
双因子随机条件极差模型及其实证研究*
2020-07-13 11:49吴鑫育谢海滨汪寿阳
管理科学学报 2020年1期
吴鑫育, 谢海滨, 汪寿阳
(1. 安徽财经大学金融学院, 蚌埠 233030; 2. 对外经济贸易大学金融学院, 北京 100029;3. 中国科学院数学与系统科学研究院, 北京 100190)
0 引 言
由于波动率在投资组合构建、风险管理以及资产定价等诸多金融领域中的重要作用, 对波动率的研究一直以来都是金融计量经济学文献关注的一个热点问题. 尤其是随着我国衍生产品市场的快速发展, 对衍生产品进行合理定价变得越来越重要和紧迫, 而这依赖于对波动率的准确估计, 由此对波动率建立合适的数学模型, 对模型估计与应用(例如波动率预测)的研究变得日益重要. 而且, 由于金融市场波动率与金融市场的稳定及至实体经济的波动有着紧密联系, 了解和关注波动率动态性对于研究人员、政策制定者和监管者都具有十分重要的意义.
金融市场波动率呈现丰富、复杂的特性. 研究表明, 波动率往往表现出时变性和聚集性, 即一个大的波动后面往往伴随着较大的波动, 而一个小的波动后面往往伴随着较小的波动. Bollerslev[1]和Taylor[2]提出的广义自回归条件异方差(GARCH)模型和随机波动率(SV)模型是两类能够较好地捕获波动率的这种动态特征的模型. GARCH模型假设条件方差是历史信息集的一个确定性函数, 而SV模型假设条件方差是由一个隐含的随机过程生成, 是不可观测的. 由于SV模型在条件方差过程中引入了一个新的随机过程, 模型的尾部拟合能力更强, 能够解释资产收益率大部分的非正态性(“尖峰”、“厚尾”), 这使得SV模型相比GARCH模型具有更高的灵活性以及对金融时间序列数据更好的样本内拟合效果和样本外波动率预测效果[3,4]. 而且, 由于SV模型与连续时间金融的紧密联系, 这类模型在资产定价和衍生产品定价中得到了广泛的关注与应用.
然而, 传统上这些模型都是基于由收盘价信息计算得到的收益率进行建模. 但是收益率数据仅利用了收盘价信息, 忽略了日内价格变动的信息, 并不能完全反映资产价格实际日内波动情况, 导致信息与效率的损失. 特别是在金融市场高波动时期, 采用收益率信息估计的波动率往往存在严重低估. 为了克服上述问题, 充分利用每天资产的最高价和最低价(日内价格路径)信息, Parkinson[5]考虑构建了价格极差(最高价和最低价之差)作为波动率的代理变量, 该估计量在理论上比基于收益率估计的波动率具有更高的效率, 提高了对波动率估计的有效性. 另一种利用日内信息对波动率估计的方法是基于日内高频交易数据构建已实现波动率测度. 已实现波动率测度的优点是构造简单且充分利用了交易日内的收益率信息, 理论上利用高频交易数据可以获得波动率更加精确的估计. 然而, 实际中由于高频数据受到微观结构噪声的影响, 高频环境下市场微观结构噪声对已实现波动率测度存在显著的影响, 而且这种影响会随着抽样频率的增加而增加, 导致已实现波动率测度往往是真实波动率的有偏估计. 相比较而言, 价格极差对微观结构噪声的影响并不敏感, 是对微观结构噪声较为稳健的波动率估计量[6]. 事实上, Degiannakis和Livada[7]研究发现, 价格极差波动率相比已实现波动率测度是更为精确的波动率估计量. 此外, 由于金融市场每天交易的最高价和最低价相比高频数据在数据的获取上也更为容易, 这使得基于价格极差的波动率建模方法具有广泛的适用性, 在金融学文献中得到了越来越多的关注与应用, 例如Chou和Wang[8]、Yarovaya等[9]和Benlagha和Chargui[10].
与基于收益率对波动率建模的研究相比, 基于价格极差对波动率建模的研究相对较少. Alizadeh等[6]和Brandt和Jones[11]考虑了将价格极差与传统SV模型和EGARCH模型结合对波动率进行估计, 他们发现基于极差的波动率模型相比基于收益率的波动率模型可以获得更好的样本外波动率预测效力. 然而, 这些研究主要针对对数价格极差进行建模, 建立在对数价格极差近似服从正态分布的假设上. 然而, 实际可能并非如此. 基于此, Chou[12]构建了对价格极差动态性直接建模的条件自回归极差(CARR)模型, 他发现基于极差的CARR模型相比传统的基于收益率的GARCH模型可以获得更准确的波动率估计结果. 随后, Chou和Liu[13]利用基于价格极差的波动率模型实证考察了波动率择时的经济价值, 发现基于价格极差的波动率模型相比基于收益率的波动率模型具有更好的表现. Chou等[14]对价格极差波动率模型的最新研究给出了一个详尽的评述. 关于价格极差波动率模型的一些其它应用可以参考Chiang和Wang[15], Miao等[16], Anderson等[17]和Auer[18].
国内一些学者也对价格极差波动率模型进行了深入研究. 周杰和刘三阳[19]、蒋祥林等[20]探讨了基于价格极差的波动率模型相对于基于收益率的波动率模型的有效性. 李红权和汪寿阳[21]、Li和Hong[22]引入并扩展了基于价格极差的自回归波动率模型, 研究发现构建的模型能够有效刻画波动率的动态性, 且比GARCH模型具有更好的波动率预测效果. 赵树然等[23]考虑了基于CARR模型和极值理论的风险价值的估计问题, 发现该方法极大提高了风险度量的精确性. 郑挺国和左浩苗[24]构建了基于价格极差的区制转移SV模型, 并对模型的波动率预测能力进行了研究. 孙便霞和王明进[25]、刘威仪等[26]将价格极差引入GARCH模型中, 考察了模型对波动率及风险价值的预测能力. 王沁[27]基于杠杆效应CARR模型考虑了波动率的预测问题, 获得了较好的波动率预测效果.
CARR模型在结构上与GARCH模型相似, 模型灵活性仍有待提高. 借鉴SV模型的建模思路, 最近Galli[28]提出随机条件极差(SCR)模型来描述价格极差的动态性. 在SCR模型中, 价格极差动态性由一个不可观测的隐变量驱动, 可以捕获市场上不可观测的信息流的到来, 模型变得更加灵活. 在该模型下, 价格极差具有混合分布特征. Galli[28]研究表明, SCR模型相比CARR模型具有更好的样本内拟合效果, 但是样本外预测表现与CARR模型并没有太大差别. 此外, 研究也发现基本的SCR模型对于描述金融时间序列的一些经验特征事实仍过于局限, 例如波动率不仅具有短期的相关性, 同时具有长期的相互影响, 即波动率具有持续性和长记忆性[29,30]. SCR模型对于充分刻画这种波动率长记忆特征仍存在局限性. 此外, Galli[28]采用对数正态分布和Weibull分布对价格极差的新息建模, 其对于价格极差尾部分布的拟合并不充分. Xie和Wu[31]在CARR模型体系下,采用Gamma分布对价格极差新息进行建模,发现其能够改进数据拟合效果,克服价格极差的“异常值”(Outliers)问题.
基于以上认识, 构建基于Gamma分布的双因子SCR(2FSCR)模型来描述价格极差的动态性, 以综合捕获金融市场波动率的时变性、聚集性与长记忆特征. Corsi和Reno[32]研究表明, 波动率的长记忆性可以由波动率因子的叠加效应(多因子波动率)来捕获. 同时, 在2FSCR 模型中引入第二个隐因子也有助于解释更为复杂的价格极差的混合分布形态. 2FSCR模型属于双因子波动率模型, 其与多因子连续时间资产定价模型有着紧密联系, 在金融计量经济学文献中引起了广泛的关注, 例如Alizadeh等[6]、Durham[33]、Christoffersen等[34]. 2FSCR 模型相比CARR模型和SCR模型都更为灵活, 但同时模型的参数估计也变得更加困难. 为了估计2FSCR模型的参数, 给出灵活且易于实现的基于连续粒子滤波(continuous particle filters)的极大似然估计方法, 并通过模拟验证了估计方法的有效性. 最后, 利用提出的2FSCR模型对上证综合指数、深证成份指数、香港恒生指数和美国标普500 指数进行拟合, 对模型与CARR模型和SCR模型的样本内拟合和样本外预测效果进行比较分析, 验证了提出模型的优越性.
