
东干族留学生汉语单字调感知及产出声学实验研究
2020-07-16 13:08:58康小明武和平
海外华文教育 2020年1期
康小明 武和平
(西北师范大学文学院, 中国 兰州 730070;西北师范大学国际文化交流学院,中国 兰州 730070)
一、引 言
东干族是生活在中亚地区的我国晚清时期陕甘回族的后裔,现主要分布于哈萨克斯坦、吉尔吉斯斯坦和乌兹别克斯坦三国,他们的母语东干语是近代汉语方言的域外变体(胡振华,2009)。因此,我们认为东干族留学生汉语声调的习得不同于其他国家的留学生,有其特殊性。
国内现阶段关于东干语语音系统的研究可概括为以下三个方面:第一,东干语语音系统的共时描写和汉语(北京方言、西北方言)的共时比较(海峰,2003;林涛,2012;王森,2015);第二,语言接触所导致的东干语语音方面的变化(林涛,2003;刘俐李,2015;Xaвaзa фaтимa,2017);第三,东干语语音共时系统的声学实验研究(刘俐李,2013、2015)。
而关于东干族留学生二语习得的研究较少,且主要是针对学习者声调偏误进行的研究,研究角度为静态的观察与分析(谢梦雅、杨吉春,2018;康小明,2018)。研究的内容主要涉及学习者声调产出方面,目前从动态角度结合声调感知所进行的研究较少。理论上,以Fledge(1999)为代表的研究者认为二语学习者的产出与感知密切相关,基于Fledge的理论,我们认为学习者的语音习得过程应该包括感知和产出两个方面。为了从动态的角度较为全面的研究东干族留学生习得汉语声调的规律与存在的问题,本文运用声调感知及产出的实验方法,对不同汉语水平组的东干族留学生进行声调感知和产出相对动态的研究,获得学习者动态习得过程中有关问题的研究结论。探讨其习得汉语声调的特点,为国际汉语声调教学提出建议。
二、感知实验
(一)区分实验
1.被试
被试为三个不同汉语水平组的东干族留学生,各20人,均来自西北师范大学东干班,年龄范围在18~25岁,均报告听力正常,划分不同水平组的主要依据是汉语听说水平,同时将学习时间作为参考因素。本次试验的初级水平组被试学习汉语平均时间四个月,能用汉语进行简单的交流,但发音生硬;中级水平组被试学习汉语平均时间一年半,通过了HSK四级考试,基本能用汉语进行日常的交际,但发音有较重的口音;高级水平组被试学习汉语平均时间三年,通过了HSK五级考试,能较流利地用汉语进行日常的交际,发音口音较轻。
2.实验材料与目的
