
基于机器学习的北京市三甲医院疾病诊断名称规范化研究
2020-08-31 10:47李谊澄侯锐志邹宗毓周子君
医学与社会 2020年8期
李谊澄 侯锐志 邹宗毓 周子君
1 北京大学公共卫生学院卫生政策与管理学系,北京,100191;2 华东师范大学数学科学学院基础数学系,上海,200062
近年来,门诊疾病诊断名称的规范化是门诊处方审核亟需解决的问题。统一规范的疾病术语既是诊断的基础工作,也是做好疾病索引和疾病分类统计以及门诊付费的关键[1]。疾病诊断名称的标准化和规范化是卫生信息化的重要组成部分,对卫生信息标准化的实现起着至关重要的作用[2]。目前,门诊疾病诊断名称的不规范化情况严重阻碍了计算机的识别和分类效率,阻碍了医保审核和用药审核的发展。医疗机构和卫生系统以往主要依靠人力对这些不规范的疾病诊断名称进行规范化整理,但随着不规范的医疗文本的积累速度不断加快[3],人工难以完成对庞大数据流的处理。本研究以国际疾病分类(International Classification of Disease, ICD)为基础标准疾病术语模板,通过扩展ICD-10分类内容和机器学习的方法对多样化和不规范的疾病诊断名称进行识别,并转化为统一的标准疾病诊断术语。
1 资料来源与方法
1.1 资料来源
本研究资料来源于北京市城镇职工基本医疗保险系统数据库,以2018年上半年北京市22家三甲医院上报的门诊疾病诊断数据作为研究对象,以国家医保局发布的ICD-10为标准,从原始诊断数据中清洗整理出783364条临床使用不规范的疾病诊断数据。
1.2 研究方法
应用Python 3.81对数据进行处理,处理过程为:数据清洗→训练集和测试集选取→规则设置→基于模型规范化→产生映射。ICD-10作为我国疾病分类与编码的国家标准,在住院病案的疾病诊断中应用广泛[4-5]。本模型选取ICD-10中的三位码、四位码和六位码及其诊断名称作为疾病诊断名称的标准化框架,同时扩充ICD-10中缺失的诊断分类(如:疾病的检验、疾病的检查以及疾病的治疗和手术操作等未具体分类的条目),应用基于“规则-贝叶斯机器学习-惩罚得分机制”的模型,将多样化和不规范的疾病诊断名称转化为统一标准的疾病诊断术语。研究流程见图1。
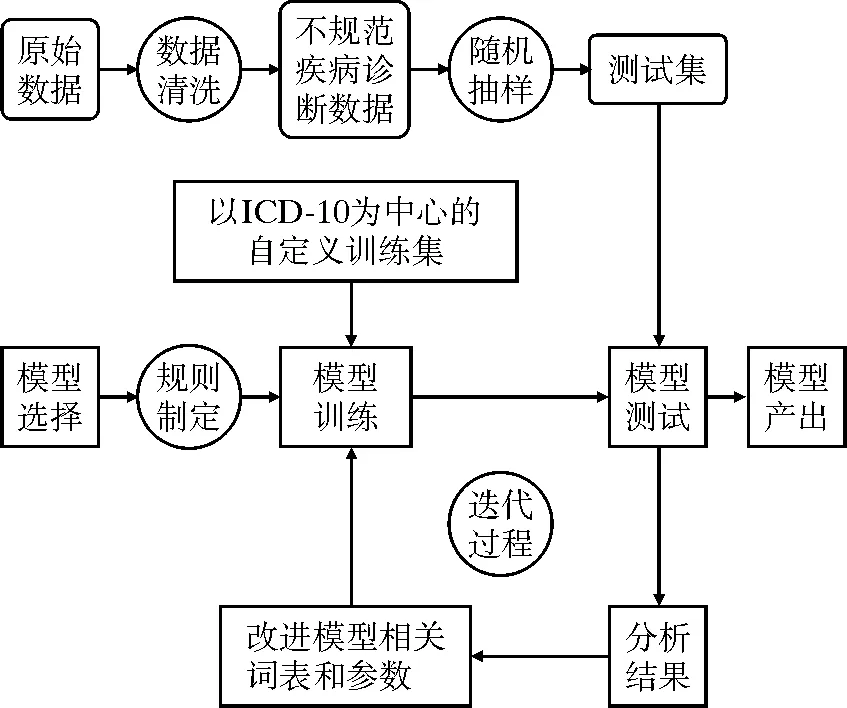
图1 研究流程
1.2.1 规则设置。为减小在数据清洗过程中噪声的影响和数据的丢失,本模型设置了相应的处理规则,用于提高模型的稳定性和效率值。
①停用词设置。停用词是指文本中的副词、连词、介词和语气助词以及一些没有实际意义或与训练数据无关的词汇。停用词设置用于将与疾病诊断术语无关的词汇过滤掉,减少噪声的产生。本模型以《哈工大停用词表》为基础,根据疾病诊断名称的特点进行了相应调整,剔除了部分疾病相关词汇,同时添加了部分与疾病无关的干扰词汇。