1 2FSCR模型
设pt是资产的对数价格, 价格极差Rt定义为
Rt≡max{pτ}-min{pτ},τ∈[t-1,t]
(1)
为了描述价格极差Rt的动态性, Chou[12]提出如下CARR(p,q)模型
Rt=λtεt
(2)
(3)
εt|Ft-1~i.i.d.f(εt;ϑ)
(4)
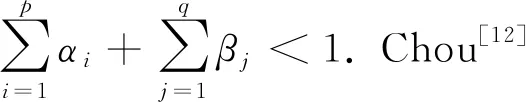
为了获得更高的模型灵活性, 借鉴SV模型的建模思路, 最近,Galli[28]对CARR模型进行了拓展, 提出如下对价格极差建模的SCR模型
Rt=exp(ξt)εt,ξt=c+λt
(5)
λt=βλt-1+ηt
(6)
εt|Ft-1~i.i.d.f(εt;ϑ)
(7)
ηt|Ft-1~i.i.d.N(0,σ2)
(8)
(9)
其中λt是不可观测的隐变量, 服从高斯AR(1)过程, 为了保证其平稳性, 必须有|β|<1,εt与ηt相互独立, 引入新息ηt增加了模型的灵活性. 可以看到, 在SCR模型中, 价格极差Rt的分布来自于exp(ξt) 的分布(对数正态分布)与εt分布的混合, 即价格极差Rt具有混合分布特征. Galli[28]在其提出的SCR模型中, 假设新息εt服从对数正态分布和Weibull分布, 但没有考虑更合适的Gamma分布对价格极差新息进行建模.
SCR模型能够成功地捕获波动率时变性和聚集性, 但对于刻画波动率的其它一些经验特征事实仍过于局限, 例如它没有考虑到波动率过程具有的长记忆特征. 鉴于此, 引入能够刻画波动率长记忆性的2FSCR模型对价格极差建模, 同时引入Gamma分布来描述价格极差新息的分布, 由此构建的2FSCR模型为
Rt=exp(ξt)εt,ξt=c+λ1,t+λ2,t
(10)
λi,t=βiλi,t-1+ηi,t,i=1,2
(11)
εt|Ft-1~i.i.d.f(εt;ϑ)
(12)
(13)
(14)
其中εt、η1,t和η2,t相互独立, 且εt服从标准Gamma(ν,1)分布, 其概率密度函数为

(15)
其中ν(ν>0)是形状参数, ϑ=ν. 当ν=1时, Gamma分布简化为指数分布. Xie和Wu[31]研究表明, 新息服从Gamma 分布的CARR模型相比新息服从对数正态分布、指数分布和Weibull分布的CARR模型更容易产生异常值, 能更好地拟合价格极差的分布.
在2FSCR模型中, 通过式(11)引入双因子(两个相互独立的AR(1)过程)来捕获波动率过程的长记忆相关性. 假设-1<β2<β1<1, 保证波动率因子过程λ1,t和波动率因子过程λ2,t是平稳的且可识别, 其中第一个因子代表波动率长期成份(持续性/长记忆波动率因子), 第二个因子代表波动率短期成份(非持续性/短记忆波动率因子). 由于2FSCR模型中引入了第二个隐因子, 其相比单因子的SCR模型, 可以解释更为复杂的价格极差的混合分布形态.
2 估计方法
由于2FSCR模型中包含不可观测的状态变量, 模型的似然函数是一个复杂的高维积分, 这导致2FSCR模型不像CARR模型那样可以直接运用极大似然方法进行估计. 为了克服这个问题, 可以运用粒子滤波方法来获得模型的似然函数, 进而采用极大似然方法对模型参数进行估计.粒子滤波方法是一种序贯蒙特卡罗方法, 它通过模拟抽样来产生预测和滤波分布. 最经典和常用的粒子滤波方法是由Gordon等[35]提出的抽样重要性重抽样(sampling/importance resampling, SIR)滤波方法. SIR方法对于处理包含不可观测状态变量的非线性模型非常方便, 它易于实现, 且具有非常强的适用性, 可以容易地应用于各种模型[36,37].
然而, 基于标准的SIR滤波算法得到的模型似然函数通常是不连续的, 这给采用传统的优化方法来最大化相应的似然函数造成困难. 为了克服这个问题, 运用Malik和Pitt[38]提出的连续重抽样方法, 构建相应的连续SIR(CSIR)算法来获得2FSCR模型连续的似然函数估计.
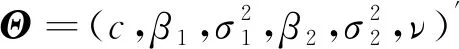
(16)
其中Ft-1={R1,…,Rt-1}为t-1时刻的信息集以及
(λt+1|Ft;Θ)dλt+1
(17)
它可以通过蒙特卡罗模拟近似得到, 即
(18)
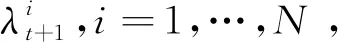
根据贝叶斯原理, 有
p(λt+1|Ft+1;Θ)∝p(Rt+1|λt+1;Θ)p(λt+1|Ft;Θ)
(19)
其中p(λt+1|Ft+1;Θ)称为滤波密度. 粒子滤波即根据式(19), 通过模拟抽样(粒子)来递归地获得滤波密度p(λt+1|Ft+1;Θ)的近似.
(20)
为了从式(20)中抽样, 可以利用SIR滤波方法. 2FSCR模型的SIR滤波算法具体如下
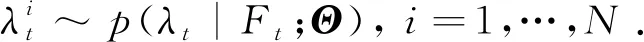
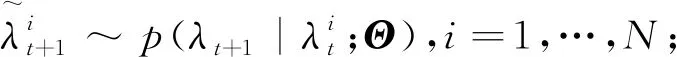
步骤2计算归一化权重
(21)
其中

基于SIR算法, 可以得到似然估计为
(22)
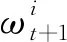
(23)
上述对数似然估计不是无偏的, 需要进行偏差修正. 修正得到无偏的对数似然的估计为
(24)
其中
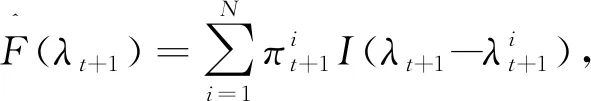
基于CSIR算法可以得到连续的似然函数估计, 进而结合极大似然方法容易得到2FSCR模型参数的模拟极大似然估计为
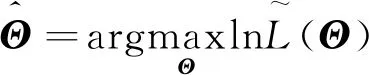
(25)
3 模拟实验
为了检验第2部分构建的基于CSIR滤波的极大似然估计方法的精确性和有限样本性质, 这部分进行蒙特卡罗模拟实验. 考虑基于SCR 模型和2FSCR模型的模拟研究(2)由于SCR模型可以看作2FSCR模型的特例, 因此第2部分构建的基于CSIR滤波的极大似然估计方法只需要简单的修改即可应用于SCR模型的估计., 模型真实参数值设定为
1) SCR模型
Rt=exp(ξt)εt,ξt=-1.50+λt
λt=0.98λt-1+ηt
εt|Ft-1~i.i.d.Gamma(7,1)
ηt|Ft-1~i.i.d.N(0,0.01)
2) 2FSCR模型
Rt=exp(ξt)εt,ξt=-2.80+λ1,t+λ2,t
λ1,t=0.98λ1,t-1+η1,t
λ2,t=0.09λ2,t-1+η2,t
εt|Ft-1~i.i.d.Gamma(30,1)
η1,t|Ft-1~i.i.d.N(0,0.004 5)
η2,t|Ft-1~i.i.d.N(0,0.10)
根据上述“真实的”SCR模型和2FSCR模型模拟产生样本长度为T=2 500与T=4 000的观测序列, 对每一观测序列运用基于CSIR滤波的极大似然方法进行估计, 重复模拟和估计实验100 次获得参数估计的均值、标准差和均方根误差(RMSE). 基于CSIR 滤波的极大似然估计方法采用MATLAB软件编程实现.
表1给出了数值模拟的实验结果. 从表1可以看到, 参数估计的均值都接近于相应的参数真实值; 参数估计的标准差都接近于RMSE, 表明估计的有限样本偏差较小. 随着样本长度的增加(T:2 500→4 000), 参数估计的标准差和RMSE都变得越小, 说明参数估计值随着样本长度的增加而趋于收敛于参数真实值. 同时, 值得注意的是, 比较SCR模型与2FSCR模型的模拟结果可以看到, 2FSCR模型参数的估计相比SCR模型参数的估计要更为困难. 特别地, 2FSCR模型中短记忆波动率因子过程参数的估计相比其它参数的估计存在更高的偏差(标准差), 这与Durham[33]的研究结果一致, 如何获得更为精确的短记忆波动率因子过程参数的估计结果有待进一步的研究. 总体上, 运用基于CSIR滤波的极大似然方法估计(2F)SCR模型可以获得较为合理和有效的参数估计结果.