每个测试项为两个意义上毫无联系的单音节词,它们的声母、韵母均相同,其声调相同或不同,共组成16个测试项(如:白—百,见附录一),此为本实验的全部语音刺激项目,其中有四个测试项为干扰项,不计入统计结果,实验的目的是考察被试对不同声调的感知区分能力。
3.试验方法
所有测试项目随机排列,由一位普通话一级甲等的发音人读出。每个测试项读一遍,用语音软件录入电脑,项目内两个字间隔1秒,项目间间隔3秒。被试每听一个测试项,都必须对选项S(声调相同)和选项D(声调不同)进行强制选择。被试使用质量较好的耳机,在安静的教室分组进行双耳语音感知测试。
4.实验结果
本试验共发放问卷60份,回收有效问卷51份,其中初级水平组17份、中级水平组16份、高级水平组18份。我们通过计算声调感知错误率(易斌,2011)来考察实验结果。用于每个测试项目的刺激样品都是两个声调不同的单音节词,这两个单音节词有AB、BA两种排列,本实验不考虑干扰项,因此,12个测试项目可归并为6类测试项目(见表1)。我们分别计算出三组被试每类测试项目的平均错误率[1]以及6类测试项目的总错误率[2],结果见表1。
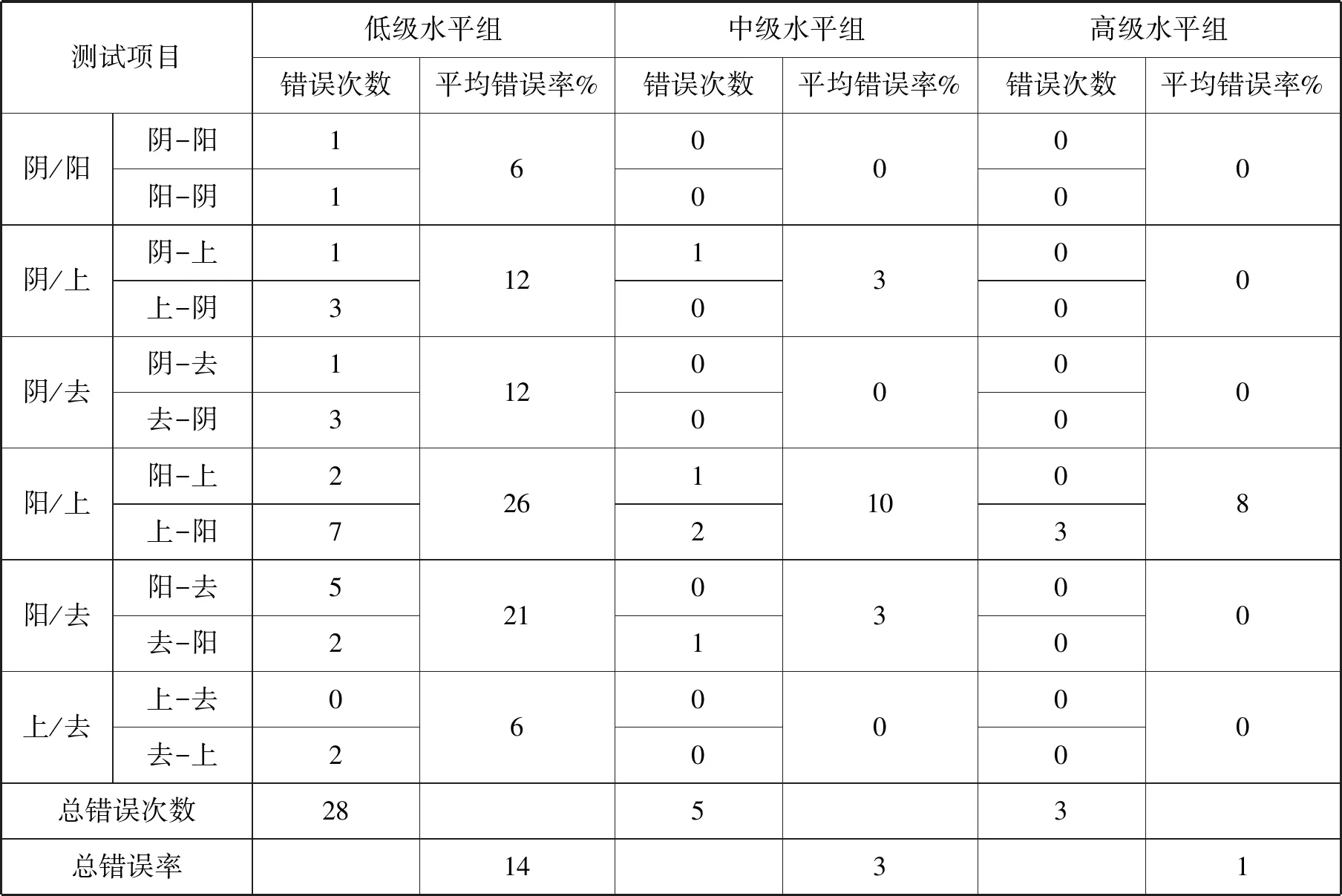
表1 汉语单字调区分测试平均错误率表
(二)辨认实验
1.被试
与区分实验相同。
2.实验材料与目的
测试项为12个汉语单音节词(见附录二),分为3组,每组词声母、韵母相同或相近,声调分别为阴平、阳平、上声、去声。实验的目的是考察被试对汉语单字调的感知辨认能力。
3.实验方法
所有测试项随机排列,由区分实验的发音人读出,每个测试项读一遍,用语音软件录入电脑,项目间间隔3秒。被试每听到一个测试项目,要求在四个备选项中选择一个答案,备选项只有四个随机排列的声调符号,没有标写汉字和拼音字母。被试使用质量较好的耳机,在安静的教室分组进行双耳语音感知测试。
4.实验结果
本试验共发放问卷60份,回收有效问卷51份,其中初级水平组17份、中级水平组16份、高级水平组18份。我通过计算声调感知错误率和感知率的方法来考察实验结果,下面分别列出各水平组感知各声调的平均错误率[3]、总错误率[4]、感知率[5]以及感知错误类型率[6],结果见表2、表3、表4(表中“→”表示“感知为”,下同)。
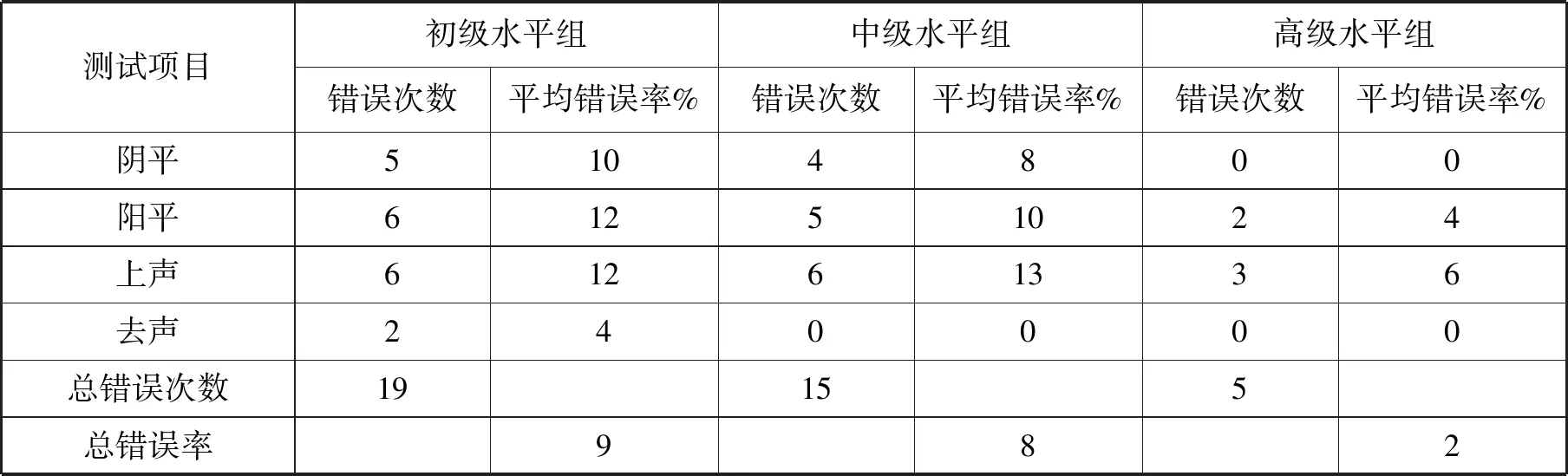
表2 单字调感知平均错误率
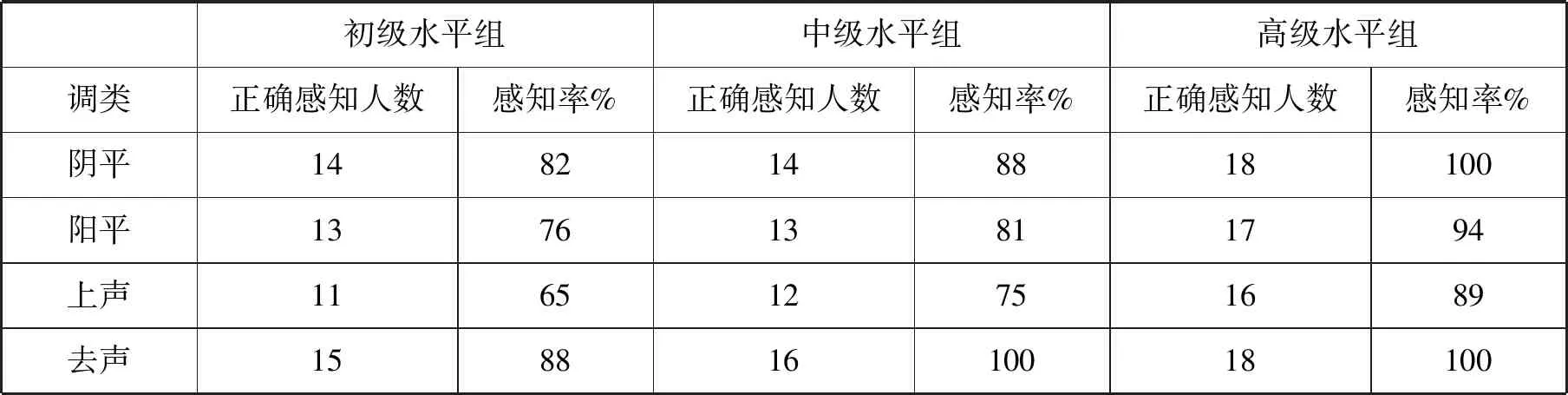
表3 单字调感知率表
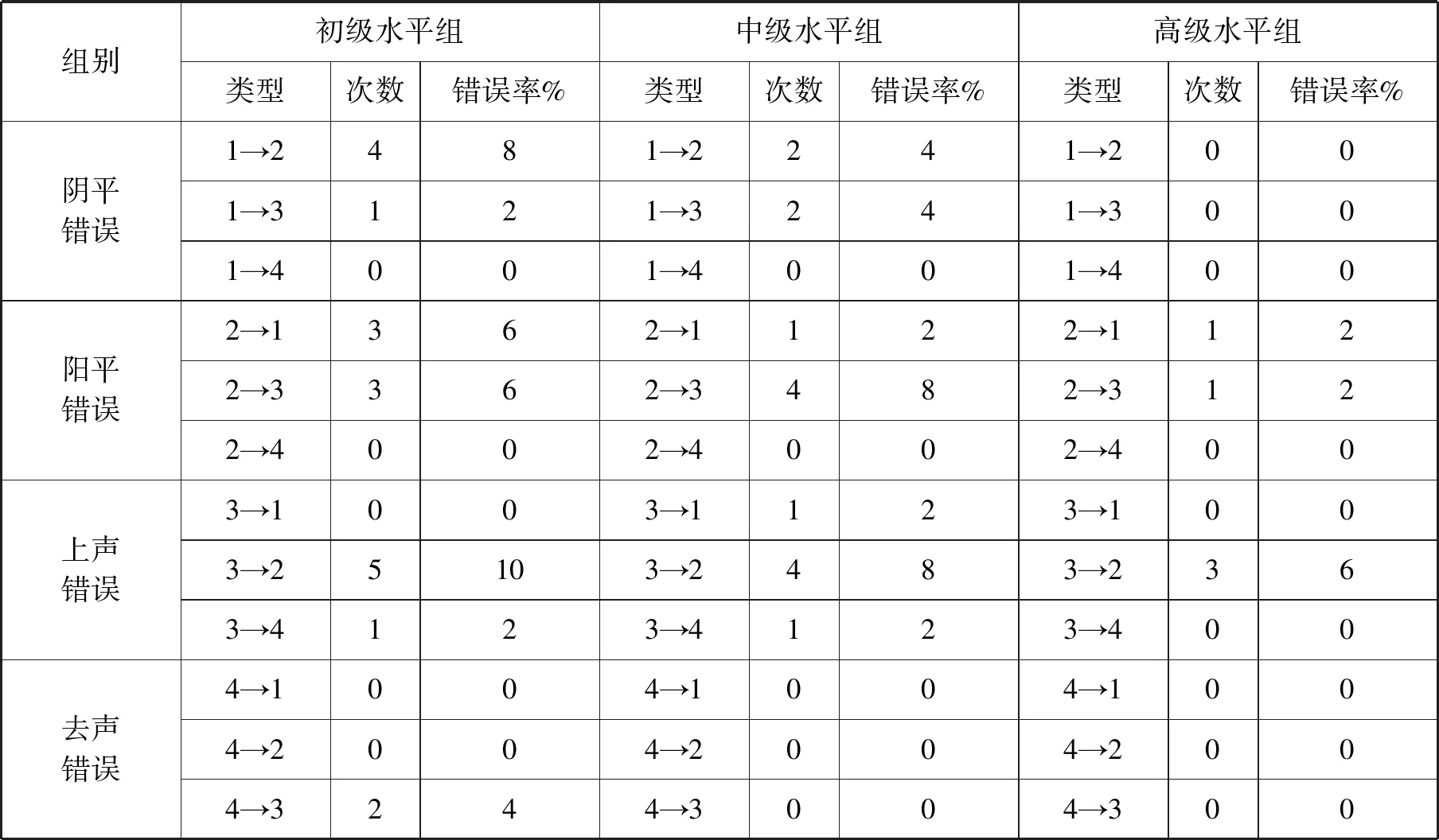
