
基于自注意力和胶囊网络的短文本情感分析
2020-07-15 08:56:24徐龙
计算机与现代化 2020年7期
徐 龙
(中国石油大学(华东)计算机与通信工程学院,山东 青岛 266580)
0 引 言
近年来,移动互联网和社交网络发展迅速,用户越来越习惯在各大电商平台中表达对某一产品或者服务的喜好,同时利用微博等社交软件在互联网中分享和传播自己对于某件事物的看法。伴随着这些在线评论的兴起,对评论文本进行情感挖掘引起了许多学者的高度关注,研究的侧重点主要是确定评论文本的情感极性[1-2]。
1 相关研究
大多数现有的情感极性分类方法都遵循Pang等人[3-4]提出的方法,主要包括传统的统计学方法以及机器学习方法,例如逻辑回归(LR)、朴素贝叶斯、支持向量机等方法。此类方法一般从带有情感标签的文本中,人为地构造合适的特征,同时通过期望交叉熵等方法选取最有效的特征来表征文本,用于学习器的训练,最终获得文本的情感极性。这些方法的优势在于算法相对简单,但是,特征的构建过程更多地依赖于大量人工提取的文本特征和领域知识,整个过程人为因素干扰大[5]。同时,人为构造的特征比较浅显,普遍无法对文本的语义特征进行更深层次抽象与提取。由于评论文本具有主题不明确、口语化严重、规范性很差等特点[6],使用传统特征提取方法则更加费时费力。
近年来,深度学习在自然语言处理领域的应用引起了工业界和学术界广泛的关注[7-8]。深度学习是一种端到端的模型,其本质上是一种表示学习方法,深度学习模型能够高效、自动地完成特征提取任务,并且取出的特征能够更好地反映出文本语义信息。Kim等人[9-11]在预训练的词向量(word embedding)模型上研究了卷积神经网络对句子级别情感分析任务的表现,将词向量与卷积神经网络相结合,获得了比较出色的应用。Bagheri等人[12]利用循环神经网络模型对短文本进行情感分析,取得了先进的性能。自2017年以来,越来越多的学者开始使用自注意力机制[13-14]进行文本特征的提取,自注意力机制是一种高效的捕捉文本特征的网络层,它通过计算self-attention,可以得到句子内部词之间的依赖关系,更高效地捕捉句子内部的结构。而多头注意力机制则多次进行self-attention的计算,可以进一步提高捕获文本特征的能力。