
基于用户行为和新闻时效性的农业信息协同过滤推荐算法
2020-07-15 11:02徐建鹏
计算机与现代化 2020年7期
徐建鹏,徐 祥,王 晖,伍 琼,王 杰
(安徽省农村综合经济信息中心,安徽 合肥 230001)
0 引 言
随着信息技术的迅猛发展,信息过载已成为亟待解决的难题,作为解决信息缺乏针对性的有效方法,信息内容推荐算法得到了广泛的研究与应用。它通过分析系统中显式或隐式信息,根据用户的关注和喜好为用户提供关联性强的信息和商品推荐服务,有效地解决了信息服务不精准的问题[1]。推荐算法是信息内容推荐服务的关键,是提升推荐内容精准性的重要前提,目前信息服务相关推荐算法有内容、知识、协同过滤以及混合4种方式,其中基于协同过滤的推荐算法是相关服务系统应用最广的推荐算法[2]。
在农业信息服务中,个性化推荐技术可以解决信息服务的精准性和针对性的难题,传统基于行为的推荐算法能挖掘农业信息服务中用户对服务内容的关注点和兴趣点,但随着时间的变化,用户所处农业生产的关键生产阶段发生了变化,同时受各类社会因素影响,农户对资源的需求随着时间的推移不断改变,其关注点和兴趣点也会发生变化。已有的基于浏览行为的推荐算法通常基于显式反馈,但实际应用中农户基本采用匿名访问方式,反馈信息也十分有限,存在严重的冷启动问题[3]。为此需要结合显式、隐式反馈信息,充分挖掘农户行为,同时考虑到农业生产的周期性、农业行情的波动性以及天气变化等因素,尽可能向农户推荐当前热点的农业新闻以及用户可能感兴趣的、对其有价值的信息。
近年来,改进时效性的协同过滤算法受到关注。张新香[4]提出了情境感知和兴趣适应的农业信息推荐模型,引入情境因素、浏览行为和兴趣改变等向量空间模型;刘江冬等人[5]提出基于信息熵和时效性的协同过滤推荐,利用用户访问评分数据获得项目时效性模型,并将项目时效性和用户信息熵2个模型相耦合。董晨露等人[6]提出的基于用户兴趣变化和评论的协同过滤算法,将用户评论和遗忘曲线引入传统协同过滤算法中,将评论文本作为商品特征描述文本,计算系统提供商品的主题特征,引入艾宾浩斯遗忘曲线来协同计算用户的评论分布及评论相似度。肖红等人[7]针对农业科技信息共享率低、分散分布等问题,应用Web信息抽取方法实现自动采集多源农业科技信息入库,采用改进的K-means聚类方法建立用户访问模式,并得到访问模式的网页特征词及权重的集合,构建用户兴趣模型库。
本文针对农业新闻时效性和周期性特点,提出一种基于用户行为和农业信息时效性的协同过滤推荐算法,综合用户的隐式、显式反馈数据等多维因素,同时考虑农业信息的分类特征及周期性特征,采用热度系数及人工参数提高农业新闻推荐的针对性和时效性。
1 相关工作
1.1 用户行为分析
用户行为数据获取及其量化是新闻个性化推荐的前提,一般而言用户对新闻的兴趣主要体现为显性反馈行为和隐式反馈行为[8],显性反馈主要是指用户针对物品做出的明确性的评价,如评分、点赞、收藏等,主要优点是量化方便,缺点是依赖用户主动贡献,通常数据稀疏不全[9]。隐式反馈主要是用户的浏览行为,包括浏览的页面及停留时间等,显式与隐式用户反馈的主要特点如表1所示。

表1 用户反馈数据分类及其特点
针对网页浏览,用户u针对新闻s的显式行为可用公式(1)表示:
(1)
其中,fi代表行为i如点赞、收藏、转发、评分等是否触发或用户打出的评分。
注意到每种行为表示用户的偏好度是不同的,因此需要为每种行为赋予权重值,可用公式(2)表示:
