
复杂背景下基于深度学习的视频动作识别
2020-07-15 11:01:50潘陈听谭晓阳
计算机与现代化 2020年7期
潘陈听,谭晓阳
(1.南京航空航天大学计算机科学与技术学院,江苏 南京 211106; 2.模式分析与机器智能工业和信息化部重点实验室,江苏 南京 211106; 3.软件新技术与产业化协同创新中心,江苏 南京 211106)
0 引 言
随着近年来计算机存储量的爆炸式增长以及网络的快速发展,视频逐渐成为人们日常面对的一类数据。自2012年AlexNet提出以来,图像识别取得了很大的进展。深度学习在图像识别问题上的优异表现也带动了视频动作识别的快速发展。视频动作识别作为机器视觉领域内一个比较年轻也极具挑战性的问题,需要应用图像处理与机器学习等方面的相关知识。视频动作识别从长远来看有着极佳的商业价值,其在物联网方面被用于智能监控;在三维游戏方面被用于人机交互;在智能零售方面被用于顾客行为分析等。然而获取的视频数据通常不是理想条件下的数据,其会受到阴影、人体晃动、背景移动等各种背景因素的干扰。因此研究在复杂背景下的人体动作识别也是一个非常重要的挑战。
视频动作识别,即视频分类,与图片识别的不同之处在多帧图像所隐含的时域信息。为了利用时域信息,目前主要有双流网络、3D神经网络以及循环神经网络( Recurrent Neural Network,RNN)[1]和卷积神经网络(Convolutional Neural Network,CNN)[2]相结合3类算法。本文以双流网络为基础,采用与机器翻译领域的自注意力[3]机制类似的非局域方法[4-5],提出非局域时间段网络以及改进的混合型非局域时间段网络,用于视频分类。该方法在双流网络的基础上,通过增添非局域计算使网络能关注到更大范围的信息,而在非局域计算中融入光流信息则能使网络更精确地将注意力放在动作区域,从而增强对视频复杂静态背景的鲁棒性。此外,为了融合双流分段网络的多路判别结果,本文引入对各类动作敏感的加权组合方法,取代原有时间段网络的简单平均。实验显示,本文的模型相对于现有方法有较为明显的提升。
1 相关工作
1.1 基于传统方法的人体动作识别
传统方法将视频动作识别显式地分成特征提取、特征聚合、特征分类3个步骤。首先通过设计好的算法提取视频的底层特征,然后将提取出的特征进行编码,最后在使用PCA[6]之后使用SVM[7]和AdaBoost[8]等分类器对编码结果进行分类。