GPT(Generative Pre-trained Transformer)[15]使用自注意力层作为文本特征提取器,并通过简单地微调预训练参数在下游任务中进行训练。谷歌于2018年提出的新的预训练语言模型BERT[16],同样以自注意力层作为特征提取器,在11个自然语言处理任务上都达到了极佳的结果。Sabour等人[17-18]提出了胶囊网络(capsule network),其本质是一个包含多个神经元的向量,向量中的每个神经元表示了图像中出现的特定实体的各种属性。
目前深度学习在情感分析领域依然存在很多问题。首先,深度学习模型的训练需要大量监督训练样本;同时,深度学习模型拥有大量的参数,在规模较小的数据集上进行训练,往往会导致过拟合的出现。其次,由于情感分析领域的数据标注大多采用人工标注的方法,成本高昂,难以得到有效扩展,在情感分析领域监督训练样本规模始终有限[19]。
为了解决传统机器学习应用中文本特征提取选择的主观性难题,同时改善深度学习技术在自然语言处理领域准确度低的问题,提升评论文本情感分析的准确性,本文提取出一种使用自注意力机制作为底层特征提取器,而胶囊网络作为网络结构顶层分类器的网络模型,并对小样本数据以及跨领域迁移情感分析进行探索。
2 模型设计
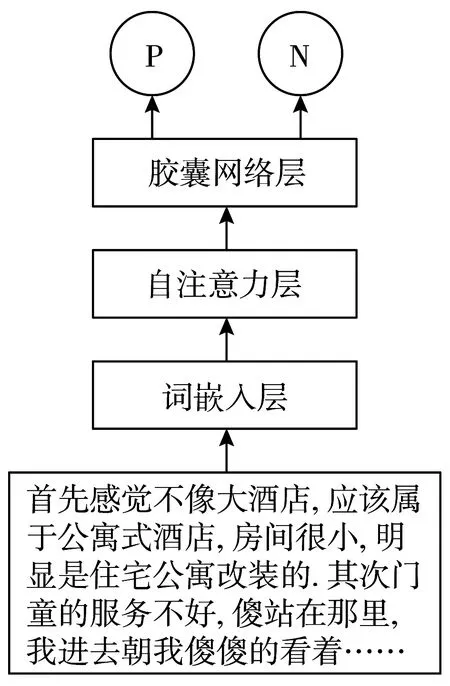
图1 模型结构图
本文提出一种基于自注意力和胶囊网络的模型用于情感分析,其结构如图1所示。它由3个模块组成:语义表示模块、自注意力特征提取模块和胶囊网络分类模块。假设输入句子是Z=[w1,…,w2],该模型的目标是预测句子Z的情感极性是正(P)还是负(N)。
2.1 文本特征矩阵构建
文档是由一个单词序列构成,神经网络的输入需要将文本数据映射为实数向量,即将每个词映射为一个向量,目前,文本向量化的表现方式主要包括2种:独热向量表征和词向量表征。本文使用词向量表征方法,通过爬虫软件爬取大约200万条某购物网站评论数据,与中文维基百科数据合并构成语料库。经过去重、无效数据删除等数据清洗手段,同时利用停用词库对该语料库进行去停用词后进行分词,利用Word2vec[20]方法得到语料库中所有词的向量表示M∈R200×|v|作为词嵌入层,其中200是词向量的维数,|v|是词汇表的大小。通过将输入文本进行相同的预处理过程,用xi∈Rk表示评论句中词语wi,每条评论均看作词语的序列,通过词嵌入层的映射后,每个词被表征为一个200维向量,既可保留评论语境前后顺序,又可以将评论表示为矩阵形式,最终得到文档集的向量表示,并在随后的训练中进行调整。