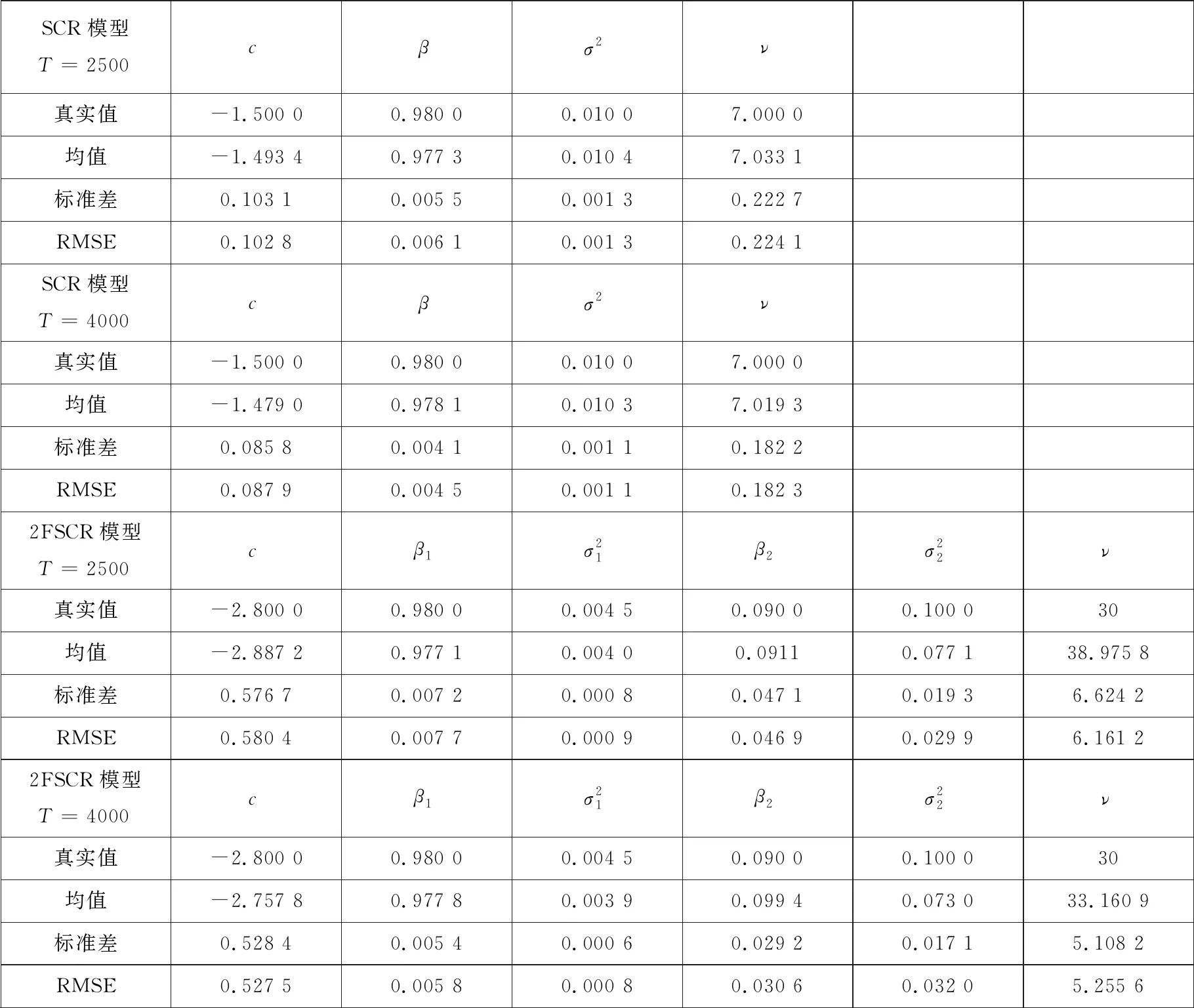
表1 数值模拟结果
注:粒子数选取为500, 重复模拟实验100次获得参数估计的均值、标准差和均方根误差(RMSE).
4 实证研究
4.1 数据
采用上证综合指数(SSE)、深证成份指数(SZSE)、香港恒生指数(HSI)和美国标普500指数(SPX)从2001年1月4日至2017年5月25 日的日交易价格数据(包括每日的开盘价、最高价、最低价和收盘价)作为研究样本, 得到四个指数各3 971、3 971、4 042和4 125组观测值. 所有数据均来源于Wind资讯. 指数价格极差采用式(1)计算, 并乘以100.
图1给出了SSE、SZSE、HSI和SPX指数价格极差时间序列图. 从图1可以看出, 四个指数在抽样阶段内均展现明显的波动率时变性和聚集性特征.
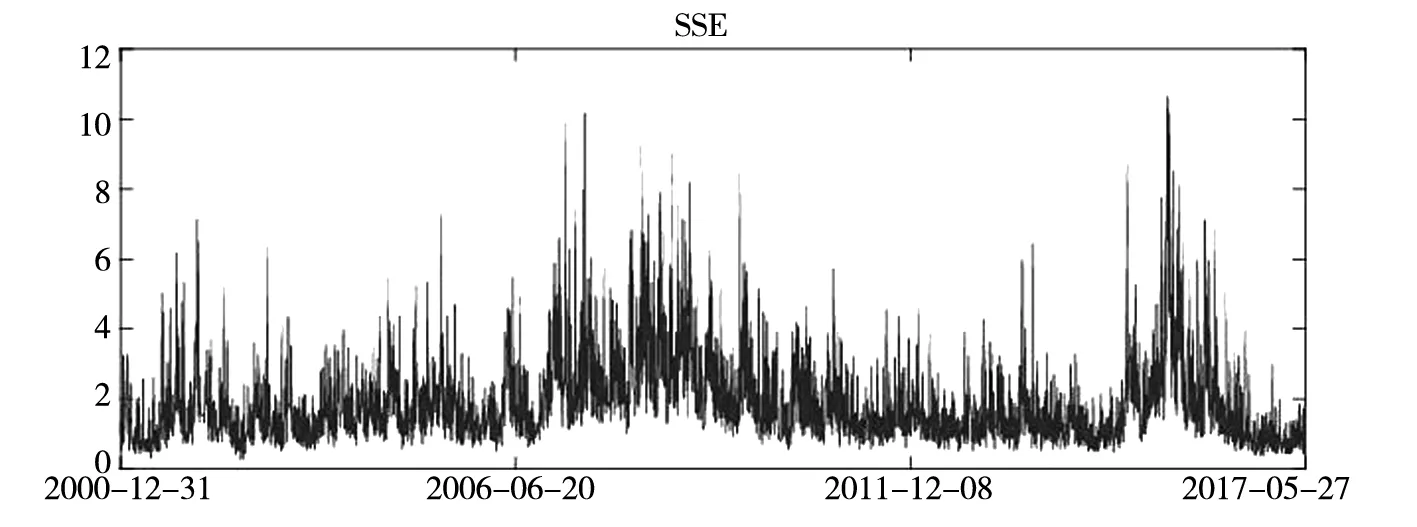
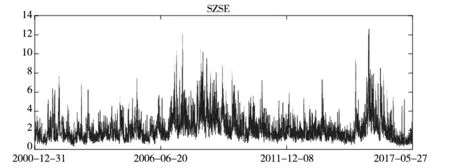
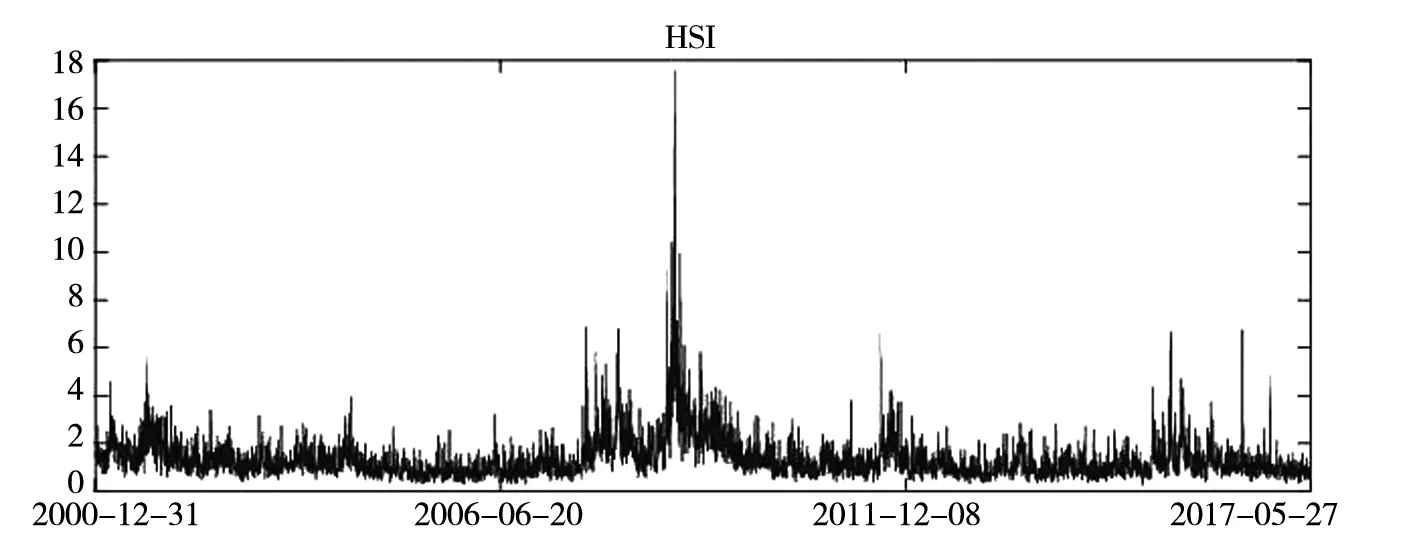
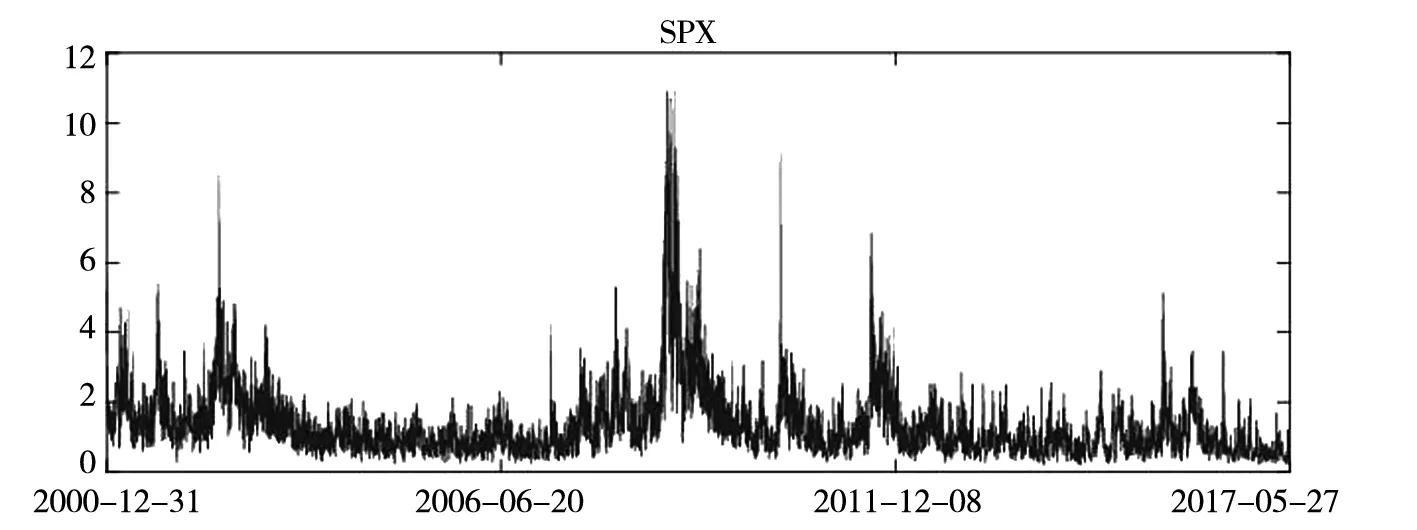
图1 指数价格极差时间序列图
表2给出了四个指数价格极差(Rt)和对数价格极差(lnRt)的描述性统计量. 从表2可以看到, 四个指数价格极差偏度都明显大于0, 峰度都大于3, 表明四个指数价格极差分布都呈现正偏、尖峰和厚尾特征; Jarque-Bera统计量显著, 拒绝其正态性假定. 但比较对数价格极差与价格极差的描述性统计量可以看到, 对数价格极差的偏度、峰度和Jarque-Bera统计量都大大降低, 虽然并不完全服从正态分布, 但相比较而言已较为接近于正态分布. Ljung-BoxQ统计量表明(对数)价格极差波动率序列具有非常强的持续性.