常用的底层特征包括SIFT[9]、SIFT-3D[10]、HOG[11]、HOG3D[12]、HOF[13]、MBH[14]、DT[15]、iDT[16]等。SIFT(Scale Invariant Feature Transform)通过计算各种尺度空间上找到的特征点的方向大小等信息作为视频描述。HOG(Histogram of Oriented Gradients)通过统计局部图像的梯度方向直方图作为视频特征。SIFT-3D与HOG3D分别在SIFT和HOG的基础上进行了时间维度的扩展。HOF(Histogram of Optical Flow)计算每帧图像的光流域,通过统计光流矢量与x轴之间的夹角的光流信息直方图来对视频进行描述。MBH(Motion Boundary Histogram)结合了HOG与HOF,对x轴与y轴的光流图计算HOG特征,比起前面2种有着更好的鲁棒性。DT(Dense Trajectory)在各尺度的单帧通过网格划分对特征点进行密集采样,并通过一些方法去除低效特征点,再对这些点提取上述特征。目前取得效果最好的手工特征是在DT基础上进行改进得到的iDT(improved Dense Trajectory)。与DT相比,iDT法改进了特征的正则化,优化了光流图,并在特征编码方式上进行了提升。
常用的对特征进行聚合的方法有BoVW[17]、FV[18]、VLAD[19]等。BoVW(Bag-of-Visual Words)使用K-means对特征进行聚类,并用距离最近的聚类中心取代特征点,该方法信息损失较多。FV(Fisher Vector)使用GMM方法对特征点进行建模,使用所有聚类中心的线性组合来作为该特征点的表示,准确度较高,计算量大,在建模过程中也损失了部分信息。VLAD(Vector of Locally Aggregated Descriptor)计算特征点到聚类中心的残差,并将落在相同聚类中心的残差累加求和再进行归一化后得到一个VLAD向量。
1.2 基于深度学习的人体动作识别
深度学习在图像相关任务上相比于传统方法取得了重大突破。视频作为图像在时间域上的扩展,近年来也大量使用深度学习的方法来进行处理分析。视频与图像最大的不同之处在于其内在包含了除长度、宽度以及通道外的第四维度——时间维度的信息,一个好的视频动作识别方法必然能充分利用时间域的信息。
