
心血管疾病并发症与虚弱症关联模式研究
2020-07-15 11:01冯云霞韩正亮薛蓉蓉
计算机与现代化 2020年7期
冯云霞,韩正亮,薛蓉蓉,宋 波
(青岛科技大学信息科学技术学院,山东 青岛 266061)
0 引 言
我国心血管疾病患者的数量已居世界首位,是危害中老年人健康的头号杀手[1]。心血管疾病具有“发病率高、致残率高、复发率高、死亡率高、并发症多”的特点,且患者多会伴有高血压、糖尿病、脑梗等多种并发症[2]。各种并发症间相互促进,造成血液循环系统的病变累积,影响对治疗策略的耐受力,最终导致身体素质水平的下降,引发虚弱症。
虚弱是指随着年龄的增长,躯体功能、心理精神等方面下降到接近健康阈值附近的一种状态[3]。在临床中常用作评价健康状况的基本指标,其主要症状包括合成代谢减慢、呼吸系统损伤、循环障碍、骨骼肌肉的缺失等躯体功能缺陷,以及不良的精神心理和社会保障等[4]。根据各年龄段所表现出的步速、握力、体重等表面特征的减退进行3级划分,分别为轻度虚弱、中度虚弱和重度虚弱。
虚弱对身体的危害具有潜藏性、持续性和积累性。其在降低患者健康水平的同时,反过来又促使患者易受慢性病及并发症的影响。为安全有效地治愈或控制虚弱症状,Uchmanowicz等人[5]通过研究虚弱与急性症状之间的关联关系后指出,提取部分高风险疾病不良后果的相关规则有利于医疗决策的制定。Abbasi等人[6]通过研究虚弱症状之间的关联性,用于医护人员对患者的临床护理,极大提升了患者护理质量。Curran等人[7]通过研究不同疾病的疫苗注射对虚弱症状的影响关系,有利于患者治疗安全性的提升。Hilmer等人[8]通过研究虚弱与身体系统器官功能之间的关联关系,获得身体症状对外部因素反应的规则知识,有利于提升药物研究的针对性。Simcox等人[9]通过研究虚弱程度与疾病死亡率、危险程度和并发症发病率之间的关联关系,对降低疾病对身体的危害,提供了一定的数据支撑。除此之外,高效准确地挖掘出心血管疾病并发症与患者虚弱程度之间的规则知识,可优化临床诊疗方案,降低患者治疗风险[10-11],同时有利于疾病辅助治疗策略的制定,以及实现患者诊治措施后并发症发生情况的实时预警[12]。
若能从大量患者信息中,发现心血管疾病并发症与虚弱症之间的知识和规则,用于疾病诊断和治疗,可极大地优化临床决策的制定,有利于并发症的防治,降低治疗风险。利用心血管疾病并发症与不同程度虚弱症之间的关联规则,可帮助医生根据患者病情制定更有针对性的治疗方案,为患者治疗模式的选择提供一定的数据支撑。通过疾病之间的关联规则,有利于治疗效果的反馈,防止部分不良后果的发生。通过潜在的规则所反映的疾病信息,有利于药物的研发,提升疾病治疗的针对性。因此,准确地提取心血管疾病并发症与虚弱症之间潜在的关联规则,对国内心血管疾病治疗的发展和提升医疗质量的水平具有推动意义。