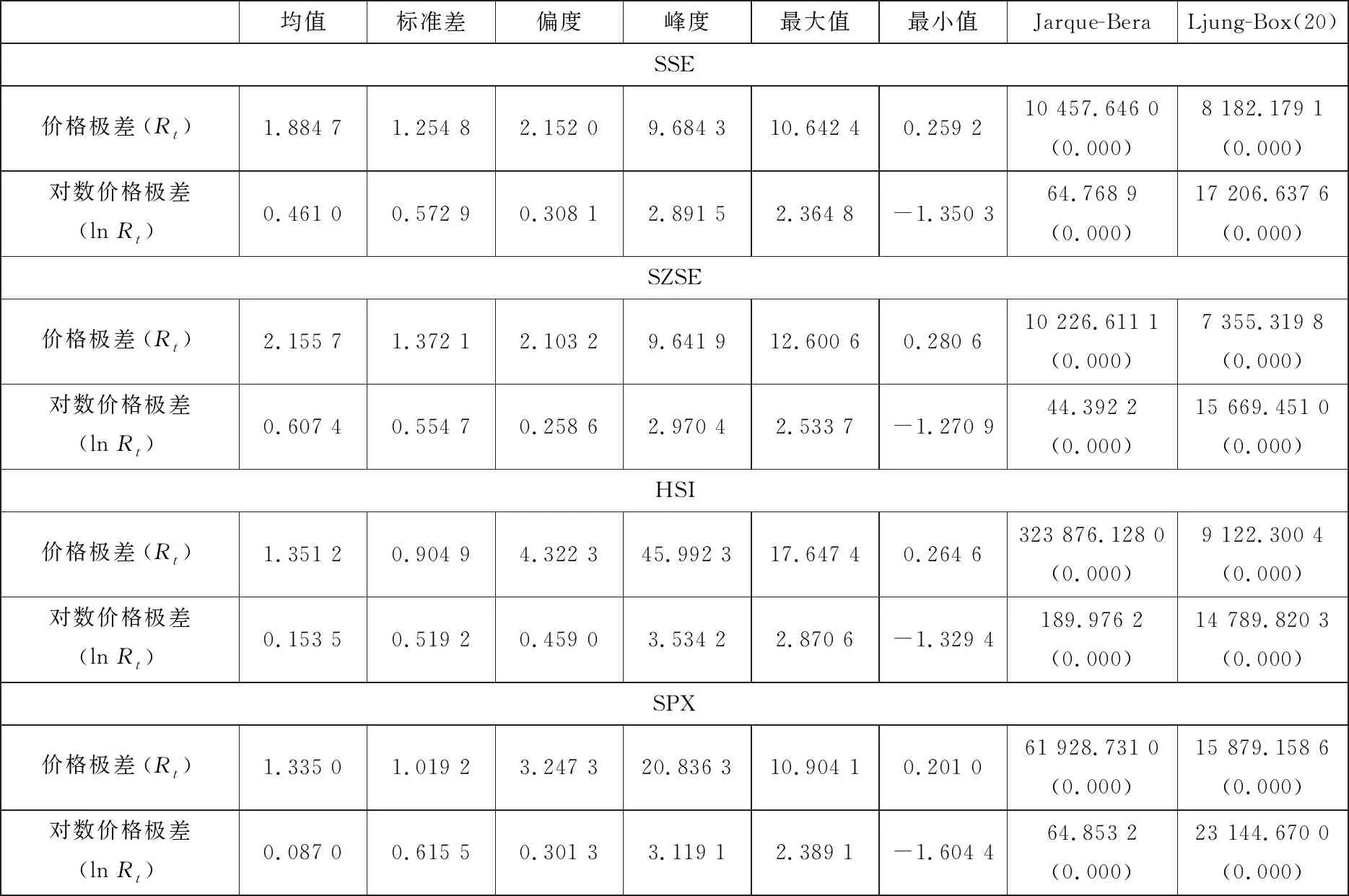
表2 指数价格极差描述性统计量
注:括号中是相应统计量的P值.
4.2 参数估计结果
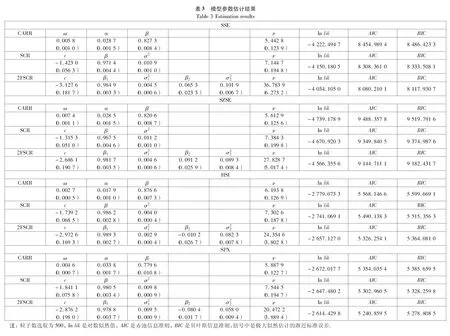
运用第2部分给出的基于CSIR滤波的极大似然估计方法, 得到2FSCR模型的参数估计结果及其标准误差、对数似然值(lnlik)、赤池信息准则(AIC)和贝叶斯信息准则(BIC)如表3所示. 为了比较起见, 表3也给出了CARR(1,1)模型和单因子的SCR模型的估计结果.
从表3可以看到, SSE、SZSE、HSI和SPX指数价格极差都具有非常高的持续性: CARR模型中系数αν+β, SCR模型中系数β和2FSCR模型中系数β1的估计值都非常接近于1. 所有模型中参数ν的估计值都明显大于1, 表明价格极差偏离于指数分布(3)事实上, 也估计了新息服从指数分布、对数正态分布与Weibull分布下的价格极差模型(CARR模型、SCR模型和2FSCR模型), 发现这些新息分布设定比新息Gamma分布的设定在模型拟合上要差. 为了节省空间, 这里没有给出这些估计结果, 如有需要可向作者索取..比较CARR模型、SCR模型和2FSCR模型的估计结果可以看到, CARR模型具有最低的对数似然值和最高的AIC值和BIC值, 表明CARR模型数据拟合表现最差. 比较SCR模型和2FSCR模型的估计结果可以看到, 双因子2FSCR模型相比单因子SCR 模型具有更高的对数似然值和更低的AIC值和BIC值, 表明能够描述波动率长记忆性和复杂混合分布形态的双因子2FSCR模型通过引入第二个波动率因子过程确实增加了模型的灵活性, 获得了最佳的数据拟合效果.