2.2 自注意力特征提取层
卷积神经网络利用文本中的局部最优信息,但浅层的卷积神经网络难以捕捉长距离特征,难以对序列数据进行建模;而循环神经网络则利用长距离的上下文历史信息,但在长距离上容易产生梯度消失或梯度爆炸问题,梯度难以传播,参数无法得到有效的更新。所以,本文采用自注意力层提取评论文本中的特征,通过将句子中的任意2个单词直接链接,一步到位捕捉到句子中词与词之间的相互关系,直接获取长距离相互依存特征,提取到的特征对文本的表征则更加丰富。
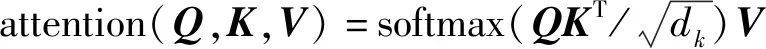
MultiHead(Q,K,V)=Concat(head1,…,headn)
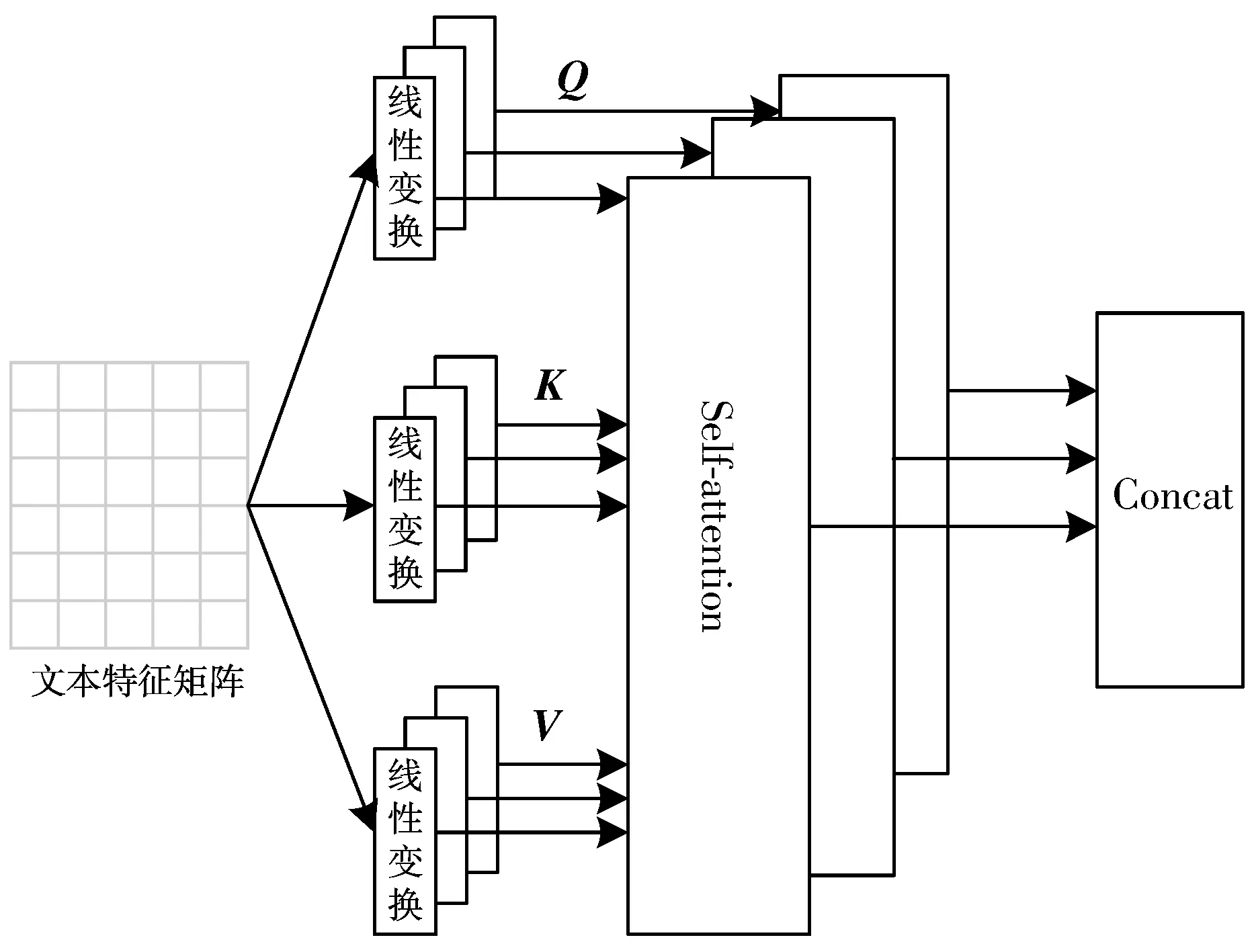
图2 多头自注意力提取层结构
2.3 胶囊网络分类层
本文使用胶囊网络中的神经元向量来代替传统神经网络中的单个神经元节点。胶囊网络除了可以在自注意力层提取丰富的文本信息,还可以有效地编码单词位置、语义和合成结构,它提高了文本表达能力,并获得了文本的更进一步的表征。
该层的输入为自注意力特征提取层的输出hi,整个模型参数的更新采用动态路由算法[17]。利用胶囊向量的模长来表示对应类别的分类概率,利用不同的胶囊向量对应不同的类别。整个网络层的结构如图3所示。图中各关键参数计算公式如下:
uj|i=Wijhi
为了能使胶囊的模长表示概率,将最后的输出使用squash函数进行归一化。
vi=(‖sj‖2/(1+‖sj‖2))×(sj/‖sj‖)
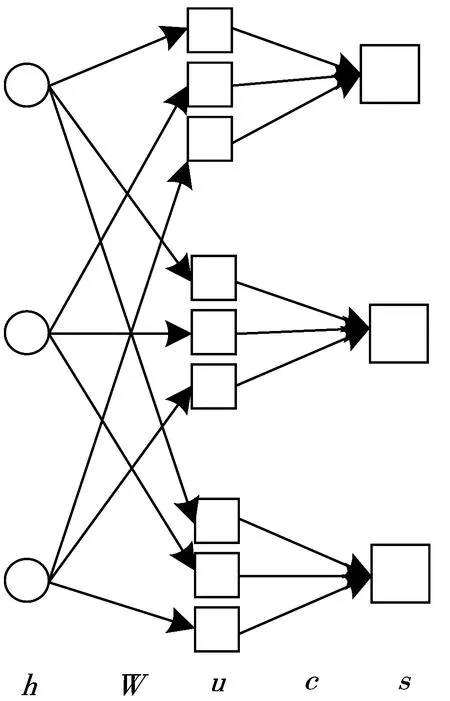
图3 胶囊网络层结构示意图
3 实验过程和结果分析
本文选择谭松波教授整理并标注好的酒店评论语料,为了探究小数据集上的模型表现,选择其中的6000条平衡评论数据,其中正面评论数目为3000,负面评论数目为3000。在作为模型的输入之前,先对数据进行数据清洗,调整语料数据的格式和字符,去除数据集中不相关的特殊符号、空格符及换行符等,并进行停用词的处理。其中,训练集与测试集的比例为7:3,是正负样本经过随机分割得到。
实验参数设置如表1所示。