双流神经网络(Two-Stream ConvNet)[20]在动作识别领域是一类很常用的方法,该方法简单却有相当优异的效果。双流网络顾名思义由时间流与空间流2路网络组成,空间流网络将视频单帧或堆叠帧输入卷积网络学习空间域上的视频信息,时间流网络将光流图以多通道的形式输入卷积网络学习时间域上的视频信息。2路网络各自对视频输出属于各类的概率,最后平均2个概率向量得到最终的分类结果。改进的双流网络[21]对空间流与时间流网络如何融合以及何时融合进行了探索。其认为将特定区域的空间特征图映射到时间特征图的对应区域对于融合效果很有帮助,因此需要在网络早期就进行融合,而不能只是在最后才融合双流信息,这样会失去很多有用信息。除此之外也有方法将音频信息也作为单独的一路网络,但终究没有成为主流。双流卷积网络以图像识别的2D网络作为基础架构,因此其可以如图像识别一样在ImageNet上进行预训练来提高训练效果,减少训练时间。Wang等人[22]结合了经典iDT手工特征和双流深度特征,提出了轨迹池化网络(TDD)。TDD用双流网络来学习卷积特征,然后用轨迹池化的方法来融合这些卷积特征,最后用SVM分类。后续许多方法都通过结合iDT达到了最佳效果。
3D神经网络[23]是另一类很常用的方法。随着近年来计算力的进一步提升以及数据集规模的进一步增加,3D神经网络发展迅速,从最开始的不如传统方法到如今与双流网络并驾齐驱。3D网络在设计之初就是一种端到端的网络架构,它可以直接将视频作为输入,并输出最终分类类别。由于网络结构复杂,3D网络需要很大的数据集才能得到较好的结果,并且网络层数不能过深。Sun等人[24]将“3D空间时间学习”分解为“2D空间学习”和“1D时间学习”,提出了空时分解卷积网络。文献[25-27]均在此基础上进行了改进。I3D[28]将预训练的2D网络的参数填充为3D并采取双流结构,每一路都是3D网络,而不像传统的双流网络是2D网络。结合了双流网络和3D神经网络的优点,I3D在主流的数据集上都获得了当前最优异的成绩。