4.3 模型诊断
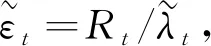
ut=F(Rt|Ft-1)
(26)
基于CSIR算法容易得到其估计为
(27)
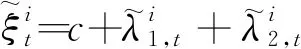
图2给出了不同模型广义残差的Q-Q图. 从图中可以看到, CARR模型对于价格极差的拟合最差, SCR模型次之, 2FSCR模型具有最佳的价格极差尾部分布拟合效果.
图3和图4分别给出了广义残差及其平方的样本自相关函数(ACF)图. 从广义残差的样本ACF图(图3)可以看到, CARR模型的广义残差存在一些(弱的1阶或2阶)自相关性, 相比较而言, SCR模型和2FSCR模型的广义残差不存在明显的序列相关性, 广义残差序列基本上是独立的. 进一步, 所有模型广义残差平方的样本ACF图(图4)表明广义残差序列不存在明显的条件异方差性, 因此模型能充分地描述价格极差波动率序列的线性相依性(长记忆性).
综上, 2FSCR模型相比CARR模型和SCR模型能更充分地综合描述价格极差波动率的尾部分布和动态性(时变性、聚集性和长记忆性).
4.4 样本外波动率预测
模型好的样本内表现不一定意味着一定具有好的样本外表现. 因此, 这部分进一步考察模型实际的样本外波动率预测效果. 考虑CARR模型、SCR模型和2FSCR模型向前一步的波动率预测, 并进行比较分析. 基于CSIR滤波方法, SCR模型和2FSCR模型的波动率预测是容易的.
由于波动率是不可观测的, 采用事后波动率: 价格极差(RANG)和已实现波动率(RV), 作为真实波动率的代理变量和比较基准. 日度RV采用5min高频数据基于下式计算得到(5)指数5min高频数据来源于Wind资讯.
(28)
其中pt,i是第t交易日的第i个时间间隔上的对数收盘价,n是日内收益率总数目. 关于采用RV作为波动率测度的理论考察可以参考Barndorff-Nielsen和Shephard[39].
采用的数据为4.1节介绍的SSE指数、SZSE指数、HSI指数和SPX指数从2001年1月4日至2017年5月25日的数据. 将数据样本分为“样本内”估计阶段和“样本外”预测评估阶段两个阶段. 采用滚动窗方法对模型进行估计与对波动率进行预测. 首先估计模型的抽样阶段为从2001年1月4日到2017年1月3日, 第一个预测日期为2017年1月4日. 当一个新的观测值增加到样本中, 删除第一个观测值并重新估计模型, 然后将重新估计的模型用于波动率预测. 整个过程不断重复直至抽样日期2017年5月24日. 因此, 最终的预测日期为2017年5月25日. 将预测波动率与相应的观测基准波动率RANG和RV进行比较.
