类评价指标。
4.3 实验结果分析
实验中各模型参数选自网格法调参,同时为更好地反映模型性能,本文通过交叉验证的方式选择模型。本文数据量小,共计569 例样本数据,为使模型得到更充分的训练,本文选择10 折交叉验证的方式选择更可靠的模型。首先将数据划分成10份,9份用作训练,1份用作测试,循环10 次,每次选择不同的测试,最后将实验的结果10次取均值。
在选择XGBoost特征选择时,本文通过网格搜索法确定模型参数,决定模型性能的参数主要包括learning_rate学习率以及n_estimators基分类器个数和max_depth树最大深度三个参数,根据经验设置三个学习参数的最大范围,并在每个范围中筛选出不同的中间值。学习率选择learning_rate=[0.01,0.05,0.1,0.3,0.5,0.8],基分类器个数n_estimators=[50,100,150,200],树的最大深度max_depth=[3,5,8,10],每当选择出一组参数时,确立参数为中间值,减小原始最大范畴,并细分中间值,不停循环直至确立的参数不再变化时输出所选参数。通过实验比对最终选择learning_rate=0.1,n_estimators=50,max_depth=4。
在XGBoost特征选择时,将原始数据经过标准化处理之后用XGBoost 方法建模,然后得到原始数据30 维特征的重要度,重要度评价如图4所示。将模型的重要度依次排序后,选择递归式的方法增加特征维度比对模型预测的准确率,实验表明选择提取12 维特征时准确率达到最高。