RNN可以处理时域信息,因此将CNN与RNN相结合也可以学习视频中时间维度的信息。LSTM(Long Short-Term Memory)[29]和GRU(Gated Recurrent Unit)[30]是RNN中2类常用的变种架构。它的基本思想是用RNN对CNN最后一层在时间轴上进行整合。这里,它没有用CNN全连接层后的最后特征进行融合,是因为全连接层后的高层特征进行池化已经丢失了空间特征在时间轴上的信息。目前效果最好的此类方法为长时递归卷积神经网络(Long-term Recurrent Convolutional Network, LRCN)[31]。
2 网络模型
本章将详细介绍带有注意力机制的时间段网络的设计原理和实现细节,具体地展示该网络模型是怎样对复杂背景下的人体动作进行有效识别。
2.1 复杂背景
本文对“复杂背景”一词的具体含义没有作特别限定,仅用于泛指非实验室控制条件下输入视频可能出现的各种噪声,可能包括人体晃动和背景变化等,这些因素可对传统视频分类算法造成巨大干扰。尽管可以通过对人体建模或对特定场景下的背景建模的方式来解决上述问题,但本文的目的在于尽量不假定其他先验知识和增加额外计算及建模代价的前提下,从深度网络结构设计的角度来寻求增强系统对上述一般性干扰的鲁棒性。


图1 本文方法能够处理的视频序列示例
2.2 非局域时间段网络
基于视频的动作识别任务为给定一个视频X,目标为学习一个分类器f,使得当f以X为输入时,将其映射为其属于每类动作的概率向量S∈Rm(m为动作类别数):
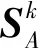
时间段网络是双流神经网络的改进版本,其优点是排除了连续帧带来的大量冗余信息,节省了大量训练时间。然而由于切片帧的时间跨度太长,以及采样自带的随机性,需要关注的图像区域变化较大,使之无法真正聚焦于目标动作发生的区域。为了使模型将识别重点放在目标区域而忽略视频中的复杂背景,本文引入了图像处理中经典的非局域均值法。该方法与近年来在机器翻译领域提出的自注意力有着本质上的联系。
自注意力的想法来自于人类的注意力机制,即人类在观察某个场景时一般不会对每个部分同等对待,而是根据兴趣和先验知识重点观察特定的部分。在计算机视觉中,自注意力机制往往是通过将同一图像中的所有位置联系起来进行加权平均的方式实现。在本文中,使用非局域方法通过点相关矩阵F对特征矩阵G进行加权平均,与自注意力模型类似,有效提高了模型对复杂背景的鲁棒性。