表4 单字调感知错误类型表
(三)对感知实验结果的分析
1.学习者感知汉语声调系统的建立及发展
以上两项实验中,三组被试的母语背景相同,生长环境相近,年龄差异不大,他们应该具有基本相同的声调习得规律,因此,我们可以把三组被试的汉语习得,看成相同学习者由汉语初级水平阶段向高级水平阶段发展的一个动态习得过程,通过它来考察学习者汉语习得过程中声调感知能力发展的特点。
当被试对目的语某一语音范畴的正确感知率达到80%~90%之间时,即可认为被试已经在中介语的感知中建立了该语音范畴(李嵬等,2000;王韫佳,2001)。根据这个标准,我们考察辨认实验的结果(表3),可以看到,学习者感知汉语声调的演变过程。低水平组被试已建立起去声调的感知范畴,而阴平的感知率为81%,阳平调的感知率为76%,处于此标准的临界点,因此,我们认为阴平调和阳平调的感知范畴已基本建立。而上声调的感知率为65%,即上声调的感知范畴尚未建立。中级水平组被试已经完全建立起阴平、阳平、去声的感知范畴,上声的感知率为75%,处于此标准的临界点,我们可以认为其感知范畴已基本建立。高级水平组被试已在感知中完全建立起汉语四个声调的感知范畴。这表明被试对汉语四个声调感知范畴的建立并不是同步的,而有先后之别,呈现一定的顺序:去声和阴平>阳平>上声(“>”表示“优于”,下同),去声和阴平哪个先被习得,统计结果表明,三组被试去声感知率均大于阳平感知率,我们由此得出,去声感知范畴的建立先于阳平。因此,从感知角度看,以东干语为母语者感知汉语单字调的基本顺序是:去声>阴平>阳平>上声。
2.学习者汉语声调感知错误的主要类型
根据表1、表2、表4的结果综合显示,虽然三组被试的实验结果并不完全相同,但有一定的规律:(1)1→2、2→3、3→2、4→3这四种错误类型分别是阴、阳、上、去四个调类中错误率最高的,出现率分别是6次、8次、12次、2次;1→4、2→4、4→1、4→2在三组被试的感知结果中错误率最低,出现率均为0。(2)2→3、3→2相混出现率最高,并且相混基本对称,学习者将阳平感知为上声的可能性与将上声感知为阳平的可能性基本相同。
(四)学习者在声调感知方面的特点及原因
我们通过声调感知实验得到了以东干语为母语者在感知汉语单字调时最显著的特点,即对汉语声调的感知具有优势。