最基础的关联规则提取算法为Apriori算法和FP-growth算法,其它关联规则提取算法都是根据待解决问题的需求,而对基础算法进行的改进。相比较这2种最基础的算法,FP-growth算法较Apriori算法能更为高效地发现频繁项集,但FP-growth实现比较困难,主要适用于标称型数据,若用于数据类型复杂的医疗数据会导致性能下降,且不利于研究的进一步扩展;同时,研究疾病间的关联规则,最关注的是获得有用的规则信息,而FP-growth算法主要依靠忽视规则而提高挖掘效率,与问题研究的需求不符。综上,Apriori算法在疾病规则生成的研究中要比FP-growth算法更为适用,因此本文以Apriori算法为基础[13]研究心血管疾病并发症与虚弱症之间的关联规则。
Apriori算法核心思想是通过逐层搜索候选项集的出现频率而查找某种联系,但将其应用于实际研究中仍存在不足。为解决存在的问题,诸多学者针对算法模型的运行效率[14-16]、存储方式[17-19]和剪枝策略[20-22]做出改进,但并未落实到实际问题的解决上。主要因为在真实患者数据的应用中,易造成规则质量差、提取效率低等问题。根据问题可总结为2个方面的原因:1)疾病之间的关联规则较为复杂,存在部分具有误导性的规则,降低了规则的可靠度;2)患者数据量庞大,但大部分数据质量较低,存在冗杂、缺失等问题。为能高效准确地提取心血管疾病并发症与虚弱症之间的关联关系,本文提出HI-Apriori(Base on Hash Table and Improved Rate of Apriori)算法对患者数据进行挖掘分析。HI-Apriori算法引入Hash表和提升率,通过提升率标记候选项集中的不可靠项集并进行剪枝,然后根据可靠项集建立基于Hash表的数据存储结构。该算法可减少数据遍历的规模,并能够去除价值不高的规则项集,具有高效准确、节省运算时间空间开销的优点。
1 基于HI-Apriori算法的关联规则提取模型
在心血管疾病并发症与虚弱症相关性复杂的情况下,HI-Apriori算法利用提升率准确选取可靠的候选项集,并用以辅助建立Hash表,减少数据对存储空间的消耗以及对数据库的扫描,最后再提取心血管疾病并发症与虚弱症之间的关联关系。
1.1 基于提升率的规则剪枝