②同义词映射词典设置。同义词映射主要是将含义相同但表现形式不同的术语映射到统一规定的术语上面。同义词映射词典的设置是一个不断迭代的过程,词典的初步设置为:术语映射(如俗名映射到通用名)、数字映射(如汉字形式的数字、罗马数字、全角数字以及半角数字等映射到阿拉伯数字上面)、解剖部位映射等。
③特殊符号过滤。特殊符号主要指文本中的各类分隔符和连接符,如标点符号(“,”、“。”“-”等)和一些无实际意义的分隔符(“空格”、“|”等)以及一些其他符号(“*”、“★”等)。在过滤符号的同时,“?”、“+”、“-”分别表示对疾病的怀疑、阳性和阴性,是需要保留的符号。
④权重词表设置。本模型将部分疾病诊断名称中相关字或词进行了加权表示,提高了该字或词的匹配权重,用以提高模型标准化的准确率。
⑤分词词典设置。本模型选用的分词模块为结巴(jieba)分词模块,并在分词模块中引入清华大学整理的《医学专业术语词典》作为分词词典,从而提高模型分词过程的效率。
1.2.2 机器学习模型设置。本研究选用的机器学习模型为贝叶斯模型,并在其基础上添加了惩罚得分机制。本模型首先通过预先定义的词表将输入中出现的特殊字符与符号转化为汉字,删除和替换无有效信息的文字;然后通过贝叶斯机器学习模型寻找出与输入文本相似的100个疾病名称作为候选答案;最后,通过正向和反向双向匹配机制和前后一致性判别等评价规则筛选评分最高的疾病名称作为输出结果。该模型的特点为:训练速度快,准确率高,可迁移性强。
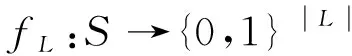
(1)
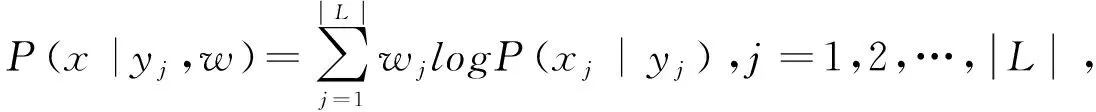
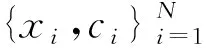
(2)
因此,权重便可通过随机搜索算法如蒙特卡罗、遗传算法等得到。
1.2.3 训练集和测试集。①训练集。该模型选用的训练集为疾病诊断名称的标准化模板,即ICD-10中的标准疾病描述和扩充的部分疾病检查、检验和手术治疗措施等的描述。训练集处理:将训练集进行向量化,采用one-hot-representation向量表示法,将训练集进行1-gram切分,去重后得到一个含有所有疾病相关表述的单个字的集合,同时对训练集进行再分词(运用的词典为jieba分词词典),得到一个分词后的集合,将这两个集合合并成一个集合。然后,将其向量化成一个词向量矩阵。这样做既保留了文本的部分语义特征,又能做单个字符之间的相似度计算。②测试集。对783364条不规范的疾病诊断名称进行清洗,主要包含运用医学专用的切词词典进行切词,将多疾病诊断的名称进行切分,同时对非疾病术语进行过滤,最后经过去重一共得到220258条非标准化疾病诊断名称。从中随机抽取5个样本,每个样本含有1000条疾病诊断术语,分别用该模型进行规范化和统一化处理,最后请专业的医务人员对处理结果进行逐一检查,并做相应的统计。