为了对模型的波动率预测精确性进行评价, 采用均方根误差(RMSE)和平均绝对误差(MAE)两个损失函数, 分别定义为
其中MV是观测的(事后)波动率, 即RANG或RV;FV(m)是预测的波动率,m为波动率模型, 即CARR模型、SCR模型或2FSCR模型.
表4给出了波动率预测精确性的评估结果. 从表4可以看到, 当采用RANG作为比较基准, SCR模型的预测效果在某些情形下(SSE指数和HSI 指数)并不比CARR模型好. 但对于2FSCR 模型, 所有情形下都获得了相比CARR模型和SCR模型更好的波动率预测效果.
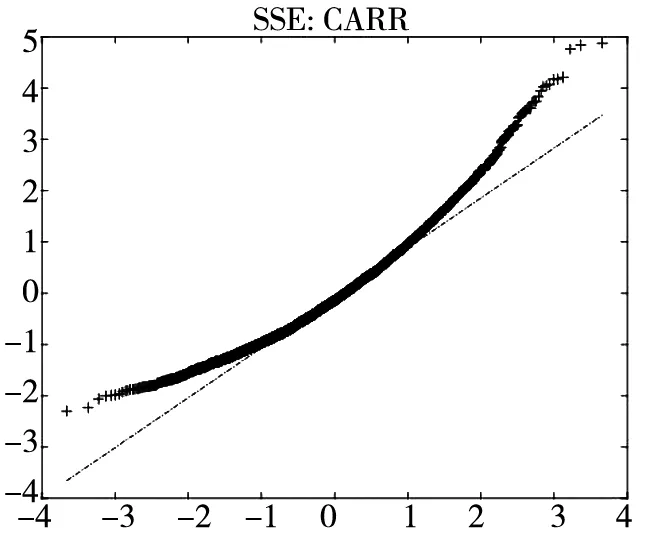
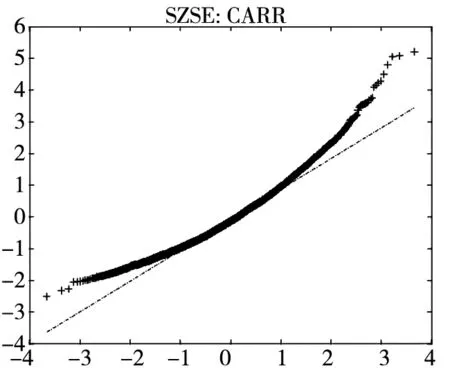
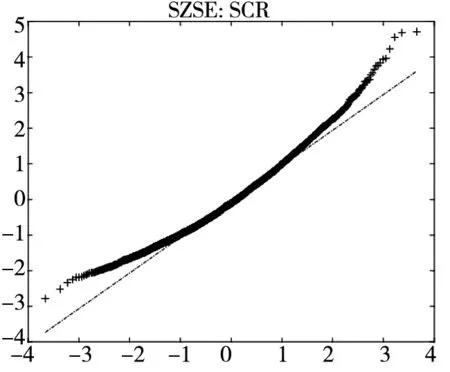
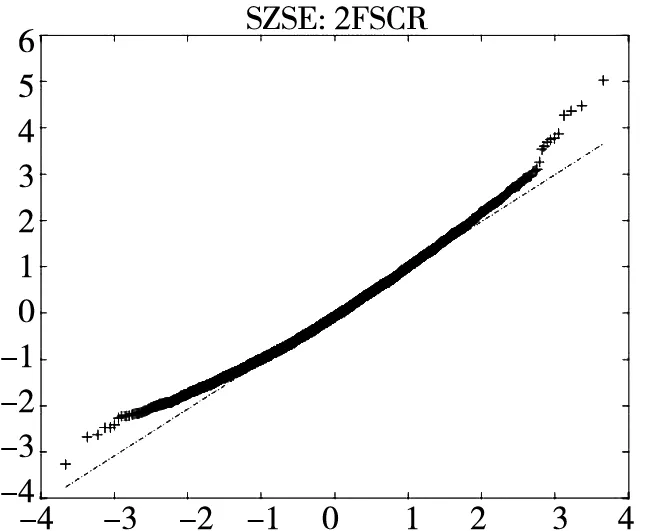
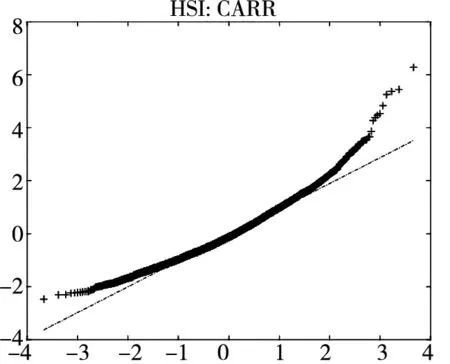
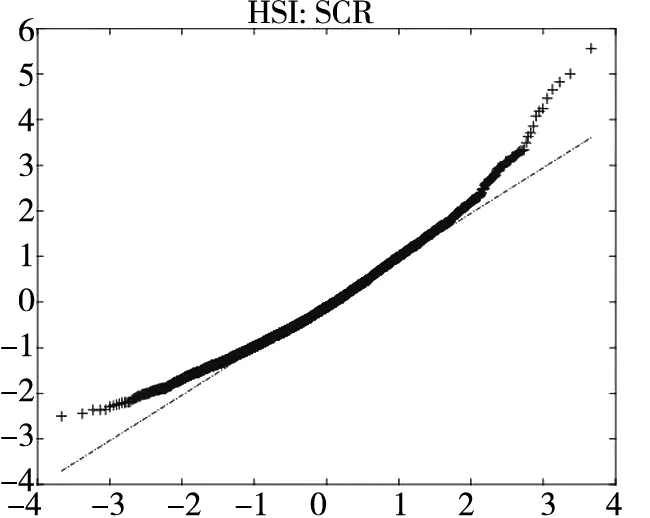
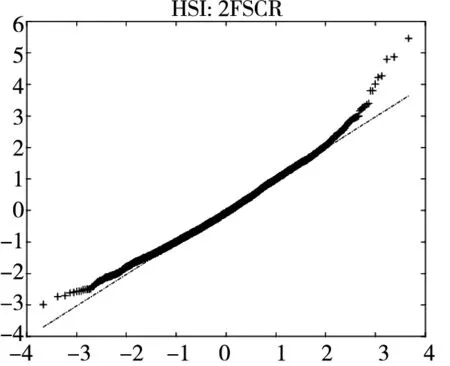
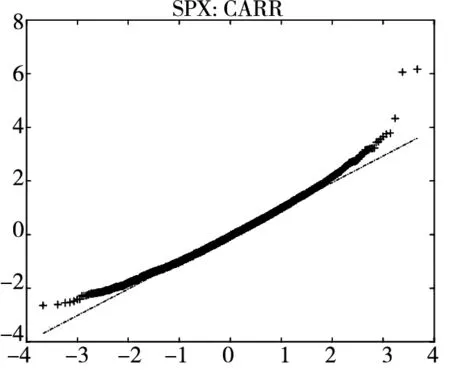
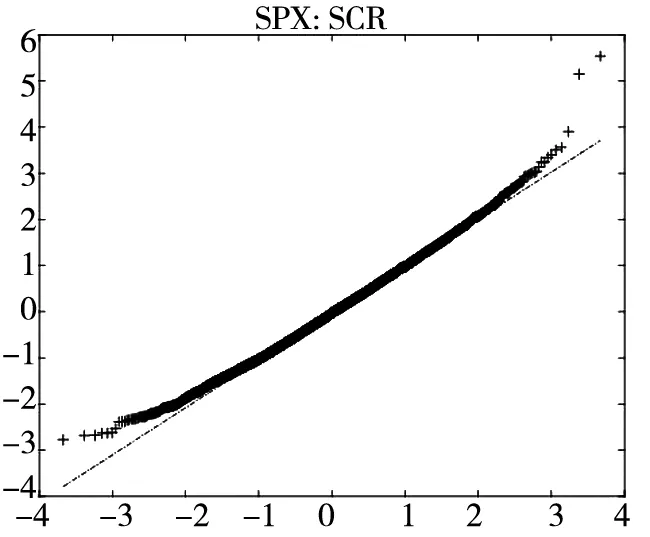
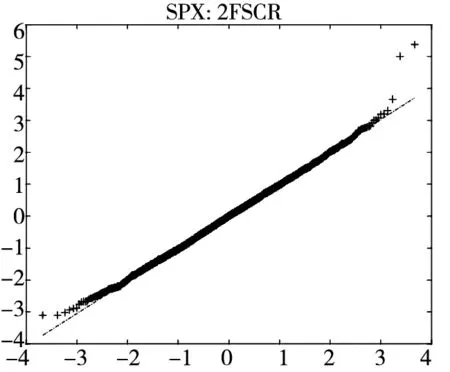
图2 不同模型广义残差的Q-Q图
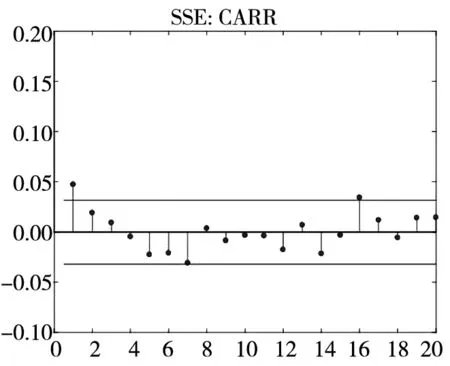
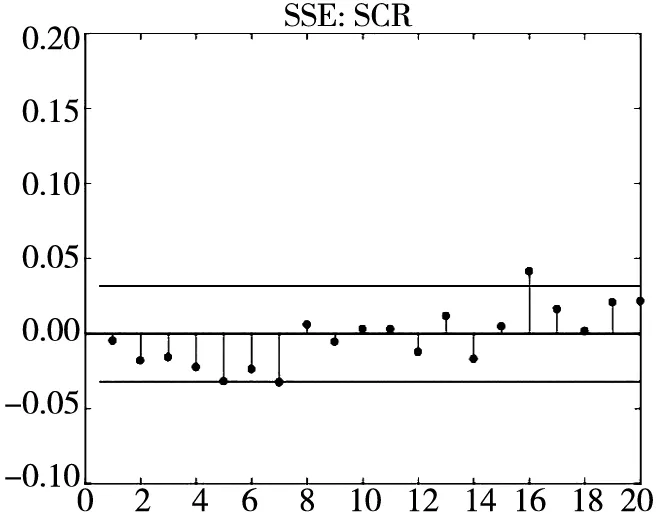
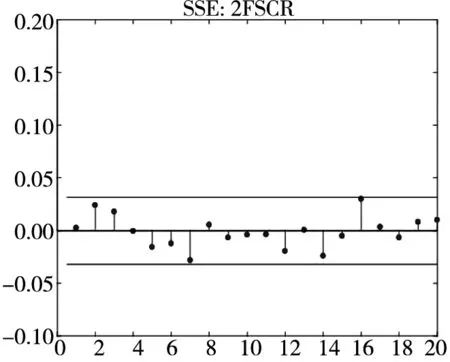
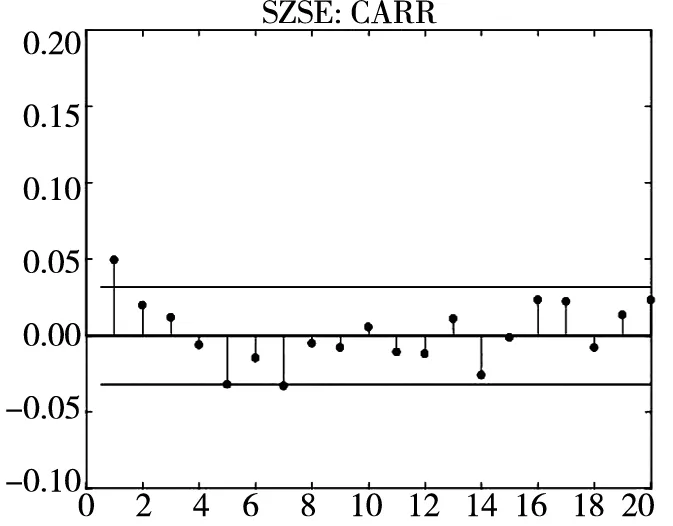
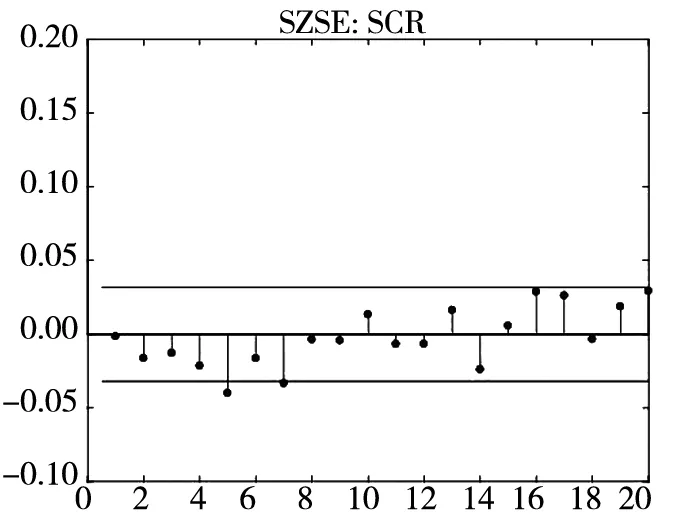
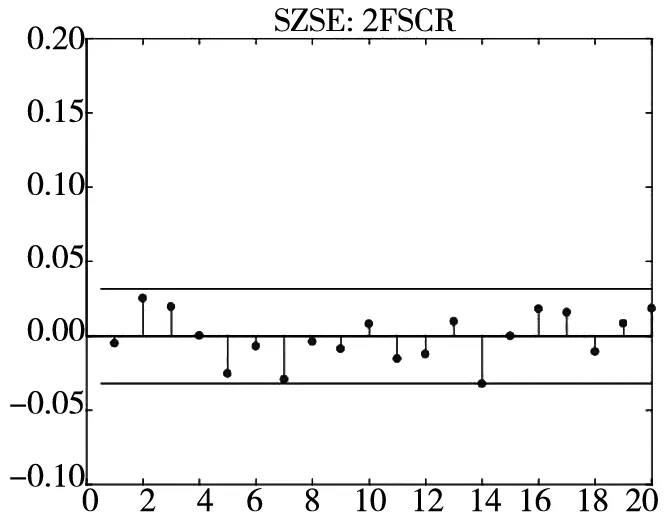