国际汉语教学界的传统共识是:母语为有声调语言的学习者更易于习得汉语声调。在实验前我们的预判是东干族留学生应该对汉语声调的感知较为敏感,因为东干语是声调语言。其实验结果证实了我们的预判:东干族留学生对汉语声调的感知具有优势。初级水平组被试已建立起去声调感知范畴,阴平调和阳平调的感知范畴已基本建立;中级水平组被试已经完全建立起阴平、阳平、去声的感知范畴,上声的感知范畴已基本建立;高级水平组被试已在感知中完全建立起汉语普通话四个声调的感知范畴。
心理语言学认为,言语知觉过程可以划分为三个阶段,即:和听任何声音刺激一样的听觉阶段;根据一组声学提示来识别单个因素的语音阶段;将音段转化为音位并将音系规律应用到声学序列中的音位阶段(桂诗春,2000)。实验结果表明,东干族留学生对汉语声调的感知,经历了从不具备系统的非音系水平的感知(低级水平组)向具系统性的音系水平感知(高级水平组)发展的动态心理过程。
东干族留学生对汉语单字调感知具有优势的原因,我们认为可能有以下三点原因:
1.就东干语而言,它属于有声调的语言系统,即平、升、降三种调型,没有凹调。对比分析假说(Lado,1957)认为:两种语言结构特征相同之处产生正迁移,差异导致负迁移。负迁移造成第二语言习得的困难和学生的错误。东干族留学生较为容易感知汉语的去声和阳平,是因为母语正迁移的作用。东干语的升调有两个,调值为21和35,没有凹调,受母语负迁移的影响使得以东干语为母语者不容易感知汉语的阳平和上声。但总的来说东干族留学生在建立汉语声调感知范畴上更具有优势。
2.东干人对东干语的语言传承,语言传承是指“一个民族大多数成员的母语是本族语,该语言在该民族家庭中一代一代地传承和使用,在社区、学校、大众传媒等领域也不同程度的传播和推行”(周庆生,2018)。而东干语在东干社区内部也却是如此。根据刘俐李(2017)的调查,在东干人的社区,俄语虽为强势语言,但东干语仍具有强大的生命力,具体表现为:在家庭用语中,东干语的使用频度为68.8%,俄语为31.2%;工作时,俄语的使用频度为84.3%,东干语为15.7%。东干人在日常的工作和生活中仍然频频地接收有声调的东干语的刺激频度,正因为如此东干族留学生更易于建立汉语声调系统的感知范畴。
3.我们认为更深层的原因是语言认同感的影响。东干语留学生对东干语有着极其深厚的感情。他们将自己的语言称为“父母的语言”或“娘亲的语言”(常文昌、唐欣,2003),又因为东干语是汉语方言的域外变体,所以东干族留学生对汉语有着较强的认同感。在学习汉语时没有畏难情绪,故而更易于建立汉语声调系统的感知范畴。
三、产出实验
(一)发音人
发音人从感知实验的被试中随机选出,各水平组发音人10位。
(二)实验词与语音样本