IW={w1,w2,…,wY}
(2)
则用户显式行为评分为:
(3)
隐式反馈行为指的是那些不能明确反应用户喜好的行为,最具代表性的就是页面浏览行为。基于用户浏览行为可以计算2个新闻的相似度,即:
(4)
其中,|N(i)|、|N(j)|分别表示浏览过新闻i、j的用户数,|N(u)|表示同时浏览过新闻i、j的用户数。
研究表明,如果对ICF的相似度矩阵进行最大值归一化,可以有效提高推荐的准确率、覆盖率和多样性[10]。归一化的公式为:
(5)
1.2 基于项目的协同过滤算法(ICF)
传统基于项目的协同过滤算法认为,用户对目标项目的评分与用户对该项目的相似项目评分接近,因此该算法的核心是计算项目间的相似度,主要步骤为:
1)建立m行n列的用户—项目评分矩阵。
2)计算目标项目i与其他项目j的相似度[6]。
皮尔逊相关系数公式为:
(6)
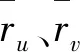
3)将其他项目按照计算出的相似度由高到低进行排列,选取其中前k个项目作为目标项目的最近邻集合。
4)计算用户u对目标项目i的最近邻集合评分的加权和,以此作为用户u对目标项目i的预测评分。项目间相似度的计算是基于共同评分的用户集进行的,公式如下:
(7)
其中,Iu表示用户u给过评分的项目集合,S(i,k)表示和项目i最相似的k个项目的集合,PC(i,j)表示项目i、j的相似度,ru,j表示用户u对项目j的评分。
由于基于项目的协同过滤算法在计算项目相似度时是根据项目的共同评分集合来进行的,因此只有在2个项目的共同评分较多的情况下得出的项目相似度才较为准确。但在现实中,由于系统数据量庞大,评分数据存在着较大的稀疏性,2个项目的共同评分数据较少,导致有些与目标项目实际有较大差异的项目因计算得出的相似度较高而被纳入项目最近邻集合,同时,单纯地依靠评分计算项目相似度而未考虑项目自身特点的算法策略,也在一定程度上降低了最近邻选取的准确性,影响了推荐效果。
2 基于用户行为和新闻时效性的协同过滤推荐算法
农业信息服务系统提供的农业信息服务大多为文章形式,与一般的新闻网站类似。用户在访问服务系统提供的信息服务时,会产生大量的浏览记录,以及实时交互和反馈信息,如阅读、点赞、评论等,能反映用户短时间内的兴趣焦点,而对这些交互反馈信息进行长期累积,就能形成贴近用户长期偏好的历史数据。因此可以基于实时反馈信息以及大量的历史浏览信息维护新闻相似度矩阵,基于相似度举证就能在考虑用户长期固有偏好的同时也能关注用户短时间内的兴趣焦点变化。
2.1 新闻相似度矩阵及其更新
新闻相似度矩阵通过维护新闻阅读量矩阵实现,矩阵如下:

(8)
该矩阵主要保存新闻i的阅读用户数N(i)以及新闻i、j的同时阅读的用户数N(i,j)。通过该矩阵以及公式可快速计算新闻相似度。
2.2 农业信息分类及周期规则
农业信息具有分类特点,农业信息服务网站主要是依据服务的类别进行栏目划分,如天气信息、行情信息、供求信息等,不同类别的农业信息农户的关注度是不同的,可以根据历史用户阅读数据统计各栏目的关注度变化情况。农业信息还表现为周期性和区域性特征,如水稻播种时用户倾向于查看水稻播种相关新闻,台风发生时倾向于查看台风防范新闻,皖北地区用户关注小麦信息的程度比皖南地区用户高,皖南地区用户关注水稻细腻的程度比皖北地区高等,根据不同周期和用户的区域分布可对热度系数进行一定的调整。