1.2.4 评价指标。由于随机抽取的疾病样本仍然带有部分与疾病诊断名称无关的词汇,如一些用药、医院信息等,影响了标准化的结果,故将标准化的结果用表1表示。

表1 训练集结果分类
模型选取的评价指标有3个,准确率P、召回率R和综合评价指标F,如下表示。
(3)
(4)
(5)
其中,ca表示模型在测试集中能够识别和转化为规范化疾病的个数,cb表示在训练集中转化为错误疾病名称的个数,cn表示在训练集中能够分离出去的非疾病名称个数,nn表示在训练集中不能分离和归类的非疾病名称个数。准确率P表示模型能正确处理非标准化疾病诊断名称的能力,P值越大,模型标准化的准确率越高;召回率R表示模型能处理疾病名称诊断的维度,R值越大,模型可处理的疾病诊断名称维度越大,非疾病术语产生的噪声越小;F值则是模型综合表现能力的体现。
2 结果
2.1 准确率P、召回率R和综合评价指标F
邀请专业人员对结果进行逐一审核,然后进行统计分析,对结果进行比较,见图2。
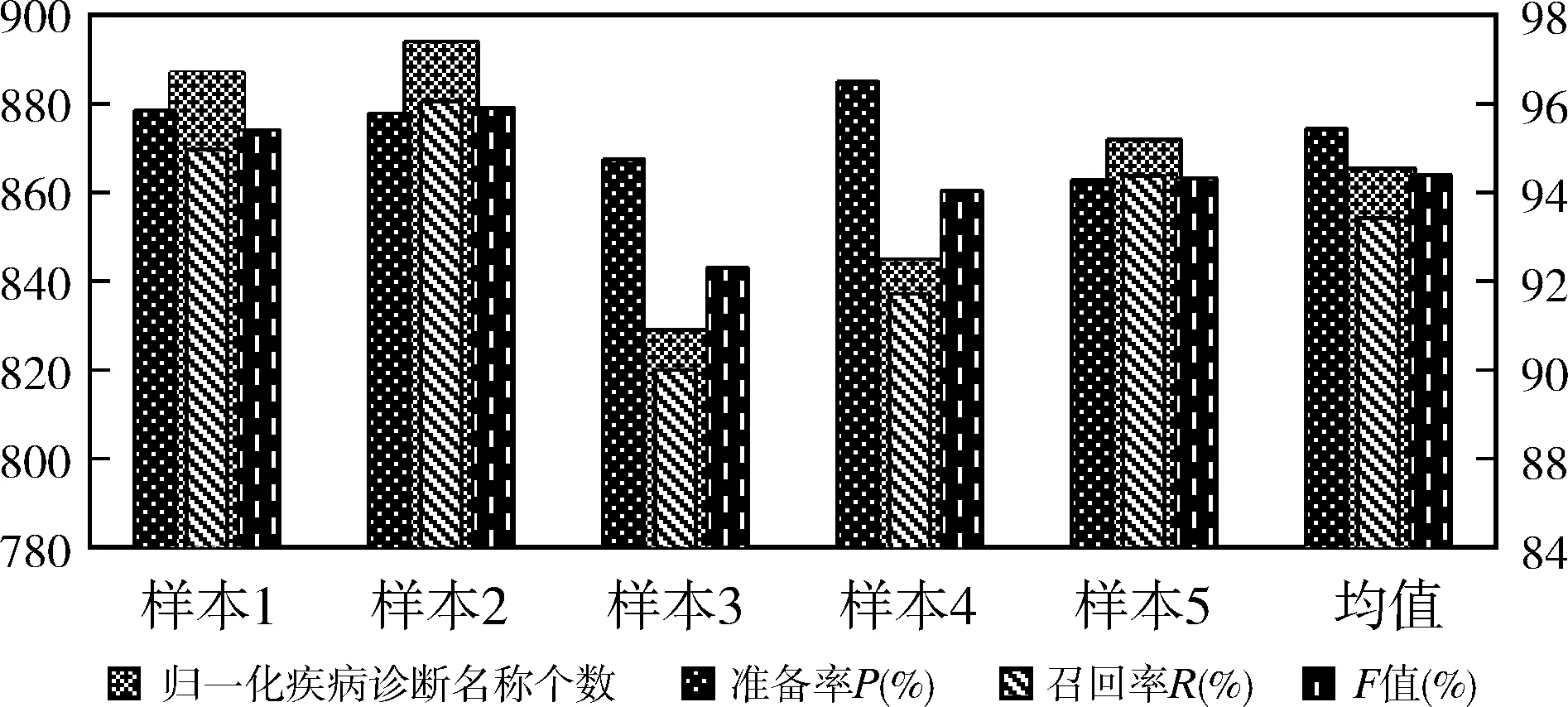
图2 规范化结果比较
5个样本的规范化疾病诊断名称数量最多的为894个,最低的为829个,平均为865.4个;准确率最高为96.24%,最低为93.66%,平均为95.00%,说明在不规范的疾病诊断名称中,95.00%的疾病名称可以通过模型转化为统一规范的标准疾病术语,并能与ICD-10产生映射关系;召回率R最高为95.72%,最低为88.66%,平均为92.65%,说明在样本的标准化结果中,疾病术语占92.65%,仍有7.35%的无关词汇没有被过滤掉,非疾病术语的影响不可忽视;F值最高为95.56%,最低为91.35%,均值为93.79%,说明模型的综合效能为93.79%。
2.2 字形相近的疾病诊断名称规范化
在疾病诊断名称规范化的结果中,本研究提出的模型能够有效解决疾病诊断描述由于个别字符不一致的多对一问题,将多样化的疾病描述归一化为统一标准的疾病描述,并和ICD-10形成相应的映射关系,见表2。
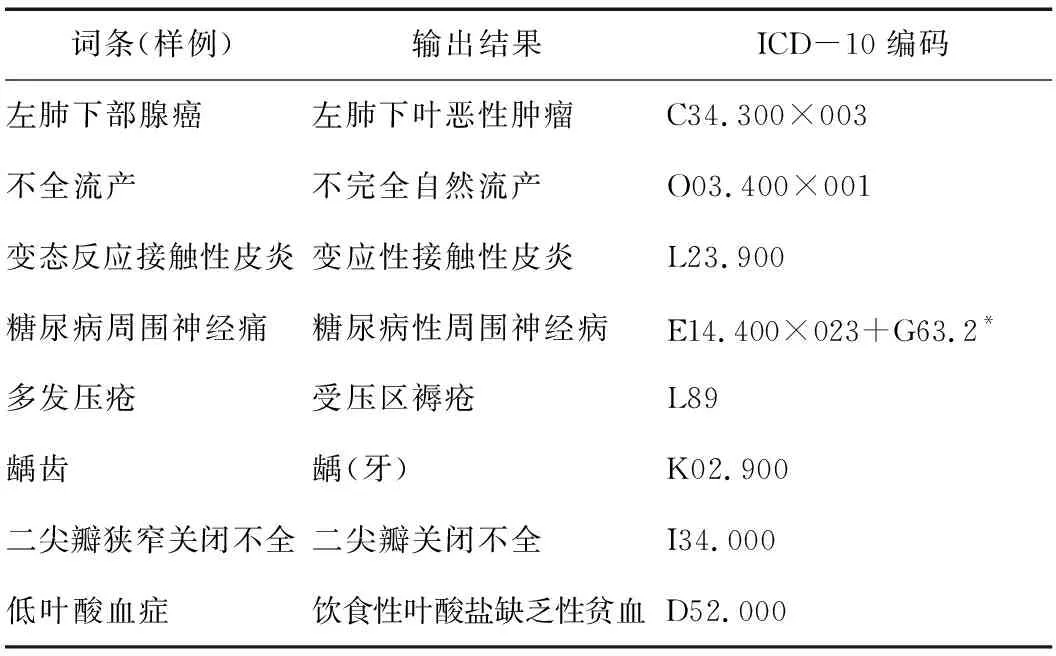
表2 因字词不一致的规范化(样例)
其中,“左肺下部腺癌”为明显的不规范疾病诊断描述,通过模型规范化为“左肺下叶恶性肿瘤”,并与ICD-10中的相关疾病描述形成映射;其次,“不全流产”“变态反应接触性皮炎”“糖尿病周围神经痛”“多发压疮”“龋齿”“二尖瓣狭窄关闭不全”等均属于相对规范的诊断描述,但是为了使计算机有效进行批量识别和编译,本模型通过词向量的学习匹配原理将其进行了归一化处理,并与其ICD-10编码一一对应。