疾病关联规则提取的可靠性问题,主要体现在数据的相关度复杂。如在2400条心血管患者数据中,中度虚弱的患者约为1300人,具有心悸症状的患者约为1700人,同时包含2种症状的患者约为800人。根据传统算法设置最小支持度为30%,最小置信度60%。可得同时患有2种症状患者的支持度为:800/2400=30%,置信度为:800/1300=62%。所得支持度和置信度满足设置条件,可总结为中度虚弱的患者患有心悸的概率较大。但实际上,患者数据中包含心悸的患者约为:1700/2400=71%,去除其中中度虚弱患者的数据后,包含心悸患者的概率约为:(1700-800)/(2400-1300)=82%,远高于包含中度虚弱患者数据中包含心悸患者的概率。由此可得:心血管患者中,中度虚弱患者患有心悸症状的概率较小。
针对上述问题,传统算法中加入了数据相关度这一关键指标,但在计算心血管疾病并发症与虚弱症的相关度时,仍面临信息丢失的问题。主要原因是由算法在计算数据相关度的过程中所导致。在数据相关度计算的过程中,传统算法所采用的描述方法为作用度或χ2统计检验。χ2统计检验不能区分数据正负相关关系,因此容易造成规则提取的误差;而对于作用度,其计算结果在一个开区间,会造成一定概率信息的损失,不易理解和使用。
因此,HI-Apriori算法在计算数据相关度的过程中,将提升率[23]Up(A,B)这一指标作为规则可靠性依据,如公式(1)所示。
(1)

1.2 基于Hash表的存储结构
Hash表的主要优点是可以显著降低数据存储和遍历的消耗。在研究心血管疾病并发症与虚弱症之间存在的关联规则时,Apriori算法需要根据生成的候选项集多次扫描患者数据集,对应的时间复杂度为O(kN)。其中k为生成的候选项集的数量,N为患者数据集的总量,随着数据量的增加,将导致不可忽视的时间开销。而将Hash表引入Apriori算法中,只需要遍历一次完整的患者数据集,就可以基于疾病症状建立候选项集表,其对应的时间复杂度为O(N)。而基于支持度的剪枝计算可以基于该表直接操作,对比传统Apriori算法明显降低了时间的开销。同时该表结合提升率对不可靠项集的剪枝,节省了不可靠项集所需要占用的存储空间,节省的空间量为O(b),其中b是不可靠项集的数量。综上可得,Hash表的引入对HI-Apriori算法挖掘效率的提升是显著的。
为能建立Hash表,可根据患者数据所得到的虚弱指标,作为该患者的标签,用于提取与这一虚弱程度相关性大的规则。因为每个患者在数据中仅会表现为某一确定的虚弱程度,为便于说明,本文以轻度虚弱患者为例建立Hash表。中度虚弱和重度虚弱患者的Hash表建立方法一致,只是在建立2-项集Hash表时需根据虚弱程度的不同分开讨论。