8个单音节实验词(附录三)随机排列并标注拼音,防止发音人不认识汉字的情况发生,每个词发音人以自然的语速读3遍,结合听感和语图选取录音效果最好的。录音软件为Pro Tools,采样率为44.1kHz,单声道,精度为16bit。录音结束后将录音资料以WAV格式存入电脑。录音地点为西北师范大学国际文化交流学院语音实验室。汉语负载句为:我说( )这个词。
(三)产出数据的归一
将语音材料导入Praat语音软件中,将音节的元音段作为测量段,测量时去掉弯头和降尾。对所测得的原始基频数据进行归一,转化为五度值。归一时采用T值公式(石锋,1994),换算公式如下:
T=5× [ (Lgx—Lgb) / (Lga—Lgb) ]
公式中的x为测点值,a、b分别为语音样本数据中的最大值和最小值。结果乘以5是为了使实验数据跟传统的五度值记调法相对应。因此,T值就是五度值的参考标度。根据公式计算出T值的取值范围只能在0到5之间。T值和五度值之间的对应关系如表5所示:

表5 T值和五度值的对应关系
(四)产出实验结果
本文采用声调格局的方法,研究东干族留学生的汉语声调系统的产出情况。声调格局中,每一声调所占据的不是一条线,而是一条带状的声学空间(石锋,2006)。因此,我们对语音样本的总体统计分析采用如下方法:用平均值加减标准差的方法得到每个声调的声学空间,标准差表示一组数据对于平均值的离散程度。声调格局主要关系到每种语言中可能出现的各类声调的限度及分布情况(石锋,2006)。我们通过考察不同水平组的汉语声调格局,分析东干族留学生汉语声调系统的建立、发展及相关问题。
我们将不同水平组发音人的T值数据进行统计处理,以30位发音人每个测量点平均T值加减标准差的方法,分别获得每个水平组汉语各调的声学空间分布和声调格局,各水平组汉语声调格局见图三至图五。为了与东干语声调、北京话声调对比,我们分别以东干族留学生、中国籍学生(汉语普通话水平为一级甲等)为发音人,对东干语、汉语普通话单音节声调进行了声学分析,做出了东干语、汉语普通话声调格局图,见图一,见图二。
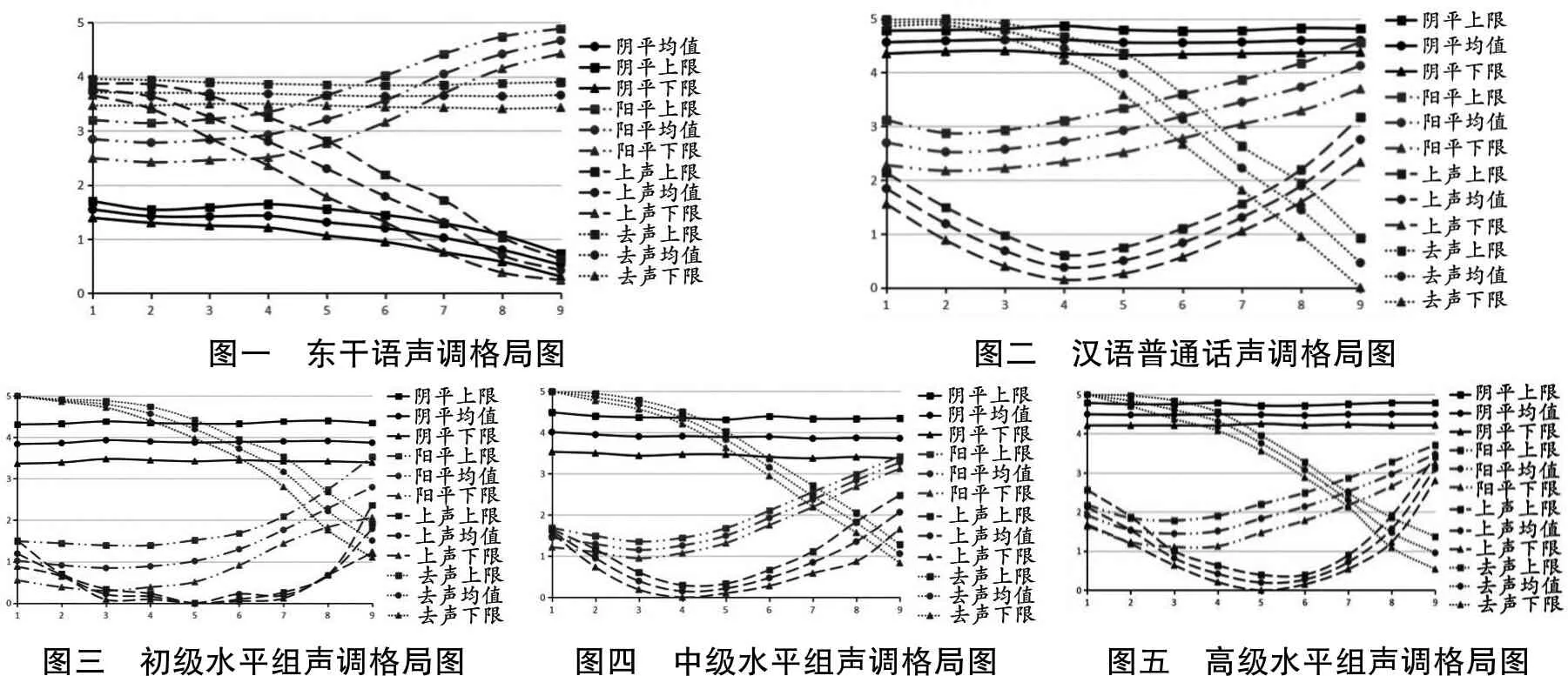
图一 东干语声调格局图图二 汉语普通话声调格局图图三 初级水平组声调格局图图四 中级水平组声调格局图图五 高级水平组声调格局图
(五)产出实验结果分析
音区和曲拱是声调的两个基本属性。音区指调域的分区。调域即声调音高的活动范围,存在于最高音高和最低音高之间。音高向不同音区的滑动变化构成了声调曲拱,即调型。汉语声调共有平、降、升、凹、角、凸、零7种曲拱型态(刘俐李,2005)。本文据此讨论东干语、汉语和不同水平组汉语单字调的习得情况。