2.3 多样性的疾病诊断名称规范化
名称的多样性问题主要为学名和俗名、英文命和中文命、简写和全写的转化问题,本研究以ICD-10中的疾病名称为模板,将简写、俗名、英文名以及英文简写均转为ICD-10中的标准疾病描述。见表3。

表3 多样性的疾病诊断名称规范化(样例)
其中,“冠心病”和“上感”在医院的疾病诊断名称中非常常见,经过模型归一化之后分别与ICD-10中的“冠状动脉粥样硬化性心脏病”、“急性上呼吸道感染”相互对应;“AECOPD”和“PSVT”分别为“慢性阻塞性肺病伴有急性加重”和“阵发性室上性心动过速”的英文缩写;“大脖子病”和“大骨节病”则是相对常见的俗称表示。针对这些由简写、俗称以及英文表述等引起的多样化疾病表述,采用规则表结构进行术语转换,将这些多样性的疾病表述转化为统一标准的疾病术语。
2.4 不易分类的疾病诊断名称规范化
在疾病诊断描述中,有一部分疾病描述在ICD-10中不易分类,或者很难归一到ICD-10里面的某一个疾病,这些诊断描述可能是一项检查、某种疾病的预防或者一些常规护理操作等。根据这些诊断的描述特点添加了部分自定义分类,专门解决不易分类的诊断描述问题。见表4。

表4 不易分类的疾病规范化(样例)
其中,主要涉及一些非确切疾病的描述,针对这些描述的特点和可能引发的相关疾病对ICD-10进行了相关内容的扩充,用以解决多样化的疾病检查、疾病预防以及一些身体部位的相关护理等诊断描述的规范化问题。
3 讨论
3.1 本研究的创新性
目前,基于计算机来进行疾病诊断名称规范化的研究相对较少,疾病诊断名称规范化主要依靠人力完成,而提高规范化效率的方法主要是对临床医师和病案整理人员进行相关的专业技能培训,以减少病案书写和整理过程中不规范现象的发生[6],从而提高临床诊断的科学性和实用性[7]。但是,由于门诊压力和工作量的影响,临床诊断名称的书写质量难以保持在相同的质量水平。本研究尝试运用计算机的方法来解决疾病诊断名称不规范的问题,为疾病诊断名称的批量规范化和实时规范化提供了可以借鉴的思路。
3.2 本研究的科学性
在已有研究中,基于语义相似度进行疾病诊断名称规范化的研究准确率最高为90%左右[8],结果的准确率很难满足大批量文本处理的需求,而且并不能解决不宜分类的问题,仍需要进行长时间的人工审核来纠正错误。本研究通过贝叶斯模型自学习加权,并且添加同义词映射词表和ICD-10扩充词表,有效解决了疾病诊断名称不规范化常见的三类问题:字形相近问题、名称多样问题以及不宜分类问题,并且模型的准确率达到95.00%,综合效能达到了93.79%,满足了大批量疾病诊断名称标准化的需求。此外,本模型所用的词典设置均为开放型,每进行一次迭代,模型的效率都会相应提高。
