
基于LSTM网络的语音服务质检推荐技术
2020-07-15 11:02:16郭晓芸王宗伟
计算机与现代化 2020年7期
武 鹏,郭晓芸,陈 鹏,王宗伟,曹 璐,金 鹏
(1.国家电网有限公司客户服务中心,天津 300306; 2.北京中电普华信息技术有限公司,北京 100031)
0 引 言
国家电网公司95598客户服务中心于2013年11月完成了下属27个省(市)电力公司的全部客户服务业务的集中运营,为客户提供全天候故障报修、资讯查询、投诉、举报、意见、建议、表扬等服务[1]。与其他客户和企业之间的沟通方式相比,语音服务提供了75%~90%的用户体验[2],具有不可取代的便捷性、信息丰富性,能够更加直接地传达双方意图。调查显示,一个具有10个座席的呼叫中心一天的话务量是5000通电话,话音量约为500 h[3]。面对全国范围内每天产生的大量话务、工单,全面保障优质服务水平十分重要。
语音服务质检工作对于95598客户服务中心服务质量的提高能够起到重要的作用。质检是客户服务中心工作中重要的一环,通过获取话务录音等数据对95598客服人员语音服务进行检查和评定,能够监控服务质量,提升客户的满意度,最大限度地减少投诉的发生[4]。然而要对95598客服中心全部话务和工单进行人工质检是一项费时耗力的工作,目前的质检主要以人工抽样的方式进行[5],这导致质检样本代表性差,检验准确性和质检效率过低[6]。
针对以上问题,近年来国内外学者进行了相关研究。Choi[7]验证了客服中心坐席相关属性对服务质量的影响。Korfiatis等人[8]采用结构主体模型利用非结构化数据研究文字评论并应用于航空公司服务质量评估。Liu等人[9]使用声音特征建立一种新颖的客户满意度分析系统以提高呼叫中心服务质量。姜冬[10]采用语音转写、中文自然语言处理的方式提高对问题工单的覆盖率。
本文提出一种语音服务质检推荐技术,创新地引入深度学习中LSTM网络的时序处理能力[11],并结合语音质检具体应用场景中问题语音占比低的特点构建改进的LSTM网络质检推荐模型,分析语音服务各项质检指标,充分挖掘其空间与时间上的深层联系形成不同等级的智能语音服务质检策略,筛选需要重点审查的记录推荐给质检员,以提高数据选择的代表性,减轻质检工作负担,提升质检效率,降低运营成本。
1 语音服务质检指标
1.1 传统质检方法相关指标
传统的语音服务缺乏全面、有效、便于统计和量化的评价指标体系,难以将先进的评价技术应用其中。其质检长期处于一种简单、粗糙的低水平状态[12]。通过人工质检的结果还受到质检员主观状态的影响,不同质检员的判断、感受不一致也会导致质检评分结果不同[13]。为了科学合理进行语音服务质检推荐,首先需要明确语音服务质检指标。传统的质检方法主要通过抽样的方式进行,95598客服中心的质检抽样策略经历了3个阶段的变化[14],从最初的简单的随机抽样演变为考虑不同业务重要程度,增大重要业务的抽检比例,再到考虑坐席话务、工单数量等因素,使用决策树、遗传算法等技术对抽样进行优化[15]。
使用抽样的方式进行质检工作效率低且存在漏检风险,但在完善抽检策略的过程中所考虑的指标对于表征语音服务的基本质量有重要的参考价值。表1给出了传统质检方法常见的指标分类。

表1 传统质检方法相关指标分类
1.2 深度学习扩展指标
深度学习通过建立数学模型模拟大脑的神经连接结构,使用多个变换阶段分层对数据特征进行描述,近年来在图像处理、自然语言处理等诸多领域取得了突破性的进展[16-18]。深度学习相对于普通的机器学习来说,非线性操作的层数更多。通过组合低层次特征形成更加抽象的高层表示,将样本在原空间的特征表示变换到新的特征空间,能够有效地揭示输入数据之间的内在联系并做出分类和判断[19]。
随着模型隐含层的增加,需要训练的中间参数也会成倍增长[20],这将对输入数据维度提出更高的要求。为了有效应用深度学习进行语音服务质检推荐,需要对传统质检指标进行扩展。本文将客服中心系统内语音服务所涉及的更多细节信息纳入指标范围内,以提取更多维度的语音特征,尤其关注需要预先通过语音分析技术获取的特征。表2给出了为应用深度学习所扩展的质检相关的指标分类。

表2 深度学习扩展指标分类
2 语音服务质检推荐LSTM网络
2.1 LSTM网络原理
语音服务记录可以看作是一个时序信号[21]。服务结果好坏的评判受到整段语音连续的历史状态的影响,同一位坐席的服务状态也受其历史工作状态的影响[22]。长短时记忆(Long Short Term Memory, LSTM)网络由于自身结构带有内部环路,适合用于处理此类时序信息[23],其单元结构如图1所示。LSTM网络可以通过3个中间层:遗忘门、输入门、输出门移除或添加信息改变单元的状态[24]。