1.东干语和汉语普通话对比
由图一、图二我们可得出东干语和汉语各自的特点,见表6(均采用最值点数据,下同):
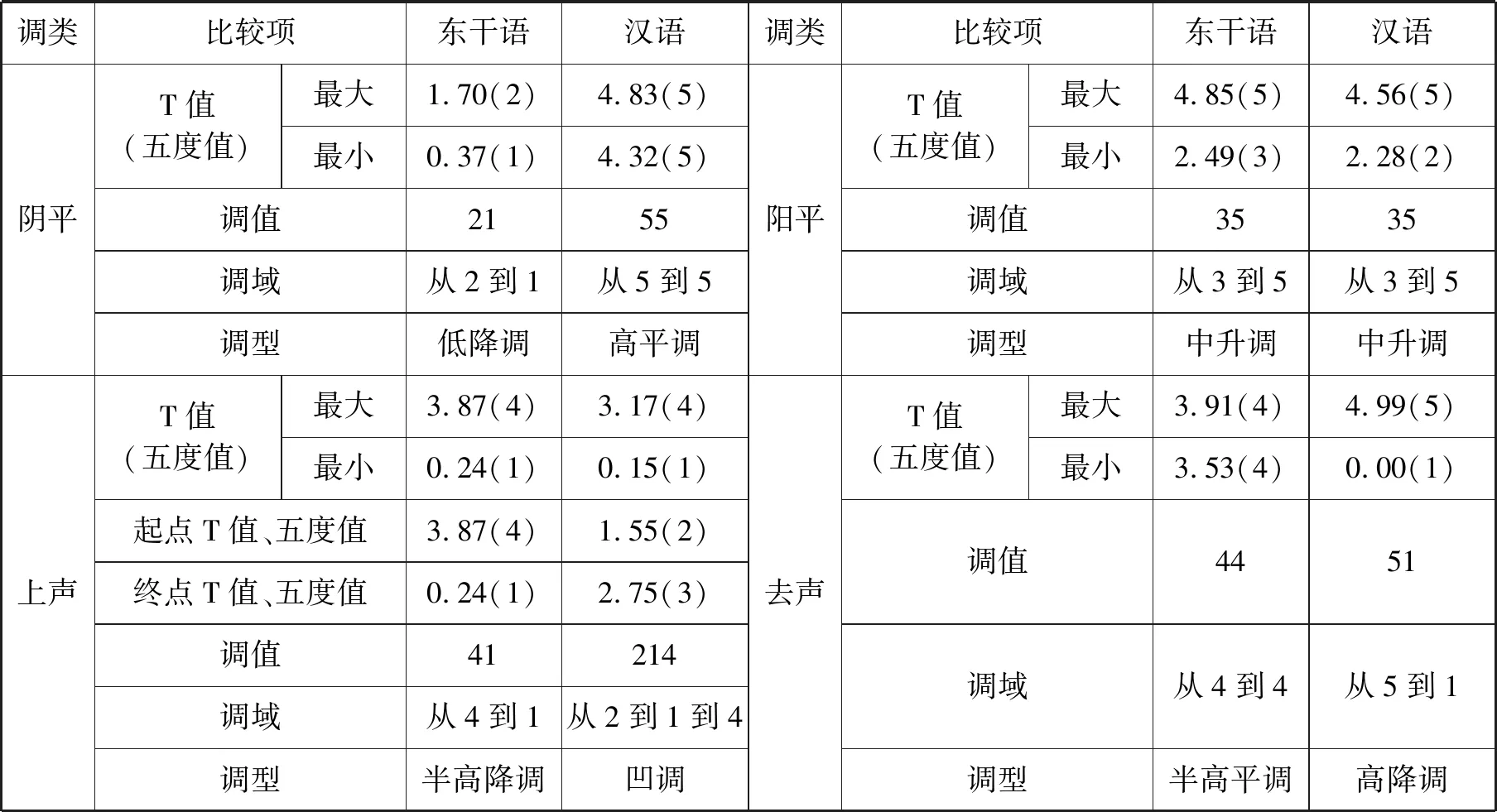
表6 东干语和汉语对比
从上表可得出:东干语共有四个声调,且调类与普通话一致,分别是阴平、阳平、上声和去声。但其相应的调值却与普通话完全不同。其调值分别是:21、35、41、44。这与王森(2015)的研究是一致的。普通话的调型有平、升、降、凹四种,东干语的调型只有平、升、降三种。根据对比分析假说(Lado,1957):两种语言结构特征相同之处产生正迁移,差异导致负迁移。负迁移造成第二语言习得的困难和学生的错误。基于此,我们可预测出东干族留学生学习凹调即上声是较为困难的。
2.学习者汉语声调系统的建立与发展
图三至图五为不同水平组汉语单字声调格局,将其作横向比较,可以得出东干族留学生汉语声调系统的建立与发展,见表7:
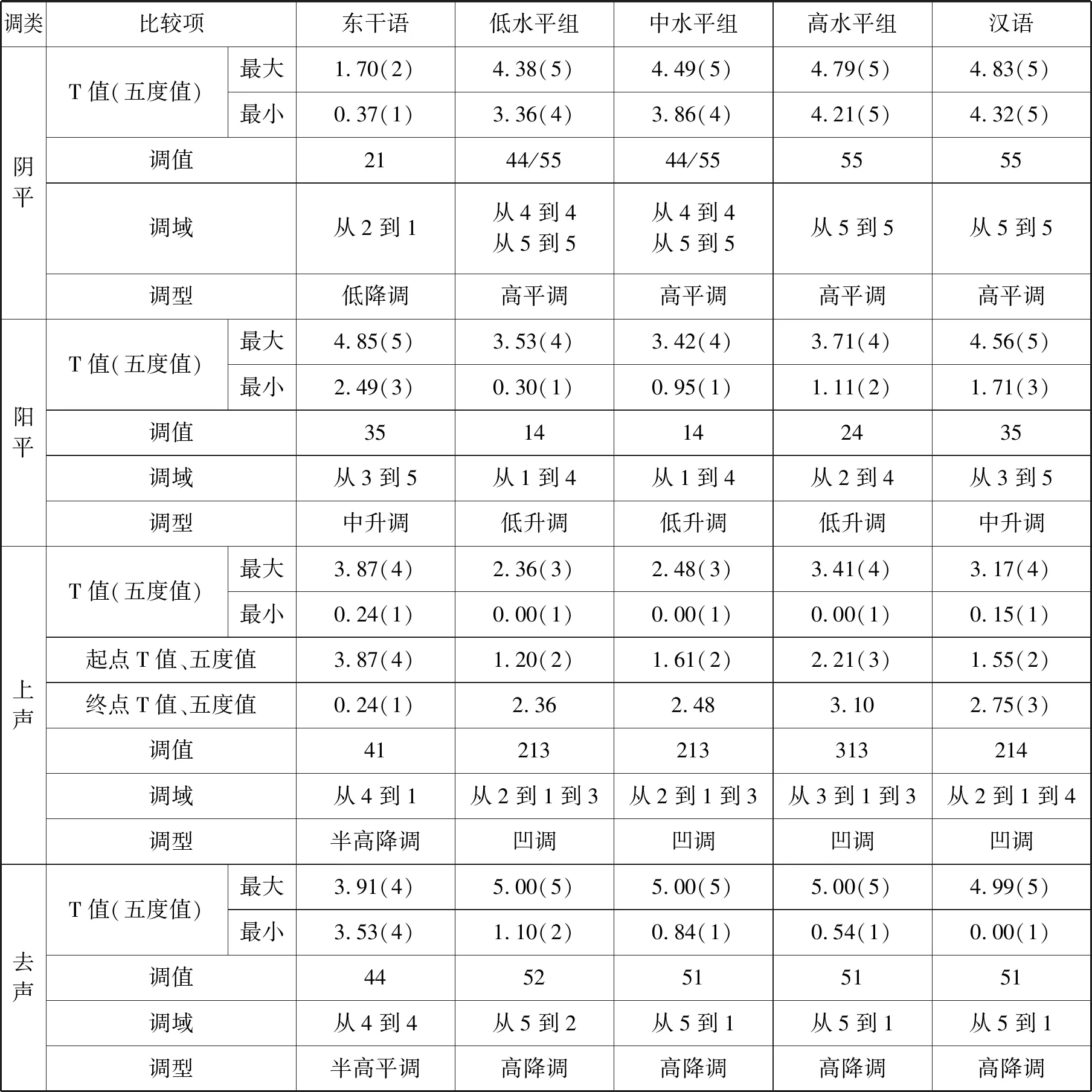
表7 不同水平组汉语单字声调格局数据表
结合图一至图五和表6、表7,我们可以看出东干族留学生汉语单字调的建立和发展过程。图三是初级水平组建立的阴平、阳平、上声、去声四个调类,完全打破了东干语原有的调值从21、35、41、44变为44/55、14、213、52,初级水平组所建立的中介语系统与汉语普通话的四个声调相比每个声调的发音都不到位,但四个声调不论调域还是调型都具备了平、升、降、凹的特征,这四个特征中,平、降与汉语声调的特征相似;升、曲与汉语声调的特征有较大差别。图四、图五是中级、高级水平组所建立的汉语单字调格局。从整体的习得过程看,学习者汉语声调系统是一个动态发展的过程,在初级水平阶段学习者建立起汉语声调近似系统,从初级水平阶段到中级水平阶段,学习者汉语声调系统变化明显,中级水平阶段到高级水平阶段只是在原有系统上进行调整,使该系统逐步向目的语声调系统靠近,但在高级水平阶段也未能真正建立起汉语声调系统。学习者汉语声调习得的顺序是:去声>阴平>阳平>上声,这也证实了上文中的预测,即上声最难习得。
3.学习者习得过程中的主要错误及原因分析
从图三至图五和表6、表7,我们可以发现学习者的主要错误表现在以下几个方面:阴平调不够高;阳平的起点、终点也不够高,有明显的拐点,易和上声相混;上声在汉语水平初级阶段调域和调型都有错误,在汉语水平中级阶段虽然调型呈曲折型,但终点上升高度不够,易和阳平相混,在汉语水平高级阶段调型和调域没有发生偏误但拐点位置靠后,在第五个点(普通话在第四个点);去声调域较窄。总的来说是调域偏误多于调型偏误。