对12条患者数据建立Hash表,其中3人为轻度虚弱,对其添加“X”标记,9人为其它虚弱,此处为方便说明不对其他程度虚弱作标记,如表1所示。患者中总共包含6种症状,分别为{S1,S2,S3,S4,S5,S6}。设置最小支持度为25%,则对应最小支持计数取整后为3。
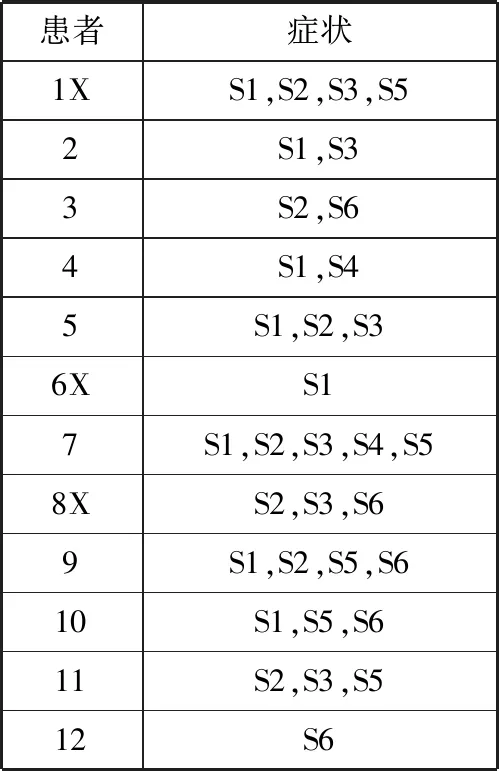
表1 患者与症状
通过对数据库进行遍历,将表1转换为Hash表,得到1-项集症状Hash表,如表2所示。
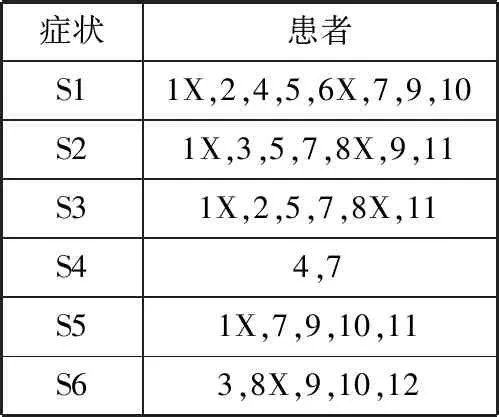
表2 1-项集症状Hash表
根据最小支持计数,需要将病症S4剪枝。之后再对每一个症状利用提升率进行筛选。如上表求轻度虚弱相对于病症S1时的提升率Up(X,S1),根据公式(1)可得值为1,表示轻度虚弱与病症S1相互独立,在建立轻度虚弱2-项集Hash表时需要舍弃。同理可得轻度虚弱相对病症S2、S3、S5和S6的提升率依次为1.2、1.5、0.75和0.75。若计算其它虚弱程度所得提升率不为1时,在下一步建立仍需要考虑分析。因此,由表2可得频繁1-项集症状Hash表,如表3所示。
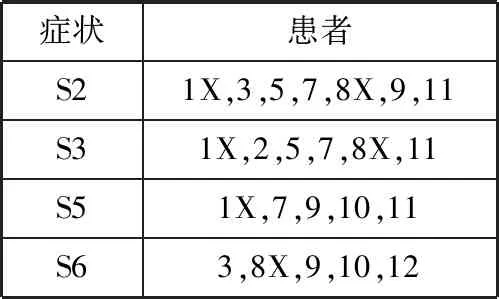
表3 频繁1-项集症状Hash表
对于建立k-项集(k=2,3,4,…),需要将得到的上一项频繁集中的症状两两组合,得到新的规则,并提取组合症状中相交的患者作为新项集的患者。如将频繁1-项集症状Hash表中的症状两两组合,获得新的2-项集的症状,并根据组合症状的患者,取交集后作为新项集的患者,如表4所示。
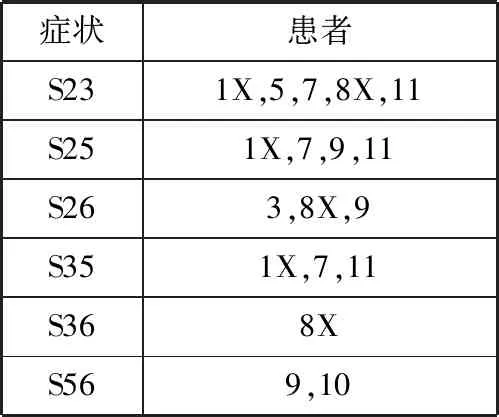
表4 2-项集症状Hash表
同理,根据最小支持数对S36和S56进行剪枝。之后分别计算轻度虚弱相对于病症S23、S25、S26和S35的提升率分别为2、1、1.5和1.5。因Up(X,S25)值为1,可得轻度虚弱与症状S2合并S5互相独立。由此可得频繁2-项集症状Hash表,如表5所示。
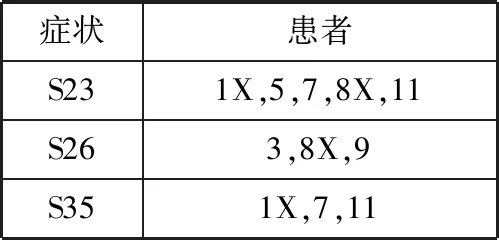
表5 频繁2-项集症状Hash表
因此,根据上述方法可分别建立轻度虚弱、中度虚弱和重度虚弱的相关频繁k-项集Hash表,用以提取心血管疾病并发症与虚弱程度之间的关联关系。利用HI-Apriori算法可将患者数据转换成Hash表存储,仅需要对整个数据遍历一次。在计算候选k-项集(k=2,3,4,…)时也只需要扫描上一频繁项集Hash表中的症状集即可,相较于传统Apriori算法,极大地减少了数据遍历的次数,对算法性能的提升效果显著。