3.3 本研究的实用性
本研究通过机器学习的方法有效解决了疾病诊断名称不规范的常见问题,可以将门诊中出现的绝大多数不规范疾病名称转化为疾病术语,并与标准的术语表形成映射。由于互联网医疗和DRG的不断发展,疾病编码的重要性越来越高[7],建立临床常用疾病诊断编码库也是大势所趋[9]。临床常用疾病诊断编码库,即临床常见疾病诊断名称与ICD形成的映射关系库,能够有效提高病案首页的编码效率和质量,推动病种统计和医教研管理工作的发展[10-11]。本研究提出的方法不仅可以高效建立疾病诊断编码库,节省了医技人员的大量时间,同时为门诊处方的批量审核提供了技术支持。
3.4 本研究的局限性
3.4.1 数字的规范化问题。当涉及一些具体数字的疾病诊断描述时,如“体表烧伤25%”“孕25+周”等疾病诊断描述,这些数字在规范化的过程中需要转化为一个数字范围,但是由于数字的多样性和不敏感性,可能导致结果出现相应的误差。
3.4.2 方位词和解剖部位词的规范化问题。比如:“右手第五掌骨闭合性骨折腱Ⅲ区断裂,指神经断裂”在规范化的过程中将其他信息遗漏,最后规范化为“手骨折”。所以,当涉及一些复杂的解剖部位的疾病诊断描述时,在疾病诊断名称统一规范化的过程中可能会把解剖部位遗漏或者只保留了粗分类,造成疾病信息的丢失。
4 建议
4.1 强化培训,完善考核
应加强医师培训,提高医师在门诊疾病诊断名称使用的规范性。同时,需要完善相关绩效考核机制,尤其是与门诊处方质量和病案首页质量相关的绩效考核。只有基于内在知识的提升和外在机制的约束,才能有效提高疾病诊断名称的规范化程度。
4.2 建立标准术语库,完善编码体系
完善疾病诊断名称的标准化词库,细化ICD编码体系,提高ICD编码的实用性。标准化的疾病诊断名称术语库是互联网医疗的基础,同样也是医疗信息化的过程。可以将临床医师常用的疾病相关术语进行整理,建立一套标准术语库,并进行编码,或者以ICD为基础进行扩编,尽可能囊括各类常见术语和医师常用术语[12-13]。术语库的迭代过程,也是规范化、信息化的推进过程。
猜你喜欢
中国典型病例大全(2022年7期)2022-04-22
校园英语·月末(2021年13期)2021-03-15
中华养生保健(2020年5期)2020-12-02
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
社会保障评论(2019年3期)2019-04-13
中国继续医学教育(2015年6期)2016-01-07
中国科技术语(2012年3期)2012-03-20
中国科技术语(2012年3期)2012-03-20
中学生英语·外语教学与研究(2008年4期)2008-03-18