表1 实验参数设置
3.1 短文本情感分类结果分析
本文实验的评价指标是准确率(Precision)、召回率(Recall)和F1值(F1-score),对比实验选择了目前主流的情感分析深度学习方法,深度模型包括TextCNN、TextRNN、TextAttBiRNN,为了防止过拟合现象,使用Early Stopping策略进行模型的训练,并通过对多组超参数调整选取了最佳的模型表现结果。
表2展示了TextCNN、TextRNN、TextAttBiRNN这3个主流的用于情感分析的深度学习模型以及本文使用的模型做情感分析的结果,对比可以发现:在样本数量比较多的条件下(4800条训练样本),经过精细的超参数选择,可以发现通过将预训练后的词向量作为深度模型的输入,主流的深度学习模型都取得了比较好的效果。其中TextCNN在3个不同数量训练样本都取得了最好的分数,因此,可以认为相较于长距离文本信息,评论文本的情感分析准确率更依赖于局部特征。
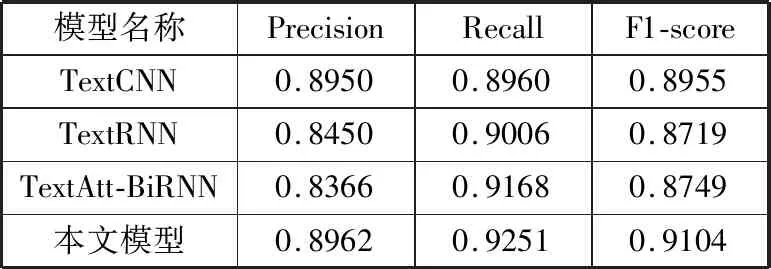
表2 短文本情感分析结果
使用本文提出的基于自注意力层和胶囊网络的模型用于文本情感分析,相较于传统的情感分析深度学习模型,精度得到了提高。可见本文提出的模型是有效的,可以有效提高评论文本情感分析的精度与准确度,本文提出的方法在情感分析任务上具有很好的性能。
3.2 小样本和语料迁移结果分析
为了验证本文提出的模型在小样本数据上的有效性,设计了小样本试验,即分别在500个训练样本中训练和在200个训练样本中训练,实验结果如表3、表4所示。
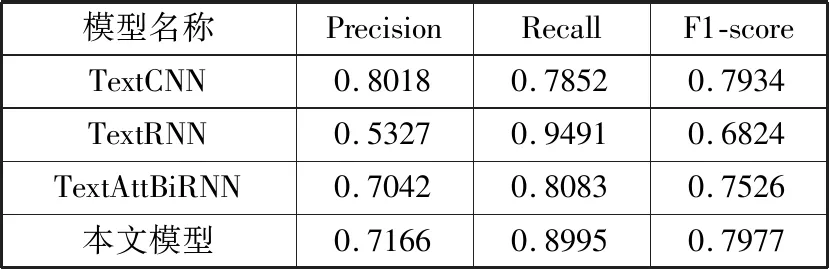
表3 500个训练样本情感分析结果
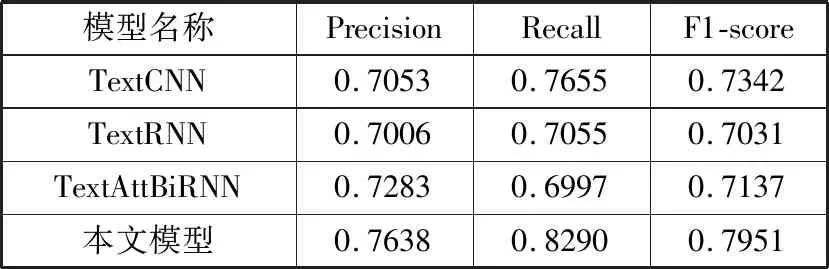
表4 200个训练样本情感分析结果
此外,为了验证本文模型充分提取到了语言的语义信息以及模型的优越性,本文设计如下实验:将在4800条酒店评论语料上充分训练得到的最优模型,用来预测3000条某网站获取的水果评论语料,该水果评论语料由1500条正面评价和1500条负面评价组成,实验结果如表5所示。

表5 跨领域迁移学习结果