图4 特征排序
为了对比XGBoost 特征选择方法在乳腺癌识别的优越性,分别使用了原始特征以及基于PCA、RFE-SVM的方法与XGBoost 作对比,原始乳腺癌30 维特征,在PCA 的实验中选择99.99%的特征重要度提取效果最佳,提取出12维特征,RFE-SVM是包裹式的方法,提取出了25维度特征。
实验表明PCA 的方法并不适用于本文数据,其没有考虑特征之间的关联性,因此会删除部分有效特征,因此会出现准确率下降的情况。而RFE-SVM的方法虽然没有删除有效特征,但特征维度依旧高达25维,剔除冗余特征效果不佳,同时识别精度提升较小,本文的XGBoost特征选择算法不仅降维效果明显,同时提取的特征更利于分类任务,模型的各项指标均有较大提升,详见表2。
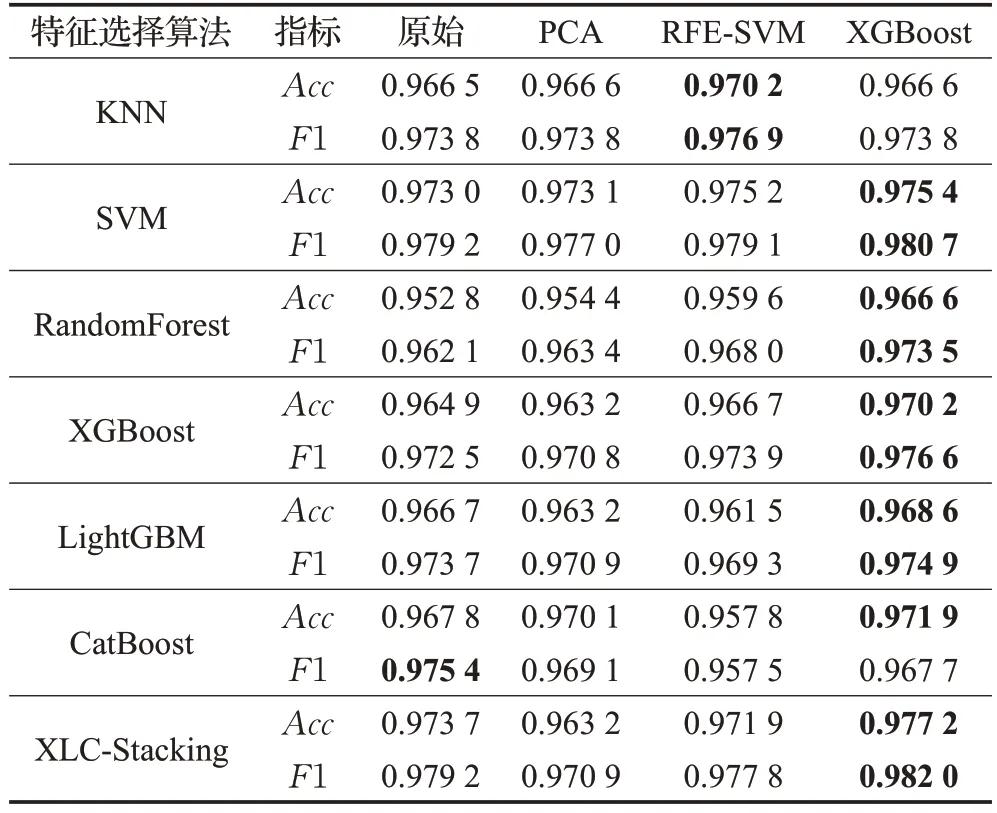
表2 特征选择方法性能对比
在Stacking的基分类器选择时,如表3所示,本文首先选择KNN、SVM、RandomForest、XGBoost 四个分类器,由于SVM鲁棒性强,分类性能远好于其余三种分类器,因此集成效果不如单一的SVM 分类器。但经过XGBoost 特征选择后建模,各基分类器性能均有所提高,Stacking方法效果明显,因此在Stacking基分类器选择的实验上,本文用XGBoost选择后的数据实验。
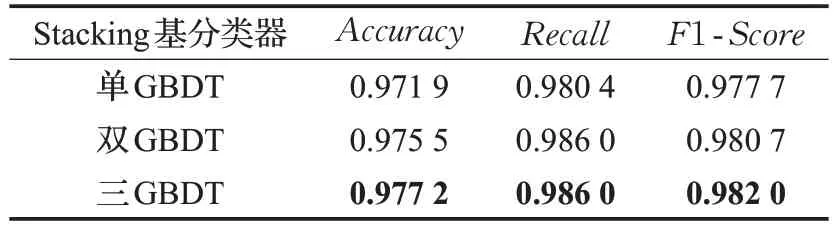
表3 不同基分类器模型性能对比
基分类器中,GBDT的改进算法XGBoost在乳腺数据上表现较好,因此考虑在基分类器中增加GBDT的改进算法,间接增大GBDT 的权重,实验中当基分类器加入第二种GBDT 的改进算法LightGBM 后,集成效果不再降低,相对错误率下降了12.82%,当加入第三种GBDT 的改进算法CatBoost 后,集成效果有明显提升,与单GBDT 的Stacking 集成模型相比相对错误率下降了19.06%,F1-Score也在原97.77%的基础上提高了0.43个百分点。因此在Stacking基分类器的选择上最终选取 KNN、SVM、RandomForest、XGBoost、LightGBM、CatBoost。
为了对比本文基于XGBoost 的XLC-Stacking 方法在乳腺癌识别上的有效性,如表4 所示,本文分别对比 KNN、SVM、LightGBM、RandomForest、CatBoost、XGBoost,以及本文未使用XGBoost 选择特征的XLCStacking 的方法。本文方法集成了异质基分类器的优点,与传统的RandomForest 方法做对比,相对错误率下降51.69%,F1-Score提高了1.85个百分点。与流行的GBDT改进算法XGBoost方法做对比,相对错误率下降35.04%,F1-Score提高了0.54 个百分点。与基分类器表现最好的SVM 做对比,相对错误率降低了15.56%,F1-Score提高了0.28 个百分点。模型ROC 曲线对比如图5,本文方法AUC 面积最高。实验对比表明,本文提出的基于XGBoost 的XLC-Stacking 方法更适合疾病预测。

表4 不同预测模型分类精度对比
5 结束语
本文提出一种基于XGBoost 特征选择的XLCStacking 的疾病预测方法,针对疾病数据高维度特征冗余现象,通过XGBoost 的特征选择方法选择最优特征。针对识别精度不高的问题,在Stacking 集成过程中,分别引入了XGBoost、LightGBM、CatBoost 间接增加了基分类器中GBDT 的权重,保持基分类器的多样性并提升预测模型精度。本文方法相比当前主流算法更加适用于疾病的识别,不仅对患病者的识别率高,同时能综合患病者准确率和召回率,降低非患者被误诊的可能性,减轻了医疗资源的浪费。略有不足的是本文方法尚未对病患风险进行分级,未来将在风险划分方向继续研究。

图5 模型ROC曲线对比
猜你喜欢
当代陕西(2022年4期)2022-04-19
当代陕西(2020年22期)2021-01-18
中华诗词(2019年7期)2019-11-25
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
电子制作(2017年23期)2017-02-02
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
航天返回与遥感(2014年5期)2014-07-31
中原工学院学报(2014年4期)2014-04-01