容易想到,一幅图片中各个像素点之间存在关联,单纯的卷积操作一般是3×3,这样的卷积能获取的信息是很局部的,为了增加感受野,普遍采用的操作是叠加这样的特征提取层逐渐地获取全局特征,但是这样的操作带来的问题是网络结构的复杂化。而非局域方法可以在一定程度上解决这个问题。计算过程如下:
(1)
C(xi)=∑jexp (θ(xi)T·φ(xj))
(2)
zi=Wzyi+xi
(3)
这里i和j为图像的位置索引,C为归一化参数,整个计算过程不改变其规格。值得指出的是,非局域机制式(1)可以写为如下矩阵形式:
(4)
其中,C为规整化因子(见式(2)),F为点相关矩阵,G(x)为按位置排列的特征矩阵。这揭示出非局部网络可视为一种逐点(point-wise)的图卷积网络[34],其核心在于设计卷积核F(本文称非局部核矩阵)。在原始非局部网络中,没有考虑从视频信息中衍生的多模态信息(如光流图),为此本文提出一种新的非局部核矩阵构造方法,以进一步融合和丰富视频外观表示的动态性。本文将该模块插入已有的时间段网络形成了新的非局域时间段网络,如图2所示。本文将在后面对该网络进行进一步的描述。
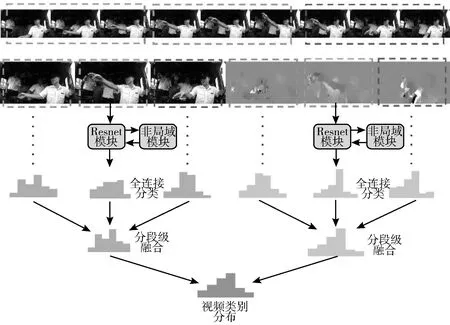
图2 非局域时间段网络
2.3 多路网络结果合成
在时间段网络中,文献[32]简单地使用平均法对双流网络k个阶段共2k个m×1概率向量进行合成。可以发现,同一个动作的不同阶段对该动作的判定的贡献值是不同的,而同流(空间流或时间流)对不同动作判定的贡献值也是不同的。简单的平均法无法有效利用这些信息,本文中采用可学习的方式来进一步融合各视频段的分类结果。具体而言,每个分段的预测可表示为2个m×1概率向量(分别对应外观和光流信息),其中m为类别数。因此,对k个视频段,共需融合2k个概率向量的分类结果。为此为每个类别分别学习一个大小2k×1的卷积核,用于表示每个概率向量对该类别判别的权重。本文采用交叉熵为损失函数,并将其与网络其余部分进行端到端微调。
2.4 混合型非局域时间段网络
在上述非局域时间段网络中,事实上考虑了本文关注的矩形区域中的所有点的相关性,而在实际中动作范围往往只占该矩形区域的一部分。为了使本文的模型进一步聚焦于真正有效的区域,考虑使用光流图的点相关性矩阵HW×HW替换原始图像的点相关性矩阵。光流图可简单地理解为前后2帧图像的变化信息,变化越剧烈的区域取值越高,变化小的区域则取值趋向0。点相关矩阵更改为:
(5)
其中x′i为xi在光流图中的对应点的取值,其余操作不加变动,如图3所示。
3 实验及结果分析
3.1 数据集和实现细节
为了验证本文模型的性能,本文构造了一个列车司机确认呼唤标准手势(TDAP)数据集。它包含6个手势动作类别以及684个剪切好的视频片段。本文使用随机梯度下降(SGD)算法来更新网络参数,动量因子设置为0.9,批大小(batch size)设置为16。本文的网络在ImageNet上进行预训练。空间流网络的学习率初始值为0.001,每迭代100次减小到原来的1/10,整个训练过程迭代250次。时间流网络的学习率初始值为0.001,每迭代150次减小到原来的1/10,整个训练过程迭代350次。考虑到数据增广,本文也使用了抖动、水平翻转、角裁剪等技术。对于光流的抽取本文采用OpenCV的TVL1光流算法[35]。在预训练后,除了初次训练,本文将冻结所有批正则化(batch normalization)[36]层的均值方差参数。同时,本文将在全局池化(pooling)层后增加一个舍弃(dropout)[37]层来减小过拟合。空间流网络的舍弃(dropout)率为0.8,时间流网络的舍弃(dropout)率为0.7。实验设备为一块TITAN X GPU,整个网络的训练时间在分3段的情况下,空间流网络需要2 h,时间流网络需要12 h。
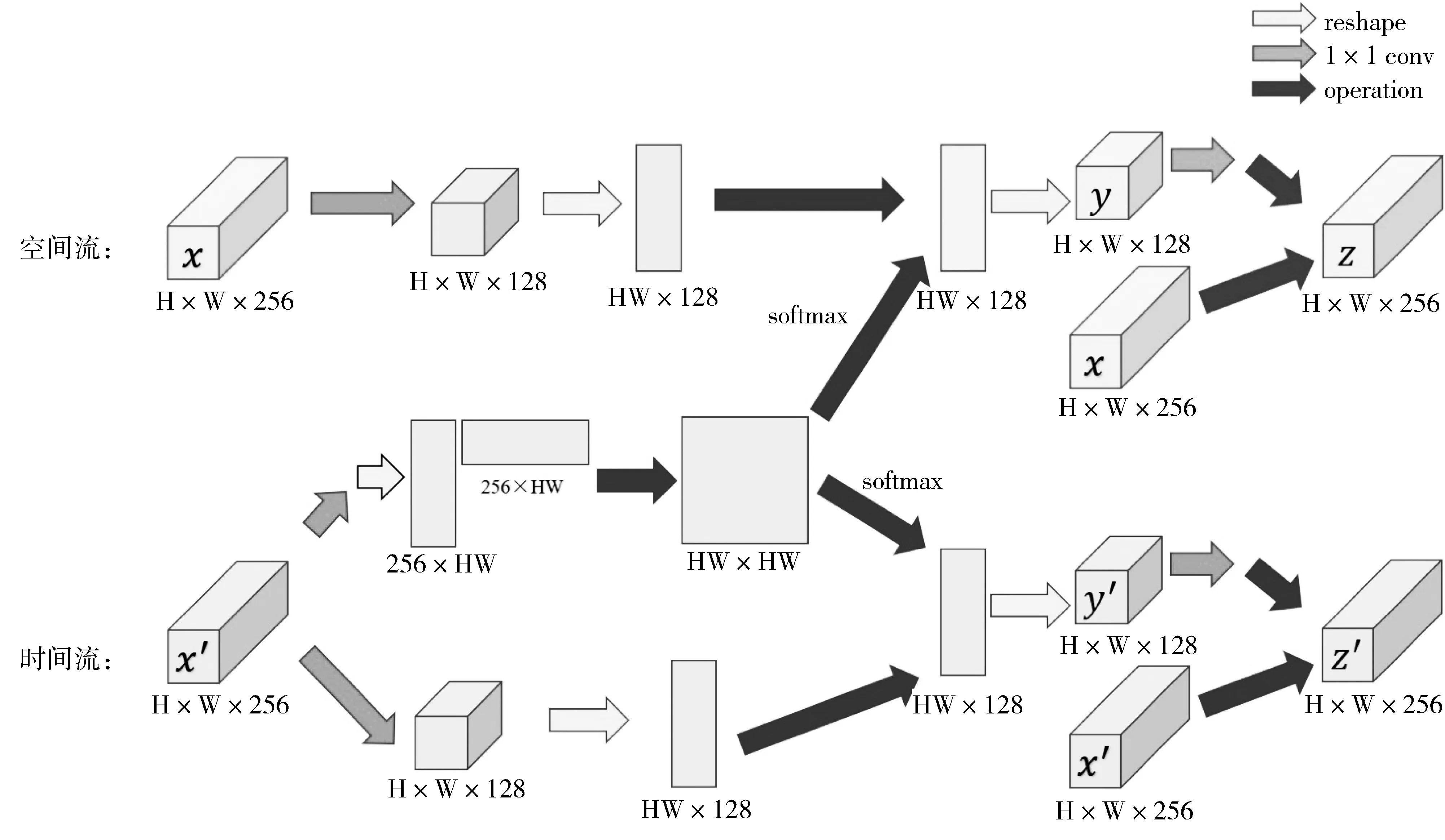
图3 混合型非局域模块
3.2 对比实验
表1比较了将非局域模块加入ResNet的不同阶段的效果。非局域模块被插入到某个阶段的最后一个残差块之前。从表1可以看出,插入res2、res3以及res4的效果是相似的,而插入res5的效果偏低。可能的解释是res5的空间规模很小所以它提供的空间信息不充分。
表2比较了添加更多非局域模块的结果。本文分别尝试在ResNet-50网络中添加1个模块(res4)、2个模块(res3和res4)、4个模块(每层1个)以及8个模块(每层2个)。在ResNet-101中本文也将其添加到相应的残差块。从表2可以看出并不是添加越多的非局域模块越好,可能的解释是数据量太少以及网络结构过深导致其过拟合。