2 算法性能验证
为验证HI-Apriori算法的性能,以当地某三甲医院中医病区患者的电子病历记录为测试数据集,其中有效病历数据2114条,包括轻度虚弱632条,中度虚弱1286条,重度虚弱196条。其中症状数据主要包括心悸、心力衰竭、咳嗽、乏力、口干、胸闷、头晕等;并发症数据包括脑梗、高血脂、高血压、糖尿病、冠心病等疾病。
2.1 实验结果及分析
比较HI-Apriori算法与传统Apriori算法的效率,主要比较在同一支持度和同一置信度下生成规则的时间量。为充分比较二者的效率,可固定置信度,设置不同的支持度进行效率比较;或固定支持度,设定不同的置信度进行效率比较。二者在比较效果上一致。本文通过固定置信度为10%,并分别选取最小支持度0.1%、1%、10%和30%进行实验,对应生成的规则量级为千位级、百位级、十位级、个位级,其挖掘时间如表6所示。
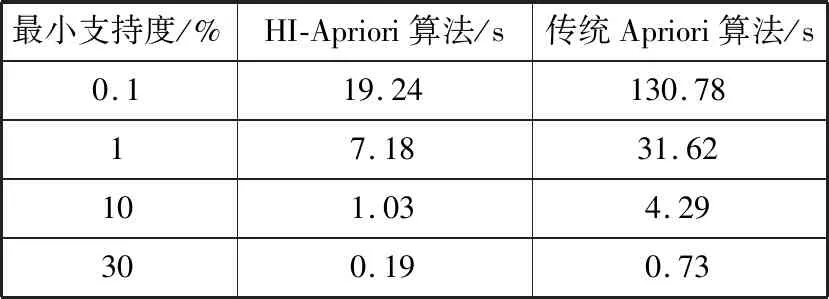
表6 算法时间效率对照表
由表6结果可得,HI-Apriori算法运行时间明显优于传统Apriori算法。随支持度的提升使HI-Apriori算法优势降低,但在计算运行方面,HI-Apriori算法提升至少约60%的效率。
在患者数据存储方面,通过剪枝策略可节省部分空间开销。即每次通过患者症状所生成的新一级项集症状Hash表,可利用基于支持度的剪枝将不频繁项集去除,如项集{心悸,糖尿病}、{口干、胸闷}等。因包含不频繁项集的超集也是不频繁的,所以该不频繁项集的剪枝,可避免下一级Hash表生成包含该不频繁项集的超集,有利于节省存储空间。再利用基于提升率的剪枝可将不可靠项集去除,如项集{咳嗽,脑梗}、{轻度虚弱,咳嗽}等,因提升率计算只考虑患有该项集症状的患者数量与总患者数量之间的关系,提前剪枝可节省下一级Hash表的存储空间并降低计算量。通过2种剪枝策略获得最终有价值的项集,在HI-Apriori算法中记录的部分剪枝项集和最终获得的项集如图1所示。
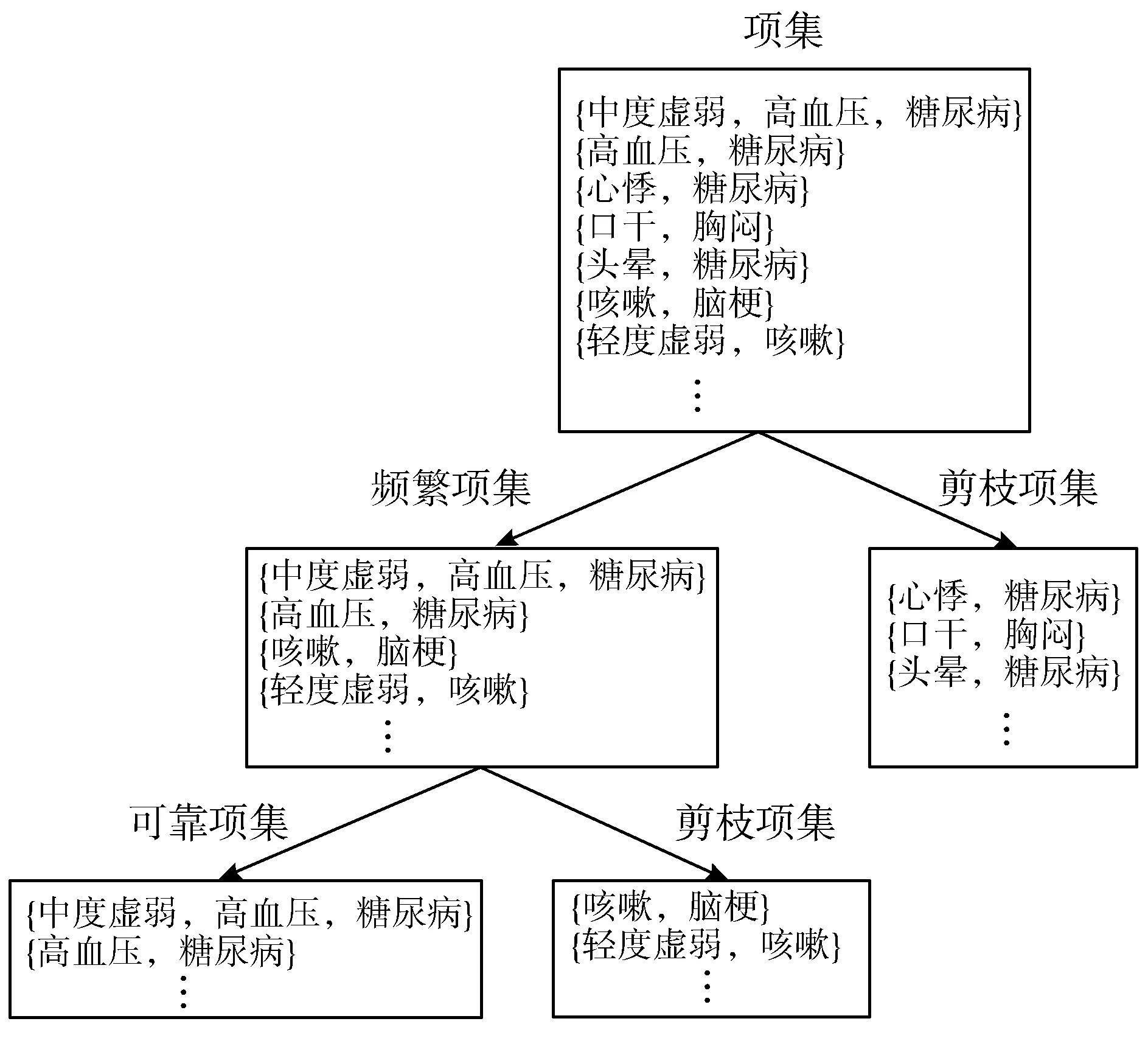
图1 HI-Apriori算法剪枝项集累计记录树状图
2.2 心血管疾病并发症与虚弱症关联度实验结果
根据心血管疾病并发症与不同程度虚弱症之间的关联关系,提取价值较高的规则,如表7所示。
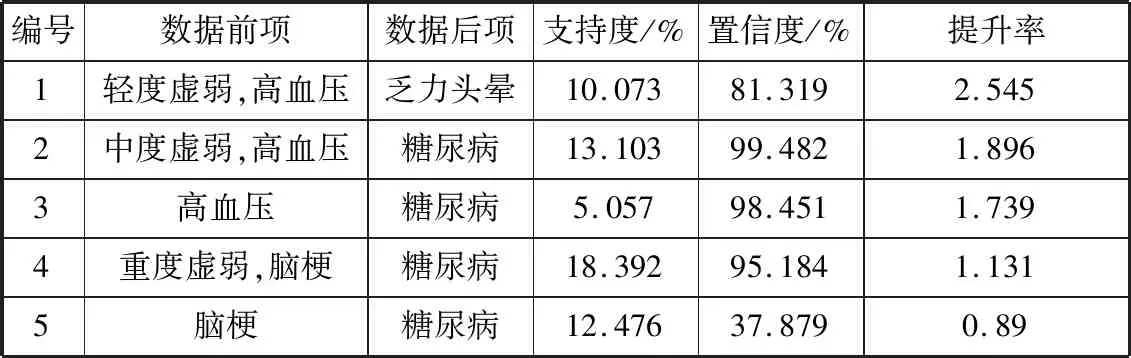
表7 心血管疾病并发症与虚弱症关联规则挖掘结果
由表7关联规则挖掘结果可得出以下结论:
1)由规则1可知高血压合并轻度虚弱的患者会出现乏力、头晕的症状,该规则的支持度达10.073%,置信度达81.319%。说明患有高血压的轻度虚弱患者,导致乏力、头晕症状的可能性为10.073%,而这种情况的发生概率为81.319%,且高血压合并轻度虚弱一定概率会促进乏力、头晕的症状发生。
2)由规则2和规则3可知高血压合并中度虚弱的患者可能引发糖尿病,该规则的支持度达13.103%,置信度达99.482%。说明患有高血压的中度虚弱患者,引发糖尿病的可能性为13.103%,而这种情况的发生概率为99.482%,且高血压合并中度虚弱一定概率会引发糖尿病。对比非虚弱的高血压患者,处于中度虚弱的高血压患者患有糖尿病的概率约为非虚弱高血压患者的2.6倍。
3)由规则4和规则5可知脑梗合并重度虚弱的患者可能引发糖尿病,该规则的支持度达18.392%,置信度达95.184%。说明患有脑梗的重度虚弱患者,导致糖尿病的可能性为18.392%,而这种情况的发生概率为95.184%,且脑梗合并重度虚弱一定概率会引发糖尿病。对比非虚弱的脑梗患者,处于重度虚弱的脑梗患者患有糖尿病的概率约为非虚弱脑梗患者的1.5倍。
3 结束语
高效准确地提取心血管疾病并发症与虚弱症之间的关联规则,有利于医生制定临床决策,辅助患者疾病的治疗。本文基于心血管疾病并发症与虚弱症患者数据的特点,针对传统Apriori算法消耗大量空间时间生成不可靠候选项集的问题进行改进,提出了基于Hash表和提升率的HI-Apriori算法。该算法可降低不可靠项集的产生,减少运算过程中空间和时间的消耗,并通过患者电子病历数据实验和测试,可有效提取心血管疾病并发症与虚弱症之间的关联关系,对虚弱和心血管疾病的研究提供了一定的技术支持。
但本文所得结果仍具有一定的局限性,主要原因为心血管疾病病因关系复杂,易受环境的影响而变化,导致实验所用的患者数据缺乏广域性。因此,本文提出的算法并不能提升数据的质量。为解决该问题,笔者将进一步研究在广域下,心血管疾病并发症与虚弱症之间的关联关系。
猜你喜欢
保健医苑(2022年5期)2022-06-10
新世纪智能(数学备考)(2021年9期)2021-11-24
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
当代陕西(2019年15期)2019-09-02
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
学苑创造·A版(2018年11期)2018-02-01
天津诗人(2017年2期)2017-03-16
读者(2017年5期)2017-02-15