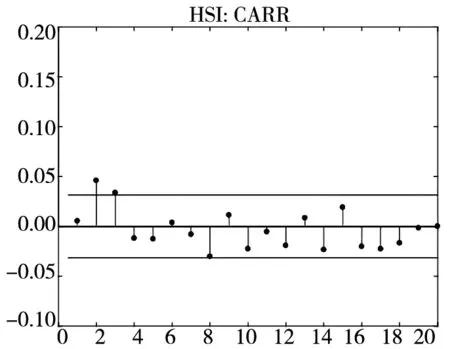
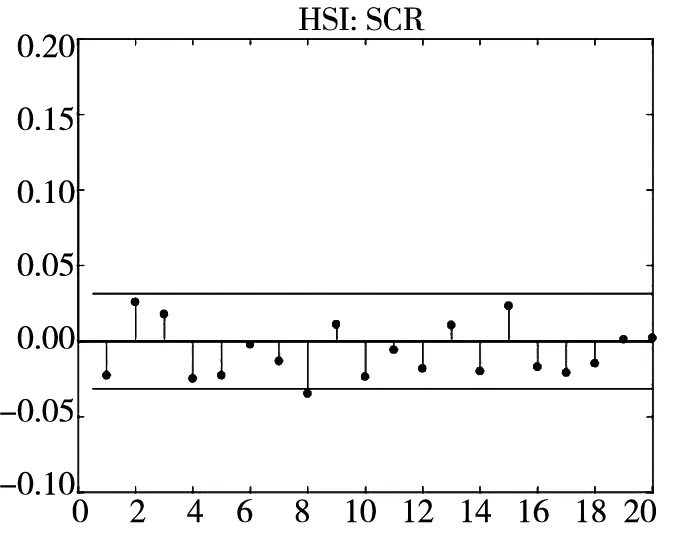
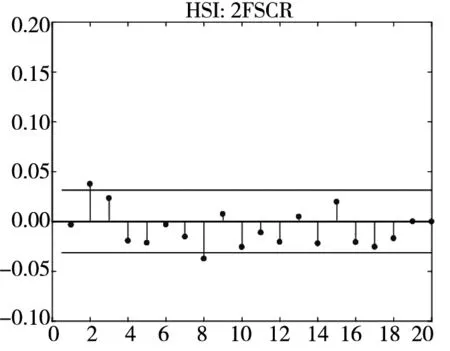
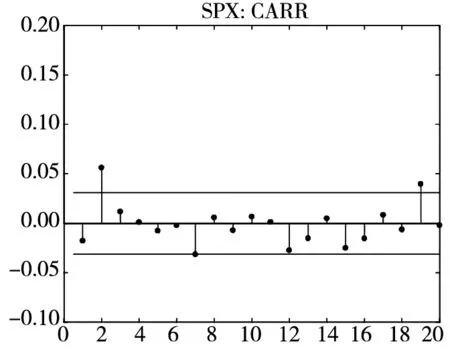
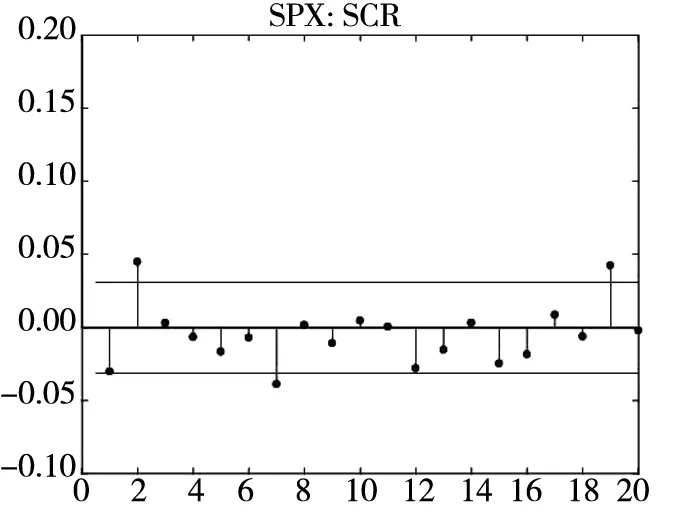
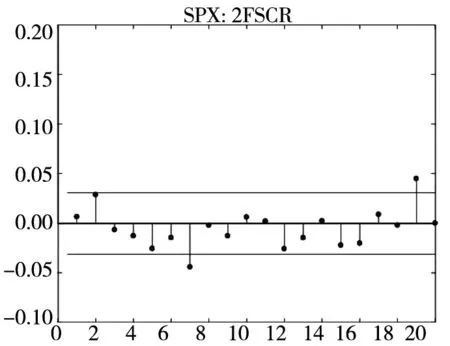
图3 不同模型广义残差的样本

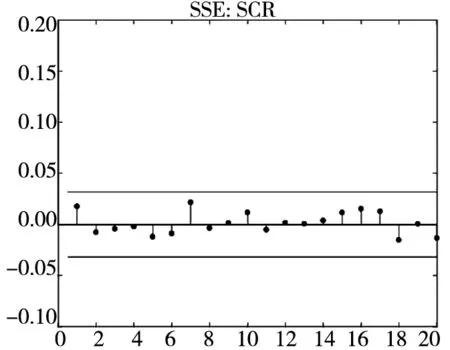
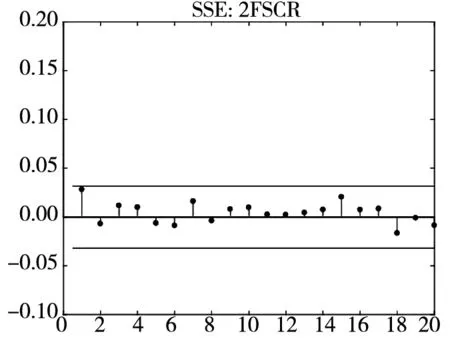
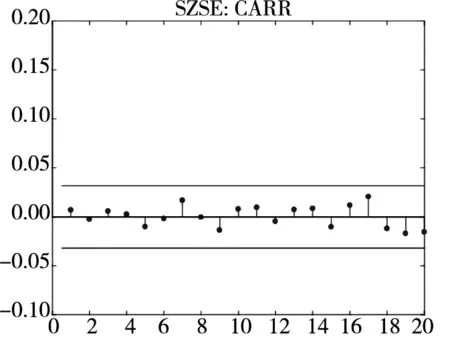
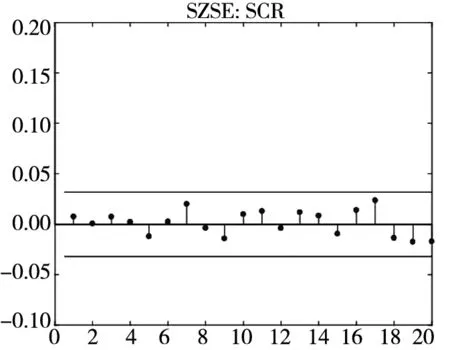
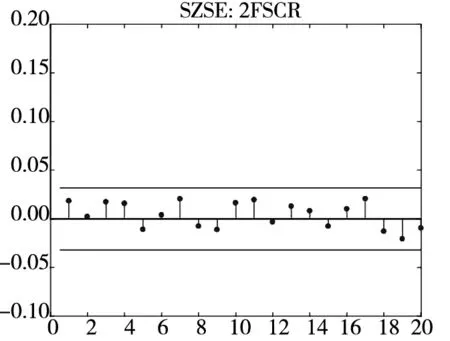
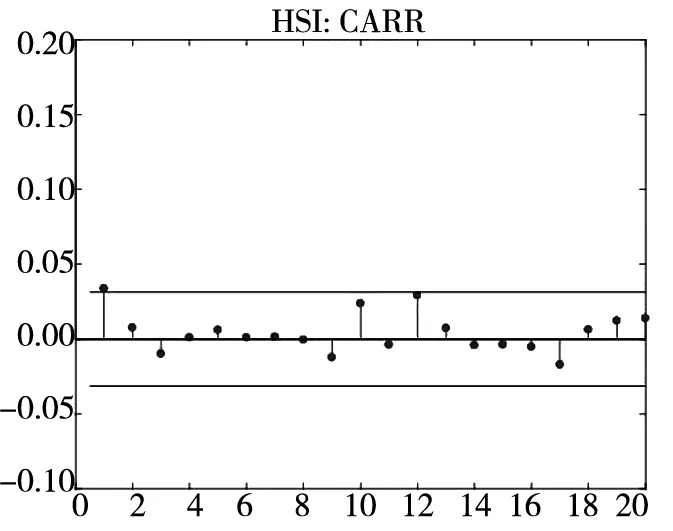

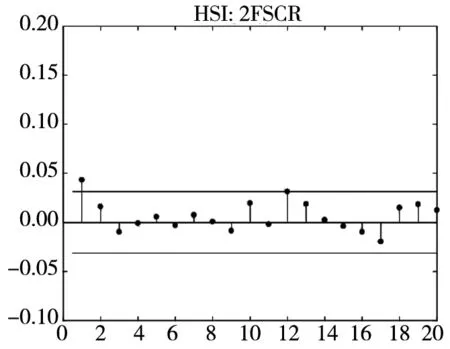
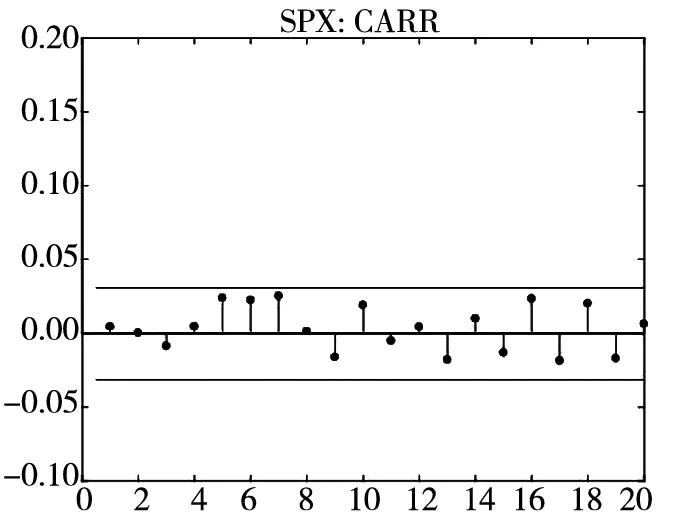
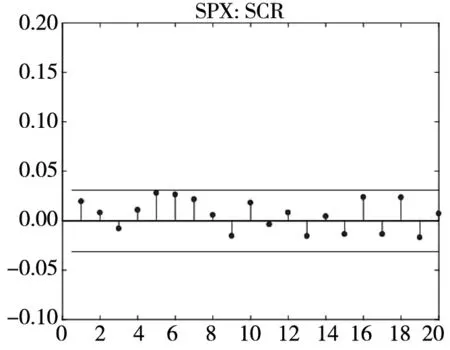

图4 不同模型广义残差平方的样本ACF图
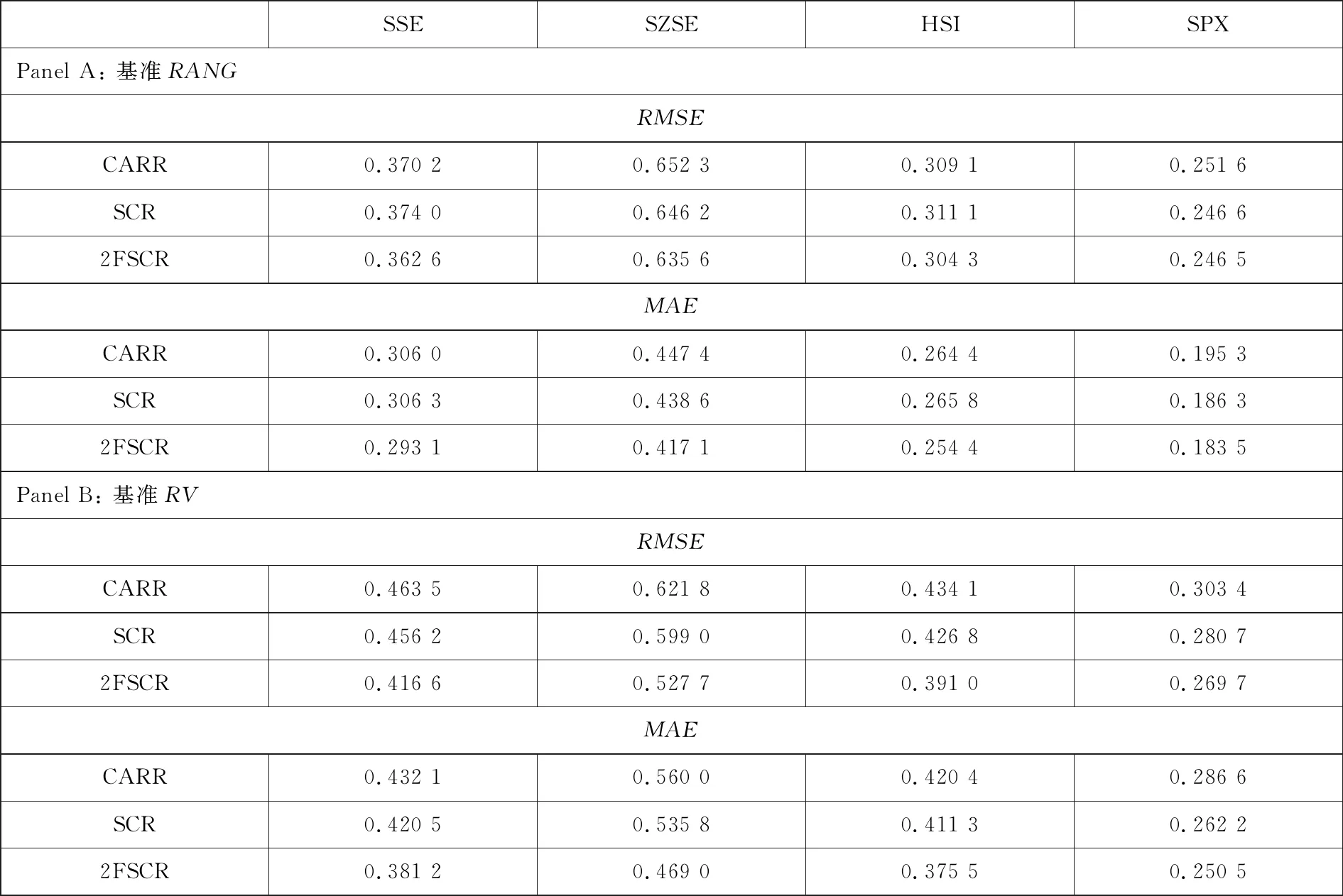
表4 波动率预测结果
注:RANG是价格极差,RV是已实现波动率.RMSE是均方根误差,MAE是平均绝对误差.
当采用RV作为比较基准时, 模型预测误差之间的差别更大, 随机条件极差类模型(SCR模型和2FSCR模型)的表现一致优于CARR模型, 表明该类模型能更好地反映波动率不可观测这一特征. 此外, 在四个指数的波动率预测中, 2FSCR模型相比CARR模型和SCR模型都具有更好的表现. 特别地, SCR模型相比CARR模型在预测精确性上的改进比率约为1.6%/2.2%到7.5%/8.5%(RMSE/MAE降低比率), 2FSCR模型相比CARR模型在预测精确性上的改进比率约为10%/11%到15%/16%, 2FSCR模型对于波动率预测结果的改进较为明显. 这可以解释为RV充分利用了每天日内信息, 所以包含了更多的波动率信息, 是波动率更好的代理变量, 故模型之间的差别更明显.