东干语与汉语一样都是声调语言,因此,他们都能够灵活的控制声带,所以东干族留学生在产出汉语声调时调型偏误较少,这是受母语正迁移的影响。而造成其调域偏误较多的原因,主要是因为母语的负迁移,学习者在学习汉语声调时,大多使用母语中近似的声调代替目的语声调,具体表现在:将东干语中的去声(44)代替阴平;将东干语中的阴平(21)或阳平(35)代替阳平;将东干语中的上声(41)代替去声。但东干语的调域相比于汉语较窄,受母语调域较窄的影响使得东干族留学生产出的汉语单字调调域偏误较多;且东干语没有凹调,所以学习者习得上声较为困难,表现为调域、调型都出现了偏误。
(六)学习者汉语声调产出的特点
根据上文的分析,学习者在汉语初级水平阶段就已建立了汉语声调的近似系统,但在建立这个近似系统后的很长时间,直至高级水平阶段,其声调系统在调域方面仍然具有东干语声调特征,学习者始终未能摆脱东干语声调特征,建立真正的汉语声调系统,这也证实了母语负迁移是二语习得的巨大障碍。
四、对东干族留学生汉语单字调感知和产出实验结果的综合分析
(一)声调感知与产出的关系
通过感知实验和产出实验,我们可以看到东干族留学生在习得汉语声调过程中声调感知系统的建立对于声调产出系统的建立十分重要,从本文的实验结果看,学习者如若可以正确感知某一声调,便可以正确产出该声调;如若不能正确感知某一声调,便不能正确产出该声调。这也支持了Flege等(1999)提出的,感知与产出密切相关且感知先于产出的看法。
(二)东干族的特殊性更易于汉语单字调的感知和产出
国际汉语教学界传统的观点认为:母语有声调的学习者更容易习得汉语声调。就是说他们在感知和产出方面更容易建立汉语声调的近似系统。因为有声调的母语对学习者汉语声调的习得产生正迁移。通过本文的实验,我们发现东干族留学生对汉语声调的习得符合国际汉语教学界传统的观点。
其原因在于东干族这个群体的特殊性。首先,东干语本来就是近代汉语方言的域外变体,它属于有声调的语言;其次,东干族对东干语的语言传承,他们在东干社区及工作生活中仍然频频地使用有声调的东干语;最后,我们认为更深层的原因是语言认同感的影响,东干族留学生对汉语有着较强的认同感。在学习汉语时没有畏难情绪。结合以上三个方面的原因,我们可以认为东干族的特殊性使得东干族留学生更易于建立汉语声调系统。
五、对汉语声调教学的启示