关注度(Attention)是指历年同一天各栏目阅读量的历史平均值,主要反映一年内农户关注的信息类别周期性变化情况。由于皖南、皖北的种植作物、气候差异较大,因此分别做了关注度统计。表2为某日关注度统计值,计算方式如公式(9)所示,即栏目的关注度系数等于该栏目的阅读用户数除以各栏目的平均阅读用户数,根据实际情况,有时也做一定的人工调整。
(9)

表2 某日关注度统计值
新闻表现出热度变化情况,突发性的舆论热点能引起某类别的新闻大量阅读,如猪肉价格上涨引起生猪养殖类新闻热度较高。同时,农业信息服务具有一定的时效性,用户对信息服务的热度值会随着时间流逝而衰减,并且趋势应该是衰减越来越快,直至趋近于0[5,11-12]。新闻i的热度系数公式如下:
(10)

2.3 推荐步骤
1)服务网站以文本日志的方式记录用户访问情况,主要信息包括用户ID、用户IP、文章ID、访问时间等。
2)将用户点赞、转发、留言等用户在网站的操作行为数据信息记录到用户行为数据库,包括用户IP、文章ID、行为ID、行为内容、分值、操作时间等。
3)每日服务器和网络空闲时(如夜里0时)读取前一日日志信息,更新新闻、文章等信息的访问用户数据,同时更新相似度矩阵、栏目关注度等信息。根据用户访问数据,更新当日各类信息的热度系数。
4)当检测到当前用户是匿名访问的用户时,依据新闻、文章的热度系数排名向其推荐相关信息服务。
5)当前系统访问用户有访问记录,依据相似度矩阵形成推荐列表,根据预测分值排序前N条数据新闻作为待推荐列表,按照当日热度系数排序分页(分页值取15)向其推荐信息服务内容。
2.4 算法实现及复杂度分析
算法主要依托维护的新闻相似度矩阵以及新闻热度值进行推荐,首先依托TopN算法获取最相似的新闻列表,然后按热度排名向其推荐新闻,具体伪代码如算法1所示。
算法1推荐算法。
输入:待推荐用户User
输出:N条推荐新闻
var UserId=GetUserId();
var IP=GetUserIP();
If(UserId>0)//登录用户
{
//获取该用户的历史阅读新闻列表
List
//依据新闻相似度矩阵获取k个最相似新闻
var Neighbor=GetNeighborNews(Read,k);
//推荐显式反馈评分推荐评分最高的N条新闻
Return SimilarNews(Neighbor,Ir,N);
}
Else//匿名用户
{
If(IP=="0.0.0.0")//无法获取用户IP
{
//无法获取IP推荐热度最高的N条新闻
Return HotNews(N);
}
Else
{
//获取该IP阅读过的新闻列表
List
if(Read.Length<10)
{
//访问较少推荐热度最高的N条新闻
Return HotNews(N);
}
Else
{
//依据新闻相似度矩阵获取k个最相似新闻
var Neighbor=GetNeighborNews(Read,k);
//从邻居新闻中返回热度最高的N条新闻
return HotNews(Neighbor, N);
}
}
}
算法复杂性分析:设新闻总数为m,选取邻居数量为k,推荐新闻数量为N。针对匿名用户直接采用热度排序推荐法的时间复杂度为O(m×N);基于IP隐式反馈推荐方法的时间复杂度为O(m×k×N);基于显式反馈的时间复杂度为O(m×k×N)。
3 评价标准与实验结果
3.1 评价标准
评估推荐系统的好坏通常采用准确率(Precision)和召回率(Recall)以及两者结合的综合测度值F等方式。
(11)
(12)