5 结束语
通过对经典的CARR模型进行扩展, 构建了基于Gamma分布的2FSCR模型来描述价格极差的动态性. 该模型在结构上与双因子SV模型类似, 能够捕获波动率的长记忆特征以及解释更复杂的价格极差的混合分布形态, 因此模型具有非常高的灵活性. 为了估计2FSCR 模型的参数, 构建了基于连续粒子滤波的极大似然估计方法. 蒙特卡罗模拟实验表明, 该估计方法是有效性的. 采用SSE指数、SZSE指数、HSI指数和SPX指数四个指数数据进行了实证研究, 得到以下结论
(1)根据AIC和BIC对模型进行比较, 2FSCR模型相比CARR模型以及单因子的SCR模型都具有更好的数据拟合效果;
(2)针对模型广义残差的诊断分析表明, 2FSCR模型相比CARR模型和SCR模型能够更好地刻画价格极差新息的尾部分布, 能够更充分地捕获波动率的动态特征(时变性、聚集性与长记忆性);
(3)采用滚动窗方法对波动率进行预测, 利用价格极差与已实现波动率作为比较基准对模型的预测能力进行了比较分析, 发现2FSCR 模型相比CARR模型和SCR模型都具有更为优越的波动率预测效果. 特别地, 当采用已实现波动率作为比较基准时, 2FSCR模型在波动率预测精确性上的改进较为明显.
因此, 提出的2FSCR模型不仅具有更好的样本内数据拟合效果, 同时获得了更好的样本外波动率预测效果, 是一个较为成功的波动率模型. 未来可以考虑对该模型进行更深入的拓展和应用研究, 例如可以考虑引入“杠杆效应”并进一步考察模型的样本内与样本外表现, 而将模型应用于金融市场风险度量、衍生产品定价和资产组合管理等问题中, 也是未来重要的研究方向.
猜你喜欢
数学物理学报(2022年2期)2022-04-26
新世纪智能(数学备考)(2021年9期)2021-11-24
初中生世界(2021年43期)2021-11-23
新世纪智能(数学备考)(2020年9期)2021-01-04
今日农业(2019年12期)2019-08-13
中学数学研究(江西)(2019年5期)2019-06-11
文学少年(原创儿童文学)(2019年1期)2019-05-23
中国化肥信息(2019年3期)2019-04-25
中学生数理化·高一版(2018年10期)2018-11-08
环境保护与循环经济(2017年2期)2017-09-26