图1 LSTM单元示意图

ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(4)
ot=σ(Wo·[ht-1,xt]+b0)
(5)
ht=ot·tanh (Ct)
(6)
2.2 LSTM网络模型搭建
使用LSTM网络搭建语音服务质检推荐模型,输入方面采用表1、表2所列29条属性。首先对各属性进行量化,对于性别、过早挂机等二值属性采用0或1进行描述。对于枚举类的数据如学历、坐席情绪,为了平衡各选项在算法中的权重,使用哑变量编码[24]的方式描述。对于语音记录的短时属性,需要按时间切片划分成数据帧提取再与非短时指标结合形成53维传统指标输入列向量和79维扩展指标列向量,归一化后作为模型的输入层。
使用首尾相连的LSTM单元作为模型的中间层,其层数取决于每一批输入列向量的数量。

(7)
其中,W(S)为softmax的权值矩阵。在时刻t,使用交叉熵损失函数(8)作为优化目标对模型进行训练。
(8)
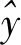

图2 语音服务质检推荐LSTM网络模型
对于95598客服中心语音服务记录,其存在差错的比例通常低于5%[26],存在严重的样本偏倚。且在质检推荐过程中,在满足一定判别准确性的情况下更关心的是能否尽可能找出疑似差错记录提供给质检员[27]。针对以上情况,为提高质检推荐效率对所搭建的模型进行2点改进:
1)将判断是否差错和差错等级分为2个模型,对应的输出层改为二维。首先使用大跨度的时间帧输入判断服务是否存在差错,对于存在差错的数据再减小时间跨度判断差错等级,以此减小数据帧的数量,提高模型训练速度。
2)判断差错时不直接使用softmax结果,而是使用公式:
(PT-PF)<5%
(9)
作为判据,其中PT和PF分别为softmax结果无差错和有差错的概率,以放宽差错标准的方式增加模型对语音服务差错的覆盖率。
3 语音服务质检推荐实验
3.1 实验准备
本文使用国家电网公司某下属供电公司客户服务中心2018年全年数据的一部分总共20000条数据进行质检推荐实验。在数据集的划分上随机抽取60%的数据作为训练样本集,用于迭代优化模型可变参数;20%的数据作为模型验证样本集,用于模型固定参数的选取;剩余20%作为测试样本集,用于模型效果验证。将数据按模型要求预处理完毕后以列向量的方式进行输入。
通过记录正确正类TP、错误正类FP、正确一般差错TN1、错误一般差错FN1、正确严重差错TN2、错误严重差错FN2作为考察指标,可以计算出算法模型的准确率为:
(10)
质检推荐希望能够尽可能找出样本中的错误,宜使用差错召回率[28]考察有多少差错被正确预测出来,其公式如下:
(11)
3.2 实验结果对比
本文将所提出的LSTM模型、改进模型与经典的决策树模型结果进行比较。在指标选取上分别采用15项传统指标和扩展的29项指标结果进行对比。实验结果如表3、表4所示。
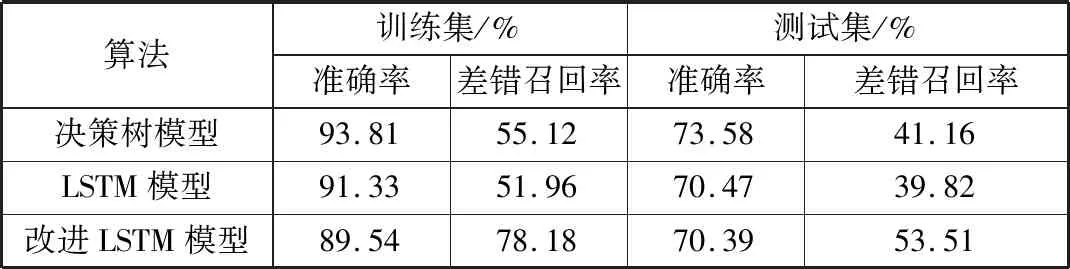
表3 使用传统指标的实验结果

表4 使用完整指标的实验结果
从表中可以看出,使用传统指标时决策树算法在准确率方面优于LSTM模型。当增加深度学习相关指标后,所有算法的准确率均有所提高,决策树模型提升较小,LSTM模型准确率最高。所提出的改进模型与LSTM模型相比在准确度略微降低1.35个百分点的情况下,差错召回率从42.61%提升至77.56%,反应出该模型能够更加高效地检测出样本中的差错记录,向质检员做出有针对性的推荐。
4 结束语
本文将具有时序分析能力的LSTM网络模型用于95598客服中心语音质检推荐。针对传统方法缺乏评价指标情况,引入通过语音分析技术获取的深度学习相关指标增加质检特征。为提高质检效率、满足不同等级质检策略的要求,本文结合实际质检中问题语音占比低的特性对模型进行了改进。实验结果表明,所提出的改进模型相比普通LSTM网络模型有更高的差错覆盖率,能够有效提高质检效率,且模型的准确性优于传统的机器学习算法结果。
猜你喜欢
军民两用技术与产品(2021年1期)2021-07-28 06:05:54
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
计算机应用(2018年12期)2019-01-08 01:55:48
商周刊(2018年26期)2018-12-29 12:56:00
小说界(2018年5期)2018-11-26 12:43:42
福建中学数学(2016年7期)2016-12-03 07:10:28
新闻传播(2016年17期)2016-07-19 10:12:05
集美大学学报(自然科学版)(2015年1期)2015-02-28 01:13:33