(13)
其中,D(s)为推荐系统为用户u推荐的项目集合;T(s)是用户u在测试集上的项目集合。a是参数,当a=1时,Fa即是常见的F1-Measure。
3.2 实验设计及结果
为检验算法的可靠性及可用性,选择安徽省农业信息服务门户网站——安徽农网(全国优秀农业信息网,网址http://www.ahnw.cn)发布日期在2018-01-01—2018-12-31之间共计9个农业栏目的多达180万条的访问记录,通过对数据进行初步整理,提取了其中访问稳定的1500个独立IP的访问记录数据作为训练样本,将2019-01-01—2019-06-01的访问记录作为测试集,在训练集阶段主要计算各类参数值,包括:
1)各信息类别皖南、皖北的关注度系数。
2)依据公式(8)计算用户通过IP区分的基于隐性反馈行为的相似度矩阵。
在测试集上生成推荐结果,依据相似度矩阵形成推荐列表,并按当日热度系数排名分页向用户推荐新闻,与实际用户的访问数据集依据公式(11)~公式(13)计算推荐效果。
表3展示了随着推荐项目N的增大,算法的准确率和召回率的变化,当推荐量较小时,推荐准确率和召回率达到了较高水平,算法推荐效果良好;基于关注度、热度以及隐式反馈数据解决了农业信息推荐中的冷启动问题。
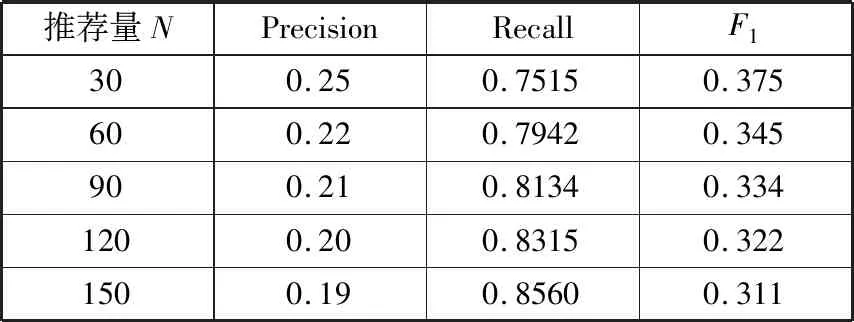
表3 算法在不同推荐量下的准确率、召回率及F1值
表4展示了本文算法在较低推荐量下与ItemCF算法准确率的比较,本文算法在准确率及召回率上都优于ItemCF算法,由于采用热度排名推荐,本文算法的首页(Top15)推荐准确率有较大提升,召回率也有一定的提高。
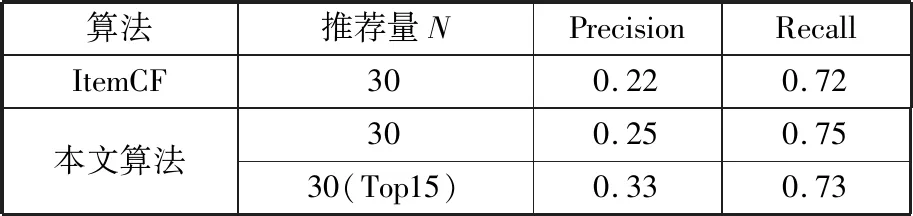
表4 本文算法与传统ItemCF算法比较
图1展示了本文算法(AHCF)即采用栏目关注度以及热度系数的推荐算法与分别只采用栏目关注度(AttentionICF)、近期热度(HotICF)推荐算法的正确率比较,采用栏目关注度即考虑农业信息的分类特征、周期性和区域性与传统推荐算法相比能较大幅度对农业新闻提升推荐准确率,集成热度系数后,推荐准确率进一步提高。

图1 本文算法与分别采用关注度、热度推荐算法以及传统ICF算法正确率比较
4 结束语
本文基于隐式、显式反馈数据等多维因素,采用基于用户行为和新闻时效性的协同过滤算法,考虑到农业信息的分类特征、周期性和区域性特征,采用热度系数及人工参数提高农业新闻推荐的针对性和时效性,在一定程度上解决了推荐算法冷启动的问题。同时在推荐时采用离线和在线相结合的方式,提高了实时推荐速度。由于农业信息推荐问题本身的复杂性,下一步还可以从农业知识图谱、农户信息采集以及扩大数据规模优化参数等方面对算法进行优化。
猜你喜欢
河北果树(2020年4期)2020-11-26
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
都市生活(2019年5期)2019-08-01
小学生学习指导(低年级)(2018年11期)2018-12-03
新闻传播(2018年14期)2018-11-13
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
现代防御技术(2016年1期)2016-06-01
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