在小样本数据集上,可以看到,主流的深度学习模型精度下降10%~20%,可见,传统深度学习模型在小样本数据集上表现糟糕,主要是由于传统模型在小数据集上无法得到有效的训练,不能很好地捕捉到文本中跟情感分析相关的语义特征,而本文提出的方法,在小样本数据集上表现稳定,在500个样本训练集上比传统的主流深度学习模型中表现最好的TextCNN,F1值稍有提高,在200个训练样本上,F1值提高了6个百分点左右,且与500个训练样本表现相当。因此可以认为自注意力层充分提取到了样本中的语言学知识,而胶囊层又能很好地对它们进行分类,因此,本文提出的方法在小样本评论文本情感分析中也有很好的性能。
通过跨领域迁移实验结果可以得出:评论语料的情感分析更多好依赖于局部特征,因此TextCNN模型表现较好,迁移性能比较好。但是,依然存在精度不足的问题,难以在实践中使用。而本文提出的模型比传统的主流深度学习模型中表现最好的TextCNN,F1值提高了近1.5个百分点,因此本文提出的模型既可以充分学到评论文本中的短距离平行特征,又因为自注意力特征提取层的机制,也可以充分学习到长距离依赖特征,因此,本文提出的模型在跨领域样本情感分析中也有很好的性能。
4 结束语
本文提出了一种新的基于自注意力机制和胶囊网络的混合模型用于情感分析任务,该模型不仅充分利用了短文的前后信息,缩短了相互依赖的特征之间的距离,而且可以提取出更丰富的文本信息。通过在相同的训练条件下,与目前主流的情感分析中的深度学习模型作对比,本文提出的模型在情感分析任务的精确度上有提升,同时,在小样本数据集上进行对比实验得出,该模型在小样本数据集上表现优异,提升了精度,同时,在跨领域迁移学习上的实验表明该模型确实增强了模型学习语义特征的能力,极大地提高了文本情感分析在不同领域上的表现。
猜你喜欢
Journal of Traditional Chinese Medicine(2022年5期)2022-11-16 01:54:34
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
Journal of Traditional Chinese Medicine(2021年6期)2021-08-09 12:36:44
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
中国科技术语(2012年3期)2012-03-20 14:36:14