表3比较了不同的时间段数量对网络性能的影响。本文在ResNet-50上添加4个模块的基础上分别使用3、5和7个时间切片。从表3可以看出,时间段分得更多可以导致更高的精度,在分成5个时间段的情况下,ResNet-50可以取得与分成3个时间段的ResNet-101一样的性能,而分成7个时间段的话则可以取得更高的性能。然而在分成5个时间段时,训练时间要增加2/3,在分成7个时间段的情况下训练时间更是要增加1倍。而本文添加的非局域模块所导致的额外训练时间相当之少(空间流网络增加几分钟,时间流网络增加近1 h)与增加时间段数量导致的负担相比基本可以忽略不计。
从表1~表3可以发现,使用加权平均可以比简单平均得到更好的结果。而使用混合模型则能得到比简单添加非局域模块更好的性能,但在此基础上再融合2路网络效果则几乎没有提升,本文猜测原因是在替换点相关矩阵的时候空间流网络已经融合了时间流的信息,所以在最后的融合时相当于没有增加有用信息。
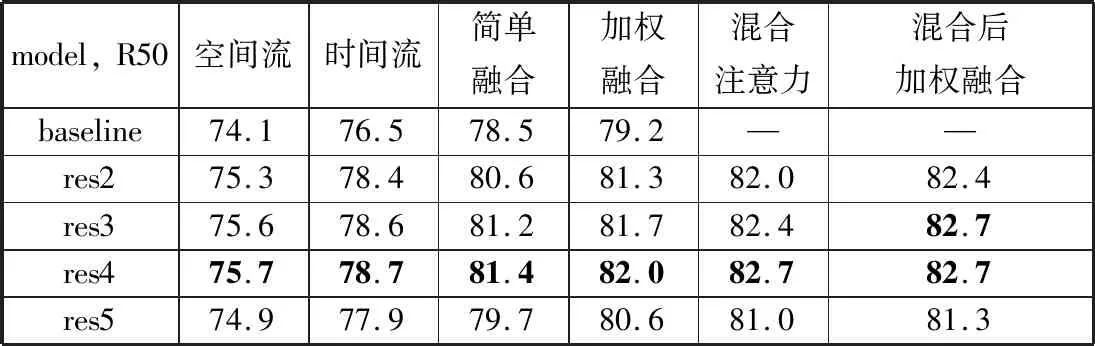
表1 不同阶段添加非局域模块的效果比较
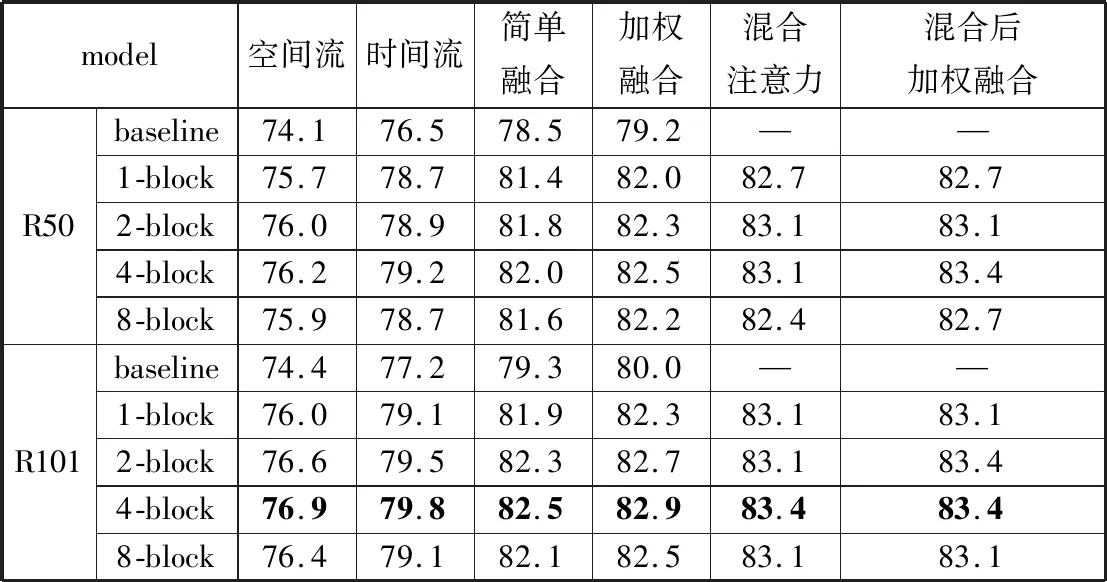
表2 不同深度的非局域网络效果比较
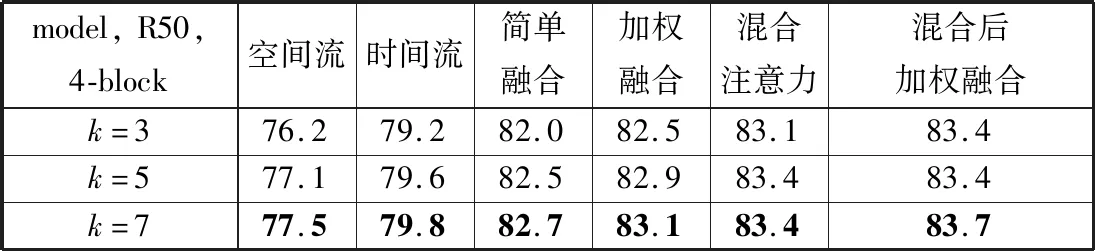
表3 时间段数不同的非局域网络效果比较
3.3 与先进模型对比
在图4中,将本文模型与近2年提出的其他模型(P3D[27]、I3D[28]、Non-local C3D[5]、R(2+1)D[25])进行了对比。这些模型采用各自的方法对时空间信息进行融合:P3D设计了3种模块将3×3×3卷积分解为1×3×3卷积和3×1×1卷积,前者获取时间信息,后者获取空间信息;I3D将2路网络都设置为C3D网络,各自同时获取时空间信息,最后将2路网络进行融合;R(2+1)D与P3D相似,但在每一层中都使用相同的非bottleneck模块;Non-local C3D将非局域模块插入C3D网络,相当于将自注意力机制引入3D卷积网络。本文将github上以上模型的源代码在本文的TDAP数据集上进行了实验,从图4可以看出本文模型比其他的模型效果更佳。3D卷积网络的机制决定了其在中小规模数据集上的效果不会太好,而Non-local C3D正是由于加入了带有注意力机制的非局域模块使其优于其他模型。本文模型在双流网络中插入改进的非局域模块,可以充分发挥双流网络在中小规模数据集的优越性以及注意力机制对环境的鲁棒性。