对于声调感知能力和声调产出能力的关系,Yip(2002)做过精辟的说明:良好的声调感知能力并不必然带来良好的声调产出能力,但没有良好的声调感知能力就不可能有良好的声调产出能力。近年来,已有大量的研究发现感知训练能够有效促进第二语言的语音习得,而且感知能力的提高还可以改善发音(McClelland et al,2002;Wang et al,2003)。易斌(2012)认为,留学生汉语发音的错误或发音的困难大致可分为以下两类:一类是由于感知错误或者困难导致的发音错误或困难;另一类是单纯的发音错误,也就是感知正确而发音错误。因此,在国际汉语声调教学中,要更加重视声调感知能力的训练,要进一步探讨声调感知的特点和规律以及如何通过感知训练提高声调的产出能力,更好地服务于国际汉语声调教学。
注释:
[1] 某组某类测试项的平均错误率=某组被试某类测试项目的错误次数之和÷(某类测试项在测试中的出现次数之和×某组被试人数)
[2] 某组所有测试项的总错误率=某组所有被试的所有测试项目的错误次数之和÷(各测试项目在测试中的测试次数之和×某组被试人数)
[3] 某组某调类的平均错误率=某组所有被试某调类错误次数之和÷(某调类在测试中的测试次数之和×某组被试人数)
[4] 某组声调总错误率=某组所有被试的所有调类错误次数之和÷(各调在测试中的测试次数之和×某组被试人数)
[5] 某组某个调类的感知率=某组正确感知该调的人次÷某组被试人数
[6] 某组某错误类型的错误率=某组被试某错误类型的错误次数之和÷(某调类在测试中的测试次数之和×某组被试人数)
猜你喜欢
中国卫生统计(2023年5期)2023-11-30 01:40:14
河北师范大学学报(哲学社会科学版)(2023年3期)2023-05-12 09:39:30
作文周刊·小学一年级版(2022年28期)2022-05-30 10:48:04
小天使·一年级语数英综合(2020年9期)2020-12-16 02:57:03
参花(下)(2019年10期)2019-11-13 15:54:48
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:16
作文周刊·小学一年级版(2019年28期)2019-09-07 03:42:03
教师·中(2017年3期)2017-04-20 21:49:49
四川文学(2016年9期)2016-09-18 23:16:32
试题与研究·教学论坛(2016年27期)2016-08-11 14:57:08