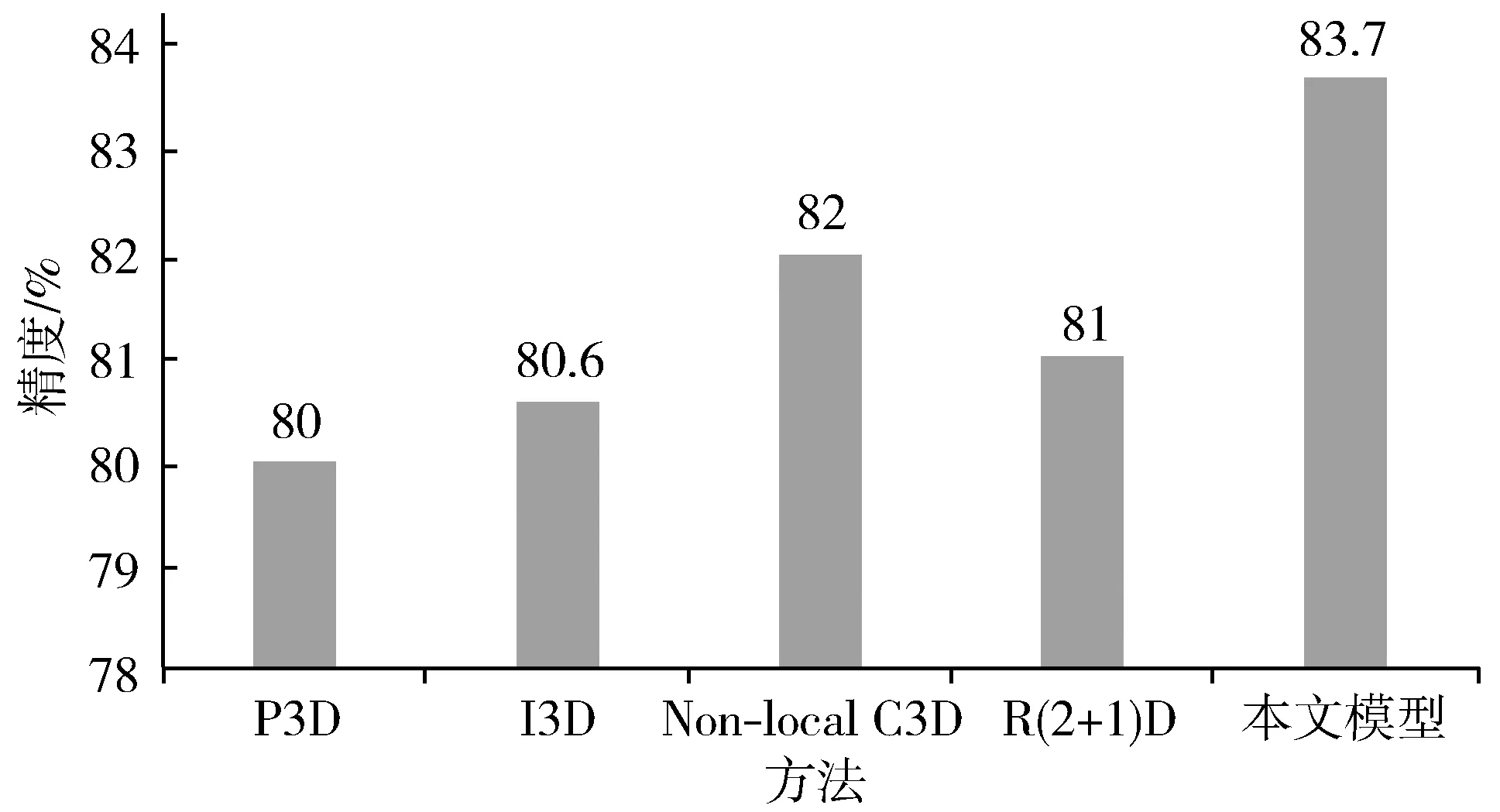
图4 与先进方法的对比
3.4 大样本数据集
为验证模型的鲁棒性和泛化性能,本文在UCF101数据集上增加了实验。UCF101是从YouTube视频网站收集的包含13320段短视频,分为101种动作的数据集。它主要包含人和物体交互、只有肢体动作、人与人交互、演奏音乐器材、各类运动等5大类动作。本文直接在第4阶段插入非局域模块,实验结果如表4所示。实验结果显示本文的模型即使在大样本数据集上依然有比较好的效果。
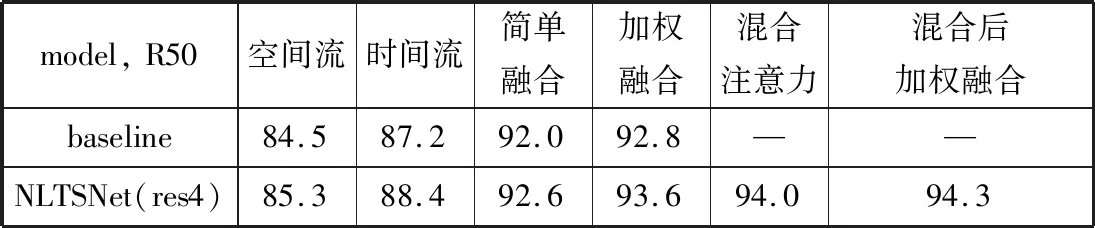
表4 在UCF101数据集上进行实验的效果
4 结束语
本文针对实际应用中视频动作识别的复杂背景,引入计算机视觉中经典的非局域均值法,提出了非局域时间段网络和混合型非局域时间段网络,旨在减弱背景对目标动作识别的干扰,并分析了其与机器翻译领域的自注意力方法的内在联系。为了验证模型的性能,本文构造了TDAP数据集并在该数据集上进行了相关实验。实验结果表明本文的模型拥有较好的性能并且产生极少的额外训练时间。本文提出的模型输入为已剪切好的视频片段,今后笔者将针对未剪切过的视频进行进一步的研究。
猜你喜欢
中小学校长(2022年7期)2022-08-19 01:36:36
冶金设备(2020年2期)2020-12-28 00:15:22
今日农业(2020年13期)2020-08-24 07:35:24
高原山地气象研究(2020年3期)2020-07-16 07:53:58
中小学校长(2019年10期)2019-11-07 04:56:38
电子测试(2018年18期)2018-11-14 02:30:34
意林(2017年8期)2017-05-02 17:40:37
中国医学装备(2015年10期)2015-12-29 12:00:24
医学研究杂志(2015年5期)2015-06-10 06:43:26
电测与仪表(2015年7期)2015-04-09 11:39:50
